Machine Learning 스튜디오(클래식)에서 모델 성능 평가
적용 대상: Machine Learning Studio(클래식)
Machine Learning Studio(클래식)  Azure Machine Learning
Azure Machine Learning
중요
Machine Learning Studio(클래식)에 대한 지원은 2024년 8월 31일에 종료됩니다. 해당 날짜까지 Azure Machine Learning으로 전환하는 것이 좋습니다.
2021년 12월 1일부터 새로운 Machine Learning Studio(클래식) 리소스를 만들 수 없습니다. 2024년 8월 31일까지는 기존 Machine Learning Studio(클래식) 리소스를 계속 사용할 수 있습니다.
- ML Studio(클래식)에서 Azure Machine Learning으로 기계 학습 프로젝트 이동에 대한 정보를 참조하세요.
- Azure Machine Learning에 대해 자세히 알아보세요.
ML Studio(클래식) 설명서는 사용 중지되며 나중에 업데이트되지 않을 수 있습니다.
이 문서에서는 Machine Learning 스튜디오(클래식)에서 모델 성능을 모니터링하는 데 사용할 수 있는 메트릭에 대해 알아봅니다. 모델 성능 평가는 데이터 과학 프로세스의 핵심 단계 중 하나입니다. 이는 학습된 모델에서 데이터 세트 점수 매기기(예측)에 성공한 정도를 나타냅니다. Machine Learning 스튜디오(클래식)에서는 두 가지 기본 기계 학습 모듈을 통해 모델 평가를 지원합니다.
이러한 모듈을 사용하여 기계 학습 및 통계에서 일반적으로 사용되는 여러 메트릭 면에서 모델의 성능을 확인할 수 있습니다.
모델 평가는 다음을 함께 고려해야 합니다.
다음 세 가지 일반적인 감독 학습 시나리오가 제공됩니다.
- 재발
- 이진 분류
- 다중 클래스 분류
평가 및 교차 유효성 검사
평가 및 교차 유효성 검사는 모델의 성능을 측정하는 표준 방법입니다. 둘 다 검사하거나 다른 모델과 비교할 수 있는 평가 메트릭을 생성합니다.
모델 평가에서는 점수가 매겨진 데이터 세트를 입력으로 사용해야 합니다(또는 두 가지 모델의 성능을 비교하려는 경우 2개의 데이터 세트 필요). 따라서 결과를 평가하려면 먼저 모델 학습 모듈을 사용하여 모델을 학습하고 모델 채점 모듈을 사용하여 일부 데이터 세트를 예측해야 합니다. 평가는 true 레이블과 함께 점수가 매겨진 레이블/확률을 기반으로 하며, 이 모두는 모델 점수 매기기 모듈에서 출력됩니다.
또는 교차 유효성 검사를 사용하여 입력 데이터의 여러 하위 집합에서 여러 학습-점수 매기기-평가 작업(접기 수 10)을 수행할 수 있습니다. 입력 데이터는 10개의 부분으로 분할되며, 하나는 테스트용으로 예약되고 나머지 9개는 학습용으로 예약됩니다. 이 프로세스가 10번 반복되어 평가 메트릭의 평균이 계산됩니다. 이는 모델이 새 데이터 세트에 얼마나 잘 일반화되는지를 결정하는 데 도움이 됩니다. 모델 교차 유효성 검사 모듈은 학습되지 않은 모델 및 레이블이 지정된 일부 데이터 세트를 사용하여 10번의 접기 각각에 대한 평가 결과를 평균 결과와 함께 출력합니다.
다음 섹션에서는 간단한 회귀 및 분류 모델을 빌드하고 모델 평가 및 모델 교차 유효성 검사 모듈을 둘 다 사용하여 해당 성능을 평가합니다.
회귀 모델 평가
크기, 마력, 엔진 사양 등의 특징을 사용하여 자동차 가격을 예측하려고 합니다. 이는 대상 변수(price)가 연속 숫자 값인 일반적인 회귀 문제입니다. 특정 자동차의 특징 값이 주어진 경우 해당 자동차의 가격을 예측할 수 있는 선형 회귀 모델을 적합화할 수 있습니다. 이 회귀 모델을 사용하여 학습한 동일한 데이터 세트의 점수를 매길 수 있습니다. 자동차 가격을 예측한 후에는 예측이 실제 가격에서 평균적으로 어느 정도 벗어났는지 확인하여 모델 성능을 평가할 수 있습니다. 이를 설명하기 위해 Machine Learning Studio(클래식)의 저장된 데이터 세트 섹션에 있는 '자동차 가격 데이터(원시) 데이터 세트'를 사용합니다.
실험 만들기
다음 모듈을 Machine Learning 스튜디오(클래식)의 작업 영역에 추가합니다.
아래 그림 1에 표시된 대로 포트를 연결하고 모델 학습 모듈의 레이블 열을 price로 설정합니다.
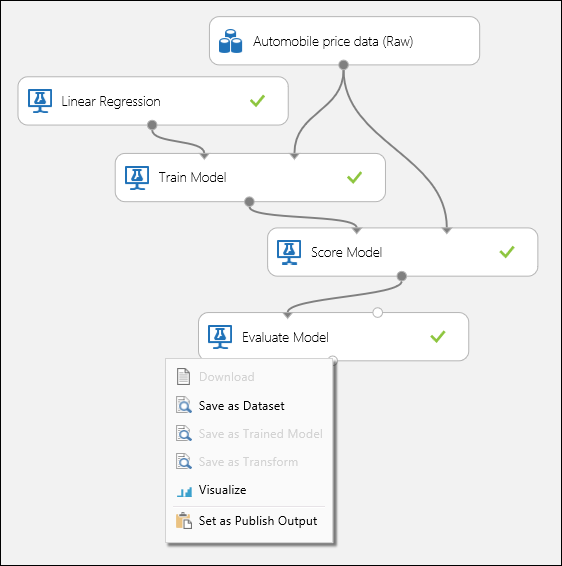
그림 1. 회귀 모델 평가
평가 결과 검사
실험을 실행한 후 모델 평가 모듈의 출력 포트를 클릭하고 시각화를 선택하여 평가 결과를 확인할 수 있습니다. 회귀 모델에 사용할 수 있는 평가 메트릭은 절대 평균 오차, 루트 절대 평균 오차, 상대 절대 오차, 상대 제곱된 오차 및 결정 계수입니다.
여기서 "오차"는 예측 값과 실제 값 간의 차이를 나타냅니다. 예측 값과 실제 값의 차이는 경우에 따라 음수일 수 있으므로 모든 인스턴스에서 오차의 총 크기를 캡처하기 위해 일반적으로 이 차이의 절대값 또는 제곱이 컴퓨팅됩니다. 오차 메트릭은 실제 값에서 예측 값의 평균 편차로 회귀 모델의 예측 성능을 측정합니다. 오차 값이 낮을수록 모델의 예측이 더 정확함을 의미합니다. 전체 오차 메트릭이 0이라는 것은 모델이 데이터에 완벽하게 적합하다는 의미입니다.
R 제곱이라고도 하는 결정 계수도 모델이 데이터에 적합한 정도를 측정하는 표준 방법입니다. 이는 모델에서 설명하는 변형의 비율로 해석될 수 있습니다. 이 경우 비율이 높을수록 좋으며, 1은 완벽한 적합을 나타냅니다.
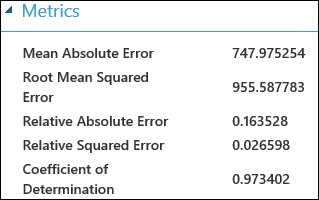
그림 2. 선형 회귀 평가 메트릭
교차 유효성 검사 사용
앞서 설명했듯이, 모델 교차 유효성 검사 모듈을 사용하여 반복적인 학습, 채점 및 평가를 자동으로 수행할 수 있습니다. 이 경우에는 데이터 세트, 학습되지 않은 모델 및 모델 교차 유효성 검사 모듈만 있으면 됩니다(아래 그림 참조). 모델 교차 유효성 검사 모듈에서 레이블 열을 price로 설정해야 합니다.
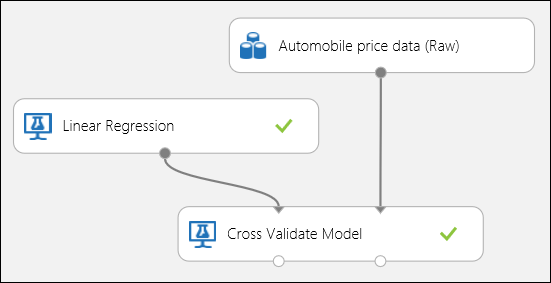
그림 3. 회귀 모델 교차 유효성 검사
실험을 실행한 후 모델 교차 유효성 검사 모듈의 오른쪽 출력 포트를 클릭하여 평가 결과를 검사할 수 있습니다. 각 반복(접기)에 대한 메트릭과 각 메트릭의 평균 결과에 대한 상세 보기가 제공됩니다(그림 4).
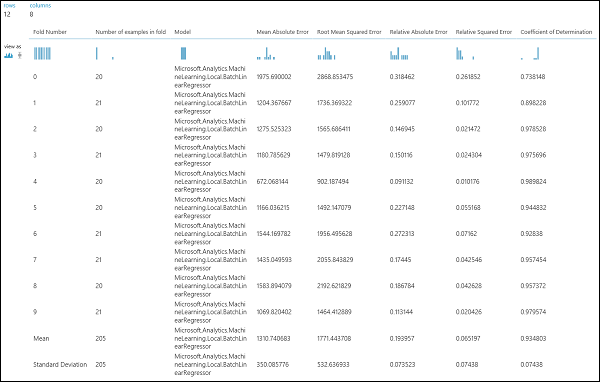
그림 4. 회귀 모델의 교차 유효성 검사 결과
이진 분류 모델 평가
이진 분류 시나리오에서는 대상 변수의 가능한 결과가 두 가지뿐입니다. 예를 들면 {0, 1} 또는 {false, true}, {negative, positive}입니다. 일부 인구 통계 및 고용 변수가 있는 성인 직원의 데이터 세트에서 값이 {“<=50K”, “>50K”}인 이진 변수로 소득 수준을 예측해 보겠습니다. 즉, 부정 클래스는 소득이 연간 50K 이하인 직원을 나타내고, 긍정 클래스는 다른 모든 직원을 나타냅니다. 회귀 시나리오와 마찬가지로 모델을 학습하고, 일부 데이터의 점수를 매긴 다음, 결과를 평가합니다. 가장 큰 차이점은 Machine Learning 스튜디오(클래식)에서 컴퓨팅하고 출력하는 메트릭의 선택입니다. 소득 수준 예측 시나리오를 보여 주기 위해 Adult 데이터 세트를 사용하여 Studio(클래식) 실험을 만들고, 일반적으로 사용되는 이진 분류자인 2클래스 로지스틱 회귀 모델의 성능을 평가합니다.
실험 만들기
다음 모듈을 Machine Learning 스튜디오(클래식)의 작업 영역에 추가합니다.
- 성인 인구 조사 소득 이진 분류 데이터 세트
- 2클래스 로지스틱 회귀
- 모델 학습
- 모델 채점
- 모델 평가
아래 그림 5에 표시된 대로 포트를 연결하고 모델 학습 모듈의 레이블 열을 income으로 설정합니다.
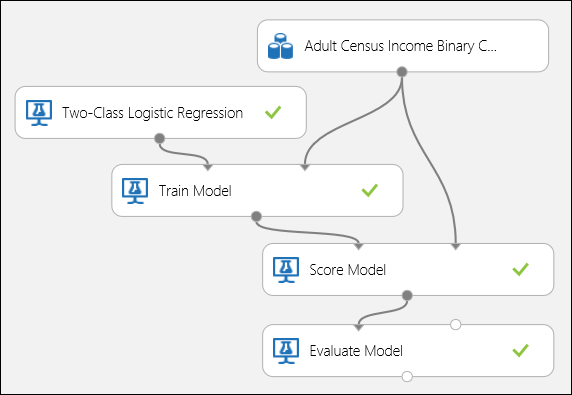
그림 5. 이진 분류 모델 평가
평가 결과 검사
실험을 실행한 후 모델 평가 모듈의 출력 포트를 클릭하고 시각화를 선택하여 평가 결과를 확인할 수 있습니다(그림 7). 이진 분류 모델에 사용할 수 있는 평가 메트릭은 정확도, 전체 자릿수, 재현율, F1 점수 및 AUC입니다. 또한 이 모듈은 ROC, 전체 자릿수/재현율 및 양력 곡선뿐만 아니라 참 긍정, 거짓 부정, 거짓 긍정 및 참 부정 수를 보여 주는 혼동 행렬을 출력합니다.
정확도는 올바르게 분류된 인스턴스의 비율일 뿐입니다. 이는 일반적으로 분류자를 평가할 때 확인하는 첫 번째 메트릭입니다. 그러나 테스트 데이터가 불균형하거나(대부분의 인스턴스가 클래스 중 하나에 속한 경우) 클래스 중 하나에 대한 성능에 더 많은 관심이 있는 경우 정확도는 실제로 분류자의 효과를 캡처하지 못합니다. 소득 수준 분류 시나리오에서는 인스턴스의 99%가 연간 소득이 50K 이하인 사람을 나타내는 일부 데이터를 테스트하는 것으로 가정합니다. 0.99의 정확도는 모든 인스턴스에 대해 “<=50K” 클래스를 예측하여 달성할 수 있습니다. 이 경우 분류자는 전반적으로 양호한 것처럼 보이지만 실제로는 고소득자(1%)를 올바르게 분류하지 못합니다.
따라서 평가의 보다 특정한 측면을 캡처하는 추가 메트릭을 계산하는 것이 좋습니다. 이러한 메트릭에 대해 자세히 알아보기 전에 이진 분류 평가의 혼동 행렬을 이해해야 합니다. 학습 집합의 클래스 레이블은 일반적으로 긍정 또는 부정이라는 두 가지 가능한 값만 취할 수 있습니다. 분류자가 올바르게 예측한 긍정 및 부정 인스턴스를 각각 TP(참 긍정) 및 TN(참 부정)이라고 합니다. 마찬가지로 잘못 분류된 인스턴스는 FP(거짓 긍정) 및 FN(거짓 부정)이라고 합니다. 혼동 행렬은 이 네 가지 범주 각각에 속하는 인스턴스 수를 보여 주는 테이블입니다. Machine Learning 스튜디오(클래식)에서는 데이터 세트의 두 클래스 중 긍정 클래스를 자동으로 결정합니다. 클래스 레이블이 부울 또는 정수인 경우에는 'true' 또는 '1' 레이블이 지정된 인스턴스에 긍정 클래스가 할당됩니다. income 데이터 세트처럼 레이블이 문자열인 경우 레이블이 사전순으로 정렬되고 첫 번째 수준은 부정 클래스로, 두 번째 수준은 긍정 클래스로 선택됩니다.
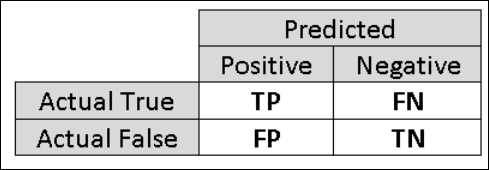
그림 6. 이진 분류 혼동 행렬
소득 분류 문제로 다시 돌아가, 사용된 분류자의 성능을 이해하는 데 도움이 되는 몇 가지 평가 질문을 해보겠습니다. 자연스럽게 나오게 되는 질문은 ‘모델에서 소득이 >50K(TP+FP)인 것으로 예측한 개인 중 올바르게 분류된(TP) 개인은 몇 명인가?’입니다. 이 질문에 대한 답은 올바르게 분류된 긍정의 비율인 모델의 정확도 , 즉 TP/(TP+FP)를 확인하여 얻을 수 있습니다. 또 다른 일반적인 질문은 ‘소득이 >50k(TP+FN)인 모든 고소득 직원 중 분류자가 올바르게 분류한(TP) 직원은 몇 명인가?’입니다. 이는 실제로 재현율또는 참 긍정 비율, 즉 분류자의 TP/(TP+FN)입니다. 정확도와 재현율 사이에는 명확한 반비례 관계가 있는 것을 볼 수 있습니다. 예를 들어 비교적 균형 잡힌 데이터 세트에서 주로 긍정 인스턴스를 예측하는 분류자는 재현율이 높지만 대부분의 거짓 인스턴스가 잘못 분류되어 많은 거짓 긍정이 발생하므로 정확도가 낮습니다. 이 두 메트릭이 어떻게 달라지는지에 대한 그림을 보려면 평가 결과 출력 페이지에서 정확도/재현율 곡선(그림 7의 왼쪽 위)을 클릭하면 됩니다.
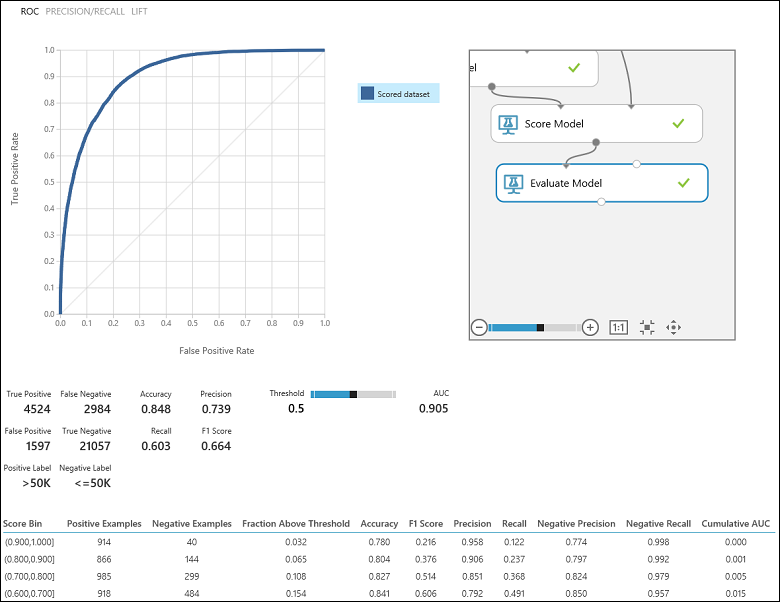
그림 7. 이진 분류 평가 결과
자주 사용되는 또 다른 관련 메트릭은 정확도와 재현율을 둘 다 고려하는 F1 점수입니다. 이는 이 두 메트릭의 조화 평균이며, 다음과 같이 계산됩니다. F1 = 2 (정확도 x 재현율) / (정확도 + 재현율). F1 점수는 평가를 단일 숫자로 요약하는 데 적합한 방법이지만 분류자의 동작 방식을 보다 잘 이해하려면 항상 정확도와 재현율을 함께 확인하는 것이 좋습니다.
또한 ROC(Receiver Operating Characteristic) 곡선에서 참 긍정 비율과 거짓 긍정 비율을 검사하고 해당 AUC(Area Under the Curve) 값을 확인할 수 있습니다. 이 곡선이 왼쪽 위 모서리에 가까울수록 분류자의 성능이 좋습니다(참 긍정 비율이 최대화되고 거짓 긍정 비율이 최소화됨). 그림의 대각선에 가까운 곡선은 예측 경향이 임의 추측에 가까운 분류자의 결과입니다.
교차 유효성 검사 사용
회귀 예제처럼 교차 유효성 검사를 수행하여 데이터의 여러 하위 집합에 대해 반복적인 학습, 채점 및 평가를 자동으로 수행할 수 있습니다. 마찬가지로 모델 교차 유효성 검사 모듈, 학습되지 않은 로지스틱 회귀 분석 모델 및 데이터 세트를 사용할 수 있습니다. 레이블 열은 모델 교차 유효성 검사 모듈의 속성에서 income으로 설정되어야 합니다. 실험을 실행한 후 모델 교차 유효성 검사 모듈의 오른쪽 출력 포트를 클릭하면 각 접기에 대한 이진 분류 메트릭 값과 각각의 평균 및 표준 편차를 볼 수 있습니다.
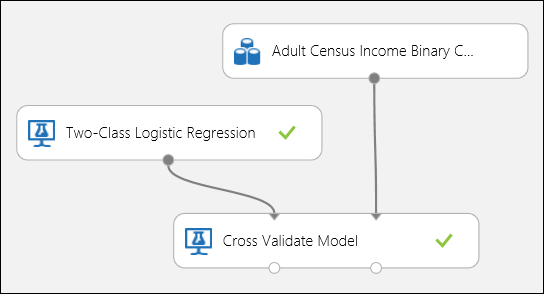
그림 8. 이진 분류 모델 교차 유효성 검사
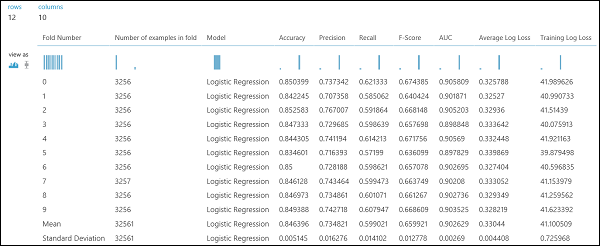
그림 9. 이진 분류자의 교차 유효성 검사 결과
다중 클래스 분류 모델 평가
이 실험에서는 널리 사용되는 아이리스 데이터 세트를 사용합니다. 여기에는 아이리스 식물의 세 가지 유형(클래스)의 인스턴스가 포함되어 있습니다. 각 인스턴스에 대해 4개의 기능 값(꽃받침 길이/너비 및 꽃잎 길이/너비)이 있습니다. 이전 실험에서 동일한 데이터 세트를 사용하여 모델을 학습하고 테스트했습니다. 여기서는 데이터 분할 모듈을 사용하여 데이터의 하위 집합 2개를 만들고 첫 번째 하위 집합을 학습한 후 두 번째 하위 집합의 점수를 매기고 평가합니다. Iris 데이터 세트는 UCI Machine Learning 리포지토리에서 공개적으로 사용할 수 있으며, 데이터 가져오기 모듈을 사용하여 다운로드할 수 있습니다.
실험 만들기
다음 모듈을 Machine Learning 스튜디오(클래식)의 작업 영역에 추가합니다.
아래의 그림 10과 같이 포트를 연결합니다.
모델 학습 모듈의 레이블 열 인덱스를 5로 설정합니다. 이 데이터 세트에는 헤더 행이 없지만 클래스 레이블이 다섯 번째 열에 있다는 것을 알고 있습니다.
데이터 가져오기 모듈을 클릭하고 데이터 원본 속성을 HTTP 통해 웹 URL로, URL을 http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data로 설정합니다.
데이터 분할 모듈에서 학습에 사용할 인스턴스 부분을 설정합니다(이 예의 경우 0.7).
그림 10. 다중 클래스 분류자 평가
평가 결과 검사
실험을 실행하고 모델 평가의 출력 포트를 클릭합니다. 이 경우 평가 결과가 혼동 행렬 형식으로 제공됩니다. 행렬에는 세 클래스 모두에 대해 실제 인스턴스와 예측 인스턴스가 표시됩니다.
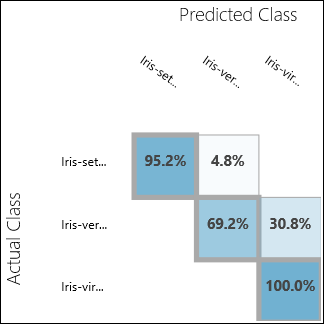
그림 11. 다중 클래스 분류 평가 결과
교차 유효성 검사 사용
앞서 설명했듯이, 모델 교차 유효성 검사 모듈을 사용하여 반복적인 학습, 채점 및 평가를 자동으로 수행할 수 있습니다. 데이터 세트, 학습되지 않은 모델 및 모델 교차 유효성 검사 모듈이 필요합니다(아래 그림 참조). 모델 교차 유효성 검사 모듈의 레이블 열을 설정해야 합니다(이 예의 경우 열 인덱스 5). 실험을 실행한 후 모델 교차 유효성 검사 모듈의 오른쪽 출력 포트를 클릭하면 각 접기에 대한 메트릭 값과 평균 및 표준 편차를 검사할 수 있습니다. 여기에 표시된 메트릭은 이진 분류 예제에서 설명한 메트릭과 유사합니다. 그러나 다중 클래스 분류에서는 전체 긍정 또는 부정 클래스가 없기 때문에 참 긍정/부정 및 거짓 긍정/부정이 클래스 단위로 계산됩니다. 예를 들어 'Iris-setosa' 클래스의 정확도 또는 재현율을 계산할 때 이것은 긍정 클래스이고 나머지는 모두 부정 클래스인 것으로 가정합니다.
그림 12. 다중 클래스 분류 모델 교차 유효성 검사
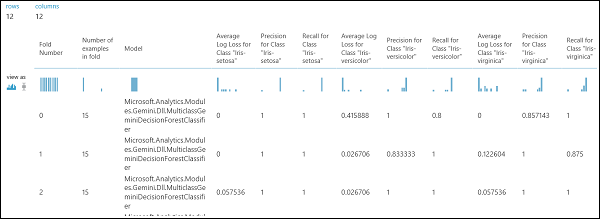
그림 13. 다중 클래스 분류 모델의 교차 유효성 검사 결과