컴퓨팅 관리
이 문서에서는 표시, 편집, 시작, 종료, 삭제, 액세스 제어, 성능 및 로그 모니터링을 포함하여 Azure Databricks 컴퓨팅을 관리하는 방법을 설명합니다. 클러스터 API를 사용하여 프로그래밍 방식으로 컴퓨팅을 관리할 수도 있습니다.
컴퓨팅 보기
컴퓨팅을 보려면 작업 영역 사이드바에서 컴퓨팅을 클릭합니다![]() .
.
왼쪽에는 컴퓨팅이 고정되었는지와 컴퓨팅의 상태 나타내는 두 개의 열이 있습니다. 자세한 내용을 보려면 상태 마우스로 가리킵니다.
컴퓨팅 구성을 JSON 파일로 보기
경우에 따라 컴퓨팅 구성을 JSON으로 보는 것이 유용할 수 있습니다. 클러스터 API를 사용하여 유사한 컴퓨팅을 만들려는 경우에 특히 유용합니다. 기존 컴퓨팅을 볼 때 구성 탭으로 이동하여 탭의 오른쪽 위에 있는 JSON을 클릭하고 JSON을 복사한 다음 API 호출에 붙여넣습니다. JSON 보기는 읽기 전용입니다.
컴퓨팅 고정
컴퓨팅이 종료된 후 30일 후에 영구적으로 삭제됩니다. 컴퓨팅이 30일 이상 종료된 후 다목적 컴퓨팅 구성을 유지하려면 관리자가 컴퓨팅을 고정할 수 있습니다. 최대 100개의 컴퓨팅 리소스를 고정할 수 있습니다.
관리 고정 아이콘을 클릭하여 컴퓨팅 목록 또는 컴퓨팅 세부 정보 페이지에서 컴퓨팅을 고정할 수 있습니다.
컴퓨팅 편집
컴퓨팅 세부 정보 UI에서 컴퓨팅의 구성을 편집할 수 있습니다.
참고 항목
- 컴퓨팅에 연결된 Notebook 및 작업은 편집 후 다시 연결되지 기본.
- 컴퓨팅에 설치된 라이브러리가 다시 기본 편집 후 설치됩니다.
- 실행 중인 컴퓨팅의 특성을 편집하는 경우(컴퓨팅 크기 및 사용 권한 제외) 다시 시작해야 합니다. 이로 인해 현재 컴퓨팅을 사용하고 있는 사용자가 방해가 될 수 있습니다.
- 실행 중이거나 종료된 컴퓨팅만 편집할 수 있습니다. 그러나 컴퓨팅 세부 정보 페이지에서 해당 상태가 아닌 컴퓨팅에 대한 권한을 업데이트할 수 있습니다.
컴퓨팅 복제
기존 컴퓨팅을 복제하려면 컴퓨팅의 케밥 메뉴에서 복제를 선택합니다.
케밥 메뉴에서 복제를 선택합니다.
복제를 선택하면 컴퓨팅 만들기 UI가 컴퓨팅 구성으로 미리 채워집니다. 다음 특성은 클론에 포함되지 않습니다.
- 컴퓨팅 권한
- 첨부된 Notebooks
복제된 컴퓨팅에 이전에 설치된 라이브러리를 포함하지 않려면 컴퓨팅 만들기 단추 옆에 있는 드롭다운 메뉴를 클릭하고 라이브러리 없이 만들기를 선택합니다.
컴퓨팅 권한
컴퓨팅에는 사용 권한 없음, 연결할 수 있는 권한, 다시 시작 가능 및 CAN MANAGE의 네 가지 사용 권한 수준이 있습니다. 표에는 각 권한에 대한 기능이 나열되어 있습니다.
Important
CAN ATTACH TO 권한이 있는 사용자는 log4j 파일에서 서비스 계정 키를 볼 수 있습니다. 이 권한 수준을 부여할 때는 주의해야 합니다.
| 기능 | 사용 권한 없음 | 연결할 수 있습니다. | 다시 시작할 수 있습니다. | 관리 가능 |
|---|---|---|---|---|
| 컴퓨팅에 Notebook 연결 | x | x | x | |
| Spark UI 보기 | x | x | x | |
| 컴퓨팅 메트릭 보기 | x | x | x | |
| 드라이버 로그 보기 | x (참고 참조) | |||
| 컴퓨팅 종료 | x | x | ||
| 컴퓨팅 시작 및 다시 시작 | x | x | ||
| 컴퓨팅 편집 | x | |||
| 컴퓨팅에 라이브러리 연결 | x | |||
| 컴퓨팅 크기 조정 | x | |||
| 권한 수정 | x |
작업 영역 관리자는 해당 작업 영역의 모든 컴퓨팅에 대해 CAN MANAGE 권한이 있습니다. 사용자가 만든 컴퓨팅에 대한 CAN MANAGE 권한이 자동으로 부여됩니다.
참고 항목
비밀 은 클러스터의 Spark 드라이버 로그 stdout 및 stderr 스트림에서 수정되지 않습니다. 중요한 데이터를 보호하기 위해 기본적으로 Spark 드라이버 로그는 작업, 단일 사용자 액세스 모드 및 공유 액세스 모드 클러스터에 대한 CAN MANAGE 권한이 있는 사용자만 볼 수 있습니다. CAN ATTACH TO 또는 CAN RESTART 권한이 있는 사용자가 이러한 클러스터의 로그를 볼 수 있도록 하려면 클러스터 구성 spark.databricks.acl.needAdminPermissionToViewLogs false에서 다음 Spark 구성 속성을 설정합니다.
격리 공유 액세스 모드 클러스터가 없는 경우 CAN ATTACH TO 또는 CAN MANAGE 권한이 있는 사용자가 Spark 드라이버 로그를 볼 수 있습니다. CAN MANAGE 권한이 있는 사용자만 로그를 읽을 수 있는 사용자를 제한하려면 다음으로 true설정합니다spark.databricks.acl.needAdminPermissionToViewLogs.
컴퓨팅 권한 구성
이 섹션에서는 작업 영역 UI를 사용하여 사용 권한을 관리하는 방법을 설명합니다. 권한 API 또는 Databricks Terraform 공급자를 사용할 수도 있습니다.
컴퓨팅 권한을 구성하려면 컴퓨팅에 대한 CAN MANAGE 권한이 있어야 합니다.
- 사이드바에서 컴퓨팅을 클릭합니다.
- 컴퓨팅 행에서 오른쪽의 케밥 메뉴를
 클릭하고 권한 편집을 선택합니다.
클릭하고 권한 편집을 선택합니다. - 사용 권한 설정 사용자, 그룹 또는 서비스 주체 선택... 드롭다운 메뉴를 클릭하고 사용자, 그룹 또는 서비스 주체를 선택합니다.
- 권한 드롭다운 메뉴에서 사용 권한을 선택합니다.
- 추가를 클릭하고 저장을 클릭합니다.
컴퓨팅 종료
컴퓨팅 리소스를 저장하려면 컴퓨팅을 종료할 수 있습니다. 종료된 컴퓨팅의 구성은 나중에 다시 사용(또는 작업의 경우 자동 시작)할 수 있도록 저장됩니다. 지정된 비활성 기간 후에 컴퓨팅을 수동으로 종료하거나 컴퓨팅이 자동으로 종료되도록 구성할 수 있습니다. 종료된 컴퓨팅 수가 150을 초과하면 가장 오래된 컴퓨팅이 삭제됩니다.
컴퓨팅이 고정 되거나 다시 시작되지 않는 한 종료 후 30일 후에 자동으로 영구적으로 삭제됩니다.
종료된 컴퓨팅은 컴퓨팅 이름 왼쪽에 회색 원을 사용하여 컴퓨팅 목록에 나타납니다.
참고 항목
일반적으로 권장되는 새 작업 컴퓨팅에서 작업을 실행하면 컴퓨팅이 종료되고 작업이 완료되면 다시 시작할 수 없습니다. 반면, 종료된 기존 다목적 컴퓨팅에서 실행되도록 작업을 예약하면 해당 컴퓨팅이 자동으로 시작됩니다.
Important
평가판 프리미엄 작업 영역을 사용하는 경우 실행 중인 모든 컴퓨팅 리소스가 종료됩니다.
- 작업 영역을 전체 프리미엄으로 업그레이드하는 경우.
- 작업 영역이 업그레이드되지 않고 평가판이 만료되는 경우.
수동 종료
컴퓨팅 목록에서 컴퓨팅을 수동으로 종료할 수 있습니다(컴퓨팅 행의 정사각형을 클릭하여) 또는 컴퓨팅 세부 정보 페이지(종료 클릭).
자동 종료
컴퓨팅에 대한 자동 종료를 설정할 수도 있습니다. 컴퓨팅을 만드는 동안 몇 분 안에 비활성 기간을 지정하여 컴퓨팅을 종료할 수 있습니다.
컴퓨팅에서 현재 시간과 마지막 명령 실행 간의 차이가 지정된 비활성 기간보다 큰 경우 Azure Databricks는 해당 컴퓨팅을 자동으로 종료합니다.
Spark 작업, 구조적 스트리밍 및 JDBC 호출을 비롯한 컴퓨팅의 모든 명령이 실행을 완료하면 컴퓨팅이 비활성 상태로 간주됩니다.
Warning
- 컴퓨팅은 D스트림 사용으로 인한 활동을 보고하지 않습니다. 즉, D스트림 실행하는 동안 자동 종료 컴퓨팅이 종료될 수 있습니다. D스트림 실행 중인 컴퓨팅에 대해 자동 종료를 해제하거나 구조적 스트리밍을 사용하는 것이 좋습니다.
- 유휴 컴퓨팅은 종료 전 비활성 기간 동안 DBU 및 클라우드 인스턴스 요금을 계속 누적합니다.
자동 종료 구성
새 컴퓨팅 UI에서 자동 종료를 구성할 수 있습니다. 상자가 검사 있는지 확인하고 비활성 설정의 ___ 이후 종료 시간(분)을 입력합니다.
자동 종료 확인란의 선택을 취소하거나 비활성 기간을 0으로 지정하여 자동 종료를 옵트아웃할 수 있습니다.
참고 항목
자동 종료는 최신 Spark 버전에서 가장 잘 지원됩니다. 이전 Spark 버전에는 알려진 제한 사항이 있어 컴퓨팅 활동을 부정확하게 보고할 수 있습니다. 예를 들어 JDBC, R 또는 스트리밍 명령을 실행하는 컴퓨팅은 부실한 작업 시간을 보고하여 컴퓨팅 종료를 조기에 발생시킬 수 있습니다. 버그 수정 및 자동 종료 개선 사항을 이용하려면 최신 Spark 버전으로 업그레이드합니다.
예기치 않은 종료
수동 종료 또는 구성된 자동 종료의 결과가 아니라 컴퓨팅이 예기치 않게 종료되는 경우가 있습니다.
종료 이유 및 수정 단계 목록은 기술 자료을 참조하세요.
컴퓨팅 삭제
컴퓨팅을 삭제하면 컴퓨팅이 종료되고 해당 구성이 제거됩니다. 컴퓨팅을 삭제하려면 컴퓨팅 메뉴에서 삭제를 선택합니다.
Warning
이 작업을 실행 취소할 수 없습니다.
고정된 컴퓨팅을 삭제하려면 먼저 관리자가 고정 해제해야 합니다.
클러스터 API 엔드포인트를 호출하여 프로그래밍 방식으로 컴퓨팅을 삭제할 수도 있습니다.
컴퓨팅 다시 시작
컴퓨팅 목록, 컴퓨팅 세부 정보 페이지 또는 Notebook에서 이전에 종료된 컴퓨팅을 다시 시작할 수 있습니다. 클러스터 API 엔드포인트를 호출하여 프로그래밍 방식으로 컴퓨팅을 시작할 수도 있습니다.
Azure Databricks는 고유한 클러스터 ID를 사용하여 컴퓨팅을 식별합니다. 종료된 컴퓨팅을 시작하면 Databricks는 동일한 ID로 컴퓨팅을 다시 만들고, 모든 라이브러리를 자동으로 설치하고, Notebook을 다시 연결합니다.
참고 항목
평가판 작업 영역을 사용하고 평가판이 만료된 경우 컴퓨팅을 시작할 수 없습니다.
컴퓨팅을 다시 시작하여 최신 이미지로 업데이트
컴퓨팅을 다시 시작하면 컴퓨팅 리소스 컨테이너 및 VM 호스트에 대한 최신 이미지를 가져옵니다. 스트리밍 데이터 처리에 사용되는 컴퓨팅과 같은 장기 실행 컴퓨팅에 대해 정기적으로 다시 시작하도록 예약하는 것이 중요합니다.
이미지를 최신 이미지 버전으로 최신 상태로 유지하기 위해 모든 컴퓨팅 리소스를 정기적으로 다시 시작해야 합니다.
Important
계정 또는 작업 영역에 규정 준수 보안 프로필을 사용하도록 설정하면 예약된 기본 기간 동안 필요에 따라 장기 실행 컴퓨팅이 자동으로 다시 시작됩니다. 이렇게 하면 자동 다시 시작으로 인해 예약된 작업이 중단될 위험이 줄어듭니다. 기본 기간 동안 강제로 다시 시작할 수도 있습니다. 자동 클러스터 업데이트를 참조하세요.
Notebook 예제: 장기 실행 컴퓨팅 찾기
작업 영역 관리자인 경우 각 컴퓨팅이 실행된 기간을 결정하는 스크립트를 실행하고, 지정된 일 수보다 오래된 경우 필요에 따라 다시 시작할 수 있습니다. Azure Databricks는 이 스크립트를 Notebook으로 제공합니다.
스크립트의 첫 번째 줄은 구성 매개 변수를 정의합니다.
min_age_output: 컴퓨팅을 실행할 수 있는 최대 일 수입니다. 기본값은 1입니다.perform_restart: 스크립트가 지정한 일min_age_output수보다 큰 모든 컴퓨팅을 다시 시작하는 경우True. 기본값은False장기 실행 컴퓨팅을 식별하지만 다시 시작하지는 않는 것입니다.secret_configuration:REPLACE_WITH_SCOPE및REPLACE_WITH_KEY를 비밀 범위 및 키 이름으로 바꿉니다. 비밀 설정에 대한 자세한 내용은 Notebook을 참조하세요.
Warning
설정 perform_restartTrue하면 스크립트가 적격 컴퓨팅을 자동으로 다시 시작하여 활성 작업이 실패하고 열린 Notebook을 다시 설정할 수 있습니다. 작업 영역의 업무상 중요한 작업을 방해할 위험을 줄이려면 예약된 기본 테넌트 창을 계획하고 작업 영역 사용자에게 알려야 합니다.
장기 실행 컴퓨팅 식별 및 선택적으로 다시 시작
작업 및 JDBC/ODBC 쿼리에 대한 컴퓨팅 자동 시작
종료된 컴퓨팅에 할당된 작업이 실행되도록 예약되거나 JDBC/ODBC 인터페이스에서 종료된 컴퓨팅에 연결하면 컴퓨팅이 자동으로 다시 시작됩니다. 작업 만들기 및 JDBC 연결을 참조하세요.
컴퓨팅 자동 시작을 사용하면 예약된 작업에 대한 컴퓨팅을 다시 시작하기 위해 수동 개입 없이 자동으로 종료되도록 컴퓨팅을 구성할 수 있습니다. 또한 종료된 컴퓨팅에서 실행할 작업을 예약하여 컴퓨팅 초기화를 예약할 수 있습니다.
컴퓨팅을 자동으로 다시 시작하기 전에 컴퓨팅 및 작업 액세스 제어 권한이 검사.
참고 항목
Azure Databricks 플랫폼 버전 2.70 이하에서 컴퓨팅을 만든 경우 자동 시작이 없습니다. 종료된 컴퓨팅에서 실행되도록 예약된 작업이 실패합니다.
Apache Spark UI에서 컴퓨팅 정보 보기
컴퓨팅 세부 정보 페이지에서 Spark UI 탭을 선택하여 Spark 작업에 대한 자세한 정보를 볼 수 있습니다.
종료된 컴퓨팅을 다시 시작하면 Spark UI는 종료된 컴퓨팅에 대한 기록 정보가 아니라 다시 시작한 컴퓨팅에 대한 정보를 표시합니다.
Spark UI를 사용하여 비용 및 성능 문제를 진단하려면 Spark UI를 사용하여 비용 및 성능 문제 진단을 참조하세요.
컴퓨팅 로그 보기
Azure Databricks는 컴퓨팅 관련 작업의 세 가지 로깅을 제공합니다.
- 생성, 종료 및 구성 편집과 같은 컴퓨팅 수명 주기 이벤트를 캡처하는 컴퓨팅 이벤트 로그입니다.
- 디버깅에 사용할 수 있는 Apache Spark 드라이버 및 작업자 로그입니다.
- init 스크립트를 디버깅하는 데 유용한 init-script 로그를 계산합니다.
이 섹션에서는 컴퓨팅 이벤트 로그와 드라이버 및 작업자 로그에 대해 설명합니다. init-script 로그에 대한 자세한 내용은 Init 스크립트 로깅을 참조하세요.
컴퓨팅 이벤트 로그
컴퓨팅 이벤트 로그는 사용자 작업에 의해 수동으로 또는 Azure Databricks에 의해 자동으로 트리거되는 중요한 컴퓨팅 수명 주기 이벤트를 표시합니다. 이러한 이벤트는 컴퓨팅 전체의 작업과 컴퓨팅에서 실행되는 작업에 영향을 줍니다.
지원되는 이벤트 유형은 클러스터 API 데이터 구조를 참조하세요.
이벤트는 60일 동안 저장되며 이는 Azure Databricks의 다른 데이터 보존 시간과 비슷합니다.
컴퓨팅의 이벤트 로그 보기
컴퓨팅의 이벤트 로그를 보려면 컴퓨팅 세부 정보 페이지에서 이벤트 로그 탭을 선택합니다.
이벤트에 대한 자세한 내용을 보려면 로그에서 해당 행을 클릭한 다음 자세한 내용을 보려면 JSON 탭을 클릭합니다.
컴퓨팅 드라이버 및 작업자 로그
Notebooks, 작업 및 라이브러리의 직접 인쇄 및 로그 문은 Spark 드라이버 로그로 이동합니다. 컴퓨팅 세부 정보 페이지의 드라이버 로그 탭에서 이러한 로그 파일에 액세스할 수 있습니다. 로그 파일을 다운로드하려면 해당 로그 파일의 이름을 클릭합니다.
이러한 로그에는 세 가지 출력이 있습니다.
- 표준 출력
- 표준 오류
- Log4j 로그
Spark 작업자 로그를 보려면 Spark UI 탭을 사용합니다. 컴퓨팅에 대한 로그 배달 위치를 구성할 수도 있습니다. 작업자 및 컴퓨팅 로그는 모두 지정한 위치로 전달됩니다.
성능 모니터링
Azure Databricks 컴퓨팅의 성능을 모니터링할 수 있도록 Azure Databricks는 컴퓨팅 세부 정보 페이지에서 메트릭에 대한 액세스를 제공합니다. Databricks Runtime 12.2 이하의 경우 Azure Databricks는 Ganglia 메트릭에 대한 액세스를 제공합니다. Databricks Runtime 13.3 LTS 이상의 경우 Azure Databricks에서 컴퓨팅 메트릭을 제공합니다.
또한 Azure용 모니터링 플랫폼인 Azure Monitor의 Log Analytics 작업 영역에 메트릭을 보내도록 Azure Databricks 컴퓨팅을 구성할 수 있습니다.
컴퓨팅 노드에 Datadog 에이전트를 설치하여 Datadog 메트릭을 Datadog 계정으로 보낼 수도 있습니다.
컴퓨팅 메트릭
컴퓨팅 메트릭은 Databricks Runtime 13.3 LTS 이상의 기본 모니터링 도구입니다. 컴퓨팅 메트릭 UI에 액세스하려면 컴퓨팅 세부 정보 페이지의 메트릭 탭으로 이동합니다.
날짜 선택기 필터를 사용하여 시간 범위를 선택하여 기록 메트릭을 볼 수 있습니다. 메트릭은 1분마다 수집됩니다. 새로 고침 단추를 클릭하여 최신 메트릭을 가져올 수도 있습니다. 자세한 내용은 컴퓨팅 메트릭 보기를 참조 하세요.
Ganglia 메트릭
참고 항목
Ganglia 메트릭은 Databricks Runtime 12.2 이하에서만 사용할 수 있습니다.
Ganglia UI에 액세스하려면 컴퓨팅 세부 정보 페이지의 메트릭 탭으로 이동합니다. CPU 메트릭은 모든 Databricks Runtime에 대한 Ganglia UI에서 사용할 수 있습니다. GPU 메트릭은 GPU 사용 컴퓨팅에 사용할 수 있습니다.
라이브 메트릭을 보려면 Ganglia UI 링크를 클릭합니다.
기록 메트릭을 보려면 스냅샷 파일을 클릭합니다. 스냅샷에는 선택한 시간 이전 시간에 대해 집계된 메트릭이 포함됩니다.
참고 항목
Ganglia는 Docker 컨테이너에서 지원되지 않습니다. 컴퓨팅과 함께 Docker 컨테이너를 사용하는 경우 Ganglia 메트릭을 사용할 수 없습니다.
Ganglia 메트릭 컬렉션 구성
기본적으로 Azure Databricks는 15분마다 Ganglia 메트릭을 수집합니다. 컬렉션 기간을 구성하려면 init 스크립트를 사용하거나 클러스터 만들기 API의 spark_env_vars 필드에서 환경 변수를 설정합니다DATABRICKS_GANGLIA_SNAPSHOT_PERIOD_MINUTES.
Azure Monitor
Azure용 모니터링 플랫폼인 Azure Monitor의 Log Analytics 작업 영역에 메트릭을 보내도록 Azure Databricks 컴퓨팅을 구성할 수 있습니다. 전체 지침은 Azure Databricks 모니터링을 참조하세요.
참고 항목
자체 가상 네트워크에 Azure Databricks 작업 영역을 배포하고 Azure Databricks에 필요하지 않은 모든 아웃바운드 트래픽을 거부하도록 NSG(네트워크 보안 그룹)를 구성한 경우 "AzureMonitor" 서비스 태그에 대한 추가 아웃바운드 규칙을 구성해야 합니다.
Notebook 예제: Datadog 메트릭
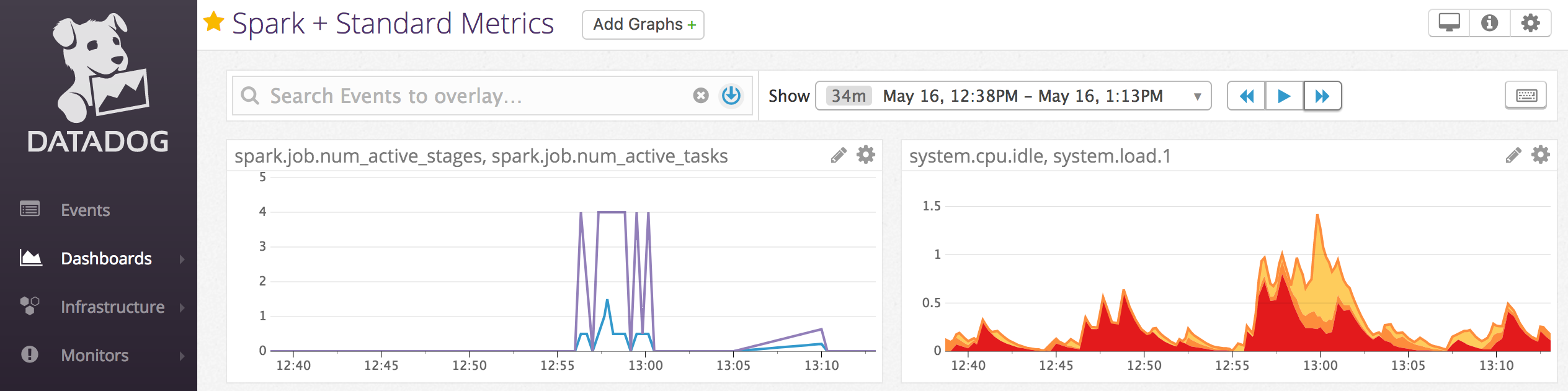
Datadog 에이전트를 컴퓨팅 노드에 설치하여 Datadog 계정에 Datadog 메트릭을 보낼 수 있습니다. 다음 Notebook에서는 컴퓨팅 범위 init 스크립트를 사용하여 컴퓨팅에 Datadog 에이전트를 설치하는 방법을 보여 줍니다.
모든 컴퓨팅에 Datadog 에이전트를 설치하려면 컴퓨팅 정책을 사용하여 컴퓨팅 범위 init 스크립트를 관리합니다.
Datadog 에이전트 init 스크립트 Notebook 설치
스폿 인스턴스 서비스 해제
스폿 인스턴스는 비용을 절감할 수 있으므로 주문형 인스턴스가 아닌 스폿 인스턴스를 사용하여 컴퓨팅을 만드는 것이 작업을 실행하는 일반적인 방법입니다. 그러나 스폿 인스턴스는 클라우드 공급자 스케줄링 메커니즘에 의해 선점될 수 있습니다. 스폿 인스턴스를 선점하면 다음을 포함하여 실행 중인 작업에 문제가 발생할 수 있습니다.
- 무작위 재생 가져오기 실패
- 무작위 재생 데이터 손실
- RDD 데이터 손실
- 작업 실패
이러한 문제를 해결하는 데 도움이 되도록 폐기를 사용하도록 설정할 수 있습니다. 폐기는 스폿 인스턴스가 폐기되기 전에 일반적으로 클라우드 공급자가 보내는 알림을 활용합니다. 실행기를 포함하는 스폿 인스턴스가 선점 알림을 수신하면 폐기 프로세스는 무작위 재생 및 RDD 데이터를 정상적인 실행기로 마이그레이션하려고 시도합니다. 최종 선점 이전의 기간은 일반적으로 클라우드 공급자에 따라 30초에서 2분입니다.
Databricks에 의하면 폐기도 사용하도록 설정된 경우 데이터 마이그레이션을 사용하도록 설정하는 것이 좋습니다. 일반적으로 무작위 재생 가져오기 실패, 무작위 재생 데이터 손실 및 RDD 데이터 손실을 포함하여 더 많은 데이터가 마이그레이션될수록 오류 가능성이 줄어듭니다. 또한 데이터 마이그레이션으로 인해 다시 계산 및 비용 절감이 감소할 수 있습니다.
참고 항목
서비스 해제는 최선의 노력이며 최종 선점 전에 모든 데이터를 마이그레이션할 수 있다고 보장하지는 않습니다. 폐기는 실행 중인 작업이 실행기에서 무작위 재생 데이터를 가져올 때 무작위 재생 가져오기 실패가 일어나지 않으리라는 것을 보장할 수 없습니다.
폐기가 사용하도록 설정되면 스폿 인스턴스 선점으로 인한 작업 실패는 총 실패한 시도 횟수에 추가되지 않습니다. 선점으로 인한 작업 실패는 실패 원인이 작업 외부에 있고 작업 실패로 이어지지 않기 때문에 실패한 시도로 계산되지 않습니다.
서비스 해제 사용
컴퓨팅에서 서비스 해제를 사용하도록 설정하려면 컴퓨팅 구성 UI의 고급 옵션 아래에 있는 Spark 탭에 다음 속성을 입력합니다. 이러한 속성에 대한 자세한 내용은 Spark 구성을 참조하세요.
애플리케이션에 대한 서비스 해제를 사용하도록 설정하려면 Spark 구성 필드에 다음 속성을 입력합니다.
spark.decommission.enabled true서비스 해제 중에 순서 섞기 데이터 마이그레이션을 사용하도록 설정하려면 Spark 구성 필드에 다음 속성을 입력합니다.
spark.storage.decommission.enabled true spark.storage.decommission.shuffleBlocks.enabled true서비스 해제 중에 RDD 캐시 데이터 마이그레이션을 사용하도록 설정하려면 Spark 구성 필드에 다음 속성을 입력합니다.
spark.storage.decommission.enabled true spark.storage.decommission.rddBlocks.enabled true참고 항목
RDD StorageLevel 복제가 1보다 크게 설정되면 복제본은 RDD에서 데이터가 손실되지 않도록 보장하므로 Databricks는 RDD 데이터 마이그레이션을 사용하도록 설정하지 않는 것이 좋습니다.
작업자에 대한 서비스 해제를 사용하도록 설정하려면 환경 변수 필드에 다음 속성을 입력합니다 .
SPARK_WORKER_OPTS="-Dspark.decommission.enabled=true"
UI에서 서비스 해제 상태 및 손실 이유 보기
UI에서 작업자의 서비스 해제 상태 액세스하려면 Spark 컴퓨팅 UI - 마스터 탭으로 이동합니다.
서비스 해제가 완료되면 컴퓨팅 세부 정보 페이지의 Spark UI > 실행기 탭에서 실행기의 손실 이유를 볼 수 있습니다.