.NET でのバッファーの使用
この記事では、複数のバッファーで実行されるデータの読み取りに役立つ型の概要について説明します。 これらは主に、PipeReader オブジェクトをサポートするために使用されます。
IBufferWriter<T>
System.Buffers.IBufferWriter<T> は、バッファーの同期を行う書き込みのためのコントラクトです。 最下位レベルでは、インターフェイスは次のようになります。
- 基本的で、簡単に使用できます。
- Memory<T> または Span<T> へのアクセスが可能です。
Memory<T>またはSpan<T>に書き込むことができ、書き込まれたT項目の数を確認できます。
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
上記のメソッドでは:
GetSpan(5)を使用して、IBufferWriter<byte>から少なくとも 5 バイトのバッファーを要求します。- 返された
Span<byte>に、ASCII 文字列 "Hello" のバイトを書き込みます。 - IBufferWriter<T> を呼び出して、バッファーに書き込まれたバイト数を示します。
この書き込みメソッドでは、IBufferWriter<T> によって提供される Memory<T>/Span<T> バッファーが使用されています。 代わりに、Write 拡張メソッドを使用して既存のバッファーを IBufferWriter<T> にコピーすることもできます。 Write によって、GetSpan/Advance を呼び出す処理が適切に実行されます。そのため、書き込み後に Advance を呼び出す必要はありません。
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> は、バッキング ストアが単一の隣接した配列である IBufferWriter<T> の実装です。
IBufferWriter の一般的な問題
GetSpanおよびGetMemoryでは、少なくとも要求された量のメモリを持つバッファーを返します。 正確なバッファー サイズを想定しないでください。- 連続する呼び出しで同じバッファーまたは同じサイズのバッファーが返される保証はありません。
- さらにデータの書き込みを続行するには、
Advanceを呼び出した後に新しいバッファーを要求する必要があります。Advanceを呼び出した後に、前に取得したバッファーに書き込むことはできません。
ReadOnlySequence<T>
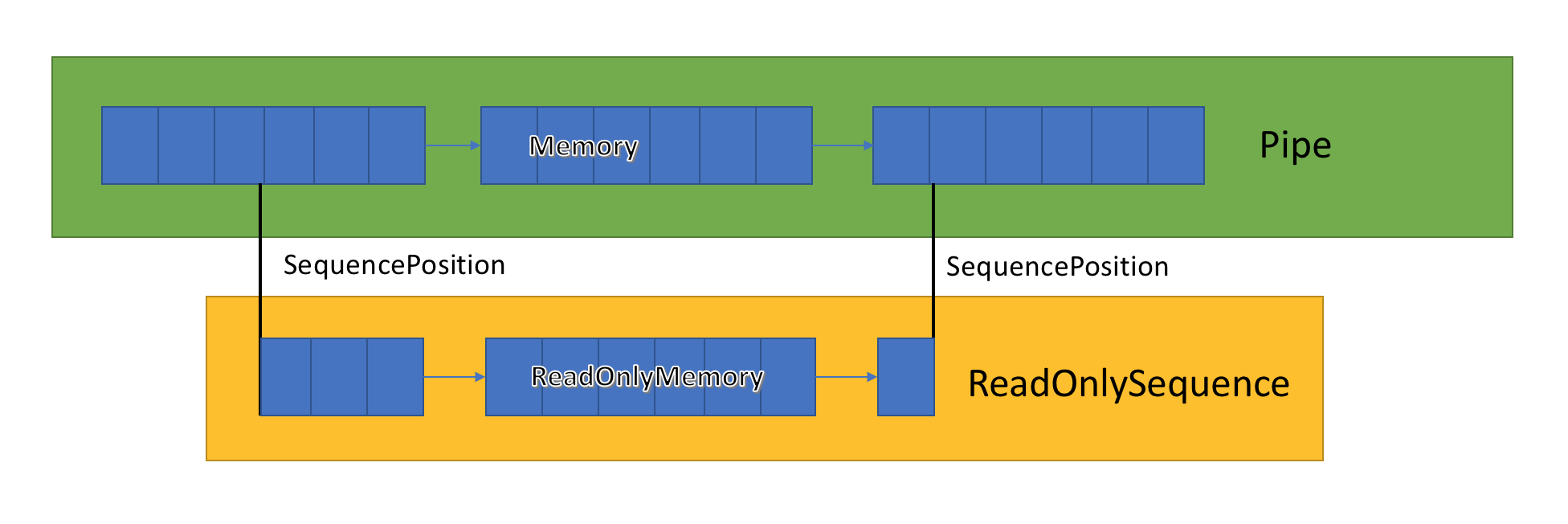
ReadOnlySequence<T> は、T の隣接したシーケンス、または隣接しないシーケンスを表すことができる構造体です。 これは次のものから構築できます。
T[]。ReadOnlyMemory<T>。- リンク リスト ノード ReadOnlySequenceSegment<T> と、シーケンスの開始位置および終了位置を表すインデックスのペア。
最も興味深いのは 3 番目の表現方法です。ReadOnlySequence<T> のさまざまな操作に対してパフォーマンスへの影響があるためです。
| 表現 | 操作 | 複雑さ |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
この混合表現のため、ReadOnlySequence<T> では整数ではなく SequencePosition としてインデックスが公開されます。 SequencePosition は:
- 発生元の
ReadOnlySequence<T>のインデックスを表す非透過的な値です。 - 整数とオブジェクトの 2 つの部分で構成されます。 これらの 2 つの値によって表されるものは、
ReadOnlySequence<T>の実装に関連付けられています。
データにアクセスする
ReadOnlySequence<T> では、列挙可能な ReadOnlyMemory<T> としてデータが公開されます。 基本的な foreach を使用して、各セグメントの列挙を行うことができます。
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
上記のメソッドでは、各セグメントで特定のバイトを検索しています。 各セグメントの SequencePosition を追跡する必要がある場合は、ReadOnlySequence<T>.TryGet の方が適しています。 次のサンプルでは、整数ではなく SequencePosition を返すように前のコードを変更しています。 SequencePosition を返すことにより、呼び出し元が特定のインデックスのデータを取得するための 2 回目のスキャンを回避できるという利点があります。
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
SequencePosition と TryGet の組み合わせは列挙子のように動作します。 position フィールドは、各反復の開始時に、ReadOnlySequence<T> 内の各セグメントの開始位置に変更されます。
上記のメソッドは、ReadOnlySequence<T> の拡張メソッドとして存在しています。 PositionOf を使用すると、上記のコードを簡略化できます。
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
ReadOnlySequence<T> の処理
ReadOnlySequence<T> の処理は困難な場合があります。シーケンス内の複数のセグメントにまたがってデータが分割されている可能性があるためです。 最適なパフォーマンスを得るには、コードを次の 2 つのパスに分割します。
- 単一セグメントのケースを処理する高速パス。
- セグメント間に分割されたデータを処理する低速パス。
複数のセグメントに分割されたシーケンスのデータを処理するには、いくつかの方法があります。
SequenceReader<T>を使用します。- セグメントごとにデータを解析し、解析されたセグメント内の
SequencePositionとインデックスを追跡する。 これにより不要な割り当てを回避できますが、非効率的になる可能性があります (特に小さなバッファーの場合)。 ReadOnlySequence<T>を隣接した配列にコピーし、それを 1 つのバッファーとして扱う。ReadOnlySequence<T>のサイズが小さい場合は、stackalloc 演算子を使用して、スタック割り当てバッファーにデータをコピーすることが適切な場合があります。- ArrayPool<T>.Shared を使用して、プールされた配列に
ReadOnlySequence<T>をコピーします。 ReadOnlySequence<T>.ToArray()を使用してください。 これは、新しいT[]をヒープに割り当てるため、ホット パスでは推奨されません。
次の例では、ReadOnlySequence<byte> を処理する一般的なケースをいくつか示しています。
バイナリ データの処理
次の例では、ReadOnlySequence<byte> の先頭から、4 バイトのビッグ エンディアンの整数長を解析しています。
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
テキスト データの処理
次のような例です。
ReadOnlySequence<byte>内の最初の改行 (\r\n) を検索し、out 'line' パラメーターを使用してそれを返します。- その line をトリミングし、入力バッファーから
\r\nを除外します。
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
空のセグメント
ReadOnlySequence<T> 内に空のセグメントを格納することができます。 セグメントを明示的に列挙するときに、空のセグメントが発生する可能性があります。
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
上記のコードでは、空のセグメントを持つ ReadOnlySequence<byte> を作成し、それらの空のセグメントがさまざまな API にどのような影響を与えるかを示しています。
- 空のセグメントを指す
SequencePositionを使用したReadOnlySequence<T>.Sliceでは、そのセグメントが保持されます。 - int を使用した
ReadOnlySequence<T>.Sliceでは、空のセグメントがスキップされます。 ReadOnlySequence<T>を列挙すると、空のセグメントが列挙されます。
ReadOnlySequence<T> と SequencePosition に関する潜在的な問題
ReadOnlySequence<T>/SequencePosition を扱うときには、通常の ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int に対して、いくつかの通常とは異なる結果が発生します。
SequencePositionは特定のReadOnlySequence<T>の位置マーカーであり、絶対位置ではありません。 これは特定のReadOnlySequence<T>を基準にするため、発生元のReadOnlySequence<T>の外部で使用されても意味がありません。ReadOnlySequence<T>を使用せずにSequencePositionに対する算術演算を行うことはできません。 つまり、position++などの基本的な処理は、position = ReadOnlySequence<T>.GetPosition(1, position)のように記述されます。GetPosition(long)では、負のインデックスがサポートされていません。 つまり、すべてのセグメントをたどることなく最後から 2 番目の文字を取得することはできません。- 2 つの
SequencePositionを比較できないため、次のことが困難になります。- ある位置が別の位置より大きいか小さいかを確認する。
- いくつかの解析アルゴリズムを記述する。
ReadOnlySequence<T>はオブジェクト参照よりも大きいため、可能な場合は in または ref によって渡す必要があります。inまたはrefによってReadOnlySequence<T>を渡すことで、struct のコピーを減らすことができます。- 空のセグメントは:
ReadOnlySequence<T>内で有効です。ReadOnlySequence<T>.TryGetメソッドを使った反復処理中に発生する可能性があります。SequencePositionオブジェクトと共にReadOnlySequence<T>.Slice()メソッドを使ったシーケンスのスライスで発生する可能性があります。
SequenceReader<T>
ReadOnlySequence<T>の処理を簡略化するために .NET Core 3.0 で導入された新しい型です。- 単一セグメントの
ReadOnlySequence<T>と複数セグメントのReadOnlySequence<T>の違いが統合されます。 - 複数のセグメントに分割されている場合でもされていない場合でも、バイナリ データとテキスト データ (
byteとchar) を読み取るためのヘルパーが提供されます。
バイナリ データと区切られたデータの両方を処理するための組み込みメソッドが用意されています。 以下のセクションでは、これらの同じメソッドが SequenceReader<T> でどのように使用されるかを示します。
データにアクセスする
SequenceReader<T> には、ReadOnlySequence<T> 内のデータを直接列挙するためのメソッドが用意されています。 次のコードは、一度に byte ずつ ReadOnlySequence<byte> を処理する例です。
while (reader.TryRead(out byte b))
{
Process(b);
}
CurrentSpan を使用すると、現在のセグメントの Span が公開されます。これは、このメソッド内で手動で行われたことに似ています。
位置の使用
次のコードでは、SequenceReader<T> を使った FindIndexOf の実装例を示します。
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
バイナリ データの処理
次の例では、ReadOnlySequence<byte> の先頭から、4 バイトのビッグ エンディアンの整数長を解析しています。
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
テキスト データの処理
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
SequenceReader<T> の一般的な問題
SequenceReader<T>は変更可能な構造体であるため、常に参照渡しする必要があります。SequenceReader<T>は ref struct であるため、同期メソッド内でのみ使用でき、フィールドに格納することはできません。 詳細については、「割り当てを回避する」を参照してください。SequenceReader<T>は、順方向専用のリーダーとして使用するために最適化されています。Rewindは、他のRead、Peek、IsNextAPI を使用しても対処できない小規模なバックアップを目的としています。
.NET
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示