Live gegevens migreren van Apache Cassandra naar De Azure Cosmos DB voor Apache Cassandra met behulp van een dual-write proxy en Apache Spark
API voor Cassandra in Azure Cosmos DB is een uitstekende keuze geworden voor zakelijke workloads die worden uitgevoerd op Apache Cassandra, om verschillende redenen, zoals:
Geen overhead voor beheer en bewaking: Het elimineert de overhead van het beheren en bewaken van talloze instellingen in besturingssysteem-, JVM- en yaml-bestanden en hun interacties.
Aanzienlijke kostenbesparingen: U kunt kosten besparen met Azure Cosmos DB, waaronder de kosten van VM's, bandbreedte en eventuele toepasselijke licenties. Bovendien hoeft u de datacentra, servers, SSD-opslag, netwerk- en elektriciteitskosten niet te beheren.
Mogelijkheid om bestaande code en hulpprogramma's te gebruiken: Azure Cosmos DB biedt compatibiliteit op wire-protocolniveau met bestaande Cassandra-SDK's en hulpprogramma's. Deze compatibiliteit zorgt ervoor dat u uw bestaande codebasis kunt gebruiken met Azure Cosmos DB voor Apache Cassandra met triviale wijzigingen.
Azure Cosmos DB biedt geen ondersteuning voor het systeemeigen Apache Cassandra-protocol voor replicatie. Daarom is een andere aanpak nodig wanneer geen downtime een vereiste is voor migratie. In deze zelfstudie wordt beschreven hoe u gegevens live migreert naar Azure Cosmos DB voor Apache Cassandra vanuit een systeemeigen Apache Cassandra-cluster met behulp van een dual-write proxy en Apache Spark.
In de volgende afbeelding ziet u het patroon. De proxy met twee schrijfbewerkingen wordt gebruikt om live wijzigingen vast te leggen, terwijl historische gegevens bulksgewijs worden gekopieerd met behulp van Apache Spark. De proxy kan verbindingen van uw toepassingscode accepteren met weinig of geen configuratiewijzigingen. Alle aanvragen worden doorgestuurd naar uw brondatabase en schrijfbewerkingen worden asynchroon naar de API voor Cassandra gerouteerd terwijl bulksgewijs wordt gekopieerd.

Vereisten
Een Azure Cosmos DB inrichten voor Apache Cassandra-account.
Bekijk de basisbeginselen van het maken van verbinding met een Azure Cosmos DB voor Apache Cassandra.
Bekijk de ondersteunde functies in Azure Cosmos DB voor Apache Cassandra om compatibiliteit te garanderen.
Zorg ervoor dat u een netwerkverbinding hebt tussen het broncluster en de doel-API voor het Cassandra-eindpunt.
Zorg ervoor dat u het keyspace-/tabelschema al hebt gemigreerd van uw cassandra-brondatabase naar uw doel-API voor cassandra-account.
Belangrijk
Als u een vereiste hebt om Apache Cassandra
writetimetijdens de migratie te behouden, moeten de volgende vlaggen worden ingesteld bij het maken van tabellen:with cosmosdb_cell_level_timestamp=true and cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=trueBijvoorbeeld:
CREATE KEYSPACE IF NOT EXISTS migrationkeyspace WITH REPLICATION= {'class': 'org.apache.> cassandra.locator.SimpleStrategy', 'replication_factor' : '1'};CREATE TABLE IF NOT EXISTS migrationkeyspace.users ( name text, userID int, address text, phone int, PRIMARY KEY ((name), userID)) with cosmosdb_cell_level_timestamp=true and > cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=true;
Een Spark-cluster inrichten
We raden Azure Databricks aan. Gebruik een runtime die ondersteuning biedt voor Spark 3.0 of hoger.
Belangrijk
U moet ervoor zorgen dat uw Azure Databricks-account een netwerkverbinding heeft met uw broncluster van Apache Cassandra. Hiervoor is mogelijk VNet-injectie vereist. Zie het artikel hier voor meer informatie.
Spark-afhankelijkheden toevoegen
U moet de Apache Spark Cassandra Connector-bibliotheek toevoegen aan uw cluster om verbinding te maken met zowel systeemeigen als Azure Cosmos DB Cassandra-eindpunten. Selecteer in uw cluster Bibliotheken>Nieuwe>Maven installeren en voeg vervolgens Maven-coördinaten toe com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 .
Belangrijk
Als u apache Cassandra writetime voor elke rij tijdens de migratie moet behouden, raden we u aan dit voorbeeld te gebruiken. Het jar-bestand voor afhankelijkheden in dit voorbeeld bevat ook de Spark-connector, dus u moet deze installeren in plaats van de connectorassembly hierboven. Dit voorbeeld is ook handig als u een rijvergelijkingsvalidatie tussen bron en doel wilt uitvoeren nadat het laden van historische gegevens is voltooid. Zie de secties 'De historische gegevensbelasting uitvoeren' en 'de bron en het doel valideren' hieronder voor meer informatie.
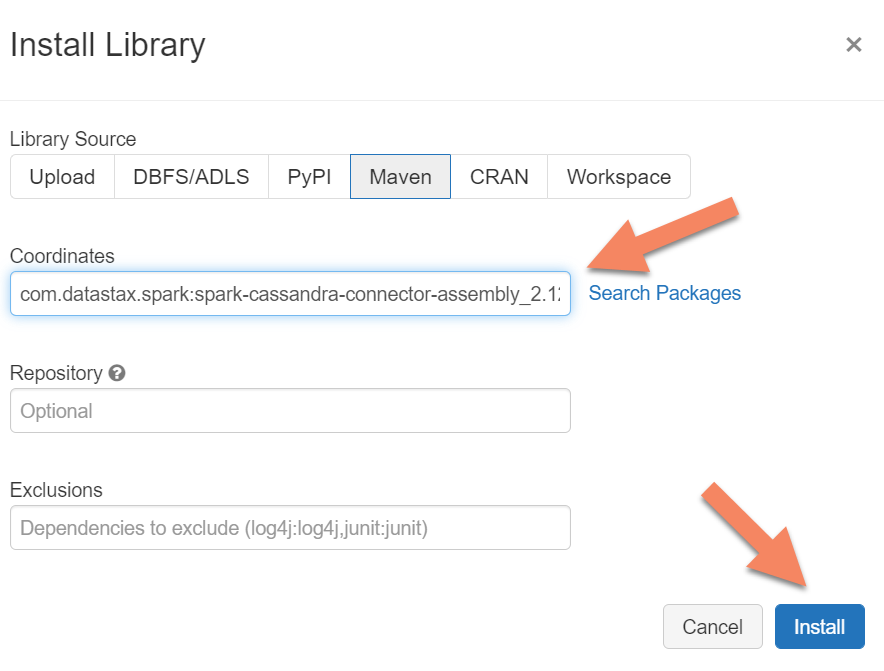
Selecteer Installeren en start het cluster opnieuw wanneer de installatie is voltooid.
Notitie
Zorg ervoor dat u het Azure Databricks-cluster opnieuw start nadat de Cassandra Connector-bibliotheek is geïnstalleerd.
De proxy voor dubbel schrijven installeren
Voor optimale prestaties tijdens dubbele schrijfbewerkingen raden we u aan de proxy te installeren op alle knooppunten in uw cassandra-broncluster.
#assuming you do not have git already installed
sudo apt-get install git
#assuming you do not have maven already installed
sudo apt install maven
#clone repo for dual-write proxy
git clone https://github.com/Azure-Samples/cassandra-proxy.git
#change directory
cd cassandra-proxy
#compile the proxy
mvn package
De proxy voor dubbel schrijven starten
U wordt aangeraden de proxy te installeren op alle knooppunten in uw cassandra-broncluster. Voer minimaal de volgende opdracht uit om de proxy op elk knooppunt te starten. Vervang door <target-server> een IP- of serveradres van een van de knooppunten in het doelcluster. Vervang door <path to JKS file> het pad naar een lokaal .jks-bestand en vervang door <keystore password> het bijbehorende wachtwoord.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password>
Als u de proxy op deze manier start, wordt ervan uitgegaan dat het volgende waar is:
- Bron- en doeleindpunten hebben dezelfde gebruikersnaam en hetzelfde wachtwoord.
- Bron- en doeleindpunten implementeren SSL (Secure Sockets Layer).
Als uw bron- en doeleindpunten niet aan deze criteria voldoen, leest u verder voor meer configuratieopties.
SSL configureren
Voor SSL kunt u een bestaand sleutelarchief implementeren (bijvoorbeeld het sleutelarchief dat door het broncluster wordt gebruikt) of een zelfondertekend certificaat maken met behulp van keytool:
keytool -genkey -keyalg RSA -alias selfsigned -keystore keystore.jks -storepass password -validity 360 -keysize 2048
U kunt SSL ook uitschakelen voor bron- of doeleindpunten als er geen SSL wordt geïmplementeerd. Gebruik de --disable-source-tls vlaggen of --disable-target-tls :
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password> --disable-source-tls true --disable-target-tls true
Notitie
Zorg ervoor dat uw clienttoepassing hetzelfde sleutelarchief en wachtwoord gebruikt als het wachtwoord dat wordt gebruikt voor de proxy voor twee schrijfbewerkingen wanneer u SSL-verbindingen met de database maakt via de proxy.
De referenties en poort configureren
De bronreferenties worden standaard doorgegeven vanuit uw client-app. De proxy gebruikt de referenties voor het maken van verbindingen met de bron- en doelclusters. Zoals eerder vermeld, wordt bij dit proces ervan uitgegaan dat de bron- en doelreferenties hetzelfde zijn. Bij het starten van de proxy moet u afzonderlijk een andere gebruikersnaam en een ander wachtwoord opgeven voor de doel-API voor het Cassandra-eindpunt:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
De standaardbron- en doelpoorten, indien niet opgegeven, zijn 9042. In dit geval wordt API voor Cassandra uitgevoerd op poort 10350, dus moet u poortnummers gebruiken --source-port of --target-port opgeven:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
De proxy extern implementeren
Er kunnen omstandigheden zijn waarin u de proxy niet op de clusterknooppunten zelf wilt installeren en u deze liever op een afzonderlijke computer installeert. In dat scenario moet u het IP-adres opgeven van <source-server>:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar <source-server> <destination-server>
Waarschuwing
Het op afstand installeren en uitvoeren van de proxy op een afzonderlijke computer (in plaats van deze uit te voeren op alle knooppunten in uw apache Cassandra-broncluster) heeft invloed op de prestaties tijdens de livemigratie. Hoewel het functioneel werkt, kan het clientstuurprogramma geen verbindingen openen met alle knooppunten in het cluster en is het afhankelijk van het enkele coördinatorknooppunt (waar de proxy is geïnstalleerd) om verbindingen te maken.
Geen wijzigingen in toepassingscode toestaan
Standaard luistert de proxy op poort 29042. De toepassingscode moet worden gewijzigd zodat deze naar deze poort verwijst. U kunt echter de poort wijzigen waarop de proxy luistert. U kunt dit doen als u codewijzigingen op toepassingsniveau wilt elimineren door:
- De cassandra-bronserver op een andere poort laten uitvoeren.
- De proxy uitvoeren op de standaard Cassandra-poort 9042.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042
Notitie
Als u de proxy op clusterknooppunten installeert, hoeft u de knooppunten niet opnieuw op te starten. Als u echter veel toepassingsclients hebt en de proxy liever uitvoert op de standaard Cassandra-poort 9042 om eventuele wijzigingen in code op toepassingsniveau te elimineren, moet u de standaardpoort van Apache Cassandra wijzigen. Vervolgens moet u de knooppunten in uw cluster opnieuw opstarten en de bronpoort configureren als de nieuwe poort die u hebt gedefinieerd voor uw cassandra-broncluster.
In het volgende voorbeeld wijzigen we het Cassandra-broncluster zodat deze wordt uitgevoerd op poort 3074 en starten we het cluster op poort 9042:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042 --source-port 3074
Protocollen forceren
De proxy heeft functionaliteit om protocollen af te dwingen, wat nodig kan zijn als het broneindpunt geavanceerder is dan het doel of anderszins niet wordt ondersteund. In dat geval kunt u opgeven --protocol-version en --cql-version afdwingen dat het protocol voldoet aan het doel:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --protocol-version 4 --cql-version 3.11
Nadat de proxy met twee schrijfbewerkingen is uitgevoerd, moet u de poort op de toepassingsclient wijzigen en opnieuw opstarten. (Of wijzig de Cassandra-poort en start het cluster opnieuw op als u deze methode hebt gekozen.) De proxy begint vervolgens met het doorsturen van schrijfbewerkingen naar het doeleindpunt. U vindt meer informatie over bewaking en metrische gegevens die beschikbaar zijn in het proxyhulpprogramma.
Het laden van historische gegevens uitvoeren
Als u de gegevens wilt laden, maakt u een Scala-notebook in uw Azure Databricks-account. Vervang uw cassandra-bron- en doelconfiguraties door de bijbehorende referenties en vervang de bron- en doelsleutelruimten en -tabellen. Voeg voor elke tabel naar behoefte meer variabelen toe aan het volgende voorbeeld en voer vervolgens uit. Nadat uw toepassing begint met het verzenden van aanvragen naar de proxy voor twee schrijfbewerkingen, bent u klaar om historische gegevens te migreren.
Belangrijk
Voordat u de gegevens migreert, moet u de doorvoer van de container verhogen tot de hoeveelheid die nodig is om uw toepassing snel te migreren. Als u de doorvoer schaalt voordat u de migratie start, kunt u uw gegevens in minder tijd migreren. Ter bescherming tegen snelheidsbeperking tijdens het laden van historische gegevens kunt u mogelijk nieuwe pogingen aan de serverzijde (SSR) inschakelen in API voor Cassandra. Zie ons artikel hier voor meer informatie en instructies voor het inschakelen van SSR.
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//set timestamp to ensure it is before read job starts
val timestamp: Long = System.currentTimeMillis / 1000
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.option("writetime", timestamp)
.mode(SaveMode.Append)
.save
Notitie
In het voorgaande Scala-voorbeeld ziet u dat timestamp wordt ingesteld op de huidige tijd voordat alle gegevens in de brontabel worden gelezen. writetime Vervolgens wordt deze backdated tijdstempel ingesteld. Dit zorgt ervoor dat records die zijn geschreven vanuit de historische gegevensbelasting naar het doeleindpunt geen updates kunnen overschrijven die met een latere tijdstempel van de proxy voor dubbele schrijfbewerkingen worden verzonden terwijl historische gegevens worden gelezen.
Belangrijk
Als u om welke reden dan ook exacte tijdstempels wilt behouden, moet u een benadering voor historische gegevensmigratie gebruiken waarbij tijdstempels behouden blijven, zoals dit voorbeeld. Het jar-bestand voor afhankelijkheden in het voorbeeld bevat ook de Spark-connector, zodat u de Assembly van de Spark-connector die in de eerdere vereisten is vermeld, niet hoeft te installeren. Als u beide in uw Spark-cluster hebt geïnstalleerd, ontstaan er conflicten.
De bron en het doel valideren
Nadat het laden van historische gegevens is voltooid, moeten uw databases gesynchroniseerd zijn en klaar zijn voor cutover. We raden u echter aan de bron en het doel te valideren om ervoor te zorgen dat ze overeenkomen voordat u definitief overhaaste.
Notitie
Als u het hierboven genoemde cassandra-migratievoorbeeld hebt gebruikt voor het behouden writetimevan , omvat dit de mogelijkheid om de migratie te valideren door rijen in bron en doel te vergelijken op basis van bepaalde toleranties.