Zelfstudie: Een Apache Spark-toepassing voor machine learning bouwen in Azure HDInsight
In deze zelfstudie leert u hoe u het Jupyter-notebook gebruikt voor het bouwen van een Apache Spark-toepassing voor Machine Learning voor Azure HDInsight.
MLlib is de aanpasbare machine learning-bibliotheek van Spark die bestaat uit veelvoorkomende machine learning-algoritmen en -hulpprogramma's. (Classificatie, regressie, clustering, gezamenlijke filtering en dimensionaliteitsvermindering. Ook onderliggende optimalisatieprimitief.)
In deze zelfstudie leert u het volgende:
- Een Apache Spark-toepassing voor Machine Learning ontwikkelen
Vereisten
Een Apache Spark-cluster in HDInsight. Zie Een Apache Spark-cluster maken.
Weten hoe u Jupyter Notebooks gebruikt met Apache Spark on HDInsight. Zie Zelfstudie: Gegevens laden en query's uitvoeren in een Apache Spark-cluster in Azure HDInsight voor meer informatie.
Informatie over de gegevensset
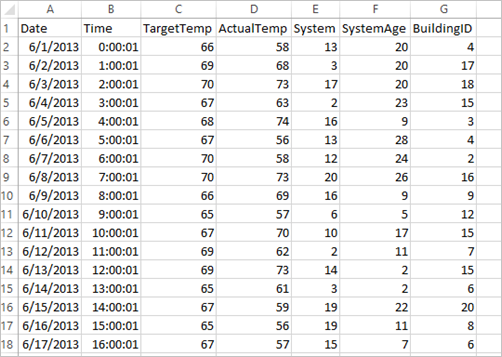
De toepassing gebruikt de voorbeeldgegevens uit HVAC.csv. Dit bestand is standaard beschikbaar in alle clusters. Het bestand bevindt zich op \HdiSamples\HdiSamples\SensorSampleData\hvac. De gegevens hebben betrekking op de gewenste temperatuur en de werkelijke temperatuur in enkele gebouwen waarin HVAC-systemen zijn geïnstalleerd. De kolom System bevat de id van het betreffende systeem en de kolom SystemAge geeft het aantal jaren aan dat het HVAC-systeem wordt gebruikt in het gebouw. U kunt voorspellen of het in een gebouw warmer of kouder zal zijn gebaseerd op de richttemperatuur, een systeem-id en de leeftijd van het systeem.
Een Spark-toepassing voor machine learning ontwikkelen met Spark MLib
Deze toepassing gebruikt een ML-pijplijn van Spark om een documentclassificatie uit te voeren. ML-pijplijnen bieden een uniforme set algemene API's die zijn gebaseerd op DataFrames. Met de DataFrames kunnen gebruikers praktische pijplijnen voor machine learning maken en afstemmen. In de pijplijn splitst u het document op in woorden, converteert u de woorden naar een numerieke functievector en bouwt u ten slotte een voorspellend model met behulp van de functievectoren en labels. Voer de volgende stappen uit om de toepassing te maken.
Maak een Jupyter-notebook met behulp van de PySpark-kernel. Zie Een Jupyter Notebook-bestand maken voor de instructies.
Importeer de typen die nodig zijn voor dit scenario. Plak het volgende codefragment in een lege cel en druk op Shift+Enter.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayLaad de gegevens (hvac.csv), parseer de gegevens en gebruik ze voor het trainen van het model.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()In het codefragment definieert u een functie waarmee de werkelijke temperatuur wordt vergeleken met de gewenste temperatuur. Als de werkelijke temperatuur hoger is, is het warm in het gebouw, aangegeven door de waarde 1.0. Anders is het koud in het gebouw, wat wordt aangegeven door de waarde 0.0.
Configureer de Spark Machine Learning-pijplijn die bestaat uit drie fasen:
tokenizer,hashingTFenlr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])Zie Apache Spark machine learning pipeline (Pijplijn voor machine learning van Apache Spark) voor meer informatie over pijplijnen en hoe ze werken.
Koppel de pijplijn aan het trainingsdocument.
model = pipeline.fit(training)Controleer het trainingsdocument om de voortgang met de toepassing te controleren.
training.show()De uitvoer is vergelijkbaar met:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Vergelijk de uitvoer met het onbewerkte CSV-bestand. De eerste rij van het CSV-bestand bevat bijvoorbeeld deze gegevens:

U ziet hoe de werkelijke temperatuur lager is dan de richttemperatuur, wat betekent dat het koud is in het gebouw. De waarde voor label in de eerste rij is 0.0, wat betekent dat het niet warm is in het gebouw.
Bereid een gegevensset voor die kan worden uitgevoerd op het getrainde model. Hiervoor geeft u een systeem-id en systeemleeftijd (aangeduid als SystemInfo in de training-uitvoer) door. Het model voorspelt of het gebouw met die systeem-id en systeemleeftijd warmer (aangeduid met 1.0) of kouder (aangeduid met 0.0) wordt.
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Genereer als laatste voorspellingen op basis van de testgegevens.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)De uitvoer is vergelijkbaar met:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Bekijk de eerste rij van de voorspelling. Voor een HVAC-systeem met de id 20 en een leeftijd van 25 jaar, is het warm in het gebouw (voorspelling=1.0). De eerste waarde voor DenseVector (0.49999) komt overeen met de voorspelling 0.0 en de tweede waarde (0.5001) komt overeen met de voorspelling 1.0. In de uitvoer toont het model prediction=1.0, ook al is de tweede waarde maar een fractie hoger.
Sluit het notebook om de resources vrij te geven. Selecteer hiervoor Sluiten en stoppen in het menu Bestand van het notebook. Met deze actie wordt het notebook afgesloten en gesloten.
scikit-learn-bibliotheek van Anaconda gebruiken voor een Spark-toepassing voor machine learning
Apache Spark-clusters in HDInsight bevatten Anaconda-bibliotheken, waaronder de bibliotheek scikit-learn voor machine learning. De bibliotheek bevat ook verschillende gegevenssets die u kunt gebruiken om rechtstreeks vanuit een Jupyter-notebook voorbeeldtoepassingen te bouwen. Zie https://scikit-learn.org/stable/auto_examples/index.html voor voorbeelden van het gebruik van de bibliotheek scikit-learn.
Resources opschonen
Als u deze toepassing verder niet meer gebruikt, verwijdert u het cluster dat u hebt gemaakt, via de volgende stappen:
Meld u aan bij het Azure-portaal.
Typ HDInsight in het Zoekvak bovenaan.
Selecteer onder Services de optie HDInsight-clusters.
Selecteer in de lijst met HDInsight-clusters die wordt weergegeven, de ... naast het cluster dat u voor deze zelfstudie hebt gemaakt.
Selecteer Verwijderen. Selecteer Ja.
Volgende stappen
In deze zelfstudie hebt u geleerd hoe u het Jupyter-notebook gebruikt voor het bouwen van een Apache Spark-toepassing voor machine learning voor Azure HDInsight. Ga naar de volgende zelfstudie voor meer informatie over het gebruik van IntelliJ IDEA voor Spark-taken.