Regionaal herstel na noodgevallen voor Azure Databricks-clusters
In dit artikel wordt een architectuur voor herstel na noodgevallen beschreven die nuttig is voor Azure Databricks-clusters en de stappen voor het uitvoeren van dat ontwerp.
Azure Databricks-architectuur
Wanneer u een Azure Databricks-werkruimte maakt vanuit Azure Portal, wordt een beheerde toepassing geïmplementeerd als een Azure-resource in uw abonnement, in de gekozen Azure-regio (bijvoorbeeld VS - west). Dit apparaat wordt geïmplementeerd in een virtueel Azure-netwerk met een netwerkbeveiligingsgroep en een Azure Storage-account dat beschikbaar is in uw abonnement. Het virtuele netwerk biedt beveiliging op perimeterniveau voor de Databricks-werkruimte en wordt beveiligd via een netwerkbeveiligingsgroep. In de werkruimte maakt u Databricks-clusters door het type werkrol- en stuurprogramma-VM en de Runtime-versie van Databricks op te geven. De persistente gegevens zijn beschikbaar in uw opslagaccount. Zodra het cluster is gemaakt, kunt u taken uitvoeren via notebooks, REST API's of ODBC/JDBC-eindpunten door ze aan een specifiek cluster te koppelen.
Het Databricks-besturingsvlak beheert en bewaakt de Databricks-werkruimteomgeving. Elke beheerbewerking, zoals het maken van een cluster, wordt gestart vanuit het besturingsvlak. Alle metagegevens, zoals geplande taken, worden opgeslagen in een Azure Database en de databaseback-ups worden automatisch geo-gerepliceerd voor in gekoppelde regio's waar deze wordt geïmplementeerd.
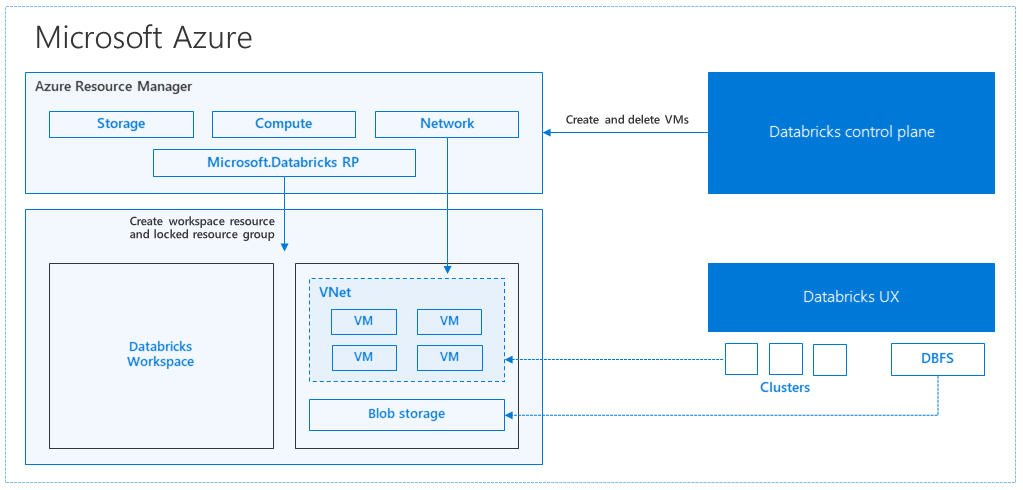
Een van de voordelen van deze architectuur is dat gebruikers Azure Databricks kunnen verbinden met elke opslagresource in hun account. Een belangrijk voordeel is dat zowel compute (Azure Databricks) als opslag onafhankelijk van elkaar kunnen worden geschaald.
Een regionale topologie voor herstel na noodgevallen maken
In de voorgaande beschrijving van de architectuur zijn er een aantal onderdelen die worden gebruikt voor een big data-pijplijn met Azure Databricks: Azure Storage, Azure Database en andere gegevensbronnen. Azure Databricks is de berekening voor de big data-pijplijn. Het is tijdelijk van aard, wat betekent dat terwijl uw gegevens nog steeds beschikbaar zijn in Azure Storage, de rekenkracht (Azure Databricks-cluster) kan worden beëindigd om te voorkomen dat u betaalt voor berekeningen wanneer u deze niet nodig hebt. De berekeningsbronnen (Azure Databricks) en opslagbronnen moeten zich in dezelfde regio bevinden, zodat taken geen hoge latentie ervaren.
Als u uw eigen regionale topologie voor herstel na noodgevallen wilt maken, volgt u deze vereisten:
Meerdere Azure Databricks-werkruimten inrichten in afzonderlijke Azure-regio's. Maak bijvoorbeeld de primaire Azure Databricks-werkruimte in VS - oost. Maak de secundaire Azure Databricks-werkruimte voor herstel na noodgevallen in een afzonderlijke regio, zoals VS - west. Zie Replicatie tussen regio's voor een lijst met gekoppelde Azure-regio's. Zie Ondersteunde regio's voor meer informatie over Azure Databricks-regio's.
Geografisch redundante opslag gebruiken. De gegevens die zijn gekoppeld aan Azure Databricks worden standaard opgeslagen in Azure Storage en de resultaten van Databricks-taken worden opgeslagen in Azure Blob Storage, zodat de verwerkte gegevens duurzaam zijn en maximaal beschikbaar blijven nadat het cluster is beëindigd. De clusteropslag en taakopslag bevinden zich in dezelfde beschikbaarheidszone. Azure Databricks-werkruimten gebruiken standaard geografisch redundante opslag om te beschermen tegen regionale onbeschikbaarheid. Met geografisch redundante opslag worden gegevens gerepliceerd naar een gekoppelde Azure-regio. Databricks raadt u aan de geografisch redundante opslag standaard te houden, maar als u in plaats daarvan lokaal redundante opslag wilt gebruiken, kunt u instellen
storageAccountSkuNameStandard_LRSop in de ARM-sjabloon voor de werkruimte.Zodra de secundaire regio is gemaakt, moet u de gebruikers, gebruikersmappen, notebooks, clusterconfiguratie, taakconfiguratie, bibliotheken, opslag, init-scripts en toegangsbeheer opnieuw configureren. Aanvullende informatie wordt beschreven in de volgende sectie.
Regionale ramp
Als u zich wilt voorbereiden op regionale rampen, moet u expliciet een andere set Azure Databricks-werkruimten in een secundaire regio onderhouden. Zie Herstel na noodgevallen.
Onze aanbevolen hulpprogramma's voor herstel na noodgevallen zijn voornamelijk Terraform (voor infrareplicatie) en Delta Deep Clone (voor gegevensreplicatie).
Gedetailleerde migratiestappen
De opdrachtregelinterface van Databricks instellen op uw computer
In dit artikel vindt u een aantal codevoorbeelden die gebruikmaken van de opdrachtregelinterface voor de meeste geautomatiseerde stappen, omdat het een eenvoudig te gebruiken wrapper is via azure Databricks REST API.
Voordat u migratiestappen uitvoert, installeert u de databricks-cli op uw desktopcomputer of een virtuele machine waarop u het werk wilt uitvoeren. Zie Databricks CLI installeren voor meer informatie
pip install databricks-cliNotitie
Python-scripts in dit artikel werken naar verwachting met Python 2.7+ < 3.x.
Configureer twee profielen.
Configureer een voor de primaire werkruimte en een voor de secundaire werkruimte:
databricks configure --profile primary --token databricks configure --profile secondary --tokenDe codeblokken in dit artikel schakelen tussen profielen in elke volgende stap met behulp van de bijbehorende werkruimteopdracht. Zorg ervoor dat de namen van de profielen die u maakt, in elk codeblok worden vervangen.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"U kunt indien nodig handmatig overschakelen op de opdrachtregel:
databricks workspace ls --profile primary databricks workspace ls --profile secondaryMicrosoft Entra ID-gebruikers (voorheen Azure Active Directory) migreren
Voeg handmatig dezelfde Microsoft Entra ID-gebruikers (voorheen Azure Active Directory) toe aan de secundaire werkruimte die aanwezig is in de primaire werkruimte.
De gebruikersmappen en notitieblokken migreren
Gebruik de volgende Python-code om de sandbox-gebruikersomgevingen te migreren, waaronder de geneste mapstructuur en notebooks per gebruiker.
Notitie
Bibliotheken worden in deze stap niet gekopieerd, omdat de onderliggende API deze niet ondersteunt.
Kopieer en sla het volgende Python-script op in een bestand en voer het uit in de Databricks-opdrachtregel. Bijvoorbeeld
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "ls", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")De clusterconfiguraties migreren
Zodra notebooks zijn gemigreerd, kunt u de clusterconfiguraties desgewenst migreren naar de nieuwe werkruimte. Het is bijna een volledig geautomatiseerde stap met databricks-cli, tenzij u selectieve clusterconfiguratiemigratie wilt uitvoeren in plaats van voor iedereen.
Notitie
Er is helaas geen clusterconfiguratie-eindpunt gemaakt en dit script probeert elk cluster meteen te maken. Als er onvoldoende kernen beschikbaar zijn in uw abonnement, kan het maken van het cluster mislukken. De fout kan worden genegeerd, zolang de configuratie is overgedragen.
Met het volgende script wordt een toewijzing afgedrukt van oude naar nieuwe cluster-id's, die later kunnen worden gebruikt voor taakmigratie (voor taken die zijn geconfigureerd voor het gebruik van bestaande clusters).
Kopieer en sla het volgende Python-script op in een bestand en voer het uit in de Databricks-opdrachtregel. Bijvoorbeeld
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")). splitlines() print("Printting Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append (cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")De taakconfiguratie migreren
Als u in de vorige stap clusterconfiguraties hebt gemigreerd, kunt u ervoor kiezen om taakconfiguraties naar de nieuwe werkruimte te migreren. Het is een volledig geautomatiseerde stap met behulp van databricks-cli, tenzij u selectieve taakconfiguratiemigratie wilt uitvoeren in plaats van dit voor alle taken te doen.
Notitie
De configuratie voor een geplande taak bevat ook de planningsgegevens, dus standaard werkt deze volgens de geconfigureerde timing zodra deze wordt gemigreerd. Daarom verwijdert het volgende codeblok alle planningsgegevens tijdens de migratie (om dubbele uitvoeringen in oude en nieuwe werkruimten te voorkomen). Configureer de planningen voor dergelijke taken zodra u klaar bent voor cutover.
Voor de taakconfiguratie zijn instellingen vereist voor een nieuw of bestaand cluster. Als u een bestaand cluster gebruikt, probeert het onderstaande script/code de oude cluster-id te vervangen door de nieuwe cluster-id.
Kopieer en sla het volgende Python-script op in een bestand. Vervang de waarde voor
old_cluster_idennew_cluster_id, door de uitvoer van de clustermigratie die in de vorige stap is uitgevoerd. Voer deze uit in uw databricks-cli-opdrachtregel, bijvoorbeeldpython scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate ") + job job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id ") + job_req_settings_json['existing_cluster_id'] continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Bibliotheken migreren
Er is momenteel geen eenvoudige manier om bibliotheken van de ene werkruimte naar de andere te migreren. Installeer deze bibliotheken in plaats daarvan handmatig opnieuw in de nieuwe werkruimte. Het is mogelijk om het gebruik van een combinatie van DBFS CLI te automatiseren om aangepaste bibliotheken te uploaden naar de werkruimte en bibliotheken CLI.
Azure Blob Storage- en Azure Data Lake Storage-koppeling migreren
Koppel alle Azure Blob Storage- en Azure Data Lake Storage-koppelpunten (Gen 2) handmatig opnieuw met behulp van een oplossing op basis van een notebook. De opslagbronnen zouden zijn gekoppeld in de primaire werkruimte en die moeten worden herhaald in de secundaire werkruimte. Er is geen externe API voor koppelingen.
Cluster-init-scripts migreren
Initialisatiescripts voor clusters kunnen worden gemigreerd van een oude naar een nieuwe werkruimte met behulp van de DBFS CLI. Kopieer eerst de benodigde scripts naar
dbfs:/dat abricks/init/..uw lokale bureaublad of virtuele machine. Kopieer deze scripts vervolgens naar de nieuwe werkruimte op hetzelfde pad.// Primary to local dbfs cp -r dbfs:/databricks/init ./old-ws-init-scripts --profile primary // Local to Secondary workspace dbfs cp -r old-ws-init-scripts dbfs:/databricks/init --profile secondaryHandmatig opnieuw configureren en toegangsbeheer opnieuw toewijzen.
Als uw bestaande primaire werkruimte is geconfigureerd voor het gebruik van de Premium- of Enterprise-laag (SKU), gebruikt u waarschijnlijk ook de functie Toegangsbeheer.
Als u de functie Toegangsbeheer gebruikt, past u het toegangsbeheer handmatig opnieuw toe op de resources (notebooks, clusters, taken, tabellen).
Herstel na noodgevallen voor uw Azure-ecosysteem
Als u andere Azure-services gebruikt, moet u ook best practices voor herstel na noodgevallen voor deze services implementeren. Als u bijvoorbeeld een extern Hive-metastore-exemplaar wilt gebruiken, moet u overwegen om herstel na noodgevallen te overwegen voor Azure SQL Database, Azure HDInsight en/of Azure Database for MySQL. Zie Herstel na noodgevallen voor Azure-toepassingen voor algemene informatie over herstel na noodgevallen.
Volgende stappen
Zie de documentatie van Azure Databricks voor meer informatie.