PyTorch-model trainen
In dit artikel wordt beschreven hoe u het onderdeel PyTorch-model trainen in azure Machine Learning Designer gebruikt om PyTorch-modellen zoals DenseNet te trainen. Training vindt plaats nadat u een model hebt gedefinieerd en de parameters ervan hebt ingesteld. Hiervoor zijn gelabelde gegevens vereist.
Momenteel ondersteunt het onderdeel PyTorch-model trainen zowel één knooppunt als gedistribueerde training.
PyTorch-model trainen gebruiken
Voeg het DenseNet-onderdeel of ResNet toe aan uw pijplijnconcept in de ontwerpfunctie.
Voeg het onderdeel PyTorch-model trainen toe aan de pijplijn. U vindt dit onderdeel onder de categorie Modeltraining . Vouw Trainen uit en sleep het onderdeel PyTorch-model trainen naar uw pijplijn.
Notitie
Het pyTorch-modelonderdeel trainen kan beter worden uitgevoerd op GPU-rekenkracht voor grote gegevenssets, anders mislukt uw pijplijn. U kunt compute voor een specifiek onderdeel selecteren in het rechterdeelvenster van het onderdeel door Ander rekendoel gebruiken in te stellen.
Koppel aan de linkerkant een niet-getraind model. Koppel de trainingsgegevensset en validatiegegevensset aan de middelste en rechterinvoer van PyTorch-model trainen.
Voor een niet-getraind model moet het een PyTorch-model zijn, zoals DenseNet; Anders wordt er een 'InvalidModelDirectoryError' gegenereerd.
Voor gegevenssets moet de trainingsgegevensset een gelabelde afbeeldingsmap zijn. Raadpleeg Converteren naar afbeeldingsmap voor het ophalen van een gelabelde afbeeldingsmap. Als dit niet is gelabeld, wordt een 'NotLabeledDatasetError' gegenereerd.
De trainingsgegevensset en validatiegegevensset hebben dezelfde labelcategorieën, anders wordt er een InvalidDatasetError gegenereerd.
Geef voor Epochs op hoeveel tijdvakken u wilt trainen. De hele gegevensset wordt in elk tijdvak opnieuw uitgevoerd, standaard 5.
Geef voor Batchgrootte op hoeveel exemplaren in een batch moeten worden getraind, standaard 16.
Geef voor Het nummer van de warming-upstap op hoeveel tijdvakken u de training wilt opwarmen, voor het geval de initiële leersnelheid iets te groot is om te beginnen met samenvoegen, standaard 0.
Geef bij Leerfrequentie een waarde op voor de leersnelheid en de standaardwaarde is 0,001. Leersnelheid bepaalt de grootte van de stap die in optimizer wordt gebruikt, zoals sgd telkens wanneer het model wordt getest en gecorrigeerd.
Door de snelheid lager in te stellen, test u het model vaker, met het risico dat u vastloopt in een lokaal plateau. Door het tarief hoger in te stellen, kunt u sneller convergeren, met het risico dat de werkelijke minima wordt overschreden.
Notitie
Als het trainingsverlies tijdens de training wordt veroorzaakt door een te hoge leersnelheid, kan het verminderen van de leersnelheid helpen. Bij gedistribueerde training wordt, om gradiëntafname stabiel te houden, de werkelijke leersnelheid berekend door
lr * torch.distributed.get_world_size()omdat de batchgrootte van de procesgroep de grootte van de wereld maal die van één proces is. Polynomial learning rate verval wordt toegepast en kan helpen bij een beter presterend model.Voor Willekeurig zaad typt u desgewenst een geheel getal dat u als seed wilt gebruiken. Het gebruik van een seed wordt aanbevolen als u de reproduceerbaarheid van het experiment tussen taken wilt garanderen.
Voor Geduld geeft u op hoeveel tijdvakken u vroegtijdig moet stoppen met trainen als het validatieverlies niet opeenvolgend afneemt. standaard 3.
Geef bij Afdrukfrequentie de afdrukfrequentie van het trainingslogboek op voor iteraties in elk tijdvak, standaard 10.
Verzend de pijplijn. Als uw gegevensset groter is, duurt het even en wordt GPU-rekenkracht aanbevolen.
Gedistribueerde training
In gedistribueerde training wordt de workload voor het trainen van een model opgesplitst en gedeeld tussen meerdere miniprocessors, werkknooppunten genoemd. Deze werkknooppunten werken parallel om modeltraining te versnellen. Momenteel ondersteunt de ontwerper gedistribueerde training voor het onderdeel PyTorch-model trainen .
Trainingstijd
Gedistribueerde training maakt het mogelijk om te trainen op een grote gegevensset zoals ImageNet (1000 klassen, 1,2 miljoen afbeeldingen) in slechts enkele uren met Behulp van Het PyTorch-model trainen. In de volgende tabel ziet u de trainingstijd en prestaties tijdens de training 50 perioden van Resnet50 op ImageNet op basis van verschillende apparaten.
| Apparaten | Trainingstijd | Doorvoer van training | Top-1 validatienauwkeurigheid | Top-5 validatienauwkeurigheid |
|---|---|---|---|---|
| 16 V100 GPU's | 6u22min | ~3200 afbeeldingen per seconde | 68.83% | 88.84% |
| 8 V100 GPU's | 12u21min | ~1670 afbeeldingen per seconde | 68.84% | 88.74% |
Klik op het tabblad Metrische gegevens van dit onderdeel en bekijk grafieken met metrische gegevens voor training, zoals 'Afbeeldingen trainen per seconde' en 'Hoogste 1 nauwkeurigheid'.

Gedistribueerde training inschakelen
Als u gedistribueerde training voor het onderdeel PyTorch-model trainen wilt inschakelen, kunt u instellen in Taakinstellingen in het rechterdeelvenster van het onderdeel. Alleen AML Compute-cluster wordt ondersteund voor gedistribueerde training.
Notitie
Er zijn meerdere GPU's vereist om gedistribueerde training te activeren, omdat het nccl-back-endonderdeel PyTorch-model de behoeften cuda gebruikt.
Selecteer het onderdeel en open het rechterdeelvenster. Vouw de sectie Taakinstellingen uit .
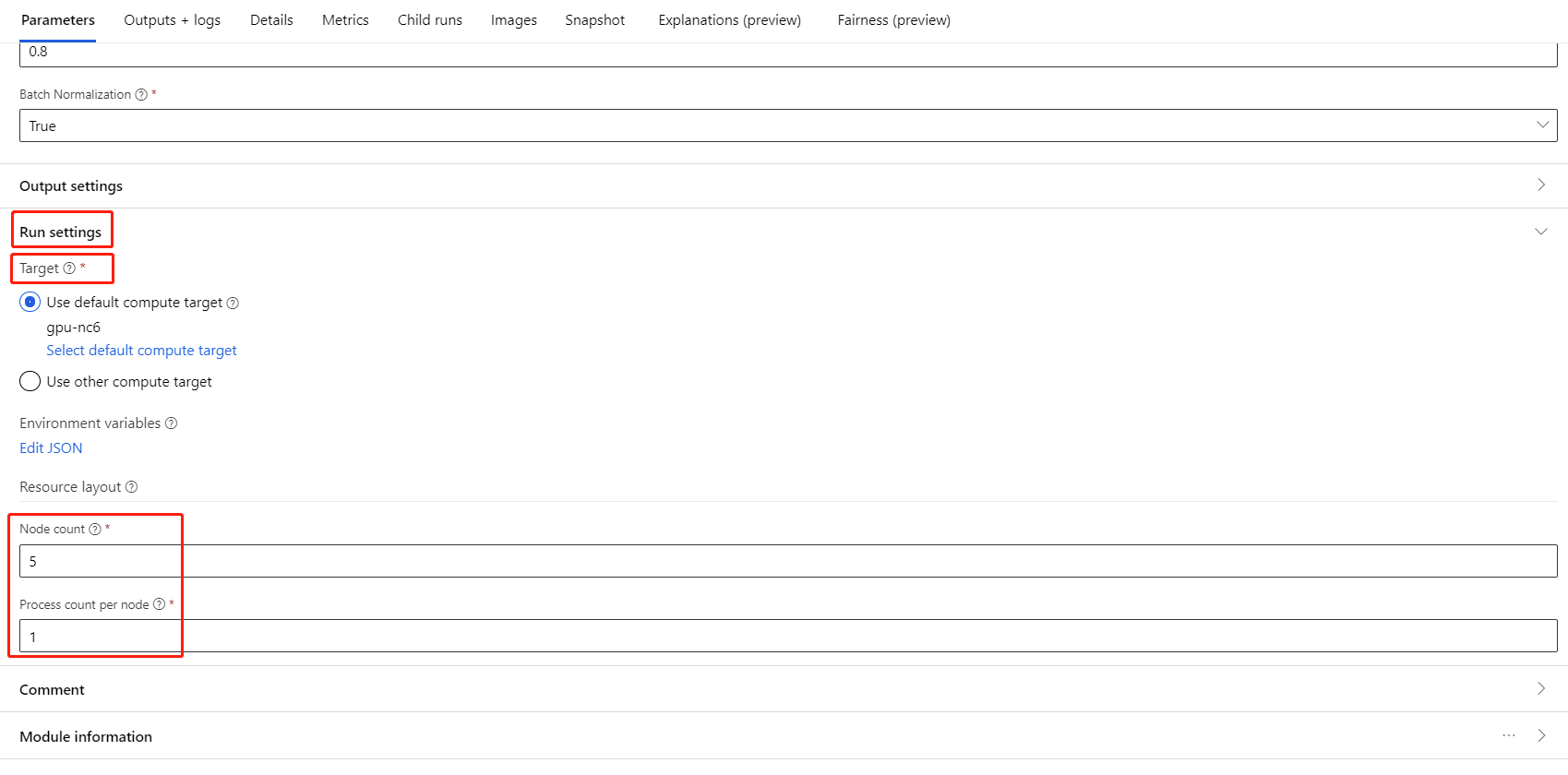
Zorg ervoor dat u AML-berekening hebt geselecteerd voor het rekendoel.
In de sectie Resource-indeling moet u de volgende waarden instellen:
Aantal knooppunten : het aantal knooppunten in het rekendoel dat wordt gebruikt voor de training. Deze moet kleiner zijn dan of gelijk zijn aan het Maximum aantal knooppunten van uw rekencluster. Standaard is dit 1, wat een taak met één knooppunt betekent.
Aantal processen per knooppunt: het aantal processen dat per knooppunt wordt geactiveerd. Deze moet kleiner zijn dan of gelijk zijn aan de verwerkingseenheid van uw rekenproces. Standaard is dit 1, wat een taak met één proces betekent.
U kunt het maximum aantal knooppunten en de verwerkingseenheid van uw rekenproces controleren door op de naam van de berekening te klikken op de pagina met rekengegevens.



Meer informatie over gedistribueerde training in Azure Machine Learning vindt u hier.
Problemen met gedistribueerde training oplossen
Als u gedistribueerde training voor dit onderdeel inschakelt, zijn er stuurprogrammalogboeken voor elk proces. 70_driver_log_0 is voor het hoofdproces. U kunt stuurprogrammalogboeken controleren op foutdetails van elk proces op het tabblad Uitvoer en logboeken in het rechterdeelvenster.

Als het onderdeel gedistribueerde training mislukt zonder 70_driver logboeken, kunt u controleren op 70_mpi_log foutdetails.
In het volgende voorbeeld ziet u een veelvoorkomende fout, namelijk het aantal processen per knooppunt is groter dan de verwerkingseenheid van de berekening.

Raadpleeg dit artikel voor meer informatie over het oplossen van problemen met onderdelen.
Resultaten
Nadat de pijplijntaak is voltooid, koppelt u het PyTorch-model trainen aan het afbeeldingsmodel scoren om waarden voor nieuwe invoervoorbeelden te voorspellen.
Technische opmerkingen
Verwachte invoer
| Naam | Type | Description |
|---|---|---|
| Niet-getraind model | UntrainedModelDirectory | Niet-getraind model, PyTorch vereisen |
| Trainingsgegevensset | ImageDirectory | Trainingsgegevensset |
| Validatiegegevensset | ImageDirectory | Validatiegegevensset voor evaluatie van elk tijdvak |
Onderdeelparameters
| Naam | Bereik | Type | Standaard | Beschrijving |
|---|---|---|---|---|
| Tijdperken | >0 | Geheel getal | 5 | Selecteer de kolom die het label of de resultaatkolom bevat |
| Batchgrootte | >0 | Geheel getal | 16 | Hoeveel exemplaren er in een batch moeten worden getraind |
| Nummer van de warming-upstap | >=0 | Geheel getal | 0 | Hoeveel tijdvakken om training op te warmen |
| Leersnelheid | >=double. Epsilon | Float | 0,1 | Het initiële leerpercentage voor de optimalisatie van stochastische gradiëntafname. |
| Willekeurig zaad | Alle | Geheel getal | 1 | De seed voor de generator voor willekeurige getallen die door het model wordt gebruikt. |
| Geduld | >0 | Geheel getal | 3 | Hoeveel tijdvakken tot vroege stoptraining |
| Afdrukfrequentie | >0 | Geheel getal | 10 | Afdrukfrequentie van trainingslogboeken over iteraties in elk tijdvak |
Uitvoerwaarden
| Naam | Type | Description |
|---|---|---|
| Getraind model | Modeldirectory | Getraind model |
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.