Scorescript voor scoren met Azure Machine Learning-deductie-HTTP-server
De HTTP-server van Azure Machine Learning-deductie is een Python-pakket dat uw scorefunctie beschikbaar maakt als een HTTP-eindpunt en de Flask-servercode en afhankelijkheden verpakt in een enkel pakket. Deze wordt opgenomen in de vooraf gemaakte Docker-installatiekopieën voor deductie die worden gebruikt bij het implementeren van een model met Azure Machine Learning. Met behulp van het pakket kunt u het model lokaal implementeren voor productie en kunt u ook eenvoudig uw scorescript (invoerscript) valideren in een lokale ontwikkelomgeving. Als er een probleem is met het scorescript, retourneert de server een fout en de locatie waar de fout is opgetreden.
De server kan ook worden gebruikt om validatiepoorten te maken in een pijplijn voor continue integratie en implementatie. U kunt bijvoorbeeld de server starten met het kandidaatscript en de testsuite uitvoeren op het lokale eindpunt.
Dit artikel is voornamelijk bedoeld voor gebruikers die de deductieserver willen gebruiken om lokaal fouten op te sporen, maar het helpt u ook inzicht te krijgen in het gebruik van de deductieserver met online-eindpunten.
Lokale foutopsporing voor online-eindpunt
Fouten opsporen in eindpunten lokaal voordat u ze implementeert in de cloud, kan u helpen fouten in uw code en configuratie eerder te ondervangen. Als u lokaal fouten wilt opsporen in eindpunten, kunt u het volgende gebruiken:
- de HTTP-server voor deductie van Azure Machine Learning
- een lokaal eindpunt
Dit artikel is gericht op de HTTP-server voor deductie van Azure Machine Learning.
De volgende tabel bevat een overzicht van scenario's waarmee u kunt kiezen wat het beste voor u werkt.
| Scenario | HTTP-server voor deductie | Lokaal eindpunt |
|---|---|---|
| Lokale Python-omgeving bijwerken zonder opnieuw opbouwen van Docker-installatiekopieën | Ja | Nr. |
| Scorescript bijwerken | Ja | Ja |
| Implementatieconfiguraties bijwerken (implementatie, omgeving, code, model) | Nr. | Ja |
| VS Code-foutopsporingsprogramma integreren | Ja | Ja |
Door de HTTP-deductieserver lokaal uit te voeren, kunt u zich richten op het opsporen van fouten in uw scorescript zonder dat dit wordt beïnvloed door de configuraties van de implementatiecontainer.
Vereisten
- Vereist: Python >=3.8
- Anaconda
Tip
De AZURE Machine Learning-deductie-HTTP-server wordt uitgevoerd op Windows- en Linux-besturingssystemen.
Installatie
Notitie
Installeer de server in een virtuele omgeving om pakketconflicten te voorkomen.
Voer de volgende opdracht uit in de cmd/terminal om de azureml-inference-server-http packageopdracht te installeren:
python -m pip install azureml-inference-server-http
Fouten opsporen in uw scorescript lokaal
Als u lokaal fouten wilt opsporen in uw scorescript, kunt u testen hoe de server zich gedraagt met een dummy scorescript, VS Code gebruiken om fouten op te sporen met het azureml-deductie-server-http-pakket of de server testen met een daadwerkelijk scorescript, modelbestand en omgevingsbestand uit onze voorbeeldenopslagplaats.
Het servergedrag testen met een dummy scoring-script
Maak een map voor het opslaan van uw bestanden:
mkdir server_quickstart cd server_quickstartAls u pakketconflicten wilt voorkomen, maakt u een virtuele omgeving en activeert u deze:
python -m venv myenv source myenv/bin/activateTip
Voer na het testen
deactivateuit om de virtuele Python-omgeving te deactiveren.Installeer het
azureml-inference-server-httppakket vanuit de pypi-feed :python -m pip install azureml-inference-server-httpMaak uw invoerscript (
score.py). In het volgende voorbeeld wordt een basisscript voor invoer gemaakt:echo ' import time def init(): time.sleep(1) def run(input_data): return {"message":"Hello, World!"} ' > score.pyStart de server (azmlinfsrv) en stel
score.pydeze in als het invoerscript:azmlinfsrv --entry_script score.pyNotitie
De server wordt gehost op 0.0.0.0.0, wat betekent dat deze luistert naar alle IP-adressen van de hostingcomputer.
Verzend een scoreaanvraag naar de server met behulp van
curl:curl -p 127.0.0.1:5001/scoreDe server moet er als volgt op reageren.
{"message": "Hello, World!"}
Na het testen kunt u op de server drukken Ctrl + C om de server te beëindigen.
U kunt nu het scorescript (score.py) wijzigen en uw wijzigingen testen door de server opnieuw uit te voeren (azmlinfsrv --entry_script score.py).
Integreren met Visual Studio Code
Er zijn twee manieren om Visual Studio Code (VS Code) en python-extensie te gebruiken om fouten op te sporen met het azureml-inference-server-http-pakket (launch and attach modes).
Startmodus: stel de in VS Code in en start de HTTP-server voor Azure Machine Learning-deductie
launch.jsonin VS Code.Start VS Code en open de map met het script (
score.py).Voeg de volgende configuratie toe aan
launch.jsondie werkruimte in VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Debug score.py", "type": "python", "request": "launch", "module": "azureml_inference_server_http.amlserver", "args": [ "--entry_script", "score.py" ] } ] }Start de foutopsporingssessie in VS Code. Selecteer Uitvoeren -> Foutopsporing starten (of
F5).
Koppelmodus: start de HTTP-server van Deductie van Azure Machine Learning in een opdrachtregel en gebruik VS Code + Python-extensie om te koppelen aan het proces.
Notitie
Als u een Linux-omgeving gebruikt, installeert u eerst het
gdbpakket door het uit te voerensudo apt-get install -y gdb.Voeg de volgende configuratie toe aan
launch.jsondie werkruimte in VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Python: Attach using Process Id", "type": "python", "request": "attach", "processId": "${command:pickProcess}", "justMyCode": true }, ] }Start de deductieserver met behulp van CLI (
azmlinfsrv --entry_script score.py).Start de foutopsporingssessie in VS Code.
- Selecteer in VS Code 'Uitvoeren' -> 'Foutopsporing starten' (of
F5). - Voer de proces-id in van de
azmlinfsrv(niet degunicorn) met behulp van de logboeken (van de deductieserver) die wordt weergegeven in de CLI.
Notitie
Als de proceskiezer niet wordt weergegeven, voert u handmatig de proces-id in het
processIdveld van delaunch.json.- Selecteer in VS Code 'Uitvoeren' -> 'Foutopsporing starten' (of
Op beide manieren kunt u stap voor stap onderbrekingspunt en foutopsporing instellen.
End-to-end-voorbeeld
In deze sectie voeren we de server lokaal uit met voorbeeldbestanden (scorescript, modelbestand en omgeving) in onze voorbeeldopslagplaats. De voorbeeldbestanden worden ook gebruikt in ons artikel voor het implementeren en beoordelen van een machine learning-model met behulp van een online-eindpunt
Kloon de voorbeeldopslagplaats.
git clone --depth 1 https://github.com/Azure/azureml-examples cd azureml-examples/cli/endpoints/online/model-1/Een virtuele omgeving maken en activeren met Conda. In dit voorbeeld wordt het
azureml-inference-server-httppakket automatisch geïnstalleerd omdat het als een afhankelijke bibliotheek van hetazureml-defaultspakketconda.ymlals volgt wordt opgenomen.# Create the environment from the YAML file conda env create --name model-env -f ./environment/conda.yml # Activate the new environment conda activate model-envControleer uw scorescript.
onlinescoring/score.py
import os import logging import json import numpy import joblib def init(): """ This function is called when the container is initialized/started, typically after create/update of the deployment. You can write the logic here to perform init operations like caching the model in memory """ global model # AZUREML_MODEL_DIR is an environment variable created during deployment. # It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION) # Please provide your model's folder name if there is one model_path = os.path.join( os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl" ) # deserialize the model file back into a sklearn model model = joblib.load(model_path) logging.info("Init complete") def run(raw_data): """ This function is called for every invocation of the endpoint to perform the actual scoring/prediction. In the example we extract the data from the json input and call the scikit-learn model's predict() method and return the result back """ logging.info("model 1: request received") data = json.loads(raw_data)["data"] data = numpy.array(data) result = model.predict(data) logging.info("Request processed") return result.tolist()Voer de deductieserver uit met het opgeven van scorescript en modelbestand. De opgegeven modelmap (
model_dirparameter) wordt gedefinieerd alsAZUREML_MODEL_DIRvariabele en opgehaald in het scorescript. In dit geval geven we de huidige map (./) op omdat de submap is opgegeven in het scorescript alsmodel/sklearn_regression_model.pkl.azmlinfsrv --entry_script ./onlinescoring/score.py --model_dir ./Het voorbeeld van het opstartlogboek wordt weergegeven als de server is gestart en het scorescript is aangeroepen. Anders worden er foutberichten weergegeven in het logboek.
Test het scorescript met een voorbeeldgegevens. Open een andere terminal en ga naar dezelfde werkmap om de opdracht uit te voeren. Gebruik de
curlopdracht om een voorbeeldaanvraag naar de server te verzenden en een scoreresultaat te ontvangen.curl --request POST "127.0.0.1:5001/score" --header "Content-Type:application/json" --data @sample-request.jsonHet scoreresultaat wordt geretourneerd als er geen probleem is in uw scorescript. Als er iets mis is, kunt u proberen het scorescript bij te werken en de server opnieuw te starten om het bijgewerkte script te testen.
Serverroutes
De server luistert op poort 5001 (standaard) op deze routes.
| Naam | Route |
|---|---|
| Levenheidstest | 127.0.0.1:5001/ |
| Score | 127.0.0.1:5001/score |
| OpenAPI (swagger) | 127.0.0.1:5001/swagger.json |
Serverparameters
De volgende tabel bevat de parameters die door de server worden geaccepteerd:
| Parameter | Vereist | Default | Beschrijving |
|---|---|---|---|
| entry_script | Waar | N.v.t. | Het relatieve of absolute pad naar het scorescript. |
| model_dir | Onwaar | N.v.t. | Het relatieve of absolute pad naar de map met het model dat wordt gebruikt voor deductie. |
| poort | Onwaar | 5001 | De serverpoort. |
| worker_count | Onwaar | 1 | Het aantal werkrolthreads dat gelijktijdige aanvragen verwerkt. |
| appinsights_instrumentation_key | Onwaar | N.v.t. | De instrumentatiesleutel voor de application insights waar de logboeken worden gepubliceerd. |
| access_control_allow_origins | Onwaar | N.v.t. | Schakel CORS in voor de opgegeven oorsprongen. Scheid meerdere oorsprongen met ','. Voorbeeld: 'microsoft.com, bing.com' |
Aanvraagstroom
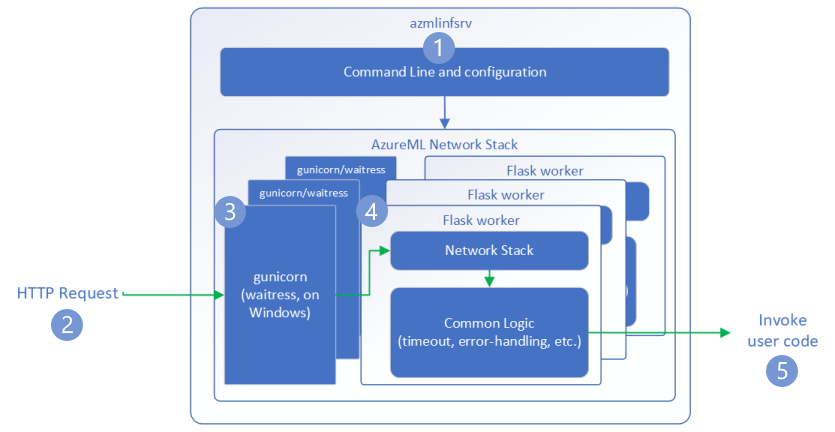
In de volgende stappen wordt uitgelegd hoe de HTTP-server van Deductie van Azure Machine Learning (azmlinfsrv) binnenkomende aanvragen verwerkt:
- Een Python CLI-wrapper bevindt zich rond de netwerkstack van de server en wordt gebruikt om de server te starten.
- Een client verzendt een aanvraag naar de server.
- Wanneer een aanvraag wordt ontvangen, gaat deze via de WSGI-server en wordt deze vervolgens verzonden naar een van de werknemers.
- Gunicorn wordt gebruikt in Linux.
- Serveertjes worden gebruikt in Windows.
- De aanvragen worden vervolgens verwerkt door een Flask-app , waarmee het invoerscript en eventuele afhankelijkheden worden geladen.
- Ten slotte wordt de aanvraag verzonden naar uw invoerscript. Het invoerscript maakt vervolgens een deductieaanroep naar het geladen model en retourneert een antwoord.
Logboeken begrijpen
Hier beschrijven we logboeken van de HTTP-server voor deductie van Azure Machine Learning. U kunt het logboek ophalen wanneer u het azureml-inference-server-http lokaal uitvoert of containerlogboeken ophalen als u online-eindpunten gebruikt.
Notitie
De indeling voor logboekregistratie is gewijzigd sinds versie 0.8.0. Als u uw logboek in een andere stijl vindt, werkt u het azureml-inference-server-http pakket bij naar de nieuwste versie.
Tip
Als u online-eindpunten gebruikt, begint het logboek van de deductieserver met Azure Machine Learning Inferencing HTTP server <version>.
Opstartlogboeken
Wanneer de server wordt gestart, worden de serverinstellingen als volgt weergegeven door de logboeken:
Azure Machine Learning Inferencing HTTP server <version>
Server Settings
---------------
Entry Script Name: <entry_script>
Model Directory: <model_dir>
Worker Count: <worker_count>
Worker Timeout (seconds): None
Server Port: <port>
Application Insights Enabled: false
Application Insights Key: <appinsights_instrumentation_key>
Inferencing HTTP server version: azmlinfsrv/<version>
CORS for the specified origins: <access_control_allow_origins>
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:<port>/
Score: POST 127.0.0.1:<port>/score
<logs>
Wanneer u bijvoorbeeld de server start, volgt u het end-to-end-voorbeeld:
Azure Machine Learning Inferencing HTTP server v0.8.0
Server Settings
---------------
Entry Script Name: /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
Model Directory: ./
Worker Count: 1
Worker Timeout (seconds): None
Server Port: 5001
Application Insights Enabled: false
Application Insights Key: None
Inferencing HTTP server version: azmlinfsrv/0.8.0
CORS for the specified origins: None
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:5001/
Score: POST 127.0.0.1:5001/score
2022-12-24 07:37:53,318 I [32726] gunicorn.error - Starting gunicorn 20.1.0
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Listening at: http://0.0.0.0:5001 (32726)
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Using worker: sync
2022-12-24 07:37:53,322 I [32756] gunicorn.error - Booting worker with pid: 32756
Initializing logger
2022-12-24 07:37:53,779 I [32756] azmlinfsrv - Starting up app insights client
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Found user script at /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - run() is not decorated. Server will invoke it with the input in JSON string.
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Invoking user's init function
2022-12-24 07:37:55,974 I [32756] azmlinfsrv.user_script - Users's init has completed successfully
2022-12-24 07:37:55,976 I [32756] azmlinfsrv.swagger - Swaggers are prepared for the following versions: [2, 3, 3.1].
2022-12-24 07:37:55,977 I [32756] azmlinfsrv - AML_FLASK_ONE_COMPATIBILITY is set, but patching is not necessary.
Logboekindeling
De logboeken van de deductieserver worden gegenereerd in de volgende indeling, met uitzondering van de startprogrammascripts omdat ze geen deel uitmaken van het Python-pakket:
<UTC Time> | <level> [<pid>] <logger name> - <message>
Hier <pid> volgt de proces-id en <level> is het eerste teken van het logboekregistratieniveau : E voor FOUT, I voor INFO, enzovoort.
Er zijn zes niveaus van logboekregistratie in Python, met getallen die zijn gekoppeld aan ernst:
| Niveau van logboekregistratie | Numerieke waarde |
|---|---|
| KRITIEK | 50 |
| FOUT | 40 |
| WARNING | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
Guide voor probleemoplossing
In deze sectie vindt u basistips voor probleemoplossing voor HTTP-server voor Azure Machine Learning-deductie. Als u problemen met online-eindpunten wilt oplossen, raadpleegt u ook Problemen met online-eindpunten oplossen
Basisstappen
De basisstappen voor het oplossen van problemen zijn:
- Verzamel versiegegevens voor uw Python-omgeving.
- Zorg ervoor dat de python-pakketversie azureml-inference-server-http die is opgegeven in het omgevingsbestand overeenkomt met de Http-serverversie van AzureML die wordt weergegeven in het opstartlogboek. Soms leidt de afhankelijkheidsoplossing van PIP tot onverwachte versies van geïnstalleerde pakketten.
- Als u Flask (en of de bijbehorende afhankelijkheden) opgeeft in uw omgeving, verwijdert u deze. De afhankelijkheden zijn onder andere
Flask,Jinja2,itsdangerous,Werkzeug,MarkupSafeenclick. Flask wordt vermeld als een afhankelijkheid in het serverpakket en het is raadzaam om de server te laten installeren. Op deze manier krijgt u deze automatisch wanneer de server nieuwe versies van Flask ondersteunt.
Serverversie
Het serverpakket azureml-inference-server-http wordt gepubliceerd naar PyPI. U vindt ons wijzigingenlogboek en alle vorige versies op onze PyPI-pagina. Werk bij naar de nieuwste versie als u een eerdere versie gebruikt.
- 0.4.x: De versie die is gebundeld in trainingsafbeeldingen ≤
20220601en inazureml-defaults>=1.34,<=1.43.0.4.13is de laatste stabiele versie. Als u de server vóór de versie0.4.11gebruikt, ziet u mogelijk problemen met Flask-afhankelijkheid, zoals kan de naamMarkupniet worden geïmporteerd.jinja2U wordt aangeraden indien mogelijk een upgrade uit te voeren naar0.4.13of0.8.x(de nieuwste versie). - 0.6.x: De versie die vooraf is geïnstalleerd in deductieinstallatiekopieën ≤ 20220516. De nieuwste stabiele versie is
0.6.1. - 0.7.x: De eerste versie die Flask 2 ondersteunt. De nieuwste stabiele versie is
0.7.7. - 0.8.x: de logboekindeling is gewijzigd en de ondersteuning voor Python 3.6 is verwijderd.
Pakketafhankelijkheden
De meest relevante pakketten voor de server azureml-inference-server-http zijn de volgende pakketten:
- Kolf
- opencensus-ext-azure
- deductieschema
Als u in uw Python-omgeving hebt opgegeven azureml-defaults , is het azureml-inference-server-http pakket afhankelijk van en wordt het automatisch geïnstalleerd.
Tip
Als u Python SDK v1 gebruikt en niet expliciet opgeeft azureml-defaults in uw Python-omgeving, kan de SDK het pakket voor u toevoegen. De SDK wordt echter vergrendeld voor de versie waarop de SDK is ingeschakeld. Als de SDK-versie bijvoorbeeld is 1.38.0, wordt deze toegevoegd aan azureml-defaults==1.38.0 de pip-vereisten van de omgeving.
Veelgestelde vragen
1. Ik heb de volgende fout aangetroffen tijdens het opstarten van de server:
TypeError: register() takes 3 positional arguments but 4 were given
File "/var/azureml-server/aml_blueprint.py", line 251, in register
super(AMLBlueprint, self).register(app, options, first_registration)
TypeError: register() takes 3 positional arguments but 4 were given
U hebt Flask 2 geïnstalleerd in uw Python-omgeving, maar er wordt een versie uitgevoerd azureml-inference-server-http die geen ondersteuning biedt voor Flask 2. Ondersteuning voor Flask 2 wordt toegevoegd azureml-inference-server-http>=0.7.0, ook in azureml-defaults>=1.44.
Als u dit pakket niet gebruikt in een AzureML Docker-installatiekopieën, gebruikt u de nieuwste versie van
azureml-inference-server-httpofazureml-defaults.Als u dit pakket gebruikt met een AzureML Docker-installatiekopie, moet u ervoor zorgen dat u een ingebouwde installatiekopie gebruikt of na juli 2022. De versie van de installatiekopieën is beschikbaar in de containerlogboeken. U moet een logboek kunnen vinden dat er ongeveer als volgt uitziet:
2022-08-22T17:05:02,147738763+00:00 | gunicorn/run | AzureML Container Runtime Information 2022-08-22T17:05:02,161963207+00:00 | gunicorn/run | ############################################### 2022-08-22T17:05:02,168970479+00:00 | gunicorn/run | 2022-08-22T17:05:02,174364834+00:00 | gunicorn/run | 2022-08-22T17:05:02,187280665+00:00 | gunicorn/run | AzureML image information: openmpi4.1.0-ubuntu20.04, Materializaton Build:20220708.v2 2022-08-22T17:05:02,188930082+00:00 | gunicorn/run | 2022-08-22T17:05:02,190557998+00:00 | gunicorn/run |De builddatum van de afbeelding wordt weergegeven na 'Materialization Build', in het bovenstaande voorbeeld,
20220708of 8 juli 2022. Deze installatiekopieën zijn compatibel met Flask 2. Als u geen banner ziet zoals deze in het containerlogboek, is uw installatiekopieën verouderd en moet deze worden bijgewerkt. Als u een CUDA-installatiekopie gebruikt en een nieuwere installatiekopie niet kunt vinden, controleert u of uw installatiekopie is afgeschaft in AzureML-Containers. Als dat het geval is, moet u vervangingen kunnen vinden.Als u de server met een online-eindpunt gebruikt, kunt u de logboeken ook vinden onder Implementatielogboeken op de pagina onlineeindpunt in Azure Machine Learning-studio. Als u implementeert met SDK v1 en geen installatiekopieën expliciet opgeeft in uw implementatieconfiguratie, wordt standaard een versie van
openmpi4.1.0-ubuntu20.04die versie gebruikt die overeenkomt met uw lokale SDK-toolset. Dit is mogelijk niet de meest recente versie van de installatiekopieën. SDK 1.43 wordt bijvoorbeeld standaard gebruiktopenmpi4.1.0-ubuntu20.04:20220616, wat niet compatibel is. Zorg ervoor dat u de nieuwste SDK voor uw implementatie gebruikt.Als u om een of andere reden de installatiekopieën niet kunt bijwerken, kunt u het probleem tijdelijk voorkomen door vast te maken
azureml-defaults==1.43ofazureml-inference-server-http~=0.4.13, waarmee de oudere versieserver wordt geïnstalleerd.Flask 1.0.x
2. Ik heb een ImportError of ModuleNotFoundError meer modulesopencensus, jinja2of MarkupSafeclick tijdens het opstarten aangetroffen, zoals in het volgende bericht:
ImportError: cannot import name 'Markup' from 'jinja2'
Oudere versies (<= 0.4.10) van de server hebben de afhankelijkheid van Flask niet vastgemaakt aan compatibele versies. Dit probleem is opgelost in de nieuwste versie van de server.
Volgende stappen
- Zie Een model implementeren met behulp van Azure Machine Learning voor meer informatie over het maken van een invoerscript en het implementeren van modellen.
- Meer informatie over vooraf gemaakte Docker-installatiekopieën voor deductie