Problemen met een trage of niet werkende taak in een HDInsight-cluster oplossen
Als een toepassing die gegevens verwerkt in een HDInsight-cluster langzaam wordt uitgevoerd of mislukt met een foutcode, hebt u verschillende opties voor probleemoplossing. Als het langer duurt voordat uw taken worden uitgevoerd dan verwacht, of als u in het algemeen trage reactietijden ziet, zijn er mogelijk fouten stroomopwaarts van uw cluster, zoals de services waarop het cluster wordt uitgevoerd. De meest voorkomende oorzaak van deze vertragingen is echter onvoldoende schaalaanpassing. Wanneer u een nieuw HDInsight-cluster maakt, selecteert u de juiste grootten voor virtuele machines.
Als u een traag of mislukt cluster wilt diagnosticeren, verzamelt u informatie over alle aspecten van de omgeving, zoals gekoppelde Azure Services, clusterconfiguratie en taakuitvoeringsgegevens. Een nuttige diagnose is om de foutstatus op een ander cluster te reproduceren.
- Stap 1: Gegevens over het probleem verzamelen.
- Stap 2: Valideer de HDInsight-clusteromgeving.
- Stap 3: De status van uw cluster weergeven.
- Stap 4: Controleer de omgevingsstack en -versies.
- Stap 5: Bekijk de clusterlogboekbestanden.
- Stap 6: Configuratie-instellingen controleren.
- Stap 7: Reproduceer de fout op een ander cluster.
Stap 1: Gegevens over het probleem verzamelen
HDInsight biedt veel hulpprogramma's die u kunt gebruiken om problemen met clusters te identificeren en op te lossen. De volgende stappen begeleiden u bij deze hulpprogramma's en bieden suggesties voor het vaststellen van het probleem.
Het probleem identificeren
Bekijk de volgende vragen om het probleem te identificeren:
- Wat had ik verwacht? Wat is er gebeurd?
- Hoe lang duurde het uitvoeren van het proces? Hoe lang zou het moeten lopen?
- Worden mijn taken altijd langzaam uitgevoerd op dit cluster? Zijn ze sneller uitgevoerd op een ander cluster?
- Wanneer is dit probleem voor het eerst opgetreden? Hoe vaak is het sindsdien gebeurd?
- Is er iets gewijzigd in mijn clusterconfiguratie?
Clusterdetails
Belangrijke clusterinformatie omvat:
- Clusternaam.
- Clusterregio: controleer op regio-storingen.
- HDInsight-clustertype en -versie.
- Het type en het aantal HDInsight-exemplaren dat is opgegeven voor de hoofd- en werkknooppunten.
De Azure-portal kan deze informatie verstrekken:
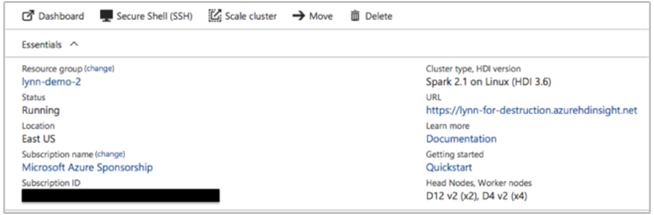
U kunt ook Azure CLI gebruiken:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Een andere optie is het gebruik van PowerShell. Zie Apache Hadoop-clusters beheren in HDInsight met Azure PowerShell voor meer informatie.
Stap 2: de HDInsight-clusteromgeving valideren
Elk HDInsight-cluster is afhankelijk van verschillende Azure-services en van opensource-software zoals Apache HBase en Apache Spark. HDInsight-clusters kunnen ook andere Azure-services aanroepen, zoals Azure Virtual Networks. Een clusterfout kan worden veroorzaakt door een van de actieve services in uw cluster of door een externe service. Een configuratiewijziging van de clusterservice kan er ook toe leiden dat het cluster mislukt.
Servicedetails
- Controleer de releaseversies van de opensource-bibliotheek.
- Controleer op storingen in De Azure-service.
- Controleer op azure-servicegebruikslimieten.
- Controleer de configuratie van het azure Virtual Network-subnet.
Clusterconfiguratie-instellingen weergeven met de Ambari-gebruikersinterface
Apache Ambari biedt beheer en bewaking van een HDInsight-cluster met een webgebruikersinterface en een REST API. Ambari is opgenomen in HDInsight-clusters op basis van Linux. Selecteer het deelvenster Clusterdashboard op de HDInsight-pagina van Azure Portal. Selecteer het deelvenster HDInsight-clusterdashboard om de Ambari-gebruikersinterface te openen en voer de aanmeldingsreferenties voor het cluster in.
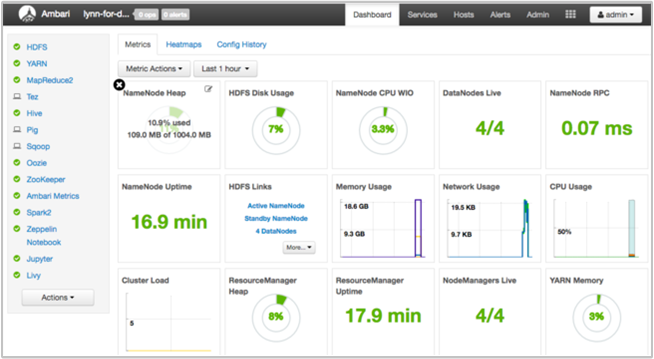
Als u een lijst met serviceweergaven wilt openen, selecteert u Ambari-weergaven op de azure-portalpagina. Deze lijst is afhankelijk van welke bibliotheken zijn geïnstalleerd. U ziet bijvoorbeeld YARN Queue Manager, Hive-weergave en Tez-weergave. Selecteer een servicekoppeling om configuratie- en servicegegevens weer te geven.
Controleren op Azure-servicestoringen
HDInsight is afhankelijk van verschillende Azure-services. Hiermee worden virtuele servers uitgevoerd in Azure HDInsight, worden gegevens en scripts opgeslagen in Azure Blob Storage of Azure Data Lake Storage en worden logboekbestanden geïndexeert in Azure Table Storage. Onderbrekingen van deze services, hoewel zeldzaam, kunnen problemen veroorzaken in HDInsight. Als u onverwachte vertragingen of fouten in uw cluster hebt, controleert u het Azure-statusdashboard. De status van elke service wordt weergegeven per regio. Controleer de regio en regio's van uw cluster voor gerelateerde services.
Limieten voor Azure-servicegebruik controleren
Als u een groot cluster start of meerdere clusters tegelijk hebt gestart, kan een cluster mislukken als u een Azure-servicelimiet hebt overschreden. Servicelimieten variëren, afhankelijk van uw Azure-abonnement. Zie Azure-abonnement en servicelimieten, quota en beperkingen voor meer informatie. U kunt microsoft vragen om het aantal beschikbare HDInsight-resources (zoals VM-kernen en VM-exemplaren) te verhogen met een aanvraag voor het verhogen van het quotum van Resource Manager.
De releaseversie controleren
Vergelijk de clusterversie met de nieuwste HDInsight-release. Elke HDInsight-release bevat verbeteringen, zoals nieuwe toepassingen, functies, patches en oplossingen voor fouten. Het probleem dat van invloed is op uw cluster, is mogelijk opgelost in de nieuwste versie van de release. Voer uw cluster indien mogelijk opnieuw uit met de nieuwste versie van HDInsight en bijbehorende bibliotheken, zoals Apache HBase, Apache Spark en andere.
Uw clusterservices opnieuw starten
Als u vertragingen ondervindt in uw cluster, kunt u overwegen uw services opnieuw te starten via de Ambari-gebruikersinterface of de klassieke Azure CLI. Het cluster ondervindt mogelijk tijdelijke fouten en het opnieuw opstarten is de snelste manier om uw omgeving te stabiliseren en de prestaties mogelijk te verbeteren.
Stap 3: De status van uw cluster weergeven
HDInsight-clusters bestaan uit verschillende typen knooppunten die worden uitgevoerd op exemplaren van virtuele machines. Elk knooppunt kan worden bewaakt op resourcehongering, netwerkverbindingsproblemen en andere problemen die het cluster kunnen vertragen. Elk cluster bevat twee hoofdknooppunten en de meeste clustertypen bevatten een combinatie van werkrol- en edge-knooppunten.
Zie Clusters instellen in HDInsight met Apache Hadoop, Apache Spark, Apache Kafka en meer voor een beschrijving van de verschillende knooppunten die elk clustertype gebruikt.
In de volgende secties wordt beschreven hoe u de status van elk knooppunt en van het algehele cluster controleert.
Een momentopname van de clusterstatus ophalen met behulp van het Ambari UI-dashboard
Het Ambari UI-dashboard (https://<clustername>.azurehdinsight.net) biedt een overzicht van de clusterstatus, zoals uptime, geheugen, netwerk- en CPU-gebruik, HDFS-schijfgebruik, enzovoort. Gebruik de sectie Hosts van Ambari om resources op hostniveau weer te geven. U kunt ook services stoppen en opnieuw opstarten.
Uw WebHCat-service controleren
Een veelvoorkomend scenario voor Apache Hive-, Apache Pig- of Apache Sqoop-taken die mislukken, is een fout met de WebHCat-service (of Templeton). WebHCat is een REST-interface voor het uitvoeren van externe taken, zoals Hive, Pig, Scoop en MapReduce. WebHCat vertaalt de aanvragen voor het indienen van taken in Apache Hadoop YARN-toepassingen en retourneert een status die is afgeleid van de YARN-toepassingsstatus. In de volgende secties worden algemene HTTP-statuscodes van WebHCat beschreven.
BadGateway (statuscode 502)
Deze code is een algemeen bericht van gatewayknooppunten en is de meest voorkomende foutcodes. Een mogelijke oorzaak hiervoor is dat de WebHCat-service niet beschikbaar is op het actieve hoofdknooppunt. Gebruik de volgende CURL-opdracht om te controleren op deze mogelijkheid:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari geeft een waarschuwing weer met de hosts waarop de WebHCat-service niet beschikbaar is. U kunt proberen een back-up van de WebHCat-service te maken door de service opnieuw op de host te starten.
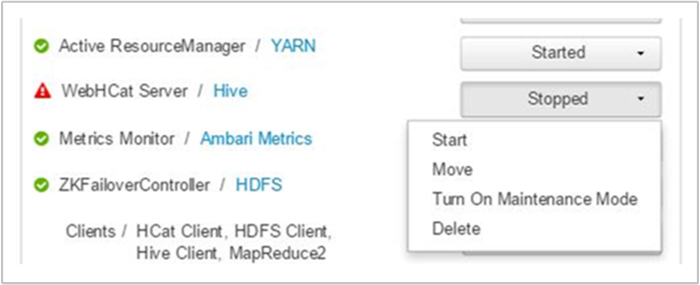
Als er nog steeds geen WebHCat-server wordt weergegeven, controleert u het bewerkingslogboek op foutberichten. Raadpleeg de stderr bestanden waarnaar stdout wordt verwezen op het knooppunt voor meer informatie.
Time-out voor WebHCat
Er treedt een time-out op voor een HDInsight-gateway die langer dan twee minuten duurt en retourneert 502 BadGateway. WebHCat voert een query uit op YARN-services voor taakstatussen en als YARN langer dan twee minuten reageert, kan er een time-out optreedt voor die aanvraag.
Bekijk in dit geval de volgende logboeken in de /var/log/webhcat map:
- webhcat.log is het log4j-logboek waarnaar de server logboeken schrijft
- webhcat-console.log is de stdout van de server wanneer deze is gestart
- webhcat-console-error.log is de stderr van het serverproces
Notitie
Elke webhcat.log wordt dagelijks overgezet en genereert bestanden met de naam webhcat.log.YYYY-MM-DD. Selecteer het juiste bestand voor het tijdsbereik dat u wilt onderzoeken.
In de volgende secties worden enkele mogelijke oorzaken beschreven voor time-outs van WebHCat.
Time-out op webHCat-niveau
Wanneer WebHCat wordt belast, met meer dan 10 open sockets, duurt het langer om nieuwe socketverbindingen tot stand te brengen, wat kan leiden tot een time-out. Als u de netwerkverbindingen van en naar WebHCat wilt weergeven, gebruikt netstat u dit op het huidige actieve hoofdknooppunt:
netstat | grep 30111
30111 is de poort waarop WebHCat luistert. Het aantal open sockets moet kleiner zijn dan 10.
Als er geen open sockets zijn, produceert de vorige opdracht geen resultaat. Als u wilt controleren of Templeton op poort 30111 staat en luistert, gebruikt u:
netstat -l | grep 30111
Time-out op YARN-niveau
Templeton roept YARN aan om taken uit te voeren en de communicatie tussen Templeton en YARN kan een time-out veroorzaken.
Op YARN-niveau zijn er twee soorten time-outs:
Het indienen van een YARN-taak kan lang genoeg duren om een time-out te veroorzaken.
Als u het
/var/log/webhcat/webhcat.loglogboekbestand opent en zoekt naar 'in de wachtrij geplaatste taak', ziet u mogelijk meerdere vermeldingen waarin de uitvoeringstijd te lang is (>2000 ms), met vermeldingen met toenemende wachttijden.De tijd voor de in de wachtrij geplaatste taken blijft toenemen, omdat de snelheid waarmee nieuwe taken worden verzonden hoger is dan de snelheid waarmee de oude taken worden voltooid. Zodra het YARN-geheugen 100% wordt gebruikt, kan de joblauncher-wachtrij geen capaciteit meer lenen uit de standaardwachtrij. Daarom kunnen er geen nieuwe taken meer worden geaccepteerd in de joblauncher-wachtrij. Dit gedrag kan ertoe leiden dat de wachttijd langer en langer wordt, waardoor er een time-outfout optreedt die meestal wordt gevolgd door vele andere.
In de volgende afbeelding ziet u de joblauncherwachtrij bij 714,4% te veel gebruikt. Dit is acceptabel zolang er nog steeds vrije capaciteit in de standaardwachtrij is waaruit kan worden geleend. Wanneer het cluster echter volledig wordt gebruikt en het YARN-geheugen 100% capaciteit heeft, moeten nieuwe taken wachten, wat uiteindelijk time-outs veroorzaakt.

Er zijn twee manieren om dit probleem op te lossen: verminder de snelheid van nieuwe taken die worden verzonden of verhoog de verbruikssnelheid van oude taken door het cluster omhoog te schalen.
YARN-verwerking kan lang duren, wat time-outs kan veroorzaken.
Alle taken weergeven: dit is een tijdrovend gesprek. Met deze aanroep worden de toepassingen van yarn ResourceManager opgesomd en voor elke voltooide toepassing krijgt u de status van de YARN JobHistoryServer. Met een hoger aantal taken kan er een time-out opgetreden voor deze aanroep.
Taken weergeven die ouder zijn dan zeven dagen: De HDInsight YARN JobHistoryServer is geconfigureerd om voltooide taakgegevens gedurende zeven dagen (
mapreduce.jobhistory.max-age-mswaarde) te bewaren. Het opsommen van opgeschoonde taken resulteert in een time-out.
Ga als volgt te werk om deze problemen vast te stellen:
- Bepaal het UTC-tijdsbereik om problemen op te lossen
- Selecteer de juiste
webhcat.logbestanden - Zoeken naar WAARSCHUWINGEN en FOUTBERICHTen gedurende die tijd
Andere WebHCat-fouten
HTTP-statuscode 500
In de meeste gevallen waarin WebHCat 500 retourneert, bevat het foutbericht details over de fout. Zoek anders naar
webhcat.logWAARSCHUWINGEN en FOUTBERICHTen.Taakfouten
Er kunnen gevallen zijn waarin interacties met WebHCat zijn geslaagd, maar de taken mislukken.
Templeton verzamelt de uitvoer van de taakconsole zoals
stderrinstatusdir, wat vaak handig is voor het oplossen van problemen.stderrbevat de YARN-toepassings-id van de werkelijke query.
Stap 4: De omgevingsstack en -versies controleren
De pagina Ambari UI Stack en Version bevat informatie over de configuratie van clusterservices en de versiegeschiedenis van de service. Onjuiste versies van de Hadoop-servicebibliotheek kunnen een oorzaak zijn van een clusterfout. Selecteer in de Ambari-gebruikersinterface het menu Beheer en vervolgens Stacks en Versions. Selecteer het tabblad Versies op de pagina om informatie over de serviceversie weer te geven:
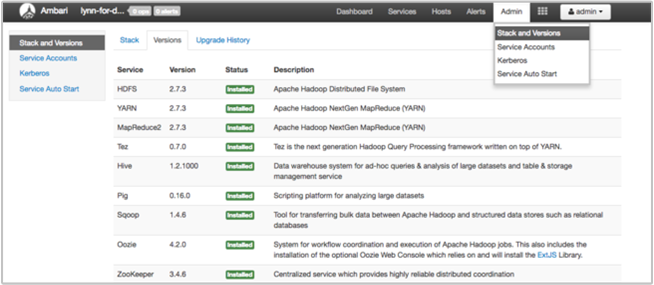
Stap 5: De logboekbestanden onderzoeken
Er zijn veel soorten logboeken die worden gegenereerd op basis van de vele services en onderdelen die bestaan uit een HDInsight-cluster. Logboekbestanden van WebHCat worden eerder beschreven. Er zijn verschillende andere nuttige logboekbestanden die u kunt onderzoeken om problemen met uw cluster te beperken, zoals beschreven in de volgende secties.
HDInsight-clusters bestaan uit verschillende knooppunten, waarvan de meeste worden belast om ingediende taken uit te voeren. Taken worden gelijktijdig uitgevoerd, maar logboekbestanden kunnen alleen lineair resultaten weergeven. HDInsight voert nieuwe taken uit, waardoor anderen die niet eerst kunnen worden voltooid, worden beëindigd. Al deze activiteit wordt geregistreerd bij de
stderrensyslogbestanden.In de logboekbestanden van de scriptactie worden fouten of onverwachte configuratiewijzigingen weergegeven tijdens het maken van uw cluster.
De Hadoop-staplogboeken identificeren Hadoop-taken die zijn gestart als onderdeel van een stap met fouten.
De scriptactielogboeken controleren
HdInsight-scriptacties voeren scripts handmatig uit op het cluster of wanneer deze zijn opgegeven. Scriptacties kunnen bijvoorbeeld worden gebruikt om extra software op het cluster te installeren of om configuratie-instellingen van de standaardwaarden te wijzigen. Het controleren van de scriptactielogboeken kan inzicht geven in fouten die zijn opgetreden tijdens het instellen en configureren van het cluster. U kunt de status van een scriptactie bekijken door de knop Ops te selecteren in de Ambari-gebruikersinterface of door de logboeken te openen vanuit het standaardopslagaccount.
De scriptactielogboeken bevinden zich in de \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE map.
HDInsight-logboeken weergeven met behulp van Ambari-snelle koppelingen
De GEBRUIKERSinterface van HDInsight Ambari bevat een aantal secties voor snelle koppelingen . Als u toegang wilt krijgen tot de logboekkoppelingen voor een bepaalde service in uw HDInsight-cluster, opent u de Ambari-gebruikersinterface voor uw cluster en selecteert u vervolgens de servicekoppeling in de lijst aan de linkerkant. Selecteer de vervolgkeuzelijst Snelle koppelingen , vervolgens het HDInsight-knooppunt van belang en selecteer vervolgens de koppeling voor het bijbehorende logboek.
Bijvoorbeeld voor HDFS-logboeken:
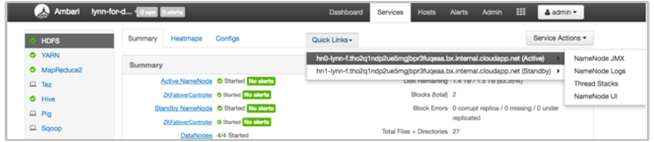
Door Hadoop gegenereerde logboekbestanden weergeven
Een HDInsight-cluster genereert logboeken die zijn geschreven naar Azure-tabellen en Azure Blob-opslag. YARN maakt eigen uitvoeringslogboeken. Zie Logboeken beheren voor een HDInsight-cluster voor meer informatie.
Heapdumps controleren
Heap-dumps bevatten een momentopname van het geheugen van de toepassing, inclusief de waarden van variabelen op dat moment, die handig zijn voor het diagnosticeren van problemen die zich tijdens runtime voordoen. Zie Heap-dumps inschakelen voor Apache Hadoop-services in HDInsight op basis van Linux voor meer informatie.
Stap 6: Configuratie-instellingen controleren
HDInsight-clusters zijn vooraf geconfigureerd met standaardinstellingen voor gerelateerde services, zoals Hadoop, Hive, HBase, enzovoort. Afhankelijk van het type cluster, de hardwareconfiguratie, het aantal knooppunten, de typen taken die u uitvoert en de gegevens waarmee u werkt (en hoe die gegevens worden verwerkt), moet u mogelijk uw configuratie optimaliseren.
Zie Clusterconfiguraties optimaliseren met Apache Ambari voor gedetailleerde instructies over het optimaliseren van prestatieconfiguraties voor de meeste scenario's. Als u Spark gebruikt, raadpleegt u Apache Spark-taken optimaliseren voor prestaties.
Stap 7: Reproduceer de fout in een ander cluster
Als u de bron van een clusterfout wilt diagnosticeren, start u een nieuw cluster met dezelfde configuratie en verzendt u vervolgens de stappen van de mislukte taak één voor één opnieuw. Controleer de resultaten van elke stap voordat u de volgende stap verwerkt. Deze methode biedt u de mogelijkheid om één mislukte stap te corrigeren en opnieuw uit te voeren. Deze methode heeft ook het voordeel dat u uw invoergegevens slechts eenmaal laadt.
- Maak een nieuw testcluster met dezelfde configuratie als het mislukte cluster.
- Verzend de eerste taakstap naar het testcluster.
- Wanneer de stap is verwerkt, controleert u op fouten in de logboekbestanden van de stap. Verbinding maken naar het hoofdknooppunt van het testcluster en bekijk de logboekbestanden daar. De logboekbestanden van de stap worden pas weergegeven nadat de stap enige tijd is uitgevoerd, is voltooid of mislukt.
- Als de eerste stap is geslaagd, voert u de volgende stap uit. Als er fouten zijn, onderzoekt u de fout in de logboekbestanden. Als het een fout in uw code was, voert u de correctie uit en voert u de stap opnieuw uit.
- Ga door totdat alle stappen zonder fouten worden uitgevoerd.
- Wanneer u klaar bent met het opsporen van fouten in het testcluster, verwijdert u het.
Volgende stappen
- HDInsight-clusters beheren met behulp van de Apache Ambari-webinterface
- HDInsight-logboeken analyseren
- Toegang tot apache Hadoop YARN-toepassing aanmelden bij HDInsight op basis van Linux
- Heap-dumps inschakelen voor Apache Hadoop-services in HDInsight op basis van Linux
- Bekende problemen voor Apache Spark-cluster in HDInsight