Tekstbestanden met een vaste lengte verwerken met data factory-toewijzingsgegevensstromen
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Met behulp van toewijzingsgegevensstromen in Microsoft Azure Data Factory kunt u gegevens transformeren vanuit tekstbestanden met een vaste breedte. In de volgende taak definiëren we een gegevensset voor een tekstbestand zonder scheidingsteken en stellen we vervolgens subtekenreekssplitsingen in op basis van rangschikkingspositie.
Een pipeline maken
Selecteer +Nieuwe pijplijn om een nieuwe pijplijn te maken.
Voeg een gegevensstroomactiviteit toe, die wordt gebruikt voor het verwerken van bestanden met een vaste breedte:
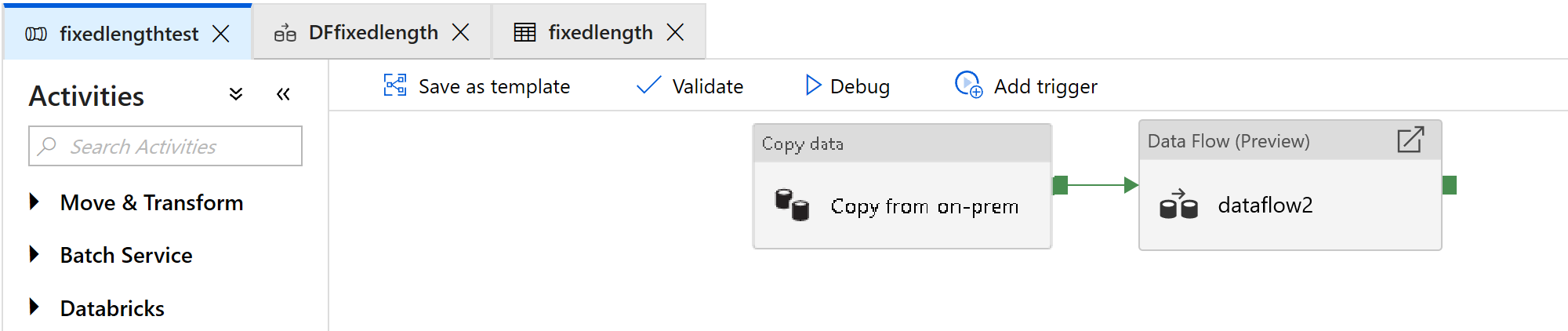
Selecteer nieuwe toewijzingsgegevensstroom in de gegevensstroomactiviteit.
Een bron-, afgeleide kolom-, selectie- en sinktransformatie toevoegen:
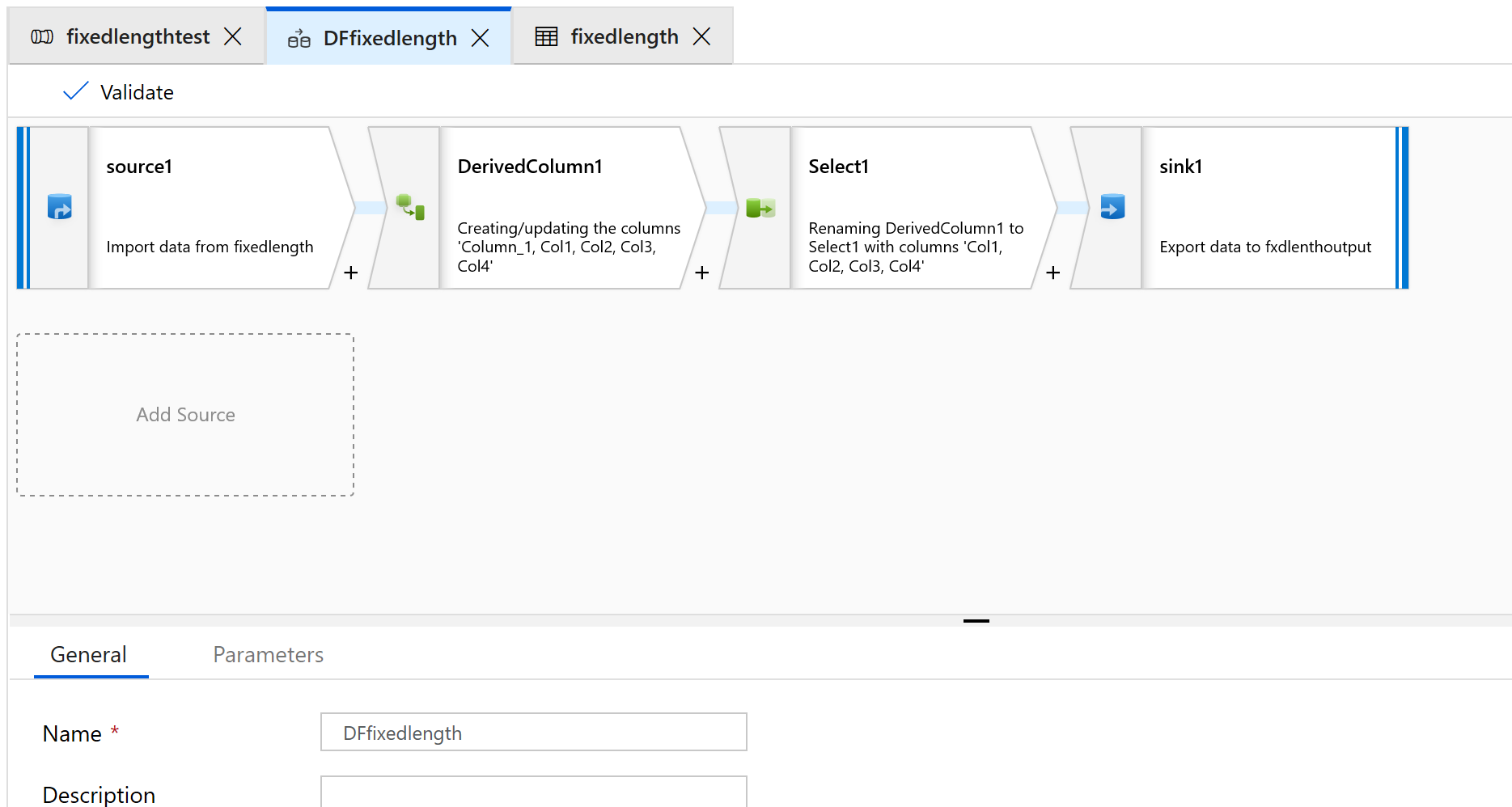
Configureer de brontransformatie voor het gebruik van een nieuwe gegevensset, die van het type tekst met scheidingstekens is.
Stel geen kolomscheidingstekens of kopteksten in.
Nu stellen we veldstartpunten en lengten in voor de inhoud van dit bestand:
1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468Op het tabblad Projectie van de brontransformatie ziet u een tekenreekskolom met de naam Column_1.
Maak in de afgeleide kolom een nieuwe kolom.
We geven de kolommen eenvoudige namen, zoals col1.
Typ het volgende in de opbouwfunctie voor expressies:
substring(Column_1,1,4)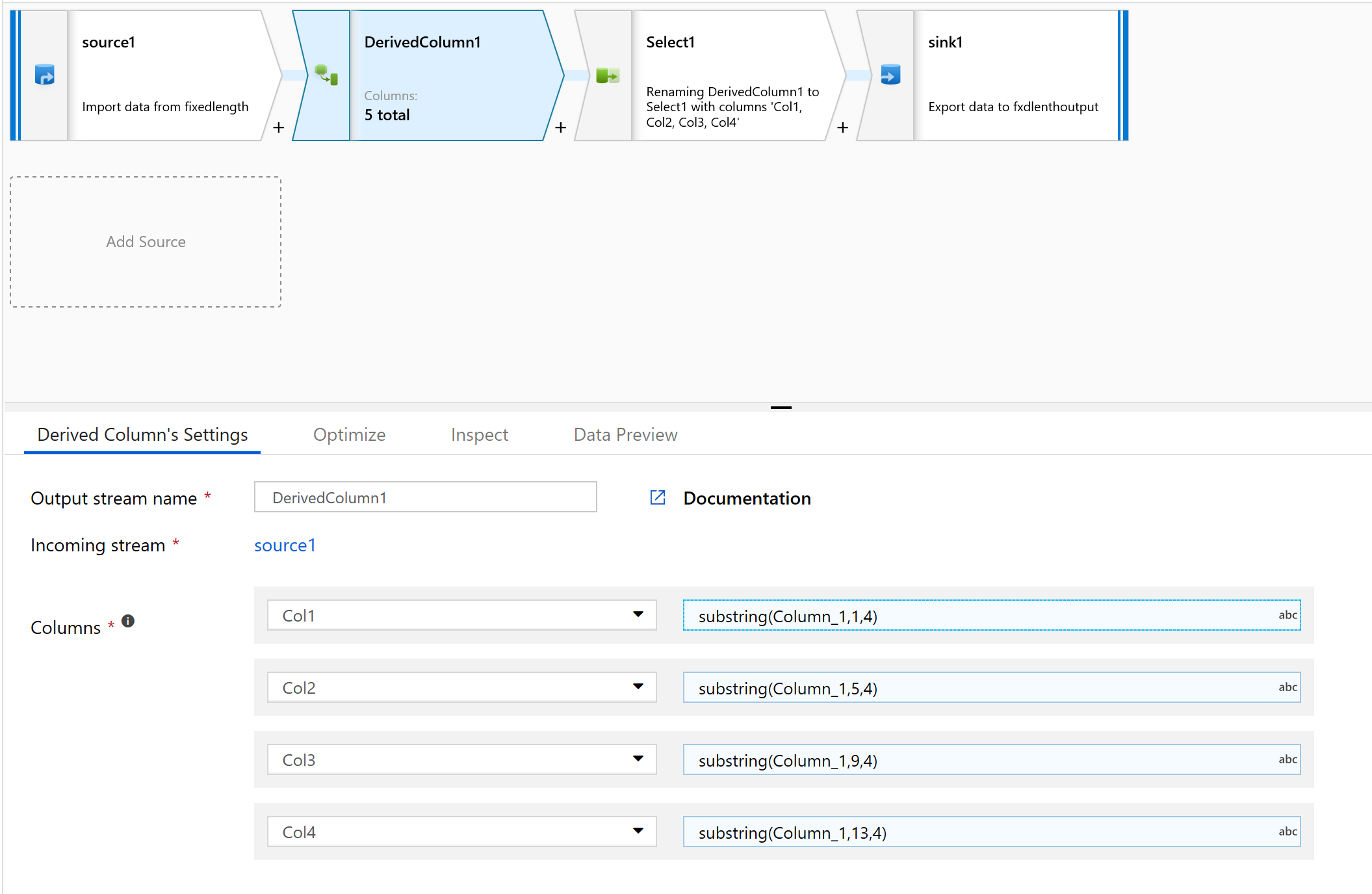
Herhaal stap 10 voor alle kolommen die u moet parseren.
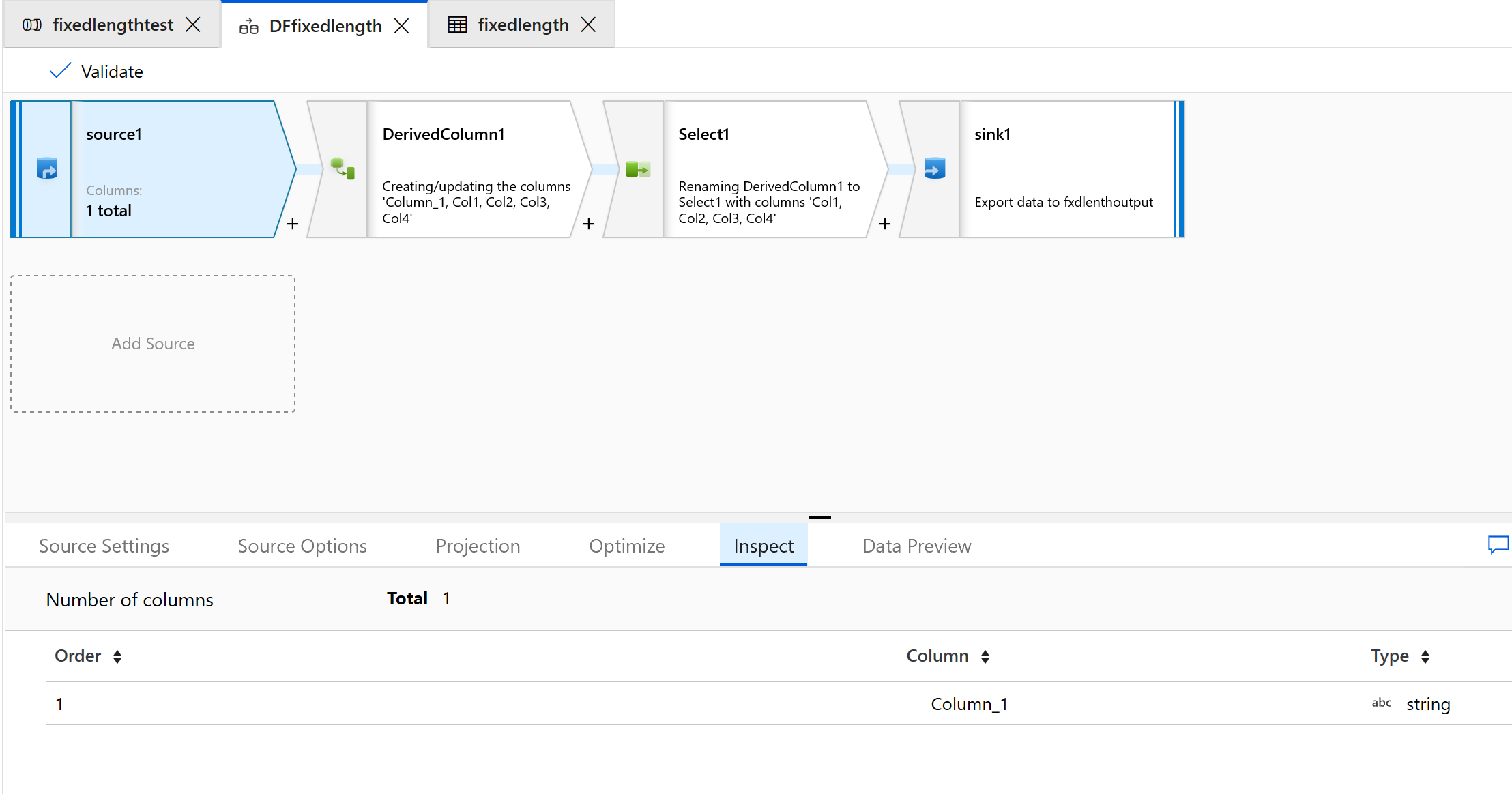
Selecteer het tabblad Inspecteren om de nieuwe kolommen te zien die worden gegenereerd:
Gebruik de transformatie Selecteren om een van de kolommen te verwijderen die u niet nodig hebt voor transformatie:
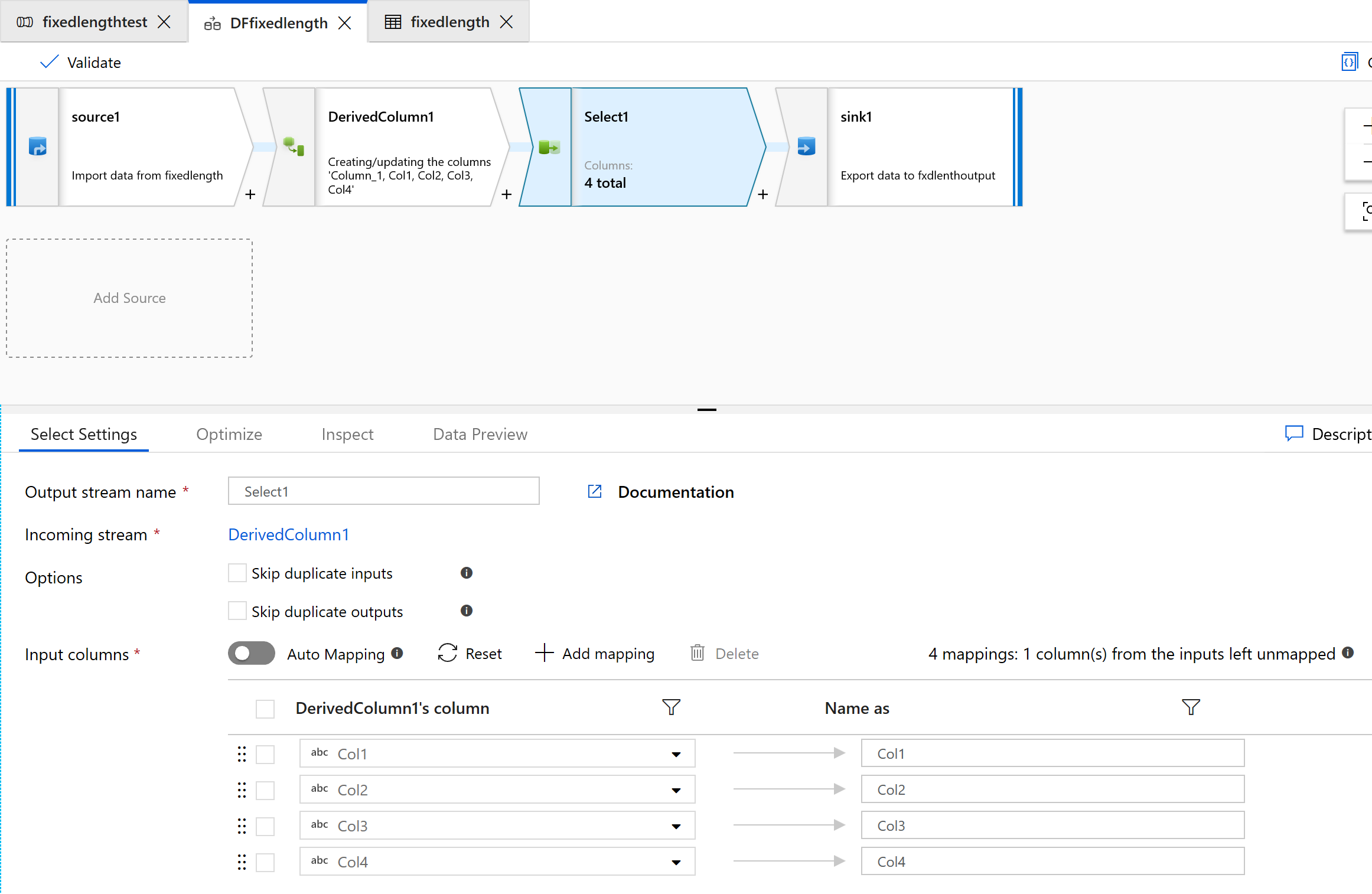
Gebruik Sink om de gegevens uit te voeren naar een map:
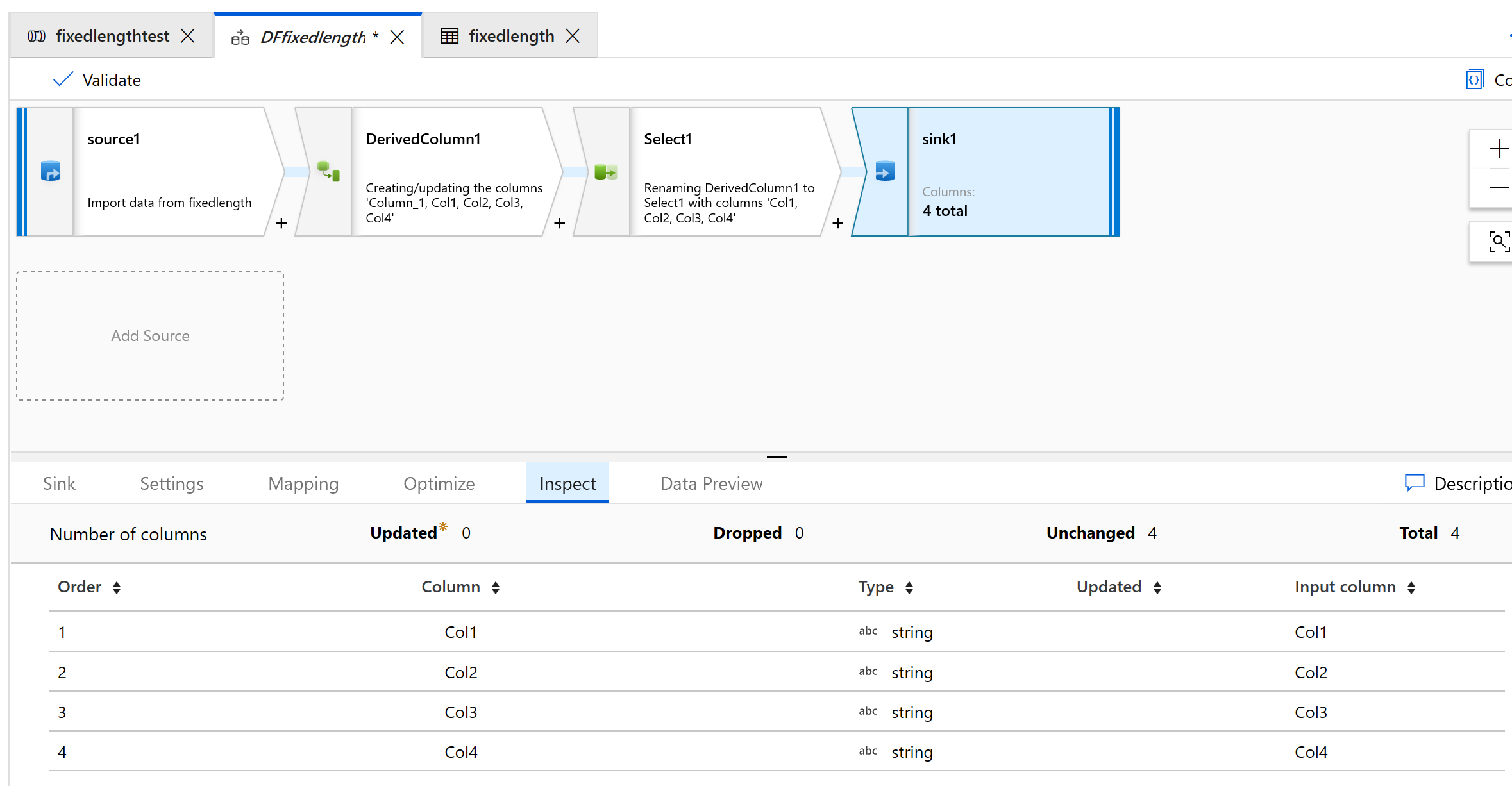
De uitvoer ziet er als volgt uit:
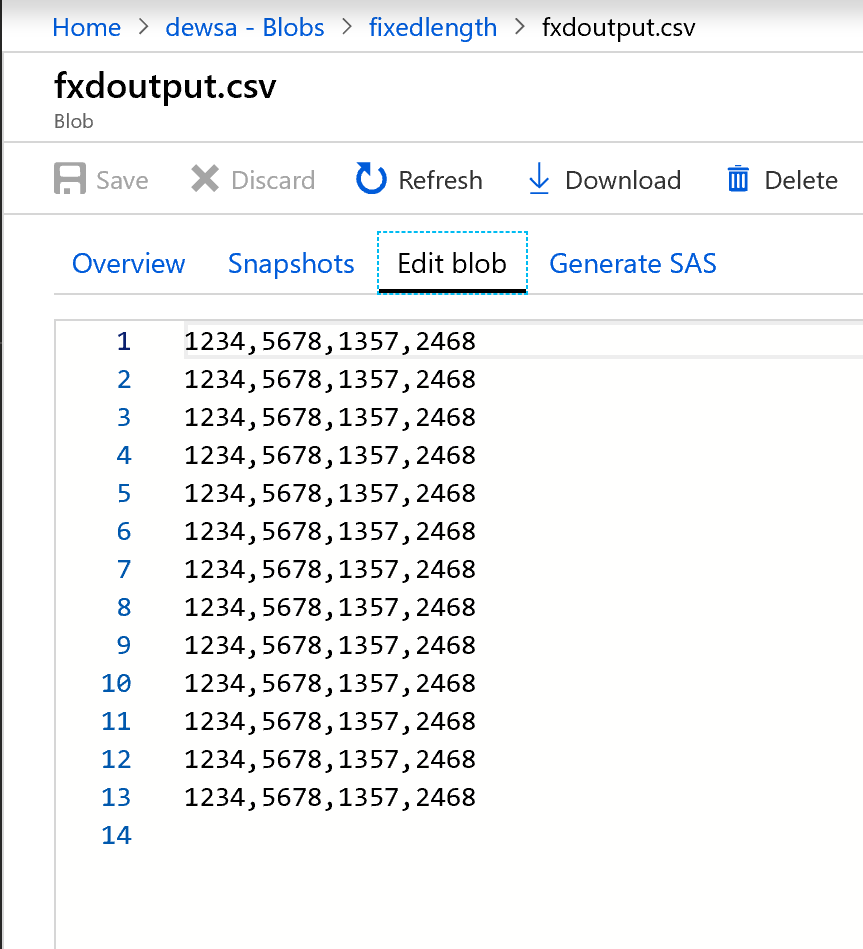
De gegevens met vaste breedte worden nu gesplitst, met elk vier tekens en toegewezen aan Col1, Col2, Col3, Col4, enzovoort. Op basis van het voorgaande voorbeeld worden de gegevens gesplitst in vier kolommen.
Gerelateerde inhoud
- Bouw de rest van uw gegevensstroomlogica met behulp van transformaties van toewijzingsgegevensstromen.