Gegevens kopiëren van een SQL Server-database naar Azure Blob-opslag
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In deze zelfstudie gebruikt u de gebruikersinterface (UI) van Azure Data Factory om een pijplijn voor een data factory te maken waarmee gegevens worden gekopieerd van een SQL Server-database naar Azure Blob-opslag. U gaat een zelf-hostende Integration Runtime maken en gebruiken. Deze verplaatst gegevens van on-premises gegevensarchieven en gegevensarchieven in de cloud en omgekeerd.
Notitie
Dit artikel is geen gedetailleerde introductie tot Data Factory. Zie Inleiding tot Data Factory voor meer informatie.
In deze zelfstudie voert u de volgende stappen uit:
- Een data factory maken.
- Een zelf-hostende Integration Runtime maken.
- Gekoppelde services maken voor SQL Server en Azure Storage.
- Gegevenssets maken voor SQL Server en Azure Blob.
- Een pijplijn maakt met een kopieeractiviteit om de gegevens te verplaatsen.
- Een pijplijnuitvoering starten.
- Controleer de pijplijnuitvoering.
Vereisten
Azure-abonnement
Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint.
Azure-rollen
Als u data factory-exemplaren wilt maken, moet het gebruikersaccount waarmee u zich bij Azure aanmeldt, toegewezen zijn aan de rollen Inzender of Eigenaar, of moet dit een beheerder van het Azure-abonnement zijn.
Ga naar Azure Portal als u de machtigingen wilt weergeven die u hebt in het abonnement. Selecteer uw gebruikersnaam in de rechterbovenhoek en selecteer vervolgens Machtigingen. Als u toegang tot meerdere abonnementen hebt, moet u het juiste abonnement selecteren. Zie Azure-rollen toewijzen met behulp van Azure Portal voor voorbeeldinstructies voor het toevoegen van een gebruiker aan een rol.
SQL Server 2014, 2016 en 2017
In deze zelfstudie gebruikt u een SQL Server-database als een brongegevensopslag. De pijplijn in de data factory die u in deze zelfstudie gaat maken, kopieert gegevens van deze SQL Server-database (bron) naar Blob-opslag (sink). Maak een tabel met de naam emp in uw SQL Server-database en voeg een aantal voorbeeldgegevens toe aan de tabel.
Start SQL Server Management Studio. Als dit niet al is geïnstalleerd op uw computer, gaat u naar SQL Server Management Studio downloaden.
Maak verbinding met SQL Server-exemplaar met behulp van uw referenties.
Maak een voorbeelddatabase. Klik in de structuurweergave met de rechtermuisknop op Databases en selecteer Nieuwe database.
Voer in het venster Nieuwe database een naam in voor de database en selecteer OK.
Voer het volgende queryscript uit voor de database. Hiermee wordt de emp-tabel gemaakt en worden enkele voorbeeldgegevens ingevoegd in deze tabel. In de structuurweergave klikt u met de rechtermuisknop op de database die u hebt gemaakt en selecteert u Nieuwe query.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Azure-storageaccount
In deze zelfstudie gaat u een algemeen Azure Storage-account (en dan met name Blob Storage) gebruiken als een doel/sink-gegevensopslag. Zie het artikel Een opslagaccount maken als u geen Azure Storage-account hebt voor algemene doeleinden. De pijplijn in de data factory die u in deze zelfstudie gaat maken, kopieert gegevens van deze SQL Server-database (bron) naar Blob Storage (sink).
De naam en sleutel van een opslagaccount ophalen
In deze zelfstudie gaat u de naam en sleutel van uw opslagaccount gebruiken. Voer de volgende stappen uit om de naam en sleutel van uw opslagaccount op te halen:
Meld u aan bij Azure Portal met uw Azure-gebruikersnaam en -wachtwoord.
Selecteer Alle services in het linkerdeelvenster. Filter met behulp van het sleutelwoord Opslag en selecteer vervolgens Opslagaccounts.
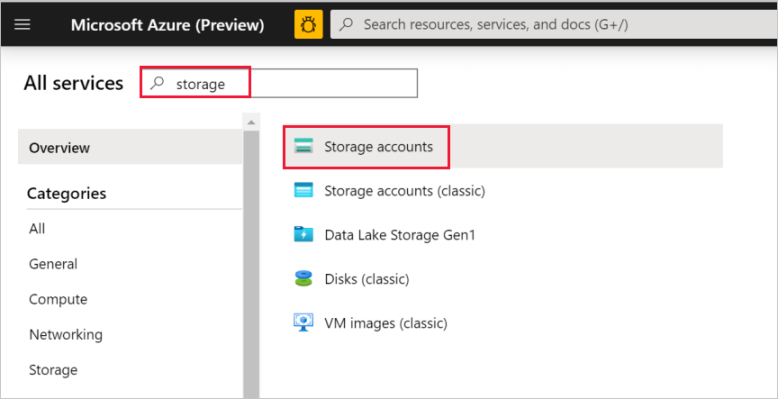
Filter indien nodig in de lijst met opslagaccounts op uw opslagaccount. Selecteer vervolgens uw opslagaccount.
Selecteer in het venster Opslagaccount de optie Toegangssleutels.
Kopieer de waarden in de vakken opslagaccountnaam en key1 en plak deze in Kladblok of een andere editor voor later gebruik in de zelfstudie.
De container adftutorial maken
In deze sectie maakt u in uw Blob Storage een blobcontainer met de naam adftutorial.
Ga in het venster Opslagaccount naar Overzicht en selecteer vervolgens Containers.
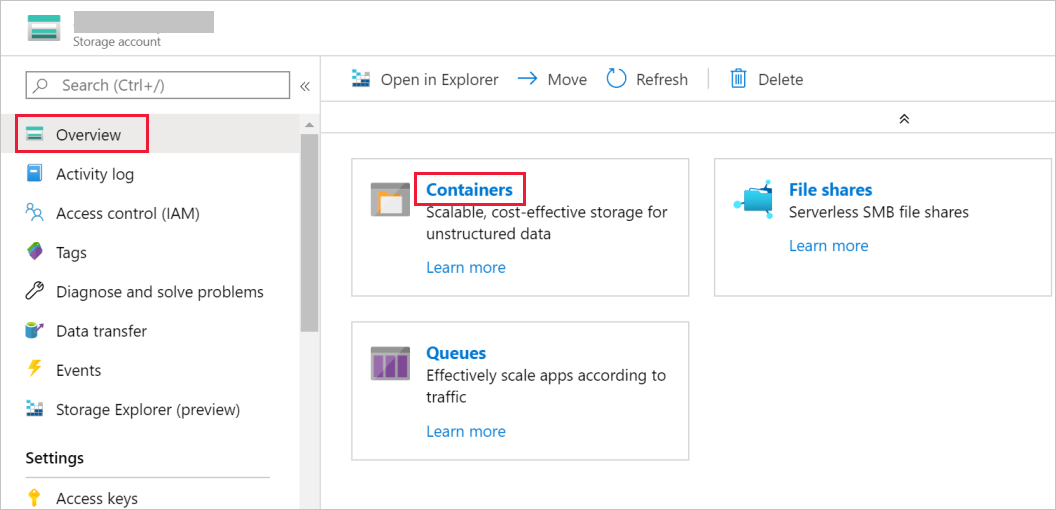
Ga naar het venster Containers en selecteer + Container om een nieuwe container te maken.
In het venster Nieuwe container voert u bij Naamadftutorial in. Selecteer vervolgens Maken.
Selecteer de zojuist gemaakte container adftutorial in de lijst met containers.
Houd het venster Container voor adftutorial geopend. U gaat hiermee aan het einde van deze zelfstudie de uitvoer controleren. In Data Factory wordt automatisch in deze container de uitvoermap gemaakt, zodat u er zelf geen hoeft te maken.
Een data factory maken
In deze stap maakt u een data factory en start u de Data Factory-gebruikersinterface om een pijplijn te maken in de data factory.
Open de webbrowser Microsoft Edge of Google Chrome. Op dit moment wordt de Data Factory-gebruikersinterface alleen ondersteund in de webbrowsers Microsoft Edge en Google Chrome.
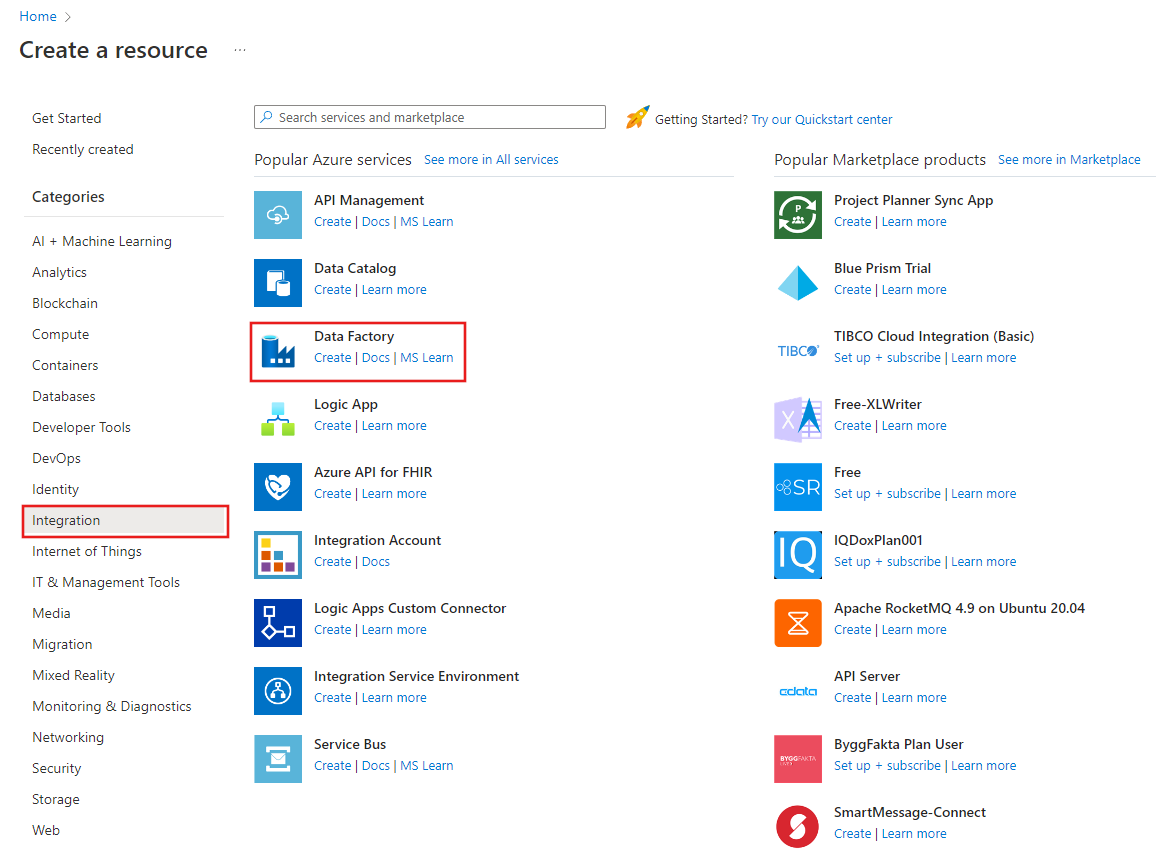
Selecteer in het linkermenu Een resource maken>Integratie>Data Factory:
Voer op de pagina Nieuwe data factoryADFTutorialDataFactory in bij Naam.
De naam van de data factory moet wereldwijd uniek zijn. Als het volgende foutbericht wordt weergegeven voor het naamveld, wijzigt u de naam van de data factory (bijvoorbeeld uwnaamADFTutorialDataFactory). Zie Data Factory naming rules (Naamgevingsregels Data Factory) voor meer informatie over naamgevingsregels voor Data Factory-artefacten.
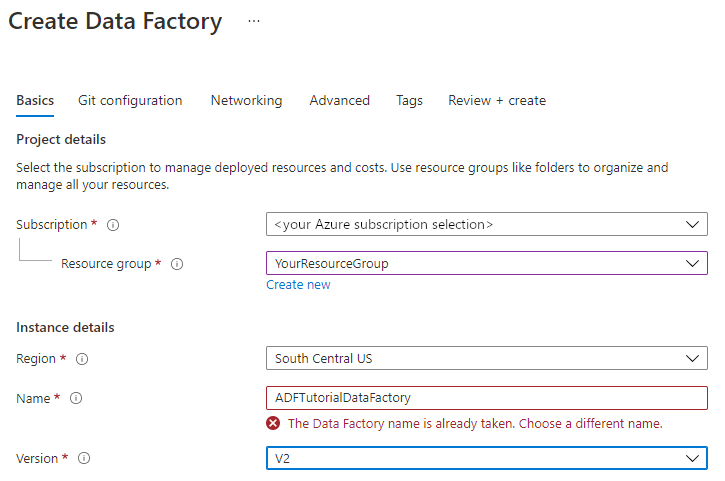
Selecteer het Azure-abonnement waarin u de data factory wilt maken.
Voer een van de volgende stappen uit voor Resourcegroep:
Selecteer Bestaande gebruiken en selecteer een bestaande resourcegroep in de vervolgkeuzelijst.
Selecteer Nieuwe maken en voer de naam van een resourcegroep in.
Zie Resourcegroepen gebruiken om Azure-resources te beheren voor meer informatie.
Selecteer V2 onder Versie.
Selecteer bij Locatie de locatie voor de data factory. In de vervolgkeuzelijst worden alleen ondersteunde locaties weergegeven. De gegevensarchieven (bijvoorbeeld Storage en SQL Database) en -berekeningen (bijvoorbeeld Azure HDInsight) die door Data Factory worden gebruikt, kunnen zich in andere regio's bevinden.
Selecteer Maken.
Na het aanmaken ziet u de pagina Data Factory zoals weergegeven in de afbeelding:
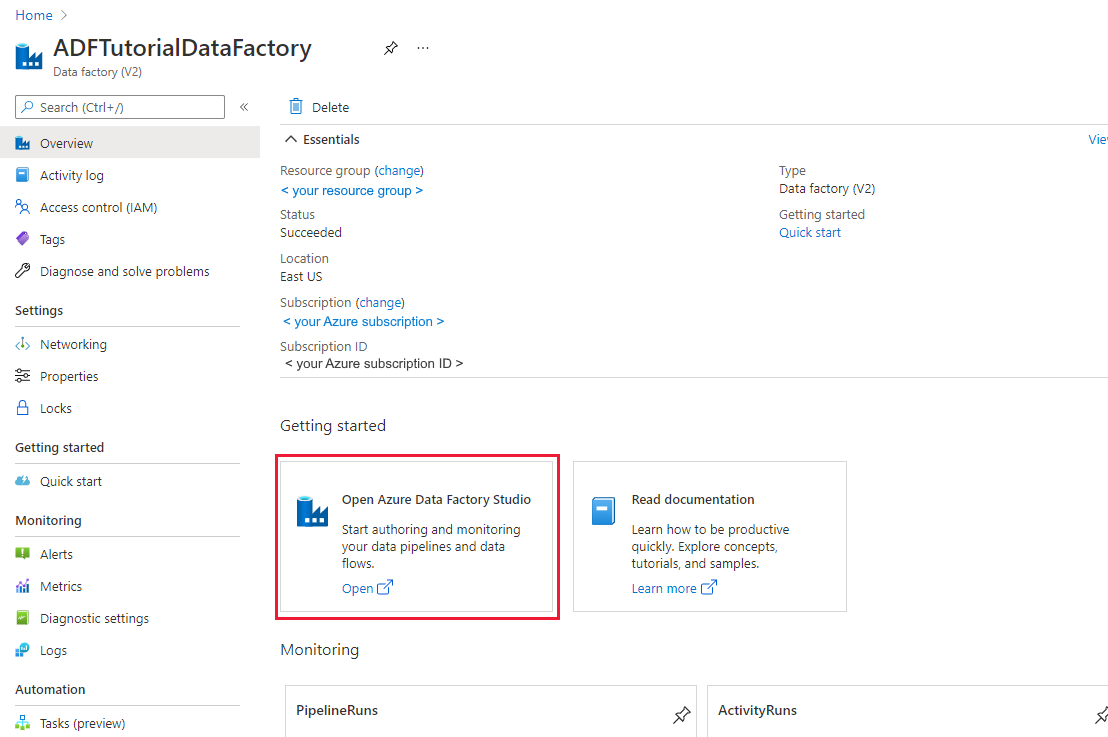
Selecteer Openen op de tegel Azure Data Factory Studio openen om de Data Factory-gebruikersinterface op een afzonderlijk tabblad te starten.
Een pipeline maken
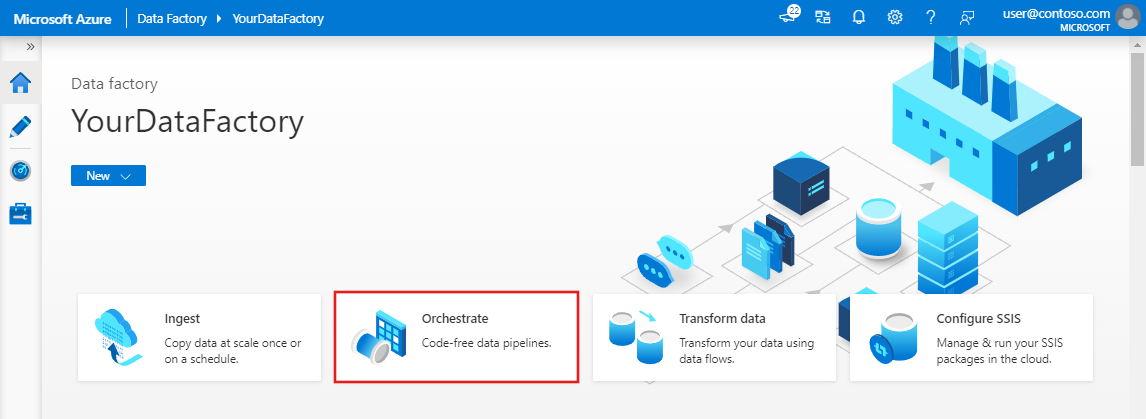
Selecteer Orchestrate op de startpagina van Azure Data Factory. Er wordt automatisch een pijplijn voor u gemaakt. U ziet de pijplijn in de structuurweergave en de bijbehorende editor wordt geopend.
Geef op het tabblad Algemeen bij EigenschappenSQLServerToBlobPipeline op als Naam. Vouw het paneel vervolgens samen door in de rechterbovenhoek op het pictogram Eigenschappen te klikken.
Open de werkset Activiteiten en vouw Verplaatsen en transformeren uit. Gebruik slepen en neerzetten om de activiteit Kopiëren naar het ontwerpoppervlak van de pijplijn te verplaatsen. Stel de naam van de activiteit in op CopySqlServerToAzureBlobActivity.
Ga in het venster Eigenschappen naar het tabblad Bron en selecteer + Nieuw.
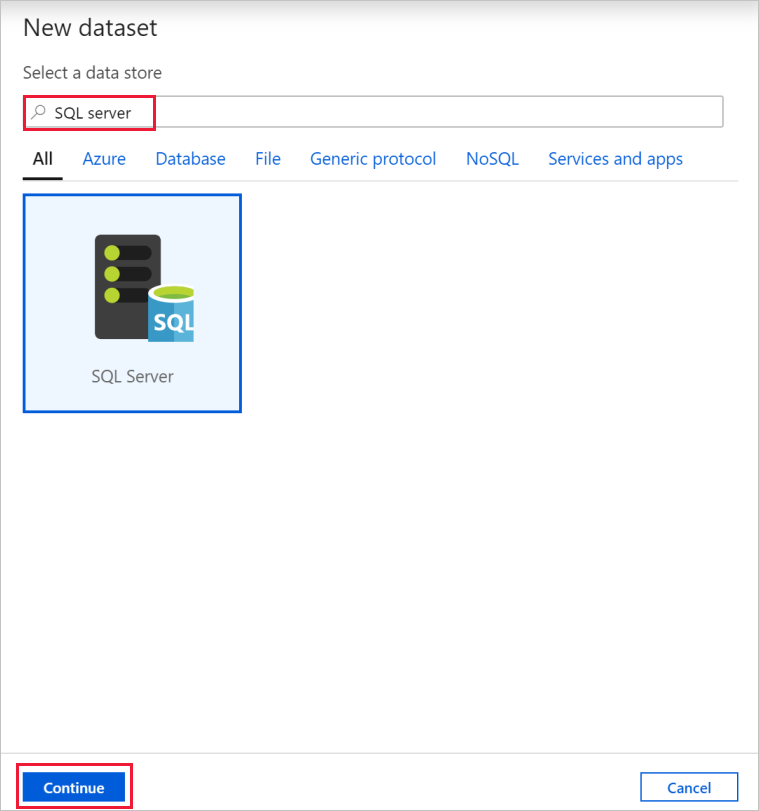
Zoek in het dialoogvenster Nieuwe gegevensset naar SQL Server. Selecteer SQL Server en vervolgens Doorgaan.
Voer in het dialoogvenster Eigenschappen instellen onder NaamSqlServerDatasetin. Selecteer + Nieuw bij Gekoppelde service. In deze stap maakt u een verbinding met het brongegevensexemplaar (SQL Server-database).
Voeg in het dialoogvenster Nieuwe gekoppelde serviceNaam toe als SqlServerLinkedService. Selecteer +Nieuw onder Verbinding maken via integratieruntime. In deze sectie kunt u een zelf-hostende Integration Runtime maken en deze koppelen aan een on-premises computer met de SQL Server database. De zelf-hostende Integration Runtime is het onderdeel waarmee gegevens worden gekopieerd van SQL Server-database op uw computer naar Blob Storage.
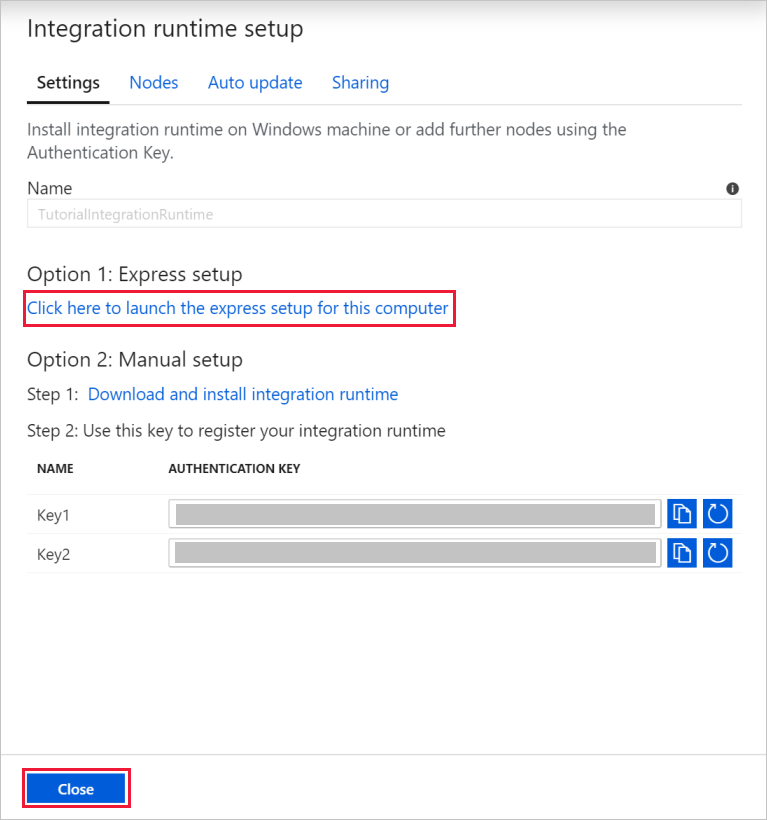
Selecteer in het dialoogvenster Integration Runtime instellen de optie Zelf-hostend. Selecteer vervolgens Doorgaan.
Voer bij de naam TutorialIntegrationRuntimein. Selecteer vervolgens Maken.
Selecteer bij Instellingen Klik hier om de snelle installatie voor deze computer te starten. Met deze actie wordt de integratieruntime op de computer geïnstalleerd en geregistreerd bij Data Factory. U kunt er ook voor kiezen om handmatig te configureren door het installatiebestand te downloaden, uit te voeren, en de sleutel te gebruiken om de integratieruntime te registreren.
Selecteer Sluiten in het venster Snelle installatie van Integration Runtime (zelf-hostend) wanneer het proces is voltooid.
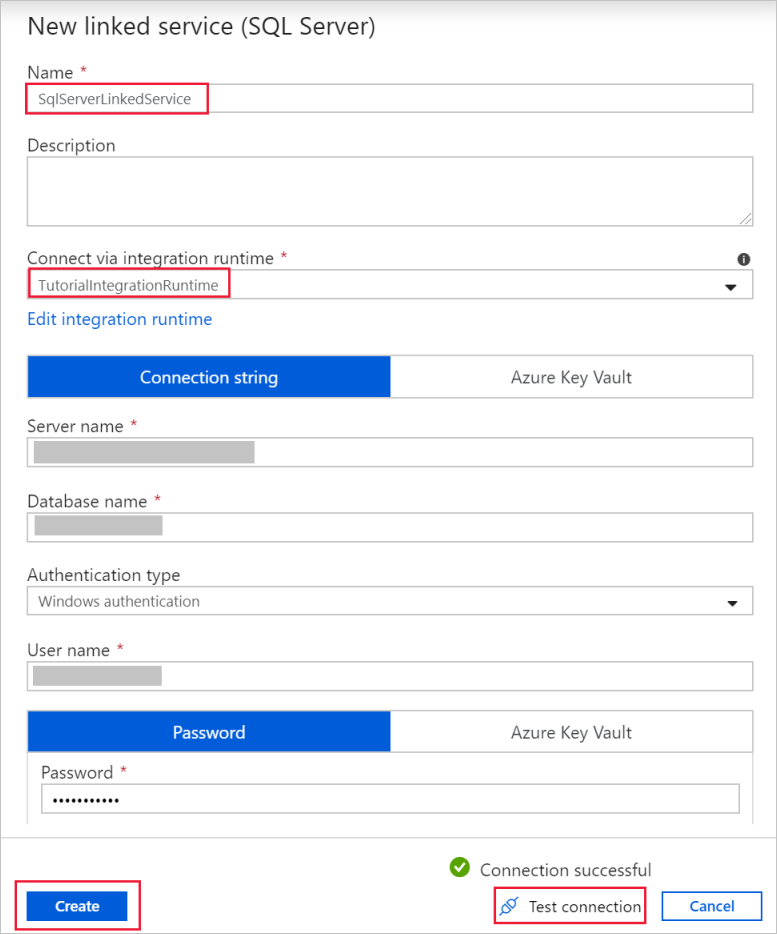
Controleer in het dialoogvenster Nieuwe gekoppelde service (SQL Server)of TutorialIntegrationRuntime is geselecteerd voor het veld Verbinden via integratieruntime. Voer dan de volgende stappen uit:
a. Voer SqlServerLinkedService in bij Naam.
b. Voer de naam van uw SQL Server-exemplaar in bij Servernaam.
c. Geef de naam van de database met de emp-tabel op bij Databasenaam.
d. Selecteer bij Verificatietype het juiste verificatietype in dat in Data Factory moet worden gebruikt om verbinding te maken met uw SQL Server-database.
e. Bij Gebruikersnaam en Wachtwoord, typt u de gebruikersnaam en het wachtwoord. Gebruik indien nodig mydomain\myuser als gebruikersnaam.
f. Selecteer Verbinding testen. Voer deze stap uit om te bevestigen dat Data Factory verbinding mag maken met de SQL Server-database met behulp van de zelf-hostende integratieruntime die u hebt gemaakt.
g. Selecteer Maken om de gekoppelde service op te slaan.
Nadat de gekoppelde service is gemaakt, gaat u terug naar de pagina Eigenschappen voor de SqlServerDataset. Voer de volgende stappen uit:
a. Controleer of in Gekoppelde serviceSqlServerLinkedService wordt weergegeven.
b. Selecteer [dbo].[emp] bij de Tabelnaam.
c. Selecteer OK.
Ga naar het tabblad met de SQLServerToBlobPipeline of selecteer SQLServerToBlobPipeline in de structuurweergave.
Ga naar het tabblad Sink onder in het venster Eigenschappen en selecteer + Nieuw.
Selecteer in het dialoogvenster Nieuwe gegevensset de optie Azure Blob Storage. Selecteer vervolgens Doorgaan.
Selecteer in het dialoogvenster Indeling selecteren het indelingstype van uw gegevens. Selecteer vervolgens Doorgaan.

Voer in het dialoogvenster Eigenschappen instellen bij Naam AzureBlobDataset in. Klik naast het tekstvak Gekoppelde service op +Nieuw.
Voer in het dialoogvenster Nieuwe gekoppelde service als naam AzureStorageLinkedService in en selecteer uw opslagaccount in de lijst Naam van opslagaccount. Test de verbinding en selecteer vervolgens Maken om de gekoppelde service te implementeren.
Nadat de gekoppelde service is gemaakt, gaat u terug naar de pagina Eigenschappen instellen. Selecteer OK.
Open de sinkgegevensset. Voer op het tabblad Verbinding de volgende stappen uit:
a. Controleer of AzureStorageLinkedService is geselecteerd bij Gekoppelde service.
b. Bij Bestandspad voert u adftutorial/fromonprem is voor het gedeelte Container/Map. Als de uitvoermap niet bestaat in de container adftutorial, wordt de uitvoermap automatisch gemaakt door Data Factory.
c. Selecteer Dynamische inhoud toevoegen voor het deel Bestand.
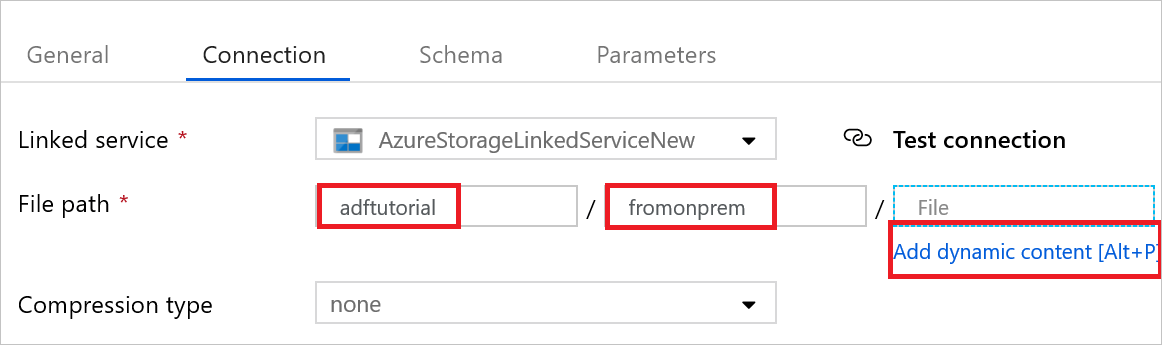
d. Selecteer
@CONCAT(pipeline().RunId, '.txt')en vervolgens Voltooien. Met deze actie wordt de naam van het bestand gewijzigd in PipelineRunID.txt.Ga naar het tabblad met de pijplijn geopend of selecteer de pijplijn in de structuurweergave. Controleer of AzureBlobDataset is geselecteerd bij Sink-gegevensset.
Selecteer in de werkbalk de optie Valideren om de instellingen voor de pijplijn te valideren. U kunt de Uitvoergegevens van de pijplijn sluiten door te klikken op het pictogram >>.
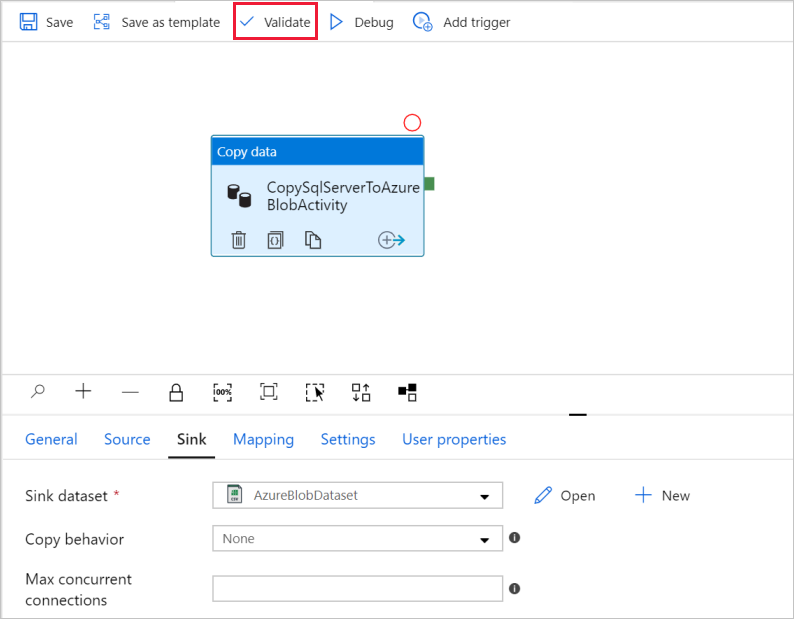
Als u entiteiten die u hebt gemaakt, naar Data Factory wilt publiceren, selecteert u Alles publiceren.
Wacht tot u de pop-up Het publiceren is voltooid ziet. U kunt de status van de publicatie controleren door aan de bovenaan Meldingen weergeven te selecteren. Selecteer Sluiten als u het meldingenvenster wilt sluiten.
Een pijplijnuitvoering activeren
Selecteer Trigger toevoegen op de werkbalk van de pijplijn en selecteer vervolgens Nu activeren.
De pijplijnuitvoering controleren.
Ga naar het tabblad Monitor . U ziet de pijplijn die u handmatig hebt geactiveerd in de vorige stap.
Selecteer de koppeling SQLServerToBlobPipeline onder NAAM PIJPLIJN om de uitvoeringen van activiteiten te zien die zijn gekoppeld aan de pijplijnuitvoering.

Selecteer de koppeling Details (afbeelding van een bril) op de pagina Uitvoeringen van activiteit om details over de kopieerbewerking weer te geven. Selecteer Alle pijplijnuitvoeringen bovenaan om terug te gaan naar de weergave Pijplijnuitvoeringen.
De uitvoer controleren
De uitvoermap fromonprem wordt automatisch door de pijplijn gemaakt in de adftutorial blobcontainer. Controleer of u het bestand [pipeline().RunId].txt in de uitvoermap ziet.
Gerelateerde inhoud
Met de pijplijn in dit voorbeeld worden gegevens gekopieerd van de ene locatie naar een andere locatie in Blob Storage. U hebt geleerd hoe u:
- Een data factory maken.
- Een zelf-hostende Integration Runtime maken.
- Gekoppelde services maakt voor SQL Server en Storage.
- Gegevenssets maakt voor SQL Server en Blob Storage.
- Een pijplijn maakt met een kopieeractiviteit om de gegevens te verplaatsen.
- Een pijplijnuitvoering starten.
- Controleer de pijplijnuitvoering.
Zie Ondersteunde gegevensopslagexemplaren voor een lijst met gegevensopslagexemplaren die worden ondersteund door Data Factory.
Ga door naar de volgende zelfstudie voor informatie over het bulksgewijs kopiëren van gegevens uit een bron naar een bestemming: