레거시 시각화
이 문서에서는 레거시 Azure Databricks 시각화에 대해 설명합니다. 현재 시각화 지원은 Databricks Notebook의 시각화를 참조하세요.
또한 Azure Databricks는 기본적으로 Python 및 R의 시각화 라이브러리를 지원하며 타사 라이브러리를 설치하고 사용할 수 있습니다.
레거시 시각화 만들기
결과 셀에서 레거시 시각화를 만들려면 +을 클릭하고 레거시 시각화를 선택합니다.
레거시 시각화는 다양한 플롯 형식 세트를 지원합니다.
레거시 차트 종류 선택 및 구성
가로 막대형 차트를 선택하려면 가로 막대형 차트 아이콘  을 클릭합니다.
을 클릭합니다.

다른 플롯 유형을 선택하려면 가로 막대형 차트의 오른쪽을 클릭하고 ![]() 그림 종류를 선택합니다.
그림 종류를 선택합니다.
레거시 차트 도구 모음
꺾은선형 차트와 가로 막대형 차트에는 다양한 클라이언트 쪽 상호 작용 집합을 지원하는 기본 제공 도구 모음이 있습니다.

차트를 구성하려면 출력 옵션…을 클릭합니다.

꺾은선형 차트에는 Y축 범위 설정, 점 표시 및 숨기기, 로그 눈금을 사용하여 Y축 표시와 같은 몇 가지 사용자 지정 차트 옵션이 있습니다.
레거시 차트 종류에 대한 자세한 내용은 다음을 참조하세요.
차트 간 색 일관성
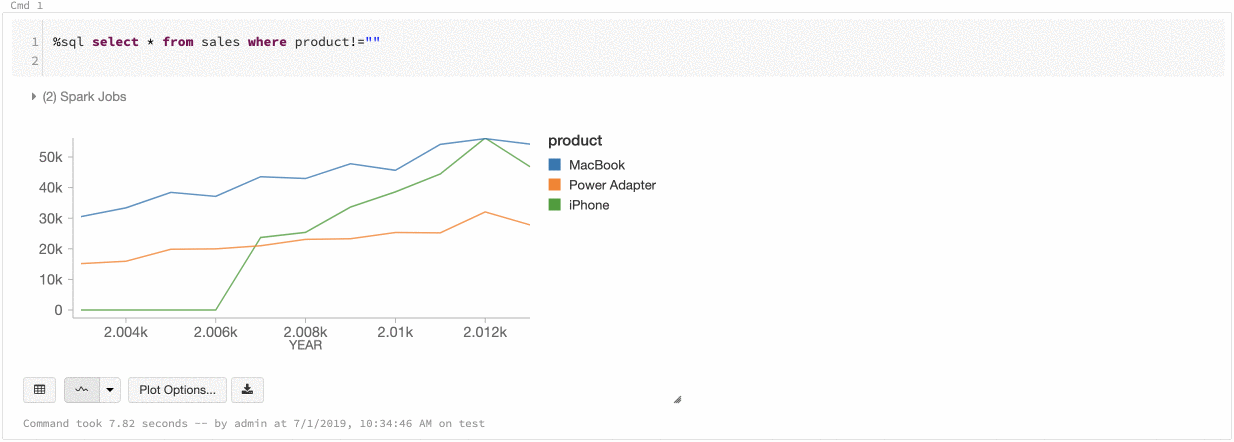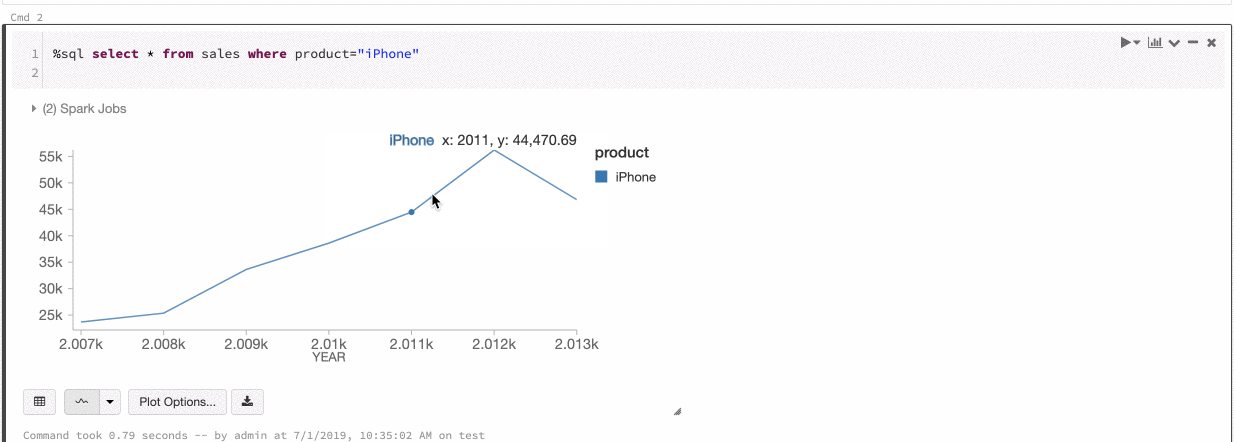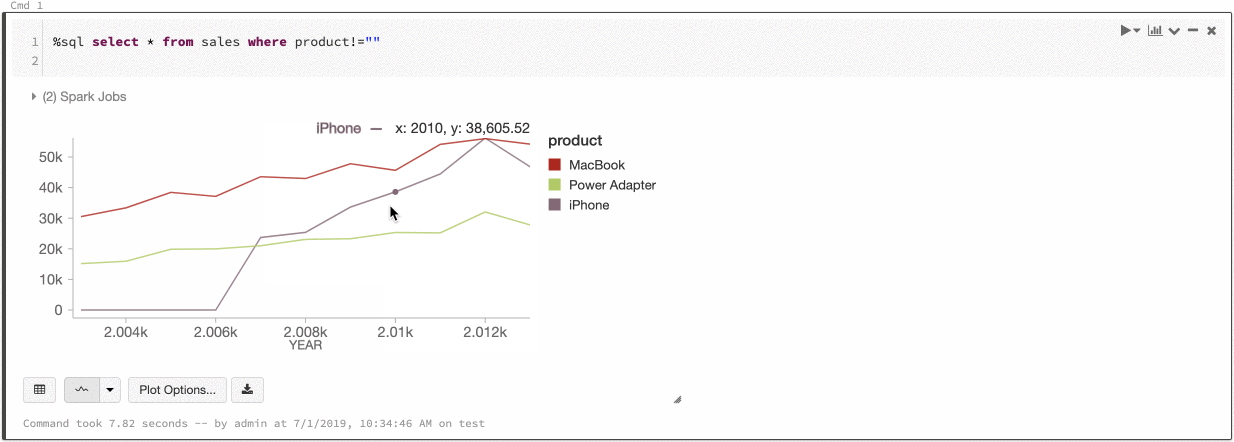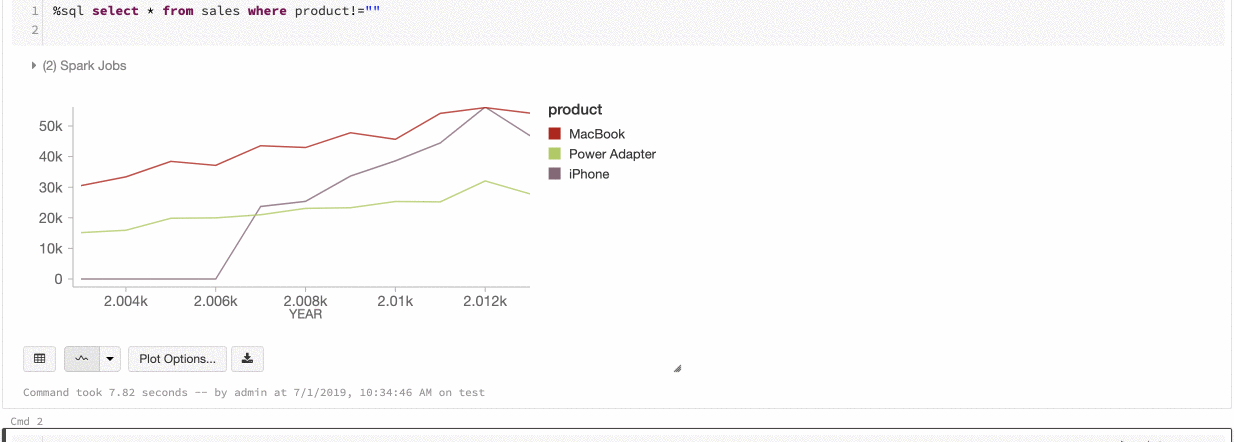
Azure Databricks는 레거시 차트에서 계열 세트 및 글로벌의 두 가지 색 일관성을 지원합니다.
계열 집합 색 일관성은 값이 같지만 순서가 다른 계열(예: A = 및 B = ["Apple", "Orange", "Banana"]["Orange", "Banana", "Apple"])이 있는 경우 동일한 값에 동일한 색을 할당합니다. 값을 그리기 전에 정렬되므로 두 범례가 같은 방식으로 정렬되고 동일한["Apple", "Banana", "Orange"] 값에 동일한 색이 지정됩니다. 그러나 C = ["Orange", "Banana"]계열이 있는 경우 집합이 동일하지 않기 때문에 A 집합과 색이 일치하지 않습니다. 정렬 알고리즘은 C 집합의 "Banana"에 첫 번째 색을 할당하지만 두 번째 색은 Set A의 "Banana"에 할당합니다. 이러한 계열을 색 일치로 설정하려면 차트에 전역 색 일관성이 있어야 하므로 지정할 수 있습니다.
글로벌 색 일관성에서 각 값은 계열의 값에 관계없이 항상 동일한 색으로 매핑됩니다. 각 차트에 대해 이를 사용하도록 설정하려면 전역 색 일관성 검사box를 선택합니다.
참고 항목
이 일관성을 달성하기 위해 Azure Databricks는 값에서 색으로 직접 해시합니다. 충돌을 방지하기 위해(두 값이 정확히 동일한 색으로 이동하는 경우) 해시는 멋진 색이나 쉽게 구별할 수 있는 색을 보장할 수 없는 부작용이 있는 큰 색 집합에 대한 것입니다. 색이 많을 때는 매우 비슷한 색이 있을 수밖에 없습니다.
기계 학습 시각화
표준 차트 종류 외에도 레거시 시각화는 다음과 같은 기계 학습 교육 매개 변수 및 결과를 지원합니다.
잔차
선형 및 로지스틱 회귀 분석의 경우 적합(fitted) 및 잔차(residual) 플롯을 렌더링할 수 있습니다. 이 플롯을 얻으려면 모델과 DataFrame을 제공합니다.
다음 예제에서는 도시 인구에 대한 선형 회귀를 실행하여 판매 가격 데이터를 보관한 다음, 잔차와 적합한 데이터를 표시합니다.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)

ROC 곡선
로지스틱 회귀의 경우 ROC 곡선을 렌더링할 수 있습니다. 이 플롯을 얻으려면 모델, fit 메서드에 입력되어 준비된 데이터 및 "ROC" 매개 변수를 제공합니다.
다음 예제에서는 개인의 다양한 특성으로부터 연간 50,000 < 또는 50,000 >의 개인 소득을 예측하는 분류자를 개발합니다. 성인 데이터 세트는 인구 조사 데이터에서 파생되며 48842 개인 및 연간 소득에 대한 정보로 구성됩니다.
이 섹션의 예제 코드는 원 핫 인코딩을 사용합니다.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")

잔여 항목을 표시하려면 매개 변수를 "ROC" 생략합니다.
display(lrModel, preppedDataDF)

의사 결정 트리
레거시 시각화는 의사 결정 트리 렌더링을 지원합니다.
이 시각화를 얻으려면 의사 결정 트리 모델을 제공합니다.
다음 예제에서는 필기 숫자 이미지의 MNIST 데이터 세트에서 숫자(0 - 9)를 인식하도록 트리를 학습한 다음 트리를 표시합니다.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)

구조적 스트리밍 데이터 프레임
스트리밍 쿼리의 결과를 실시간으로 시각화하려면 Scala 및 Python에서 구조적 스트리밍 데이터 프레임을 만들 수 있습니다 display .
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display 는 다음과 같은 선택적 매개 변수를 지원합니다.
streamName: 스트리밍 쿼리 이름입니다.trigger(Scala) 및processingTime(Python): 스트리밍 쿼리가 실행되는 빈도를 정의합니다. 지정하지 않으면 시스템은 이전 처리가 완료되는 즉시 새 데이터의 가용성을 확인합니다. Databricks에서 프로덕션 비용을 줄이려면 항상 트리거 간격을 설정하는 것이 좋습니다. 기본 트리거 간격은 500ms입니다.checkpointLocation: 시스템에서 모든 검사포인트 정보를 쓰는 위치입니다. 지정되지 않은 경우 시스템은 DBFS에 임시 검사점 위치를 자동으로 생성합니다. 스트림이 중단된 위치에서 데이터를 계속 처리하려면 검사점 위치를 지정해야 합니다. Databricks는 프로덕션 환경에서 항상 옵션을 지정하는checkpointLocation것이 좋습니다.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
이러한 매개 변수에 대한 자세한 내용은 스트리밍 쿼리 시작을 참조하세요.
displayHTML 함수
Azure Databricks 프로그래밍 언어 Notebook(Python, R 및 Scala)은 함수를 사용하여 displayHTML HTML 그래픽을 지원합니다. 모든 HTML, CSS 또는 JavaScript 코드를 함수에 전달할 수 있습니다. 이 함수는 D3과 같은 JavaScript 라이브러리를 사용하여 대화형 그래픽을 지원합니다.
displayHTML 사용 예는 다음을 참조하세요.
참고 항목
iframe은 displayHTML do기본 databricksusercontent.com제공되고 iframe 샌드박스에는 특성이 allow-same-origin 포함됩니다. databricksusercontent.com 는 브라우저에서 액세스할 수 있어야 합니다. 현재 회사 네트워크에서 차단된 경우 허용 목록에 추가해야 합니다.
이미지
이미지 데이터 형식이 포함된 열을 서식 있는 HTML로 렌더링합니다. Azure Databricks는 Spark ImageSchema와 일치하는 DataFrame 열의 이미지 썸네일을 렌더링하려고 시도합니다.
썸네일 렌더링은 함수를 통해 spark.read.format('image') 성공적으로 읽은 모든 이미지에 대해 작동합니다. 다른 수단을 통해 생성된 이미지 값의 경우 Azure Databricks는 다음 제약 조건을 사용하여 1, 3 또는 4 채널 이미지(각 채널이 단일 바이트로 구성됨)의 렌더링을 지원합니다.
- 한 채널 이미지:
mode필드는 0과 같아야 합니다.height,width및nChannels필드는 필드의 이진 이미지 데이터를data정확하게 설명해야 합니다. - 3개 채널 이미지:
mode필드는 16과 같아야 합니다.height,width및nChannels필드는 필드의 이진 이미지 데이터를data정확하게 설명해야 합니다.data필드는 3바이트 청크의 픽셀 데이터를 포함해야 하며, 각 픽셀의 채널 순서는(blue, green, red)입니다. - 4개 채널 이미지:
mode필드는 24와 같아야 합니다.height,width및nChannels필드는 필드의 이진 이미지 데이터를data정확하게 설명해야 합니다. 필드에는data픽셀 데이터가 4 바이트 청크로 포함되어야 하며 각 픽셀에 대한 채널 순서가 지정(blue, green, red, alpha)되어 있어야 합니다.
예시
일부 이미지가 포함된 폴더가 있다고 가정해 보겠습니다.

이미지를 DataFrame으로 읽은 다음, DataFrame을 표시하면 Azure Databricks에서 이미지의 썸네일을 렌더링합니다.
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Python의 시각화
이 섹션의 내용:
Seaborn
또한 다른 Python 라이브러리를 사용하여 플롯을 생성할 수도 있습니다. Databricks 런타임에는 해상 시각화 라이브러리가 포함됩니다. Seaborn 플롯을 만들려면 라이브러리를 가져오고 플롯을 만든 다음, 플롯을 display 함수로 전달합니다.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)

기타 Python 라이브러리
R의 시각화
R에서 데이터를 그리려면 다음과 같이 함수를 display 사용합니다.
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
기본 R 플롯 함수를 사용할 수 있습니다.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)

모든 R 시각화 패키지를 사용할 수도 있습니다. R Notebook은 결과 플롯을 a .png 로 캡처하고 인라인으로 표시합니다.
이 섹션의 내용:
Lattice
Lattice 패키지는 하나 이상의 다른 변수에서 조건부로 변수 또는 변수 간의 관계를 표시하는 그래프인 격자 그래프를 지원합니다.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")

DandEFA
DandEFA 패키지는 민들레 플롯을 지원합니다.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)

Plotly
Plotly R 패키지는 R에 대한 htmlwidgets를 사용합니다. 설치 지침 및 Notebook은 htmlwidgets를 참조하세요.
기타 R 라이브러리
Scala의 시각화
Scala에서 데이터를 그리려면 다음과 같이 함수를 display 사용합니다.
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Python 및 Scala에 대한 심층 분석 Notebook
Python 시각화에 대한 자세한 내용은 다음 Notebook을 참조하세요.
Scala 시각화에 대한 자세한 내용은 다음 Notebook을 참조하세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기