Azure Databricks에서 제공하는 레거시 MLflow 모델
Important
이 기능은 공개 미리 보기 상태입니다.
Important
- 이 설명서는 사용 중지되었으며 업데이트되지 않을 수 있습니다. 이 콘텐츠에 언급된 제품, 서비스 또는 기술은 더 이상 지원되지 않습니다.
- 이 문서의 지침은 레거시 MLflow 모델 서비스용입니다. Databricks는 향상된 모델 엔드포인트 배포 및 확장성을 위해 워크플로를 제공하는 모델을 모델 서비스로 마이그레이션하는 것이 좋습니다. 자세한 내용은 Azure Databricks에서 제공하는 모델을 참조 하세요.
레거시 MLflow 모델 서비스를 사용하면 모델 버전 및 해당 단계의 가용성에 따라 자동으로 업데이트되는 REST 엔드포인트로 모델 레지스트리의 기계 학습 모델을 호스트할 수 있습니다. 현재 클래식 컴퓨팅 평면이라고 하는 자체 계정으로 실행되는 단일 노드 클러스터를 사용합니다. 이 컴퓨팅 평면에는 가상 네트워크 및 관련 컴퓨팅 리소스(예: Notebook 및 작업용 클러스터, pro 및 클래식 SQL 웨어하우스, 엔드포인트를 제공하는 레거시 모델)가 포함됩니다.
지정된 등록된 모델에 대해 모델 서비스를 사용하도록 설정하면 Azure Databricks는 모델에 대한 고유 클러스터를 자동으로 만들고 해당 클러스터에 보관되지 않은 모든 버전의 모델을 배포합니다. Azure Databricks는 오류가 발생하면 클러스터를 다시 시작하고, 모델에 대해 모델 서비스를 사용하지 않도록 설정한 경우 클러스터를 종료합니다. 모델 서비스는 모델 레지스트리와 자동으로 동기화되고 등록된 모든 새 모델 버전을 배포합니다. 배포된 모델 버전은 표준 REST API 요청으로 쿼리할 수 있습니다. Azure Databricks는 표준 인증을 사용하여 모델에 대한 요청을 인증합니다.
이 서비스가 미리 보기 상태에 있는 동안에는 처리량이 낮고 중요하지 않은 애플리케이션에 사용하는 것이 좋습니다. 대상 처리량은 200qps이고 대상 가용성은 99.5%이지만 어느 쪽도 보장할 수 없습니다. 또한 요청당 16MB의 페이로드 크기 제한이 있습니다.
각 모델 버전은 MLflow 모델 배포를 사용하여 배포되고 해당 종속성에 지정된 Conda 환경에서 실행됩니다.
참고 항목
- 활성 모델 버전이 없더라도 서비스를 사용하도록 설정되어 있으면 클러스터가 유지됩니다. 서비스 클러스터를 종료하려면 등록된 모델에 대한 모델 서비스를 사용하지 않도록 설정합니다.
- 클러스터는 다목적 워크로드 가격 책정에 따라 다목적 클러스터로 간주됩니다.
- 전역 init 스크립트는 클러스터를 제공하는 모델에서 실행되지 않습니다.
Important
Anaconda Inc.는 anaconda.org 채널에 대한 서비스 약관을 업데이트했습니다. 새로운 서비스 약관에 따라 Anaconda의 패키지 및 배포에 의존하는 경우 상용 라이선스가 필요할 수 있습니다. 자세한 내용은 Anaconda Commercial Edition FAQ를 참조하세요. Anaconda 채널의 사용은 해당 서비스 약관에 따라 관리됩니다.
v1.18 이전에 기록된 MLflow 모델(Databricks Runtime 8.3 ML 이하)은 기본적으로 conda defaults 채널(https://repo.anaconda.com/pkgs/)을 종속성으로 로깅했습니다. 이 라이선스 변경으로 인해 Databricks는 MLflow v1.18 이상을 사용하여 기록된 모델에 대한 채널 defaults 사용을 중지했습니다. 로깅된 기본 채널은 이제 conda-forge(으)로, 관리되는 커뮤니티 https://conda-forge.org/를 가리킵니다.
모델에 대한 conda 환경에서 defaults 채널을 제외하지 않고 MLflow v1.18 이전 모델을 로깅한 경우 해당 모델은 의도하지 않았을 수 있는 defaults 채널에 대한 종속성을 가질 수 있습니다.
모델에 이 종속성이 있는지 여부를 수동으로 확인하려면 기록된 모델로 패키지된 conda.yaml 파일의 channel 값을 검사할 수 있습니다. 예를 들어 defaults 채널 종속성이 있는 모델의 conda.yaml 모양은 다음과 같습니다.
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricks는 Anaconda와의 관계에서 Anaconda 리포지토리를 사용하여 모델과 상호 작용하는 것이 허용되는지 여부를 확인할 수 없으므로 Databricks는 고객이 변경하도록 강요하지 않습니다. Databricks 사용을 통한 Anaconda.com 리포지토리 사용이 Anaconda의 조건에 따라 허용되는 경우 어떠한 조치도 취할 필요가 없습니다.
모델 환경에서 사용되는 채널을 변경하려는 경우 새 conda.yaml을(를) 사용하여 모델 레지스트리에 모델을 다시 등록할 수 있습니다. log_model()의 conda_env 매개 변수에 채널을 지정하여 이 작업을 수행할 수 있습니다.
log_model() API에 대한 자세한 내용은 작업 중인 모델 버전에 대한 MLflow 설명서(예: scikit-learn용 log_model)를 참조하세요.
conda.yaml 파일에 대한 자세한 내용은 MLflow 설명서를 참조하세요.
요구 사항
- 레거시 MLflow 모델 제공은 Python MLflow 모델에 사용할 수 있습니다. conda 환경에서 모든 모델 종속성을 선언해야 합니다. 로그 모델 종속성을 참조하세요.
- 모델 서비스를 사용하도록 설정하려면 클러스터 만들기 권한이 있어야 합니다.
모델 레지스트리의 모델 서비스
모델 서비스는 모델 레지스트리의 Azure Databricks에서 사용할 수 있습니다.
모델 서비스를 사용 및 사용하지 않도록 설정
등록된 모델 페이지에서 서비스할 모델을 사용하도록 설정합니다.
Serving(서비스) 탭을 클릭합니다. 모델이 서비스를 사용하도록 아직 설정되지 않은 경우 Enable Serving(서비스 사용) 단추가 표시됩니다.
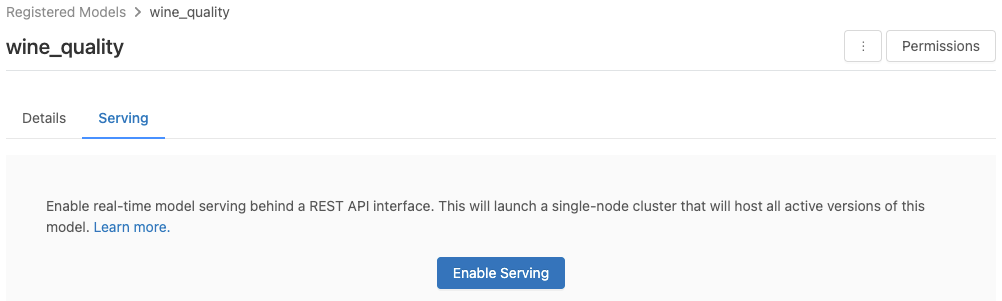
Enable Serving(서비스 사용)을 클릭합니다. Serving(서비스) 탭에 상태가 보류 중으로 표시됩니다. 몇 분 후 상태가 준비로 변경됩니다.
서비스할 모델을 사용하지 않도록 설정하려면 중지를 클릭합니다.
모델 서비스의 유효성 검사
Serving(서비스) 탭에서 서비스를 제공한 모델에 요청을 보내고 응답을 볼 수 있습니다.
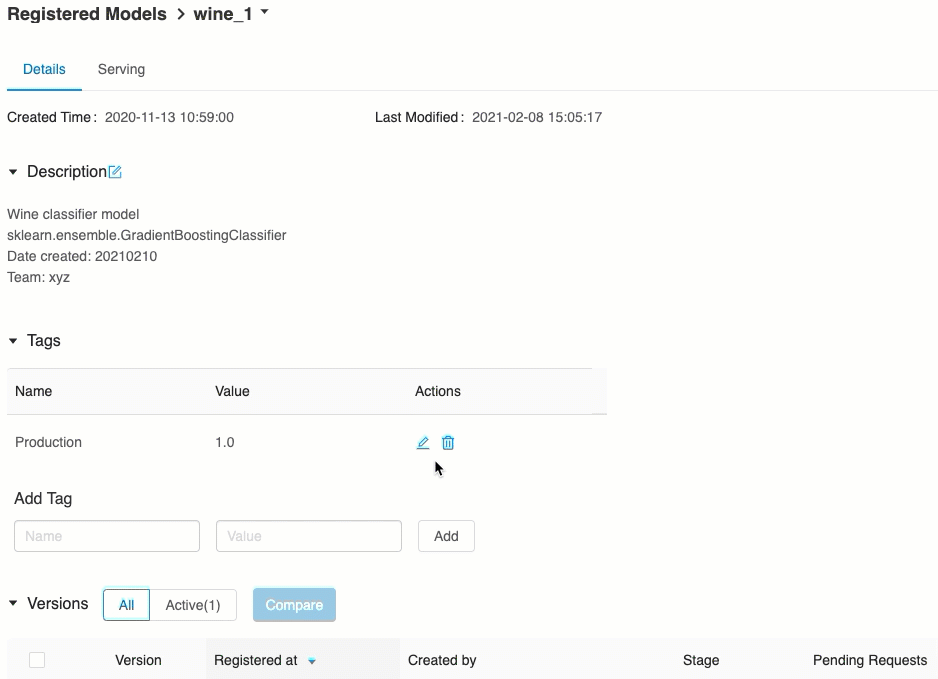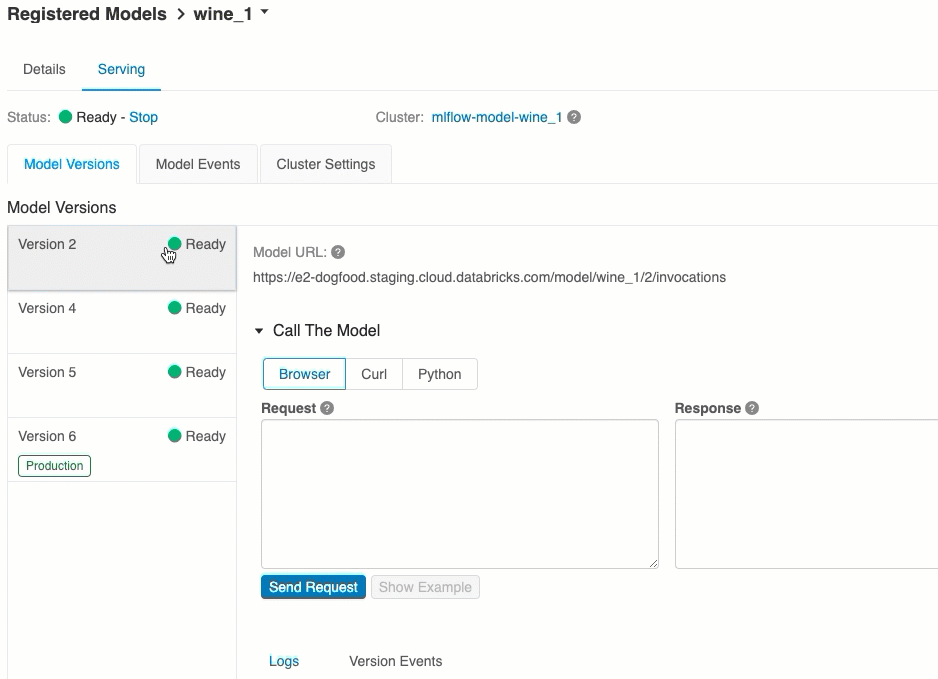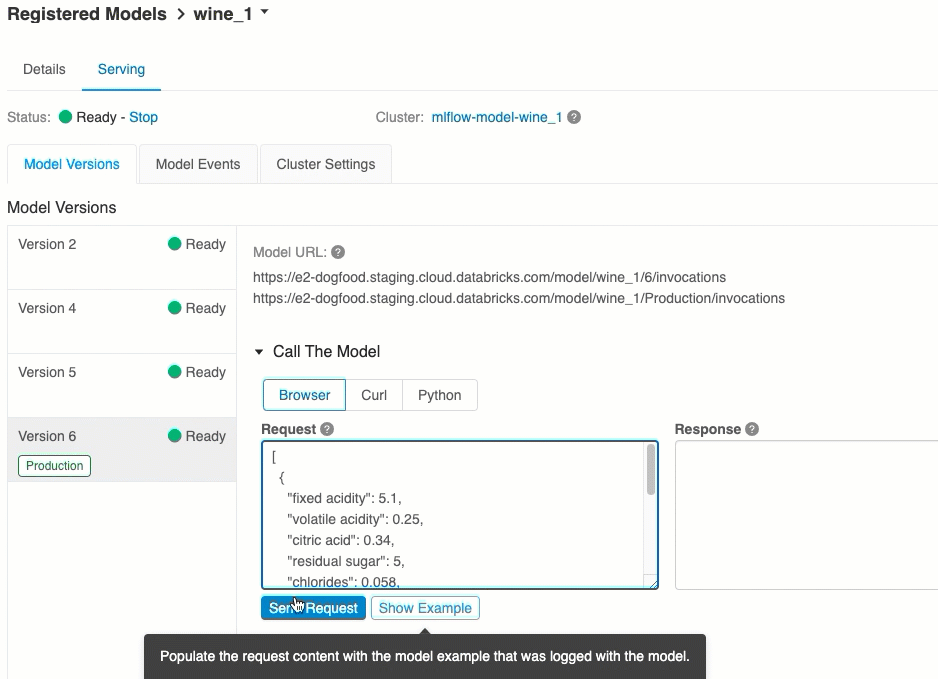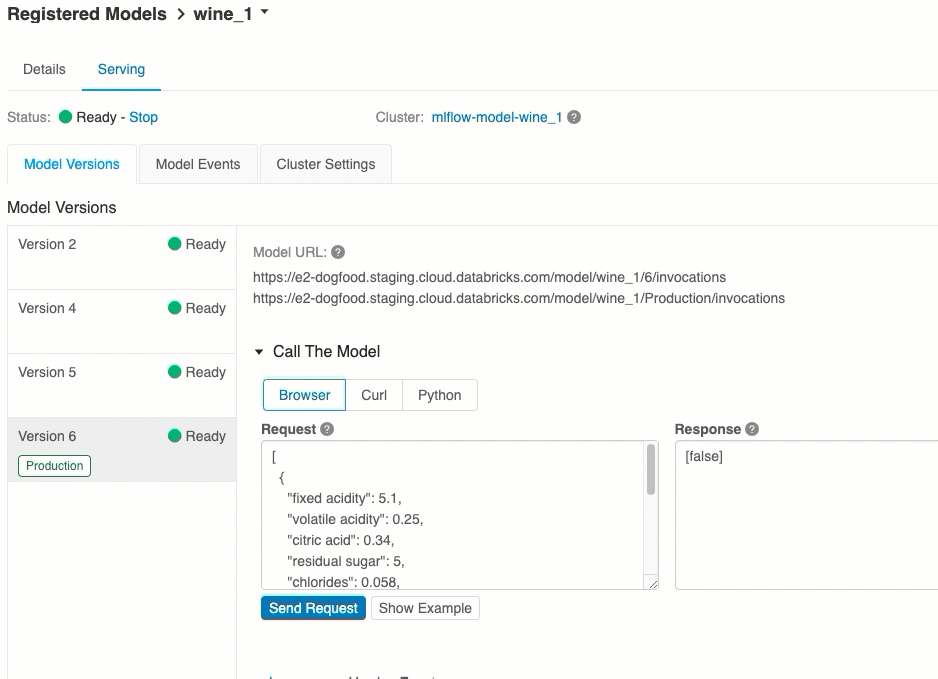
모델 버전 URI
배포된 각 모델 버전에는 하나 이상의 고유한 URI가 할당됩니다. 최소한 각 모델 버전에는 다음과 같이 생성된 URI가 할당됩니다.
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
예를 들어 iris-classifier로 등록된 모델의 버전 1을 호출하려면 다음 URI를 사용합니다.
https://<databricks-instance>/model/iris-classifier/1/invocations
단계별로 모델 버전을 호출할 수도 있습니다. 예를 들어 버전 1이 프로덕션 단계에 있는 경우 이 URI를 사용하여 점수를 매길 수도 있습니다.
https://<databricks-instance>/model/iris-classifier/Production/invocations
사용 가능한 모델 URI 목록은 Serving(서비스) 페이지의 Model Versions(모델 버전) 탭 맨 위에 표시됩니다.
제공된 버전 관리
모든 활성(보관되지 않은) 모델 버전이 배포되며 URI를 사용하여 쿼리할 수 있습니다. Azure Databricks는 새 모델 버전이 등록되면 해당 버전을 자동으로 배포하고, 이전 버전이 보관된 경우 해당 버전을 자동으로 제거합니다.
참고 항목
등록된 모델의 배포된 모든 버전은 동일한 클러스터를 공유합니다.
모델 액세스 권한 관리
모델 액세스 권한은 모델 레지스트리에서 상속됩니다. 서비스 기능을 사용하거나 사용하지 않도록 설정하려면 등록된 모델에 대한 '관리' 권한이 필요합니다. 읽기 권한이 있는 모든 사용자는 배포된 버전에 점수를 매길 수 있습니다.
배포된 모델 버전에 점수 매기기
배포된 모델에 점수를 매기려면 UI를 사용하거나 REST API 요청을 모델 URI로 보낼 수 있습니다.
UI를 통해 점수 매기기
모델을 테스트하는 가장 쉽고 빠른 방법입니다. 모델 입력 데이터를 JSON 형식으로 삽입하고 요청 보내기를 클릭할 수 있습니다. 위의 그래픽과 같이 모델이 입력 예제와 함께 로깅되면 Load Example(예제 로드)을 클릭하여 입력 예제를 로드합니다.
REST API 요청을 통해 점수 매기기
표준 Databricks 인증을 사용하여 REST API를 통해 점수 매기기 요청을 보낼 수 있습니다. 아래 예제에서는 MLflow 1.x에서 개인용 액세스 토큰을 사용한 인증을 보여 줍니다.
참고 항목
보안 모범 사례로, 자동화된 도구, 시스템, 스크립트 및 앱을 사용하여 인증하는 경우 Databricks는 작업 영역 사용자 대신 서비스 주체에 속한 개인용 액세스 토큰을 사용하는 것이 좋습니다. 서비스 주체에 대한 토큰을 만들려면 서비스 주체에 대한 토큰 관리를 참조하세요.
https://<databricks-instance>/model/iris-classifier/Production/invocations와 같은 MODEL_VERSION_URI(여기서 <databricks-instance>는 Databricks 인스턴스의 이름임)와 DATABRICKS_API_TOKEN이라는 Databricks REST API 토큰이 지정된 경우 다음 예제에서는 제공된 모델을 쿼리하는 방법을 보여줍니다.
다음 예제에서는 MLflow 1.x로 만든 모델의 채점 형식을 반영합니다. MLflow 2.0을 사용하려면 요청 페이로드 형식을 업데이트해야 합니다.
Bash
데이터 프레임 입력을 허용하는 모델을 쿼리하는 코드 조각입니다.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
텐서 입력을 허용하는 모델을 쿼리하는 코드 조각입니다. TensorFlow 서비스 API 문서에 설명된 대로 텐서 입력 형식을 지정해야 합니다.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Powerbi
다음 단계를 사용하여 Power BI Desktop의 데이터 세트에 대한 점수를 매길 수 있습니다.
점수를 매기려는 데이터 세트를 엽니다.
데이터 변환으로 이동합니다.
왼쪽 패널을 마우스 오른쪽 단추로 클릭하고 새 쿼리 만들기를 선택합니다.
보기 > 고급 편집기로 이동합니다.
적절한
DATABRICKS_API_TOKEN및MODEL_VERSION_URI를 입력한 후 쿼리 본문을 아래 코드 조각으로 바꿉니다.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPrediction원하는 모델 이름으로 쿼리 이름을 지정합니다.
데이터 세트에 대한 고급 쿼리 편집기를 열고 모델 함수를 적용합니다.
제공된 모델 모니터링
Serving(서비스) 페이지에는 개별 모델 버전뿐만 아니라 서비스 클러스터에 대한 상태 표시기가 표시됩니다.
- 서비스 클러스터의 상태를 검사하려면 이 모델에 대한 모든 서비스 이벤트 목록을 표시하는 Model Events(모델 이벤트) 탭을 사용합니다.
- 단일 모델 버전의 상태를 검사하려면 Model Versions(모델 버전) 탭을 클릭하고 스크롤하여 로그 또는 Version Events(버전 이벤트) 탭을 봅니다.
서비스 클러스터 사용자 지정
서비스 클러스터를 사용자 지정하려면 Serving(서비스) 탭의 Cluster Settings(클러스터 설정) 탭을 사용합니다.
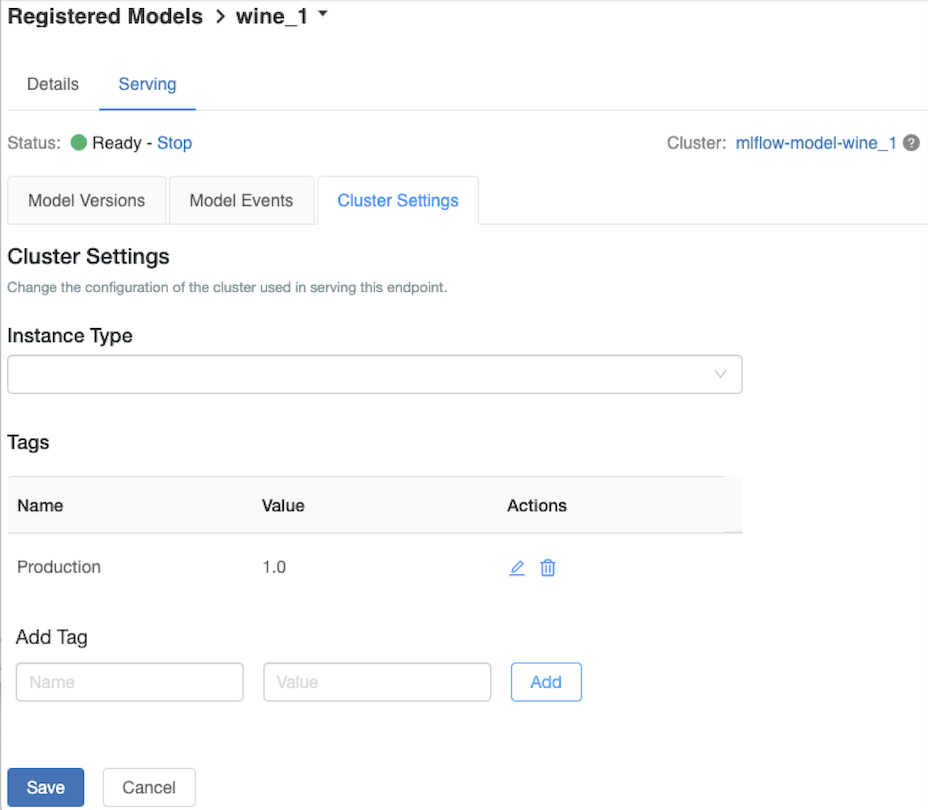
- 서비스 클러스터의 메모리 크기와 코어 수를 수정하려면 인스턴스 유형 드롭다운 메뉴를 사용하여 원하는 클러스터 구성을 선택합니다. 저장을 클릭하면 기존 클러스터가 종료되고 지정된 설정으로 새 클러스터가 만들어집니다.
- 태그를 추가하려면 태그 추가 필드에 이름과 값을 입력하고 추가를 클릭합니다.
- 기존 태그를 편집하거나 삭제하려면 태그 테이블의 작업 열에 있는 아이콘 중 하나를 클릭합니다.
기능 저장소 통합
레거시 모델 서비스 기능은 게시된 온라인 스토어에서 기능 값을 자동으로 조회할 수 있습니다.
.. Aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
알려진 오류
ResolvePackageNotFound: pyspark=3.1.0
모델이 pyspark에 종속되고 Databricks Runtime 8.x를 사용하여 로깅되면 이 오류가 발생할 수 있습니다.
이 오류가 표시되면 conda_env 매개 변수를 사용하여 모델을 로깅할 때 pyspark 버전을 명시적으로 지정합니다.
Unrecognized content type parameters: format
이 오류는 새 MLflow 2.0 채점 프로토콜 형식의 결과로 발생할 수 있습니다. 이 오류가 표시되는 경우 오래된 채점 요청 형식을 사용하고 있을 수 있습니다. 오류를 해결하기 위해 다음을 수행할 수 있습니다.
채점 요청 형식을 최신 프로토콜로 업데이트합니다.
참고 항목
다음 예제는 MLflow 2.0에 도입된 채점 형식을 반영합니다. MLflow 1.x를 사용하려는 경우
extra_pip_requirements매개 변수에 원하는 MLflow 버전 종속성을 포함하도록log_model()API 호출을 수정할 수 있습니다. 이렇게 하면 적절한 채점 형식이 사용됩니다.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
pandas 데이터 프레임 입력을 허용하는 모델을 쿼리합니다.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'텐서 입력을 수락하는 모델을 쿼리합니다. TensorFlow 서비스 API 문서에 설명된 대로 텐서 입력 형식을 지정해야 합니다.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Powerbi
다음 단계를 사용하여 Power BI Desktop의 데이터 세트에 대한 점수를 매길 수 있습니다.
점수를 매기려는 데이터 세트를 엽니다.
데이터 변환으로 이동합니다.
왼쪽 패널을 마우스 오른쪽 단추로 클릭하고 새 쿼리 만들기를 선택합니다.
보기 > 고급 편집기로 이동합니다.
적절한
DATABRICKS_API_TOKEN및MODEL_VERSION_URI를 입력한 후 쿼리 본문을 아래 코드 조각으로 바꿉니다.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPrediction원하는 모델 이름으로 쿼리 이름을 지정합니다.
데이터 세트에 대한 고급 쿼리 편집기를 열고 모델 함수를 적용합니다.
채점 요청에서
mlflow.pyfunc.spark_udf()와 같은 MLflow 클라이언트를 사용하는 경우 MLflow 클라이언트를 버전 2.0 이상으로 업그레이드하여 최신 형식을 사용합니다. MLflow 2.0에서 업데이트된 MLflow 모델 채점 프로토콜에 대해 자세히 알아봅니다.
서버에서 허용하는 입력 데이터 형식(예: pandas 분할 지향 형식)에 대한 자세한 내용은 MLflow 설명서를 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기