Prestaties bewaken van modellen die zijn geïmplementeerd in productie
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Leer hoe u modelbewaking van Azure Machine Learning gebruikt om continu de prestaties van machine learning-modellen in productie bij te houden. Modelbewaking biedt een breed overzicht van bewakingssignalen en waarschuwingen voor potentiële problemen. Wanneer u signalen en metrische prestatiegegevens van modellen in productie bewaakt, kunt u de inherente risico's die eraan zijn gekoppeld, kritisch evalueren en blinde vlekken identificeren die uw bedrijf nadelig kunnen beïnvloeden.
In dit artikel leert u de volgende taken uit te voeren:
- Out-of-box en geavanceerde bewaking instellen voor modellen die zijn geïmplementeerd op online-eindpunten van Azure Machine Learning
- Prestatiegegevens bewaken voor modellen in productie
- Modellen bewaken die buiten Azure Machine Learning zijn geïmplementeerd of zijn geïmplementeerd in Azure Machine Learning-batcheindpunten
- Modelbewaking instellen met aangepaste signalen en metrische gegevens
- Bewakingsresultaten interpreteren
- Azure Machine Learning-modelbewaking integreren met Azure Event Grid
Vereisten
Voordat u de stappen in dit artikel volgt, moet u ervoor zorgen dat u over de volgende vereisten beschikt:
De Azure CLI en de
mlextensie voor de Azure CLI. Zie De CLI (v2) installeren, instellen en gebruiken voor meer informatie.Belangrijk
In de CLI-voorbeelden in dit artikel wordt ervan uitgegaan dat u de Bash-shell (of compatibele) shell gebruikt. Bijvoorbeeld vanuit een Linux-systeem of Windows-subsysteem voor Linux.
Een Azure Machine Learning-werkruimte. Als u er nog geen hebt, gebruikt u de stappen in de installatie, het instellen en gebruiken van de CLI (v2) om er een te maken.
Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) wordt gebruikt om toegang te verlenen tot bewerkingen in Azure Machine Learning. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de rol eigenaar of inzender voor de Azure Machine Learning-werkruimte zijn toegewezen, of een aangepaste rol die toestaat
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Zie Toegang tot een Azure Machine Learning-werkruimte beheren voor meer informatie.Voor het bewaken van een model dat is geïmplementeerd op een online-eindpunt van Azure Machine Learning (beheerd online-eindpunt of Kubernetes Online-eindpunt), moet u het volgende doen:
Een model al hebt geïmplementeerd op een online-eindpunt van Azure Machine Learning. Zowel het beheerde online-eindpunt als het online-eindpunt van Kubernetes worden ondersteund. Als u geen model hebt geïmplementeerd op een online-eindpunt van Azure Machine Learning, raadpleegt u Een machine learning-model implementeren en beoordelen met behulp van een online-eindpunt.
Gegevensverzameling inschakelen voor uw modelimplementatie. U kunt gegevensverzameling inschakelen tijdens de implementatiestap voor online-eindpunten van Azure Machine Learning. Zie Productiegegevens verzamelen van modellen die zijn geïmplementeerd in een realtime-eindpunt voor meer informatie.
Voor het bewaken van een model dat is geïmplementeerd in een Azure Machine Learning-batcheindpunt of buiten Azure Machine Learning, moet u het volgende doen:
- Een middel hebben om productiegegevens te verzamelen en te registreren als een Azure Machine Learning-gegevensasset.
- Werk de geregistreerde gegevensasset continu bij voor modelbewaking.
- (Aanbevolen) Registreer het model in een Azure Machine Learning-werkruimte voor het bijhouden van herkomst.
Belangrijk
Modelbewakingstaken worden gepland voor uitvoering op serverloze Spark-rekengroepen met ondersteuning voor de volgende TYPEN VM-exemplaren: Standard_E4s_v3, Standard_E8s_v3, Standard_E16s_v3, Standard_E32s_v3en Standard_E64s_v3. U kunt het type VM-exemplaar selecteren met de create_monitor.compute.instance_type eigenschap in uw YAML-configuratie of in de vervolgkeuzelijst in de Azure Machine Learning-studio.
Out-of-box-modelbewaking instellen
Stel dat u uw model implementeert in productie in een online-eindpunt van Azure Machine Learning en gegevensverzameling inschakelt tijdens de implementatie. In dit scenario verzamelt Azure Machine Learning productiedeductiegegevens en slaat deze automatisch op in Microsoft Azure Blob Storage. Vervolgens kunt u Azure Machine Learning-modelbewaking gebruiken om deze productiedeductiegegevens continu te bewaken.
U kunt de Azure CLI, de Python SDK of de studio gebruiken voor een out-of-box-installatie van modelbewaking. De out-of-box-modelbewakingsconfiguratie biedt de volgende bewakingsmogelijkheden:
- Azure Machine Learning detecteert automatisch de productiedeductiegegevensset die is gekoppeld aan een onlineimplementatie van Azure Machine Learning en gebruikt de gegevensset voor modelbewaking.
- De vergelijkingsreferentiegegevensset wordt ingesteld als de recente gegevensset voor productiedeductie in het verleden.
- Het instellen van de bewaking omvat en volgt automatisch de ingebouwde bewakingssignalen: gegevensdrift, voorspellingsdrift en gegevenskwaliteit. Voor elk bewakingssignaal maakt Azure Machine Learning gebruik van:
- de recente, eerdere productiedeductiegegevensset als de vergelijkingsreferentiegegevensset.
- slimme standaardinstellingen voor metrische gegevens en drempelwaarden.
- Er wordt een bewakingstaak gepland om dagelijks om 3:15 uur (in dit voorbeeld) om bewakingssignalen te verkrijgen en elk metrische resultaat te evalueren op basis van de bijbehorende drempelwaarde. Wanneer een drempelwaarde wordt overschreden, verzendt Azure Machine Learning standaard een waarschuwings-e-mail naar de gebruiker die de monitor heeft ingesteld.
Azure Machine Learning-modelbewaking maakt gebruik az ml schedule van het plannen van een bewakingstaak. U kunt de out-of-box modelmonitor maken met de volgende CLI-opdracht en YAML-definitie:
az ml schedule create -f ./out-of-box-monitoring.yaml
De volgende YAML bevat de definitie voor de out-of-box modelbewaking.
# out-of-box-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: credit_default_model_monitoring
display_name: Credit default model monitoring
description: Credit default model monitoring setup with minimal configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute: # specify a spark compute for monitoring job
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification # model task type: [classification, regression, question_answering]
endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id
alert_notification: # emails to get alerts
emails:
- abc@example.com
- def@example.com


Geavanceerde modelbewaking instellen
Azure Machine Learning biedt veel mogelijkheden voor continue modelbewaking. Zie Mogelijkheden voor modelbewaking voor een uitgebreide lijst met deze mogelijkheden. In veel gevallen moet u modelbewaking instellen met geavanceerde bewakingsmogelijkheden. In de volgende secties stelt u modelbewaking in met deze mogelijkheden:
- Gebruik van meerdere bewakingssignalen voor een breed overzicht.
- Gebruik van historische modeltrainingsgegevens of validatiegegevens als de vergelijkingsreferentiegegevensset.
- Bewaking van de belangrijkste N-functies en afzonderlijke functies.
Urgentie van functies configureren
Het belang van functies vertegenwoordigt het relatieve belang van elke invoerfunctie voor de uitvoer van een model. Kan bijvoorbeeld temperature belangrijker zijn voor de voorspelling van een model in vergelijking met elevation. Het inschakelen van het belang van functies kan u inzicht geven in welke functies u niet wilt driften of problemen met de gegevenskwaliteit in productie wilt hebben.
Als u het belang van functies wilt inschakelen met een van uw signalen (zoals gegevensdrift of gegevenskwaliteit), moet u het volgende opgeven:
- Uw trainingsgegevensset als de
reference_datagegevensset. - De
reference_data.data_column_names.target_columneigenschap, de naam van de uitvoer-/voorspellingskolom van uw model.
Nadat u het belang van functies hebt ingeschakeld, ziet u een functie-urgentie voor elke functie die u bewaakt in de gebruikersinterface van het Azure Machine Learning-modelbewakingsstudio.
U kunt Azure CLI, de Python SDK of de studio gebruiken voor geavanceerde configuratie van modelbewaking.
Maak geavanceerde configuratie van modelbewaking met de volgende CLI-opdracht en YAML-definitie:
az ml schedule create -f ./advanced-model-monitoring.yaml
De volgende YAML bevat de definitie voor geavanceerde modelbewaking.
# advanced-model-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with advanced configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:credit-default:main
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1 # use training data as comparison reference dataset
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
features:
top_n_feature_importance: 10 # monitor drift for top 10 features
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_data_quality:
type: data_quality
# reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
features: # monitor data quality for 3 individual features only
- SEX
- EDUCATION
metric_thresholds:
numerical:
null_value_rate: 0.05
categorical:
out_of_bounds_rate: 0.03
feature_attribution_drift_signal:
type: feature_attribution_drift
# production_data: is not required input here
# Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data
# Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
metric_thresholds:
normalized_discounted_cumulative_gain: 0.9
alert_notification:
emails:
- abc@example.com
- def@example.com






Bewaking van modelprestaties instellen
Met azure Machine Learning-modelbewaking kunt u de prestaties van uw modellen in productie bijhouden door hun prestatiegegevens te berekenen. De volgende metrische gegevens over modelprestaties worden momenteel ondersteund:
Voor classificatiemodellen:
- Precisie
- Nauwkeurigheid
- Intrekken
Voor regressiemodellen:
- Gemiddelde absolute fout (MAE)
- Gemiddelde kwadratische fout (MSE)
- Wortel van gemiddelde kwadratische fout (RMSE)
Meer vereisten voor het bewaken van modelprestaties
U moet voldoen aan de volgende vereisten om uw modelprestatiesignaal te configureren:
Uitvoergegevens hebben voor het productiemodel (de voorspellingen van het model) met een unieke id voor elke rij. Als u productiegegevens verzamelt met de Azure Machine Learning-gegevensverzamelaar, wordt er een
correlation_idgegeven voor elke deductieaanvraag voor u. Met de gegevensverzamelaar hebt u ook de mogelijkheid om uw eigen unieke id van uw toepassing te registreren.Notitie
Voor prestatiebewaking van Azure Machine Learning-modellen raden we u aan om uw unieke id in een eigen kolom te registreren met behulp van de Azure Machine Learning-gegevensverzamelaar.
Gegevens over grondwaar (werkelijke waarden) hebben met een unieke id voor elke rij. De unieke id voor een bepaalde rij moet overeenkomen met de unieke id voor de modeluitvoer voor die specifieke deductieaanvraag. Deze unieke id wordt gebruikt om uw gegevensset met de grondwaargegevensset samen te voegen met de modeluitvoer.
Zonder grond waarheidsgegevens te hebben, kunt u geen bewaking van modelprestaties uitvoeren. Omdat er op toepassingsniveau waarheidsgegevens worden aangetroffen, is het uw verantwoordelijkheid om deze te verzamelen zodra deze beschikbaar is. U moet ook een gegevensasset in Azure Machine Learning onderhouden die deze grondwaargegevens bevat.
(Optioneel) U hebt een vooraf gekoppelde gegevensset in tabelvorm met modeluitvoer en gegevens over grondwaargegevens die al aan elkaar zijn gekoppeld.
Prestatievereisten voor modellen bewaken bij het gebruik van gegevensverzamelaar
Als u de Azure Machine Learning-gegevensverzamelaar gebruikt om productiedeductiegegevens te verzamelen zonder uw eigen unieke id voor elke rij als een afzonderlijke kolom op te geven, wordt een correlationid automatisch gegenereerd voor u en opgenomen in het vastgelegde JSON-object. De gegevensverzamelaar voert echter batchrijen in batches uit die binnen korte tijdsintervallen van elkaar worden verzonden . Batchrijen vallen binnen hetzelfde JSON-object en hebben dus hetzelfde correlationid.
Om onderscheid te maken tussen de rijen in hetzelfde JSON-object, maakt de prestatiebewaking van het Azure Machine Learning-model gebruik van indexering om de volgorde van de rijen in het JSON-object te bepalen. Als bijvoorbeeld drie rijen samen worden gebatcheerd en de correlationid is, heeft rij één een id vantest_0, rij twee heeft een id van test_1en rij drie heeft een id van test_2test. Om ervoor te zorgen dat uw gegevensset voor de grondwaargegevens unieke id's bevat die overeenkomen met de uitvoer van het verzamelde productiedeductiemodel, moet u ervoor zorgen dat u elk gegevensset op de correlationid juiste wijze indexeert. Als uw vastgelegde JSON-object slechts één rij heeft, is dat correlationid het volgende correlationid_0.
Om te voorkomen dat u deze indexering gebruikt, wordt u aangeraden uw unieke id in een eigen kolom in het Pandas DataFrame te registreren dat u zich aanmeldt met de Azure Machine Learning-gegevensverzamelaar. Vervolgens geeft u in uw configuratie voor modelbewaking de naam van deze kolom op om de uitvoergegevens van uw model te koppelen aan uw gegevens over de waarheid. Zolang de id's voor elke rij in beide gegevenssets hetzelfde zijn, kan azure Machine Learning-modelbewaking modelprestaties bewaken.
Voorbeeldwerkstroom voor het bewaken van modelprestaties
Bekijk deze voorbeeldwerkstroom om inzicht te hebben in de concepten die zijn gekoppeld aan de bewaking van modelprestaties. Stel dat u een model implementeert om te voorspellen of creditcardtransacties frauduleus zijn of niet, u kunt deze stappen volgen om de prestaties van het model te bewaken:
- Configureer uw implementatie om de gegevensverzamelaar te gebruiken om de productiedeductiegegevens van het model te verzamelen (invoer- en uitvoergegevens). Stel dat de uitvoergegevens worden opgeslagen in een kolom
is_fraud. - Registreer voor elke rij van de verzamelde deductiegegevens een unieke id. De unieke id kan afkomstig zijn van uw toepassing of u kunt de
correlationidunieke id van Azure Machine Learning gebruiken voor elk geregistreerd JSON-object. - Later, wanneer de grondwaar (of de werkelijke)
is_fraudgegevens beschikbaar komen, worden ze ook geregistreerd en toegewezen aan dezelfde unieke id die is vastgelegd met de uitvoer van het model. - Deze grondwaargegevens
is_fraudworden ook verzameld, onderhouden en geregistreerd bij Azure Machine Learning als gegevensasset. - Maak een signaal voor de bewaking van modelprestaties waarmee de productiedeductie en de grondwaargegevensassets van het model worden samengevoegd met behulp van de unieke id-kolommen.
- Bereken ten slotte de metrische gegevens over de prestaties van het model.
Zodra u aan de vereisten voor modelprestatiebewaking hebt voldaan, kunt u modelbewaking instellen met de volgende CLI-opdracht en YAML-definitie:
az ml schedule create -f ./model-performance-monitoring.yaml
De volgende YAML bevat de definitie voor modelbewaking met productiedeductiegegevens die u hebt verzameld.
$schema: http://azureml/sdk-2-0/Schedule.json
name: model_performance_monitoring
display_name: Credit card fraud model performance
description: Credit card fraud model performance
trigger:
type: recurrence
frequency: day
interval: 7
schedule:
hours: 10
minutes: 15
create_monitor:
compute:
instance_type: standard_e8s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment
monitoring_signals:
fraud_detection_model_performance:
type: model_performance
production_data:
data_column_names:
prediction: is_fraud
correlation_id: correlation_id
reference_data:
input_data:
path: azureml:my_model_ground_truth_data:1
type: mltable
data_column_names:
actual: is_fraud
correlation_id: correlation_id
data_context: actuals
alert_enabled: true
metric_thresholds:
tabular_classification:
accuracy: 0.95
precision: 0.8
alert_notification:
emails:
- abc@example.com





Modelbewaking instellen door uw productiegegevens naar Azure Machine Learning te brengen
U kunt ook modelbewaking instellen voor modellen die zijn geïmplementeerd in Azure Machine Learning-batcheindpunten of buiten Azure Machine Learning worden geïmplementeerd. Als u geen implementatie hebt, maar wel productiegegevens hebt, kunt u de gegevens gebruiken om continue modelbewaking uit te voeren. Als u deze modellen wilt bewaken, moet u het volgende kunnen doen:
- Verzamel productiedeductiegegevens van modellen die in productie zijn geïmplementeerd.
- Registreer de productiedeductiegegevens als een Azure Machine Learning-gegevensasset en zorg ervoor dat de gegevens continu worden bijgewerkt.
- Geef een aangepast gegevensvoorverwerkingsonderdeel op en registreer het als een Azure Machine Learning-onderdeel.
U moet een aangepast gegevensvoorverwerkingsonderdeel opgeven als uw gegevens niet worden verzameld met de gegevensverzamelaar. Zonder dit aangepaste voorverwerkingsonderdeel voor gegevens weet het bewakingssysteem van het Azure Machine Learning-model niet hoe u uw gegevens in tabelvorm verwerkt met ondersteuning voor tijdvensters.
Uw aangepaste voorverwerkingsonderdeel moet deze invoer- en uitvoerhandtekeningen hebben:
| Invoer/uitvoer | Handtekeningnaam | Type | Description | Voorbeeldwaarde |
|---|---|---|---|---|
| input | data_window_start |
letterlijk, tekenreeks | begintijd van het gegevensvenster in ISO8601 indeling. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
letterlijk, tekenreeks | eindtijd van het gegevensvenster in ISO8601 indeling. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | De verzamelde productiedeductiegegevens, die zijn geregistreerd als een Azure Machine Learning-gegevensasset. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Een tabellaire gegevensset die overeenkomt met een subset van het referentiegegevensschema. |
Zie custom_preprocessing in de GitHub-opslagplaats met azuremml-voorbeelden voor een voorbeeld van een aangepast gegevensvoorverwerkingsonderdeel.
Zodra u aan de vorige vereisten hebt voldaan, kunt u modelbewaking instellen met de volgende CLI-opdracht en YAML-definitie:
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
De volgende YAML bevat de definitie voor modelbewaking met productiedeductiegegevens die u hebt verzameld.
# model-monitoring-with-collected-data.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with your own production data
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_inputs
pre_processing_component: azureml:production_data_preprocessing:1
reference_data:
input_data:
path: azureml:my_model_training_data:1 # use training data as comparison baseline
type: mltable
data_context: training
data_column_names:
target_column: is_fraud
features:
top_n_feature_importance: 20 # monitor drift for top 20 features
metric_thresholds:
numberical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_prediction_drift: # monitoring signal name, any user defined name works
type: prediction_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_outputs
pre_processing_component: azureml:production_data_preprocessing:1
reference_data:
input_data:
path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset
type: mltable
data_context: validation
metric_thresholds:
categorical:
pearsons_chi_squared_test: 0.02
alert_notification:
emails:
- abc@example.com
- def@example.com
Modelbewaking instellen met aangepaste signalen en metrische gegevens
Met bewaking van Azure Machine Learning-modellen kunt u een aangepast signaal definiëren en eventuele metrische gegevens van uw keuze implementeren om uw model te bewaken. U kunt dit aangepaste signaal registreren als een Azure Machine Learning-onderdeel. Wanneer de bewakingstaak van uw Azure Machine Learning-model volgens de opgegeven planning wordt uitgevoerd, worden de metrische gegevens berekend die u hebt gedefinieerd binnen uw aangepaste signaal, net zoals voor de vooraf gedefinieerde signalen (gegevensdrift, voorspellingsdrift en gegevenskwaliteit).
Als u een aangepast signaal wilt instellen voor modelbewaking, moet u eerst het aangepaste signaal definiëren en registreren als een Azure Machine Learning-onderdeel. Het Azure Machine Learning-onderdeel moet deze invoer- en uitvoerhandtekeningen hebben:
Handtekening voor onderdeelinvoer
Het DataFrame voor onderdeelinvoer moet de volgende items bevatten:
- Een
mltablemet de verwerkte gegevens uit het voorverwerkingsonderdeel - Elk aantal letterlijke waarden, elk dat een geïmplementeerde metriek vertegenwoordigt als onderdeel van het aangepaste signaalonderdeel. Als u bijvoorbeeld de metrische waarde hebt geïmplementeerd,
std_deviationhebt u een invoer nodig voorstd_deviation_threshold. Over het algemeen moet er één invoer per metrische waarde zijn met de naam<metric_name>_threshold.
| Handtekeningnaam | Type | Description | Voorbeeldwaarde |
|---|---|---|---|
| production_data | mltable | Een tabellaire gegevensset die overeenkomt met een subset van het referentiegegevensschema. | |
| std_deviation_threshold | letterlijk, tekenreeks | Respectieve drempelwaarde voor de geïmplementeerde metrische gegevens. | 2 |
Handtekening voor onderdeeluitvoer
De uitvoerpoort van het onderdeel moet de volgende handtekening hebben.
| Handtekeningnaam | Type | Description |
|---|---|---|
| signal_metrics | mltable | De mltable die de berekende metrische gegevens bevat. Het schema wordt gedefinieerd in de volgende sectie signal_metrics schema. |
signal_metrics schema
Het dataframe van de componentuitvoer moet vier kolommen bevatten: group, metric_name, metric_valueen threshold_value.
| Handtekeningnaam | Type | Description | Voorbeeldwaarde |
|---|---|---|---|
| groeperen | letterlijk, tekenreeks | Logische groepering op het hoogste niveau die moet worden toegepast op deze aangepaste metrische gegevens. | TRANSACTIONAMOUNT |
| metric_name | letterlijk, tekenreeks | De naam van de aangepaste metrische waarde. | std_deviation |
| metric_value | Numerieke | De waarde van de aangepaste metrische waarde. | 44,896.082 |
| threshold_value | Numerieke | De drempelwaarde voor de aangepaste metrische gegevens. | 2 |
In de volgende tabel ziet u een voorbeelduitvoer van een aangepast signaalonderdeel waarmee de std_deviation metrische gegevens worden berekend:
| groeperen | metric_value | metric_name | threshold_value |
|---|---|---|---|
| TRANSACTIONAMOUNT | 44,896.082 | std_deviation | 2 |
| LOCALHOUR | 3.983 | std_deviation | 2 |
| TRANSACTIONAMOUNT GATEWAY | 54,004.902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| PHYSICALITEMCOUNT | 5.509 | std_deviation | 2 |
Zie custom_signal in de opslagplaats azureml-examples voor een voorbeeld van een aangepaste definitie van het signaalonderdeel en de metrische rekencode.
Zodra u aan de vereisten voor het gebruik van aangepaste signalen en metrische gegevens hebt voldaan, kunt u modelbewaking instellen met de volgende CLI-opdracht en YAML-definitie:
az ml schedule create -f ./custom-monitoring.yaml
De volgende YAML bevat de definitie voor modelbewaking met een aangepast signaal. Enkele dingen die u moet zien over de code:
- Hierbij wordt ervan uitgegaan dat u uw onderdeel al hebt gemaakt en geregistreerd met de aangepaste signaaldefinitie in Azure Machine Learning.
- Het
component_idgeregistreerde aangepaste signaalonderdeel isazureml:my_custom_signal:1.0.0. - Als u uw gegevens hebt verzameld met de gegevensverzamelaar, kunt u de
pre_processing_componenteigenschap weglaten. Als u een voorverwerkingsonderdeel wilt gebruiken om productiegegevens vooraf te verwerken die niet door de gegevensverzamelaar worden verzameld, kunt u dit opgeven.
# custom-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: my-custom-signal
trigger:
type: recurrence
frequency: day # can be minute, hour, day, week, month
interval: 7 # #every day
create_monitor:
compute:
instance_type: "standard_e4s_v3"
runtime_version: "3.3"
monitoring_signals:
customSignal:
type: custom
component_id: azureml:my_custom_signal:1.0.0
input_data:
production_data:
input_data:
type: uri_folder
path: azureml:my_production_data:1
data_context: test
data_window:
lookback_window_size: P30D
lookback_window_offset: P7D
pre_processing_component: azureml:custom_preprocessor:1.0.0
metric_thresholds:
- metric_name: std_deviation
threshold: 2
alert_notification:
emails:
- abc@example.com
Bewakingsresultaten interpreteren
Nadat u de modelmonitor hebt geconfigureerd en de eerste uitvoering is voltooid, kunt u teruggaan naar het tabblad Bewaking in Azure Machine Learning-studio om de resultaten weer te geven.
Selecteer in de hoofdweergave Bewaking de naam van uw modelmonitor om de overzichtspagina van Monitor weer te geven. Op deze pagina ziet u het bijbehorende model, eindpunt en implementatie, samen met details over de signalen die u hebt geconfigureerd. In de volgende afbeelding ziet u een bewakingsdashboard met gegevensdrift- en gegevenskwaliteitssignalen. Afhankelijk van de bewakingssignalen die u hebt geconfigureerd, kan uw dashboard er anders uitzien.
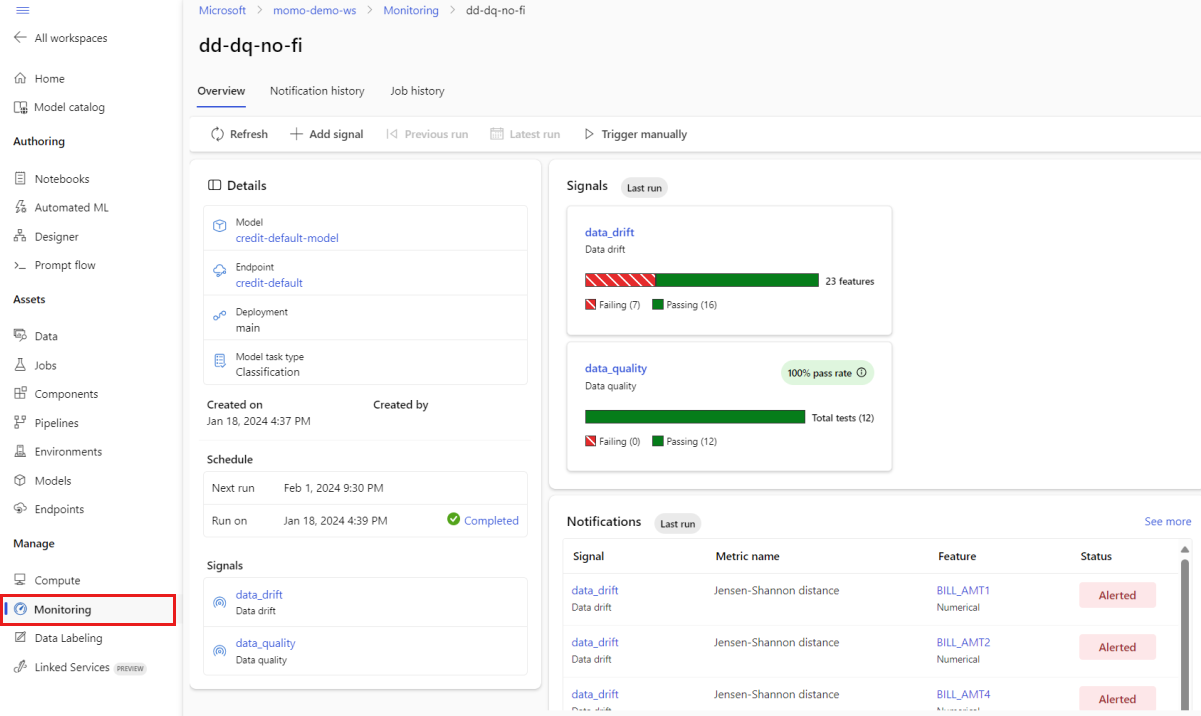
Kijk in de sectie Meldingen van het dashboard om voor elk signaal te zien dat de geconfigureerde drempelwaarde voor hun respectieve metrische gegevens is overschreden:
Selecteer de data_drift om naar de gegevensdriftpagina te gaan. Op de detailpagina ziet u de metrische waarde voor gegevensdrift voor elke numerieke en categorische functie die u hebt opgenomen in uw bewakingsconfiguratie. Wanneer uw monitor meer dan één uitvoering heeft, ziet u een trendlijn voor elke functie.
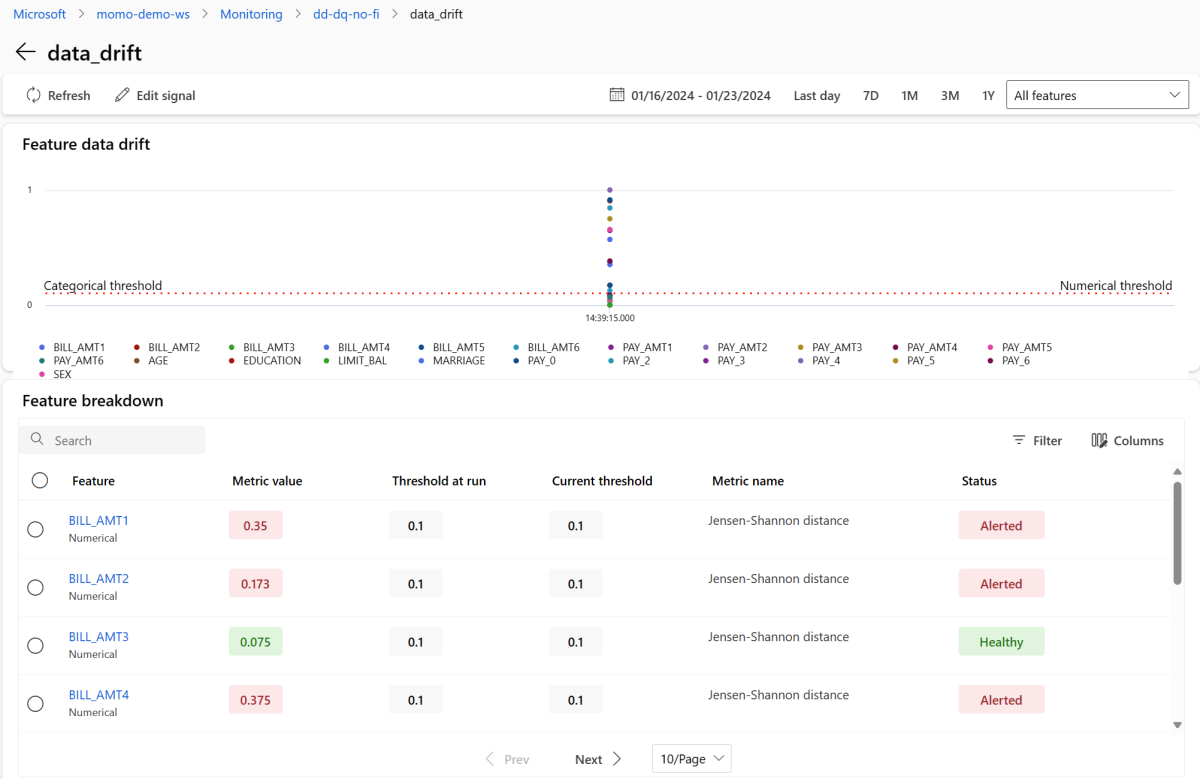
Als u een afzonderlijke functie in detail wilt weergeven, selecteert u de naam van de functie om de productiedistributie weer te geven in vergelijking met de verwijzingsdistributie. Met deze weergave kunt u ook drift in de loop van de tijd bijhouden voor die specifieke functie.

Ga terug naar het bewakingsdashboard en selecteer data_quality om de gegevenskwaliteitssignaalpagina weer te geven. Op deze pagina ziet u de null-waardepercentages, de frequenties buiten de grenzen en de foutpercentages van het gegevenstype voor elke functie die u bewaakt.





Modelbewaking is een continu proces. Met bewaking van Azure Machine Learning-modellen kunt u meerdere bewakingssignalen configureren om een breed overzicht te krijgen van de prestaties van uw modellen in productie.
Azure Machine Learning-modelbewaking integreren met Azure Event Grid
U kunt gebeurtenissen die worden gegenereerd door azure Machine Learning-modelbewaking gebruiken om gebeurtenisgestuurde toepassingen, processen of CI/CD-werkstromen in te stellen met Azure Event Grid. U kunt gebeurtenissen gebruiken via verschillende gebeurtenis-handlers, zoals Azure Event Hubs, Azure-functies en logische apps. Op basis van de drift die door uw monitors is gedetecteerd, kunt u programmatisch actie ondernemen, bijvoorbeeld door een machine learning-pijplijn in te stellen om een model opnieuw te trainen en het opnieuw te implementeren.
Ga als volgt te werk om aan de slag te gaan met het integreren van Bewaking van Azure Machine Learning-modellen met Event Grid:
Volg de stappen in Instellen in Azure Portal. Geef uw gebeurtenisabonnement een naam, zoals MonitoringEvent, en selecteer alleen het vak Uitvoeringsstatus gewijzigd onder Gebeurtenistypen.
Waarschuwing
Zorg ervoor dat u de status Uitvoeren selecteert die is gewijzigd voor het gebeurtenistype. Selecteer geen gegevenssetdrift gedetecteerd, omdat deze van toepassing is op gegevensdrift v1, in plaats van bewaking van Azure Machine Learning-modellen.
Volg de stappen in Filteren en abonneren op gebeurtenissen om gebeurtenisfiltering in te stellen voor uw scenario. Navigeer naar het tabblad Filters en voeg de volgende sleutel, operator en waarde toe onder Geavanceerde filters:
- Sleutel:
data.RunTags.azureml_modelmonitor_threshold_breached - Waarde: is mislukt vanwege een of meer functies die de metrische drempelwaarden schenden
- Operator: tekenreeks bevat
Met dit filter worden gebeurtenissen gegenereerd wanneer de uitvoeringsstatus verandert (van Voltooid naar Mislukt of van Mislukt naar Voltooid) voor elke monitor in uw Azure Machine Learning-werkruimte.
- Sleutel:
Als u wilt filteren op het bewakingsniveau, gebruikt u de volgende sleutel, operator en waarde onder Geavanceerde filters:
- Sleutel:
data.RunTags.azureml_modelmonitor_threshold_breached - Waarde:
your_monitor_name_signal_name - Operator: tekenreeks bevat
Zorg ervoor dat dit
your_monitor_name_signal_namede naam is van een signaal in de specifieke monitor waarvoor u gebeurtenissen wilt filteren. Bijvoorbeeld:credit_card_fraud_monitor_data_drift. Dit filter werkt alleen als deze tekenreeks overeenkomt met de naam van het bewakingssignaal. U moet uw signaal een naam geven met zowel de monitornaam als de signaalnaam voor dit geval.- Sleutel:
Wanneer u de configuratie van uw gebeurtenisabonnement hebt voltooid, selecteert u het gewenste eindpunt dat moet fungeren als uw gebeurtenis-handler, zoals Azure Event Hubs.
Nadat gebeurtenissen zijn vastgelegd, kunt u deze bekijken vanaf de eindpuntpagina:
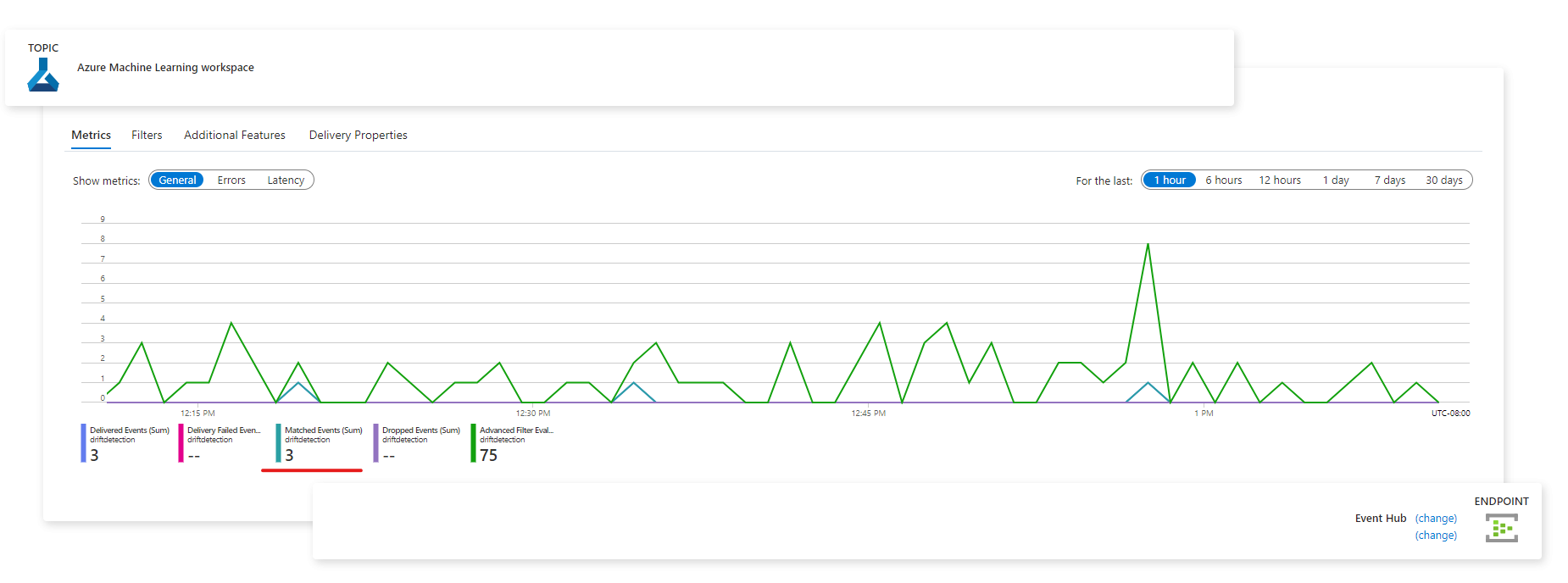

U kunt ook gebeurtenissen bekijken op het tabblad Metrische gegevens van Azure Monitor:
