Aanbevolen procedures voor HADR-configuratie (SQL Server op virtuele machines van Azure)
Van toepassing op:![]() SQL Server op Azure VM
SQL Server op Azure VM
Een Windows Server-failovercluster wordt gebruikt voor hoge beschikbaarheid en herstel na noodgevallen (HADR) met SQL Server op Azure Virtual Machines (VM's).
Dit artikel bevat aanbevolen procedures voor clusterconfiguratie voor zowel failoverclusterexemplaren (GFA's) als beschikbaarheidsgroepen wanneer u deze gebruikt met SQL Server op Virtuele Azure-machines.
Zie de andere artikelen in deze reeks voor meer informatie: Controlelijst, VM-grootte, Opslag, Beveiliging, HADR-configuratie, Basislijn verzamelen.
Checklijst
Bekijk de volgende controlelijst voor een kort overzicht van de best practices van HADR die in de rest van het artikel in meer detail worden behandeld.
Functies voor hoge beschikbaarheid en herstel na noodgevallen (HADR), zoals de AlwaysOn-beschikbaarheidsgroep en het failoverclusterexemplaren , zijn afhankelijk van onderliggende Windows Server Failover Cluster-technologie . Bekijk de aanbevolen procedures voor het wijzigen van uw HADR-instellingen om de cloudomgeving beter te ondersteunen.
Houd rekening met de volgende aanbevolen procedures voor uw Windows-cluster:
- Implementeer uw SQL Server-VM's waar mogelijk naar meerdere subnetten om de afhankelijkheid van een Azure Load Balancer of een gedistribueerde netwerknaam (DNN) te voorkomen om verkeer naar uw HADR-oplossing te routeren.
- Wijzig het cluster in minder agressieve parameters om onverwachte storingen te voorkomen bij tijdelijke netwerkfouten of onderhoud van Het Azure-platform. Zie heartbeat- en drempelwaarde-instellingen voor meer informatie. Gebruik voor Windows Server 2012 en hoger de volgende aanbevolen waarden:
- SameSubnetDelay: 1 seconde
- SameSubnetThreshold: 40 heartbeats
- CrossSubnetDelay: 1 seconde
- CrossSubnetThreshold: 40 heartbeats
- Plaats uw VM's in een beschikbaarheidsset of verschillende beschikbaarheidszones. Zie beschikbaarheidsinstellingen voor VM's voor meer informatie.
- Gebruik één NIC per clusterknooppunt.
- Configureer clusterquorumstemmen om 3 of meer oneven stemmen te gebruiken. Wijs geen stemmen toe aan dr-regio's.
- Bewaak resourcelimieten zorgvuldig om onverwachte herstarts of failovers te voorkomen vanwege resourcebeperkingen.
- Zorg ervoor dat uw besturingssysteem, stuurprogramma's en SQL Server de nieuwste builds hebben.
- Optimaliseer de prestaties voor SQL Server op Azure-VM's. Bekijk de andere secties in dit artikel voor meer informatie.
- Verminder of verspreid de workload om resourcelimieten te voorkomen.
- Ga naar een virtuele machine of schijf waarvoor zijn hogere limieten gelden om beperkingen te voorkomen.
Houd rekening met de volgende aanbevolen procedures voor uw SQL Server-beschikbaarheidsgroep of failoverclusterexemplaren:
- Als u regelmatig onverwachte fouten ondervindt, volgt u de best practices voor prestaties die in de rest van dit artikel worden beschreven.
- Als het optimaliseren van de prestaties van DE SQL Server-VM uw onverwachte failovers niet oplost, kunt u overwegen de bewaking voor de beschikbaarheidsgroep of het failoverclusterexemplaren te versoepelen. Als u dit doet, kan dit echter niet de onderliggende oorzaak van het probleem oplossen en symptomen maskeren door de kans op fouten te verminderen. Mogelijk moet u de onderliggende hoofdoorzaak nog steeds onderzoeken en aanpakken. Gebruik voor Windows Server 2012 of hoger de volgende aanbevolen waarden:
- Time-out voor lease: gebruik deze vergelijking om de maximale time-outwaarde voor lease te berekenen:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Begin met 40 seconden. Als u de eerder aanbevolen ontspannenSameSubnetThresholdwaardenSameSubnetDelaygebruikt, mag u niet langer zijn dan 80 seconden voor de time-outwaarde van de lease. - Maximum aantal fouten in een opgegeven periode: stel deze waarde in op 6.
- Time-out voor lease: gebruik deze vergelijking om de maximale time-outwaarde voor lease te berekenen:
- Wanneer u de naam van het virtuele netwerk (VNN) en een Azure Load Balancer gebruikt om verbinding te maken met uw HADR-oplossing, geeft u
MultiSubnetFailover = truedit op in de verbindingsreeks, zelfs als uw cluster slechts één subnet omvat.- Als de client geen ondersteuning biedt
MultiSubnetFailover = True, moet u mogelijk de clientreferenties voor kortere tijd instellenRegisterAllProvidersIP = 0enHostRecordTTL = 300in de cache opslaan. Dit kan echter leiden tot extra query's op de DNS-server.
- Als de client geen ondersteuning biedt
- Als u verbinding wilt maken met uw HADR-oplossing met behulp van de DNN (Distributed Network Name), kunt u het volgende overwegen:
- U moet een clientstuurprogramma gebruiken dat ondersteuning biedt
MultiSubnetFailover = Trueen deze parameter moet zich in de verbindingsreeks. - Gebruik een unieke DNN-poort in de verbindingsreeks wanneer u verbinding maakt met de DNN-listener voor een beschikbaarheidsgroep.
- U moet een clientstuurprogramma gebruiken dat ondersteuning biedt
- Gebruik een databasespiegeling verbindingsreeks voor een eenvoudige beschikbaarheidsgroep om de noodzaak van een load balancer of DNN te omzeilen.
- Valideer de sectorgrootte van uw VHD's voordat u uw oplossing voor hoge beschikbaarheid implementeert om te voorkomen dat de I/Os verkeerd is uitgelijnd. Zie KB3009974 voor meer informatie.
- Als de SQL Server-database-engine, alwayson-beschikbaarheidsgroeplistener of statustest van het failoverclusterexemplaren zijn geconfigureerd voor het gebruik van een poort tussen 49.152 en 65.536 (het standaard dynamische poortbereik voor TCP/IP), voegt u een uitsluiting toe voor elke poort. Als u dit doet, voorkomt u dat andere systemen dynamisch dezelfde poort worden toegewezen. In het volgende voorbeeld wordt een uitsluiting voor poort 59999 gemaakt:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Als u de HADR-controlelijst wilt vergelijken met de andere best practices, raadpleegt u de uitgebreide controlelijst voor best practices voor prestaties.
Vm-beschikbaarheidsinstellingen
Als u het effect van downtime wilt verminderen, moet u rekening houden met de volgende instellingen voor de beste beschikbaarheid van de VM:
- Gebruik nabijheidsplaatsingsgroepen samen met versneld netwerken voor de laagste latentie.
- Plaats clusterknooppunten van virtuele machines in afzonderlijke beschikbaarheidszones om te beschermen tegen storingen op datacenterniveau of in één beschikbaarheidsset voor redundantie met een lagere latentie binnen hetzelfde datacenter.
- Gebruik premium beheerde besturingssysteem- en gegevensschijven voor VM's in een beschikbaarheidsset.
- Configureer elke toepassingslaag in afzonderlijke beschikbaarheidssets.
Quorum
Hoewel een cluster met twee knooppunten zonder quorumresource functioneert, moeten klanten strikt een quorumresource gebruiken om productieondersteuning te bieden. Bij clustervalidatie wordt geen cluster zonder quorumresource doorgegeven.
Technisch gezien kan een cluster met drie knooppunten één knooppuntverlies overleven (tot twee knooppunten) zonder quorumresource, maar nadat het cluster is neergezet op twee knooppunten, als er een ander knooppuntverlies of communicatiefout is, is er een risico dat de geclusterde resources offline gaan om een split-brain-scenario te voorkomen. Als u een quorumresource configureert, kan het cluster online blijven met slechts één knooppunt online.
De schijfwitness is de meest tolerante quorumoptie, maar als u een schijfwitness wilt gebruiken op een SQL Server op azure-VM, moet u een gedeelde Azure-schijf gebruiken, die enkele beperkingen voor de oplossing voor hoge beschikbaarheid met zich meebrengt. Gebruik daarom een schijfwitness wanneer u uw failoverclusterexemplaren configureert met Azure Shared Disks. Gebruik anders waar mogelijk een cloudwitness.
De volgende tabel bevat de quorumopties die beschikbaar zijn voor SQL Server op Azure-VM's:
| Cloudwitness | Schijfwitness | Bestandssharewitness | |
|---|---|---|---|
| Ondersteund besturingssysteem | Windows Server 2016+ | Alle | Alle |
- De cloudwitness is ideaal voor implementaties op meerdere sites, meerdere zones en meerdere regio's. Gebruik waar mogelijk een cloudwitness, tenzij u een clusteroplossing voor gedeelde opslag gebruikt.
- De schijfwitness is de meest tolerante quorumoptie en heeft de voorkeur voor elk cluster dat gebruikmaakt van Azure Shared Disks (of een oplossing voor gedeelde schijven, zoals gedeelde SCSI-, iSCSI- of glasvezelkanaal-SAN). Een geclusterd gedeeld volume kan niet worden gebruikt als schijfwitness.
- De bestandssharewitness is geschikt voor wanneer de schijfwitness en cloudwitness niet beschikbaar zijn.
Zie Clusterquorum configureren om aan de slag te gaan.
Quorumstemmen
Het is mogelijk om de quorumstem te wijzigen van een knooppunt dat deelneemt aan een Windows Server-failovercluster.
Als u de steminstellingen voor knooppunten wijzigt, volgt u deze richtlijnen:
| Richtlijnen voor quorumstemmen |
|---|
| Begin met elk knooppunt dat standaard geen stem heeft. Elk knooppunt mag alleen een stem met expliciete reden hebben. |
| Schakel stemmen in voor clusterknooppunten die als host fungeren voor de primaire replica van een beschikbaarheidsgroep of de voorkeurseigenaren van een failoverclusterexemplaren. |
| Stemmen inschakelen voor automatische failover-eigenaren. Elk knooppunt dat een primaire replica of FCI kan hosten als gevolg van een automatische failover, moet een stem hebben. |
| Als een beschikbaarheidsgroep meer dan één secundaire replica heeft, schakelt u alleen stemmen in voor de replica's met automatische failover. |
| Stemmen uitschakelen voor knooppunten die zich op secundaire sites voor herstel na noodgevallen bevinden. Knooppunten in secundaire sites mogen niet bijdragen aan het offline nemen van een cluster als er niets mis is met de primaire site. |
| Een oneven aantal stemmen hebben, met minimaal drie quorumstemmen. Voeg indien nodig een quorumwitness toe voor een extra stem in een cluster met twee knooppunten. |
| Stemtoewijzingen na failover opnieuw beoordelen. U wilt geen failover uitvoeren naar een clusterconfiguratie die geen ondersteuning biedt voor een goed functionerend quorum. |
Connectiviteit
Implementeer uw SQL Server-VM's in meerdere subnetten binnen hetzelfde virtuele netwerk om verbinding te maken met de listener van uw beschikbaarheidsgroep of failoverclusterexemplaren, zodat deze overeenkomen met de on-premises ervaring voor het maken van verbinding met de listener van uw beschikbaarheidsgroep of failoverclusterexemplaren. Als u meerdere subnetten hebt, hoeft u niet meer afhankelijk te zijn van een Azure Load Balancer of een gedistribueerde netwerknaam om uw verkeer naar uw listener te routeren.
Als u uw HADR-oplossing wilt vereenvoudigen, implementeert u waar mogelijk uw SQL Server-VM's in meerdere subnetten. Zie Multi-subnet AG en Multi-subnet FCI voor meer informatie.
Als uw SQL Server-VM's zich in één subnet bevinden, is het mogelijk om een naam van een virtueel netwerk (VNN) en een Azure Load Balancer of een gedistribueerde netwerknaam (DNN) te configureren voor zowel failoverclusterexemplaren als listeners voor beschikbaarheidsgroepen.
De gedistribueerde netwerknaam is de aanbevolen verbindingsoptie, indien beschikbaar:
- De end-to-end-oplossing is robuuster omdat u de load balancer-resource niet meer hoeft te onderhouden.
- Het elimineren van de load balancer-tests minimaliseert de duur van de failover.
- De DNN vereenvoudigt het inrichten en beheren van het failoverclusterexemplaren of de listener voor beschikbaarheidsgroepen met SQL Server op Azure-VM's.
Overweeg de volgende beperkingen:
- Het clientstuurprogramma moet de
MultiSubnetFailover=Trueparameter ondersteunen. - De DNN-functie is beschikbaar vanaf SQL Server 2016 SP3, SQL Server 2017 CU25 en SQL Server 2019 CU8 op Windows Server 2016 en hoger.
Zie het overzicht van het Windows Server-failovercluster voor meer informatie.
Raadpleeg de volgende artikelen om connectiviteit te configureren:
- Beschikbaarheidsgroep: DNN configureren, VNN configureren
- Failoverclusterexemplaren: DNN configureren, VNN configureren.
De meeste SQL Server-functies werken transparant met FCI en beschikbaarheidsgroepen bij het gebruik van de DNN, maar er zijn bepaalde functies waarvoor mogelijk speciale overwegingen nodig zijn. Zie FCI- en DNN-interoperabiliteit en AG- en DNN-interoperabiliteit voor meer informatie.
Fooi
Stel de parameter MultiSubnetFailover = true in de verbindingsreeks in, zelfs voor HADR-oplossingen die één subnet omvatten om toekomstige spanning van subnetten te ondersteunen zonder dat u verbindingsreeks s hoeft bij te werken.
Heartbeat en drempelwaarde
Wijzig de heartbeat- en drempelwaarde-instellingen van het cluster in ontspannen instellingen. De standaardinstellingen voor heartbeat- en drempelwaardeclusters zijn ontworpen voor sterk afgestemde on-premises netwerken en overwegen geen verhoogde latentie in een cloudomgeving. Het heartbeat-netwerk wordt onderhouden met UDP 3343, dat traditioneel veel minder betrouwbaar is dan TCP en gevoeliger is voor onvolledige gesprekken.
Wijzig daarom bij het uitvoeren van clusterknooppunten voor SQL Server op Azure VM-oplossingen voor hoge beschikbaarheid de clusterinstellingen in een meer ontspannen bewakingsstatus om tijdelijke fouten te voorkomen vanwege de verhoogde mogelijkheid van netwerklatentie of -storing, Azure-onderhoud of het raken van knelpunten in resources.
De instellingen voor vertraging en drempelwaarden hebben een cumulatief effect op de totale statusdetectie. Als u CrossSubnetDelay bijvoorbeeld instelt om elke 2 seconden een heartbeat te verzenden en de CrossSubnetThreshold in te stellen op 10 gemiste heartbeats voordat u herstel uitvoert, betekent dit dat het cluster een totale netwerktolerantie van 20 seconden kan hebben voordat de herstelactie wordt uitgevoerd. Over het algemeen is het de voorkeur om frequente heartbeats te blijven verzenden, maar hogere drempelwaarden hebben de voorkeur.
Om te zorgen voor herstel tijdens legitieme storingen terwijl u meer tolerantie biedt voor tijdelijke problemen, versoepelt u de vertragings- en drempelwaarde-instellingen tot de aanbevolen waarden die in de volgende tabel worden beschreven:
| Instelling | WindowsServer 2012 of later | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 seconde | 2 seconde |
| SameSubnetThreshold | 40 heartbeats | 10 heartbeats (max) |
| CrossSubnetDelay | 1 seconde | 2 seconde |
| CrossSubnetThreshold | 40 heartbeats | 20 heartbeats (max) |
Gebruik PowerShell om de clusterparameters te wijzigen:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Gebruik PowerShell om uw wijzigingen te controleren:
get-cluster | fl *subnet*
Denk aan het volgende:
- Deze wijziging is onmiddellijk, het cluster opnieuw wordt opgestart of resources zijn niet vereist.
- Dezelfde subnetwaarden mogen niet groter zijn dan subnetwaarden tussen subnetten.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
Kies ontspannen waarden op basis van hoeveel rusttijd acceptabel is en hoe lang voordat een corrigerende actie moet plaatsvinden, afhankelijk van uw toepassing, bedrijfsbehoeften en uw omgeving. Als u de standaardwaarden voor Windows Server 2019 niet kunt overschrijden, probeert u deze ten minste te vinden, indien mogelijk:
Ter referentie bevat de volgende tabel de standaardwaarden:
| Instelling | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 - 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1 seconde | 1 seconde | 1 seconde |
| SameSubnetThreshold | 20 heartbeats | 10 heartbeats | 5 heartbeats |
| CrossSubnetDelay | 1 seconde | 1 seconde | 1 seconde |
| CrossSubnetThreshold | 20 heartbeats | 10 heartbeats | 5 heartbeats |
Zie Drempelwaarden voor failoverclusternetwerk afstemmen voor meer informatie.
Ontspannen bewaking
Als het afstemmen van de heartbeat- en drempelwaarde-instellingen van uw cluster zoals aanbevolen onvoldoende tolerantie is en u nog steeds failovers ziet vanwege tijdelijke problemen in plaats van echte storingen, kunt u uw AG- of FCI-bewaking zo configureren dat deze soepeler verloopt. In sommige scenario's kan het nuttig zijn om de bewaking tijdelijk te versoepelen op basis van het activiteitsniveau. U kunt bijvoorbeeld de bewaking versoepelen wanneer u I/O-intensieve workloads uitvoert, zoals databaseback-ups, indexonderhoud, DBCC CHECKDB, enzovoort. Zodra de activiteit is voltooid, stelt u uw bewaking in op minder ontspannen waarden.
Waarschuwing
Het wijzigen van deze instellingen kan een onderliggend probleem maskeren en moet worden gebruikt als tijdelijke oplossing om de kans op fouten te verminderen, in plaats van te elimineren. Onderliggende problemen moeten nog steeds worden onderzocht en opgelost.
Begin met het verhogen van de volgende parameters op basis van hun standaardwaarden voor ontspannen bewaking en pas deze indien nodig aan:
| Parameter | Default value | Ontspannen waarde | Omschrijving |
|---|---|---|---|
| Time-out voor statuscontrole | 30.000 | 60000 | Bepaalt de status van de primaire replica of het primaire knooppunt. Het DLL-bestand sp_server_diagnostics van de clusterresource retourneert resultaten met een interval dat gelijk is aan 1/3 van de time-outdrempel voor statuscontrole. Als sp_server_diagnostics het traag is of geen informatie retourneert, wacht de resource-DLL op het volledige interval van de time-outdrempel voor statuscontrole voordat wordt vastgesteld dat de resource niet reageert en een automatische failover wordt gestart, indien geconfigureerd om dit te doen. |
| Niveau foutvoorwaarde | 3 | 2 | Voorwaarden die een automatische failover activeren. Er zijn vijf foutvoorwaardeniveaus, die variëren van de minst beperkende (niveau één) tot de meest beperkende (niveau vijf) |
Gebruik Transact-SQL (T-SQL) om de statuscontrole en foutvoorwaarden voor zowel AG's als FC's te wijzigen.
Voor beschikbaarheidsgroepen:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
Voor failoverclusterexemplaren:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Specifiek voor beschikbaarheidsgroepen, begin met de volgende aanbevolen parameters en pas deze indien nodig aan:
| Parameter | Default value | Ontspannen waarde | Omschrijving |
|---|---|---|---|
| Time-out voor lease | 20000 | 40.000 | Voorkomt split-brain. |
| Sessietime-out | 10.000 | 20000 | Controleert communicatieproblemen tussen replica's. De sessietime-outperiode is een replica-eigenschap waarmee wordt bepaald hoe lang (in seconden) een beschikbaarheidsreplica wacht op een ping-reactie van een verbonden replica voordat de verbinding is mislukt. Standaard wacht een replica 10 seconden op een ping-antwoord. Deze replica-eigenschap is alleen van toepassing op de verbinding tussen een bepaalde secundaire replica en de primaire replica van de beschikbaarheidsgroep. |
| Maximum aantal fouten in de opgegeven periode | 2 | 6 | Wordt gebruikt om onbepaalde verplaatsing van een geclusterde resource binnen meerdere knooppuntfouten te voorkomen. Te laag van een waarde kan ertoe leiden dat de beschikbaarheidsgroep de status Mislukt heeft. Verhoog de waarde om korte onderbrekingen van prestatieproblemen te voorkomen omdat een te lage waarde kan leiden tot een mislukte status van de beschikbaarheidsgroep. |
Voordat u wijzigingen aanbrengt, moet u rekening houden met het volgende:
- Verlaag geen time-outwaarden onder de standaardwaarden.
- Gebruik deze vergelijking om de maximale time-outwaarde voor leases te berekenen:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Begin met 40 seconden. Als u de eerder aanbevolen ontspannenSameSubnetThresholdwaardenSameSubnetDelaygebruikt, mag u niet langer zijn dan 80 seconden voor de time-outwaarde van de lease. - Voor synchrone doorvoerreplica's kan het wijzigen van sessietime-out naar een hoge waarde HADR_sync_commit wachttijden verhogen.
Time-out voor lease
Gebruik Failoverclusterbeheer om de time-outinstellingen voor de lease voor uw beschikbaarheidsgroep te wijzigen. Raadpleeg de documentatie voor de leasestatus van de SQL Server-beschikbaarheidsgroep voor gedetailleerde stappen.
Sessietime-out
Gebruik Transact-SQL (T-SQL) om de sessietime-out voor een beschikbaarheidsgroep te wijzigen:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Maximum aantal fouten in de opgegeven periode
Gebruik Failoverclusterbeheer om de maximumfouten in de opgegeven periodewaarde te wijzigen:
- Selecteer Rollen in het navigatiedeelvenster.
- Klik onder Rollen met de rechtermuisknop op de geclusterde resource en kies Eigenschappen.
- Selecteer het tabblad Failover en verhoog de maximumfouten in de opgegeven periodewaarde naar wens.
Bronlimieten
VM- of schijflimieten kunnen leiden tot een knelpunt in een resource die van invloed is op de status van het cluster en de statuscontrole belemmert. Als u problemen ondervindt met resourcelimieten, kunt u het volgende overwegen:
- Zorg ervoor dat uw besturingssysteem, stuurprogramma's en SQL Server de nieuwste builds hebben.
- SQL Server optimaliseren in een Azure VM-omgeving, zoals beschreven in de prestatierichtlijnen voor SQL Server op Azure Virtual Machines
- De workload verminderen of verspreiden om het gebruik te verminderen zonder resourcelimieten te overschrijden
- De SQL Server-workload afstemmen als er een kans is, zoals
- Indexen toevoegen/optimaliseren
- Statistieken bijwerken indien nodig en indien mogelijk, met volledige scan
- Gebruik functies zoals resource governor (te beginnen met SQL Server 2014, alleen onderneming) om het resourcegebruik te beperken tijdens specifieke workloads, zoals back-ups of indexonderhoud.
- Ga naar een VIRTUELE machine of schijf met hogere limieten om te voldoen aan de vereisten van uw workload of deze te overschrijden.
Netwerken
Implementeer uw SQL Server-VM's waar mogelijk naar meerdere subnetten om de afhankelijkheid van een Azure Load Balancer of een gedistribueerde netwerknaam (DNN) te voorkomen om verkeer naar uw HADR-oplossing te routeren.
Gebruik één NIC per server (clusterknooppunt). Azure-netwerken hebben fysieke redundantie, waardoor extra NIC's onnodig zijn op een gastcluster van een virtuele Azure-machine. Het clustervalidatierapport waarschuwt u dat de knooppunten alleen bereikbaar zijn in één netwerk. U kunt deze waarschuwing negeren op gastfailoverclusters van virtuele Azure-machines.
Bandbreedtelimieten voor een bepaalde VM worden gedeeld tussen NIC's en het toevoegen van een extra NIC verbetert de prestaties van de beschikbaarheidsgroep voor SQL Server op Virtuele Azure-machines niet. Daarom hoeft u geen tweede NIC toe te voegen.
De niet-RFC-compatibele DHCP-service in Azure kan ertoe leiden dat bepaalde failoverclusterconfiguraties mislukken. Deze fout treedt op omdat aan de clusternetwerknaam een dubbel IP-adres is toegewezen, zoals hetzelfde IP-adres als een van de clusterknooppunten. Dit is een probleem wanneer u beschikbaarheidsgroepen gebruikt, die afhankelijk zijn van de functie Windows-failovercluster.
Houd rekening met het scenario wanneer een cluster met twee knooppunten wordt gemaakt en online wordt gebracht:
- Het cluster is online en vervolgens vraagt NODE1 een dynamisch toegewezen IP-adres aan voor de naam van het clusternetwerk.
- De DHCP-service geeft geen ander IP-adres dan het eigen IP-adres van NODE1, omdat de DHCP-service herkent dat de aanvraag afkomstig is van NODE1 zelf.
- Windows detecteert dat een dubbel adres is toegewezen aan NODE1 en aan de netwerknaam van het failovercluster en dat de standaardclustergroep niet online komt.
- De standaardclustergroep wordt verplaatst naar NODE2. NODE2 behandelt het IP-adres van NODE1 als het IP-adres van het cluster en brengt de standaardclustergroep online.
- Wanneer NODE2 verbinding probeert te maken met NODE1, verlaten pakketten die zijn gericht op NODE1 node2 nooit omdat het IP-adres van NODE1 naar zichzelf wordt omgezet. NODE2 kan geen verbinding maken met NODE1 en verliest vervolgens quorum en sluit het cluster af.
- NODE1 kan pakketten verzenden naar NODE2, maar NODE2 kan niet reageren. NODE1 verliest quorum en sluit het cluster af.
U kunt dit scenario vermijden door een ongebruikt statisch IP-adres toe te wijzen aan de naam van het clusternetwerk om de naam van het clusternetwerk online te brengen en het IP-adres toe te voegen aan Azure Load Balancer.
Als de SQL Server-database-engine, AlwaysOn-listener voor beschikbaarheidsgroepen, statustest voor failoverclusterexemplaren, eindpunt voor databasespiegeling, clusterkern-IP-resource of een andere SQL-resource is geconfigureerd voor het gebruik van een poort tussen 49.152 en 65.536 (het standaard dynamische poortbereik voor TCP/IP), voegt u een uitsluiting toe voor elke poort. Als u dit doet, voorkomt u dat andere systeemprocessen dynamisch dezelfde poort worden toegewezen. In het volgende voorbeeld wordt een uitsluiting voor poort 59999 gemaakt:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Het is belangrijk om de uitsluiting van de poort te configureren wanneer de poort niet in gebruik is, anders mislukt de opdracht met een bericht zoals 'Het proces heeft geen toegang tot het bestand omdat het wordt gebruikt door een ander proces'.
Gebruik de volgende opdracht om te bevestigen dat de uitsluitingen correct zijn geconfigureerd: netsh int ipv4 show excludedportrange tcp
Als u deze uitsluiting instelt voor de IP-testpoort van de beschikbaarheidsgroep, moeten gebeurtenissen zoals gebeurtenis-id: 1069 met status 10048 worden voorkomen. Deze gebeurtenis kan worden weergegeven in de Windows Failover-cluster gebeurtenissen met het volgende bericht:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
Dit kan worden veroorzaakt door een intern proces waarbij dezelfde poort wordt gebruikt die is gedefinieerd als de testpoort. Houd er rekening mee dat de testpoort wordt gebruikt om de status van een back-endpoolexemplaren van de Azure Load Balancer te controleren.
Als de statustest geen antwoord krijgt van een back-endexemplaren, worden er geen nieuwe verbindingen naar dat back-endexemplaren verzonden totdat de statustest opnieuw slaagt.
Bekende problemen
Bekijk de oplossingen voor enkele veelvoorkomende problemen en fouten.
Resourceconflicten (IO in het bijzonder) veroorzaken failover
Een uitputting van de I/O- of CPU-capaciteit voor de VIRTUELE machine kan ertoe leiden dat uw beschikbaarheidsgroep een failover-overschakeling uitvoert. Het identificeren van de conflicten die zich direct vóór de failover voordoet, is de meest betrouwbare manier om te bepalen wat automatische failover veroorzaakt. Bewaak virtuele Azure-machines om de metrische gegevens over io-gebruik van opslag te bekijken om inzicht te hebben in de latentie van VM's of schijfniveaus.
Volg deze stappen om de algemene IO-uitputtingsgebeurtenis van azure-VM te controleren:
Navigeer naar uw virtuele machine in Azure Portal , niet naar de virtuele SQL-machines.
Selecteer Metrische gegevens onder Bewaking om de pagina Metrische gegevens te openen.
Selecteer Lokale tijd om het tijdsbereik op te geven waarin u geïnteresseerd bent, en de tijdzone, lokaal naar de virtuele machine of UTC/GMT.
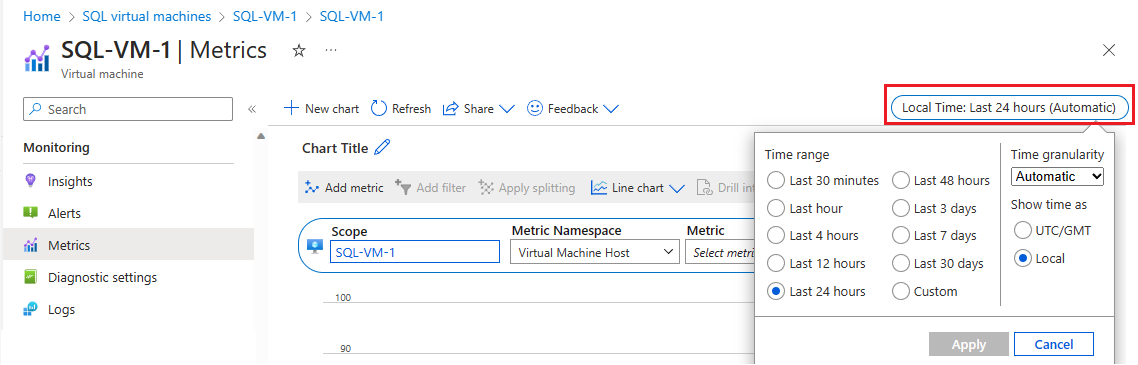
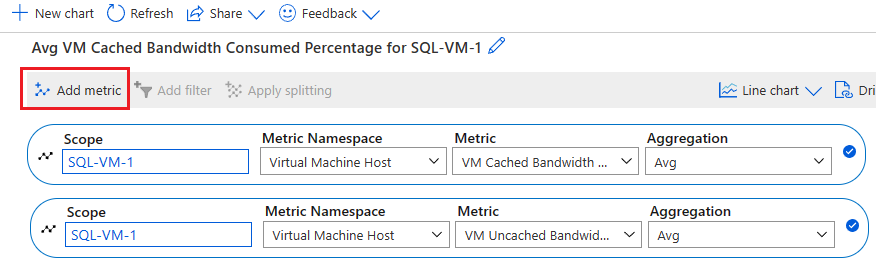
Selecteer Metrische waarde toevoegen om de volgende twee metrische gegevens toe te voegen om de grafiek weer te geven:
- Verbruikt percentage verbruikte bandbreedte in cache van VM
- Percentage van bandbreedte van de niet in cache opgeslagen schijf dat wordt gebruikt door de VM
Azure VM HostEvents veroorzaakt failover
Het is mogelijk dat een Azure VM HostEvent ervoor zorgt dat uw beschikbaarheidsgroep een failover uitvoert. Als u denkt dat een Azure VM HostEvent een failover heeft veroorzaakt, kunt u het Azure Monitor-activiteitenlogboek en het overzicht van Azure VM Resource Health controleren.
Het Azure Monitor-activiteitenlogboek is een platformlogboek in Azure, dat inzicht biedt in gebeurtenissen op abonnementsniveau. Het activiteitenlogboek bevat informatie zoals wanneer een resource wordt gewijzigd of een virtuele machine wordt gestart. U kunt het activiteitenlogboek bekijken in Azure Portal of vermeldingen ophalen met PowerShell en de Azure CLI.
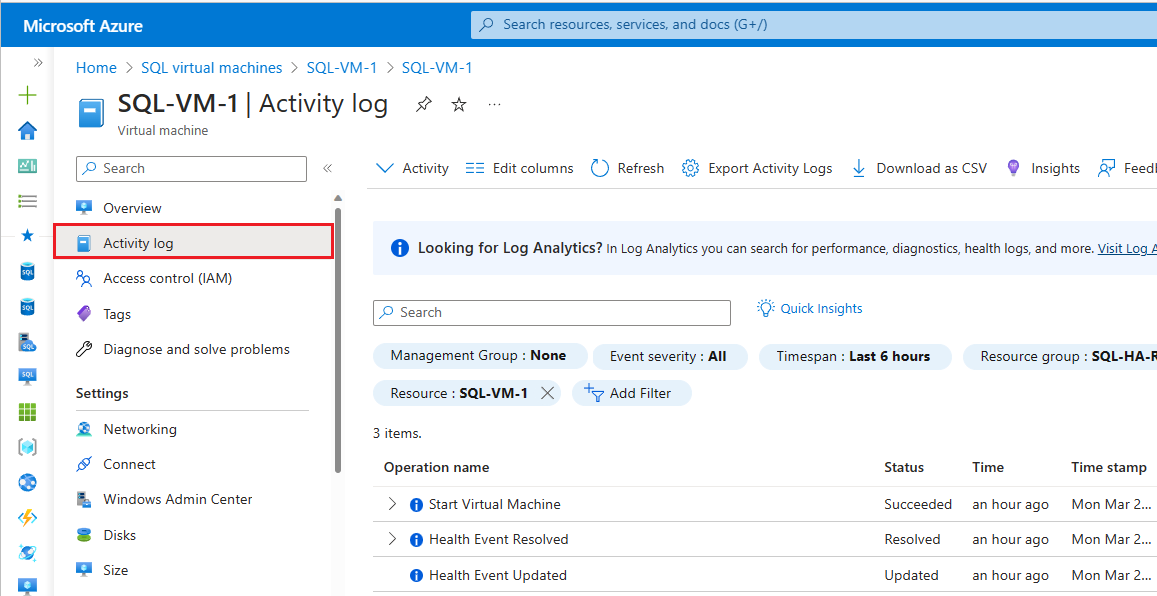
Voer de volgende stappen uit om het Activiteitenlogboek van Azure Monitor te controleren:
Navigeer naar uw virtuele machine in Azure Portal
Activiteitenlogboek selecteren in het deelvenster Virtuele machine
Selecteer Tijdspanne en kies vervolgens het tijdsbestek wanneer uw beschikbaarheidsgroep een failover heeft uitgevoerd. Selecteer Toepassen.
Als Azure meer informatie heeft over de hoofdoorzaak van een door het platform geïnitieerde onbeschikbaarheid, kan die informatie worden geplaatst op de azure-VM - Resource Health-overzichtspagina tot 72 uur na de eerste onbeschikbaarheid. Deze informatie is op dit moment alleen beschikbaar voor virtuele machines.
- Navigeer naar uw virtuele machine in Azure Portal
- Selecteer Resource Health in het deelvenster Status .
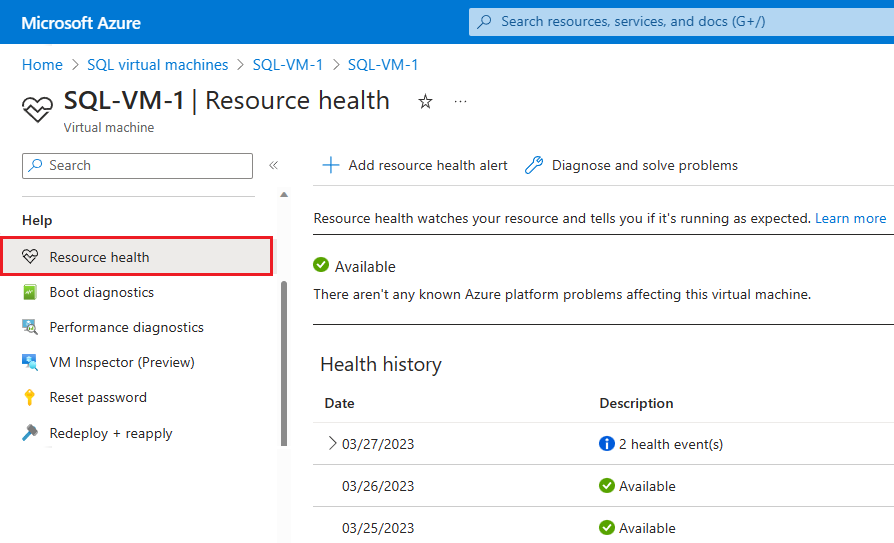
U kunt ook waarschuwingen configureren op basis van status gebeurtenissen op deze pagina.
Clusterknooppunt verwijderd uit lidmaatschap
Als de heartbeat- en drempelwaarde-instellingen van het Windows-cluster te agressief zijn voor uw omgeving, ziet u mogelijk regelmatig het volgende bericht in het gebeurtenislogboek van het systeem.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Raadpleeg het oplossen van clusterproblemen met gebeurtenis-id 1135 voor meer informatie.
Lease is verlopen/ Lease is niet meer geldig
Als de bewaking te agressief is voor uw omgeving, ziet u mogelijk frequente beschikbaarheidsgroep of FCI-herstarts, fouten of failovers. Voor beschikbaarheidsgroepen ziet u mogelijk de volgende berichten in het foutenlogboek van SQL Server:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Time-out van verbinding
Als de sessietime-out te agressief is voor de omgeving van uw beschikbaarheidsgroep, ziet u mogelijk regelmatig de volgende berichten:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
Een failover van de groep wordt niet uitgevoerd
Als de waarde maximumfouten in de opgegeven periode te laag is en u onregelmatige fouten ondervindt vanwege tijdelijke problemen, kan uw beschikbaarheidsgroep eindigen op een mislukte status. Verhoog deze waarde om tijdelijke fouten te tolereren.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Gebeurtenis 1196 - Registratie van gekoppelde DNS-naam is mislukt voor netwerknaamresource
- Ga naar de NIC-instellingen voor elk van de clusterknooppunten en controleer of er geen externe DNS-records aanwezig zijn
- Zorg ervoor dat de A-record voor het cluster bestaat op de interne DNS-servers. Als dit niet het geval is, maakt u handmatig een nieuwe A-record op de DNS-server voor het object Clustertoegangsbeheer. Schakel vervolgens deze optie in: Toestaan dat alle geverifieerde gebruikers DNS-records kunnen bijwerken met dezelfde naam van eigenaar.
- Haal de resource Clusternaam met de IP-resource offline, een herstel deze.
Gebeurtenis 157 - Schijf is verrast.
Dit kan gebeuren als de eigenschap Opslagruimten AutomaticClusteringEnabled is ingesteld op True voor een AG-omgeving. Wijzig deze in False. Daarnaast kan het uitvoeren van een validatierapport met opslagoptie het opnieuw instellen of onverwacht verwijderen van een schijf activeren. Beperking van het opslagsysteem kan er ook voor zorgen dat een schijf onverwacht wordt verwijderd.
Gebeurtenis 1206 - Resource voor clusternetwerknamen kan niet online worden gebracht.
Het computerobject dat aan de resource is gekoppeld, kan niet worden bijgewerkt in het domein. Zorg ervoor dat u over de juiste machtigingen voor het domein beschikt
Windows Clustering-fouten
Er kunnen problemen optreden bij het instellen van een Windows-failovercluster of de bijbehorende connectiviteit als u geen clusterservicepoorten hebt geopend voor communicatie.
Als u Windows Server 2019 gebruikt en u geen IP-adres van een Windows-cluster ziet, hebt u gedistribueerde netwerknaam geconfigureerd. Dit wordt alleen ondersteund op SQL Server 2019. Als u een van de eerdere versies van SQL Server hebt, kunt u het cluster verwijderen en opnieuw maken met behulp van een netwerknaam.
Bekijk hier andere fouten met Windows-failoverclustering en hun oplossingen
Volgende stappen
Raadpleeg voor meer informatie:
- HADR-instellingen voor SQL Server op Azure-VM's
- Windows Server-failovercluster met SQL Server op Azure-VM's
- AlwaysOn-beschikbaarheidsgroepen met SQL Server op Azure-VM's
- Windows Server-failovercluster met SQL Server op Azure-VM's
- Failoverclusterexemplaren met SQL Server op Azure-VM's
- Overzicht van failoverclusterexemplaren
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor