Modelonderdeel evalueren
In dit artikel wordt een onderdeel in Azure Machine Learning Designer beschreven.
Gebruik dit onderdeel om de nauwkeurigheid van een getraind model te meten. U geeft een gegevensset op die scores bevat die zijn gegenereerd op basis van een model en het onderdeel Evaluate Model berekent een set metrische metrische gegevens over de standaardevaluatie.
De metrische gegevens die door Evaluate Model worden geretourneerd, zijn afhankelijk van het type model dat u evalueert:
- Classificatiemodellen
- Regressiemodellen
- Clusteringmodellen
Tip
Als u geen ervaring hebt met modelevaluatie, raden we de videoserie van Dr. Stephen Elston aan als onderdeel van de machine learning-cursus van EdX.
Evaluate Model gebruiken
Verbinding maken de Scored gegevenssetuitvoer van de uitvoer van de scoremodel- of resultaatgegevensset van de toewijzingsgegevens aan clusters aan de linkerinvoerpoort van Evaluate Model.
Notitie
Als u onderdelen zoals 'Kolommen in gegevensset selecteren' gebruikt om een deel van de invoergegevensset te selecteren, moet u ervoor zorgen dat de kolom Werkelijke labelkolom (gebruikt in de training) en de kolom Scored Labels bestaan om metrische gegevens zoals AUC, Nauwkeurigheid voor binaire classificatie/anomaliedetectie te berekenen. De kolom 'Scored Labels' bestaat voor het berekenen van metrische gegevens voor classificatie/regressie van meerdere klassen. Kolom 'Toewijzingen', kolommen 'DistancesToClusterCenter no.X' (X is zwaartepuntsindex, variërend van 0, ..., aantal zwaartepunten-1) bestaat om metrische gegevens voor clustering te berekenen.
Belangrijk
- Als u de resultaten wilt evalueren, moet de uitvoergegevensset specifieke kolomnamen voor scoren bevatten, die voldoen aan de vereisten voor het evalueren van modelonderdelen.
- De
Labelskolom wordt beschouwd als werkelijke labels. - Voor regressietaak moet de te evalueren gegevensset één kolom hebben met de naam
Regression Scored Labels, die scoren labels vertegenwoordigt. - Voor de binaire classificatietaak moet de gegevensset die moet worden geëvalueerd twee kolommen met de naam
Binary Class Scored Labels,Binary Class Scored Probabilitiesdie respectievelijk scoren labels en waarschijnlijkheden vertegenwoordigen. - Voor een taak met meerdere classificaties moet de gegevensset die moet worden geëvalueerd, één kolom hebben met de naam
Multi Class Scored Labels, die gescoorde labels vertegenwoordigt. Als de uitvoer van het upstream-onderdeel deze kolommen niet bevat, moet u deze wijzigen volgens de bovenstaande vereisten.
[Optioneel] Verbinding maken de Scored gegevenssetuitvoer van de uitvoer van de scoremodel- of resultaatgegevensset van de toewijzingsgegevens aan clusters voor het tweede model aan de juiste invoerpoort van Evaluate Model. U kunt eenvoudig resultaten van twee verschillende modellen op dezelfde gegevens vergelijken. De twee invoeralgoritmen moeten hetzelfde algoritmetype zijn. Of u kunt scores van twee verschillende uitvoeringen vergelijken met dezelfde gegevens met verschillende parameters.
Notitie
Het algoritmetype verwijst naar 'Classificatie met twee klassen', 'Classificatie met meerdere klassen', 'Regressie', 'Clustering' onder 'Machine Learning-algoritmen'.
Verzend de pijplijn om de evaluatiescores te genereren.
Resultaten
Nadat u Evaluate Model hebt uitgevoerd, selecteert u het onderdeel om het navigatiedeelvenster Evaluate Model aan de rechterkant te openen. Kies vervolgens het tabblad Uitvoer en logboeken en op dat tabblad bevat de sectie Gegevensuitvoer verschillende pictogrammen. Het pictogram Visualiseren heeft een staafdiagrampictogram en is een eerste manier om de resultaten te bekijken.
Nadat u op het pictogram Visualiseren hebt geklikt, kunt u de binaire verwarringsmatrix visualiseren voor binaire classificatie. Voor meerdere classificaties vindt u het bestand met verwarringsmatrixtekens onder het tabblad Uitvoer en logboeken als volgt:
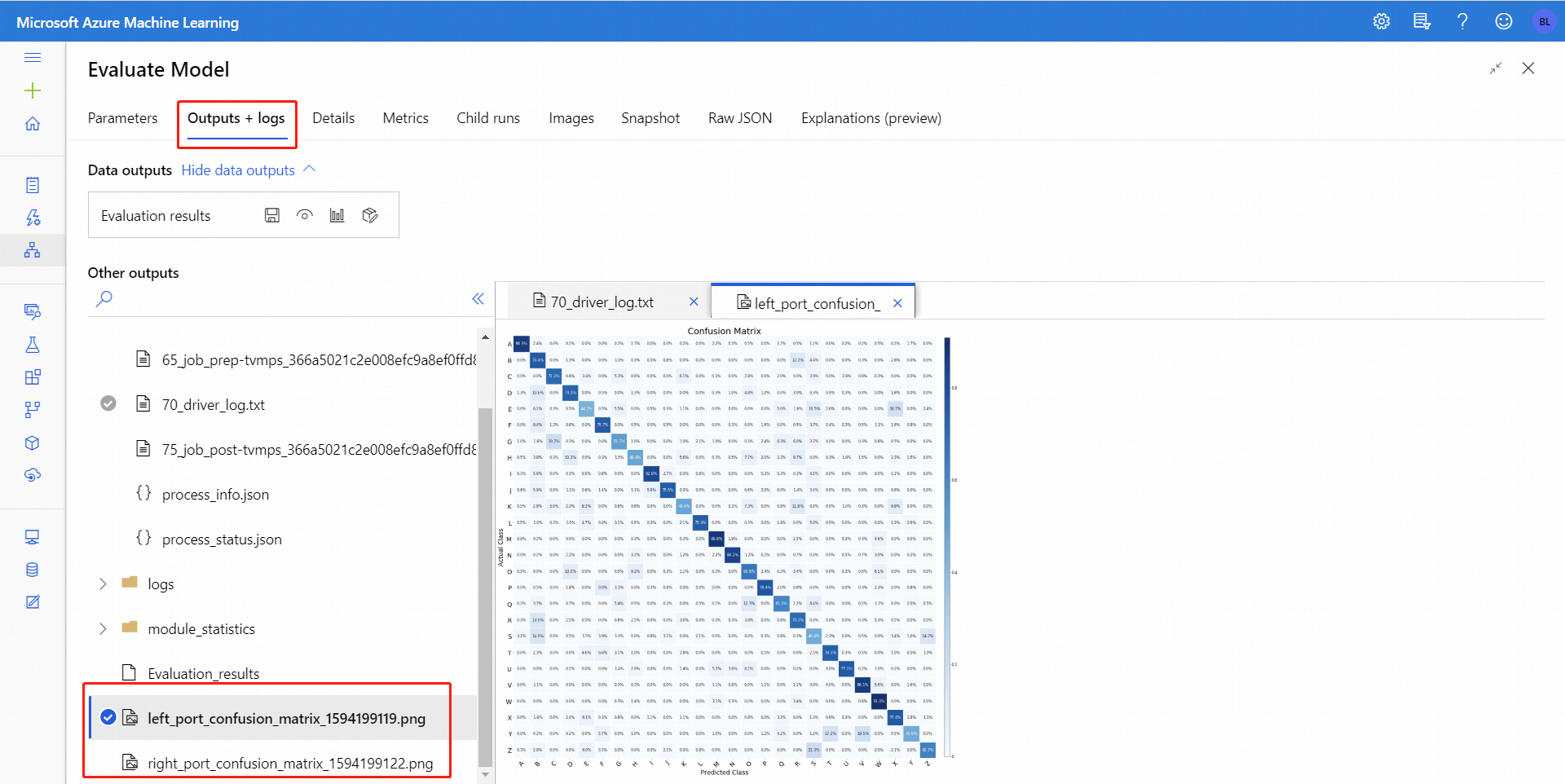
Als u gegevenssets verbindt met beide invoer van Evaluate Model, bevatten de resultaten metrische gegevens voor beide gegevenssets of beide modellen. Het model of de gegevens die aan de linkerpoort zijn gekoppeld, worden eerst weergegeven in het rapport, gevolgd door de metrische gegevens voor de gegevensset of het model dat is gekoppeld aan de rechterpoort.
De volgende afbeelding vertegenwoordigt bijvoorbeeld een vergelijking van resultaten van twee clusteringmodellen die zijn gebouwd op dezelfde gegevens, maar met verschillende parameters.
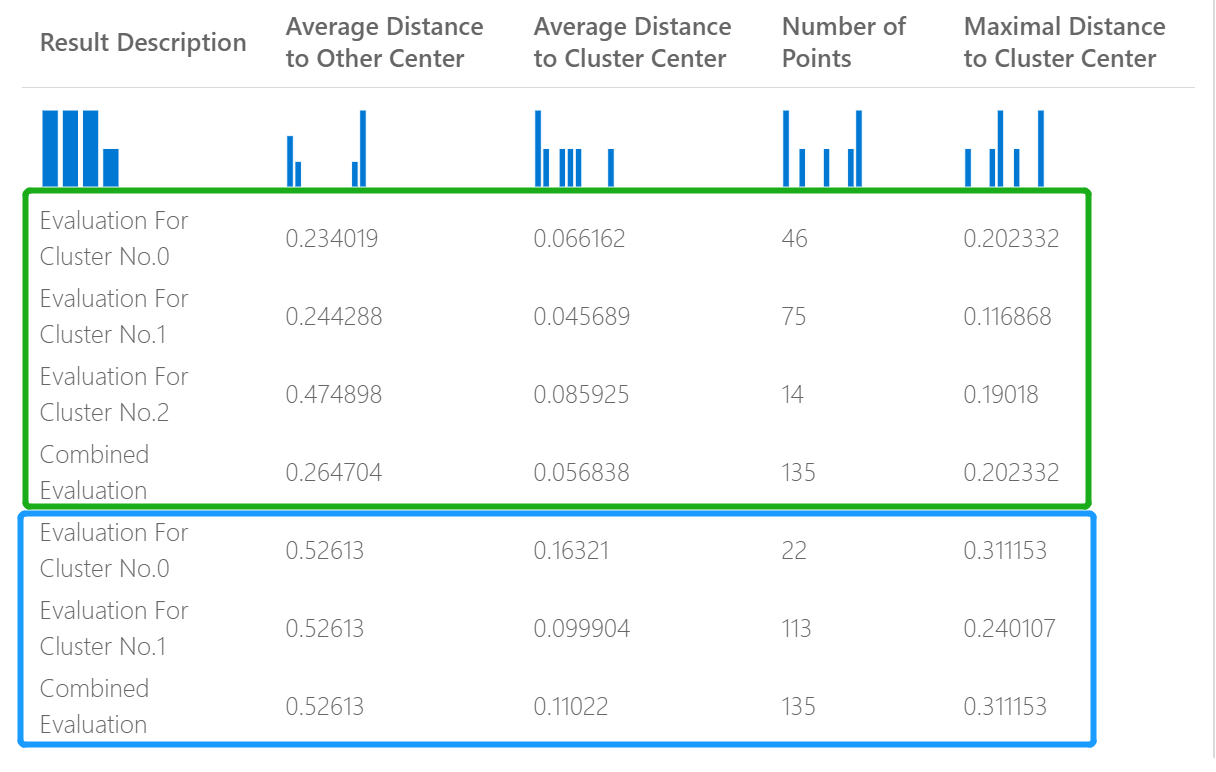
Omdat dit een clusteringmodel is, zijn de evaluatieresultaten anders dan als u scores van twee regressiemodellen hebt vergeleken of twee classificatiemodellen hebt vergeleken. De algehele presentatie is echter hetzelfde.
Metrische gegevens voor
In deze sectie worden de metrische gegevens beschreven die worden geretourneerd voor de specifieke typen modellen die worden ondersteund voor gebruik met Evaluate Model:
Metrische gegevens voor classificatiemodellen
De volgende metrische gegevens worden gerapporteerd bij het evalueren van binaire classificatiemodellen.
Nauwkeurigheid meet de goedheid van een classificatiemodel als het aandeel werkelijke resultaten in totaal.
Precisie is het aandeel werkelijke resultaten ten opzichte van alle positieve resultaten. Precision = TP/(TP+FP)
Terughalen is het deel van de totale hoeveelheid relevante exemplaren die daadwerkelijk zijn opgehaald. Relevante overeenkomsten = TP/(TP+FN)
F1-score wordt berekend als het gewogen gemiddelde van precisie en relevante overeenkomsten tussen 0 en 1, waarbij de ideale F1-scorewaarde 1 is.
AUC meet het gebied onder de curve met terecht-positieven op de y-as en fout-positieven op de x-as. Deze metrische waarde is handig omdat het één getal biedt waarmee u modellen van verschillende typen kunt vergelijken. AUC is classificatie-drempelwaarde-invariant. Het meet de kwaliteit van de voorspellingen van het model, ongeacht welke classificatiedrempel wordt gekozen.
Metrische gegevens voor regressiemodellen
De metrische gegevens die worden geretourneerd voor regressiemodellen zijn ontworpen om de hoeveelheid fouten te schatten. Een model wordt beschouwd als geschikt voor de gegevens als het verschil tussen waargenomen en voorspelde waarden klein is. Als u echter kijkt naar het patroon van de residuen (het verschil tussen een voorspeld punt en de bijbehorende werkelijke waarde), kunt u veel vertellen over mogelijke vooroordelen in het model.
De volgende metrische gegevens worden gerapporteerd voor het evalueren van lineaire regressiemodellen. Andere regressiemodellen, zoals Fast Forest Quantile Regression , kunnen verschillende metrische gegevens bevatten.
Gemiddelde absolute fout (MAE) meet hoe dicht de voorspellingen bij de werkelijke resultaten liggen. Een lagere score is dus beter.
RmSE (Root Mean Squared Error) maakt één waarde die de fout in het model samenvat. Door het verschil te kwadraten, negeert de metrische waarde het verschil tussen overvoorspelling en ondervoorspelling.
Relatieve absolute fout (RAE) is het relatieve absolute verschil tussen verwachte en werkelijke waarden; relatief omdat het gemiddelde verschil wordt gedeeld door het rekenkundige gemiddelde.
De relatieve kwadratische fout (RSE) normaliseert op vergelijkbare wijze de totale kwadratische fout van de voorspelde waarden door de totale kwadratische fout van de werkelijke waarden te delen.
De bepalingscoëfficiënt, vaak R 2 genoemd, vertegenwoordigt de voorspellende kracht van het model als een waarde tussen 0 en 1. Nul betekent dat het model willekeurig is (legt niets uit); 1 betekent dat er een perfecte pasvorm is. Wees echter voorzichtig bij het interpreteren van R2-waarden , omdat lage waarden volledig normaal kunnen zijn en hoge waarden kunnen worden vermoed.
Metrische gegevens voor clusteringmodellen
Omdat clusteringmodellen in veel opzichten aanzienlijk verschillen van classificatie- en regressiemodellen, retourneert Evaluate Model ook een andere set statistieken voor clusteringmodellen.
De statistieken die worden geretourneerd voor een clusteringmodel beschrijven hoeveel gegevenspunten aan elk cluster zijn toegewezen, de hoeveelheid scheiding tussen clusters en hoe strak de gegevenspunten in elk cluster worden samengevoegd.
De statistieken voor het clusteringmodel worden gemiddeld berekend over de hele gegevensset, met extra rijen met de statistieken per cluster.
De volgende metrische gegevens worden gerapporteerd voor het evalueren van clustermodellen.
De scores in de kolom Gemiddelde afstand tot het andere centrum geven aan hoe dicht elk punt in het cluster gemiddeld ligt aan de zwaartepunten van alle andere clusters.
De scores in de kolom Gemiddelde afstand tot clustercentrum vertegenwoordigen de nabijheid van alle punten in een cluster tot het zwaartepunt van dat cluster.
In de kolom Aantal punten ziet u hoeveel gegevenspunten aan elk cluster zijn toegewezen, samen met het totale totale aantal gegevenspunten in een cluster.
Als het aantal gegevenspunten dat is toegewezen aan clusters kleiner is dan het totale aantal beschikbare gegevenspunten, betekent dit dat de gegevenspunten niet kunnen worden toegewezen aan een cluster.
De scores in de kolom Maximal Distance to Cluster Center vertegenwoordigen het maximum van de afstanden tussen elk punt en het zwaartepunt van het cluster van dat punt.
Als dit aantal hoog is, kan dit betekenen dat het cluster veel verspreid is. Bekijk deze statistiek samen met de gemiddelde afstand tot het clustercentrum om de verspreiding van het cluster te bepalen.
De gecombineerde evaluatiescore onderaan elke sectie met resultaten bevat de gemiddelde scores voor de clusters die in dat specifieke model zijn gemaakt.
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.