Gegevens kopiëren van Amazon RDS voor SQL Server met behulp van Azure Data Factory of Azure Synapse Analytics
In dit artikel wordt beschreven hoe u de kopieeractiviteit in Azure Data Factory en Azure Synapse-pijplijnen gebruikt om gegevens te kopiëren van Amazon RDS voor SQL Server-database. Lees het inleidende artikel voor Azure Data Factory of Azure Synapse Analytics voor meer informatie.
Ondersteunde mogelijkheden
Deze Amazon RDS voor SQL Server-connector wordt ondersteund voor de volgende mogelijkheden:
| Ondersteunde mogelijkheden | IR |
|---|---|
| Copy-activiteit (bron/-) | (1) (2) |
| Activiteit Lookup | (1) (2) |
| GetMetadata-activiteit | (1) (2) |
| Opgeslagen procedureactiviteit | (1) (2) |
(1) Azure Integration Runtime (2) Zelf-hostende Integration Runtime
Zie de tabel Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen of sinks door de kopieeractiviteit.
Deze Amazon RDS voor SQL Server-connector ondersteunt met name:
- SQL Server versie 2005 en hoger.
- Gegevens kopiëren met behulp van SQL- of Windows-verificatie.
- Als bron kunt u gegevens ophalen met behulp van een SQL-query of een opgeslagen procedure. U kunt er ook voor kiezen om parallel te kopiëren vanuit Amazon RDS voor SQL Server-bron. Zie de sectie Parallel kopiëren uit de SQL-database voor meer informatie.
SQL Server Express LocalDB wordt niet ondersteund.
Vereisten
Als uw gegevensarchief zich in een on-premises netwerk, een virtueel Azure-netwerk of een virtuele particuliere cloud van Amazon bevindt, moet u een zelf-hostende Integration Runtime configureren om er verbinding mee te maken.
Als uw gegevensarchief een beheerde cloudgegevensservice is, kunt u De Azure Integration Runtime gebruiken. Als de toegang is beperkt tot IP-adressen die zijn goedgekeurd in de firewallregels, kunt u IP-adressen van Azure Integration Runtime toevoegen aan de acceptatielijst.
U kunt ook de beheerde functie voor integratieruntime voor virtuele netwerken in Azure Data Factory gebruiken om toegang te krijgen tot het on-premises netwerk zonder een zelf-hostende Integration Runtime te installeren en te configureren.
Zie Strategieën voor gegevenstoegang voor meer informatie over de netwerkbeveiligingsmechanismen en -opties die door Data Factory worden ondersteund.
Aan de slag
Als u de kopieeractiviteit wilt uitvoeren met een pijplijn, kunt u een van de volgende hulpprogramma's of SDK's gebruiken:
- Het hulpprogramma voor het kopiëren van gegevens
- Azure Portal
- De .NET-SDK
- De Python-SDK
- Azure PowerShell
- De REST API
- Een Azure Resource Manager-sjabloon
Een gekoppelde Amazon RDS-service voor SQL Server maken met behulp van de gebruikersinterface
Gebruik de volgende stappen om een gekoppelde Amazon RDS-service voor SQL Server te maken in de gebruikersinterface van Azure Portal.
Blader naar het tabblad Beheren in uw Azure Data Factory- of Synapse-werkruimte en selecteer Gekoppelde services en klik vervolgens op Nieuw:
Zoek naar Amazon RDS voor SQL Server en selecteer de Amazon RDS voor SQL Server-connector.
Configureer de servicedetails, test de verbinding en maak de nieuwe gekoppelde service.
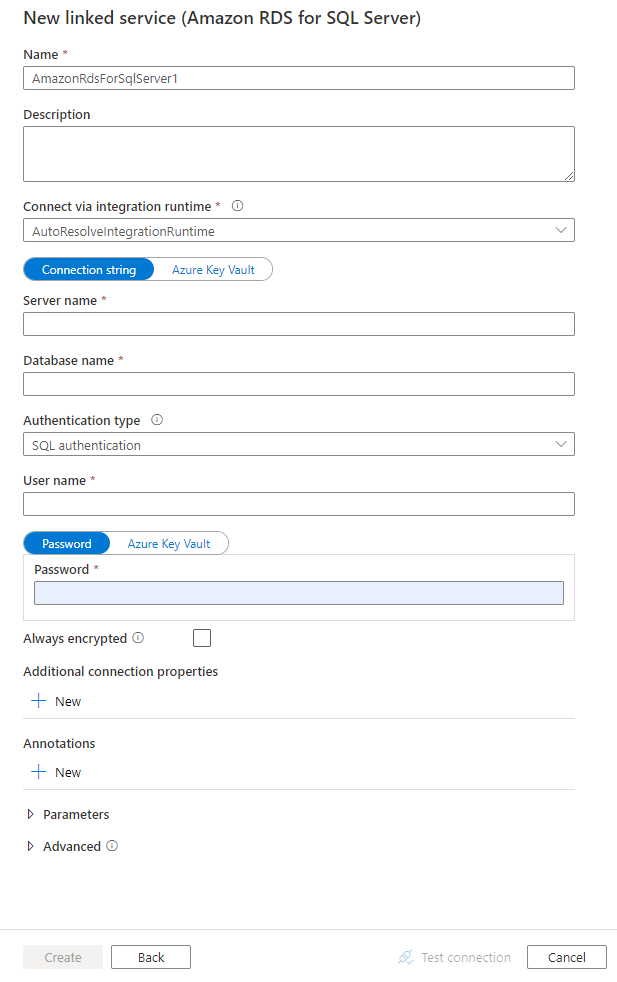
configuratiedetails Verbinding maken or
De volgende secties bevatten details over eigenschappen die worden gebruikt voor het definiëren van Data Factory- en Synapse-pijplijnentiteiten die specifiek zijn voor de Amazon RDS voor SQL Server-databaseconnector.
Eigenschappen van gekoppelde service
De volgende eigenschappen worden ondersteund voor de gekoppelde Amazon RDS voor sql Server-service:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De eigenschap type moet worden ingesteld op AmazonRdsForSqlServer. | Ja |
| connectionString | Geef connectionString-informatie op die nodig is om verbinding te maken met de Amazon RDS voor SQL Server-database met behulp van SQL-verificatie of Windows-verificatie. Raadpleeg de volgende voorbeelden. U kunt ook een wachtwoord in Azure Key Vault plaatsen. Als het SQL-verificatie is, haalt u de password configuratie uit de verbindingsreeks. Zie het JSON-voorbeeld na de tabel en De referenties opslaan in Azure Key Vault voor meer informatie. |
Ja |
| gebruikersnaam | Geef een gebruikersnaam op als u Windows-verificatie gebruikt. Een voorbeeld is domeinnaam\gebruikersnaam. | Nee |
| password | Geef een wachtwoord op voor het gebruikersaccount dat u hebt opgegeven voor de gebruikersnaam. Markeer dit veld als SecureString om het veilig op te slaan. U kunt ook verwijzen naar een geheim dat is opgeslagen in Azure Key Vault. | Nee |
| alwaysEncrypted Instellingen | Geef altijd versleuteldesettingsgegevens op die nodig zijn om Always Encrypted in te schakelen voor het beveiligen van gevoelige gegevens die zijn opgeslagen in Amazon RDS voor SQL Server met behulp van beheerde identiteit of service-principal. Zie het JSON-voorbeeld na de tabel en de sectie Always Encrypted gebruiken voor meer informatie. Als dit niet is opgegeven, wordt de standaardinstelling altijd versleuteld uitgeschakeld. | Nee |
| connectVia | Deze integratieruntime wordt gebruikt om verbinding te maken met het gegevensarchief. Meer informatie vindt u in de sectie Vereisten . Als dit niet is opgegeven, wordt de standaard Azure Integration Runtime gebruikt. | Nr. |
Notitie
Amazon RDS voor SQL Server Always Encrypted wordt niet ondersteund in de gegevensstroom.
Tip
Als u een fout krijgt met de foutcode UserErrorFailedTo Verbinding maken ToSqlServer en een bericht zoals 'De sessielimiet voor de database is XXX en is bereikt', voegt u toe Pooling=false aan uw verbindingsreeks en probeert u het opnieuw.
Voorbeeld 1: SQL-verificatie gebruiken
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld 2: SQL-verificatie gebruiken met een wachtwoord in Azure Key Vault
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld 3: Windows-verificatie gebruiken
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=True;",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Voorbeeld 4: Always Encrypted gebruiken
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"connectionString": "Data Source=<servername>\\<instance name if using named instance>;Initial Catalog=<databasename>;Integrated Security=False;User ID=<username>;Password=<password>;"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Eigenschappen van gegevensset
Zie het artikel gegevenssets voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor het definiëren van gegevenssets . Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Amazon RDS voor SQL Server-gegevensset.
Als u gegevens wilt kopiëren van een Amazon RDS voor SQL Server-database, worden de volgende eigenschappen ondersteund:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de gegevensset moet worden ingesteld op AmazonRdsForSqlServerTable. | Ja |
| schema | Naam van het schema. | Nee |
| table | Naam van de tabel/weergave. | Nee |
| tableName | Naam van de tabel/weergave met schema. Deze eigenschap wordt ondersteund voor compatibiliteit met eerdere versies. Voor nieuwe workload gebruikt schema u en table. |
Nee |
Voorbeeld
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Eigenschappen van de kopieeractiviteit
Zie het artikel Pijplijnen voor een volledige lijst met secties en eigenschappen die beschikbaar zijn voor gebruik om activiteiten te definiëren. Deze sectie bevat een lijst met eigenschappen die worden ondersteund door de Amazon RDS voor SQL Server-bron.
Amazon RDS voor SQL Server als bron
Tip
Als u gegevens efficiënt wilt laden vanuit Amazon RDS voor SQL Server met behulp van gegevenspartitionering, vindt u meer informatie over parallel kopiëren vanuit sql-database.
Als u gegevens van Amazon RDS voor SQL Server wilt kopiëren, stelt u het brontype in de kopieeractiviteit in op AmazonRdsForSqlServerSource. De volgende eigenschappen worden ondersteund in de sectie bron van kopieeractiviteit:
| Eigenschappen | Beschrijving | Vereist |
|---|---|---|
| type | De typeeigenschap van de bron van de kopieeractiviteit moet worden ingesteld op AmazonRdsForSqlServerSource. | Ja |
| sqlReaderQuery | Gebruik de aangepaste SQL-query om gegevens te lezen. Een voorbeeld is select * from MyTable. |
Nee |
| sqlReaderStoredProcedureName | Deze eigenschap is de naam van de opgeslagen procedure waarmee gegevens uit de brontabel worden gelezen. De laatste SQL-instructie moet een SELECT-instructie zijn in de opgeslagen procedure. | Nee |
| storedProcedureParameters | Deze parameters zijn voor de opgeslagen procedure. Toegestane waarden zijn naam- of waardeparen. De namen en hoofdletters van parameters moeten overeenkomen met de namen en hoofdletters van de opgeslagen procedureparameters. |
Nee |
| isolationLevel | Hiermee geeft u het gedrag voor transactievergrendeling voor de SQL-bron op. De toegestane waarden zijn: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Als dit niet is opgegeven, wordt het standaardisolatieniveau van de database gebruikt. Raadpleeg dit document voor meer informatie. | Nee |
| partitionOptions | Hiermee geeft u de opties voor gegevenspartitionering op die worden gebruikt voor het laden van gegevens uit Amazon RDS voor SQL Server. Toegestane waarden zijn: Geen (standaard), PhysicalPartitionsOfTable en DynamicRange. Wanneer een partitieoptie is ingeschakeld (dat wil niet None), wordt de mate van parallelle uitvoering om gegevens van Amazon RDS voor SQL Server gelijktijdig te laden, beheerd door de parallelCopies instelling voor de kopieeractiviteit. |
Nee |
| partitie Instellingen | Geef de groep van de instellingen voor gegevenspartitionering op. Toepassen wanneer de partitieoptie niet Noneis. |
Nee |
Onder partitionSettings: |
||
| partitionColumnName | Geef de naam op van de bronkolom in geheel getal of datum/datum/tijd -type (int, smallint, bigintdate, smalldatetime, , datetimeof datetime2datetimeoffset) dat wordt gebruikt door bereikpartitionering voor parallelle kopie. Als deze niet is opgegeven, wordt de index of de primaire sleutel van de tabel automatisch gedetecteerd en gebruikt als partitiekolom.Toepassen wanneer de partitieoptie is DynamicRange. Als u een query gebruikt om de brongegevens op te halen, koppelt u deze ?DfDynamicRangePartitionCondition aan de WHERE-component. Zie de sectie Parallel kopiëren uit de SQL-database voor een voorbeeld. |
Nee |
| partitionUpperBound | De maximumwaarde van de partitiekolom voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partitie-onderdrukking te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Toepassen wanneer de partitieoptie is DynamicRange. Zie de sectie Parallel kopiëren uit de SQL-database voor een voorbeeld. |
Nee |
| partitionLowerBound | De minimale waarde van de partitiekolom voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partitie-onderdrukking te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Toepassen wanneer de partitieoptie is DynamicRange. Zie de sectie Parallel kopiëren uit de SQL-database voor een voorbeeld. |
Nee |
Houd rekening met de volgende punten:
- Als sqlReaderQuery is opgegeven voor AmazonRdsForSqlServerSource, voert de kopieeractiviteit deze query uit op de Amazon RDS voor SQL Server-bron om de gegevens op te halen. U kunt ook een opgeslagen procedure opgeven door sqlReaderStoredProcedureName en storedProcedureParameters op te geven als de opgeslagen procedure parameters gebruikt.
- Wanneer u opgeslagen procedure in de bron gebruikt om gegevens op te halen, moet u er rekening mee houden dat uw opgeslagen procedure is ontworpen als het retourneren van een ander schema wanneer een andere parameterwaarde wordt doorgegeven, mogelijk een fout optreedt of onverwacht resultaat ziet bij het importeren van het schema uit de gebruikersinterface of bij het kopiëren van gegevens naar sql-database met automatisch maken van tabellen.
Voorbeeld: SQL-query gebruiken
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Voorbeeld: Een opgeslagen procedure gebruiken
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
De definitie van de opgeslagen procedure
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Parallel kopiëren uit SQL-database
De Amazon RDS voor SQL Server-connector in kopieeractiviteit biedt ingebouwde gegevenspartitionering om gegevens parallel te kopiëren. U vindt opties voor gegevenspartitionering op het tabblad Bron van de kopieeractiviteit.

Wanneer u gepartitioneerde kopie inschakelt, voert de kopieeractiviteit parallelle query's uit op uw Amazon RDS voor SQL Server-bron om gegevens te laden op partities. De parallelle graad wordt bepaald door de parallelCopies instelling voor de kopieeractiviteit. Als u bijvoorbeeld instelt op parallelCopies vier, genereert de service gelijktijdig vier query's op basis van de opgegeven partitieoptie en -instellingen en haalt elke query een deel van de gegevens op uit uw Amazon RDS voor SQL Server.
U wordt aangeraden om parallel kopiëren met gegevenspartitionering in te schakelen, met name wanneer u grote hoeveelheden gegevens uit uw Amazon RDS voor SQL Server laadt. Hier volgen voorgestelde configuraties voor verschillende scenario's. Wanneer u gegevens kopieert naar een bestandsgegevensarchief, is het raadzaam om naar een map te schrijven als meerdere bestanden (alleen mapnaam opgeven), in welk geval de prestaties beter zijn dan schrijven naar één bestand.
| Scenario | Voorgestelde instellingen |
|---|---|
| Volledige belasting van grote tabellen, met fysieke partities. | Partitieoptie: fysieke partities van de tabel. Tijdens de uitvoering detecteert de service automatisch de fysieke partities en kopieert de gegevens per partitie. Als u wilt controleren of uw tabel een fysieke partitie heeft of niet, kunt u naar deze query verwijzen. |
| Volledige belasting van grote tabellen, zonder fysieke partities, terwijl met een geheel getal of datum/tijd-kolom voor gegevenspartitionering. | Partitieopties: partitie dynamisch bereik. Partitiekolom (optioneel): Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Als dit niet is opgegeven, wordt de primaire-sleutelkolom gebruikt. Bovengrens en partitieondergrens partitioneren (optioneel): Geef op of u de partitie-onderdrukking wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel, alle rijen in de tabel worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarden en kan het lang duren, afhankelijk van MIN- en MAX-waarden. Het wordt aanbevolen om bovengrens en ondergrens op te geven. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100 en u de ondergrens instelt op 20 en de bovengrens als 80, met parallelle kopie als 4, haalt de service gegevens op met 4 partities - id's in bereik <=20, [21, 50], [51, 80] en >=81. |
| Laad een grote hoeveelheid gegevens met behulp van een aangepaste query, zonder fysieke partities, terwijl u een geheel getal of een datum/datum/tijd-kolom gebruikt voor gegevenspartitionering. | Partitieopties: partitie dynamisch bereik. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitiekolom: Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Bovengrens en partitieondergrens partitioneren (optioneel): Geef op of u de partitie-onderdrukking wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel, alle rijen in het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100 en u de ondergrens instelt op 20 en de bovengrens als 80, waarbij de parallelle kopie als 4 is, haalt de service gegevens op met 4 partities- id's in het bereik <=20, [21, 50], [51, 80] en >=81. Hier volgen meer voorbeeldquery's voor verschillende scenario's: 1. Voer een query uit op de hele tabel: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Query's uitvoeren uit een tabel met kolomselectie en aanvullende where-componentfilters: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Query uitvoeren met subquery's: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Query uitvoeren met partitie in subquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Aanbevolen procedures voor het laden van gegevens met partitieoptie:
- Kies een onderscheidende kolom als partitiekolom (zoals primaire sleutel of unieke sleutel) om scheeftrekken van gegevens te voorkomen.
- Als de tabel een ingebouwde partitie heeft, gebruikt u de partitieoptie Fysieke partities van de tabel om betere prestaties te krijgen.
- Als u Azure Integration Runtime gebruikt om gegevens te kopiëren, kunt u grotere 'Data-Integratie eenheden (DIU)' (>4) instellen om meer rekenresources te gebruiken. Controleer de toepasselijke scenario's daar.
- "Mate van kopieerparallellisme" bepaalt de partitienummers, stelt dit getal een beetje te groot voor de prestaties, raadt u aan dit getal in te stellen als (DIU of het aantal zelf-hostende IR-knooppunten) * (2 tot 4).
Voorbeeld: volledige belasting van grote tabellen met fysieke partities
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Voorbeeld: query met partitie dynamisch bereik
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Voorbeeldquery om fysieke partitie te controleren
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Als de tabel een fysieke partitie heeft, ziet u HasPartition als ja, zoals hieronder.

Eigenschappen van opzoekactiviteit
Als u meer wilt weten over de eigenschappen, controleert u de lookup-activiteit.
Eigenschappen van GetMetadata-activiteit
Als u meer wilt weten over de eigenschappen, controleert u de Activiteit GetMetadata
Always Encrypted gebruiken
Wanneer u gegevens kopieert van/naar Amazon RDS voor SQL Server met Always Encrypted, volgt u de onderstaande stappen:
Sla de Kolomhoofdsleutel (CMK) op in een Azure Key Vault. Meer informatie over het configureren van Always Encrypted met behulp van Azure Key Vault
Zorg ervoor dat u toegang verleent tot de sleutelkluis waar de CMK (Column Master Key) is opgeslagen. Raadpleeg dit artikel voor vereiste machtigingen.
Maak een gekoppelde service om verbinding te maken met uw SQL-database en schakel de functie Always Encrypted in met behulp van een beheerde identiteit of service-principal.
Verbindingsproblemen oplossen
Configureer uw Amazon RDS voor SQL Server-exemplaar om externe verbindingen te accepteren. Start Amazon RDS voor SQL Server Management Studio, klik met de rechtermuisknop op de server en selecteer Eigenschappen. Selecteer Verbinding maken ions in de lijst en schakel het selectievakje Externe verbindingen met deze server toestaan in.
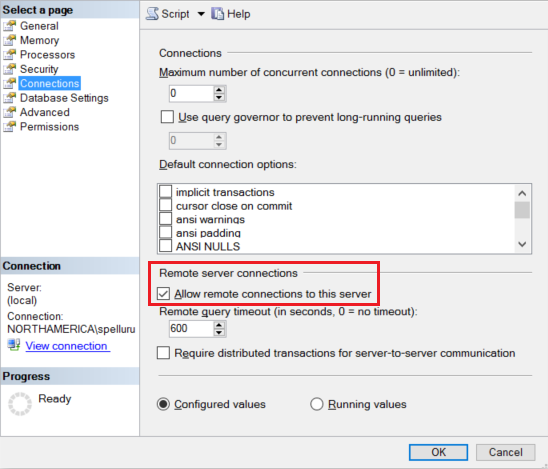
Zie De configuratieoptie voor rastoegangsserver configureren voor gedetailleerde stappen.
Start Amazon RDS voor SQL Server Configuration Manager. Vouw Amazon RDS voor SQL Server-netwerkconfiguratie uit voor het gewenste exemplaar en selecteer Protocollen voor MSSQLSERVER. Protocollen worden weergegeven in het rechterdeelvenster. Schakel TCP/IP in door met de rechtermuisknop op TCP/IP te klikken en Inschakelen te selecteren.
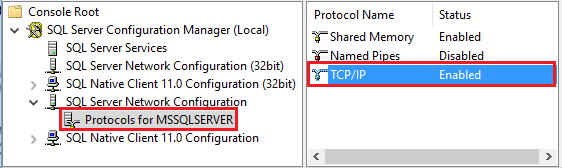
Zie Een servernetwerkprotocol in- of uitschakelen voor meer informatie en alternatieve manieren om TCP/IP-protocol in te schakelen.
Dubbelklik in hetzelfde venster op TCP/IP om het venster TCP/IP-eigenschappen te starten.
Ga naar het tabblad IP-adressen . Schuif omlaag om de sectie IPAll weer te geven. Noteer de TCP-poort. De standaardwaarde is 1433.
Maak een regel voor Windows Firewall op de computer om binnenkomend verkeer via deze poort toe te staan.
Verbinding controleren: Als u verbinding wilt maken met Amazon RDS voor SQL Server met behulp van een volledig gekwalificeerde naam, gebruikt u Amazon RDS voor SQL Server Management Studio vanaf een andere computer. Een voorbeeld is
"<machine>.<domain>.corp.<company>.com,1433".
Gerelateerde inhoud
Zie Ondersteunde gegevensarchieven voor een lijst met gegevensarchieven die worden ondersteund als bronnen en sinks door de kopieeractiviteit.