Team Data Science Process 수명 주기의 모델링 단계
이 문서에서는 TDSP(팀 데이터 과학 프로세스)의 모델링 단계와 관련된 목표, 작업 및 결과물을 설명합니다. 이 프로세스는 팀이 데이터 과학 프로젝트를 구성하는 데 사용할 수 있는 권장 수명 주기를 제공합니다. 수명 주기는 팀이 수행하는 주요 단계를 간략하게 설명하며, 종종 반복적으로 다음과 같습니다.
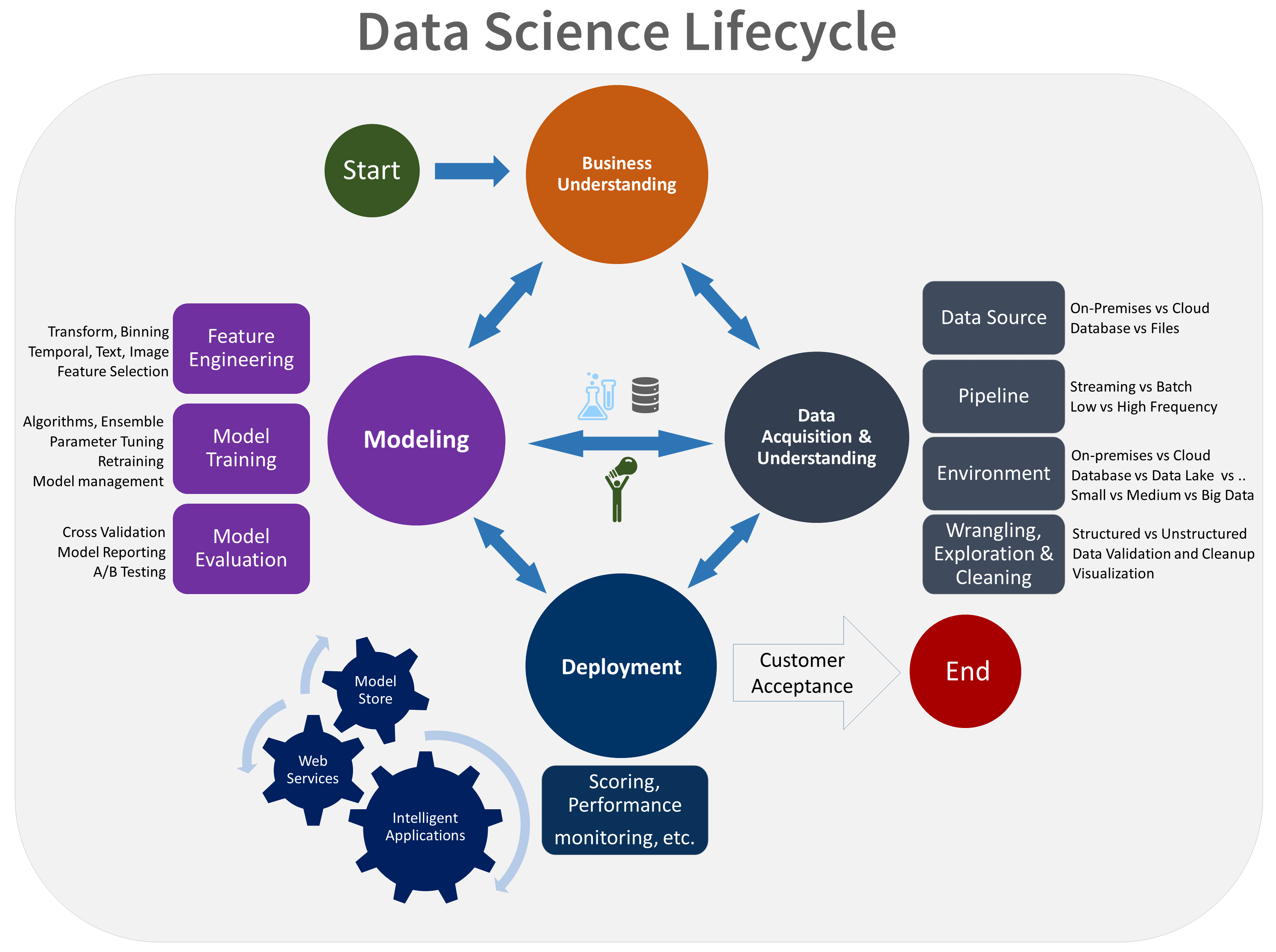
- 비즈니스 이해
- 데이터 취득 및 이해
- 모델링
- 배포
- 고객 승인
TDSP 수명 주기의 시각적 표현은 다음과 같습니다.
목표
모델링 단계의 목표는 다음과 같습니다.
기계 학습 모델에 대한 최적의 데이터 기능을 결정합니다.
대상을 가장 정확하게 예측하는 정보 제공 기계 학습 모델을 만듭니다.
프로덕션에 적합한 기계 학습 모델을 만듭니다.
작업을 완료하는 방법
모델링 단계에는 세 가지 기본 작업이 있습니다.
기능 엔지니어링: 모델 학습을 용이하게 하기 위해 원시 데이터로부터 데이터 기능을 만듭니다.
모델 학습: 모델의 성공 메트릭을 비교하여 질문에 가장 정확하게 대답하는 모델을 찾습니다.
모델 평가: 모델이 프로덕션에 적합한지 확인합니다.
특징 엔지니어링
기능 엔지니어링은 원시 변수의 포함, 집계 및 변환을 포함하여 분석에 사용되는 기능을 만듭니다. 모델을 빌드하는 방법에 대한 인사이트를 얻으려면 모델의 기본 기능을 연구해야 합니다.
이 단계에서 도메인 전문지식과 데이터 탐색 단계에서 얻은 통찰력을 창의적으로 결합해야 합니다. 기능 엔지니어링은 정보 변수를 찾고 포함하는 분산 작업이지만 동시에 관련 없는 변수가 너무 많이 발생하지 않도록 합니다. 정보 변수는 결과를 향상시킵니다. 관련 없는 변수는 모델에 불필요한 노이즈를 발생합니다. 또한 점수 매기기 중에 가져온 새로운 데이터에 대해 이러한 기능을 생성해야 합니다. 따라서 이러한 기능은 점수를 매길 때 사용할 수 있는 데이터에만 기반하여 생성할 수 있습니다.
모델 학습
답변하려는 질문 유형에 따라 사용할 수 있는 많은 모델링 알고리즘이 있습니다. 미리 빌드된 알고리즘을 선택하는 방법에 대한 지침은 Azure Machine Learning 디자이너용 Machine Learning 알고리즘 치트 시트를 참조하세요. 다른 알고리즘은 R 또는 Python의 오픈 소스 패키지를 통해 사용할 수 있습니다. 이 문서에서는 Azure Machine Learning에 중점을 두고 있지만 이 문서에서 제공하는 지침은 많은 기계 학습 프로젝트에 유용합니다.
모델 학습 프로세스에는 다음 단계가 포함됩니다.
모델링을 위해 학습 데이터 집합과 테스트 데이터 집합으로 입력 데이터를 임의로 분할합니다.
학습 데이터 집합을 사용하여 모델을 빌드합니다.
학습 및 테스트 데이터 집합을 평가합니다. 일련의 경쟁 기계 학습 알고리즘을 사용합니다. 현재 데이터에 대한 관심 있는 질문에 답하기 위한 다양한 관련 튜닝 매개 변수(매개 변수 스윕이라고 함)를 사용합니다.
대체 방법 간의 성공 메트릭을 비교하여 질문에 대답할 수 있는 최상의 솔루션을 결정합니다.
자세한 내용은 Machine Learning을 사용하여 모델 학습을 참조 하세요.
참고 항목
누출 방지: 모델 또는 기계 학습 알고리즘이 비현실적으로 좋은 예측을 할 수 있도록 학습 데이터 집합 외부의 데이터를 포함하는 경우 데이터 누출이 발생할 수 있습니다. 유출은 데이터 과학자들이 진실하기에는 너무 좋아 보이는 예측 결과를 가져올 때 불안해 하는 일반적 이유입니다. 이러한 종속성은 검색하기 어려울 수 있습니다. 누출을 방지하려면 분석 데이터 집합을 빌드하고, 모델을 만들고, 결과의 정확도를 평가하는 것 사이에서 반복해야 하는 경우가 많습니다.
모델 평가
모델을 학습한 후 팀의 데이터 과학자는 모델 평가에 중점을 둡니다.
결정: 모델이 프로덕션에 대해 충분히 수행되는지 여부를 평가합니다. 몇 가지 주요 질문은 다음과 같습니다.
테스트 데이터가 제공되면 질문에 대해 모델에서 매우 신뢰성 있게 대답합니까?
대안을 시도해야 할까요?
더 많은 데이터를 수집하거나, 더 많은 기능 엔지니어링을 수행하거나, 다른 알고리즘을 실험해야 하나요?
모델 해석: Machine Learning Python SDK를 사용하여 다음 작업을 수행합니다.
로컬에서 개인 컴퓨터의 전체 모델 동작 또는 개별 예측을 설명합니다.
해석력 기술을 사용하여 엔지니어링된 기능을 지원합니다.
Azure에서 전체 모델 및 개별 예측의 동작을 설명합니다.
Machine Learning 실행 기록에 설명을 업로드합니다.
시각화 대시보드를 사용하여 Jupyter Notebook 및 Machine Learning 작업 영역에서 모델 설명과 상호 작용합니다.
모델에 점수 매기기 설명자를 배포하여 추론 중에 설명을 관찰합니다.
공정성 평가: Machine Learning과 함께 fairlearn 오픈 소스 Python 패키지를 사용하여 다음 작업을 수행합니다.
모델 예측의 공정성을 평가합니다. 이 프로세스를 통해 팀은 기계 학습의 공정성에 대해 자세히 알아볼 수 있습니다.
Machine Learning Studio에서 공정성 평가 인사이트를 업로드, 나열 및 다운로드합니다.
모델의 공정성 인사이트와 상호 작용하려면 Machine Learning Studio의 공정성 평가 대시보드를 참조하세요.
MLflow와 통합
Machine Learning은 MLflow와 통합하여 모델링 수명 주기를 지원합니다. 실험, 프로젝트 배포, 모델 관리 및 모델 레지스트리에 MLflow의 추적을 사용합니다. 이 통합은 원활하고 효율적인 기계 학습 워크플로를 보장합니다. Machine Learning의 다음 기능은 이 모델링 수명 주기 요소를 지원하는 데 도움이 됩니다.
실험 추적: MLflow의 핵심 기능은 모델링 단계에서 광범위하게 사용되어 다양한 실험, 매개 변수, 메트릭 및 아티팩트 추적을 수행합니다.
프로젝트 배포: MLflow Projects를 사용하여 코드를 패키징하면 팀 구성원 간에 일관된 실행과 간편한 공유가 보장되며, 이는 반복적인 모델 개발 중에 필수적입니다.
모델 관리: 다양한 모델이 빌드, 평가 및 구체화되므로 이 단계에서는 모델 관리 및 버전 관리가 중요합니다.
모델 등록: 모델 레지스트리는 수명 주기 내내 모델의 버전 관리 및 관리에 사용됩니다.
피어 검토 문헌
연구원은 동료 검토한 문헌에 있는 TDSP에 관하여 연구 결과를 간행합니다. 인용은 모델링 수명 주기 단계를 포함하여 TDSP에 대한 다른 애플리케이션 또는 유사한 아이디어를 조사할 수 있는 기회를 제공합니다.
참가자
Microsoft에서 이 문서를 유지 관리합니다. 원래 다음 기여자가 작성했습니다.
보안 주체 작성자:
- Mark Tabladillo | 선임 클라우드 솔루션 설계자
비공개 LinkedIn 프로필을 보려면 LinkedIn에 로그인합니다.
관련 참고 자료
다음 문서에서는 TDSP 수명 주기의 다른 단계를 설명합니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기