Apache Hive를 ETL(추출, 변환 및 로드) 도구로 사용
일반적으로 들어오는 데이터를 분석에 적합한 대상으로 로드하기 전에, 정리하고 변환해야 합니다. ELT(추출, 변환 및 로드) 작업은 데이터를 준비하고 데이터 대상에 로드하는 데 사용됩니다. HDInsight의 Apache Hive는 구조화되지 않은 데이터를 읽고, 필요에 따라 데이터를 처리한 다음, 의사 결정 지원 시스템에 대한 관계형 데이터 웨어하우스에 데이터를 로드할 수 있습니다. 이 방법에서는 원본에서 데이터를 추출합니다. 그런 다음 데이터는 Azure Storage BLOB 또는 Azure Data Lake Storage와 같이 조정 가능한 스토리지에 저장됩니다. 그런 다음 데이터는 Hive 쿼리 시퀀스를 사용하여 변환됩니다. 이후, 데이터는 대상 데이터 저장소로의 대량 로드를 대비하여 Hive 내에 스테이징됩니다.
사용 사례 및 모델 개요
다음 그림은 ETL 자동화에 대한 사용 사례 및 모델을 간략하게 보여 줍니다. 적절한 출력을 생성하기 위해 입력 데이터가 변환됩니다. 변환이 진행되는 동안 데이터는 모양, 데이터 형식, 심지어는 언어도 변경됩니다. ETL 프로세스는 대상의 기존 데이터에 맞게 영국 단위를 미터법으로 변환하고, 표준 시간대를 변경하고, 정밀도를 높일 수 있습니다. 또한 ETL 프로세스는 새 데이터를 기존 데이터와 결합하여 보고를 최신 상태로 유지하거나 기존 데이터에 대한 추가 인사이트를 제공할 수 있습니다. 그런 다음, 보고 도구나 서비스 같은 애플리케이션이 데이터를 원하는 형식으로 사용할 수 있습니다.
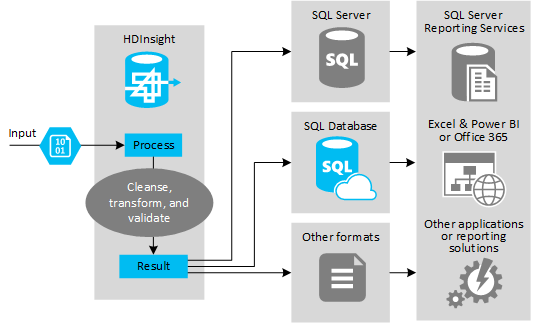
Hadoop은 일반적으로 대량의 텍스트 파일(예: CSV)을 가져오는 ETL 프로세스에서 사용됩니다. 또는 더 작지만 자주 변경되는 수의 텍스트 파일, 또는 두 가지 모두를 가져오는 경우에도 해당합니다. Hive는 데이터를 데이터 대상으로 로드하기 전에 데이터를 준비하는 데 사용할 수 있는 유용한 도구입니다. Hive를 사용하여 CSV를 통해 스키마를 만들고, SQL 유사 언어를 사용하여 데이터와 상호 작용하는 MapReduce 프로그램을 생성할 수 있습니다.
Hive를 사용하여 ETL을 수행하는 일반적인 단계는 다음과 같습니다.
데이터를 Azure Data Lake Storage 또는 Azure Blob Storage에 로드합니다.
Hive에서 스키마를 저장하는 데 사용할 메타데이터 저장소 데이터베이스(Azure SQL Database 사용)를 만듭니다.
HDInsight 클러스터를 만들고 데이터 저장소를 연결합니다.
데이터 저장소의 데이터에 대해 읽기 타임에 적용할 스키마를 정의합니다.
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';데이터를 변환하고 대상에 로드합니다. 변환 및 로드 중에 Hive를 사용하는 방법에는 여러 가지가 있습니다.
- Hive를 사용하여 데이터를 쿼리 및 준비하고, Azure Data Lake Store 또는 Azure Blob Storage에서 CSV로 저장합니다. 그런 후 SSIS(SQL Server Integration Services)와 같은 도구를 사용하여 해당 CSV를 획득한 후, SQL Server와 같은 대상 관계형 데이터베이스에 데이터를 로드합니다.
- Hive ODBC 드라이버를 사용하여 Excel 또는 C#에서 직접 데이터를 쿼리합니다.
- Apache Sqoop를 사용하여 준비된 플랫 CSV 파일을 읽고 대상 관계형 데이터베이스에 로드합니다.
데이터 원본
데이터 원본은 일반적으로 데이터 저장소의 기존 데이터와 일치시킬 수 있는 외부 데이터입니다. 예를 들면 다음과 같습니다.
- 데이터 파일을 생성하는 소셜 미디어 데이터, 로그 파일, 센서 및 애플리케이션
- 날씨 통계 또는 공급업체 판매 횟수와 같이 데이터 공급자에서 가져온 데이터 세트
- 적합한 도구 또는 프레임워크를 통해 캡처, 필터링 및 처리된 스트리밍 데이터
출력 대상
Hive를 사용하여 다음을 비롯한 다양한 종류의 대상으로 데이터를 출력할 수 있습니다.
- 관계형 데이터(예: SQL Server 또는 Azure SQL Database)
- Azure Synapse Analytics 등의 데이터 웨어하우스.
- Excel.
- Azure 테이블 및 Blob Storage
- 데이터를 특정 형식으로 또는 특정 형식의 정보 구조를 포함하는 파일로 처리해야 하는 애플리케이션 또는 서비스
- Azure Cosmos DB와 같은 JSON 문서 저장소.
고려 사항
ETL 모델은 일반적으로 다음 작업을 수행하려는 경우에 사용됩니다.
* 스트림 데이터나 외부 원본의 대량의 반정형 또는 비정형 데이터를 기존 데이터베이스 또는 정보 시스템으로 로드합니다.
* 클러스터를 통한 둘 이상의 변환 패스를 사용하는 방법 등을 통해 데이터를 로드하기 전에 데이터의 정리, 변환 및 유효성 검사를 수행합니다.
* 정기적으로 업데이트되는 보고서 및 시각화 요소를 생성합니다. 예를 들어, 보고서가 너무 길어서 낮 동안 생성할 수 없는 경우 밤에 실행되도록 보고서를 예약할 수 있습니다. Azure Logic Apps 및 PowerShell을 사용하여 Hive 쿼리를 자동으로 실행할 수 있습니다.
데이터에 대한 대상이 데이터베이스가 아닌 경우 쿼리 내에서 적절한 형식으로 파일을 생성할 수 있습니다(예: CSV). 그런 후 이 파일을 Excel 또는 Power BI로 가져올 수 있습니다.
ETL 프로세스의 일부로 해당 데이터에 대해 여러 작업을 실행해야 할 경우 관리 방법을 고려하세요. 작업이 솔루션 내의 워크플로가 아닌 외부 프로그램에 의해 제어되는 경우, 일부 작업을 동시에 실행할 수 있는지 결정해야 합니다. 또, 각 작업이 완료되는 시기를 검색해야 합니다. Hadoop 내에서 Oozie와 같은 워크플로 메커니즘을 사용하는 것이 외부 스크립트 또는 사용자 지정 프로그램을 사용하여 작업 시퀀스를 오케스트레이션하는 것보다 더 쉬울 수 있습니다.