자습서: Azure Databricks Notebook에서 가상 네트워크의 SQL Server Linux Docker 컨테이너 쿼리
이 자습서에서는 가상 네트워크의 SQL Server Linux Docker 컨테이너와 Azure Databricks를 통합하는 방법을 설명합니다.
이 자습서에서는 다음 작업 방법을 알아봅니다.
- 가상 네트워크에 Azure Databricks 작업 영역 배포
- 공용 네트워크에 Linux 가상 머신 설치
- Docker 설치
- Microsoft SQL Server on Linux docker 컨테이너 설치
- Databricks Notebook에서 JDBC를 사용하여 SQL Server 쿼리
사전 요구 사항
Linux 가상 머신 만들기
Azure Portal Virtual Machines 아이콘을 선택합니다. 그런 다음 , + 추가를 선택합니다.
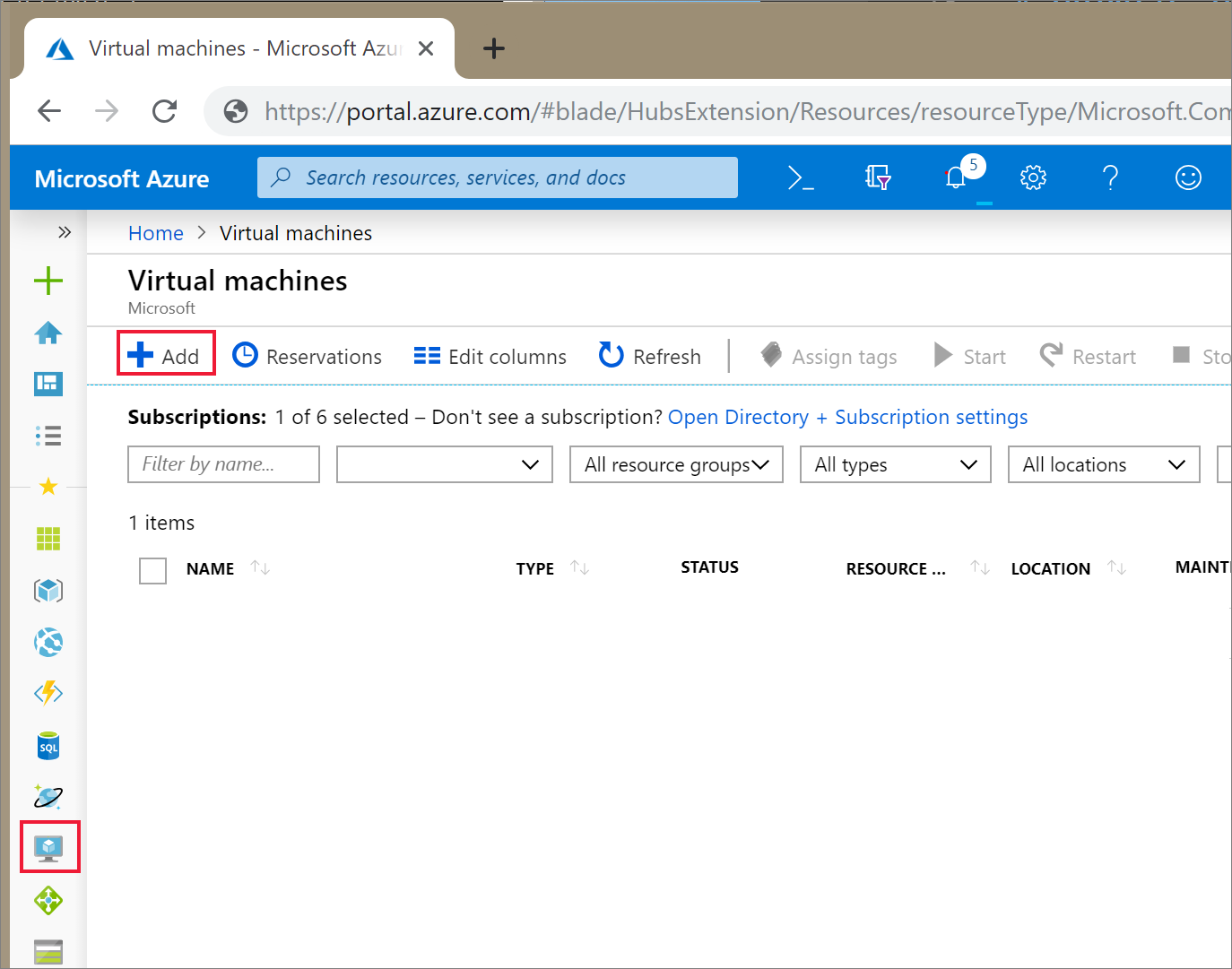
기본 탭에서 Ubuntu Server 18.04 LTS를 선택하고 VM 크기를 B2s로 변경합니다. 관리자 사용자 이름 및 암호를 선택합니다.
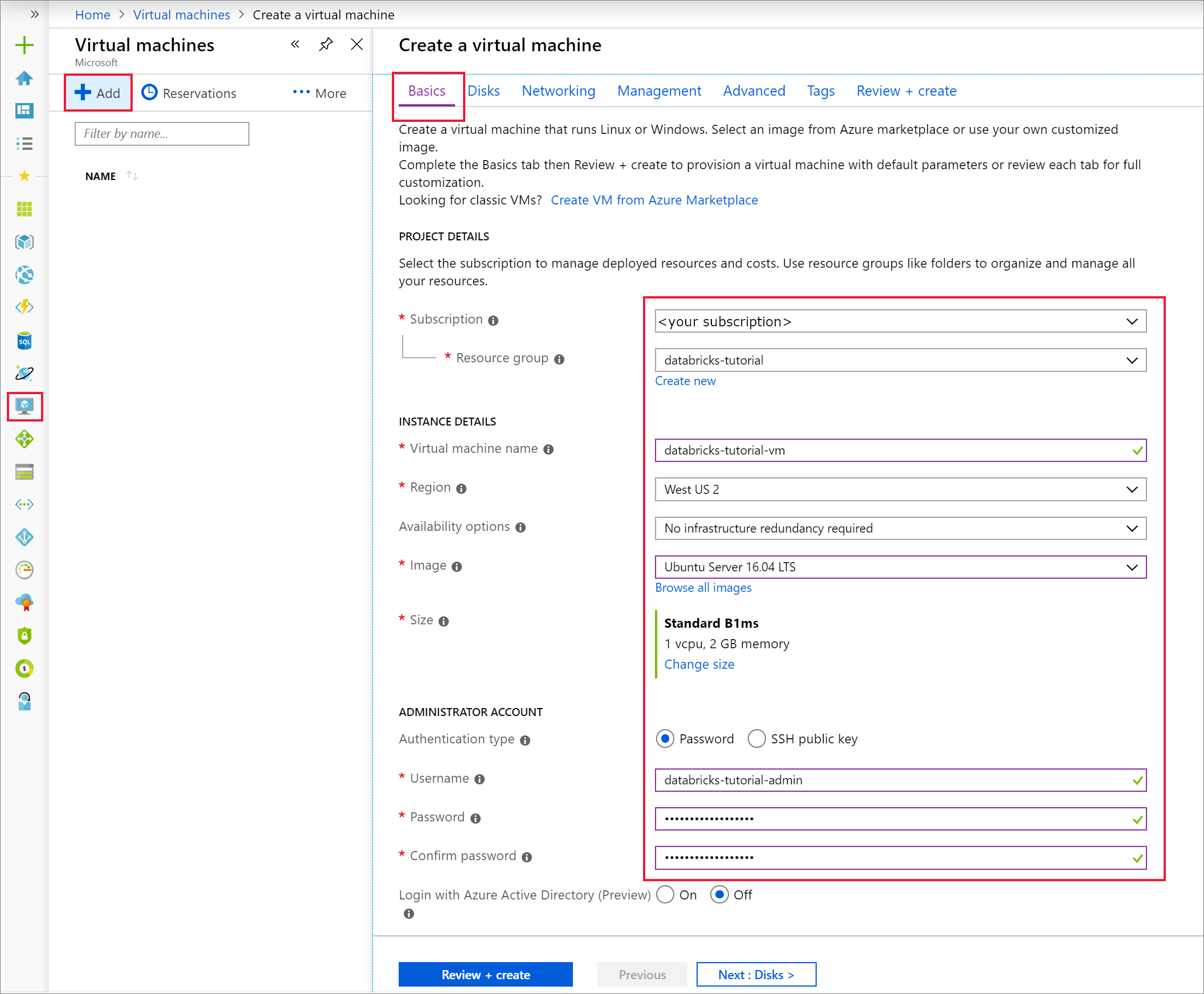
네트워킹 탭으로 이동합니다. Azure Databricks 클러스터를 포함하는 가상 네트워크 및 공용 서브넷을 선택합니다. 검토 + 만들기를 선택한 다음, 만들기를 선택하여 가상 머신을 배포합니다.
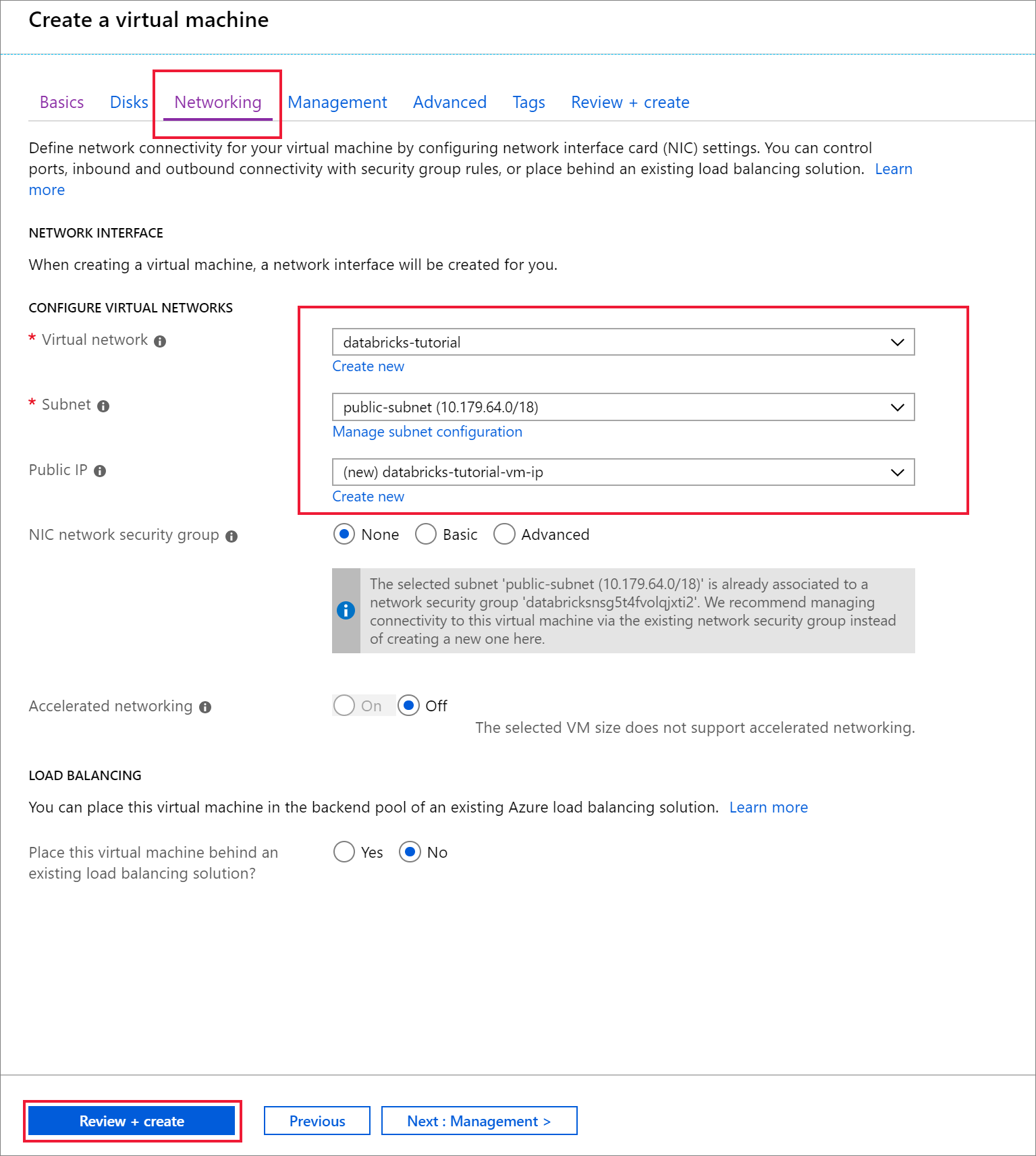
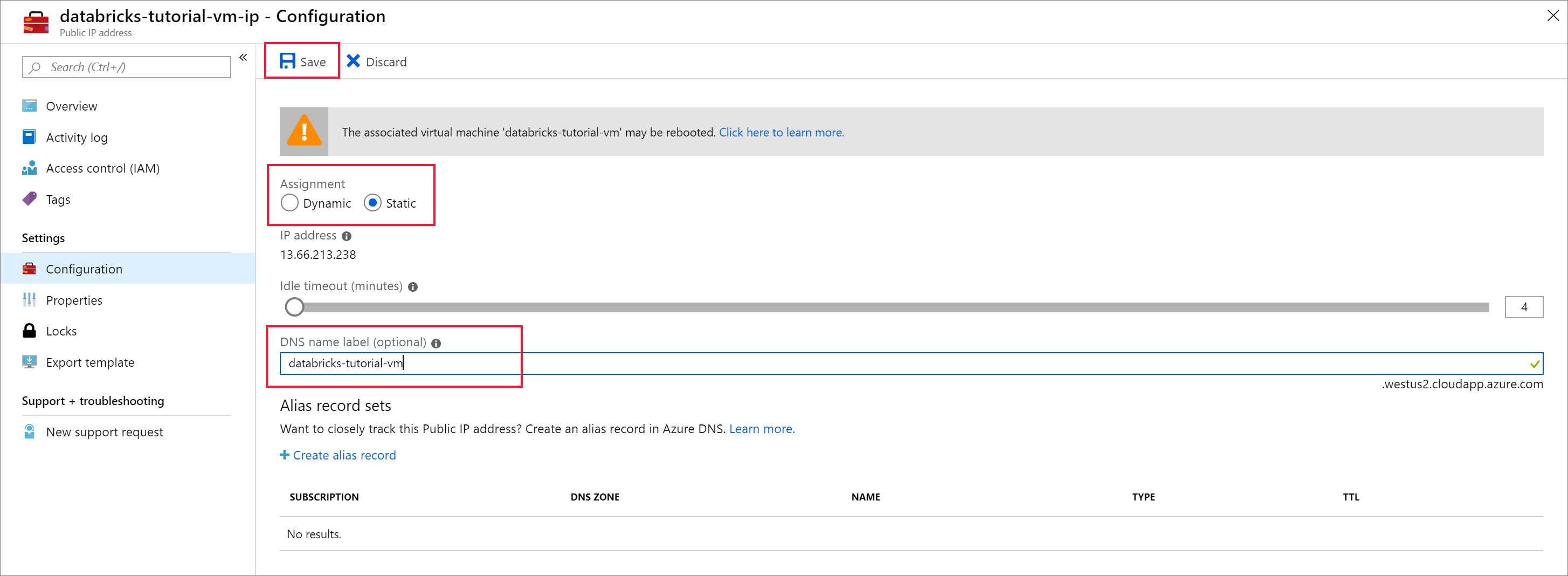
배포가 완료되면 가상 머신으로 이동합니다. 개요에서 공용 IP 주소 및 가상 네트워크/서브넷을 확인 합니다. 공용 IP 주소 선택
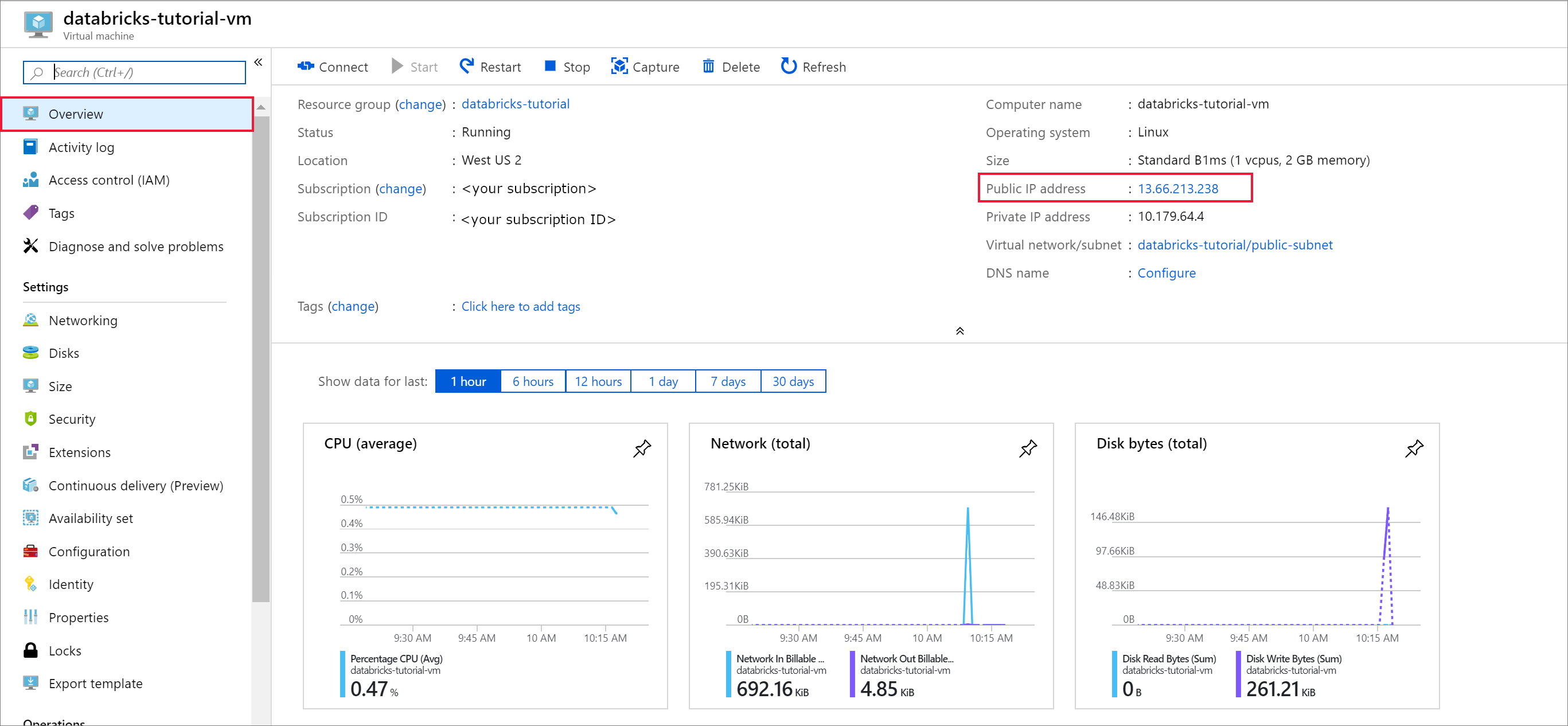
할당을 정적으로 변경하고 DNS 이름 레이블을 입력합니다. 저장을 선택하고 가상 머신을 다시 시작합니다.
설정에서 네트워킹 탭을 선택합니다. Azure Databricks 배포 중에 생성된 네트워크 보안 그룹은 가상 머신과 연결됩니다. 인바운드 포트 규칙 추가를 선택합니다.
SSH용 포트 22를 여는 규칙을 추가합니다. 다음 설정을 사용합니다.
설정 제안 값 Description 원본 IP 주소 IP 주소는 특정 원본 IP 주소에서 들어오는 트래픽이 이 규칙에 의해 허용되거나 거부되도록 지정합니다. 원본 IP 주소 <공용 IP> 공용 IP 주소를 입력합니다. bing.com 방문하여 "내 IP"를 검색하여 공용 IP 주소를 찾을 수 있습니다. 원본 포트 범위 * 모든 포트에서 트래픽을 허용합니다. 대상 IP 주소 IP 주소는 특정 원본 IP 주소에 대한 나가는 트래픽이 이 규칙에 의해 허용되거나 거부되도록 지정합니다. 대상 IP 주소 <vm 공용 IP> 가상 머신의 공용 IP 주소를 입력합니다. 가상 머신의 개요 페이지에서 찾을 수 있습니다. 대상 포트 범위 22 SSH용 포트 22를 엽니다. 우선 순위 290 규칙의 우선 순위를 지정합니다. Name ssh-databricks-tutorial-vm 규칙에 이름을 지정합니다. 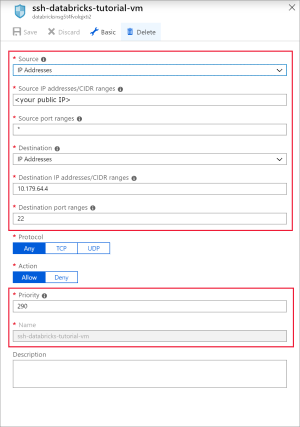
다음 설정을 사용하여 SQL용 포트 1433을 여는 규칙을 추가합니다.
설정 제안 값 Description 원본 모두 원본은 특정 원본 IP 주소에서 들어오는 트래픽이 이 규칙에 의해 허용되거나 거부되도록 지정합니다. 원본 포트 범위 * 모든 포트에서 트래픽을 허용합니다. 대상 IP 주소 IP 주소는 특정 원본 IP 주소에 대한 나가는 트래픽이 이 규칙에 의해 허용되거나 거부되도록 지정합니다. 대상 IP 주소 <vm 공용 IP> 가상 머신의 공용 IP 주소를 입력합니다. 가상 머신의 개요 페이지에서 찾을 수 있습니다. 대상 포트 범위 1433 SQL Server 포트 22를 엽니다. 우선 순위 300 규칙의 우선 순위를 지정합니다. Name sql-databricks-tutorial-vm 규칙에 이름을 지정합니다. 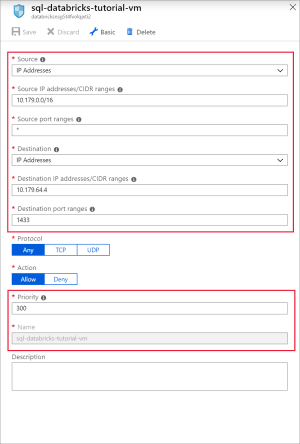
Docker 컨테이너에서 SQL Server 실행
Windows용 Ubuntu를 열거나 가상 머신에 SSH할 수 있는 다른 도구를 엽니다. Azure Portal 가상 머신으로 이동하고 연결을 선택하여 연결해야 하는 SSH 명령을 가져옵니다.

Ubuntu 터미널에서 명령을 입력하고 가상 머신을 구성할 때 만든 관리자 암호를 입력합니다.
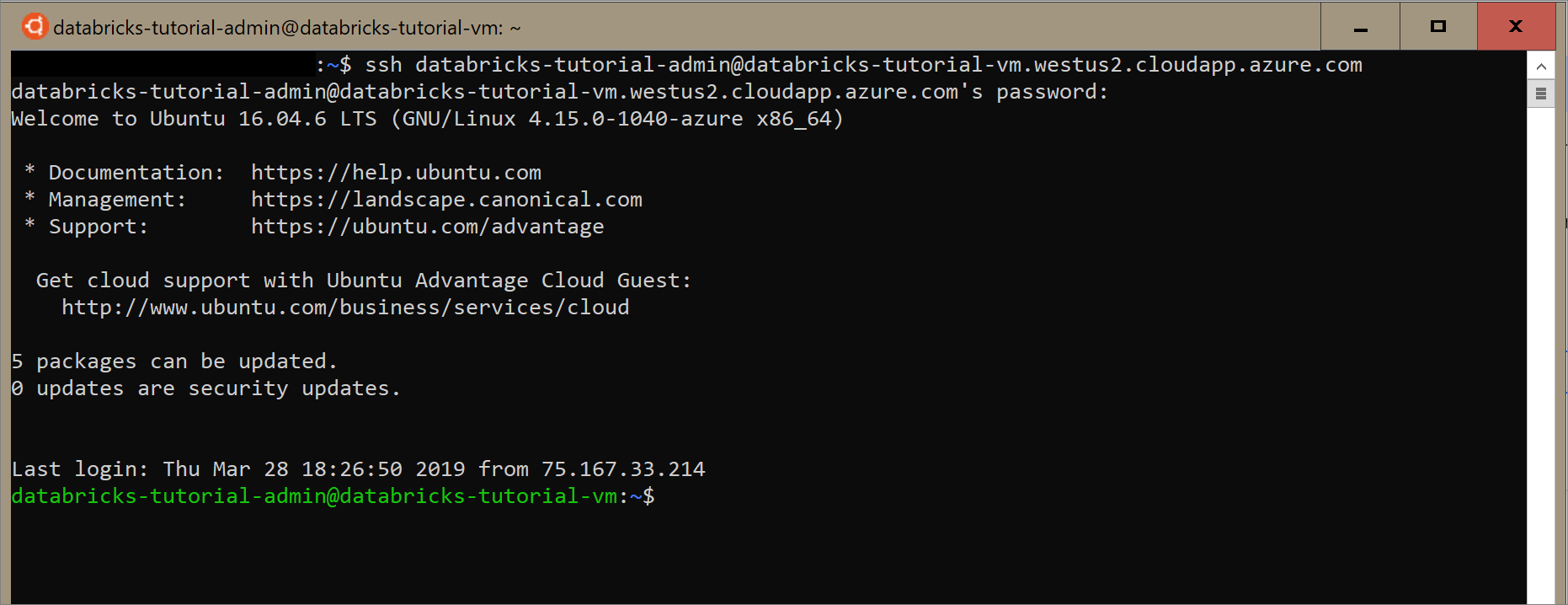
다음 명령을 사용하여 가상 머신에 Docker를 설치합니다.
sudo apt-get install docker.io다음 명령을 사용하여 Docker 설치를 확인합니다.
sudo docker --version이미지를 설치합니다.
sudo docker pull mcr.microsoft.com/mssql/server:2017-latest이미지를 확인합니다.
sudo docker images이미지에서 컨테이너를 실행합니다.
sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Password1234' -p 1433:1433 --name sql1 -d mcr.microsoft.com/mssql/server:2017-latest컨테이너가 실행 중인지 확인합니다.
sudo docker ps -a
SQL 데이터베이스 만들기
SQL Server Management Studio 열고 서버 이름 및 SQL 인증을 사용하여 서버에 연결합니다. 로그인 사용자 이름은 SA 이고 암호는 Docker 명령에 설정된 암호입니다. 예제 명령의 암호는 입니다
Password1234.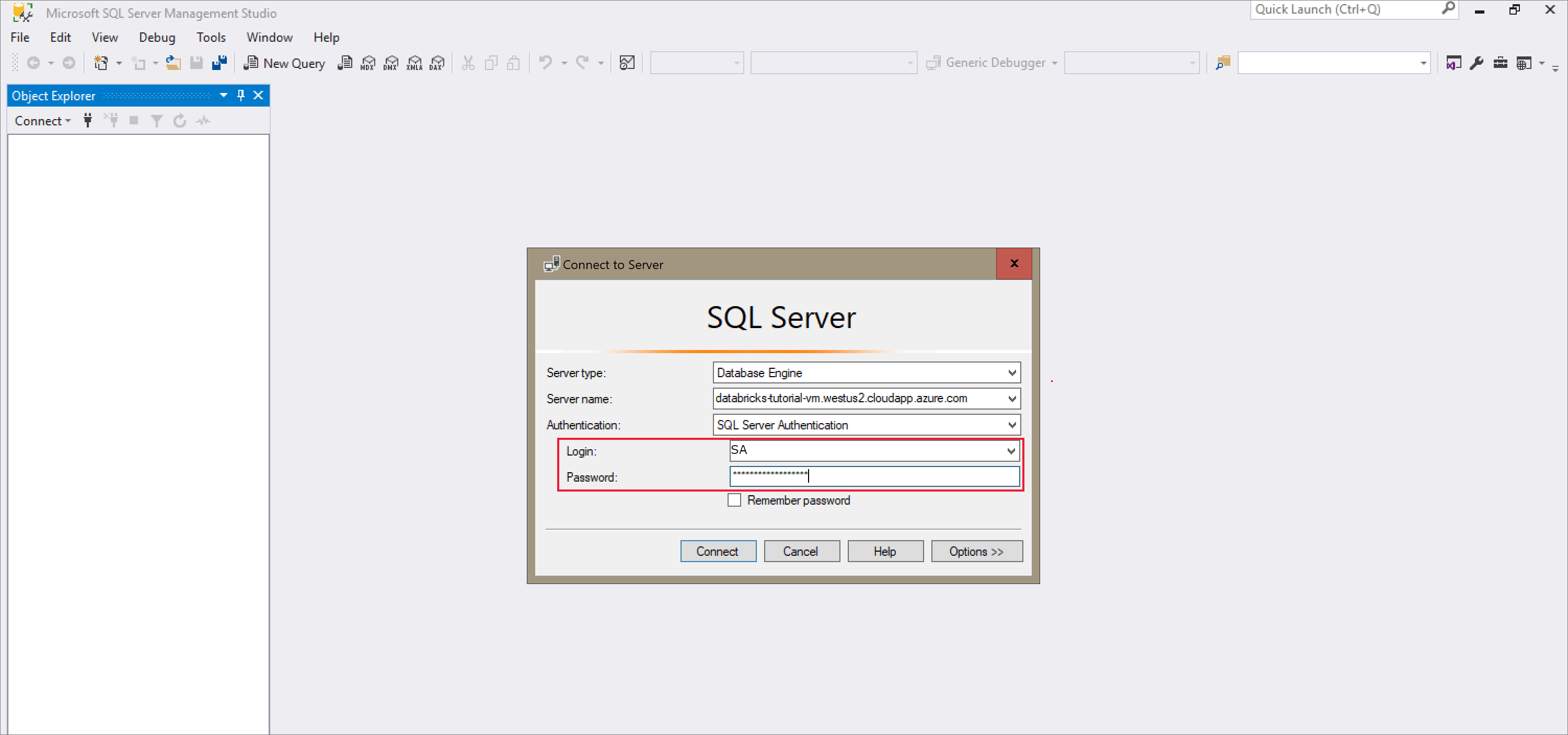
성공적으로 연결되면 새 쿼리 를 선택하고 다음 코드 조각을 입력하여 데이터베이스, 테이블을 만들고 테이블에 일부 레코드를 삽입합니다.
CREATE DATABASE MYDB; GO USE MYDB; CREATE TABLE states(Name VARCHAR(20), Capitol VARCHAR(20)); INSERT INTO states VALUES ('Delaware','Dover'); INSERT INTO states VALUES ('South Carolina','Columbia'); INSERT INTO states VALUES ('Texas','Austin'); SELECT * FROM states GO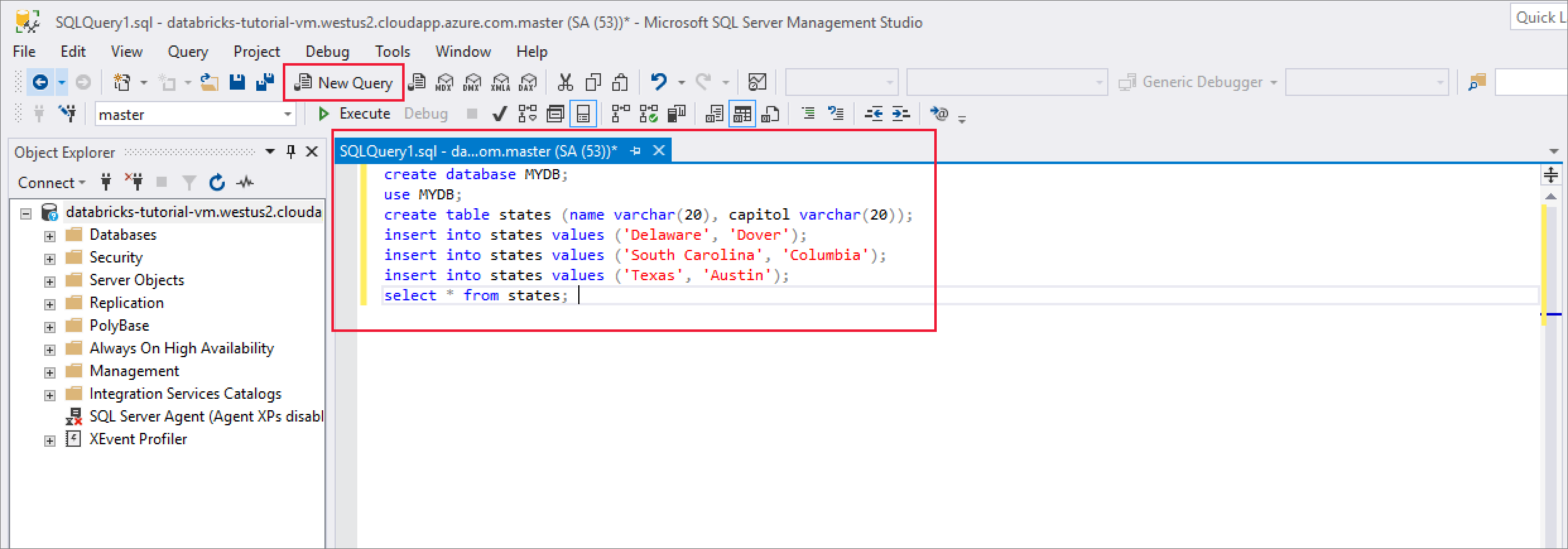
Azure Databricks에서 SQL Server 쿼리
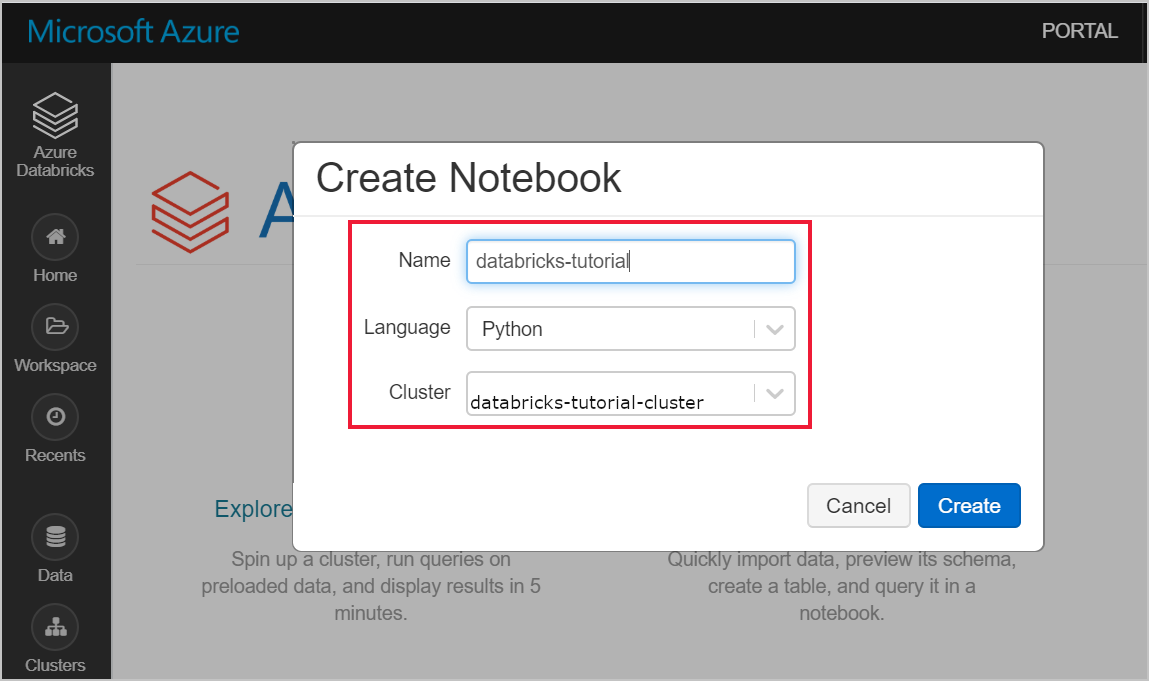
Azure Databricks 작업 영역으로 이동하여 필수 구성 요소의 일부로 클러스터를 생성했는지 확인합니다. 그런 다음 전자 필기장 만들기를 선택합니다. Notebook에 이름을 지정하고 Python 을 언어로 선택한 다음, 만든 클러스터를 선택합니다.
다음 명령을 사용하여 SQL Server 가상 머신의 내부 IP 주소를 ping합니다. 이 ping은 성공해야 합니다. 그렇지 않은 경우 컨테이너가 실행 중인지 확인하고 NSG(네트워크 보안 그룹) 구성을 검토합니다.
%sh ping 10.179.64.4nslookup 명령을 사용하여 검토할 수도 있습니다.
%sh nslookup databricks-tutorial-vm.westus2.cloudapp.azure.comSQL Server 성공적으로 ping했으면 데이터베이스와 테이블을 쿼리할 수 있습니다. 다음 Python 코드를 실행합니다.
jdbcHostname = "10.179.64.4" jdbcDatabase = "MYDB" userName = 'SA' password = 'Password1234' jdbcPort = 1433 jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, userName, password) df = spark.read.jdbc(url=jdbcUrl, table='states') display(df)
리소스 정리
더 이상 필요하지 않은 경우 리소스 그룹, Azure Databricks 작업 영역 및 모든 관련 리소스를 삭제합니다. 작업을 삭제하면 불필요한 청구가 방지됩니다. 나중에 Azure Databricks 작업 영역을 사용하려는 경우 클러스터를 중지하고 나중에 다시 시작할 수 있습니다. 이 Azure Databricks 작업 영역을 계속 사용하지 않려면 다음 단계를 사용하여 이 자습서에서 만든 모든 리소스를 삭제합니다.
Azure Portal 왼쪽 메뉴에서 리소스 그룹을 클릭한 다음 만든 리소스 그룹의 이름을 클릭합니다.
리소스 그룹 페이지에서 삭제를 선택하고 텍스트 상자에 삭제할 리소스의 이름을 입력한 다음 삭제 를 다시 선택합니다.
다음 단계
다음 문서로 이동하여 Azure Databricks를 사용하여 데이터를 추출, 변환 및 로드하는 방법을 알아봅니다.