K-means-clustering
Belangrijk
De ondersteuning voor Azure Machine Learning-studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden om vóór die datum over te stappen naar Azure Machine Learning.
Vanaf 1 december 2021 kunt u geen nieuwe resources voor Azure Machine Learning-studio (klassiek) meer maken. Tot en met 31 augustus 2024 kunt u de bestaande resources van Azure Machine Learning-studio (klassiek) blijven gebruiken.
- Zie informatie over het verplaatsen van machine learning-projecten van ML Studio (klassiek) naar Azure Machine Learning.
- Meer informatie over Azure Machine Learning.
De documentatie van ML-studio (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet meer bijgewerkt.
Configureert en initialiseert een K-means-clusteringmodel
Categorie: Machine Learning/Model initialiseren/Clustering
Notitie
Van toepassing op: alleen Machine Learning Studio (klassiek)
Vergelijkbare modules voor slepen en neerzetten zijn beschikbaar in de Azure Machine Learning-ontwerpfunctie.
Moduleoverzicht
In dit artikel wordt beschreven hoe u de module K-Means Clustering in Machine Learning Studio (klassiek) gebruikt om een niet-getraind K-means-clusteringmodel te maken.
K-means is een van de eenvoudigste en bekendste leeralgoritmen zonder supervisie en kan worden gebruikt voor diverse machine learning-taken, zoals het detecteren van abnormale gegevens, het clusteren van tekstdocumenten en het analyseren van een gegevensset voordat andere classificatie- of regressiemethoden worden gebruikt. Als u een clusteringmodel wilt maken, voegt u deze module toe aan uw experiment, verbindt u een gegevensset en stelt u parameters in, zoals het aantal clusters dat u verwacht, de afstandsmetrieken die moeten worden gebruikt bij het maken van de clusters, enzovoort.
Nadat u de hyperparameters van de module hebt geconfigureerd, verbindt u het niet-getrainde model met de modules Clusteringmodel trainen of Opruimen clustering om het model te trainen op de invoergegevens die u opgeeft. Omdat het K-means-algoritme een leermethode zonder supervisie is, is een labelkolom optioneel.
- Als uw gegevens een label bevatten, kunt u de labelwaarden gebruiken om de selectie van de clusters te begeleiden en het model te optimaliseren.
- Als uw gegevens geen label hebben, maakt het algoritme clusters die mogelijke categorieën vertegenwoordigen, uitsluitend op basis van de gegevens.
Tip
Als uw trainingsgegevens labels bevatten, kunt u overwegen een van de classificatiemethoden onder supervisie in Machine Learning te gebruiken. U kunt bijvoorbeeld de resultaten van clustering vergelijken met de resultaten wanneer u een van de beslissingsstructuuralgoritmen met meerdere klassen gebruikt.
Inzicht in k-means-clustering
In het algemeen maakt clustering gebruik van iteratieve technieken om cases in een gegevensset te groeperen in clusters die vergelijkbare kenmerken bevatten. Deze groeperingen zijn handig voor het verkennen van gegevens, het identificeren van afwijkingen in de gegevens en uiteindelijk voor het maken van voorspellingen. Clusteringmodellen kunnen u ook helpen bij het identificeren van relaties in een gegevensset die u mogelijk niet logisch kunt afleiden door te bladeren of eenvoudige observatie. Daarom wordt clustering vaak gebruikt in de eerste fasen van machine learning-taken, om de gegevens te verkennen en onverwachte correlaties te detecteren.
Wanneer u een clusteringmodel configureert met behulp van de methode k-means, moet u een doelnummer k opgeven dat het aantal zwaartepunten aangeeft dat u in het model wilt gebruiken. Het zwaartepunt is een punt dat representatief is voor elk cluster. Het K-means-algoritme wijst elk binnenkomend gegevenspunt toe aan een van de clusters door de som van kwadraten binnen het cluster te minimaliseren.
Bij het verwerken van de trainingsgegevens begint het K-means-algoritme met een initiële set willekeurig gekozen zwaartepunten, die als uitgangspunt voor elk cluster dienen, en past lloyd's algoritme toe om de locaties van de zwaartepunten iteratief te verfijnen. Het K-means-algoritme stopt met het bouwen en verfijnen van clusters wanneer het voldoet aan een of meer van de volgende voorwaarden:
De zwaartepunten stabiliseren, wat betekent dat clustertoewijzingen voor afzonderlijke punten niet meer veranderen en het algoritme is geconvergeerd op een oplossing.
Het algoritme is voltooid met het uitvoeren van het opgegeven aantal iteraties.
Nadat u de trainingsfase hebt voltooid, gebruikt u de module Gegevens toewijzen aan clusters om nieuwe cases toe te wijzen aan een van de clusters die door het k-means-algoritme zijn gevonden. Clustertoewijzing wordt uitgevoerd door de afstand tussen de nieuwe case en het zwaartepunt van elk cluster te berekenen. Elke nieuwe case wordt toegewezen aan het cluster met het dichtstbijzijnde zwaartepunt.
K-Means-clustering configureren
Voeg de module K-Means Clustering toe aan uw experiment.
Geef op hoe u het model wilt trainen door de optie Trainermodus maken in te stellen.
Enkele parameter: als u de exacte parameters kent die u in het clusteringmodel wilt gebruiken, kunt u een specifieke set waarden opgeven als argumenten.
Parameterbereik: als u niet zeker bent van de beste parameters, kunt u de optimale parameters vinden door meerdere waarden op te geven en de module Sweep Clustering te gebruiken om de optimale configuratie te vinden.
De trainer herhaalt meerdere combinaties van de instellingen die u hebt opgegeven en bepaalt de combinatie van waarden die de optimale clusteringresultaten oplevert.
Bij Aantal centroids typt u het aantal clusters waarmee het algoritme moet beginnen.
Het is niet gegarandeerd dat het model precies dit aantal clusters produceert. De algorithn begint met dit aantal gegevenspunten en herhaalt om de optimale configuratie te vinden, zoals beschreven in de sectie Technische opmerkingen .
Als u een parameter-sweep uitvoert, verandert de naam van de eigenschap in Bereik voor Aantal zwaartepunten. U kunt de Opbouwfunctie voor bereiken gebruiken om een bereik op te geven of u kunt een reeks getallen typen die verschillende aantallen clusters vertegenwoordigen die moeten worden gemaakt bij het initialiseren van elk model.
De eigenschappen Initialisatie of Initialisatie voor opruimen worden gebruikt om het algoritme op te geven dat wordt gebruikt om de eerste clusterconfiguratie te definiëren.
Eerste N: Een bepaald beginaantal gegevenspunten wordt gekozen uit de gegevensset en gebruikt als het eerste middel.
Ook wel de Forgy-methode genoemd.
Willekeurig: het algoritme plaatst willekeurig een gegevenspunt in een cluster en berekent vervolgens het aanvankelijke gemiddelde als het zwaartepunt van de willekeurig toegewezen punten van het cluster.
Ook wel de methode willekeurige partitie genoemd.
K-Means++: dit is de standaardmethode voor het initialiseren van clusters.
Het K-means++ algoritme werd in 2007 voorgesteld door David Arthur en Sergei Vassilvitskii om slechte clustering door het standaard k-means algoritme te voorkomen. K-means ++ verbetert de standaard-K-middelen door een andere methode te gebruiken voor het kiezen van de eerste clustercentra.
K-Means++Fast: een variant van het algoritme K-means ++ dat is geoptimaliseerd voor snellere clustering.
Gelijkmatig: centroïden bevinden zich op gelijke afstand van elkaar in de d-dimensionale ruimte van n-gegevenspunten.
Labelkolom gebruiken: de waarden in de labelkolom worden gebruikt om de selectie van zwaartepunten te begeleiden.
Typ bij Seed voor willekeurige getallen desgewenst een waarde die moet worden gebruikt als seed voor de cluster initialisatie. Deze waarde kan een aanzienlijk effect hebben op de clusterselectie.
Als u een parameter sweep gebruikt, kunt u opgeven dat er meerdere initiële zaden moeten worden gemaakt om te zoeken naar de beste beginwaarde voor het zaad. Typ bij Aantal te vegen zaden het totale aantal willekeurige zaadwaarden dat als beginpunt moet worden gebruikt.
Kies voor Metrisch de functie die moet worden gebruikt voor het meten van de afstand tussen clustervectoren of tussen nieuwe gegevenspunten en het willekeurig gekozen zwaartepunt. Machine Learning ondersteunt de volgende metrische gegevens over de clusterafstand:
Euclidisch: De Euclidische afstand wordt vaak gebruikt als een meting van clusterspreiding voor K-means-clustering. Deze metrische waarde heeft de voorkeur omdat hiermee de gemiddelde afstand tussen punten en de zwaartepunten wordt geminimaliseerd.
Cosinus: de cosinusfunctie wordt gebruikt om de gelijkenis van clusters te meten. Cosinus-gelijkenis is handig in gevallen waarin u niet om de lengte van een vector geeft, alleen de hoek.
Voor Iteraties typt u het aantal keren dat het algoritme de trainingsgegevens moet herhalen voordat de selectie van zwaartepunten wordt voltooid.
U kunt deze parameter aanpassen om een balans te vinden tussen nauwkeurigheid en trainingstijd.
Kies voor de modus Label toewijzen een optie die aangeeft hoe een labelkolom, indien aanwezig in de gegevensset, moet worden verwerkt.
Omdat K-means-clustering een machine learning-methode zonder supervisie is, zijn labels optioneel. Als uw gegevensset echter al een labelkolom heeft, kunt u deze waarden gebruiken om de selectie van de clusters te begeleiden of kunt u opgeven dat de waarden worden genegeerd.
Labelkolom negeren: de waarden in de labelkolom worden genegeerd en worden niet gebruikt bij het bouwen van het model.
Ontbrekende waarden invullen: de labelkolomwaarden worden gebruikt als functies voor het bouwen van de clusters. Als een label ontbreekt in rijen, wordt de waarde toegerekend met behulp van andere functies.
Overschrijven van het dichtst bij het midden: de labelkolomwaarden worden vervangen door voorspelde labelwaarden, met behulp van het label van het punt dat zich het dichtst bij het huidige zwaartepunt bevindt.
Het model trainen.
Als u de modus Trainer maken instelt op Enkele parameter, voegt u een getagde gegevensset toe en traint u het model met behulp van de module Clusteringmodel trainen .
Als u de modus Trainer maken instelt op Parameterbereik, voegt u een getagde gegevensset toe en traint u het model met behulp van Sweep Clustering. U kunt het model gebruiken dat is getraind met behulp van deze parameters, of u kunt de parameterinstellingen noteren die moeten worden gebruikt bij het configureren van een cursist.
Resultaten
Nadat u klaar bent met het configureren en trainen van het model, hebt u een model dat u kunt gebruiken om scores te genereren. Er zijn echter meerdere manieren om het model te trainen en meerdere manieren om de resultaten weer te geven en te gebruiken:
Een momentopname van het model vastleggen in uw werkruimte
Als u de module Clusteringmodel trainen hebt gebruikt
- Klik met de rechtermuisknop op de module Clusteringmodel trainen .
- Selecteer Getraind model en klik vervolgens op Opslaan als getraind model.
Als u de module Sweep Clustering hebt gebruikt om het model te trainen
- Klik met de rechtermuisknop op de module Sweep Clustering .
- Selecteer Het best getrainde model en klik vervolgens op Opslaan als getraind model.
Het opgeslagen model vertegenwoordigt de trainingsgegevens op het moment dat u het model hebt opgeslagen. Als u later de trainingsgegevens bijwerkt die in het experiment worden gebruikt, wordt het opgeslagen model niet bijgewerkt.
Een visuele weergave van de clusters in het model bekijken
Als u de module Clusteringmodel trainen hebt gebruikt
- Klik met de rechtermuisknop op de module en selecteer Resultatengegevensset.
- Selecteer Visualiseren.
Als u de module Clustering opruimen hebt gebruikt
Voeg een exemplaar van de module Gegevens toewijzen aan clusters toe en genereer scores met behulp van het best getrainde model.
Klik met de rechtermuisknop op de module Gegevens toewijzen aan clusters , selecteer resultatengegevensset en selecteer Visualiseren.
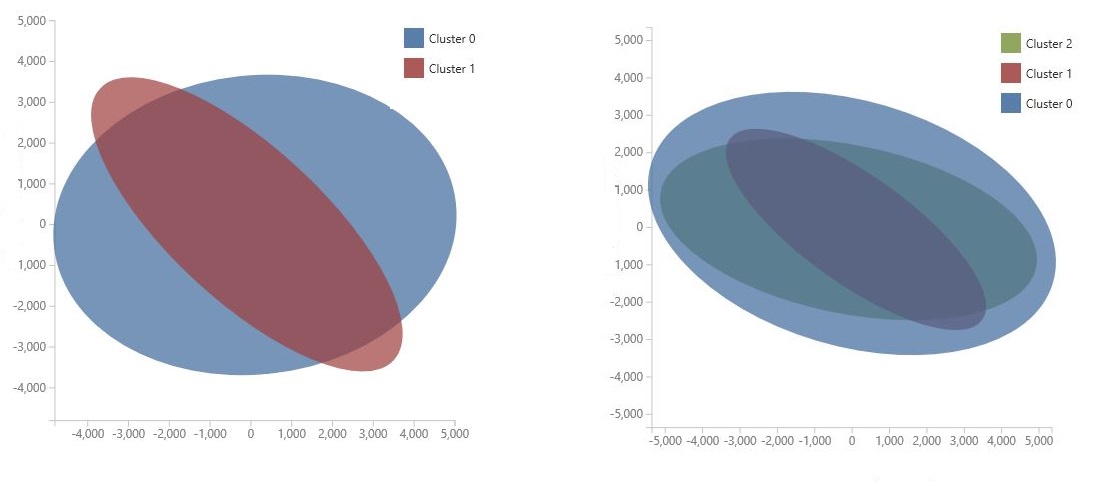
De grafiek wordt gegenereerd met behulp van Principal Component Analysis, een techniek in gegevenswetenschap voor het comprimeren van de functieruimte van een model. In de grafiek ziet u een aantal functies, gecomprimeerd in twee dimensies, die het beste het verschil tussen de clusters aangeven. Door de algemene grootte van de functieruimte voor elk cluster en de mate waarin de clusters overlappen visueel te bekijken, krijgt u een idee van hoe goed uw model kan presteren.
De volgende PCA-grafieken geven bijvoorbeeld de resultaten weer van twee modellen die zijn getraind met dezelfde gegevens: de eerste is geconfigureerd om twee clusters uit te voeren en de tweede is geconfigureerd om drie clusters uit te voeren. In deze grafieken ziet u dat het verhogen van het aantal clusters niet noodzakelijkerwijs de scheiding van de klassen heeft verbeterd.
Tip
Gebruik de module Sweep Clustering om de optimale set hyperparameters te kiezen, met inbegrip van de willekeurige seed en het aantal beginnende zwaartepunten.
De lijst met gegevenspunten en de clusters waartoe ze behoren bekijken
Er zijn twee opties voor het weergeven van de gegevensset met resultaten, afhankelijk van hoe u het model hebt getraind:
Als u de module Sweep Clustering hebt gebruikt om het model te trainen
- Gebruik het selectievakje in de module Clustering opruimen om op te geven of u de invoergegevens samen met de resultaten wilt zien of alleen de resultaten wilt zien.
- Wanneer de training is voltooid, klikt u met de rechtermuisknop op de module en selecteert u Resultatengegevensset (uitvoernummer 2)
- Klik op Visualiseren.
Als u de module Clusteringmodel trainen hebt gebruikt
- Voeg de module Gegevens toewijzen aan clusters toe en verbind het getrainde model met de invoer aan de linkerkant. Verbind een gegevensset met de rechterinvoer.
- Voeg de module Converteren naar gegevensset toe aan uw experiment en verbind deze met de uitvoer van Gegevens toewijzen aan clusters.
- Gebruik het selectievakje in de module Gegevens toewijzen aan clusters om op te geven of u de invoergegevens samen met de resultaten wilt zien of alleen de resultaten wilt zien.
- Voer het experiment uit of voer alleen de module Converteren naar gegevensset uit.
- Klik met de rechtermuisknop op Converteren naar gegevensset, selecteer Resultatengegevensset en klik op Visualiseren.
De uitvoer bevat eerst de invoergegevenskolommen, als u deze hebt opgenomen, en de volgende kolommen voor elke rij met invoergegevens:
Toewijzing: De toewijzing is een waarde tussen 1 en n, waarbij n het totale aantal clusters in het model is. Elke rij met gegevens kan slechts aan één cluster worden toegewezen.
DistancesToClusterCenter no.n: Deze waarde meet de afstand van het huidige gegevenspunt tot het zwaartepunt voor het cluster. Een afzonderlijke kolom in de uitvoer voor elk cluster in het getrainde model.
De waarden voor clusterafstand zijn gebaseerd op de metrische afstand die u hebt geselecteerd in de optie Metrisch voor het meten van het clusterresultaat. Zelfs als u een parameter-sweep uitvoert op het clusteringmodel, kan er slechts één metriek worden toegepast tijdens het opruimen. Als u de metrische waarde wijzigt, krijgt u mogelijk verschillende afstandswaarden.
Afstanden tussen clusters visualiseren
Klik in de gegevensset met resultaten uit de vorige sectie op de kolom met afstanden voor elk cluster. In Studio (klassiek) wordt een histogram weergegeven waarin de verdeling van afstanden voor punten binnen het cluster wordt gevisualiseerd.
De volgende histogrammen tonen bijvoorbeeld de verdeling van clusterafstanden tot hetzelfde experiment, met behulp van vier verschillende metrische gegevens. Alle andere instellingen voor de parameter sweep zijn hetzelfde. Het wijzigen van de metrische waarde heeft geleid tot een ander aantal clusters in één model.
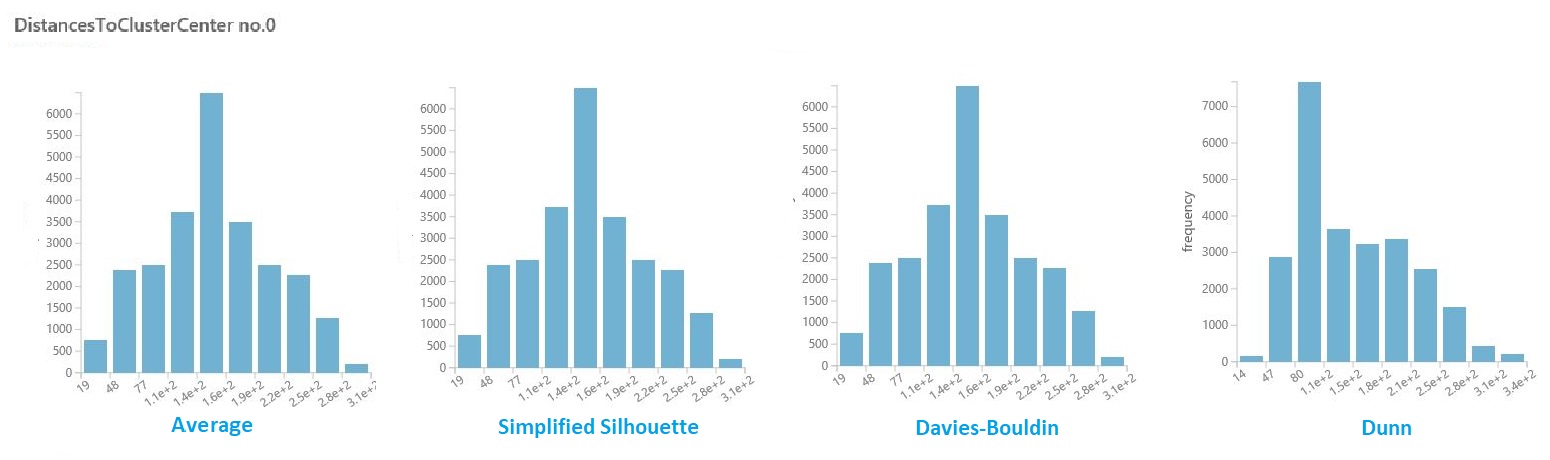
Over het algemeen moet u een metrische waarde kiezen waarmee de afstand tussen gegevenspunten in verschillende klassen wordt gemaximaliseerd en de afstanden binnen een klasse worden geminimaliseerd. U kunt de vooraf gecomputeerde middelen en andere waarden in het deelvenster Statistieken gebruiken om u bij deze beslissing te begeleiden.
Tip
U kunt de middelen en andere waarden die in visualisaties worden gebruikt, extraheren met behulp van de PowerShell-module voor Machine Learning.
Of gebruik de module Execute R Script om een aangepaste afstandsmatrix te berekenen.
Tips voor het genereren van het beste clusteringmodel
Het is bekend dat het seedingproces dat tijdens clustering wordt gebruikt, het model aanzienlijk kan beïnvloeden. Seeding betekent de eerste plaatsing van punten in potentale zwaartepunten.
Als de gegevensset bijvoorbeeld veel uitbijters bevat en er een uitbijter wordt gekozen om de clusters te seeden, passen er geen andere gegevenspunten goed bij dat cluster en kan het cluster een singleton zijn, dat wil weten een cluster met slechts één punt.
Er zijn verschillende manieren om dit probleem te voorkomen:
Gebruik een parameter sweep om het aantal zwaartepunten te wijzigen en meerdere seed-waarden te proberen.
Meerdere modellen maken, de metrische gegevens variëren of meer herhalen.
Gebruik een methode zoals PCA om variabelen te vinden die een nadelig effect hebben op clustering. Zie het voorbeeld Vergelijkbare bedrijven zoeken voor een demonstratie van deze techniek.
In het algemeen is het met clusteringmodellen mogelijk dat een bepaalde configuratie resulteert in een lokaal geoptimaliseerde set clusters. Met andere woorden, de set clusters die door het model wordt geretourneerd, past alleen bij de huidige gegevenspunten en is niet generaliseerbaar voor andere gegevens. Als u een andere initiële configuratie hebt gebruikt, kan de K-means-methode een andere, misschien betere, configuratie vinden.
Belangrijk
U wordt aangeraden altijd te experimenteren met de parameters, meerdere modellen te maken en de resulterende modellen te vergelijken.
Voorbeelden
Zie de volgende experimenten in de Azure AI-galerie voor voorbeelden van hoe K-means-clustering wordt gebruikt in Machine Learning:
Irisgegevens groeperen: vergelijkt de resultaten van K-Means Clustering en Multiclass Logistic Regression voor een classificatietaak.
Voorbeeld van kleurkwantisatie: bouwt meerdere K-means-modellen met verschillende parameters om de optimale compressie van afbeeldingen te vinden.
Clustering: Vergelijkbare bedrijven: varieert het aantal zwaartepunten om groepen vergelijkbare bedrijven te vinden in de S&P500.
Technische opmerkingen
Op basis van een specifiek aantal clusters (K) dat moet worden gevonden voor een set D-dimensionale gegevenspunten met N-gegevenspunten , bouwt het K-means-algoritme de clusters als volgt:
De module initialiseert een K-voor-D-matrix met de uiteindelijke zwaartepunten die de gevonden K-clusters definiëren.
Standaard wijst de module de eerste K-gegevenspunten toe aan de K-clusters .
Beginnend met een eerste set K-zwaartepunten , gebruikt de methode het algoritme van Lloyd om de locaties van de zwaartepunten iteratief te verfijnen.
Het algoritme wordt beëindigd wanneer de zwaartepunten zich stabiliseren of wanneer een opgegeven aantal iteraties is voltooid.
Er wordt een metrische overeenkomstwaarde (standaard Euclidische afstand) gebruikt om elk gegevenspunt toe te wijzen aan het cluster dat het dichtstbijzijnde zwaartepunt heeft.
Waarschuwing
- Als u een parameterbereik doorgeeft aan Clustering model trainen, wordt alleen de eerste waarde in de lijst met parameterbereiken gebruikt.
- Als u één set parameterwaarden doorgeeft aan de module Clustering opruimen en er een reeks instellingen voor elke parameter wordt verwacht, worden de waarden genegeerd en worden de standaardwaarden voor de cursist gebruikt.
- Als u de optie Parameterbereik selecteert en één waarde voor een parameter invoert, wordt die ene waarde die u hebt opgegeven, gebruikt tijdens de sweep, zelfs als andere parameters in een bereik van waarden veranderen.
Moduleparameters
| Name | Bereik | Type | Standaard | Beschrijving |
|---|---|---|---|---|
| Aantal zwaartepunten | >=2 | Geheel getal | 2 | Aantal zwaartepunten |
| Metrisch | Lijst (subset) | Metrisch | Euclidische | Geselecteerde metrische waarde |
| Initialisatie | Lijst | Methode voor initialisatie van het zwaartepunt | K-Means++ | Initialisatie-algoritme |
| Iteraties | >=1 | Geheel getal | 100 | Aantal iteraties |
Uitvoerwaarden
| Naam | Type | Description |
|---|---|---|
| Niet-getraind model | ICluster-interface | Niet-getraind K-Means-clusteringmodel |
Uitzonderingen
Zie Foutcodes voor machine learning-modules voor een lijst met alle uitzonderingen.
| Uitzondering | Description |
|---|---|
| Fout 0003 | Uitzondering treedt op als een of meer invoerwaarden null of leeg zijn. |
Zie ook
Clustering
Gegevens aan cluster toewijzen
Clustermodel trainen
Clustering opruimen