Datu importēšanas un eksportēšanas darbu pārskats
Datu importēšanas un eksportēšanas darbu izveidei un pārvaldībai tiek izmantota darbvieta Datu pārvaldība. Pēc noklusējuma datu importēšanas un eksportēšanas process izveido sagatavošanas tabulu katram elementam mērķa datu bāzē. Sagatavošanas tabulas pirms jums ļauj datus pārbaudīt, iztīrīt vai konvertēt, pirms tos pārvietojat.
Piezīme
Šajā rakstā tiek pieņemts, ka pārzināt datu elementus.
Datu importēšanas/eksportēšanas process
Tālāk ir aprakstītas darbības datu importēšanai vai eksportēšanai.
Izveidojiet importēšanas vai eksportēšanas darbu, kur jūs izpildāt tālāk uzskaitītos uzdevumus.
- Definējiet projekta kategoriju.
- Norādiet importējamos vai eksportējamos elementus.
- Iestatiet darba datu formātu.
- Norādiet elementu secību, lai tie tiktu apstrādāti loģiskās grupās un saprotamā secībā.
- Nosakiet, vai izmantot sagatavošanas tabulas.
Pārliecinieties, vai avota dati un mērķa dati ir kartēti pareizi.
Pārbaudiet sava importēšanas vai eksportēšanas darba drošību.
Palaidiet importēšanas vai eksportēšanas darbu.
Pārbaudiet, vai darba norise notiek, kā paredzēts, pārskatot darba vēsturi.
Iztīriet sagatavošanas tabulas.
Atlikušajās raksta sadaļās ir sniegta plašāka informāciju par katru šī procesa posmu.
Piezīme
Lai atsvaidzinātu datu importēšanas/eksportēšanas veidlapu un tajā tiktu rādīta jaunākā informācija par norisi, izmantojiet veidlapas atsvaidzināšanas ikonu. Pārlūka līmeņa atsvaidzināšana nav ieteicama, jo tā pārtrauks visus importēšanas/eksportēšanas darbus, kas nedarbojas partijā.
Importēšanas vai eksportēšanas darba izveidošana
Datu importēšanas vai eksportēšanas darbu var palaist vienu reizi vai vairākas reizes.
Projekta kategorijas definēšana
Iesakām jums veltīt laiku tam, lai savam importēšanas vai eksportēšanas darbam atlasītu atbilstošu projektu kategoriju. Projektu kategorijas var jums palīdzēt saistīto darbu pārvaldīšanā.
Importējamo vai eksportējamo elementu norādīšana
Importēšanas vai eksportēšanas darbiem varat pievienot konkrētus elementus vai atlasīt izmantojamo veidni. Veidnes darbu aizpilda ar elementu sarakstu. Opcija Lietot veidni ir pieejama pēc tam, kad darbam piešķirat nosaukumu un šo darbu saglabājat.
Darba datu formāta iestatīšana
Kad atlasāt kādu elementu, ir jāatlasa formāts tiem datiem, kas tiks eksportēti vai importēti. Formātus jūs definējat, izmantojot elementu Datu avotu iestatīšana. Avota datu formāts sastāv no atribūtiem Tips, Faila formāts, Rindas norobežotājs un Kolonnas norobežotājs. Pastāv arī citi atribūti, bet minētie ir vissvarīgākie. Sekojošajā tabulā ir minētas derīgās kombinācijas.
| Faila formāts | Rindas/kolonnas norobežotājs | XML stils |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | XML-elements XML-atribūts |
| Norobežots, fiksēts platums | Komats, semikols, tabulēšanas rakstzīme, vertikālā josla, kols | -NA- |
Piezīme
Ir svarīgi Rindas norobežotājam, Kolonnu norobežotājam un Teksta kvalificētājam atlasīt pareizu vērtību, ja Faila formāta opcija ir iestatīta uz Norobežots. Pārliecinieties, vai datos nav ietverta rakstzīme, kas tiek lietota kā norobežotājs vai ierobežotājs, jo tādējādi importēšanas un eksportēšanas laikā var rasties kļūdas.
Piezīme
Uz XML balstītiem failu formātiem izmantojiet tikai juridiskās rakstzīmes. Papildinformāciju par derīgām rakstzīmēm skatiet sadaļā Derīgas rakstzīmes XML 1.0. XML 1.0 neatļauj nekādas kontroles rakstzīmes, izņemot cilnes, karietes atgriešanas un rindu plūsmas. Nelegālu rakstzīmju piemēri ir kvadrātiekavas, cirtainas iekavas un slīpsvītras.
Lai importētu vai eksportētu datus, izmantojiet Unicode, nevis konkrētu kodu lapu. Tas palīdz nodrošināt konsekventākos rezultātus un novērst datu pārvaldības uzdevumus, kas neizdodas, jo tajos ir iekļautas unikoda rakstzīmes. Visiem sistēmas definētajiem avota datu formātiem, kas izmanto Unicode, avota nosaukumā ir Unicode . Unikoda formāts tiek lietots, cilnē Reģionālie iestatījumi atlasot Unikoda kodēšanas ANSI koda lapu kā Koda lapu . Atlasiet vienu no šīm kodu lapām Unicode:
| Kodu lapa | Parādāmais vārds/nosaukums |
|---|---|
| 1200 | Unikods |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Papildinformāciju par kodu lapām skatiet sadaļā Kodu lapu identifikatori.
Elementu secības norādīšana
Datu veidnē vai importēšanas un eksportēšanas darbos elementus var izkārtot noteiktā secībā. Kad palaižat darbu, kurā ir vairāki datu elementi, jums ir pārliecinās, vai šie datu elementi ir sakārtoti pareizā secībā. Elementu secību jūs galvenokārt norādāt tā, lai varētu ievērot visas funkcionālās atkarības starp elementiem. Ja elementiem nav funkcionālo atkarību, tad tos var ieplānot paralēlai importēšanai vai eksportēšanai.
Izpildes vienības, līmeņi un secības
Izpildes vienība, līmenis izpildes vienībā un elementu secība palīdzēt kontrolēt kārtību, kādā dati tiek eksportēti vai importēti.
- Elementi citās izpildes vienībās tiek apstrādāti paralēli.
- Katrā izpildes vienībā elementi tiek apstrādāti paralēli, ja tiem ir viens līmenis.
- Katrā līmenī elementi tiek apstrādāti atbilstoši to kārtas numuram attiecīgajā līmenī.
- Kad viens līmenis ir apstrādāts, tiek apstrādāts nākamais līmenis.
Atkārtota secības norādīšana
Elementu secību varat vēlēties norādīt no jauna tālāk uzskaitītajos gadījumos.
- Ja visām jūsu izmaiņām tiek lietots tikai viens datu darbs, tad atkārtotas secības norādīšanas opcijas varat izmantot, lai optimizētu pilnā darba izpildes laiku. Šajos gadījumos varat izmantot izpildes vienību, lai pārstāvētu moduli, varat izmantot līmeni, lai pārstāvētu moduļa līdzekļa apgabalu, un izmantot secību, lai pārstāvētu elementu. Izmantojot šo metodi, varat strādāt dažādos moduļos paralēli, bet katrā modulī joprojām varat strādāt secībā. Lai palīdzētu nodrošināt, ka paralēlās operācijas norit sekmīgi, ir jāņem vērā visas atkarības.
- Ja tiek lietoti vairāki datu darbi (piemēram, viens darbs katram modulim), tad secības noteikšanu varat izmantot, lai ietekmētu elementu līmeni un secību optimālai izpildīšanai.
- Ja atkarību nav vispār, tad maksimālas optimizēšanas nolūkos elementus varat sakārtot dažādās izpildes vienībās.
Izvēlne Atkārtota secības norādīšana ir pieejama, ja ir atlasīti vairāki elementi. Secību varat atkārtoti norādīt, pamatojoties uz izpildes vienības, līmeņa vai secības opcijām. Lai atkārtoti norādītu secību atlasītiem elementiem, varat izmantot kādu soli. Katram elementam atlasītā vienība, līmenis un/vai kārtas numurs tiek atjaunināts ar norādīto soli.
Kārtošana
Lai elementu sarakstu skatītu secības kārtībā, varat izmantot opciju Kārtot pēc.
Apciršana
Importa projektiem varat izlemt, ka ieraksti entītijās pirms importēšanas ir jāapcērt. Saīsināšana ir noderīga, ja ieraksti jāimportē tīrā tabulu komplektā. Pēc noklusējuma šis iestatījums ir izslēgts.
Pārliecināšanās, vai avota dati un mērķa dati ir kartēti pareizi
Kartēšana ir funkcija, kas attiecas gan uz importēšanas, gan uz eksportēšanas darbiem.
- Saistībā ar importēšanas darbu kartēšanas apraksta, kuras kolonnas avota failā kļūst par kolonnām sagatavošanas tabulā. Tādēļ sistēma var noteikt, kuras avota faila kolonnas dati ir jākopē kurā sagatavošanas tabulas kolonnā.
- Saistībā ar eksportēšanas darbu kartēšanas apraksta, kuras sagatavošanas tabulas (t.i., avota) kolonnas kļūst par kolonnām mērķa failā.
Ja kolonnu nosaukumi sagatavošanas tabulā atbilst nosaukumiem failā, tad sistēma kartējumu izveido automātiski, pamatojoties uz nosaukumiem. Taču, ja nosaukumi atšķiras, kolonnas netiek kartētas automātiski. Šādos gadījumos jums ir jāizpilda kartēšana, datu darbā atlasot elementa opciju Skatīt karti.
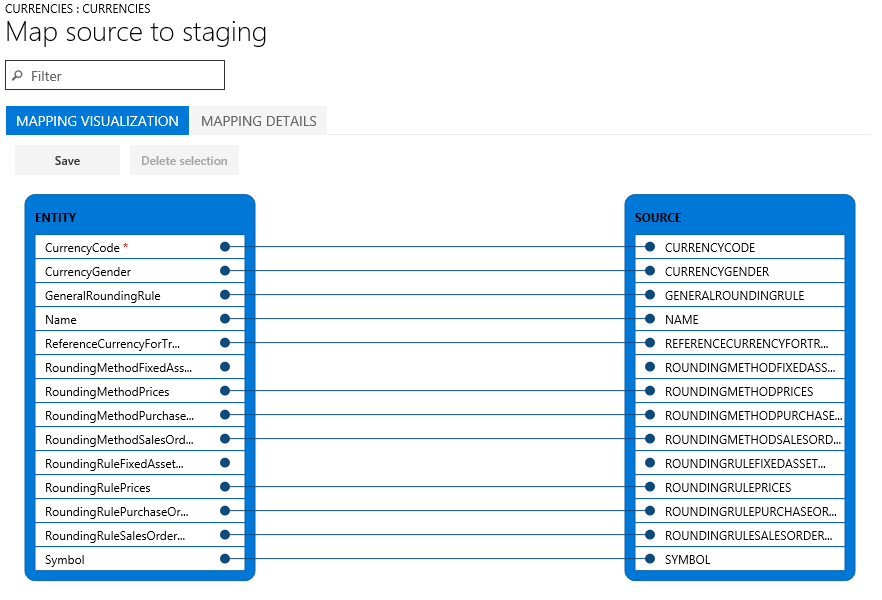
Pastāv divi kartēšanas skati: Kartēšanas vizualizēšana, kurš ir noklusējuma skats, un Detalizēta informācija par kartēšanu. Sarkana zvaigznīte (*) norāda visus elementa obligātos laukus. Lai varētu strādāt ar elementu, ir jānorāda šo lauku kartējums. Kad strādājat ar elementu, ja nepieciešams, varat atcelt kartējumu citiem laukiem. Lai atceltu kartējumu kādam laukam, atzīmējiet šo lauku kolonnā Elements vai kolonnā Avots un pēc tam atlasiet Dzēst atlasi. Atlasiet Saglabāt, lai saglabātu veiktās izmaiņas, un pēc tam aizveriet lapu, lai atgrieztos pie projekta. Šo pašu procesu varat izmantot, lai pēc importēšanas rediģētu lauku kartējumu no avota uz sagatavošanu.
Kartējumu lapā varat ģenerēt, atlasot Ģenerēt avota kartējumu. Ģenerēts kartējums darbojas tāpat kā automātisks kartējums. Tādēļ visi nekartētie lauki jums ir jākartē manuāli.
Sava importēšanas vai eksportēšanas darba drošības pārbaudīšana
Piekļuve darbvietai Datu pārvaldība var būt ierobežota, lai lietotāji bez administratora tiesībām varētu piekļūt tikai noteiktiem datu darbiem. Piekļuve datu darbam tostarp nozīmē pilnu piekļuvi šī darba izpildes vēsturei un piekļuvi sagatavošanas tabulām. Tādēļ, kad veidojat datu darbu, jums ir jāpārliecinās, vai tiek izmantotas atbilstošas piekļuves kontroles.
Darba nodrošināšana pēc lomām un lietotājiem
Lai piekļuvi darbam atļautu tikai vienai vai vairākām drošības lomām, izmantojiet izvēlni Piemērojamās lomas. Šim darbam varēs piekļūt tikai lietotāji ar šīm lomām.
Piekļuvi darbam varat arī sniegt tikai konkrētiem lietotājiem. Kad darbu nodrošināt pēc lietotājiem, nevis pēc lomām, tad notiek lielāka kontrole, ja vienai lomai ir piešķirti vairāki lietotāji.
Darba nodrošināšana pēc juridiskajās personas
Datu darbi ir globāla rakstura. Tādēļ, ja datu darbs tika izveidots un izmantots kādā juridiskajā personā, tad šis darbs būs redzams citās sistēmas juridiskajās personās. Šai noklusējuma uzvedībai var tikt dota priekšroka noteiktos lietojuma scenārijos. Piemēram, organizācija, kas importē rēķinus, izmantojot datu elementus, var nodrošināt centralizēta rēķinu apstrādes darba grupu, kas ir atbildīga par rēķinu kļūdu pārvaldīšanu visās organizācijas nodaļās. Šādā scenārijā centralizētajai rēķinu apstrādes darba grupai var noderēt piekļuve rēķinu importēšanas darbiem no visām juridiskajām personām. Tādēļ noklusējuma uzvedība atbilst prasībām no juridiskās personas perspektīvas.
Taču organizācija var vēlēties, lai rēķinu apstrādes darba grupas darbotos katrā juridiskajā personā. Šajā gadījumā darba grupai kādā juridiskajā personā ir nepieciešama piekļuve tikai rēķinu importēšanas darbam savā juridiskajā personā. Lai izpildītu šo prasību, datu darbiem varat konfigurēt no juridiskās personas atkarīgu piekļuves kontroli, datu darbā izmantojot izvēlni Piemērojamās juridiskās personas. Kad konfigurēšana ir pabeigta, lietotāji var redzēt tikai darbus, kas ir pieejami tajā juridiskajā personā, kurā šie lietotāji pašlaik ir pierakstījušies. Lai redzētu darbus no citas juridiskās personas, lietotājiem ir jāpārslēdzas uz attiecīgo juridisko personu.
Darbu var vienlaikus nodrošināt pēc lomām, lietotājiem un juridiskajām personām.
Importēšanas vai eksportēšanas darba palaišana
Darbu varat palaist vienu reizi, pēc darba definēšanas atlasot pogu Importēt vai Eksportēt. Lai iestatītu periodisko darbu, atlasiet Izveidot periodisku datu darbu.
Piezīme
Importēšanas vai eksportēšanas darbu var izpildīt, atlasot pogu Importēt vai Eksportēt. Tas ieplānos, ka partijas darbs tiks izpildīts tikai vienu reizi. Darbs var netikt izpildīts nekavējoties, ja partijas pakalpojumu aizkavē partijas pakalpojuma noslodze. Darbus arī var izpildīt sinhroni, atlasot Importēt tūlīt vai Eksportēt tūlīt. Tas sāk darbu nekavējoties un ir noderīgi, ja partijas izpilde netiek uzsākta aizkaves dēļ. Darbus var ieplānot arī izpildīšanai vēlāk. To var izdarīt, izvēloties opciju Izpildīt partijā. Uz partijas resursiem attiecas ierobežošana, tādēļ pakešuzdevuma izpilde var nenotikt nekavējoties. Partijas izmantošana ir ieteicamā opcija, jo tā palīdzēs arī ar lielu datu apjomu, kas ir jāimportē vai jāeksportē. Pakešuzdevumus var plānot izpildei noteiktā pakešuzdevumu grupā — tas sniedz lielāku kontroli slodzes līdzsvarošanas ziņā.
Pārbaudīšana, vai darba norise notiek paredzētajā veidā
Gan eksportēšanas, gan importēšanas darbiem problēmu novēršanai un izmeklēšanai ir pieejama darbu vēsture. Vēsturiskās darbu izpildes ir sakārtotas pēc laika diapazoniem.
Par katru darba palaišanu ir tālāk aprakstītā detalizētā informācija.
- Detalizēta informācija par izpildi
- Izpildes žurnāls
Detalizēta informācija par izpildi rāda stāvokli katram datu elementam, kuru šis darbs apstrādāja. Tādēļ jūs varat ātri atrast tālāk uzskaitīto informāciju.
- Kuri elementi tika apstrādāti.
- Attiecībā uz elementu — cik ierakstu tika sekmīgi apstrādāti un cik daudzi bija nesekmīgi.
- Sagatavošanas posmu ieraksti katram elementam.
Sagatavošanas posmu datus eksportēšanas darbiem varat lejupielādēt failā, vai importēšanas un eksportēšanas darbiem tos varat lejupielādēt kā paketi.
No detalizētas informācijas par izpildi varat arī atvērt izpildes žurnālu.
Paralēlais imports
Lai paātrinātu datu importu, var iespējot paralēlu faila importēšanu, ja elements atbalsta paralēlo importu. Lai konfigurētu paralēlo importu elementam, ir jāievēro šādi soļi.
Dodieties uz Sistēmas administrēšana > Darbvietas > Datu pārvaldība.
Sadaļā Importēšana/eksportēšana atlasiet elementu Struktūras parametri, lai atvērtu lapu Datu importēšanas/eksportēšanas struktūras parametri.
Cilnē Elementa iestatījumi atlasiet Konfigurēt elementa izpildes parametrus, lai atvērtu lapu Elementa importēšanas izpildes parametri.
Iestatiet šādus laukus, lai konfigurētu paralēlo importu elementam:
- Laukā Elements atlasiet juridisko personu. Ja entītijas lauks ir tukšs, tukšā vērtība tiek izmantota kā noklusējuma iestatījums visiem turpmākajiem importiem, ja entītija atbalsta paralēlo importēšanu.
- Laukā Importa sliekšņa ierakstu skaits ievadiet sliekšņa ierakstu skaitu importam. Tas nosaka ierakstu skaits, ko apstrādā pavediens. Ja failam ir 10 000 ierakstu, 2500 ieraksti ar uzdevumu skaitu 4 nozīmē, ka katrs pavediens apstrādās 2500 ierakstus.
- Laukā Importēt uzdevumu skaitu ievadiet importa uzdevumu skaitu. Tas nedrīkst pārsniegt maksimālo partijas pavedienu skaitu, kas piešķirts pakešveida apstrādei Sistēmas administrēšanā >Servera konfigurācijā.
Darbu vēstures tīrīšana
Pēc noklusējuma darbu vēstures ieraksti un saistītie stadiju tabulas dati, kas ir vecāki par 90 dienām, tiks automātiski dzēsti. Darba vēstures tīrīšanas funkcionalitāti datu pārvaldībā var izmantot, lai konfigurētu periodisku izpildes vēstures tīrīšanu ar mazāku saglabāšanas periodu nekā šis noklusējuma iestatījums. Šī funkcionalitāte aizstāj iepriekšējo sagatavošanas posmu tabulas tīrīšanas funkcionalitāti, kas tagad ir novecojusi. Tālāk minētās tabulas tiks tīrītas, izmantojot tīrīšanas procesu.
Visas inscinējuma tabulas
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
Izpildes vēstures tīrīšanas funkcijai var piekļūt no Datu pārvaldības > Darbu vēstures tīrīšanas.
Parametru plānošana
Plānojot tīrīšanas procesu, ir jānorāda tālāk norādītie parametri, lai definētu tīrīšanas kritērijus.
Vēstures saglabāšanas dienu skaits — šis iestatījums tiek izmantots, lai kontrolētu izpildes vēstures apjomu, kas jāsaglabā. Vēsture ir norādīta dienu skaitā. Kad tīrīšanas darbs ir ieplānots kā periodisks pakešuzdevums, šis iestatījums darbosies kā pastāvīgi kustīgs logs, tādējādi vienmēr atstājot norādītā dienu skaita vēsturi neskartu un dzēšot pārējo. Noklusējums ir 7 dienas.
Darba izpildes stundu skaits — atkarībā no notīrāmā vēstures apjoma kopējais tīrīšanas darba izpildes laiks var būt robežās no dažām minūtēm līdz dažām stundām. Šim parametram ir jābūt iestatītam uz to stundu skaitu, cik ilgā darbs tiks izpildīts. Kad tīrīšanas darbs ir izpildīts noteiktam stundu skaitam, darbs tiks aizvērts un atsāks tīrīšanu nākamreiz, kad tas tiks palaists, pamatojoties uz atkārtošanās grafiku.
Maksimālo izpildes laiku var norādīt, iestatot maksimālo ierobežojumu stundu skaitam, kad darbs ir jāpalaiž, izmantojot šo iestatījumu. Tīrīšanas loģika izpaužas kā viena darba izpildes ID vienā laikā hronoloģiski sakārtotā secībā, saistītās izpildes vēstures tīrīšanā pirmo notīrot vecāko. Tas pārtrauks jauna izpildes ID pieņemšanu, ja atlikušais izpildes ilgums ir pēdējo 10 % robežās no norādītā ilguma. Dažos gadījumos tiks prognozēts, ka tīrīšanas darbs turpināsies pēc norādītā maksimālā laika. Tas lielā mērā būs atkarīgs no to ierakstu skaita, kuri tiks dzēsti pašreizējam izpildes ID, kas tika sākts pirms 10 % sliekšņa sasniegšanas. Sāktā tīrīšana ir jāpabeidz, lai nodrošinātu datu integritāti, kas nozīmē, ka tīrīšana turpināsies, neraugoties uz noteiktā ierobežojuma pārsniegšanu. Kad tas ir pabeigts, jauni izpildes ID netiek pieņemti, un tīrīšanas darbs tiek pabeigts. Atlikusī izpildes vēsture, kas netika iztīrīta pietiekama izpildes laika trūkuma dēļ, tiks izvēlēta nākamajā reizē, kad ieplānots tīrīšanas darbs. Noklusējuma un minimālā vērtība šim iestatījumam ir iestatīta uz 2 stundām.
Periodiska partija — tīrīšanas darbu var palaist kā vienreizēju, manuālu izpildi vai arī to var plānot periodiskai izpildei partijā. Partiju var ieplānot, izmantojot iestatījumus Palaist fonā, kas ir partijas standarta iestatījums.
Piezīme
Ja darbu vēstures tīrīšanas līdzeklis netiek izmantots, izpildes vēsture, kas vecāka par 90 dienām, joprojām tiek automātiski dzēsta. Papildus šai automātiskajai dzēšanai var palaist darbu vēstures tīrīšanu. Pārliecinieties, vai tīrīšanas darbs ir ieplānots atkārtoti. Kā paskaidrots iepriekš, jebkurā tīrīšanas izpildē darbs attīrīs tikai tik daudz izpildes ID, cik tas ir iespējams norādītā maksimālo stundu laikā.
Darba vēstures tīrīšana un arhivēšana
Darba vēstures tīrīšanas un arhivēšanas funkcionalitāte aizstāj tīrīšanas funkcionalitātes iepriekšējās versijas. Šajā sadaļā tiks izskaidrotas šīs jaunās iespējas.
Viena no galvenajām izmaiņām tīrīšanas funkcionalitātē ir sistēmas partijas darba izmantošana vēstures tīrīšanai. Sistēmas partijas darba izmantošana ļauj finanšu un operāciju programmām automātiski ieplānot tīrīšanas partijas darbu un palaist to, tiklīdz sistēma ir gatava. Vairs nav nepieciešams manuāli ieplānot partijas darbu. Šajā noklusējuma izpildes režīmā partijas darbs tiks izpildīts katru stundu, sākot no pusnakts, un saglabās izpildes vēsturi par iepriekšējām 7 dienām. Iztīrītā vēsture tiek arhivēta turpmākai izguvei. Sākot ar versiju 10.0.20, šis līdzeklis vienmēr ir iespējots.
Otrā izmaiņa tīrīšanas procesā ir iztīrītās izpildes vēstures arhivēšana. Tīrīšanas darbs arhivēs dzēstos ierakstus uz BLOB krātuvi, ko DIXF izmanto regulārai integrācijai. Arhivētais fails būs DIXF pakotnes formātā un būs pieejams BLOB 7 dienas, kuru laikā to iespējams lejupielādēt. Arhivēšanas faila noklusējuma 7 dienu ilgmūžību parametros iespējams mainīt uz maksimums 90 dienām.
Noklusējuma iestatījumu maiņa
Šī funkcionalitāte pašlaik ir priekšskatījumā, un tā ir skaidri jāieslēdz, iespējojot ierobežoto līdzekli DMFEnableExecutionHistoryCleanupSystemJob. Tīrīšanas līdzekļa izstādīšanai arī ir jābūt ieslēgtai arī līdzekļa pārvaldībā.
Lai mainītu arhivētā faila ilgmūžības noklusējuma iestatījumu, dodieties uz datu pārvaldības darbvietu un atlasiet Darba vēstures tīrīšana. Iestatiet Dienas, lai saglabātu pakotni BLOB uz vērtību starp 7 un 90 (ieskaitot). Tas stāsies spēkā arhīvos, kas tiek izveidoti pēc šo izmaiņu veikšanas.
Arhivētās pakotnes lejupielādēšana
Šī funkcionalitāte pašlaik ir priekšskatījumā, un tā ir skaidri jāieslēdz, iespējojot ierobežoto līdzekli DMFEnableExecutionHistoryCleanupSystemJob. Tīrīšanas līdzekļa izstādīšanai arī ir jābūt ieslēgtai arī līdzekļa pārvaldībā.
Lai lejupielādētu arhivēto izpildes vēsturi, dodieties uz datu pārvaldības darbvietu un atlasiet Darba vēstures tīrīšana. Atlasiet Pakotnes dublēšanas vēsture, lai atvērtu vēstures veidlapu. Šajā veidlapā parādīts visu arhivēto pakotņu saraksts. Arhīvu var atlasīt un lejupielādēt, atlasot Lejupielādēt pakotni. Lejupielādētā pakotne būs DIXF pakotnes formātā, un tajā būs iekļauti tālāk norādītie faili.
- Elementa izstādīšanas tabulas fails
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG