빠른 시작: 사용자 고유의 Virtual Network에서 Azure Databricks 작업 영역 만들기
Azure Databricks의 기본 배포는 Databricks에서 관리하는 새 가상 네트워크를 만듭니다. 이 빠른 시작에서는 사용자 고유의 가상 네트워크에서 Azure Databricks 작업 영역을 만드는 방법을 보여 줍니다. 또한 해당 작업 영역 내에 Apache Spark 클러스터를 만듭니다.
사용자 고유의 가상 네트워크에서 Azure Databricks 작업 영역을 만들도록 선택하는 이유에 대한 자세한 내용은 Azure Virtual Network(VNet 삽입)에 Azure Databricks 배포를 참조하세요.
필수 조건
Azure 구독이 없는 경우 무료 계정을 만드세요. 이 자습서는 Azure 평가판 구독을 사용하여 수행할 수 없습니다. 무료 계정이 있는 경우 프로필로 이동하여 구독을 종량제로 변경합니다. 자세한 내용은 Azure 체험 계정을 참조하세요. 그런 다음, 지출 한도를 제거하고 해당 지역의 vCPU에 대한 할당량 증가를 요청합니다. Azure Databricks 작업 영역을 만들 때 평가판(프리미엄 - 14일 무료 DPU) 가격 책정 계층을 선택하여 작업 영역에 14일 동안 무료 Premium Azure Databricks DPU에 대한 액세스 권한을 부여할 수 있습니다.
Azure 기여자 또는 소유자이거나 Microsoft.ManagedIdentity 리소스 공급자를 구독에 등록해야 합니다. 자세한 내용은 리소스 공급자 등록을 참조하세요.
Azure Portal에 로그인
Azure Portal에 로그인합니다.
참고 항목
FedRAMP High와 같은 미국 정부 규정 준수 인증을 보유하는 Azure Commercial Cloud에서 Azure Databricks 작업 영역을 만들려면 Microsoft 또는 Databricks 계정 팀에 문의하여 이 환경에 액세스하세요.
가상 네트워크 만들기
Azure Portal 메뉴에서 리소스 만들기를 선택합니다. 그런 다음 네트워킹 > 가상 네트워크를 차례로 선택합니다.
가상 네트워크 만들기 아래에서 다음 설정을 적용합니다.
설정 제안 값 설명 구독 <구독> 사용할 Azure 구독을 선택합니다. Resource group databricks-quickstart 새로 만들기를 선택하고 계정의 새 리소스 그룹 이름을 입력합니다. 속성 databricks-quickstart 가상 네트워크의 이름을 선택합니다. 지역 <사용자와 가장 가까운 지역 선택> 가상 네트워크를 호스트할 수 있는 지리적 위치를 선택합니다. 사용자와 가장 가까운 위치를 사용합니다. 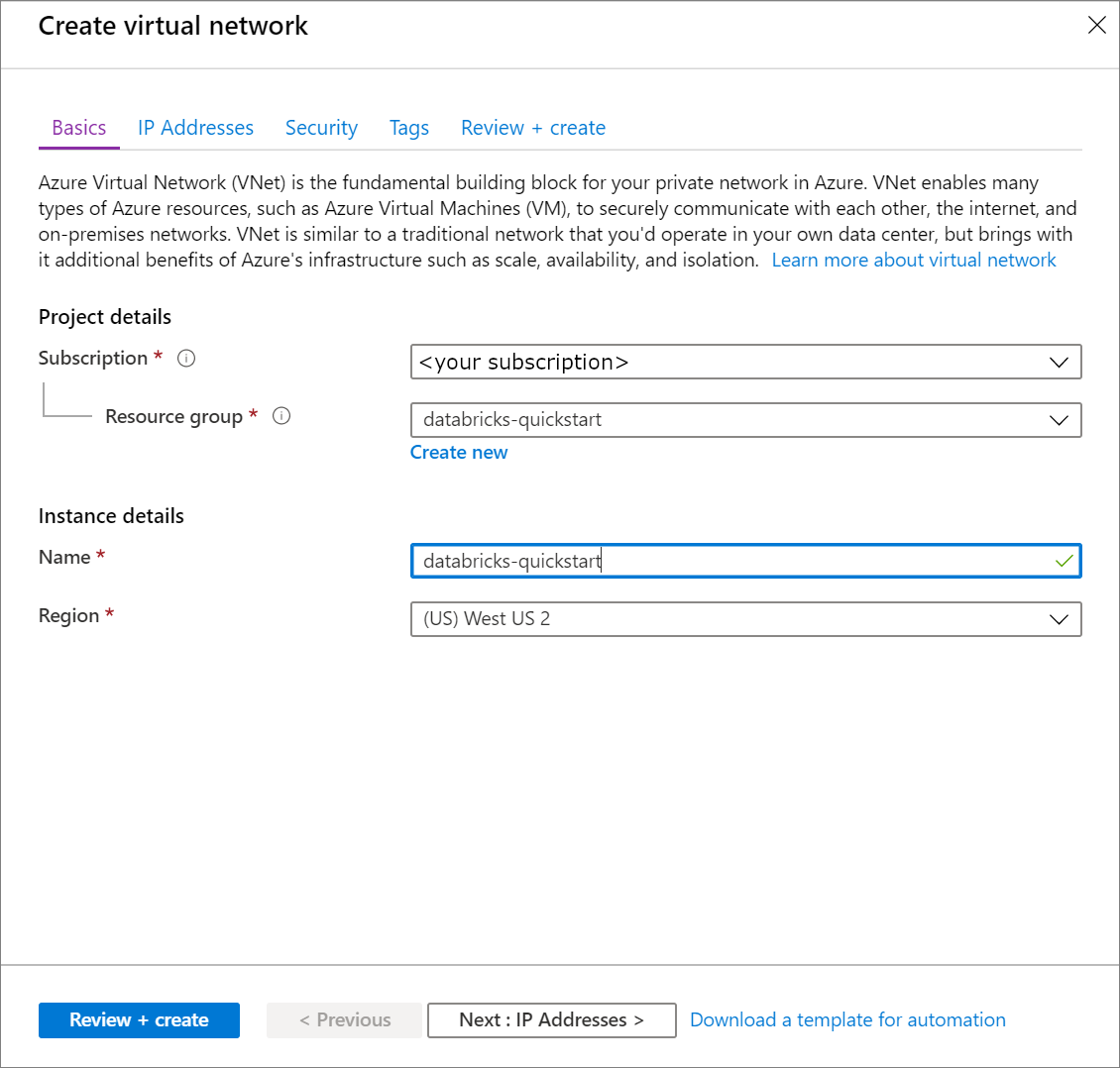
다음: IP 주소 >를 선택하고 다음 설정을 적용합니다. 그런 다음, 검토 + 생성를 선택합니다.
설정 제안 값 설명 IPv4 주소 공간 10.2.0.0/16 CIDR 표기법의 가상 네트워크 주소 범위입니다. CIDR 범위는 /16과 /24 사이여야 합니다 서브넷 이름 default 가상 네트워크에서 기본 서브넷의 이름을 선택합니다. 서브넷 주소 범위 10.2.0.0/24 서브넷의 주소 범위가 CIDR 표기법으로 되어 있습니다. 가상 네트워크의 주소 공간에 포함되어야 합니다. 사용 중인 서브넷의 주소 범위는 편집할 수 없습니다. 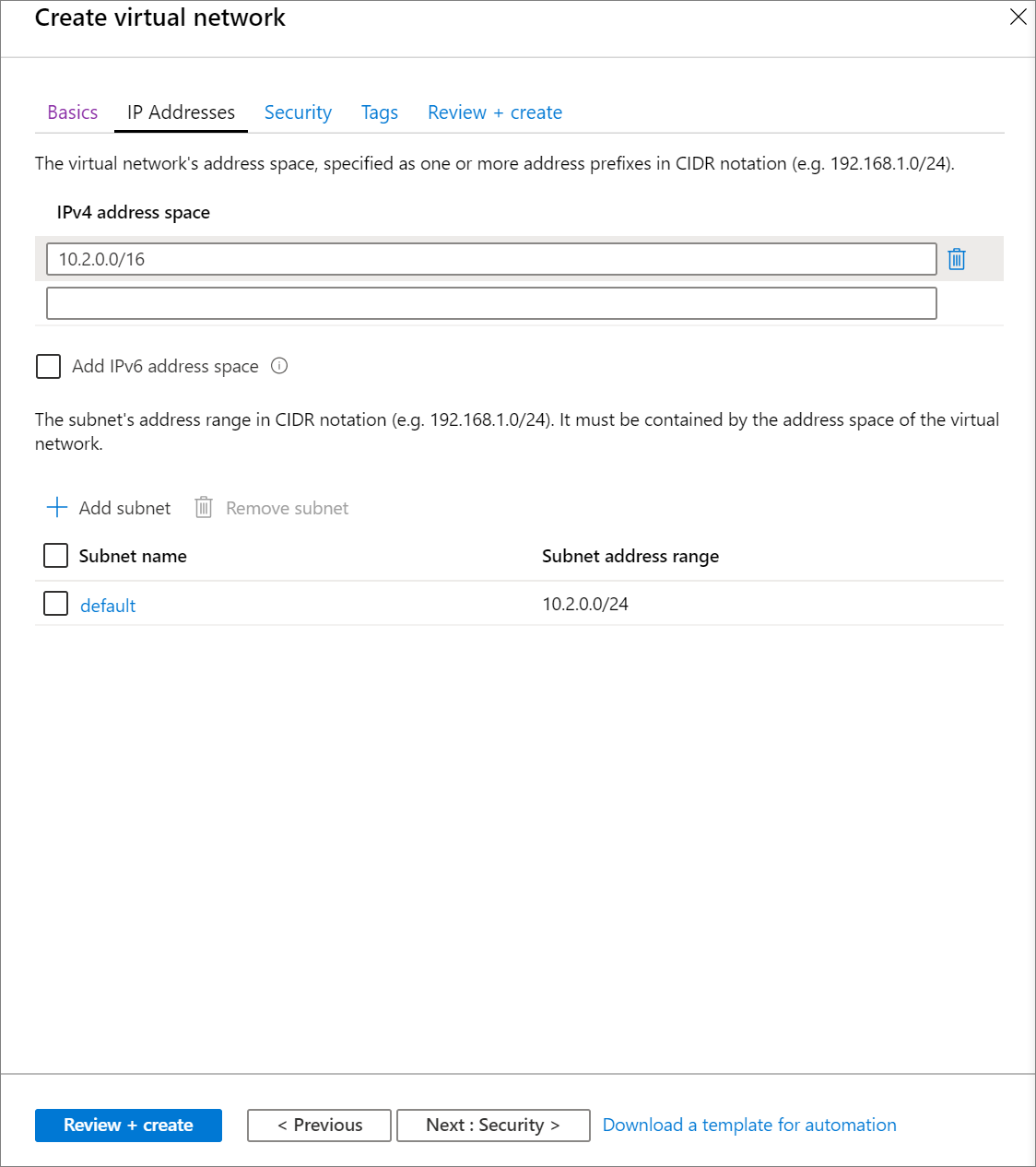
검토 + 만들기 탭에서 만들기를 선택하여 가상 네트워크를 배포합니다. 배포가 완료되면 가상 네트워크로 이동하고 설정 아래에서 주소 공간을 선택합니다. 주소 범위 더 추가라는 상자에서
10.179.0.0/16을 삽입하고, 저장을 선택합니다.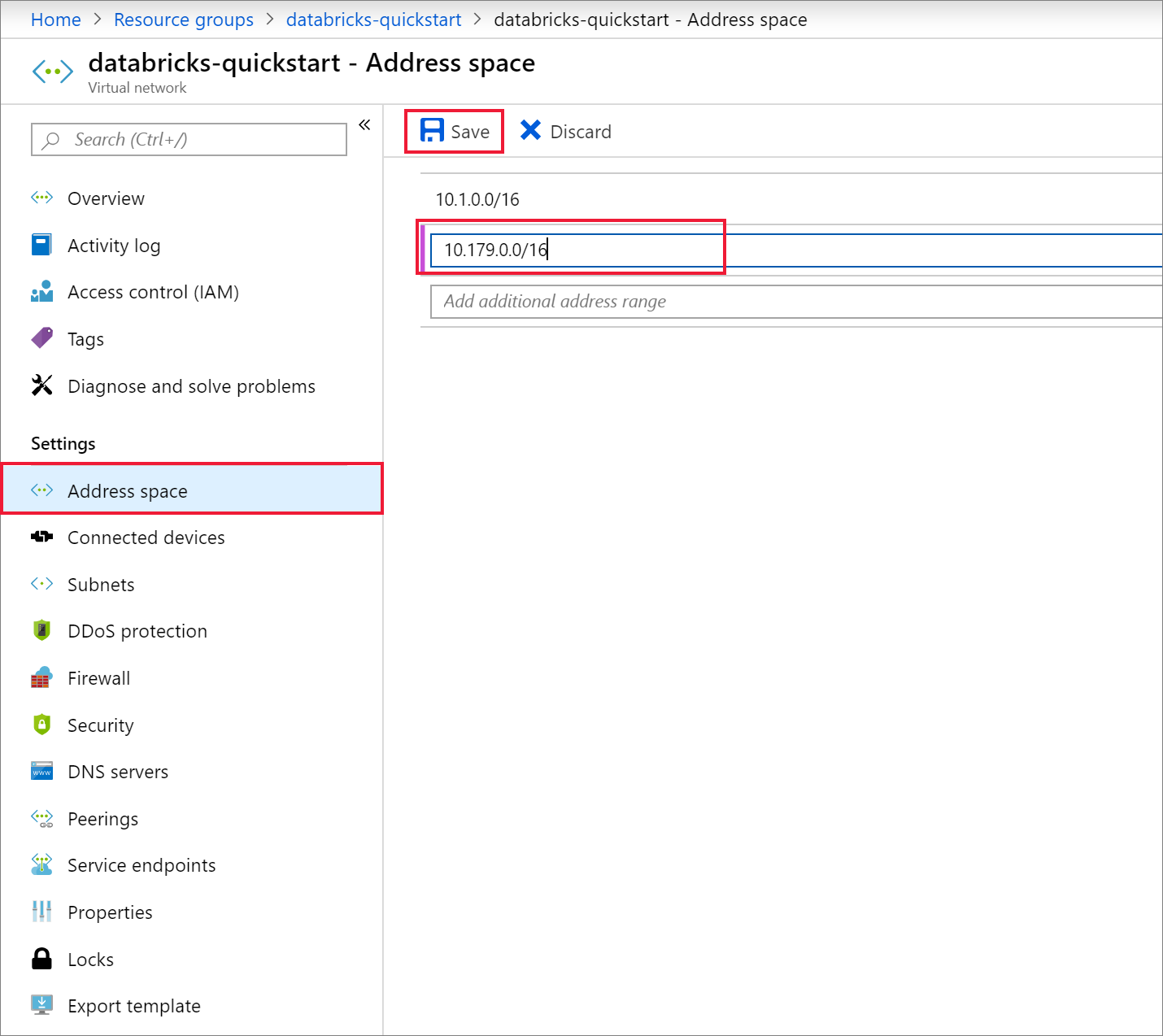
Azure Databricks 작업 영역 만들기
Azure Portal 메뉴에서 리소스 만들기를 선택합니다. 그런 다음 Analytics > Databricks를 선택합니다.
Azure Databricks Service에서 다음 설정을 적용합니다.
설정 제안 값 설명 작업 영역 이름 databricks-quickstart Azure Databricks 작업 영역 이름을 선택합니다. 구독 <구독> 사용할 Azure 구독을 선택합니다. Resource group databricks-quickstart 가상 네트워크에 사용한 것과 동일한 리소스 그룹을 선택합니다. 위치 <사용자와 가장 가까운 지역 선택> 가상 네트워크와 동일한 위치를 선택합니다. 가격 책정 계층 [표준] 또는 [프리미엄] 중에서 선택합니다. 가격 책정 계층에 대한 자세한 내용은 Databricks 가격 책정 페이지를 참조하세요. 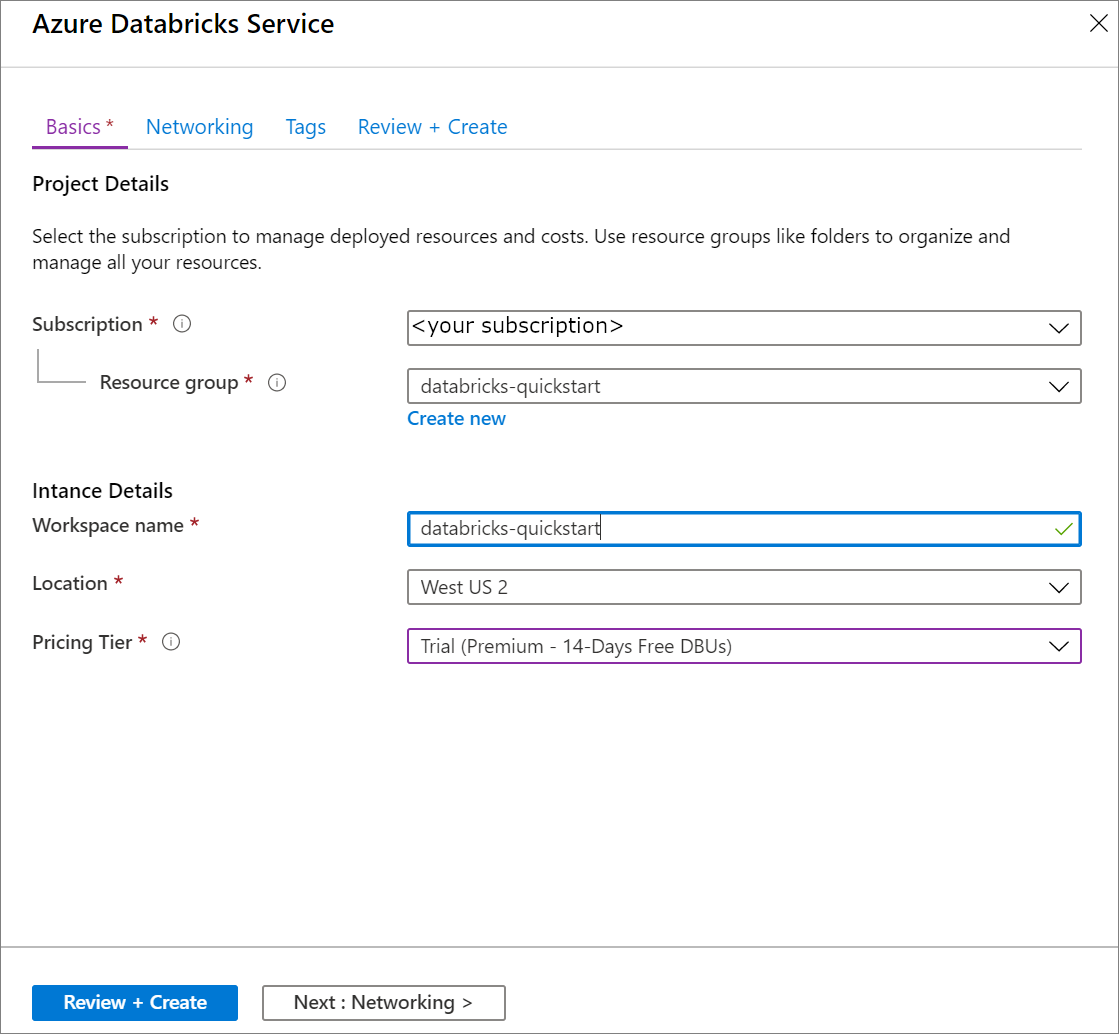
기본 페이지에서 설정 입력이 완료되면 다음: 네트워킹 >을 선택하고 다음 설정을 적용합니다.
설정 제안 값 설명 VNet(Virtual Network)에 Azure Databricks 작업 영역 배포 예 이 설정을 사용하면 가상 네트워크에 Azure Databricks 작업 영역을 배포할 수 있습니다. Virtual Network databricks-quickstart 이전 섹션에서 만든 가상 네트워크를 선택합니다. 퍼블릭 서브넷 이름 public-subnet 기본 공용 서브넷 이름을 사용합니다. 퍼블릭 서브넷 CIDR 범위 10.179.64.0/18 /26까지 CIDR 범위를 사용합니다. 프라이빗 서브넷 이름 private-subnet 기본 프라이빗 서브넷 이름을 사용합니다. 프라이빗 서브넷 CIDR 범위 10.179.0.0/18 /26까지 CIDR 범위를 사용합니다. 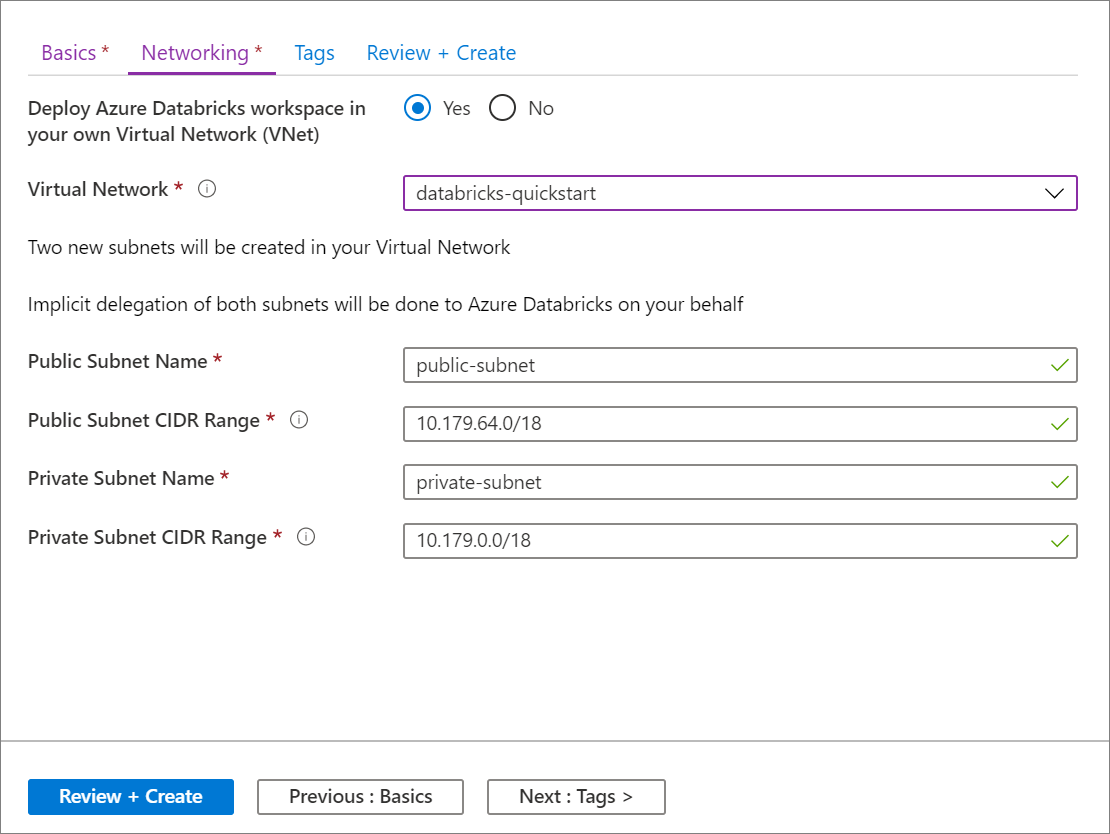
배포가 완료되면 Azure Databricks 리소스로 이동합니다. 가상 네트워크 피어링을 사용할 수 없습니다. 또한 개요 페이지에서 리소스 그룹 및 관리되는 리소스 그룹을 확인합니다.
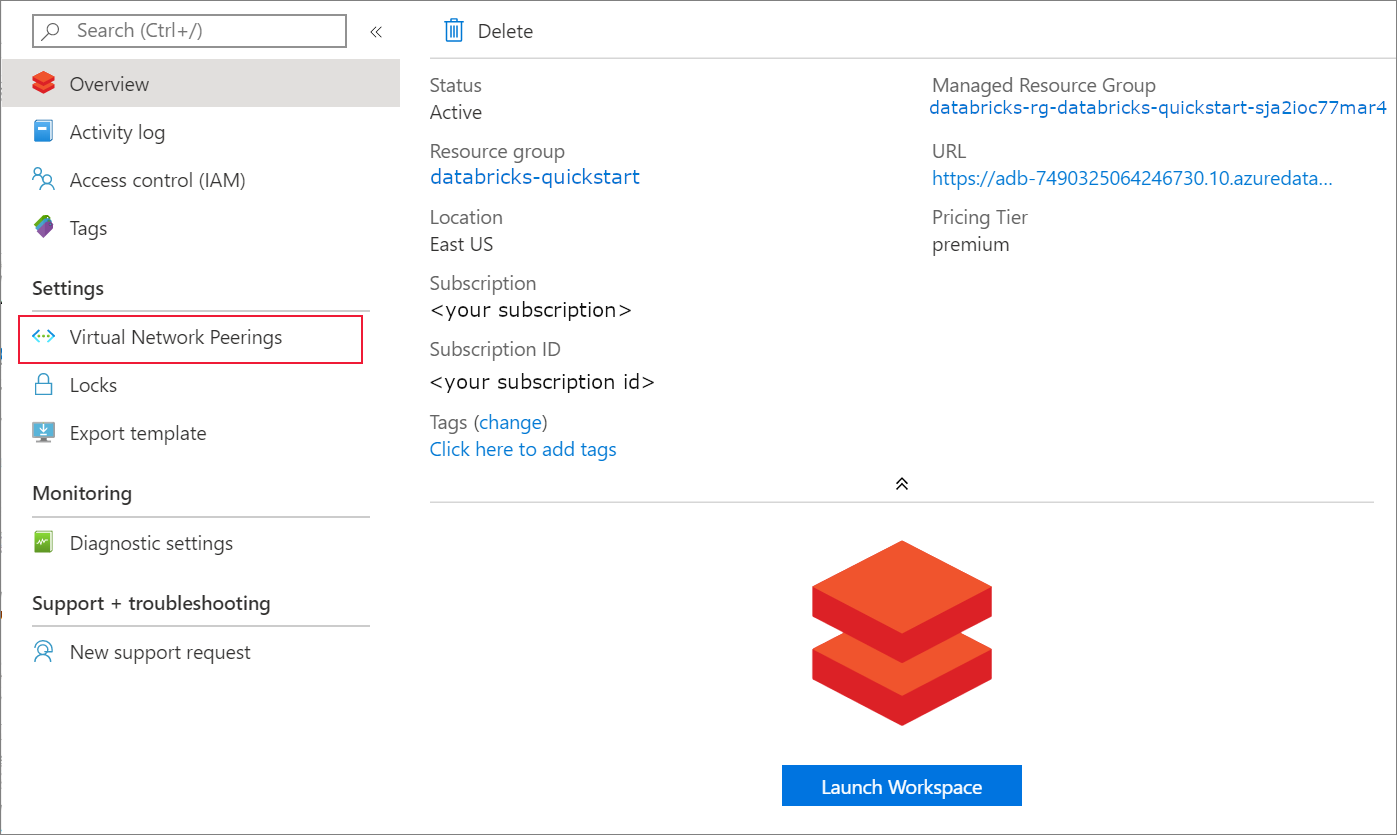
관리되는 리소스 그룹은 수정할 수 없으며 가상 머신을 만드는 데 사용되지 않습니다. 관리하는 리소스 그룹에서만 가상 머신을 만들 수 있습니다.
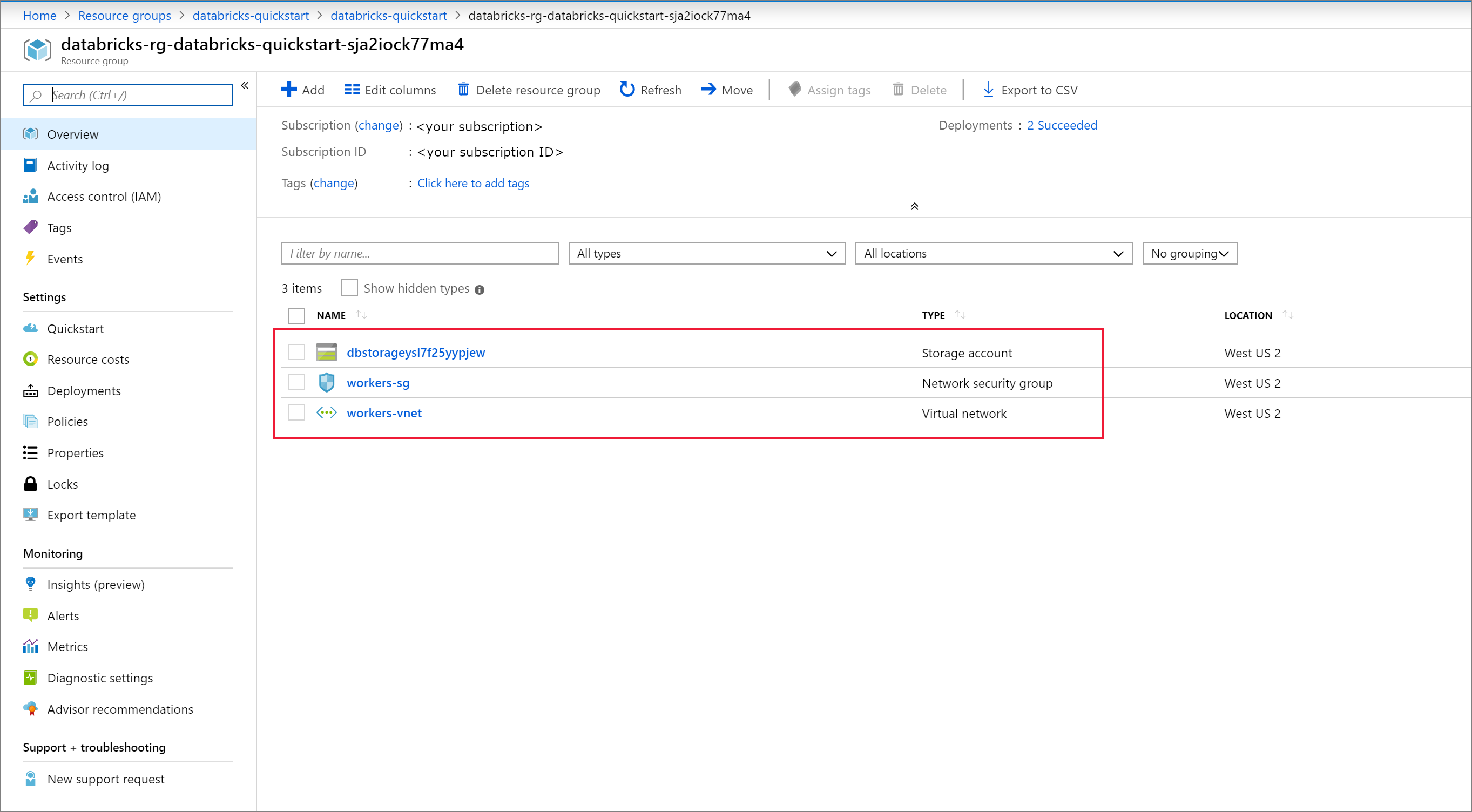
작업 영역 배포가 실패하면 작업 영역은 여전히 실패한 상태로 만들어집니다. 실패한 작업 영역을 삭제하고 배포 오류를 해결하는 새 작업 영역을 만듭니다. 실패한 작업 영역을 삭제하면 관리되는 리소스 그룹 및 성공적으로 배포된 리소스도 삭제됩니다.
클러스터 만들기
참고 항목
무료 계정을 사용하여 Azure Databricks 클러스터를 만들려면 클러스터를 만들기 전에 프로필로 이동하고 구독을 종량제로 변경합니다. 자세한 내용은 Azure 체험 계정을 참조하세요.
Azure Databricks 서비스로 돌아가서 개요 페이지에서 작업 영역 시작을 선택합니다.
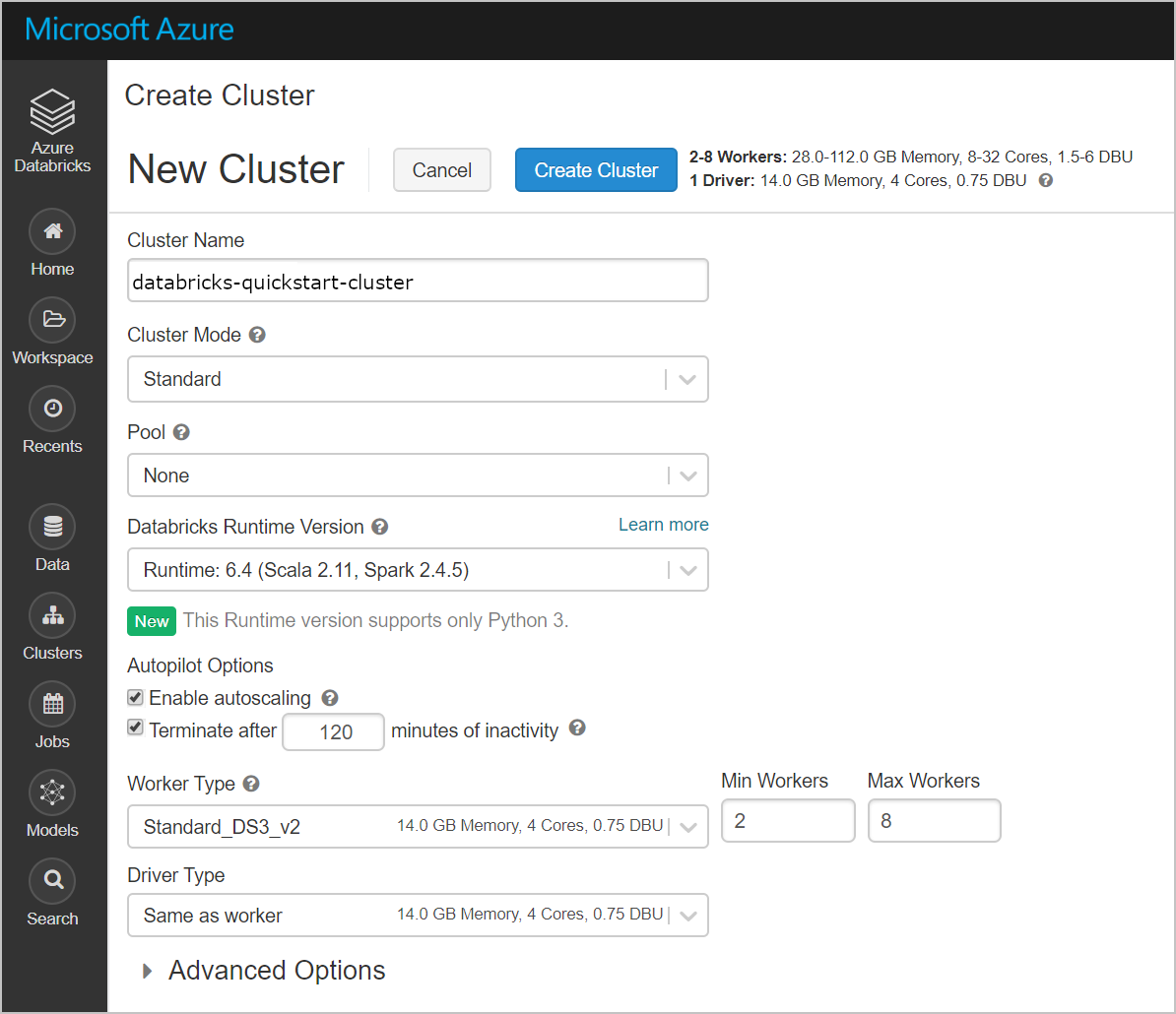
클러스터+ 클러스터 만들기를> 선택합니다. 그런 다음 databricks-quickstart-cluster와 같은 클러스터 이름을 만들고 다시 기본 기본 설정을 적용합니다. 클러스터 만들기를 선택합니다.
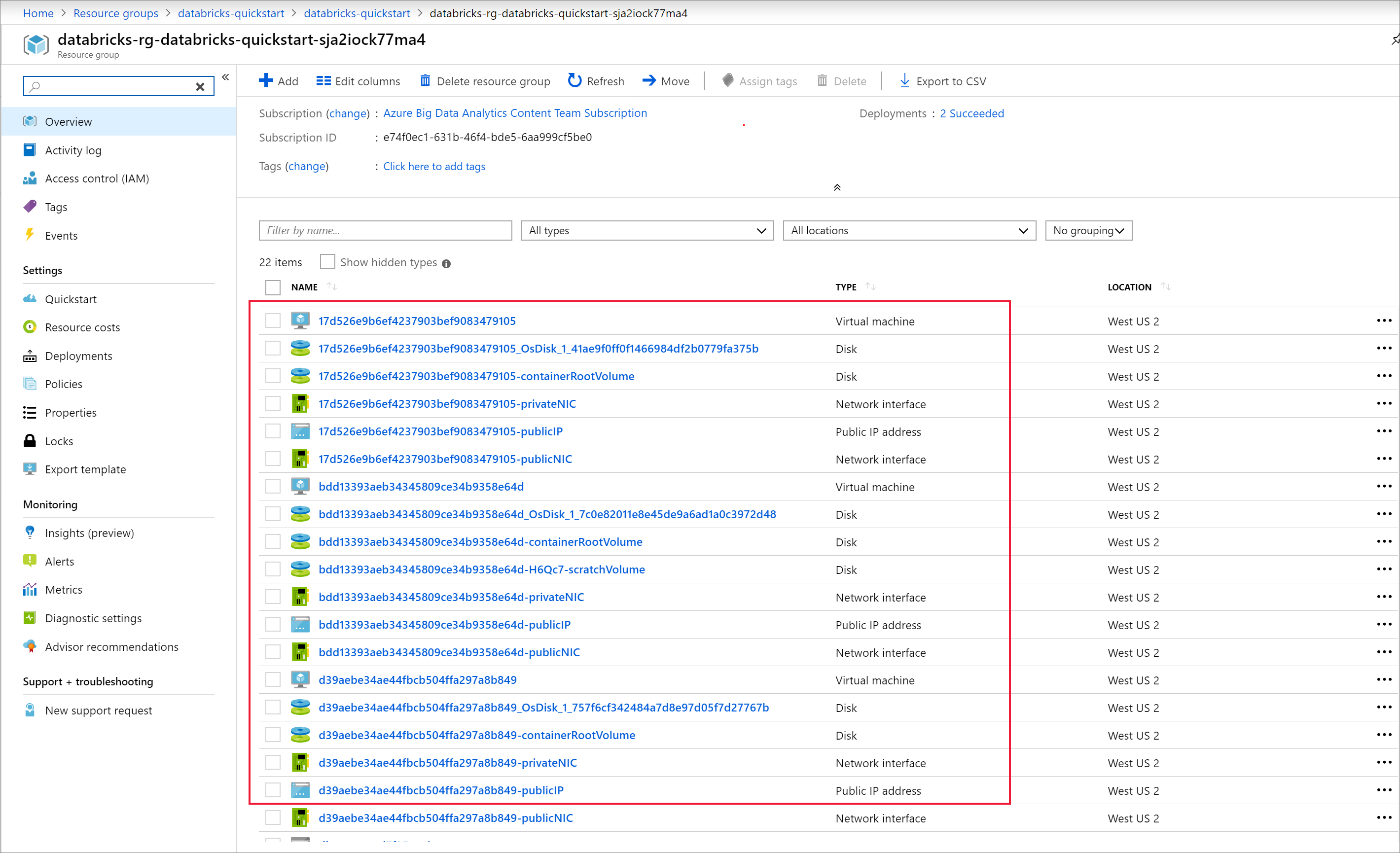
클러스터가 실행되면 Azure Portal에서 관리되는 리소스 그룹으로 돌아갑니다. 새 가상 머신, 디스크, IP 주소 및 네트워크 인터페이스를 확인합니다. IP 주소가 있는 퍼블릭 서브넷 및 프라이빗 서브넷 각각에 네트워크 인터페이스가 만들어집니다.
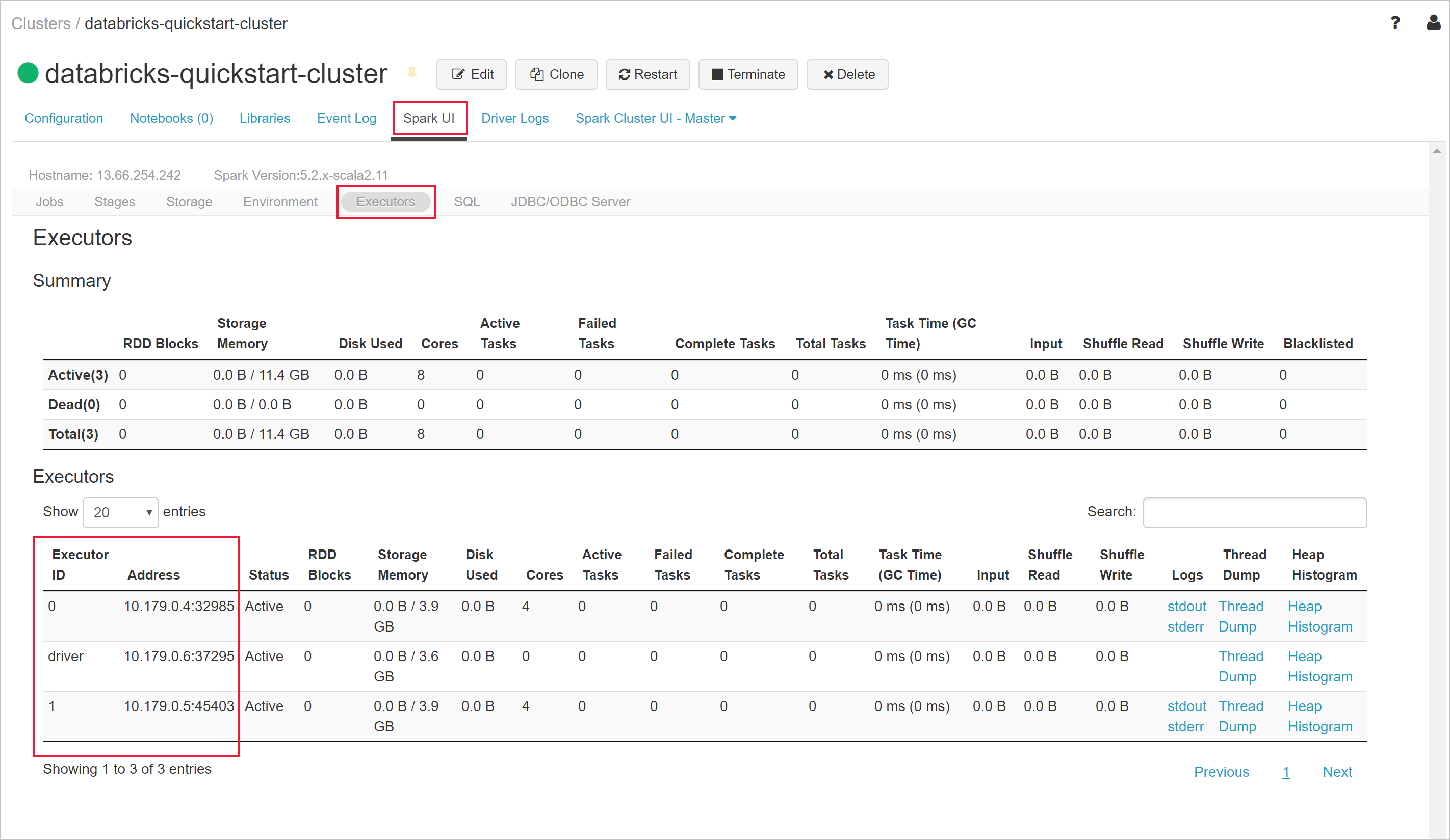
Azure Databricks 작업 영역으로 돌아가서 만든 클러스터를 선택합니다. 그런 다음 Spark UI 페이지의 실행기 탭으로 이동합니다. 드라이버 및 실행기의 주소는 프라이빗 서브넷 범위에 있습니다. 이 예제에서 드라이버는 10.179.0.6이고 실행기는 10.179.0.4 및 10.179.0.5입니다. 이 IP 주소가 다를 수 있습니다.
리소스 정리
문서를 완료한 후 클러스터를 종료할 수 있습니다. 이렇게 하려면 Azure Databricks 작업 영역의 왼쪽 창에서 클러스터를 선택합니다. 종료하려는 클러스터의 경우 동작 열 아래 줄임표 위로 커서를 이동하고 종료 아이콘을 선택합니다. 그러면 클러스터가 중지됩니다.
클러스터를 수동으로 종료하지 않으면 클러스터를 만드는 동안 __minutes의 비활성 검사box 후 종료를 선택한 경우 자동으로 중지됩니다. 이 경우 지정한 시간 동안 클러스터가 비활성 상태이면 클러스터가 자동으로 중지됩니다.
클러스터를 다시 사용하지 않으려면 Azure Portal에서 만든 리소스 그룹을 삭제할 수 있습니다.
다음 단계
이 문서에서는 가상 네트워크에 배포한 Azure Databricks에서 Spark 클러스터를 만들었습니다. 다음 문서로 이동하여 Azure Databricks Notebook에서 JDBC를 사용하여 가상 네트워크의 SQL Server Linux Docker 컨테이너를 쿼리하는 방법을 알아봅니다.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기