クエリ処理アーキテクチャ ガイド
適用対象:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
SQL Server データベース エンジンは、ローカル テーブル、パーティション テーブル、複数のサーバーに分散されたテーブルなど、さまざまなデータ ストレージ アーキテクチャでクエリを処理します。 以下のセクションでは、SQL Server でクエリを処理して、実行プランのキャッシュによりクエリの再利用を最適化する方法について説明します。
実行モード
SQL Server データベース エンジンは、2 つの異なる処理モードで Transact-SQL ステートメントを処理できます。
- 行モード実行
- バッチ モード実行
行モード実行
行モード実行は、データが行形式で格納される、従来の RDBMS テーブルで使用されるクエリ処理方法です。 クエリが実行され、行ストア テーブルのデータにアクセスするとき、実行ツリーの演算子と子演算子は、テーブル スキーマに指定されている列全体で、必要な行をそれぞれ読み取ります。 SELECT ステートメント、JOIN 述語、フィルター述語で参照される結果セットに必要な列を SQL Server は読み取られる各行から取得します。
Note
行モード実行は OLTP シナリオで非常に効率的ですが、データ ウェアハウスのシナリオなど、大量のデータをスキャンするときは効率性が下がることがあります。
バッチ モード実行
バッチ モード実行は、複数の行をまとめて処理するためのクエリ処理方法です (そのため、バッチという言葉が使われています)。 バッチ内の各列は、別個のメモリ領域のベクトルとして格納されています。そのため、バッチ モード処理はベクトル基準となります。 バッチ モード処理ではまた、マルチコア CPU 向けに最適化されており、最新ハードウェアでメモリ スループットを上げるアルゴリズムが使用されています。
最初に導入されたとき、バッチ モード実行は、列ストア ストレージ形式と緊密に統合され、このストレージ形式に合わせて最適化されていました。 ただし、SQL Server 2019 (15.x) 以降、Azure SQL Database では、バッチ モードの実行に列ストア インデックスが不要になります。 詳細については、「行ストアでのバッチ モード」を参照してください。
バッチ モードの処理は、可能な場合は圧縮データに対して行われるので、行モード実行で使用される交換操作が不要になります。 結果的に、並行処理の向上と高速なパフォーマンスが得られます。
クエリがバッチ モードで実行され、列ストア インデックスのデータにアクセスするとき、実行ツリーの演算子と子演算子は、列セグメントにある複数の行をまとめて読み取ります。 SQL Server は、SELECT ステートメント、JOIN 述語、フィルター述語で参照される結果に必要な列のみ読み取ります。 列ストア インデックスの詳細については、「列ストア インデックスのアーキテクチャ」を参照してください。
Note
バッチ モード実行は、大量のデータが読み取られ、集計される、データ ウェアハウス シナリオで非常に効率的となります。
SQL ステートメントの処理
単一の Transact-SQL ステートメントの処理は、SQL Server で Transact-SQL ステートメントを実行する最も基本的な方法です。 ローカルのベース テーブルだけを参照する (ビューやリモート テーブルは参照しない) 単一の SELECT ステートメントを処理する手順が、この基本的な処理の良い例です。
論理演算子の優先順位
1 つのステートメントで複数の論理演算子を使用すると、最初に NOT が評価され、次に AND、最後に OR が評価されます。 算術演算子、およびビット演算子は論理演算子より前に処理されます。 詳細については、「Operator Precedence (Transact-SQL)」 (演算子の順位 (Transact-SQL)) を参照してください。
次の例では、色の条件が製品モデル 21 には該当しますが、製品モデル 20 には該当しません。これは、AND が OR よりも優先されるためです。
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
OR が必ず最初に評価されるように、かっこを付け加えることでクエリの意味を変えることができます。 次のクエリでは、モデル 20 とモデル 21 で赤色の製品のみが検索されます。
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
必要ない場合でもかっこを使用すると、クエリが読みやすくなり、演算子の優先順位が原因の微妙な間違いを犯す危険性が低減されます。 かっこを使用することでパフォーマンスが大幅に低下することはありません。 次の例は、元の例と構文は同じですが、元の例よりも読みやすくなっています。
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
SELECT ステートメントを最適化する
SELECT ステートメントは非手続き型であり、要求したデータを取得するときにデータベース サーバーで使用する手順が細かく指定されません。 つまり、データベース サーバーが SELECT ステートメントを分析して、要求したデータを抽出する最も効率的な方法を決定する必要があります。 これを、 SELECT ステートメントの最適化と呼びます。 また、最適化を行うコンポーネントをクエリ オプティマイザーと呼びます。 クエリ オプティマイザーへの入力は、クエリ、データベース スキーマ (テーブル定義やインデックスの定義)、およびデータベース統計で構成されます。 クエリ オプティマイザーの出力がクエリ実行プランです。これは、クエリ プランや実行プランと呼ばれることもあります。 実行プランの内容については、この記事の後半で詳しく説明します。
単一の SELECT ステートメントを最適化する場合のクエリ オプティマイザーの入出力は、次の図のようになります。

SELECT ステートメントは次の事項だけを定義します。
- 結果セットの形式。 ほとんどの場合、選択リスト内で指定します。 ただし、
ORDER BYやGROUP BYなどの句も結果セットの最終形式に影響します。 - 取得するデータが含まれているテーブル。 これは
FROM句で指定します。 SELECTステートメントを実行するためにテーブルを論理的に関連付ける方法。 これは、結合指定で定義され、WHERE句またはFROMに続くON句に現れる場合があります。- 基になるテーブルの行が
SELECTステートメントの対象になるために満たす必要がある条件。WHERE句とHAVING句で指定します。
クエリ実行プランは、次の事項を定義しています。
基になるテーブルにアクセスする順序。
通常、データベース サーバーからベース テーブルにアクセスして結果セットを構築する順序は何とおりもあります。 たとえば、SELECTステートメントが 3 つのテーブルを参照している場合、データベース サーバーは最初にTableAにアクセスし、TableAのデータを使用してTableBから一致する行を抽出します。次に、TableBのデータを使用してTableCのデータを抽出することができます。 データベースがテーブルにアクセスする際に可能な順序には、次の組み合わせがあります。
TableC、TableB、TableA、または
TableB、TableA、TableC、または
TableB、TableC、TableA、または
TableC、TableA、TableB各テーブルからデータを取り出すための方法。
通常、各テーブルのデータにアクセスする方法にも何とおりかあります。 特定のキー値を持つ数行だけが必要な場合、データベース サーバーではインデックスを使用できます。 テーブル内のすべての行が必要な場合は、インデックスを無視してテーブル スキャンを実行できます。 テーブル内のすべての行が必要なときに、キー列がORDER BYにあるインデックスが存在する場合、テーブル スキャンではなくインデックス スキャンを行うと、結果セットの並べ替えを個別に行わずに済みます。 テーブルが非常に小さい場合は、テーブルにどのようにアクセスするときでもテーブル スキャンが最も効率的な方法になることがあります。計算に使用される方法と、各テーブルのデータのフィルター処理、集計、並べ替えを行う方法。
テーブルのデータにアクセスするときは、データに対して計算を実行するためのさまざまな方法が存在します (スカラー値の計算など)。また、クエリ テキストで定義されているようにデータの集計や並べ替えを行ったり (GROUP BY句やORDER BY句を使う場合など)、データをフィルター処理したり (WHERE句やHAVING句を使う場合など) するための方法も多数存在します。
可能性のある多数のプラン候補の中から実行プランを 1 つ選択する処理を最適化と呼びます。 クエリ オプティマイザーは、データベース エンジンの最も重要なコンポーネントの 1 つです。 クエリ オプティマイザーはクエリの分析やプランの選択を行うため、オーバーヘッドが発生します。ただし、クエリ オプティマイザーが効率的な実行プランを選択すれば、このオーバーヘッドの数倍の負荷を削減することができます。 たとえば、2 つの建築会社が一軒の住宅に同じ青写真を提供する場合について考えてみます。 一方の会社は数日かけて建築プランを立て、他方の会社はプランを立てずに建築を開始するとします。ほとんどの場合、プロジェクトのプランに時間をかけた会社の方が先に完成します。
SQL Server クエリ オプティマイザーは、コストベースのオプティマイザーです。 実行プラン候補ごとに、計算に使用するリソースの量の観点から関連するコストが異なります。 クエリ オプティマイザーでは、候補のプランを分析し、算出コストが最も低いプランを選択する必要があります。 複雑な SELECT ステートメントの場合、何千もの実行プラン候補があります。 このような場合、クエリ オプティマイザーはすべての組み合わせを分析するわけではありません。 複雑なアルゴリズムを使用して、理論上の最低コストに最も近い実行プランを迅速に見つけ出します。
SQL Server クエリ オプティマイザーは、リソース コストが最も低い実行プランに限定して選択するわけではありません。妥当なリソース コストで、最も迅速に結果を返すプランを選択します。 たとえば、クエリを並列に処理すれば、直列に処理するよりもリソースを多く使用します。ただし、クエリの完了時間は短縮されます。 SQL Server クエリ オプティマイザーは、サーバー側の負荷に悪影響がない限り、並列実行プランを使用して結果を返します。
SQL Server クエリ オプティマイザーは、テーブルやインデックスから情報を取り出す複数の方法のリソース コストを算出する場合、分布統計に大きく依存します。 列とインデックスに対する分布統計が保持されます。この分布統計では、基になるデータの密度 1 に関する情報が保持されます。 これは、特定のインデックスまたは列内の値の選択度を表すために使用されます。 たとえば、車を表すテーブルの場合、同メーカーの車がいくつもあります。ただし、VIN (車両番号) はそれぞれの車両固有のものです。 VIN 上のインデックスは、製造元でのインデックスより選択度が高くなります。これは VIN の密度が製造元の場合より低いからです。 インデックス統計が最新でない場合、クエリ オプティマイザーはテーブルの現在の状態に最適な選択ができないことがあります。 密度の詳細については、「統計」を参照してください。
1密度では、データ内に存在する一意の値の分布、または特定の列における重複値の平均数が定義されます。 密度が減少するにつれて、値の選択度が高くなります。
SQL Server クエリ オプティマイザーを使用すると、プログラマーやデータベース管理者が入力しなくても、データベース内の状態の変化に合わせてデータベース サーバーを動的に調整できるので、クエリ オプティマイザーは不可欠です。 これにより、プログラマはクエリの最終結果の記述だけに重点を置くことができます。 SQL Server クエリ オプティマイザーは、ステートメントを実行するたびに、データベースの状態に合わせて効率的な実行プランを構築します。
Note
SQL Server Management Studio には、実行プランを表示するための 3 つのオプションがあります。
- *"推定実行プラン"。これは、クエリ オプティマイザーによって生成されたコンパイル済みプランです。
- "実際の実行プラン"。これは、コンパイル済みプランにその実行コンテキストを加えたものと同じです。 これには、実行が完了した後に利用可能なランタイム情報 (実行に関する警告など)、または実行中に使用された経過時間および CPU 時間 (新しいバージョンのデータベース エンジンの場合) が含まれます。
- "ライブ クエリ統計"。これは、コンパイル済みプランにその実行コンテキストを加えたものと同じです。 これには、実行が進行中のランタイム情報が含まれ、1 秒ごとに更新されます。 ランタイム情報には、演算子を通過する実際の行数などが含まれます。
SELECT ステートメントを処理する
SQL Server が単一の SELECT ステートメントを処理する基本的な手順は次のとおりです。
- パーサーが
SELECTステートメントをスキャンし、キーワード、式、演算子、識別子などの論理単位に分解します。 - 基になるデータを結果セットで必要な形式に変換する論理手順を記述するクエリ ツリーが構築されます。クエリ ツリーはシーケンス ツリーとも呼ばれます。
- クエリ オプティマイザーでは、基になるテーブルにアクセスできるさまざまな方法が分析されます。 その後、使用するリソースが少なく、最も短時間で結果を返す一連の手順が選択されます。 クエリ ツリーが更新され、この一連の手順が正確に記録されます。 この最終的に得られた最適化済みのクエリ ツリーを実行プランと呼びます。
- リレーショナル エンジンによって、実行プランの実行が開始されます。 リレーショナル エンジンは、ベース テーブルからのデータを必要とする手順を処理するときに、要求した行セットのデータを渡すようにストレージ エンジンに要求します。
- リレーショナル エンジンでは、ストレージ エンジンから返されたデータが結果セット用に定義された形式に変換され、結果セットをクライアントに返します。
定数のたたみ込みと式の評価
SQL Server では、クエリのパフォーマンスを向上するために、いくつかの定数式を前もって評価します。 これを定数のたたみ込みと呼びます。 定数は Transact-SQL リテラル (3、'ABC'、'2005-12-31'、1.0e3、0x12345678 など) です。
たたみ込み可能な式
SQL Server では、次の種類の式に定数のたたみ込みを適用します。
- 定数のみから構成される数式 (
1 + 1、5 / 3 * 2など)。 - 定数のみから構成される論理式 (
1 = 1、1 > 2 AND 3 > 4など)。 - SQL Server によってたたみ込み可能と判断された組み込み関数 (
CAST、CONVERTなど)。 固有の関数は、通常はたたみ込み可能です。ただし結果が関数への入力のみによって決まらず、SET オプション、言語設定、データベース オプション、暗号化キーなどの、状況によって変わりうる他の情報を交えて決まる場合は例外です。 非決定論的関数はたたみ込み不可能です。 組み込みの決定的関数はたたみ込み可能ですが、一部例外があります。 - CLR ユーザー定義型の決定論的メソッドおよび決定論的スカラー値 CLR ユーザー定義関数 (SQL Server 2012 (11.x) 以降)。 詳細については、「CLR ユーザー定義関数およびメソッドの定数たたみ込み」を参照してください。
Note
例外の 1 つは LOB 型です。 たたみ込み処理の出力の種類がラージ オブジェクト型 (text、ntext、image、nvarchar(max)、varchar(max)、varbinary(max)、または XML) である場合、SQL Server では式はたたみ込まれません。
たたみ込み不可能な式
その他の種類の式は、すべてたたみ込み不可能です。 具体的には、次に示す種類の式です。
- 定数ではない式 (結果が列の値によって変わる式など)。
- 結果がローカル変数またはパラメーター (@x など) によって変わる式。
- 非決定的関数。
- ユーザー定義 Transact-SQL 関数1。
- 結果が言語設定によって変わる式。
- 結果が SET オプションによって変わる式。
- 結果がサーバー構成オプションによって変わる式。
1 SQL Server 2012 (11.x) より前は、決定論的スカラー値 CLR ユーザー定義関数および CLR ユーザー定義型のメソッドはたたみ込み可能ではありませんでした。
たたみ込み可能/不可能な定数式の例
次のクエリがあるとします。
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
このクエリの PARAMETERIZATION データベース オプションが FORCED に設定されていない場合、クエリをコンパイルする前に式 117.00 + 1000.00 が評価され、その結果である 1117.00 に置き換えられます。 定数のたたみ込みには、次に示す利点があります。
- 実行時に式を繰り返し評価する必要がありません。
- クエリ
TotalDue > 117.00 + 1000.00の部分の結果セットのサイズをクエリ オプティマイザーで推定するときは、評価後の式の値が使用されます。
一方、ユーザー定義関数を含んだ式は決定論的関数であっても SQL Server がたたみ込まないので、dbo.f がスカラー値のユーザー定義関数である場合、式 dbo.f(100) はたたみ込まれません。 パラメーター化の詳細については、この記事で後述する「強制パラメーター化」を参照してください。
式の評価
また、定数のたたみ込みは行われませんが、引数がコンパイル時に確定する式は、引数がパラメーターと定数のどちらであっても、最適化のときにクエリ オプティマイザーのカーディナリティ (結果セットのサイズ) 推定機能によって評価されます。
具体的には、次の組み込み関数と特殊演算子は、入力がすべて確定する場合コンパイル時に評価されます: UPPER、LOWER、RTRIM、DATEPART( YY only )、GETDATE、CAST、CONVERT。 次に示す演算子も、入力がすべて確定する場合コンパイル時に評価されます。
- 算術演算子: +、-、*、/、単項演算子の -
- 論理演算子:
AND、OR、NOT - 比較演算子: <、>、<=、>=、<>、
LIKE、IS NULL、IS NOT NULL
上記以外の関数および演算子は、カーディナリティを推定するときにはクエリ オプティマイザーによって評価されません。
コンパイル時の式の評価の例
次のストアド プロシージャについて考えてみましょう。
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
このストアド プロシージャの SELECT ステートメントを最適化するとき、条件 OrderDate > @d+1 に対する結果セットの予測カーディナリティがクエリ オプティマイザーによって評価されます。 式 @d+1 は @d がパラメーターであるために定数のたたみ込みが行われません。 しかし、最適化のときにはパラメーターの値が確定しています。 したがって結果セットのサイズがクエリ オプティマイザーによって正確に推定できるので、適切なクエリ プランが選択されます。
次は、上記のクエリの @d2 をローカル変数 @d+1 に置き換え、クエリではなく SET ステートメントで式を評価するストアド プロシージャの例を考えてみます。
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
SQL Server で MyProc2 の SELECT ステートメントを最適化するとき、@d2 の値は確定していません。 そのため、クエリ オプティマイザーでは OrderDate > @d2 の選択度に対して既定の推定が使用されます (この場合は 30%)。
その他のステートメントを処理する
SELECT ステートメントの処理で説明した基本的な手順は、INSERT、UPDATE、DELETE などの他の Transact-SQL ステートメントにも適用されます。 UPDATE ステートメントと DELETE ステートメントは、いずれも変更または削除する行セットを対象とする必要があります。 これらの行を特定する処理は、 SELECT ステートメントの結果セットを得るために使用された、基になる行を特定する処理と同じです。 UPDATE ステートメントと INSERT ステートメントのどちらにも、更新または挿入するデータ値を指定する SELECT ステートメントを埋め込むことができます。
CREATE PROCEDURE または ALTER TABLE などの DDL (データ定義言語) ステートメントも、最終的には、システム カタログ テーブル上の一連のリレーショナル操作になります。また、場合によっては ALTER TABLE ADD COLUMN など、データ テーブルに対する一連のリレーショナル操作になります。
作業テーブル
リレーショナル エンジンでは、Transact-SQL ステートメントで指定された論理演算を行う際に、作業テーブルの作成が必要な場合があります。 作業テーブルとは、中間結果を格納するための内部テーブルです。 作業テーブルは、特定の GROUP BYクエリ、 ORDER BYクエリ、 UNION クエリで生成されます。 たとえば、インデックスの対象になっていない列が ORDER BY 句で参照されている場合、リレーショナル エンジンでは、要求された順に結果セットを並べ替えるための作業テーブルを生成する必要が生じることがあります。 また、クエリ プランの一部を実行した結果を一時的に格納するためのスプールとして作業テーブルが使用されることもあります。 作業テーブルは tempdb に作成され、不要になると自動的に削除されます。
ビューの解決
SQL Server クエリ プロセッサでは、インデックス付きビューとインデックスなしのビューの処理方法が異なります。
- インデックス付きビューの行は、テーブルと同じ形式でデータベースに格納されます。 クエリ オプティマイザーでクエリ プランにインデックス付きビューを使用することが決定されると、インデックス付きビューはベース テーブルと同じ方法で処理されます。
- インデックスなしのビューでは、ビューの行ではなく、定義のみが格納されます。 クエリ オプティマイザーにより、ロジックがビューの定義から、インデックスなしのビューを参照する Transact-SQL ステートメントに対して作成された実行プランに組み込まれます。
SQL Server のクエリ オプティマイザーでは、いつインデックス付きビューを使用するかを決定するときに、テーブルのインデックスをいつ使用するかを決定するのとよく似たロジックが使用されます。 インデックス付きビューに含まれるデータが Transact-SQL ステートメントの一部またはすべてを対象としており、クエリ オプティマイザーによってビュー上のインデックスが低コストのアクセス パスであると判断されると、クエリ内でビューが名前で参照されるかどうかにかかわらず、クエリ オプティマイザーではインデックスが選択されます。
Transact-SQL ステートメントからインデックスなしのビューが参照されるときは、パーサーとクエリ オプティマイザーで Transact-SQL ステートメントとビューのソースが両方分析され、それらが 1 つの実行プランに解決されます。 Transact-SQL ステートメントの実行プランとビューの実行プランに別々に解決されるわけではありません。
たとえば、次のビューがあるとします。
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
次の 2 つの Transact-SQL ステートメントはどちらも、このビューに基づいてベース テーブルに同じ操作を行い、同じ結果を生成します。
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
SQL Server Management Studio のプラン表示機能では、リレーショナル エンジンがこの 2 つの SELECT ステートメントのどちらに対しても同じ実行プランを構築することが示されます。
ビューでヒントを使用する
クエリのビューに設定されるヒントは、ベース テーブルにアクセスするためにビューを展開するときに検出される他のヒントと競合することがあります。 この競合が発生すると、クエリはエラーを返します。 たとえば、定義にテーブル ヒントが含まれている、次のビューについて考えてみます。
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
ここで次のクエリを入力したとします。
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
このクエリは失敗します。その理由として、ビューが展開されるときに、クエリ内の SERIALIZABLE ビューに適用される Person.AddrState ヒントが、ビューの Person.Address テーブルと Person.StateProvince テーブルの両方に反映されます。 しかし、ビューを展開することで、 NOLOCK の Person.Addressヒントも公開されます。 その結果、 SERIALIZABLE ヒントと NOLOCK ヒントが競合するので、クエリ結果は正しくありません。
PAGLOCK、 NOLOCK、 ROWLOCK、 TABLOCK、 TABLOCKX の各テーブル ヒントが競合するのと同様に、 HOLDLOCK、 NOLOCK、 READCOMMITTED、 REPEATABLEREAD、 SERIALIZABLE の各テーブル ヒントも互いに競合します。
ヒントは、入れ子になったビュー全体に反映されます。 たとえば、クエリでビュー HOLDLOCK に v1ヒントが適用されるとします。 v1 を展開すると、ビュー v2 がその定義の一部であることがわかります。 v2の定義では、ベース テーブルの 1 つに NOLOCK ヒントが含まれています。 しかし、このテーブルはビュー HOLDLOCK のクエリから v1ヒントも継承します。 その結果、 NOLOCK ヒントと HOLDLOCK ヒントが競合するので、クエリが失敗します。
ビューが含まれるクエリで FORCE ORDER ヒントを使用すると、ビュー内のテーブルの結合順序は、順序付けられた構造内のビューの位置によって決まります。 たとえば、次のクエリは 3 つのテーブルとビューから選択を行います。
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
さらに、次に示すように View1 が定義されています。
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
クエリ プランでの結合順序は、 Table1、 Table2、 TableA、 TableB、 Table3の順になります。
ビューのインデックスを解決する
インデックス付きビューは他のインデックスと同様、使用することにメリットがあるとクエリ オプティマイザーで判断された場合にのみ、SQL Server でクエリ プランに使用されます。
インデックス付きビューは SQL Server のどのエディションでも作成できます。 SQL Server の一部の古いバージョンのエディションによっては、クエリ オプティマイザーにより自動的にインデックス付きビューが考慮されます。 SQL Server の一部の古いバージョンのエディションによっては、インデックス付きビューを使用するには NOEXPAND テーブル ヒントを使用する必要があります。 SQL Server 2016 (13.x) Service Pack 1 より前のバージョンでは、SQL Server の特定のエディションでのみ、クエリ オプティマイザーによるインデックス付きビューの自動的な使用がサポートされています。 すべてのエディションでは、インデックス付きビューの自動使用がサポートされているためです。 また、Azure SQL Database および Azure SQL Managed Instance では、NOEXPAND ヒントを指定しなくても、インデックス付きビューの自動的な使用もサポートされます。
SQL Server クエリ オプティマイザーは、次の条件が満たされている場合にインデックス付きビューを使用します。
- 次のセッション オプションが
ONに設定されている。ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
NUMERIC_ROUNDABORTセッション オプションは OFF に設定します。- クエリ オプティマイザーにより、ビューのインデックス列とクエリ要素との間で、次のような項目の一致が検出される。
- WHERE 句の検索条件の述語
- 結合操作
- 集計関数
GROUP BY句- テーブルの参照
- クエリ オプティマイザーが検討したアクセス方法の中で、インデックスを使用した場合の推定コストが最小である。
- クエリ内で (直接、またはビューを展開して基になるテーブルにアクセスすることにより) 参照しているテーブルのうち、インデックス付きビュー内のテーブル参照に対応しているすべてのテーブルについて、クエリ内で適用されているヒントの組み合わせが同じである。
Note
現在のトランザクション分離レベルにかかわらず、このコンテキストでは READCOMMITTED ヒントと READCOMMITTEDLOCK ヒントは常に異なるヒントと見なされます。
SET オプションおよびテーブル ヒントの要件を除くと、上記の条件は、テーブル インデックスがクエリをカバーするかどうかを判断するためにクエリ オプティマイザーにより使用されるルールと同じです。 クエリで他に何も指定しなくてもインデックス付きビューを使用できます。
クエリの FROM 句でインデックス付きビューを明示的に参照しなくても、クエリ オプティマイザーはインデックス付きビューを使用します。 ベース テーブル内の列に対する参照がクエリに含まれており、その参照がインデックス付きビューにも存在する場合、クエリ オプティマイザーは、インデックス付きビューの使用によりアクセス コストを最小にできると推定できれば、インデックス付きビューを選択します。これはクエリ オプティマイザーが、ベース テーブルのインデックスを、クエリ内で直接参照されていない場合に選択するのと同じ手法です。 クエリ内で指定されている 1 つ以上の列をカバーするオプションとして最もコストが低ければ、クエリで参照されていない列がビューに含まれていても、クエリ オプティマイザーがそのビューを選択することがあります。
クエリ オプティマイザーは FROM 句で参照されているインデックス付きビューを標準のビューとして扱います。 最適化処理の開始時には、ビューの定義をクエリにまで拡張します。 そのうえで、インデックス付きビューの照合を実行します。 クエリ オプティマイザーが選択した最終的な実行プランでは、インデックス付きビューが使用されることも、ビューが参照するベース テーブルにアクセスすることにより、ビュー内の必要なデータが具体化されることもあります。 いずれにしても、最もコストが低いプランが選択されます。
インデックス付きビューでヒントを使用する
EXPAND VIEWS クエリ ヒントを指定すると、ビューのインデックスがクエリで使用されるのを禁止できます。 NOEXPAND テーブル ヒントを指定すると、クエリの FROM 句で指定したインデックス付きビューのインデックスを強制的に使用することができます。 ただし、各クエリを使用するための最適なアクセス方法はクエリ オプティマイザーによる動的な判断に任せることをお勧めします。 EXPAND および NOEXPAND を使用するのは、テストで結果パフォーマンスの大幅な向上が示された場合のみにしてください。
EXPAND VIEWSオプションは、クエリ オプティマイザーに対し、クエリ全体に関してビュー インデックスを使用しないことを指定します。NOEXPANDをビューに対して指定した場合、ビューに定義されたインデックスを使用することがクエリ オプティマイザーにより検討されます。NOEXPANDをオプションのINDEX()句で指定すると、クエリ オプティマイザーの判断で指定されたインデックスが強制的に使用されます。NOEXPANDを指定できるのはインデックス付きビューに対してのみであり、インデックスのないビューには指定できません。 SQL Server 2016 (13.x) Service Pack 1 より前のバージョンでは、SQL Server の特定のエディションでのみ、クエリ オプティマイザーによるインデックス付きビューの自動的な使用がサポートされています。 すべてのエディションでは、インデックス付きビューの自動使用がサポートされているためです。 また、Azure SQL Database および Azure SQL Managed Instance では、NOEXPANDヒントを指定しなくても、インデックス付きビューの自動的な使用もサポートされます。
ビューを含んだクエリで NOEXPAND と EXPAND VIEWS のいずれも指定しない場合、基になるテーブルにアクセスするためにビューが拡張されます。 ビューを構成するクエリにテーブル ヒントが含まれている場合、基になるテーブルにヒントが反映されます (この処理の詳細については、「ビューの解決」を参照してください)。ビューの基になるテーブルに存在するヒントのセットがテーブル間で同一であれば、クエリはインデックス付きビューと一致する可能性があります。 ほとんどの場合、ヒントはビューから直接継承されるので双方のヒントは一致します。 ただし、クエリの参照先がビューではなくテーブルであり、これらのテーブルに直接適用されているヒントがテーブルによって異なる場合、そのようなクエリはインデックス付きビューと一致しません。 ビューの展開後、INDEX、PAGLOCK、ROWLOCK、TABLOCKX、UPDLOCK、XLOCK のいずれかのヒントがクエリの参照先テーブルに適用される場合、クエリはインデックス付きビューと一致しません。
INDEX (index_val[ ,...n] ) という形式のテーブル ヒントでクエリ内のビューを参照しているときに、NOEXPAND ヒントを指定しない場合、インデックス ヒントは無視されます。 特定のインデックスを使用するように指定するには NOEXPAND を使用します。
通常、インデックス付きビューがクエリに一致すると、クエリ内のテーブルまたはビューに指定したヒントが直接インデックス付きビューに適用されます。 クエリ オプティマイザーがインデックス付きビューを使用しないと判断した場合、ヒントはすべて、ビュー内で参照しているテーブルに直接伝達されます。 詳細については、「ビューの解決」を参照してください。 この伝達は、結合ヒントには当てはまりません。 結合ヒントはクエリ内の元の場所でのみ適用されます。 クエリ オプティマイザーがクエリとインデックス付きビューを照合する際に、結合ヒントは無視されます。 結合ヒントを含むクエリの一部に一致したインデックス付きビューがクエリ プランで使用される場合、その結合ヒントはプランに使用されません。
インデックス付きビューの定義ではヒントが許可されていません。 互換性モードが 80 以上の場合、SQL Server はインデックス付きビューの定義の保守時にも、インデックス付きビューを使用したクエリの実行時にも、定義に含まれているヒントを無視します。 互換モード 80 では、インデックス付きビューの定義でヒントを使用しても構文エラーにはなりませんが、ヒントは無視されます。
詳細については、「テーブル ヒント (Transact-SQL)」を参照してください。
分散パーティション ビューを解決する
SQL Server のクエリ プロセッサでは、分散パーティション ビューのパフォーマンスが最適化されます。 分散パーティション ビューのパフォーマンスで最も重要な点は、メンバー サーバー間で転送されるデータの量を最小限に抑えることです。
SQL Server では、リモート メンバー テーブルからのデータにアクセスするときに分散クエリを効率的に使用できる、高機能で動的なプランが構築されます。
- クエリ プロセッサでは、最初に OLE DB を使用して、各メンバー テーブルから CHECK 制約の定義が取得されます。 これにより、クエリ プロセッサは、メンバー テーブル間でキー値の分布をマップできるようになります。
- クエリ プロセッサでは、Transact-SQL ステートメントの
WHERE句で指定されたキーの範囲が、メンバー テーブルでの行の分布状況を示すマップと比較されます。 次に、クエリ プロセッサでは、分散クエリを使用して Transact-SQL ステートメントの完了に必要なリモート行だけを取得するクエリ実行プランが構築されます。 この実行プランでは、リモート メンバー テーブルのデータやメタデータへのアクセスが、情報が要求されるまで遅延されます。
たとえば、Customers テーブルが Server1 (CustomerID 1 から 3299999)、Server2 (CustomerID 3300000 から 6599999)、および Server3 (CustomerID 6600000 から 9999999) にパーティション分割されたシステムがあるとします。
Server1 で実行される次のクエリ用に構築される実行プランを考えてみます。
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
このクエリの実行プランでは、ローカル メンバー テーブルから CustomerID のキー値が 3200000 ~ 3299999 の行が抽出され、分散クエリを実行して Server2 からキー値が 3300000 ~ 3400000 の行が取得されます。
SQL Server のクエリ プロセッサでは、プランを構築する必要があるときにキー値がわからない Transact-SQL ステートメント用に、クエリの実行プランに動的なロジックを組み込むこともできます。 たとえば、次のようなストアド プロシージャがあるとします。
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server では、プロシージャが実行されるたびに @CustomerIDParameter パラメーターによって指定されるキー値を予測できません。 クエリ プロセッサはキー値を予測できないので、アクセスする必要のあるメンバー テーブルを予測することもできません。 この状況に対処するために、SQL Server では、動的フィルターと呼ばれる条件ロジックを含む実行プランが構築され、アクセスされるメンバー テーブルが入力パラメーター値に基づいて制御されます。 GetCustomer ストアド プロシージャが Server1 で実行されたと仮定すると、実行プランのロジックは次のように表すことができます。
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server では、パラメーター化されていないクエリに対してもこのような動的実行プランが構築されます。 クエリ オプティマイザーはクエリをパラメーター化し、実行プランを再利用できるようにします。 クエリ オプティマイザーがパーティション ビューを参照しているクエリをパラメーター化すると、必要な行が指定されたベース テーブルにあると仮定することができなくなります。 そのため、実行プランで動的フィルターを使用する必要があります。
ストアド プロシージャとトリガー実行
SQL Server では、ストアド プロシージャとトリガーのソースだけが格納されます。 ストアド プロシージャまたはトリガーを最初に実行するときに、ソースが実行プランにコンパイルされます。 時間が経過して実行プランがメモリから削除される前にストアド プロシージャまたはトリガーを再度実行すると、リレーショナル エンジンは既存の実行プランを検出してそれを再利用します。 時間が経過して実行プランがメモリから削除されると、新しい実行プランが構築されます。 これは、SQL Server がすべての Transact-SQL ステートメントに行うのと同じ処理です。 SQL Server で、動的 Transact-SQL のバッチと比較した場合の、ストアド プロシージャやトリガーのパフォーマンス上の主な利点は、Transact-SQL ステートメントが常に同じであることです。 したがって、リレーショナル エンジンを既存の実行プランに容易に適合させることができます。 その結果、ストアド プロシージャやトリガーのプランを簡単に再利用できます。
ストアド プロシージャとトリガーの実行プランは、ストアド プロシージャを呼び出すバッチやトリガーを起動するバッチの実行プランとは別に実行されます。 このため、ストアド プロシージャやトリガーの実行プランを何回でも再利用できます。
実行プランのキャッシュと再利用
SQL Server には、実行プランとデータ バッファーの両方を格納するためのメモリのプールが用意されています。 実行プランまたはデータ バッファーに割り当てられるプールの割合は、システムの状態によって動的に変動します。 実行プランの格納に使用されるメモリ プールの部分をプラン キャッシュといいます。
プラン キャッシュには、すべてのコンパイル済みプラン用の 2 つのストアがあります。
- Object Plans キャッシュ ストア (OBJCP)。これは、持続オブジェクト (ストアド プロシージャ、関数、およびトリガー) に関連するプランに使用されます。
- SQL Plans キャッシュ ストア (SQLCP)。これは、自動パラメーター化、動的、または準備されたクエリに関連するプランに使用されます。
以下のクエリでは、これら 2 つのキャッシュ ストアのメモリ使用量に関する情報が提供されます。
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Note
プラン キャッシュには、プランの格納に使用されない 2 つの追加のストアがあります。
- Bound Trees キャッシュ ストア (PHDR)。これは、ビュー、制約、および既定値のプランのコンパイル中に使われるデータ構造で使用されます。 これらの構造は、Bound Trees または Algebrizer Trees と呼ばれます。
- Extended Stored Procedures キャッシュ ストア (XPROC)。これは、Transact-SQL ステートメントを使わずに、DLL を使って定義されている、
sp_executeSqlやxp_cmdshellのような定義済みのシステム プロシージャに使用されます。 キャッシュされた構造には、プロシージャが実装されている関数名と DLL 名のみが含まれます。
SQL Server の実行プランは、主に次の要素から構成されます。
コンパイル済みプラン (またはクエリ プラン)
コンパイル プロセスで生成されるクエリ プランはほとんどの場合、任意の数のユーザーによって使用される、再入可能な読み取り専用のデータ構造です。 これには、次の情報が格納されます。論理演算子で記述される操作を実装する物理演算子。
データにアクセスし、フィルター処理し、集約する順序を決定する、これらの演算子の順序。
演算子を通過する推定行の数。
Note
新しいバージョンのデータベース エンジンでは、カーディナリティ推定に使用された統計オブジェクトに関する情報も格納されます。
tempdbの作業テーブルや作業ファイルなど、作成する必要があるサポート オブジェクト。 ユーザー コンテキストやランタイムの情報は、クエリ プランには格納されません。 また、メモリに複数のクエリ プランのコピーが配置されることはありません。すべての直列実行に 1 つのコピーが使用され、すべての並列実行に 1 つのコピーが使用されます。 並列実行用コピーは、並列処理の次数に関係なくすべての並列実行に適用されます。
実行コンテキスト
クエリを現在実行しているユーザーごとに、パラメーター値など、実行に固有のデータを保持するデータ構造体が用意されています。 このデータ構造体を実行コンテキストといいます。 実行コンテキストのデータ構造は再利用されますが、その内容は再利用されません。 別のユーザーが同じクエリを実行すると、新しいユーザーのコンテキストでデータ構造が再初期化されます。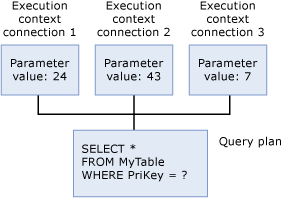
SQL Server で任意の Transact-SQL ステートメントが実行されると、データベース エンジンによって、まず、プラン キャッシュが調べられ、同じ Transact-SQL ステートメントの既存の実行プランが存在するかどうかが確認されます。 Transact-SQL ステートメントは、キャッシュされたプランで前に実行された Transact-SQL ステートメントと文字単位で一致する場合、既存と見なされます。 SQL Server では、既存のプランが見つかった場合にはそれが再利用され、Transact-SQL ステートメントを再びコンパイルするオーバーヘッドが削減されます。 実行プランが存在しない場合、SQL Server によってクエリの新しい実行プランが生成されます。
Note
一部の Transact-SQL ステートメントの実行プランは、プラン キャッシュに保持されません。たとえば、行ストア上で実行される一括操作ステートメントやサイズが 8 KB より大きい文字列リテラルを含むステートメントなどです。 これらのプランは、クエリの実行中にのみ存在します。
SQL Server には、特定の Transact-SQL ステートメントの既存の実行プランを検索する効率的なアルゴリズムが用意されています。 ほとんどのシステムでは、このスキャンで使用される最低限のリソースの量が、すべての Transact-SQL ステートメントをコンパイルせずに既存の実行プランを再利用することで節約できるリソースの量を超えることはありません。
新しい Transact-SQL ステートメントをプラン キャッシュ内の使用されていない既存の実行プランと照合するアルゴリズムでは、すべてのオブジェクト参照が完全に修飾されている必要があります。 たとえば、Person は下の SELECT ステートメント実行するユーザーに対する既定のスキーマであるものとします。 この例では、実行するために Person テーブルが完全修飾されている必要はありませんが、これは、2 番目のステートメントは既存のプランと一致しないのに対し、3 番目は一致することを意味します。
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
特定の実行に対する以下のいずれかの SET オプションを変更すると、プランを再利用する機能に影響します。これは、データベース エンジンで定数のたたみ込みが行われ、これらのオプションがこのような式の結果に影響するためです。
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
LANGUAGE
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
同じクエリに対する複数のプランをキャッシュする
クエリおよび実行プランは、データベース エンジンで一意に識別でき、フィンガープリントとよく似ています。
- クエリ プラン ハッシュは、特定のクエリの実行プランで計算されるバイナリ ハッシュ値であり、類似する実行プランを一意に識別するために使用されます。
- クエリ ハッシュは、クエリの Transact-SQL テキストで計算されるバイナリ ハッシュ値であり、クエリを一意に識別するために使用されます。
コンパイル済みプランは、プラン キャッシュからプラン ハンドルを使用して取得できます。これは、プランがキャッシュに残っている間だけ一定に保たれる一時 ID です。 プラン ハンドルは、バッチ全体のコンパイル済みプランから派生したハッシュ値です。 バッチ内の 1 つまたは複数のステートメントが再コンパイルされた場合でも、コンパイル済みプランのプラン ハンドルは変わりません。
Note
単一ステートメントではなくバッチに対してプランがコンパイルされた場合は、プラン ハンドルとステートメント オフセットを使用して、バッチ内の個々のステートメントのプランを取得できます。
sys.dm_exec_requests DMV には、各レコードの statement_start_offset および statement_end_offset 列が含まれており、現在実行中のバッチまたは持続オブジェクトの現在実行中のステートメントを参照します。 詳しくは「sys.dm_exec_requests (Transact-SQL)」をご覧ください。
また、sys.dm_exec_query_stats DMV には、バッチまたは持続オブジェクト内のステートメントの位置を参照する、各レコードのこれらの列が含まれています。 詳細については、「sys.dm_exec_query_stats (Transact-SQL)」を参照してください。
バッチの実際の Transact-SQL テキストは、SQL Manager キャッシュ (SQLMGR) と呼ばれる、プラン キャッシュとは別のメモリ領域に格納されます。 コンパイル済みプランの Transact-SQL テキストは、sql manager キャッシュから SQL ハンドルを使用して取得できます。これは、参照元の 1 つ以上のプランがプラン キャッシュに残っている間だけ一定に保たれる一時識別子です。 sql ハンドルは、バッチ テキスト全体から派生したハッシュ値であり、すべてのバッチで一意であることが保証されます。
Note
コンパイル済みプランと同様に、Transact-SQL テキストは、コメントを含め、バッチごとに格納されます。 sql ハンドルには、バッチ テキスト全体の MD5 ハッシュが含まれており、すべてのバッチで一意であることが保証されます。
以下のクエリでは、sql manager キャッシュのメモリ使用量に関する情報が提供されます。
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
sql ハンドルとプラン ハンドルの間には、1:N の関係があります。 このような状況は、コンパイル済みプランのキャッシュ キーが異なる場合に発生します。 これは、同じバッチの 2 回の実行間で SET オプションが変更されたことが原因で発生する可能性があります。
次のストアド プロシージャについて考えてみます。
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
以下のクエリを使用して、プラン キャッシュで検出できる内容を確認します。
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
結果セットは次のようになります。
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
次に、別のパラメーターを使用してストアド プロシージャを実行しますが、実行コンテキストに対するその他の変更はありません。
EXEC usp_SalesByCustomer 8
GO
プラン キャッシュで検出できる内容をもう一度確認します。 結果セットは次のようになります。
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
usecounts が 2 に増えていることに注目してください。これは、実行コンテキストのデータ構造が再利用されたため、同じキャッシュされたプランがそのまま再利用されたことを意味します。 次に、SET ANSI_DEFAULTS オプションを変更し、同じパラメーターを使用してストアド プロシージャを実行します。
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
プラン キャッシュで検出できる内容をもう一度確認します。 結果セットは次のようになります。
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
sys.dm_exec_cached_plans DMV の出力に、現在、2 つのエントリがあることに注目してください。
- 最初のレコードでは、
usecounts列に1という値が表示されています。これは、SET ANSI_DEFAULTS OFFで 1 回実行されたプランです。 - 2 番目のレコードでは、
usecounts列に2という値が表示されています。これは、SET ANSI_DEFAULTS ONで実行されたプランであり、2 回実行されたためです。 - 異なる
memory_object_addressで、プラン キャッシュ内の別の実行プラン エントリが参照されます。 しかし、sql_handle値は両方のエントリで同じになります。これは、同じバッチが参照されているためです。ANSI_DEFAULTSが OFF に設定された実行には新しいplan_handleがあり、同じ SET オプション セットの呼び出しで再利用できます。 SET オプションの変更により、実行コンテキストが再初期化されたため、新しいプラン ハンドルが必要になります。 しかし、再コンパイルはトリガーされません。query_plan_hashとquery_hashの値が同じであることからわかるように、両方のエントリで同じプランとクエリが参照されます。
これは事実上、同じバッチに対応するキャッシュに 2 つのプラン エントリがあることを意味し、同じクエリが繰り返し実行される場合は、プラン キャッシュに影響する SET オプションが確実に同じになるようにし、プランの再利用のために最適化し、プラン キャッシュのサイズを必要な最小値に維持することの重要性が明確に示されています。
ヒント
よくある落とし穴は、さまざまなクライアントで、SET オプションに対して異なる既定値が設定される可能性があるということです。 たとえば、SQL Server Management Studio によって確立された接続では自動的に QUOTED_IDENTIFIER が ON に設定されますが、SQLCMD では QUOTED_IDENTIFIER が OFF に設定されます。 これら 2 つのクライアントから同じクエリを実行すると、(上の例で説明したように) 複数のプランが生成されます。
プラン キャッシュから実行プランを削除する
実行プランは、格納しておくためのメモリがある間はプラン キャッシュに残ります。 メモリ負荷が存在する場合、SQL Server データベース エンジンはコストベースの手法を使用して、どの実行プランをプラン キャッシュから削除するかを判断します。 コストベースの判断をするために、SQL Server データベース エンジンは各実行プランの現在のコスト変数を以下のような要因に基づいて増減させます。
ユーザー プロセスは、キャッシュに実行プランを挿入するときに、現在のコストを元のクエリ コンパイル コストと同じ値に設定します。アドホック実行プランの場合、ユーザー プロセスは現在のコストをゼロに設定します。 これ以降、ユーザー プロセスは、実行プランを参照するたびに、現在のコストを元のコンパイル コストにリセットします。アドホック実行プランの場合、ユーザー プロセスは現在のコストを増加させます。 すべてのプランについて、現在のコストの最大値は元のコンパイル コストです。
メモリ負荷が存在する場合、SQL Server データベース エンジンは実行プランをプラン キャッシュから削除することによって対応します。 どのプランを削除するかを決めるために、SQL Server データベース エンジンは各実行プランの状態を繰り返し検証して、現在のコストがゼロであるプランを削除します。 現在のコストがゼロである実行プランは、メモリ負荷がある場合でも、自動的には削除されません。削除されるのは、SQL Server データベース エンジンがプランを検証し、現在のコストがゼロになっている場合だけです。 SQL Server データベース エンジンは、実行プランを検証するとき、クエリがそのプランを現在使用していない場合は、現在のコストを減少させ、ゼロに近づけます。
SQL Server データベース エンジンは、メモリ要件を満たすために必要な数の実行プランが削除されるまで、実行プランの検証を繰り返します。 メモリ負荷が存在する場合、実行プランのコストは数回にわたって増減することになります。 メモリ負荷が存在しなくなると、SQL Server データベース エンジンは使用されていない実行プランの現在のコストを減らさなくなり、コストがゼロの実行プランもプラン キャッシュに残されます。
SQL Server データベース エンジンはリソース モニターとユーザー ワーカー スレッドを使用して、メモリ負荷に応じてプラン キャッシュからメモリを解放します。 リソース モニターとユーザー ワーカー スレッドは、使用されていない各実行プランの現在のコストを減らすために、プランを同時に実行して検証することができます。 リソース モニターは、グローバルなメモリ負荷が存在する場合に、実行プランをプラン キャッシュから削除します。 リソース モニターはメモリを解放することによって、システム メモリ、プロセス メモリ、リソース プール メモリ、およびすべてのキャッシュの最大サイズのポリシーを強制的に適用します。
すべてのキャッシュの最大サイズは、バッファー プール サイズの関数で、最大サーバー メモリを超えることはできません。 最大サーバー メモリの構成の詳細については、「 max server memory 」の sp_configure設定を参照してください。
ユーザー ワーカー スレッドは、単一キャッシュ メモリ負荷が存在する場合に、実行プランをプラン キャッシュから削除します。 単一キャッシュの最大サイズおよび最大エントリのポリシーを強制的に適用します。
次の例では、どの実行プランがプラン キャッシュから削除されるかを示しています。
- 実行プランは頻繁に参照されるため、そのコストがゼロになることはありません。 メモリ負荷が存在しないか、現在のコストがゼロでない場合、実行プランはプラン キャッシュに残り、削除されません。
- アドホック実行プランは挿入され、メモリ負荷が生じるまでは再度参照されることはありません。 アドホック プランの現在のコストはゼロに初期化されます。そのため、SQL Server データベース エンジンは実行プランを検証するときに現在のコストがゼロであると認識し、プラン キャッシュからプランを削除します。 メモリ負荷が存在しない場合、アドホック実行プランは、現在のコストがゼロでもプラン キャッシュに残ります。
キャッシュから 1 つまたはすべてのプランを手動で削除するには、 DBCC FREEPROCCACHEを使用します。 DBCC FREESYSTEMCACHE はプラン キャッシュを含むすべてのキャッシュの消去に使用できます。 SQL Server 2016 (13.x) 以降は、ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE でスコープ内のデータベースのプロシージャ (プラン) キャッシュをクリアします。
sp_configure および reconfigure を使用して一部の構成設定を変更すると、プラン キャッシュからプランが削除されることがあります。 これらの構成設定の一覧については、「DBCC FREEPROCCACHE」の記事の「注釈」を参照してください。 このような構成の変更があると、次の情報メッセージがエラー ログに記録されます。
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
実行プランを再コンパイルする
データベースに変更を加えた場合、データベースの新しい状態によっては、実行プランの効率が低下したり、実行プランが無効になったりします。 実行プランが無効になるような変更は SQL Server によって検出され、その実行プランは無効としてマークされます。 このため、クエリを実行する次回の接続用に新しい実行プランを再コンパイルする必要があります。 実行プランが無効になるのは、次の場合です。
- クエリ (
ALTER TABLEおよびALTER VIEW) によって参照されるテーブルまたはビューに変更を加えた場合 - 単一のプロシージャに変更を加え、キャッシュからこのプロシージャの全プランを削除した場合 (
ALTER PROCEDURE) - 実行プランで使用されるインデックスに変更を加えた場合
UPDATE STATISTICSなどのステートメントを使用して明示的に生成した実行プラン、または自動的に生成された実行プランによって使用される統計を更新した場合- 実行プランで使用されるインデックスを削除した場合
sp_recompileを明示的に呼び出した場合- クエリによって参照されるテーブルを変更する他のユーザーが、
INSERTステートメントまたはDELETEステートメントを使用して大量の変更をキーに加えた場合 - トリガーを含むテーブルで、inserted テーブルまたは deleted テーブルの行数が大幅に増加する場合
WITH RECOMPILEオプションを使用してストアド プロシージャを実行する場合
主として再コンパイルが必要になるのは、ステートメントの正確性を維持したり、より処理速度が速いクエリ実行プランを取得したりする場合です。
2005 より前の SQL Server バージョンでは、バッチ内のステートメントが原因で再コンパイルが実行されるときに、そのバッチがストアド プロシージャ、トリガー、アドホック バッチ、または準備されたステートメントのいずれを使用して送信されたかどうかに関係なく、常にバッチ全体が再コンパイルされました。 SQL Server 2005 (9.x) 以降では、再コンパイルをトリガーしたバッチ内のステートメントのみが再コンパイルされます。 また、SQL Server 2005 (9.x) 以降の再コンパイルには、拡張機能セットによって種類が追加されています。
ステートメントレベルの再コンパイルにより、パフォーマンスが向上します。これは、多くの場合、再コンパイルとそれに関連付けられた CPU 時間やロックへの悪影響を引き起こすステートメントの数が少ないからです。 したがって、再コンパイルする必要がないバッチの他のステートメントでは、これらの悪影響を回避できます。
sql_statement_recompile 拡張イベント (xEvent) によりステートメントレベルの再コンパイルが報告されます。 この xEvent は、ステートメントレベルの再コンパイルが何らかのバッチにより要求されるときに発生します。 ストアド プロシージャ、トリガー、アドホック バッチ、クエリなどが相当します。 バッチは、sp_executesql、動的 SQL、Prepare メソッド、Execute メソッドなど、いくつかのインターフェイスを使用して送信できます。
sql_statement_recompile xEvent の recompile_cause 列には、再コンパイルの理由を示す整数コードが含まれます。 考えられる理由をまとめたのが次の表です。
スキーマの変更
統計の変更
コンパイルの遅延
SET オプションの変更
一時テーブルの変更
リモート行セットの変更
FOR BROWSE アクセス許可の変更
クエリ通知環境の変更
パーティション ビューの変更
カーソル オプションの変更
OPTION (RECOMPILE) の要求
パラメーター化されたプランのフラッシュ
プランに影響を与えるデータベース バージョンの変更
クエリ ストア プラン強制ポリシーの変更
クエリ ストア プラン強制の失敗
クエリ ストアにプランがない
Note
xEvents が利用できない SQL Server バージョンの場合、ステートメントレベルの再コンパイルの報告という同じ目的に SQL Server プロファイラー SP:Recompile トレース イベントを利用できます。
トレース イベント SQL:StmtRecompile では、ステートメントレベルの再コンパイルも報告されます。また、このトレース イベントを使用して、再コンパイルを追跡およびデバッグすることもできます。
SP:Recompile では、ストアド プロシージャとトリガーのみに対して値が生成されますが、SQL:StmtRecompile では、ストアド プロシージャ、トリガー、アドホック バッチ に対して値が生成され、sp_executesql、準備されたクエリ、および動的 SQL を使用して実行されたバッチに対しても値が生成されます。
SP:Recompile と SQL:StmtRecompile の EventSubClass 列には、再コンパイルの理由を示す整数コードが含まれます。 コードの説明はここにあります。
Note
AUTO_UPDATE_STATISTICS データベース オプションが ON に設定されていると、対象にしているテーブルまたはインデックス付きビューの統計が更新された場合、または前回の実行から基数が大きく変更された場合、クエリが再コンパイルされます。
この動作は、標準のユーザー定義テーブル、一時テーブル、および DML トリガーによって作成された inserted テーブルと deleted テーブルに当てはまります。 過度の再コンパイルによってクエリのパフォーマンスが低下する場合は、この設定を OFFに変更することを検討してください。 AUTO_UPDATE_STATISTICS データベース オプションを OFF に設定すると、統計や基数の変更に基づく再コンパイルは行われません。ただし、DML INSTEAD OF トリガーで作成した inserted テーブルおよび deleted テーブルは例外です。 これらのテーブルは tempdb で作成されるため、それらにアクセスするクエリの再コンパイルは tempdb の AUTO_UPDATE_STATISTICS の設定によって異なります。
2005 より前の SQL Server では、この設定を OFF にした場合も、DML トリガーの inserted テーブルと deleted テーブルに対するカーディナリティの変更に基づいてクエリによる再コンパイルが引き続き行われます。
パラメーターと実行プランの再利用
ADO、OLE DB、ODBC の各アプリケーションのパラメーター マーカーなどのパラメーターを使用すると、実行プランの再利用回数を増やすことができます。
警告
エンド ユーザーが入力した値をパラメーターまたはパラメーター マーカーを使用して保持する方法は、文字列に値を連結し、その後この文字列をデータ アクセス API メソッド、 EXECUTE ステートメント、または sp_executesql ストアド プロシージャのいずれかを使用して実行する方法よりも安全です。
次の 2 つの SELECT ステートメントでは、 WHERE 句で比較する値のみが異なっています。
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
これらのクエリの実行プランでは、 ProductSubcategoryID 列に対して比較用に格納された値のみが異なります。 最終的な目標は、ステートメントが生成するプランは基本的に同じであると SQL Server に常に認識させてプランを再利用することにありますが、Transact-SQL ステートメントが複雑になると SQL Server がこのことを検出できない場合があります。
パラメーターを使用して Transact-SQL ステートメントと定数を切り離すと、同一のプランをリレーショナル エンジンが認識できるようになります。 パラメーターは、次の方法で使用できます。
Transact-SQL では、
sp_executesqlを使用します。DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmこの方法は、SQL ステートメントを動的に生成する Transact-SQL スクリプト、ストアド プロシージャ、またはトリガーで使用することをお勧めします。
ADO、OLE DB、および ODBC ではパラメーター マーカーを使用します。 パラメーター マーカーは疑問符 (?) です。SQL ステートメント内の定数の代わりに置かれ、プログラム変数にバインドされます。 たとえば、ODBC アプリケーションでは次のような操作を実行できます。
SQLBindParameterを使用して、整数変数を SQL ステートメントの最初のパラメーター マーカーにバインドします。変数に整数値を代入します。
次のように、パラメーター マーカー (?) を指定してステートメントを実行します。
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
アプリケーション内でパラメーター マーカーが使用されると、SQL Server に搭載されている SQL Server Native Client OLE DB プロバイダーと SQL Server Native Client ODBC ドライバーが
sp_executesqlを使用して、SQL Server にステートメントを送信します。ストアド プロシージャをデザインする場合は、意図的にパラメーターを使用できます。
アプリケーションのデザインにパラメーターを明示的に組み込まない場合は、簡易パラメーター化の既定の動作を使用して、SQL Server クエリ オプティマイザーで自動的に特定のクエリをパラメーター化することもできます。 また、ALTER DATABASE ステートメントの PARAMETERIZATION オプションを FORCED に設定することで、クエリ オプティマイザーにデータベース内のすべてのクエリをパラメーター化するように強制できます。
強制パラメーター化が有効になっている場合でも、簡易パラメーター化が行われる可能性はあります。 たとえば、強制パラメーター化のルールに従えば、次のクエリはパラメーター化できません。
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
ただし、簡易パラメーター化のルールに従ってパラメーター化することはできます。 強制パラメーター化の試行に失敗した場合でも、簡易パラメーター化が続けて試行されます。
簡易パラメーター化
SQL Server では、Transact-SQL ステートメントでパラメーターまたはパラメーター マーカーを使用することで、新しい Transact-SQL ステートメントと既存のコンパイル済みの実行プランとを照合するリレーショナル エンジンの機能が強化されています。
警告
パラメーターまたはパラメーター マーカーを使用してエンド ユーザーの入力値を保持する方法は、文字列に値を連結し、その後この文字列をデータ アクセス API メソッド、 EXECUTE ステートメント、または sp_executesql ストアド プロシージャのいずれかを使用して実行する方法よりも安全です。
パラメーターを指定せずに Transact-SQL ステートメントを実行した場合、SQL Server ではステートメントを内部でパラメーター化することにより、既存の実行プランとの照合機能が高められます。 この処理を簡易パラメーター化と呼びます。 2005 より前の SQL Server バージョンでは、この処理を自動パラメーター化と呼んでいました。
次のステートメントについて考えてみます。
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
ステートメントの最後の値 1 は、パラメーターとして指定できます。 リレーショナル エンジンにより、値 1 の位置にパラメーターが指定されたときと同様にこのバッチの実行プランが構築されます。 この簡易パラメーター化により、SQL Server で次の 2 つのステートメントから基本的に同じ実行プランが生成されると認識され、2 番目のステートメントにも最初のプランが再利用されます。
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
複雑な Transact-SQL ステートメントを処理する場合、リレーショナル エンジンでは、どの式をパラメーター化できるのかを簡単に決定できない可能性があります。 複雑な Transact-SQL ステートメントと既存の使用されていない実行プランを照合するリレーショナル エンジンの機能を向上させるには、sp_executesql またはパラメーター マーカーを使用してパラメーターを明示的に指定します。
Note
+、-、*、/、または % の算術演算子を使用して int、smallint、tinyint、または bigint の定数値を float、real、decimal、または numeric のデータ型に暗黙的にまたは明示的に変換した場合、その式の結果の型および有効桁数を計算するための特定の規則が SQL Server により適用されます。 ただし、これらの規則はクエリがパラメーター化されるかどうかによって異なります。 したがって、クエリ内の類似の式から異なる結果が生成される場合があります。
簡易パラメーター化の既定の動作では、SQL Server により、比較的小さなクエリがパラメーター化されます。 ただし、いくつかの制約はありますが、 PARAMETERIZATION コマンドの ALTER DATABASE オプションを FORCEDに設定することにより、データベース内のすべてのクエリをパラメーター化するように指定できます。 これにより、クエリをコンパイルする頻度が低くなり、大量のクエリが同時に実行されるデータベースのパフォーマンスが向上します。
また、単一クエリと、単一クエリと構文的に等しくパラメーター値だけが異なるクエリをパラメーター化することを指定できます。
ヒント
Entity Framework (EF) などのオブジェクト リレーショナル マッピング (ORM) ソリューションを使う場合、手動の LINQ クエリ ツリーや特定の未加工の SQL クエリのようなアプリケーション クエリがパラメーター化されない可能性があります。これは、プランの再利用とクエリ ストアでクエリを追跡する機能に影響します。 詳細については、EF クエリのキャッシュとパラメーター化および EF の未加工の SQL クエリに関する記事を参照してください。
強制パラメーター化
データベースのすべての SELECT、INSERT、UPDATE、および DELETE ステートメントをパラメーター化するように指定することで、いくつかの制約はありますが SQL Server の簡易パラメーター化の既定動作をオーバーライドできます。 強制パラメータ化を有効にするには、 PARAMETERIZATION ステートメントの FORCED オプションを ALTER DATABASE に設定します。 強制パラメーター化を行うと、クエリをコンパイルおよび再コンパイルする頻度が低くなるので、データベースによってはパフォーマンスが向上する可能性があります。 一般的に POS (point-of-sale) などのアプリケーションから大量のクエリが同時に実行されるデータベースは、強制パラメーター化によりパフォーマンスが向上します。
PARAMETERIZATION オプションを FORCEDに設定すると、 SELECT、 INSERT、 UPDATE、 DELETE の各ステートメントに使用されているリテラル値は、その形式を問わずクエリのコンパイル時にパラメーターに変換されます。 ただし、次に示すクエリ構造に現れるリテラルは例外です。
INSERT...EXECUTEステートメント。- ストアド プロシージャ、トリガー、またはユーザー定義関数の本体内のステートメント。 これらのルーチンのクエリ プランは既に SQL Server により再利用されています。
- クライアント側のアプリケーションで既にパラメーター化されている、準備されたステートメント。
- XQuery メソッド呼び出しを含んでいるステートメントを、
WHERE句など通常は引数がパラメーター化されるコンテキストで使用した場合。 引数がパラメーター化されないコンテキストでこのメソッドが現れた場合は、ステートメントの残りの部分がパラメーター化されます。 - TRANSACT-SQL カーソル内のステートメント (API カーソル内の
SELECTステートメントはパラメーター化されます)。 - 非推奨のクエリ構造。
ANSI_PADDINGまたはANSI_NULLSがOFFに設定されている状態で実行されているステートメント。- パラメーター化が可能なリテラルが 2,097 を超えるステートメント。
WHERE T.col2 >= @bbなど、変数を参照するステートメント。RECOMPILEクエリ ヒントを含んだステートメント。COMPUTE句を含むステートメント。WHERE CURRENT OF句を含むステートメント。
また、次のクエリ句はパラメーター化されません。 以下の場合については、パラメーター化されないのはこれらの句だけです。 同じクエリ内のその他の句では強制パラメーター化が可能な場合もあります。
SELECTステートメントの <select_list>。 これには、サブクエリのSELECTリストやINSERTステートメント内のSELECTも含まれます。SELECTステートメント内のサブクエリのIFステートメント。- クエリの
TOP句、TABLESAMPLE句、HAVING句、GROUP BY句、ORDER BY句、OUTPUT...INTO句、FOR XML句。 OPENROWSET、OPENQUERY、OPENDATASOURCE、OPENXML、または任意のFULLTEXT演算子に渡す引数。直接渡すか、サブ式として渡すかは問いません。LIKE句の pattern 引数と escape_character 引数。CONVERT句の style 引数。IDENTITY句内の整数の定数。- ODBC 拡張機能の構文で指定した定数。
- 演算子
+、-、*、/、%の引数であり、定数の畳み込みが可能な式。 SQL Server は、強制パラメーター化を行うことができるかどうかを判断する際に、次のいずれかの条件が満たされていれば式で定数のたたみ込みが可能であると見なします。- 式に列、変数、およびサブクエリが使用されていない。
- 式に
CASE句が含まれている。
- クエリ ヒントの句に渡す引数。
FASTクエリ ヒントの number_of_rows 引数、MAXDOPクエリ ヒントの number_of_processors 引数、MAXRECURSIONクエリ ヒントの number 引数がこれに該当します。
パラメーター化は個々の Transact-SQL ステートメント レベルで行われます。 つまり、バッチ内では個々のステートメントがパラメーター化されます。 コンパイルの後、パラメーター化クエリは、最初に送信されたバッチのコンテキストで実行されます。 クエリの実行プランがキャッシュに残っている場合、sys.syscacheobjects 動的管理ビューの sql 列を参照することでクエリがパラメーター化されているかどうかを判断できます。 クエリがパラメーター化されている場合、この列には送信されたバッチのテキストの前に "@1 tinyint" のように、パラメーターの名前とデータ型が付加されます。
Note
パラメーター名の規則はありません。 特定の命名順序に依存することは避けてください。 また、パラメーター名、パラメーター化されるリテラル、およびパラメーター化されたテキストに含まれるスペースは、SQL Server のバージョンおよび Service Pack の適用状況によって異なります。
パラメーターのデータ型
SQL Server がリテラルをパラメーター化する際に、パラメーターは次のデータ型に変換されます。
- int データ型の範囲に収まるサイズの整数リテラルは、int 型にパラメーター化されます。それよりも大きな整数リテラルのうち、比較演算子 (
<、<=、=、!=、>、>=、!<、!>、<>、ALL、ANY、SOME、BETWEEN、INなど) を伴う述語で使用されているものは numeric(38,0) 型にパラメーター化されます。 比較演算子を伴う述語で使用されていないものは、リテラルのサイズに見合う十分な有効桁数があり、小数点以下桁数が 0 の numeric 型にパラメーター化されます。 - 比較演算子を伴う述語で使用されている固定小数点型のリテラルは、有効桁数が 38 桁で、リテラルのサイズに見合う十分な小数点以下桁数がある numeric 型にパラメーター化されます。 比較演算子を伴う述語で使用されていない固定小数点型のリテラルは、リテラルのサイズに見合う十分な有効桁数および小数点以下桁数がある numeric 型にパラメーター化されます。
- 浮動小数点型のリテラルは float(53) 型にパラメーター化されます。
- Unicode 以外の文字列リテラルは、8,000 文字以内の場合は varchar(8000) 型に、8,000 文字を超える場合は varchar(max) 型にパラメーター化されます。
- Unicode 文字列リテラルは、4,000 文字以内の場合は nvarchar(4000) 型に、4,000 文字を超える場合は nvarchar(max) 型にパラメーター化されます。
- バイナリ リテラルは、8,000 バイト以内の場合は varbinary(8000) 型にパラメーター化されます。 8,000 バイトを超える場合は、varbinary(max) 型に変換されます。
- money 型のリテラルは、money 型にパラメーター化されます。
強制パラメーター化使用のガイドライン
PARAMETERIZATION オプションを FORCED に設定するときは、次のことを考慮してください。
- 強制パラメーター化を行うと、クエリをコンパイルするときにクエリ内のリテラル定数がパラメーターに変更されます。 そのため、クエリ オプティマイザーで最適なクエリ プランが選択されない可能性があります。 特に、インデックス付きビューや、計算列のインデックスに合わせてクエリが調整されることはあまりありません。 パーティション テーブルおよび分散パーティション ビューに発行するクエリについても、最適なプランが選択されない場合があります。 インデックス付きビューおよび計算列のインデックスに大きく依存する環境では、強制パラメーター化を使用しないでください。 一般的に、
PARAMETERIZATION FORCEDオプションは、熟練したデータベース管理者が、パフォーマンスに悪影響が出ないことを確認した上でのみ使用してください。 - 複数のデータベースを参照する分散クエリでは、そのクエリを実行しているデータベースのコンテキストで
PARAMETERIZATIONオプションがFORCEDに設定されていれば強制パラメーター化を行うことができます。 PARAMETERIZATIONオプションをFORCEDに設定すると、コンパイル中、再コンパイル中、および実行中のクエリ プランを除くすべてのクエリ プランがデータベースのプラン キャッシュから消去されます。 設定の変更時にコンパイルまたは実行されているクエリのプランは、次回そのクエリを実行するときにパラメーター化されます。PARAMETERIZATIONオプションはオンライン操作で設定します。このとき、データベースレベルの排他ロックは必要ありません。PARAMETERIZATIONオプションの現在の設定は、データベースを再アタッチまたは復元するときも維持されます。
単一クエリ、および構文は同じでパラメーター値のみが異なる他の任意のクエリを簡易パラメーター化するように指定することで、強制パラメーター化の動作をオーバーライドできます。 逆に、データベースで強制パラメーター化の動作が無効になっている場合に、構文が同じクエリに対してのみ強制パラメーター化の動作を指定することもできます。 この方法については、「プラン ガイド 」を参照してください。
Note
PARAMETERIZATION オプションを FORCED に設定すると、PARAMETERIZATION オプションを SIMPLE に設定する場合と比べて、報告されるエラー メッセージに違いが現れる場合があります。複数のエラー メッセージが強制パラメーター化で報告される場合があり、簡易パラメーター化よりも多くのエラー メッセージが報告されることがあります。また、エラーが発生した行番号が間違って報告されることがあります。
SQL ステートメントを準備する
SQL Server のリレーショナル エンジンでは、Transact-SQL ステートメントを実行前に準備する方式が完全にサポートされるようになりました。 アプリケーションでは、Transact-SQL ステートメントを複数回実行する必要がある場合、データベース API を使用して次の処理を実行できます。
- ステートメントを 1 回準備します。 これにより、Transact-SQL ステートメントがコンパイルされて実行プランが作成されます。
- ステートメントの実行が必要になるたびに、コンパイル済みの実行プランを実行します。 これにより、2 回目以降は実行ごとに Transact-SQL ステートメントを再コンパイルする必要がなくなります。 ステートメントの準備と実行は、API の関数およびメソッドによって制御されます。 Transact-SQL 言語の一部ではありません。 Transact-SQL ステートメントを実行するための準備/実行のモデルは、SQL Server Native Client OLE DB プロバイダーと SQL Server Native Client ODBC ドライバーによってサポートされています。 準備要求時に、プロバイダーまたはドライバーから SQL Server に対し、準備要求と共にステートメントが送信されます。 SQL Server で実行プランがコンパイルされ、このプランのハンドルがプロバイダーまたはドライバーに返されます。 実行要求時に、プロバイダーまたはドライバーのいずれかによって、ハンドルに関連付けられたプランの実行要求がサーバーに送信されます。
SQL Server では、準備されたステートメントを使用して一時オブジェクトを作成することはできません。 また、準備されたステートメントでは、一時テーブルなどの一時オブジェクトを作成するシステム ストアド プロシージャを参照できません。 このようなプロシージャは、直接実行する必要があります。
準備/実行のモデルを過度に使用すると、パフォーマンスが低下することがあります。 ステートメントを 1 回だけ実行する場合は、直接実行のためのネットワークからサーバーへのアクセスは 1 回だけで済みます。 1 回だけ実行される Transact-SQL ステートメントを準備してから実行する場合は、もう 1 回余分にネットワークからサーバーにアクセスする必要があります。つまり、1 回はステートメントを準備するため、もう 1 回はステートメントを実行するためです。
パラメーター マーカーを使用する場合、ステートメントを準備するとより効果的です。 たとえば、あるアプリケーションに対して、 AdventureWorks サンプル データベースから製品情報を取得するように頻繁に要求する場合を考えます。 アプリケーションでこの処理を実行できる方法は 2 つあります。
最初の方法を使用すると、アプリケーションでは、次のように要求された製品ごとに個別のクエリを実行できます。
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
2 番目の方法を使用すると、アプリケーションによって次の処理が行われます。
次のように、パラメーター マーカー (?) を含むステートメントを準備します。
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;プログラム変数をパラメーター マーカーにバインドします。
製品情報が必要になるたびに、バインドした変数にキー値を入力し、ステートメントを実行します。
ステートメントを 4 回以上実行する場合は、2 番目の方法がより効率的です。
SQL Server では、直接実行と比べて準備/実行モデルにパフォーマンス上のメリットはほとんどありません。これは、SQL Server では実行プランが再利用されるためです。 SQL Server には、現在の Transact-SQL ステートメントを、同じ Transact-SQL ステートメントの前回の実行用に生成された実行プランと照合する効率的なアルゴリズムが備わっています。 アプリケーションにより、パラメーター マーカーを使用して Transact-SQL ステートメントが複数回実行される場合、SQL Server では 2 回目以降の実行に最初の実行で使用した実行プランが再利用されます。ただし、プラン キャッシュのプランが古くなった場合は、実行プランは再利用されません。 準備/実行のモデルには次の利点もあります。
- 識別のためのハンドルによって実行プランを検索する方が、Transact-SQL ステートメントを既存の実行プランと照合するために使用するアルゴリズムよりも効率的です。
- 実行プランの作成および再利用のタイミングをアプリケーションで制御できます。
- 準備/実行のモデルは、以前のバージョンの SQL Server など、他のデータベースに移植できます。
パラメーターの感度
パラメーターの感度は "パラメーター スニッフィング" とも呼ばれ、コンパイルまたは再コンパイルの間に SQL Server が現在のパラメーター値を "スニッフィング (傍受)" し、クエリ オプティマイザーに渡すプロセスです。渡されたパラメーター値は、より効率的な可能性のあるクエリ実行プランを生成するために利用できます。
パラメーター値は、次のようなバッチのコンパイルまたは再コンパイル中にスニッフィングされます。
- ストアド プロシージャ
sp_executesqlを介して送信されたクエリ- 準備されたクエリ
不適切なパラメーター スニッフィングの問題のトラブルシューティングの詳細については、次を参照してください。
- パラメーターに依存する問題を調査して解決する
- パラメーターと実行プランの再利用
- パラメーターに依存するプランの最適化
- Azure SQL Database で、パラメーター依存クエリ実行プランの問題があるクエリをトラブルシューティングする
- Azure SQL Managed Instance で、パラメーター依存クエリ実行プランの問題があるクエリをトラブルシューティングする
Note
RECOMPILE ヒントを利用するクエリの場合、パラメーター値とローカル変数の現在の値の両方がスニッフィングされます。 (パラメーターとローカル変数の) スニッフィングされた値は、バッチの中で、RECOMPILE ヒントのあるステートメントの手前に存在する値です。 特に、パラメーターの場合、バッチ呼び出しで共に与えられた値はスニッフィングされません。
並列クエリ処理
SQL Server では、複数の CPU (マイクロプロセッサ) を搭載したコンピューターのクエリ実行およびインデックス操作を最適化するための並列クエリを使用できます。 SQL Server はオペレーティング システムのワーカー スレッドを複数使用してクエリやインデックス操作を並列的に実行できるため、操作を短時間で効率的に完了できます。
SQL Server は、クエリを最適化する過程で、並列実行による効果が期待できるクエリやインデックス操作を検索します。 次に、SQL Server は、そのようなクエリの実行プランに交換操作を挿入して並列実行用クエリを作成します。 交換操作とは、プロセス管理、データの再配布、およびフロー制御を行うクエリ実行プラン内の操作です。 交換操作は Distribute Streams論理操作、 Repartition Streams論理操作、および Gather Streams 論理操作から構成されており、これらは並列クエリのプラン表示出力に含まれる可能性があります。
重要
一部の構造は、実行プランの全体または一部分で、並列処理を利用する SQL Server の機能を妨げます。
並列処理を妨げる構造は次のとおりです。
スカラー UDF
スカラー ユーザー定義関数について詳しくは、「ユーザー定義関数の作成」をご覧ください。 SQL Server 2019 (15.x) 以降の SQL Server データベース エンジンには、これらの関数をインライン化する機能があり、クエリ処理中の並列処理の使用をロック解除します。 スカラー UDF のインライン化について詳しくは、「SQL データベースでのインテリジェントなクエリ処理」をご覧ください。リモート クエリ
リモート クエリについて詳しくは、「プラン表示の論理操作と物理操作のリファレンス」をご覧ください。動的カーソル
カーソルについて詳しくは、「DECLARE CURSOR」をご覧ください。再帰クエリ
再帰について詳しくは、「再帰共通テーブル式の定義および使用に関するガイドライン」および「Recursion in T-SQL」(T-SQL での再帰) をご覧ください。複数ステートメント テーブル値関数 (MSTVF)
MSTVF の詳細については、「ユーザー定義関数の作成 (データベース エンジン)」を参照してください。TOP キーワード
詳しくは、「TOP (Transact-SQL)」をご覧ください。
クエリ実行プランでは、並列処理が使用されなかった理由を説明する NonParallelPlanReason 属性が QueryPlan 要素に含まれる場合があります。 この属性の値は次のとおりです。
| NonParallelPlanReason Value | 説明 |
|---|---|
| MaxDOPSetToOne | 並列処理の最大限度を 1 に設定します。 |
| EstimatedDOPIsOne | 並列処理の推定次数は 1 です。 |
| NoParallelWithRemoteQuery | 並列処理はリモート クエリではサポートされていません。 |
| NoParallelDynamicCursor | 並列プランは動的カーソルではサポートされていません。 |
| NoParallelFastForwardCursor | 並列プランは高速順方向カーソルではサポートされていません。 |
| NoParallelCursorFetchByBookmark | ブックマークによってフェッチされるカーソルに対しては、並列プランはサポートされていません。 |
| NoParallelCreateIndexInNonEnterpriseEdition | 並列インデックスの作成は Enterprise 以外のエディションではサポートされていません。 |
| NoParallelPlansInDesktopOrExpressEdition | 並列プランは Desktop および Express エディションではサポートされていません。 |
| NonParallelizableIntrinsicFunction | クエリは並列化できない組み込み関数を参照しています。 |
| CLRUserDefinedFunctionRequiresDataAccess | データ アクセスを必要とする CLR UDF の場合、並列処理はサポートされていません。 |
| TSQLUserDefinedFunctionsNotParallelizable | クエリは並列化できない T-SQL ユーザー定義関数を参照しています。 |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | テーブル変数トランザクションは入れ子になった並列トランザクションをサポートしていません。 |
| DMLQueryReturnsOutputToClient | DML クエリからクライアントに出力が返されます。また、並列化できません。 |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | 1 つのオンライン インデックス ビルドにサポートされていない直列プランと並列プランが混在しています。 |
| CouldNotGenerateValidParallelPlan | 並列プランを検証できませんでした。シリアルにフェールバックします。 |
| NoParallelForMemoryOptimizedTables | 参照されるインメモリ OLTP テーブルでは並列処理はサポートされていません。 |
| NoParallelForDmlOnMemoryOptimizedTable | インメモリ OLTP テーブル上の DML では並列処理はサポートされていません。 |
| NoParallelForNativelyCompiledModule | 参照されているネイティブ コンパイル モジュールでは並列処理はサポートされていません。 |
| NoRangesResumableCreate | 再開可能な作成操作の範囲の生成に失敗しました。 |
交換操作を挿入すると、並列クエリの実行プランになります。 並列クエリの実行プランでは複数のワーカー スレッドを使用できます。 並列でない (直列) クエリで使用する直列の実行プランの場合、実行時に使用するワーカー スレッドは 1 つのみです。 並列クエリで実際に使用するワーカー スレッドの数は、クエリ プランを実行するための初期化の時点で、プランの複雑さと並列処理の次数に応じて決まります。
並列処理の次数 (DOP) は、使用している CPU の最大数によって決まります (これは使用しているワーカー スレッドの数という意味ではありません)。 DOP の制限は、タスクごとに設定されます。 この設定は、要求ごとまたはクエリ制限ごとではありません。 つまり、並列クエリ実行中に、1 つの要求で、スケジューラに割り当てられてた複数のタスクを生成することができます。 さまざまなタスクが同時に実行される場合、MAXDOP によって指定された数よりも多くのプロセッサが、クエリ実行の特定の時点で同時に使用される可能性があります。 詳細については、「スレッドおよびタスクのアーキテクチャ ガイド」を参照してください。
次のいずれかの条件が満たされている場合、SQL Server のクエリ オプティマイザーは、クエリに対して並列実行プランを使用しません。
- 直列実行プランが単純な場合。または、並列処理設定のコストしきい値を超えない場合。
- 直列実行プランの推定サブツリー コストの合計は、オプティマイザーによって探索されたどの並列実行プランよりも低くなります。
- クエリに、並列では実行できないスカラー演算子または関係演算子が含まれる場合。 演算子によっては、クエリ プランのセクションまたはプラン全体が直列モードで実行される場合があります。
Note
並列プランの推定サブツリー コストの合計は、並列処理設定のコストしきい値より低い場合があります。 これは、直列プランの推定サブツリーコストの合計の方が大きく、推定サブツリーの合計コストが低いクエリ プランが選択されたことを示します。
並列処理の次数 (DOP)
SQL Server は、並列クエリの実行またはインデックス DDL (データ定義言語) 操作のインスタンスごとに、並列処理の最適な次数を自動的に検出します。 この処理は次の基準に基づいて実行されます。
SQL Server が、SMP (対称型マルチプロセッシング) コンピューターなど、複数のマイクロプロセッサまたは CPU を搭載したコンピューターで実行されているかどうか。 並列クエリを使用できるのは、複数の CPU を搭載したコンピューターだけです。
十分な数のワーカー スレッドを使用できるかどうか。 各クエリまたはインデックス操作では、一定数のワーカー スレッドを実行する必要があります。 並列プランの実行には直列プランの場合よりも多くのワーカー スレッドが必要になり、必要なワーカー スレッド数は並列処理の次数が高くなるほど増加します。 並列処理の特定の次数に応じた並列プランのワーカー スレッド要件を満たすことができない場合、SQL Server データベース エンジンが並列処理の次数を自動的に下げるか、指定されたワークロード コンテキストでの並列プランを完全に放棄します。 その後、直列プラン (1 つのワーカー スレッド) を実行します。
実行するクエリまたはインデックス操作の種類。 インデックスの作成や再構築またはクラスター化インデックスの削除を行うインデックス操作、および CPU サイクルを大量に使用するクエリは並列プランの候補として最適です。 たとえば、大きなテーブルの結合、大量の集計、および大きな結果セットの並べ替えは候補として適しています。 トランザクション処理アプリケーションに多い単純なクエリの場合、クエリを並列実行するにはさらに調整が必要なので、パフォーマンスの向上は困難です。 並列処理の利点を得られるクエリとそうでないクエリを区別するために、SQL Server データベース エンジンは cost threshold for parallelism 値を使用して、クエリまたはインデックス操作を実行するための推定コストを比較します。 適切なテストで実行中のワークロードには異なる値がより適していることが判明した場合、ユーザーは sp_configure を使用して既定値の 5 を変更することができます。
処理する十分な数の行があるかどうか。 クエリ オプティマイザーによって行数が少なすぎると判断されると、行を分散するための交換操作は導入されません。 したがって、操作は直列に実行されます。 直列プランで操作を実行すると、並列操作を実行したときに得られる効果より、起動、分散、および調整のコストの方が上回る事態を回避することができます。
現在の分布統計が使用できるかどうか。 並列処理の最高次数が不可能な場合、並列プランが放棄される前に、それより低い次数が検討されます。 たとえば、ビューにクラスター化インデックスを作成する場合、クラスター化インデックスはまだ存在しないので、分布統計を評価できません。 この場合、SQL Server データベース エンジンでは、インデックス操作用に並列処理の最高次数を提供できません。 ただし、並べ替えやスキャンなどの一部の操作では、それまでどおり並列実行の利点を得ることができます。
Note
並列インデックス操作は、SQL Server Enterprise Edition、Developer Edition、および Evaluation Edition でのみ使用できます。
既に説明したような現在のシステムのワークロードと構成情報で並列実行が可能かどうかは、実行時に SQL Server データベース エンジンによって判断されます。 並列実行の条件を満たしている場合、SQL Server データベース エンジンにより、最適なワーカー スレッド数が判断され、これらのワーカー スレッド全体に並列プランの実行が分散されます。 複数のワーカー スレッドでクエリまたはインデックス操作が並列実行で開始された後は、操作で使用されるワーカー スレッド数は操作の完了時まで変化しません。 SQL Server データベース エンジンは、プラン キャッシュから実行プランを取得するたびに、最適なワーカー スレッド数を再調査して決定します。 たとえば、1 回のクエリの実行では直列プランを使用し、同じクエリを再度実行するときは 3 つのワーカー スレッドを使用する並列プランを使用し、3 回目に実行するときは 4 つのワーカー スレッドを使用する並列プランを使用する場合があります。
並列クエリ実行プランの更新および削除演算子は直列に実行されますが、UPDATE または DELETE ステートメントの WHERE 句は並列に実行される場合があります。 実際のデータ変更は、データベースに直列に適用されます。
SQL Server 2012 (11.x) までは、挿入演算子も直列に実行されます。 ただし、INSERT ステートメントの SELECT 部分は並列に実行される場合があります。 実際のデータ変更は、データベースに直列に適用されます。
SQL Server 2014 (12.x) およびデータベース互換レベル 110 以降、SELECT ... INTO ステートメントは並列実行できるようになりました。 他の形式の挿入演算子は、SQL Server 2012 (11.x) の説明と同じように機能します。
SQL Server 2016 (13.x) およびデータベース互換レベル 130 以降、ヒープまたはクラスター化列ストア インデックス (CCI) に挿入し、TABLOCK ヒントを使用するときに、INSERT ... SELECT ステートメントを並列実行できるようになりました。 ローカル一時テーブル (# プレフィックスで識別されます) とグローバル一時テーブル (## プレフィックスで識別されます) への挿入は、TABLOCK ヒントを使用した並列処理にも有効です。 詳細については、「INSERT (Transact-SQL)」を参照してください。
静的カーソルとキーセット ドリブン カーソルは、並列実行プランによって作成できます。 ただし、動的カーソルの動作は、直列実行の場合だけ有効です。 クエリ オプティマイザーは、動的カーソルの一部であるクエリに対しては必ず直列実行プランを生成します。
並列処理の次数をオーバーライドする
並列プランの実行で使用するプロセッサの数は、並列処理の次数によって設定されます。 この構成は、次のさまざまなレベルで設定できます。
サーバー レベル。並列処理の最大限度 (MAXDOP)サーバー構成オプションを使用します。
適用対象: SQL ServerNote
SQL Server 2019 (15.x) では、インストール プロセス中に MAXDOP サーバー構成オプションを設定するための自動推奨事項が導入されています。 セットアップのユーザー インターフェイスでは、推奨設定を受け入れることも、独自の値を入力することもできます。 詳細については、「[データベース エンジンの構成] - [MAXDOP] ページ」を参照してください。
ワークロード レベル。MAX_DOPResource Governor ワークロード グループ構成オプションを使用します。
適用対象: SQL Serverデータベース レベル。MAXDOPデータベース スコープ構成を使用します。
適用対象: SQL Server および Azure SQL Databaseクエリまたはインデックス ステートメント レベル。MAXDOPクエリ ヒントまたは MAXDOP インデックス オプションを使用します。 たとえば、MAXDOP オプションを使用すると、オンライン インデックス操作専用のプロセッサの数を増減することによって制御できます。 このようにすることで、インデックス操作で使用されるリソースと同時実行ユーザーが使用するリソースのバランスをとることができます。
適用対象: SQL Server および Azure SQL Database
max degree of parallelism オプションを 0 (既定) に設定すると、SQL Server で並列プランの実行で使用するプロセッサの数を最大 64 に制限できます。 MAXDOP オプションを 0 に設定すると、SQL Server では 64 個の論理プロセッサという実行時ターゲットが設定されますが、必要であれば、別の値を手動で設定できます。 クエリおよびインデックスに対して MAXDOP を 0 に設定すると、並列プランの実行で指定されたクエリまたはインデックスに対して SQL Server で利用可能なすべてのプロセッサ (最大 64) を使用できます。 MAXDOP はあらゆる並列クエリに強制される値ではなく、並列処理に適したすべてのクエリにとっての仮の目標です。 つまり、実行時に十分なワーカー スレッドが使用できない場合、MAXDOP サーバー構成オプションよりも低い並列処理の次数でクエリが実行される可能性があります。
ヒント
サーバー、データベース、クエリ、またはヒント レベルでの MAXDOP の構成に関するガイドラインの詳細については、MAXDOP に関する推奨事項を参照してください。
並列クエリの例
次のクエリでは、2000 年 4 月 1 日を開始日とする特定の四半期に受けた注文のうち、納品期日を過ぎた項目を 1 つ以上含む注文の件数を数えます。 さらに、該当する注文を受注優先度別にグループ分けし、受注優先度の昇順に並べ替えてその注文数を一覧表示します。
この例には、架空のテーブル名と列名を使用しています。
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
lineitem テーブルと orders テーブルで次のインデックスが定義されていると想定します。
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
上記のクエリに対して生成される並列プランの例を次に示します。
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
以下の図は、並列処理の次数が 4 で実行され、2 つのテーブルが結合されているクエリ プランを示しています。
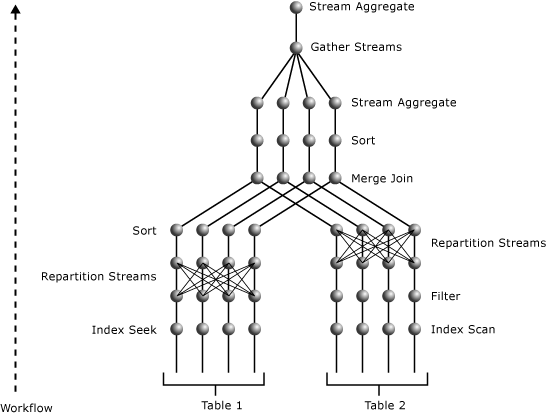
並列プランには、3 つの並列処理操作が含まれています。 o_datkey_ptr インデックスの Index Seek 操作と l_order_dates_idx インデックスの Index Scan 操作が並列で実行されます。 これにより、複数の排他ストリームが生成されます。 この処理は、Index Scan 操作と Index Seek 操作の上位にあり最も近い Parallelism 操作からそれぞれ決定できます。 どちらの操作もストリームを再分割し、交換の種類を決定しています。 つまり、単にストリーム間でデータを再移動して、入力時と同じ数のストリームを出力時に生成しているということです。 このストリーム数は並列処理の次数と同じになります。
l_order_dates_idx Index Scan 操作の上位にある並列操作は、L_ORDERKEY の値を使用して入力ストリームを再分割します。 このようにして、同じ L_ORDERKEY の値が同じ出力ストリームで終了します。 同時に、出力ストリームは L_ORDERKEY 列の順序を維持し、Merge Join 操作の入力要件を満たします。
Index Seek 操作の上位にある並列操作は、O_ORDERKEY の値を使用して入力ストリームを再分割します。 この入力は O_ORDERKEY 列の値で並べ替えられておらず、Merge Join 操作の結合列であるので、並列処理と Merge Join 操作の間の Sort 操作により、Merge Join 操作のために入力を結合列で並べ替えています。 Sort 操作は、Merge Join 操作と同様に並列処理されます。
最上位にある並列操作は、複数のストリームから得た結果を 1 つのストリームに集めます。 この並列操作の下位にある Stream Aggregate 操作で実行された部分集計は、並列操作の上位にある Stream Aggregate 操作の O_ORDERPRIORITY の異なる値ごとに 1 つの SUM 値に累計されます。 このプランには並列処理の次数が 4 に設定された 2 つの交換セグメントが含まれているため、8 個のワーカー スレッドが使用されます。
この例で使用されている操作の詳細については、「プラン表示の論理操作と物理操作のリファレンス」を参照してください。
並列インデックス操作
インデックスの作成や再構築、クラスター化インデックスの削除などのインデックス操作用に構築されたクエリ プランでは、複数のマイクロプロセッサを備えたコンピューターでの並列マルチワーカー スレッド操作が可能になります。
Note
並列インデックス操作は、SQL Server 2008 (10.0.x) 以降、Enterprise Edition でのみ使用できます。
SQL Server では、インデックス操作の並列処理の限度 (実行に使用する個別ワーカー スレッドの合計数) を決める際に、他のクエリに行うのと同じアルゴリズムが使用されます。 インデックス操作に必要な並列処理の最大限度は、 max degree of parallelism サーバー構成オプションによって決まります。 CREATE INDEX、ALTER INDEX、DROP INDEX、および ALTER TABLE の各ステートメントで MAXDOP インデックス オプションを設定することにより、個別のインデックス操作の max degree of parallelism 値をオーバーライドできます。
SQL Server データベース エンジンによってインデックス実行プランが構築される際に、並列操作の数は、次のうち最も低い値に設定されます。
- コンピューター内のマイクロプロセッサ (CPU) の数。
- max degree of parallelism サーバー構成オプションで指定されている数。
- SQL Server のワーカー スレッド用に実行されるワークのしきい値以下の CPU の数。
たとえば、CPU が 8 基ある場合でも、max degree of parallelism が 6 に設定されているコンピューターでは、インデックス操作用に生成される並列ワーカー スレッドの数は最大 6 つです。 インデックス実行プランを構築するとき、コンピューター内の 5 基の CPU が SQL Server のワークのしきい値を超えている場合は、実行プランによって指定される並列ワーカー スレッドの数は 3 つだけになります。
並列インデックス操作の主なフェーズには、次のフェーズがあります。
- 調整ワーカー スレッドがテーブルを迅速かつランダムにスキャンし、インデックス キーの分布を算出します。 調整ワーカー スレッドが、並列操作の限度と等しい数のキー範囲を作成するキーの境界を確立します。それぞれのキー範囲は、同じ数の行を処理対象として算出されます。 たとえば、テーブル内に 400 万行あって並列処理の限度が 4 の場合、調整ワーカー スレッドは 1 セット 100 万行で 4 セットの行に区切るキー値を決定します。 すべての CPU を使用するために十分なキー範囲を確立できない場合、並列処理の限度が適宜減少されます。
- 調整ワーカー スレッドは、並列操作の限度と等しい数のワーカー スレッドを優先して、それらのワーカー スレッドの作業が完了するまで待ちます。 各ワーカー スレッドは、ワーカー スレッドに割り当てられた範囲内のキー値を持つ行だけを取得するフィルターを使用して、ベース テーブルをスキャンします。 各ワーカー スレッドは、そのキーの範囲内で行のインデックス構造を構築します。 パーティション インデックスの場合、各ワーカー スレッドで指定した数のパーティションが構築されます。 パーティションはワーカー スレッド間では共有されません。
- すべての並列ワーカー スレッドが完了した後で、調整ワーカー スレッドはインデックスのサブユニットを単一のインデックスに接続します。 このフェーズは、オフライン インデックス操作にのみ適用されます。
個別の CREATE TABLE ステートメントまたは ALTER TABLE ステートメントには、インデックスの作成を必要とする複数の制約が課される場合があります。 これらの複数のインデックス作成操作は連続して実行されますが、個別のインデックス作成操作は複数の CPU を備えたコンピューターでは並列操作になることがあります。
分散クエリ アーキテクチャ
Microsoft SQL Server は、Transact-SQL ステートメント内で異種 OLE DB データ ソースを参照する方法として、次の 2 つをサポートしています。
リンク サーバー名
sp_addlinkedserverとsp_addlinkedsrvloginの各システム ストアド プロシージャを使用して、OLE DB データ ソースにサーバー名を渡します。 リンク サーバー内のオブジェクトは、4 部構成の名前を使用して Transact-SQL ステートメント内で参照できます。 たとえば、DeptSQLSrvrというリンク サーバー名が SQL Server の別のインスタンスで定義されている場合、次のステートメントはこのサーバー上のテーブルを参照します。SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;リンク サーバー名を
OPENQUERYステートメントで指定して、OLE DB データ ソースの行セットを開くこともできます。 この行セットは、Transact-SQL ステートメント内でテーブルと同じように参照できます。アドホック コネクタ名
データ ソースを頻繁に参照しない場合は、リンク サーバーに接続するために必要な情報を含めたOPENROWSET関数またはOPENDATASOURCE関数を指定します。 これにより、行セットを Transact-SQL ステートメント内でテーブルと同じように参照できます。SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server では、OLE DB を使用してリレーショナル エンジンとストレージ エンジンの間の通信を行います。 リレーショナル エンジンは、各 Transact-SQL ステートメントを一連の操作に分割します。それぞれの操作は、ストレージ エンジンがベース テーブルから開いた単純な OLE DB 行セットに対する操作です。 これは、リレーショナル エンジンは、OLE DB データ ソースに対する単純な OLE DB 行セットも開くことができることを意味しています。
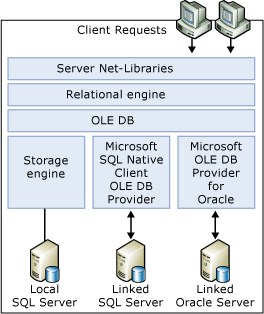
リレーショナル エンジンは OLE DB API (アプリケーション プログラミング インターフェイス) を使用して、リンク サーバー上の行セットを開き、行をフェッチし、トランザクションを管理します。
OLE DB データ ソースにリンク サーバーとしてアクセスするには、SQL Server が動作するサーバー上に OLE DB プロバイダーが存在している必要があります。 OLE DB データ ソースに対して使用できる Transact-SQL 操作の数は、OLE DB プロバイダーの機能によって決まります。
sysadmin 固定サーバー ロールのメンバーは、SQL Server のインスタンスごとに SQL Server DisallowAdhocAccess プロパティを使用して、OLE DB プロバイダーのアドホック コネクタ名の使用を有効化または無効化できます。 アドホック アクセスが有効化されると、そのインスタンスにログオンしているユーザーは、アドホック コネクタ名を含んだ Transact-SQL ステートメントを実行し、OLE DB プロバイダーを使用してアクセスできるネットワークのすべてのデータ ソースを参照できます。 sysadmin ロールのメンバーは、データ ソースへのアクセスを制御するために、その OLE DB プロバイダーに対するアドホック アクセスを無効化できます。その結果、ユーザーは管理者が定義したリンク サーバー名で参照されるデータ ソースのみに制限されます。 既定では、SQL Server OLE DB プロバイダーではアドホック アクセスが有効化されており、他のすべての OLE DB プロバイダーでは無効化されています。
分散クエリを使用すると、 SQL Server サービスを実行している Microsoft Windows アカウントのセキュリティ コンテキストを使用して、他のデータ ソース (たとえば、ファイルや Active Directory などのリレーショナルでないデータ ソース) にアクセスできます。 SQL Server は Windows ログインでは適切にログインを偽装できますが、SQL Server ログインでは適切に偽装できません。 このため、分散クエリユーザーにデータソースへのアクセス許可がなくても、SQL Server サービスを実行しているアカウントにアクセス許可があれば、分散クエリ ユーザーからのアクセスを許可してしまう可能性があります。 対応するリンク サーバーにアクセスする権限のある特定のログインを定義するには、 sp_addlinkedsrvlogin を使用します。 このような制御は、アドホック名では使用できないので、OLE DB プロバイダーでアドホック アクセスを有効にする場合は注意してください。
SQL Server は、可能であれば、OLE DB データ ソースに対して、結合、条件、射影、並べ替え、および GROUP BY (SQL 言語) 操作などのリレーショナル操作を試行します。 特に指定しない限り、SQL Server 自身がベース テーブルをスキャンして SQL Server に読み込んだり、リレーショナル操作を実行することはありません。 SQL Server は OLE DB プロバイダーに問い合わせて、そのプロバイダーがサポートする SQL 文法のレベルを判別し、その情報に基づいて、可能な限り多くのリレーショナル操作をプロバイダーに送ります。
SQL Server では、OLE DB プロバイダーのメカニズムを指定して、OLE DB データ ソース内でのキー値の分布状況を示す統計を返すようにします。 これにより、各 Transact-SQL ステートメントの必要条件に対して、SQL Server クエリ オプティマイザーがデータ ソース内のデータのパターンをより正確に分析できるようになり、最適な実行プランを作成するクエリ オプティマイザーの機能が向上します。
パーティション テーブルとパーティション インデックスに対するクエリ処理の機能強化
SQL Server 2008 (10.0.x) では、多くの並列プランでのパーティション テーブルに対するクエリ処理のパフォーマンスが向上しています。また、並列プランと直列プランを表す方法が変更され、コンパイル時と実行時の両方の実行プランで示されるパーティション分割情報が強化されています。 この記事では、これらの機能強化について説明します。また、パーティション テーブルとパーティション インデックスのクエリ実行プランを解釈する方法、およびパーティション分割されたオブジェクトに対するクエリのパフォーマンス向上に関するベスト プラクティスについて説明します。
Note
SQL Server 2014 (12.x) までは、パーティション テーブルとパーティション インデックスは、SQL Server の Enterprise エディション、Developer エディション、および Evaluation エディションでのみサポートされています。 SQL Server 2016 (13.x) SP1 以降では、SQL Server Standard エディションでもパーティション テーブルとパーティション インデックスがサポートされています。
新しいパーティション対応のシーク操作
SQL Server ではパーティション テーブルの内部表現が変更され、テーブルはクエリ プロセッサに対して、先頭列に PartitionID を持つ複数列インデックスとして表されます。 PartitionID は、特定の行を含むパーティションの ID を表すために内部的に使用される非表示の計算列です。 たとえば、 T(a, b, c)として定義されているテーブル T が列 a でパーティション分割され、列 b にクラスター化インデックスがあるとします。 SQL Server では、内部的にはこのパーティション テーブルは、スキーマが T(PartitionID, a, b, c) で複合キー (PartitionID, b)にクラスター化インデックスがある非パーティション テーブルとして扱われます。 これにより、クエリ オプティマイザーは、パーティション テーブルまたはパーティション インデックスの PartitionID に基づいてシーク操作を実行できます。
パーティションの解消は、このシーク操作で行われるようになりました。
In addition, the Query Optimizer is extended so that a seek or scan operation with one condition can be done on PartitionID (論理的な先頭列) およびその他のインデックス キー列に基づいて実行し、続いて 2 番目のレベルのシークを実行できます。このシークは最初のレベルのシーク操作の条件を満たす値ごとに、別の条件を指定した 1 つ以上の追加の列に基づいて実行できます。 つまり、スキップ スキャンと呼ばれるこの操作によって、クエリ オプティマイザーは、ある条件に基づいてシーク操作またはスキャン操作を実行してアクセス対象のパーティションを特定し、その操作内で 2 番目のレベルのインデックスのシーク操作を実行し、特定済みのパーティションのうち別の条件を満たすパーティションから行を返すことができます。 たとえば、次のクエリについて考えてみます。
SELECT * FROM T WHERE a < 10 and b = 2;
この例では、 T(a, b, c)として定義されているテーブル T が列 a でパーティション分割され、列 b にクラスター化インデックスがあるとします。 テーブル T のパーティション境界は、次のパーティション関数によって定義されます。
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
クエリを解決するために、クエリ プロセッサによって最初のレベルのシーク操作が実行され、条件 T.a < 10を満たす行を含むすべてのパーティションが検索されます。 これにより、アクセス対象のパーティションが特定されます。 特定された各パーティション内で、プロセッサによって列 b のクラスター化インデックスに対する 2 番目のレベルのシーク操作が実行され、条件 T.b = 2 および T.a < 10を満たす行が検索されます。
次の図は、スキップ スキャン操作を論理的に表したものです。 列 T および a にデータが格納されているテーブル b を示しています。 パーティションには 1 ~ 4 の番号が割り当てられており、パーティション境界は破線の縦線で表示されています。 パーティションに対する最初のレベルのシーク操作 (図には示されていません) で、パーティション 1、2、および 3 が、テーブルに対して定義されたパーティション分割および列 a の述語で暗黙的に指定された Seek 条件を満たすことが特定されています。 つまり、条件 T.a < 10を満たします。 スキップ スキャン操作の 2 番目のレベルの Seek 部分でスキャンされるパスは、曲線で表示されています。 基本的に、スキップ スキャン操作によって、前の各パーティションで条件 b = 2を満たす行がシークされます。 スキップ スキャン操作の総コストは、3 つの個別のインデックス シークの総コストと同じです。
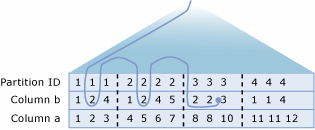
クエリ実行プランのパーティション分割情報を表示する
パーティション テーブルとパーティション インデックスに対するクエリの実行プランは、Transact-SQL SET ステートメントの SET SHOWPLAN_XML または SET STATISTICS XMLを使用するか、SQL Server Management Studio のグラフィカル実行プラン出力を使用して調べることができます。 たとえば、コンパイル時の実行プランを表示するには、クエリ エディターのツール バーの [推定実行プランの表示] を選択し、実行時のプランを表示するには、[実際の実行プランを含める] を選択します。
これらのツールを使用すると、次の情報を確認できます。
- パーティション テーブルまたはパーティション インデックスにアクセスする
scans、seeks、inserts、updates、merges、deletesなどの操作。 - クエリによってアクセスされるパーティション。 たとえば、実行時の実行プランでは、アクセスされるパーティションの総数やアクセスされる連続したパーティションの範囲を確認できます。
- シーク操作またはスキャン操作でスキップ スキャン操作が使用され、1 つ以上のパーティションからデータが取得されるタイミング。
パーティション情報に関する機能強化
SQL Server では、コンパイル時と実行時の両方の実行プランのパーティション分割情報が強化されています。 実行プランで次の情報が示されるようになりました。
Partitioned、seek、scan、insert、update、mergeなどの操作がパーティション テーブルに対して実行されることを示すdelete属性 (オプション)。- 先頭のインデックス キー列として
SeekPredicateNewを含み、SeekKeysに対して範囲シークを指定するフィルター条件を含むPartitionIDサブ要素を持つ新しいPartitionID要素。 2 つのSeekKeysサブ要素が存在する場合は、PartitionIDに対するスキップ スキャン操作が使用されることを示しています。 - アクセスされるパーティションの総数を示す概要情報。 この情報は、実行時のプランでのみ確認できます。
この情報をグラフィカル実行プラン出力と XML プラン表示出力の両方で表示する方法の説明のために、パーティション テーブル fact_salesに対する次のクエリについて考えます。 このクエリでは、2 つのパーティションのデータが更新されます。
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
次の図は、このクエリの実行時の実行プランにおける Clustered Index Seek 操作のプロパティを示しています。 fact_sales テーブルの定義およびパーティション定義を確認するには、この記事の「例」を参照してください。

Partitioned 属性
Index Seek などの操作がパーティション テーブルまたはインデックスに対して実行される場合、コンパイル時および実行時のプランに Partitioned 属性が表示され、True (1) に設定されます。 False (0) に設定された場合、この属性は表示されません。
Partitioned 属性は、次の物理操作と論理操作で表示されます。
- Table Scan
- Index Scan
- Index Seek
- 挿入
- 更新
- 削除
- マージする
前の図に示したように、この属性は、属性が定義されている操作のプロパティに表示されます。 XML プラン表示出力では、この属性は、属性が定義されている操作の Partitioned="1" ノードに RelOp として表示されます。
新しい seek 述語
XML プラン表示出力では、 SeekPredicateNew 要素がその要素を定義している操作に表示されます。 この要素には、SeekKeys サブ要素が最大 2 つ含まれることがあります。 最初の SeekKeys アイテムは、論理インデックスのパーティション ID レベルで最初のレベルのシーク操作を指定します。 つまり、この Seek によって、クエリの条件を満たすためにアクセスする必要があるパーティションが特定されます。 2 番目の SeekKeys アイテムは、最初のレベルの Seek で特定された各パーティション内で行われるスキップ スキャン操作の 2 番目のレベルの Seek 部分を指定します。
パーティションの概要情報
実行時の実行プランでは、パーティションの概要情報に、アクセスしたパーティションの数やアクセスした実際のパーティションの ID が示されます。 この情報を使用して、クエリで正しいパーティションにアクセスしているかどうか、および他のすべてのパーティションが考慮の対象から除外されているかどうかを確認できます。
示される情報は、 Actual Partition Countと Partitions Accessedです。
Actual Partition Count は、クエリでアクセスされるパーティションの総数です。
Partitions Accessed(XML プラン表示出力内) は、新しい RuntimePartitionSummary 要素に表示されるパーティションの概要情報です。この要素は、要素が定義されている操作の RelOp ノードに表示されます。 次の例に、合計 2 つのパーティション (パーティション 2 および 3) にアクセスすることを示す RuntimePartitionSummary 要素の内容を示します。
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
プラン表示のその他のメソッドを使用してパーティション情報を表示する
SHOWPLAN_ALL、SHOWPLAN_TEXT、STATISTICS PROFILE の各プラン表示のメソッドでは、この記事で説明したパーティション情報はレポートされません。 ただし、例外として、アクセスされるパーティションが、 SEEK 述語の一部としてパーティション ID を表す計算列の範囲述語によって特定されます。 次の例に、 SEEK 操作の Clustered Index Seek 述語を示します。 パーティション 2 および 3 にアクセスし、シーク オペレーターによって条件 date_id BETWEEN 20080802 AND 20080902を満たす行がフィルター選択されます。
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
パーティション分割されたヒープの実行プランを解釈する
パーティション分割されたヒープは、パーティション ID の論理インデックスとして扱われます。 パーティション分割されたヒープのパーティションの解消は、実行プランでは、 Table Scan 述語がパーティション ID に対して指定された SEEK 操作として表されます。 次の例は、プラン表示情報を示しています。
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
併置結合の実行プランを解釈する
結合のコロケーションは、同じパーティション関数または同等のパーティション関数を使用して 2 つのテーブルをパーティション分割し、結合の両側のパーティション列をクエリの結合条件に指定すると発生します。 クエリ オプティマイザーでは、同じパーティション ID を持つ各テーブルのパーティションが個別に結合されるプランを生成できます。 併置結合では必要なメモリが少なくなり、処理時間が短縮されることがあるので、この結合は非併置結合よりも処理が高速になる場合があります。 クエリ オプティマイザーでは、コストの推定に基づいて、非併置プランまたは併置プランが選択されます。
併置プランでは、 Nested Loops 結合は内側の 1 つ以上の結合テーブルまたはインデックス パーティションを読み取ります。 Constant Scan 操作内の数値は、パーティション番号を表します。
パーティション テーブルまたはパーティション インデックスに対して併置結合の並行プランが生成された場合、結合操作 Constant Scan と Nested Loops の間に Parallelism 操作が表れます。 その場合、結合外部にある複数のワーカー スレッドがそれぞれ異なるパーティションに対して読み取りや操作を行います。
次の図は、併置結合の並列クエリ プランを示しています。

パーティション分割されたオブジェクトの並列クエリの実行戦略
クエリ プロセッサは、パーティション分割されたオブジェクトから選択するクエリに対して並列実行を使用します。 クエリ プロセッサでは、実行戦略の一環として、クエリに必要なテーブル パーティションと、各パーティションに割り当てるワーカー スレッドの数を決定します。 ほとんどの場合、クエリ プロセッサは、各パーティションに同数またはほぼ同数のワーカー スレッドを割り当て、パーティション全体でクエリを並列実行します。 以降、ワーカー スレッドの割り当てについてさらに詳しく説明します。
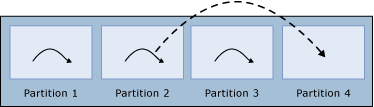
ワーカー スレッドの数がパーティションの数よりも少ない場合、クエリ プロセッサが各ワーカー スレッドを別々のパーティションに割り当てると、最初に、ワーカー スレッドが割り当てられていないパーティションが 1 つ以上残ります。 パーティションでワーカー スレッドの実行が完了すると、クエリ プロセッサは、各パーティションに 1 つのワーカー スレッドが割り当てられるまで、そのワーカー スレッドを次のパーティションに割り当てます。 これが当てはまるのは、クエリ プロセッサがワーカー スレッドを他のパーティションに再割り当てする場合に限ります。
終了後に再割り当てされたワーカー スレッド。 ワーカー スレッドの数とパーティションの数が同じ場合、クエリ プロセッサは各パーティションに 1 つのワーカー スレッドを割り当てます。 ワーカー スレッドの終了時に、そのワーカー スレッドが別のパーティションに再割り当てされることはありません。

ワーカー スレッドの数がパーティションの数よりも多い場合、クエリ プロセッサは各パーティションに同じ数のワーカー スレッドを割り当てます。 ワーカー スレッドの数がパーティションの数で割り切れない場合、クエリ プロセッサは、使用できるすべてのワーカー スレッドを使用するために、一部のパーティションにワーカー スレッドを 1 つ多く割り当てます。 パーティションが 1 つしかない場合は、すべてのワーカー スレッドがそのパーティションに割り当てられます。 次の図では、4 個のパーティションと 14 個のワーカー スレッドがあります。 各パーティションには 3 つのワーカー スレッドが割り当てられ、さらに 2 つのパーティションには追加のワーカー スレッドが割り当てられて、合計で 14 ワーカー スレッドが割り当てられています。 ワーカー スレッドは、終了時に別のパーティションに再割り当てされることはありません。

上の例では簡単にワーカー スレッドを割り当てる方法を示していますが、実際の方法はより複雑で、クエリの実行中に発生する他の変数を使用します。 たとえば、テーブルがパーティション分割され、その列 A にクラスター化インデックスが設定されている場合、クエリで述語句 WHERE A IN (13, 17, 25)を使用すると、クエリ プロセッサは、1 つ以上のワーカー スレッドを、各テーブル パーティションではなくワーカー スレッドの 3 つの各シーク値 (A=13、A=17、A=25) に割り当てます。 これらの値を含むパーティションでクエリを実行すれば十分です。これらのシーク述語がすべて同じテーブル パーティションに含まれる場合は、すべてのワーカー スレッドが同じテーブル パーティションに割り当てられます。
別の例として、テーブルで列 A に境界点が (10、20、30) である 4 つのパーティションと、列 B にインデックスが設定されており、クエリに述語句 WHERE B IN (50, 100, 150)が含まれるとします。 テーブル パーティションは A の値に基づいているため、B の値はどのテーブル パーティションにも存在する可能性があります。 したがって、クエリ プロセッサは、4 つの各テーブル パーティションで、B の 3 つの値 (50、100、150) を検索します。 クエリ プロセッサは、これらの 12 個の各クエリ スキャンを並列実行できるように、ワーカー スレッドを均等に割り当てます。
| 列 A に基づいたテーブル パーティション | 各テーブル パーティションにおける列 B の検索 |
|---|---|
| テーブル パーティション 1: A < 10 | B=50、B=100、B=150 |
| テーブル パーティション 2: A >= 10 AND A < 20 | B=50、B=100、B=150 |
| テーブル パーティション 3: A >= 20 AND A < 30 | B=50、B=100、B=150 |
| テーブル パーティション 4: A >= 30 | B=50、B=100、B=150 |
ベスト プラクティス
大きなパーティション テーブルおよびパーティション インデックスの大量のデータにアクセスするクエリのパフォーマンスを向上するために推奨するベスト プラクティスを次に示します。
- 各パーティションを多くのディスクにわたってストライピングします。 これは、回転ディスクを使用する場合に特に関連性が高くなります。
- 可能な場合は、アクセス頻度の高いパーティションまたはすべてのパーティションを保持できる十分なメイン メモリがあるサーバーを使用して、I/O コストを軽減します。
- クエリ対象のデータがメモリ内に収まらない場合は、テーブルおよびインデックスを圧縮します。 これにより、I/O コストを軽減します。
- 高速なプロセッサおよびできるだけ多くのプロセッサ コアを搭載したサーバーを使用して、並列クエリ処理機能を活用します。
- サーバーに十分な I/O コントローラーの帯域幅があることを確認します。
- すべての大きなパーティション テーブルにクラスター化インデックスを作成して、B ツリーのスキャンの最適化を活用します。
- パーティション テーブルへのデータの一括読み込みを行う場合は、 データ読み込みのパフォーマンス ガイドに関するホワイト ペーパーで説明されている推奨事項に従ってください。
例
次の例では、7 つのパーティションを持つ 1 つのテーブルを含むテスト データベースを作成します。 この例でクエリを実行し、コンパイル時と実行時の両方のプランのパーティション分割情報を表示する場合は、前に説明したツールを使用します。
Note
この例では、100 万以上の行をテーブルに挿入します。 この例を実行すると、ハードウェアによっては数分かかる場合があります。 この例を実行する前に、1.5 GB を超えるディスク領域が確保されていることを確認してください。
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
関連するコンテンツ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示