Februari 2019
Deze functies en azure Databricks-platformverbeteringen zijn uitgebracht in februari 2019.
Notitie
Releases worden gefaseerd. Uw Azure Databricks-account kan pas een week na de eerste releasedatum worden bijgewerkt.
Databricks Light is algemeen beschikbaar
26 februari - 5 maart 2019: versie 2.92
Databricks Light (ook wel bekend als Data-engineer light) is nu beschikbaar. Databricks Light is de Databricks-verpakking van de open source Apache Spark-runtime. Het biedt een runtime-optie voor taken waarvoor de geavanceerde prestaties, betrouwbaarheid of automatische schaalaanpassing van Databricks Runtime niet nodig zijn. U kunt Databricks Light alleen selecteren wanneer u een cluster maakt om een JAR-, Python- of Spark-submit-taak uit te voeren. U kunt deze runtime niet selecteren voor clusters waarop u interactieve of notebooktaakworkloads uitvoert. Zie Databricks Light.
Beheerde MLflow op Azure Databricks (openbare preview)
26 februari - 5 maart 2019: versie 2.92
MLflow is een open source-platform voor het beheer van de end-to-end levenscyclus van machine learning. Er worden drie primaire functies behandeld:
- Experimenten bijhouden om parameters en resultaten vast te leggen en te vergelijken.
- Het beheren en implementeren van modellen van verschillende ML-bibliotheken tot verschillende model-service- en deductieplatforms.
- ML-code in een herbruikbare, reproduceerbare vorm verpakken om te delen met andere gegevenswetenschappers of overdracht naar productie.
Azure Databricks biedt nu een volledig beheerde en gehoste versie van MLflow die is geïntegreerd met bedrijfsbeveiligingsfuncties, hoge beschikbaarheid en andere azure Databricks-werkruimtefuncties, zoals experimentbeheer, run management en revisie van notebooks. MLflow op Azure Databricks biedt een geïntegreerde ervaring voor het volgen en beveiligen van machine learning-modeltrainingen en het uitvoeren van machine learning-projecten. Door beheerde MLflow te gebruiken in Azure Databricks, krijgt u de voordelen van beide platforms, waaronder:
- Werkruimten: Experimenten en resultaten gezamenlijk bijhouden en organiseren in Azure Databricks-werkruimten met een gehoste MLflow Tracking Server en geïntegreerde experimentgebruikersinterface. Wanneer u MLflow gebruikt in notebooks, legt Azure Databricks automatisch notebookrevisies vast, zodat u dezelfde code kunt reproduceren en later kunt uitvoeren.
- Beveiliging: Profiteer van één algemeen beveiligingsmodel voor de volledige ML-levenscyclus via ACL's.
- Taken: MLflow-projecten uitvoeren als Azure Databricks-taken op afstand en rechtstreeks vanuit Azure Databricks-notebooks.
Hier volgt een demo van een traceringswerkstroom in een Azure Databricks-werkruimte:
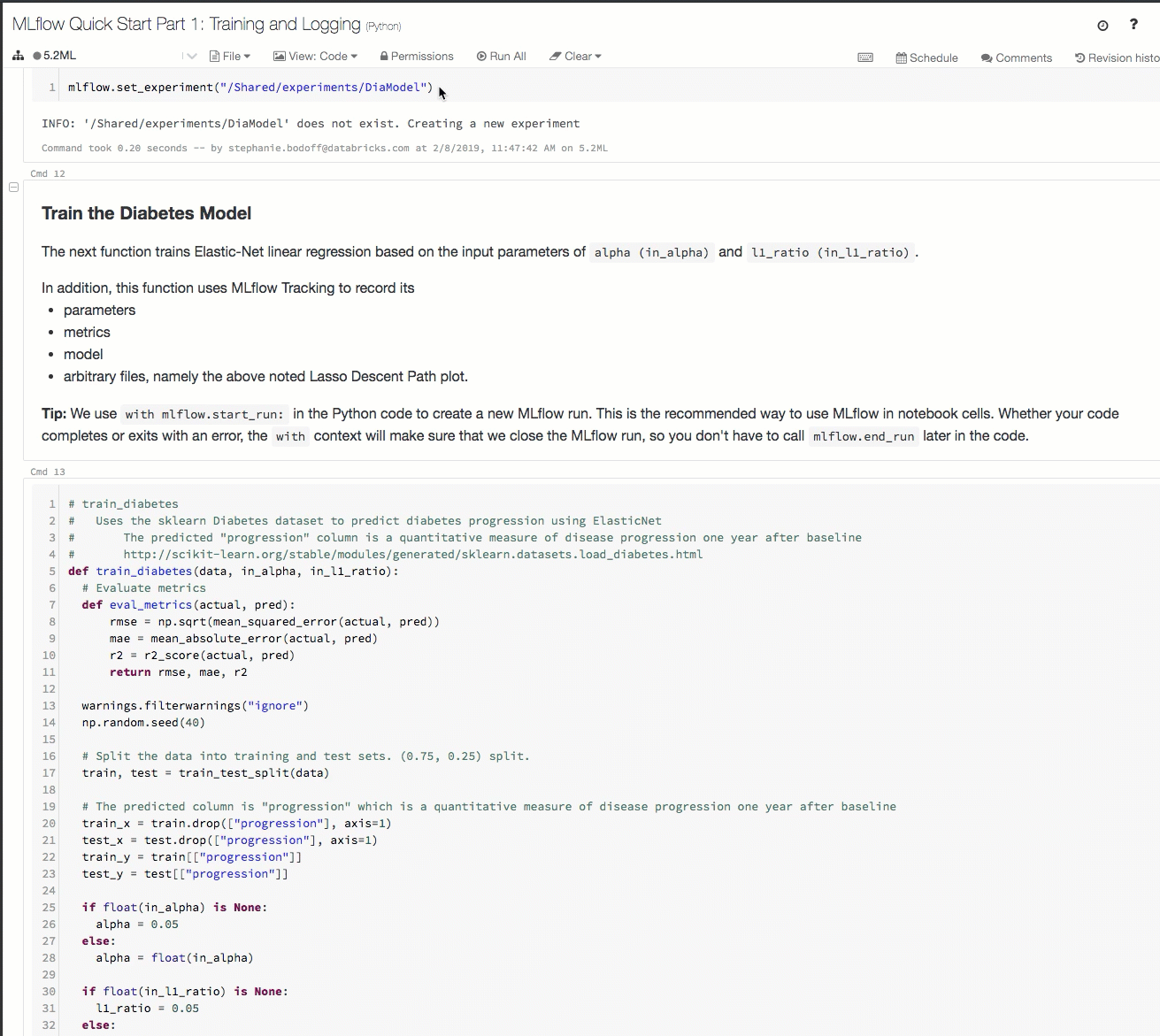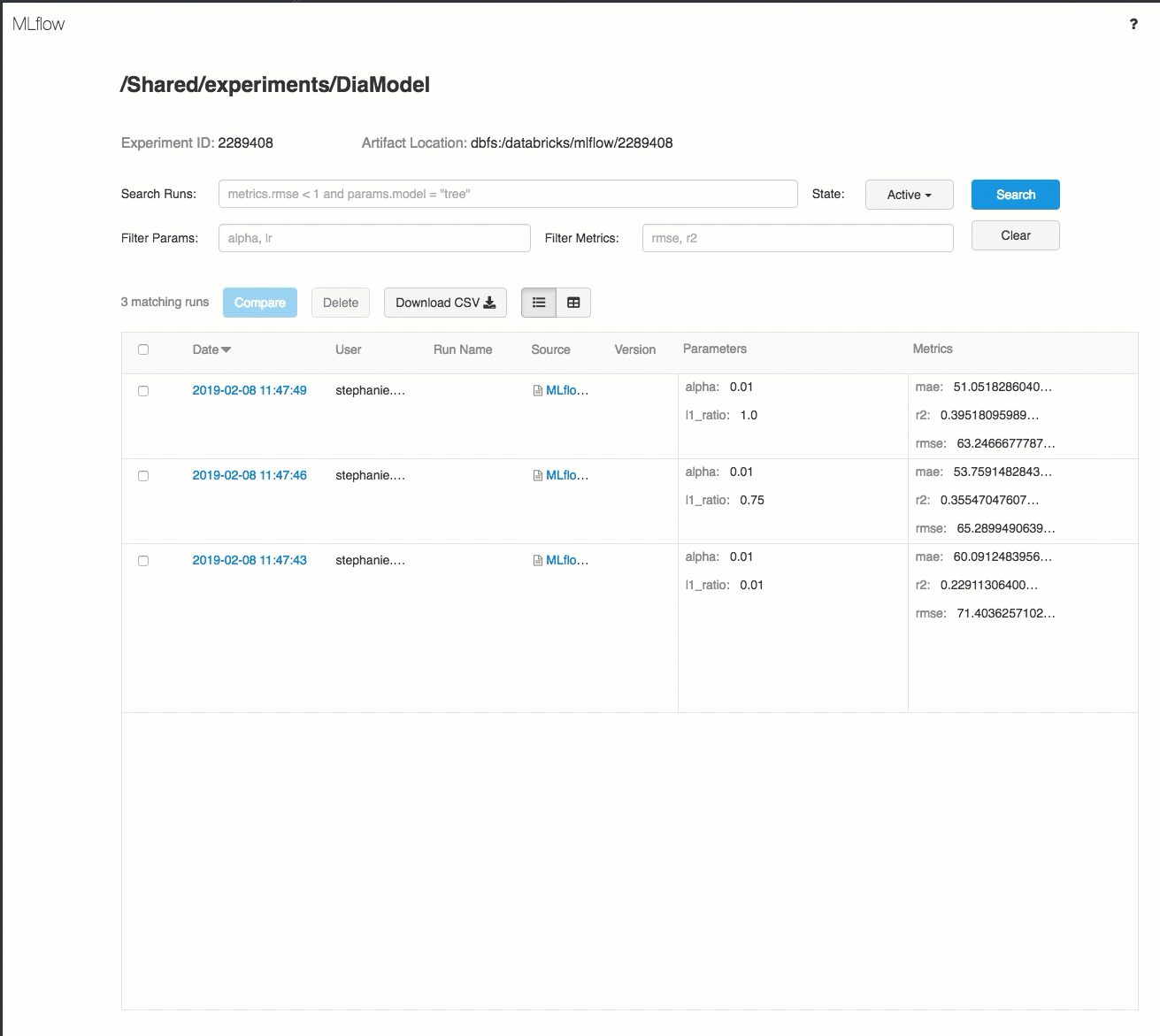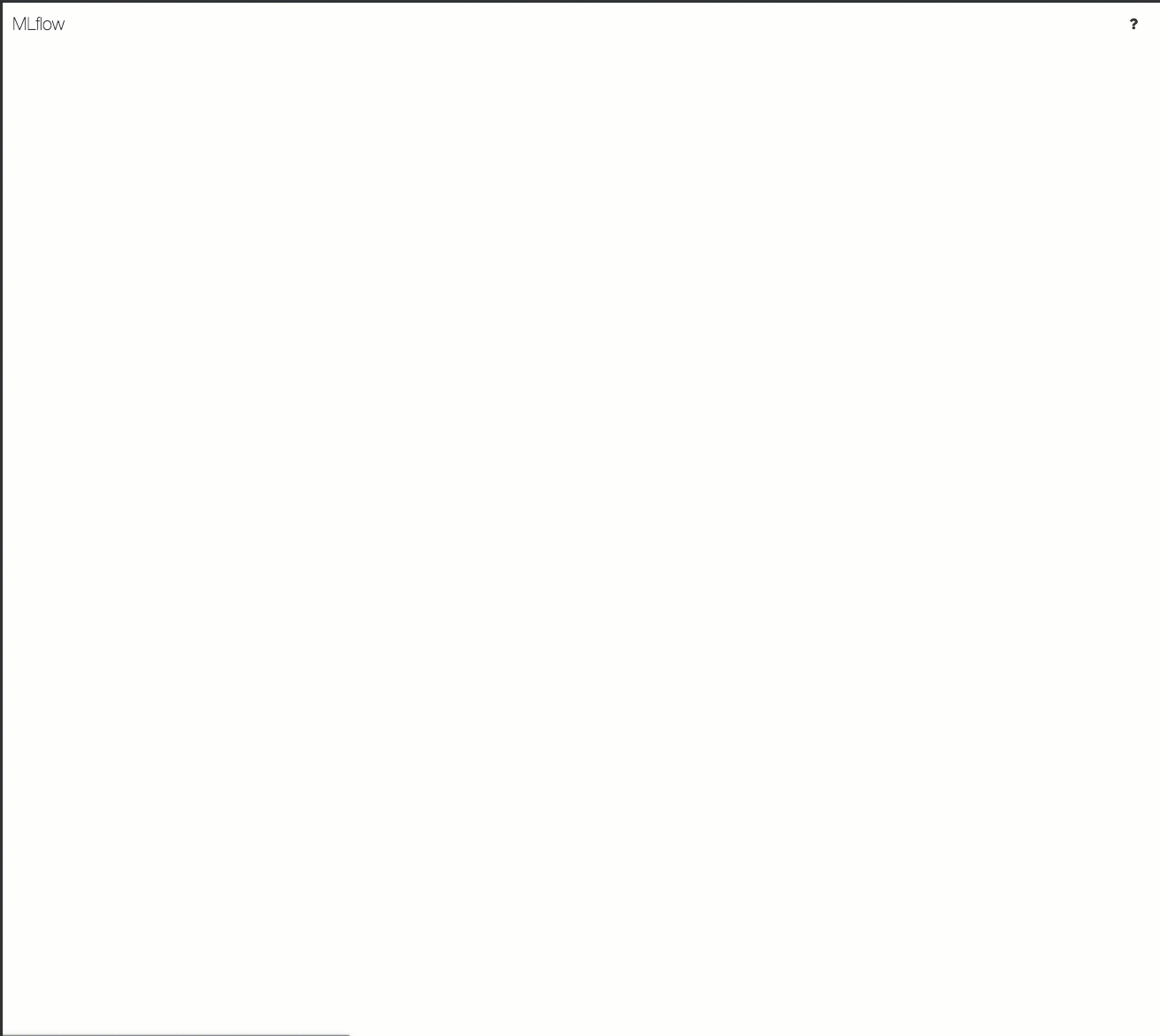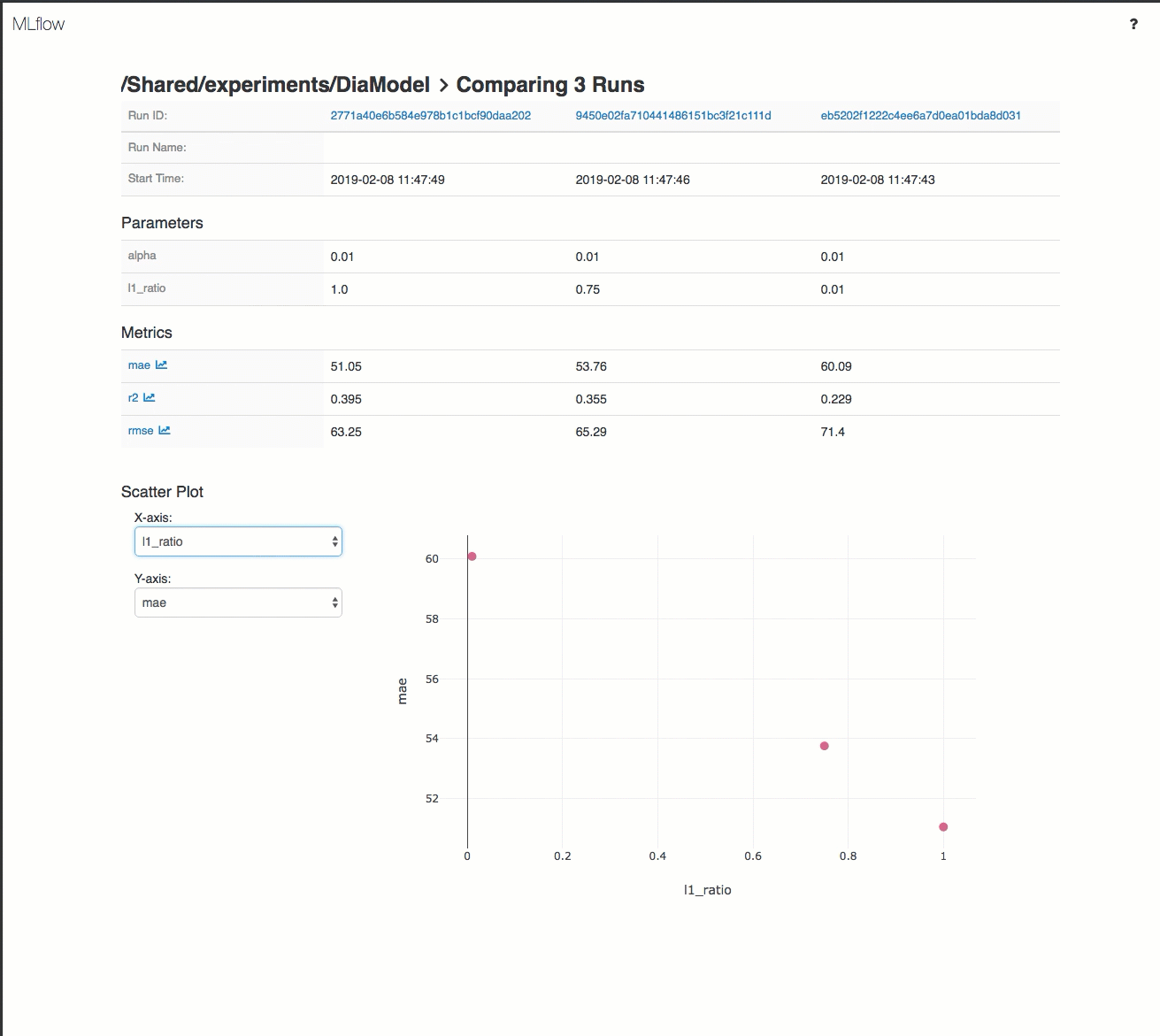
Zie Trainingsuitvoeringen voor ml en deep learning bijhouden en MLflow-projecten uitvoeren in Azure Databricks voor meer informatie.
Azure Data Lake Storage Gen2-connector is algemeen beschikbaar
15 februari 2019
Azure Data Lake Storage Gen2 (ADLS Gen2 ), de data lake-oplossing van de volgende generatie voor big data-analyses, is nu algemeen beschikbaar, net als de ADLS Gen2-connector voor Azure Databricks. We zijn ook verheugd om aan te kondigen dat ADLS Gen2 Databricks Delta ondersteunt wanneer u clusters uitvoert op Databricks Runtime 5.2 en hoger.
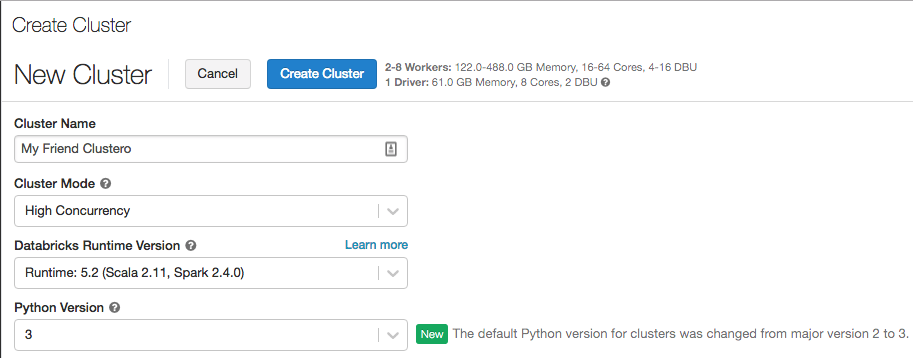
Python 3 is nu de standaard wanneer u clusters maakt
12 februari 19, 2019: versie 2.91
De standaardversie van Python voor clusters die zijn gemaakt met behulp van de gebruikersinterface, is overgeschakeld van Python 2 naar Python 3. De standaardinstelling voor clusters die zijn gemaakt met behulp van de REST API is nog steeds Python 2.
Bestaande clusters wijzigen hun Python-versies niet. Maar als u de standaardinstelling voor Python 2 hebt gebruikt wanneer u nieuwe clusters maakt, moet u beginnen met het selecteren van uw Python-versie.
Delta Lake algemeen beschikbaar
1 februari 2019
Nu kan iedereen profiteren van de voordelen van de krachtige transactionele opslaglaag van Databricks Delta en super snelle leesbewerkingen: Vanaf 1 februari is Delta Lake algemeen beschikbaar voor alle ondersteunde versies van Databricks Runtime. Zie het Wat is Delta Lake? voor meer informatie over Delta.