Tips voor betere prestaties voor De Python SDK van Azure Cosmos DB
VAN TOEPASSING OP: ![]() NoSQL
NoSQL
Belangrijk
De tips voor prestaties in dit artikel zijn alleen bedoeld voor Azure Cosmos DB Python SDK. Raadpleeg de releaseopmerkingen voor De Leesmij-releasevan Azure Cosmos DB Python SDK, Package (PyPI), Package (Conda) en gids voor probleemoplossing voor meer informatie.
Azure Cosmos DB is een snelle en flexibele gedistribueerde database die naadloos wordt geschaald met gegarandeerde latentie en doorvoer. U hoeft geen belangrijke architectuurwijzigingen aan te brengen of complexe code te schrijven om uw database te schalen met Azure Cosmos DB. Omhoog en omlaag schalen is net zo eenvoudig als het maken van één API-aanroep of SDK-methode-aanroep. Omdat Azure Cosmos DB echter toegankelijk is via netwerkaanroepen, zijn er optimalisaties aan de clientzijde die u kunt maken om piekprestaties te bereiken bij het gebruik van de Python SDK van Azure Cosmos DB.
Dus als u 'Hoe kan ik de prestaties van mijn database verbeteren?' vraagt, moet u rekening houden met de volgende opties:
Netwerken
- Clients in dezelfde Azure-regio plaatsen voor prestaties
Plaats indien mogelijk toepassingen die Azure Cosmos DB aanroepen in dezelfde regio als de Azure Cosmos DB-database. Voor een geschatte vergelijking zijn aanroepen naar Azure Cosmos DB binnen dezelfde regio voltooid binnen 1-2 ms, maar de latentie tussen de west- en oostkust van de VS is >50 ms. Deze latentie kan waarschijnlijk variëren van aanvraag tot aanvraag, afhankelijk van de route die door de aanvraag wordt genomen, omdat deze wordt doorgegeven van de client naar de grens van het Azure-datacenter. De laagst mogelijke latentie wordt bereikt door ervoor te zorgen dat de aanroepende toepassing zich in dezelfde Azure-regio bevindt als het ingerichte Azure Cosmos DB-eindpunt. Zie Azure-regio's voor een lijst met beschikbare regio's.
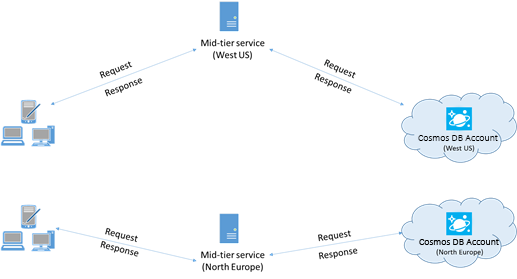
Een app die communiceert met een Azure Cosmos DB-account met meerdere regio's, moet voorkeurslocaties configureren om ervoor te zorgen dat aanvragen naar een regio met meerdere regio's gaan.
Versneld netwerken inschakelen om latentie en CPU-jitter te verminderen
Het is raadzaam om de instructies te volgen om versneld netwerken in te schakelen in uw Windows (selecteer voor instructies) of Linux (selecteer voor instructies) Azure VM om de prestaties te maximaliseren (latentie en CPU-jitter verminderen).
Zonder versneld netwerken kan IO die tussen uw Azure-VM en andere Azure-resources wordt verzonden, onnodig worden gerouteerd via een host en virtuele switch tussen de VIRTUELE machine en de bijbehorende netwerkkaart. Als de host en virtuele switch inline in het gegevenspad worden geplaatst, neemt niet alleen de latentie en jitter in het communicatiekanaal toe, maar wordt ook de CPU-cycli van de VIRTUELE machine gestolen. Met versneld netwerken, de VM-interfaces rechtstreeks met de NIC zonder tussenpersonen; alle netwerkbeleidsgegevens die door de host en virtuele switch werden verwerkt, worden nu verwerkt in hardware op de NIC; de host en virtuele switch worden omzeild. Over het algemeen kunt u lagere latentie en hogere doorvoer verwachten, evenals consistentere latentie en een lager CPU-gebruik wanneer u versneld netwerken inschakelt.
Beperkingen: versneld netwerken moeten worden ondersteund op het VM-besturingssysteem en kunnen alleen worden ingeschakeld wanneer de VIRTUELE machine wordt gestopt en de toewijzing ervan ongedaan wordt gemaakt. De VM kan niet worden geïmplementeerd met Azure Resource Manager. App Service heeft geen versneld netwerk ingeschakeld.
Raadpleeg de windows- en Linux-instructies voor meer informatie.
SDK-gebruik
- De meest recente SDK installeren
De Azure Cosmos DB SDK's worden voortdurend verbeterd om de beste prestaties te bieden. Zie de releaseopmerkingen van de Azure Cosmos DB SDK om de meest recente SDK te bepalen en verbeteringen te bekijken.
- Een Singleton Azure Cosmos DB-client gebruiken voor de levensduur van uw toepassing
Elk Azure Cosmos DB-clientexemplaren is thread-veilig en voert efficiënt verbindingsbeheer en adrescaching uit. Om efficiënt verbindingsbeheer en betere prestaties van de Azure Cosmos DB-client mogelijk te maken, is het raadzaam om één exemplaar van de Azure Cosmos DB-client te gebruiken voor de levensduur van de toepassing.
- Time-outs afstemmen en configuraties opnieuw proberen
Time-outconfiguraties en beleid voor opnieuw proberen kunnen worden aangepast op basis van de behoeften van de toepassing. Raadpleeg het configuratiedocument voor time-outs en nieuwe pogingen om een volledige lijst met configuraties op te halen die kunnen worden aangepast.
- Het laagste consistentieniveau gebruiken dat is vereist voor uw toepassing
Wanneer u een CosmosClient maakt, wordt consistentie op accountniveau gebruikt als er geen is opgegeven bij het maken van de client. Zie het document over consistentieniveaus voor meer informatie over consistentieniveaus .
- Uw clientworkload uitschalen
Als u test op hoge doorvoerniveaus, kan de clienttoepassing het knelpunt worden omdat de computer het CPU- of netwerkgebruik beperkt. Als u dit punt bereikt, kunt u het Azure Cosmos DB-account verder pushen door uw clienttoepassingen uit te schalen op meerdere servers.
Een goede vuistregel is niet groter dan >50% CPU-gebruik op een bepaalde server, om latentie laag te houden.
- Resourcelimiet voor openen van besturingssysteembestanden
Sommige Linux-systemen (zoals Red Hat) hebben een bovengrens voor het aantal geopende bestanden en dus het totale aantal verbindingen. Voer het volgende uit om de huidige limieten weer te geven:
ulimit -a
Het aantal geopende bestanden (nofile) moet groot genoeg zijn om voldoende ruimte te hebben voor de geconfigureerde grootte van de verbindingsgroep en andere geopende bestanden door het besturingssysteem. Het kan worden gewijzigd om een grotere verbindingsgroepgrootte toe te staan.
Open het bestand limits.conf:
vim /etc/security/limits.conf
Voeg de volgende regels toe/wijzigt:
* - nofile 100000
Querybewerkingen
Zie de prestatietips voor querybewerkingen voor query's.
Indexeringsbeleid
- Niet-gebruikte paden uitsluiten van indexering voor snellere schrijfbewerkingen
Met het indexeringsbeleid van Azure Cosmos DB kunt u opgeven welke documentpaden moeten worden opgenomen of uitgesloten van indexering door gebruik te maken van indexeringspaden (setIncludedPaths en setExcludedPaths). Het gebruik van indexeringspaden kan betere schrijfprestaties en lagere indexopslag bieden voor scenario's waarin de querypatronen vooraf bekend zijn, omdat indexeringskosten rechtstreeks worden gecorreleerd aan het aantal unieke paden dat is geïndexeerd. In de volgende code ziet u bijvoorbeeld hoe u volledige secties van de documenten (ook wel substructuur genoemd) kunt opnemen en uitsluiten van indexering met behulp van het jokerteken *.
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Zie Het indexeringsbeleid van Azure Cosmos DB voor meer informatie.
Doorvoer
- Meten en afstemmen op lagere aanvraageenheden/tweede gebruik
Azure Cosmos DB biedt een uitgebreide set databasebewerkingen, waaronder relationele en hiërarchische query's met UDF's, opgeslagen procedures en triggers, die allemaal werken op de documenten in een databaseverzameling. De kosten die gepaard gaan met elke bewerking hangen af van de CPU, de IO en het geheugen, vereist om de bewerking uit te voeren. In plaats van aan hardwareresources te denken en te beheren, kunt u een aanvraageenheid (RU) beschouwen als één meting voor de resources die nodig zijn voor het uitvoeren van verschillende databasebewerkingen en het uitvoeren van een toepassingsaanvraag.
Doorvoer wordt ingericht op basis van het aantal aanvraageenheden dat is ingesteld voor elke container. Verbruik van aanvraageenheden wordt geëvalueerd als een tarief per seconde. Toepassingen die de ingerichte aanvraageenheidsnelheid voor hun container overschrijden, zijn beperkt totdat de snelheid lager is dan het ingerichte niveau voor de container. Als uw toepassing een hoger doorvoerniveau vereist, kunt u de doorvoer verhogen door extra aanvraageenheden in te richten.
De complexiteit van een query heeft invloed op het aantal aanvraageenheden dat wordt verbruikt voor een bewerking. Het aantal predicaten, de aard van de predicaten, het aantal UDF's en de grootte van de brongegevensset zijn allemaal van invloed op de kosten van querybewerkingen.
Als u de overhead van een bewerking wilt meten (maken, bijwerken of verwijderen), inspecteert u de header x-ms-request-charge om het aantal aanvraageenheden te meten dat door deze bewerkingen wordt verbruikt.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
De aanvraagkosten die in deze header worden geretourneerd, zijn een fractie van uw ingerichte doorvoer. Als u bijvoorbeeld 2000 RU/s hebt ingericht en als de voorgaande query 1000 1KB-documenten retourneert, zijn de kosten van de bewerking 1000. Daarom eert de server binnen één seconde slechts twee dergelijke aanvragen voordat de frequentie van volgende aanvragen wordt beperkt. Zie Aanvraageenheden en de rekenmachine voor aanvraageenheden voor meer informatie.
- Snelheidsbeperking/aanvraagsnelheid te groot verwerken
Wanneer een client de gereserveerde doorvoer voor een account probeert te overschrijden, is er geen prestatievermindering op de server en is er geen gebruik van doorvoercapaciteit buiten het gereserveerde niveau. De server beëindigt de aanvraag met RequestRateTooLarge (HTTP-statuscode 429) en retourneert de header x-ms-retry-after-ms die de hoeveelheid tijd aangeeft, in milliseconden, dat de gebruiker moet wachten voordat de aanvraag opnieuw wordt geïmplementeerd.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
De SDK's vangen dit antwoord impliciet op, respecteren de server opgegeven nieuwe poging na header en probeer de aanvraag opnieuw. Tenzij uw account gelijktijdig wordt geopend door meerdere clients, slaagt de volgende nieuwe poging.
Als u meerdere clients cumulatief boven de aanvraagsnelheid hebt, is het standaardaantal nieuwe pogingen dat momenteel is ingesteld op 9 intern door de client mogelijk niet voldoende; In dit geval genereert de client een CosmosHttpResponseError met statuscode 429 aan de toepassing. Het standaardaantal nieuwe pogingen kan worden gewijzigd door de configuratie door te geven retry_total aan de client. De CosmosHttpResponseError met statuscode 429 wordt standaard geretourneerd na een cumulatieve wachttijd van 30 seconden als de aanvraag blijft werken boven de aanvraagsnelheid. Dit gebeurt zelfs wanneer het huidige aantal nieuwe pogingen kleiner is dan het maximumaantal nieuwe pogingen, of het nu de standaardwaarde is van 9 of een door de gebruiker gedefinieerde waarde.
Hoewel het geautomatiseerde gedrag voor opnieuw proberen helpt om de tolerantie en bruikbaarheid voor de meeste toepassingen te verbeteren, kan het even vreemd komen bij het uitvoeren van prestatiebenchmarks, met name bij het meten van latentie. De door de client waargenomen latentie zal pieken als het experiment de server beperkt en ervoor zorgt dat de client-SDK op de achtergrond opnieuw probeert. Als u latentiepieken tijdens prestatieexperimenten wilt voorkomen, meet u de kosten die door elke bewerking worden geretourneerd en zorgt u ervoor dat aanvragen onder de gereserveerde aanvraagsnelheid worden uitgevoerd. Zie Aanvraageenheden voor meer informatie.
- Ontwerpen voor kleinere documenten voor hogere doorvoer
De aanvraagkosten (de aanvraagverwerkingskosten) van een bepaalde bewerking worden rechtstreeks gecorreleerd aan de grootte van het document. Bewerkingen op grote documenten kosten meer dan bewerkingen voor kleine documenten. U kunt uw toepassing en werkstromen het beste ontwerpen om de grootte van uw item ongeveer 1 kB te hebben, of een vergelijkbare volgorde of grootte. Voor latentiegevoelige toepassingen moeten grote items worden vermeden: documenten met meerdere MB vertragen uw toepassing.
Volgende stappen
Zie Partitioneren en schalen in Azure Cosmos DB voor meer informatie over het ontwerpen van uw toepassing voor schaalaanpassing en hoge prestaties.
Wilt u capaciteitsplanning uitvoeren voor een migratie naar Azure Cosmos DB? U kunt informatie over uw bestaande databasecluster gebruiken voor capaciteitsplanning.
- Als alles wat u weet het aantal vCores en servers in uw bestaande databasecluster is, leest u meer over het schatten van aanvraageenheden met behulp van vCores of vCPU's
- Als u typische aanvraagtarieven voor uw huidige databaseworkload kent, leest u meer over het schatten van aanvraageenheden met behulp van azure Cosmos DB-capaciteitsplanner