Modelresultaten interpreteren in Machine Learning Studio (klassiek)
VAN TOEPASSING OP: Machine Learning Studio (klassiek)
Machine Learning Studio (klassiek)  Azure Machine Learning
Azure Machine Learning
Belangrijk
De ondersteuning voor Azure Machine Learning-studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden om vóór die datum over te stappen naar Azure Machine Learning.
Vanaf 1 december 2021 kunt u geen nieuwe resources voor Azure Machine Learning-studio (klassiek) meer maken. Tot en met 31 augustus 2024 kunt u de bestaande resources van Azure Machine Learning-studio (klassiek) blijven gebruiken.
- Zie informatie over het verplaatsen van machine learning-projecten van ML Studio (klassiek) naar Azure Machine Learning.
- Meer informatie over Azure Machine Learning
De documentatie van ML-studio (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet meer bijgewerkt.
In dit onderwerp wordt uitgelegd hoe u voorspellingsresultaten kunt visualiseren en interpreteren in Machine Learning Studio (klassiek). Nadat u een model hebt getraind en er voorspellingen op hebt gedaan ('het model beoordeeld'), moet u het voorspellingsresultaat begrijpen en interpreteren.
Er zijn vier belangrijke soorten machine learning-modellen in Machine Learning Studio (klassiek):
- Classificatie
- Clustering
- Regressie
- Aanbevelingssystemen
De modules die worden gebruikt voor voorspelling boven op deze modellen zijn:
- Score Model-module voor classificatie en regressie
- Toewijzen aan clustersmodule voor clustering
- Score Matchbox Recommender voor aanbevelingssystemen
Meer informatie over het kiezen van parameters voor het optimaliseren van uw algoritmen in ML Studio (klassiek).
Zie Modelprestaties evalueren voor meer informatie over het evalueren van uw modellen.
Als u nog geen ervaring hebt met ML Studio (klassiek), leert u hoe u een eenvoudig experiment maakt.
Classificatie
Er zijn twee subcategorieën van classificatieproblemen:
- Problemen met slechts twee klassen (twee klassen of binaire classificatie)
- Problemen met meer dan twee klassen (classificatie met meerdere klassen)
Machine Learning Studio (klassiek) heeft verschillende modules voor elk van deze typen classificaties, maar de methoden voor het interpreteren van hun voorspellingsresultaten zijn vergelijkbaar.
Classificatie van twee klassen
Voorbeeldexperiment
Een voorbeeld van een classificatieprobleem met twee klassen is de classificatie van irisbloemen. De taak is om irisbloemen te classificeren op basis van hun kenmerken. De Iris-gegevensset die wordt geleverd in Machine Learning Studio (klassiek) is een subset van de populaire Iris-gegevensset met slechts twee bloemsoorten (klassen 0 en 1). Er zijn vier kenmerken voor elke bloem (sepal length, sepal width, petal length, and petal width).
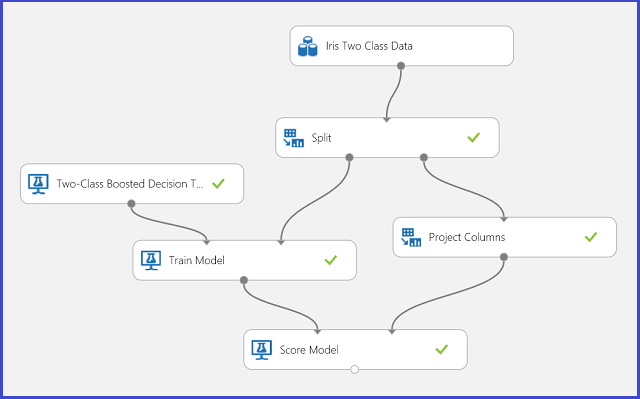
Afbeelding 1. Iris tweeklasse classificatieprobleem experiment
Er is een experiment uitgevoerd om dit probleem op te lossen, zoals wordt weergegeven in afbeelding 1. Er is een model voor een versterkte beslissingsstructuur in twee klassen getraind en beoordeeld. U kunt nu de voorspellingsresultaten van de module Score Model visualiseren door op de uitvoerpoort van de module Score Model te klikken en vervolgens op Visualize te klikken.
Hiermee worden de scoreresultaten weergegeven, zoals weergegeven in afbeelding 2.
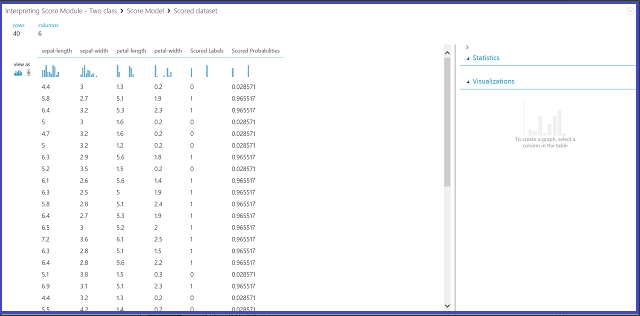
Afbeelding 2. Een scoremodelresultaat visualiseren in classificatie in twee klassen
Resultaatinterpretatie
De resultatentabel bevat zes kolommen. De vier linkerkolommen zijn de vier functies. De juiste twee kolommen, Scored Labels en Scored Probabilities, zijn de voorspellingsresultaten. In de kolom Scored Probabilities ziet u de kans dat een bloem deel uitmaakt van de positieve klasse (klasse 1). Het eerste getal in de kolom (0,028571) betekent bijvoorbeeld dat er 0,028571 waarschijnlijkheid is dat de eerste bloem deel uitmaakt van klasse 1. De kolom Scored Labels toont de voorspelde klasse voor elke bloem. Dit is gebaseerd op de kolom Scored Probabilities. Als de score van een bloem groter is dan 0,5, wordt deze voorspeld als klasse 1. Anders wordt het voorspeld als klasse 0.
Webservicepublicatie
Nadat de voorspellingsresultaten zijn begrepen en beoordeeld, kan het experiment worden gepubliceerd als een webservice, zodat u het in verschillende toepassingen kunt implementeren en het kunt aanroepen om klassevoorspellingen te verkrijgen voor elke nieuwe irisbloem. Zie Zelfstudie 3: Kredietrisicomodel implementeren voor meer informatie over het wijzigen van een trainingsexperiment in een scoreexperiment en het publiceren als een webservice. Deze procedure biedt u een score-experiment zoals wordt weergegeven in afbeelding 3.
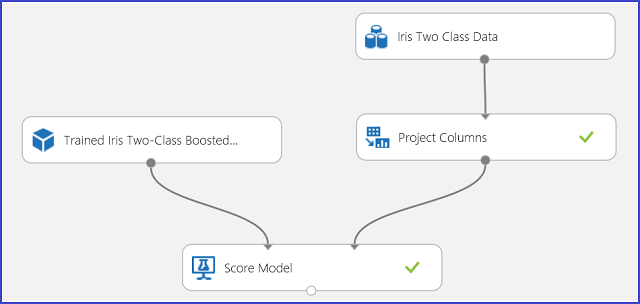
Afbeelding 3. Het probleemexperiment met twee klassen classificatie van irissen beoordelen
Nu moet u de invoer en uitvoer voor de webservice instellen. De invoer is de juiste invoerpoort van Score Model. Dit is de irisbloem bevat invoer. De keuze van de uitvoer is afhankelijk van of u geïnteresseerd bent in de voorspelde klasse (scorelabel), de scoren waarschijnlijkheid of beide. In dit voorbeeld wordt ervan uitgegaan dat u geïnteresseerd bent in beide. Als u de gewenste uitvoerkolommen wilt selecteren, gebruikt u een module Kolommen selecteren in de gegevensset . Klik op Kolommen selecteren in de gegevensset, klik op Kolomkiezer starten en selecteer Scored Labels en Scored Waarschijnlijkheden. Nadat u de uitvoerpoort van select columns in de gegevensset hebt ingesteld en opnieuw hebt uitgevoerd, moet u klaar zijn om het score-experiment te publiceren als een webservice door te klikken op PUBLISH WEB SERVICE. Het laatste experiment ziet eruit als afbeelding 4.
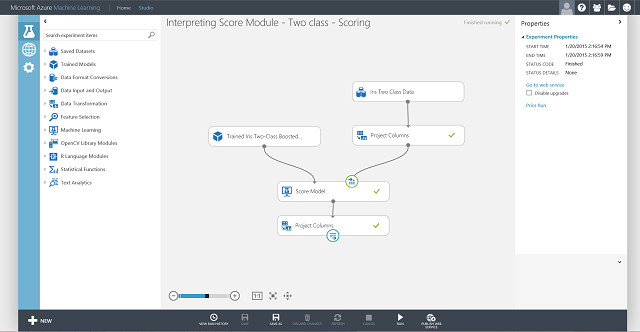
Afbeelding 4: Laatste score-experiment van een irisclassificatieprobleem met twee klassen
Nadat u de webservice hebt uitgevoerd en enkele functiewaarden van een testexemplaren hebt ingevoerd, retourneert het resultaat twee getallen. Het eerste getal is het scored label en de tweede is de scored waarschijnlijkheid. Deze bloem wordt voorspeld als klasse 1 met 0,9655 kans.


Afbeelding 5. Webserviceresultaat van irisclassificatie in twee klassen
Classificatie met meerdere klassen
Voorbeeldexperiment
In dit experiment voert u een letterherkenningstaak uit als voorbeeld van classificatie met meerdere klassen. De classificatie probeert een bepaalde letter %28class%29 te voorspellen op basis van enkele handgeschreven kenmerkwaarden die zijn geëxtraheerd uit de handgeschreven afbeeldingen.
In de trainingsgegevens zijn er 16 functies geëxtraheerd uit handgeschreven briefafbeeldingen. De 26 brieven vormen onze 26 klassen. Afbeelding 6 toont een experiment dat een classificatiemodel met meerdere klassen traint voor letterherkenning en voorspelt voor dezelfde functieset in een testgegevensset.
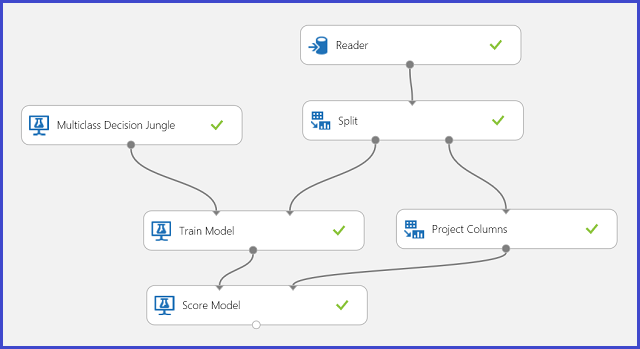
Afbeelding 6. Probleemexperiment met classificatie van meerdere klassen letterherkenning
Als u de resultaten van de module Score Model visualiseert door op de uitvoerpoort van de module Score Model te klikken en vervolgens op Visualiseren te klikken, ziet u de inhoud zoals weergegeven in afbeelding 7.
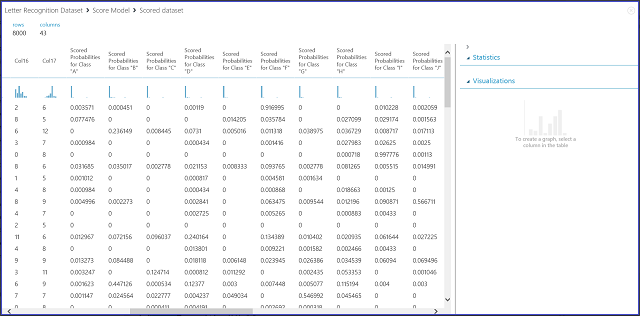
Afbeelding 7. Scoremodelresultaten visualiseren in een classificatie met meerdere klassen
Resultaatinterpretatie
De linker 16 kolommen vertegenwoordigen de functiewaarden van de testset. De kolommen met namen zoals Scored Probabilities voor klasse XX zijn net als de kolom Scored Probabilities in de case van twee klassen. Ze tonen de waarschijnlijkheid dat de bijbehorende vermelding in een bepaalde klasse valt. Voor de eerste vermelding is er bijvoorbeeld 0,003571-waarschijnlijkheid dat het een 'A', 0,000451-kans is dat het een 'B' is, enzovoort. De laatste kolom (Scored Labels) is hetzelfde als Scored Labels in het geval van twee klassen. Hiermee selecteert u de klasse met de grootste score waarschijnlijkheid als de voorspelde klasse van de bijbehorende vermelding. Voor de eerste vermelding is het scored label bijvoorbeeld 'F' omdat het de grootste kans heeft om een 'F' (0,916995) te zijn.
Publicatie van webservice
U kunt ook het scored label voor elke vermelding en de waarschijnlijkheid van het scorenlabel ophalen. De basislogica is het vinden van de grootste kans tussen alle scoren. Hiervoor moet u de execute R Script-module gebruiken. De R-code wordt weergegeven in afbeelding 8 en het resultaat van het experiment wordt weergegeven in afbeelding 9.

Afbeelding 8. R-code voor het extraheren van scored labels en de bijbehorende waarschijnlijkheden van de labels
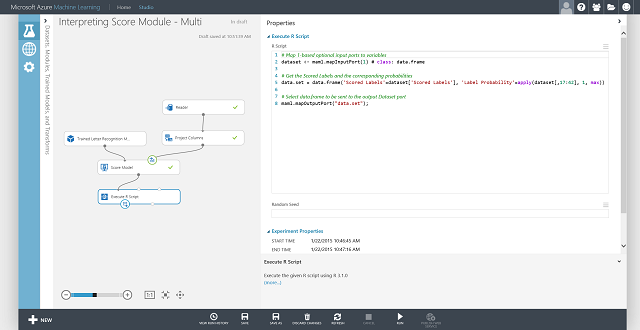
Afbeelding 9. Laatste scoreexperiment van het probleem met classificatie met meerdere klassen voor letterherkenning
Nadat u de webservice hebt gepubliceerd en uitgevoerd en enkele invoerfunctiewaarden hebt ingevoerd, ziet het geretourneerde resultaat eruit als afbeelding 10. Deze handgeschreven brief, met de geëxtraheerde 16 kenmerken, wordt voorspeld een "T" te zijn met 0,9715 waarschijnlijkheid.

Afbeelding 10. Webserviceresultaat van classificatie met meerdere klassen
Regressie
Regressieproblemen verschillen van classificatieproblemen. In een classificatieprobleem probeert u discrete klassen te voorspellen, zoals tot welke klasse een irisbloem behoort. Maar zoals u kunt zien in het volgende voorbeeld van een regressieprobleem, probeert u een continue variabele te voorspellen, zoals de prijs van een auto.
Voorbeeldexperiment
Gebruik autoprijsvoorspelling als voorbeeld voor regressie. U probeert de prijs van een auto te voorspellen op basis van de kenmerken, waaronder merk, brandstoftype, lichaamstype en aandrijfwiel. Het experiment wordt weergegeven in afbeelding 11.
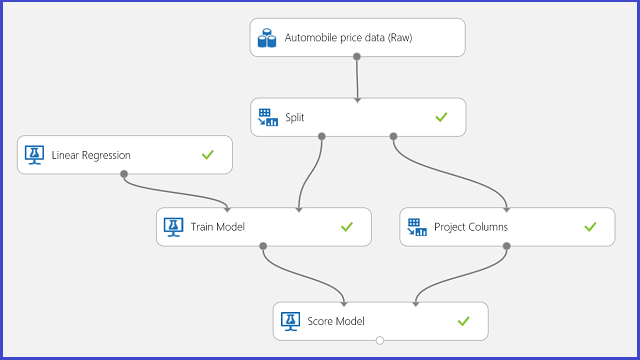
Afbeelding 11. Probleemexperiment autoprijsregressie
Als u de module Score Model visualiseert, ziet het resultaat eruit als afbeelding 12.
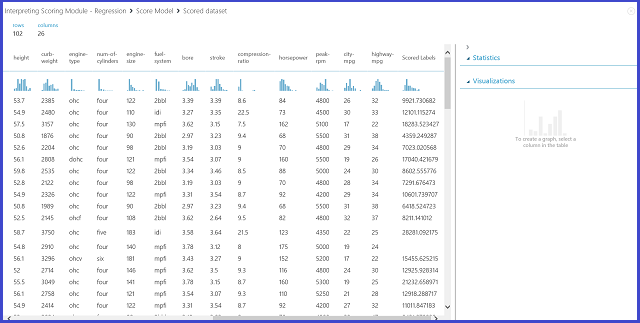
Afbeelding 12. Scoreresultaat voor het probleem met prijsvoorspelling van auto's
Resultaatinterpretatie
Scored Labels is de resultaatkolom in dit scoreresultaat. De getallen zijn de voorspelde prijs voor elke auto.
Publicatie van webservice
U kunt het regressieexperiment publiceren in een webservice en deze aanroepen voor prijsvoorspelling voor auto's op dezelfde manier als in het gebruiksscenario voor classificaties in twee klassen.
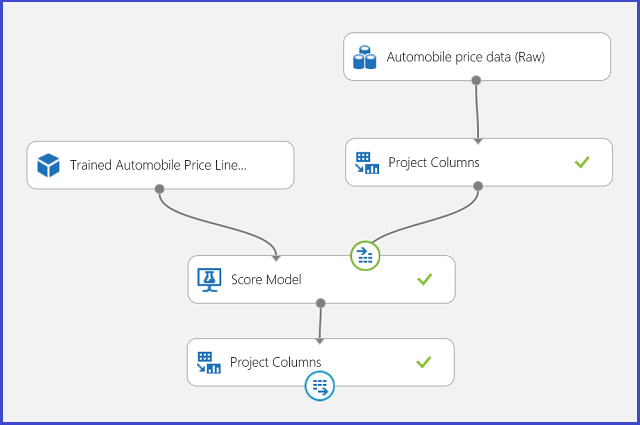
Afbeelding 13. Score-experiment van een probleem met regressie van autoprijzen
Als u de webservice uitvoert, ziet het geretourneerde resultaat eruit als afbeelding 14. De voorspelde prijs voor deze auto is $ 15.085,52.


Afbeelding 14. Webserviceresultaat van een probleem met autoprijsregressie
Clustering
Voorbeeldexperiment
We gaan de Iris-gegevensset opnieuw gebruiken om een clusteringexperiment te bouwen. Hier kunt u de klasselabels in de gegevensset filteren, zodat deze alleen functies heeft en kan worden gebruikt voor clustering. Geef in dit irisgebruiksscenario het aantal clusters op dat twee moet zijn tijdens het trainingsproces, wat betekent dat u de bloemen in twee klassen zou clusteren. Het experiment wordt weergegeven in afbeelding 15.
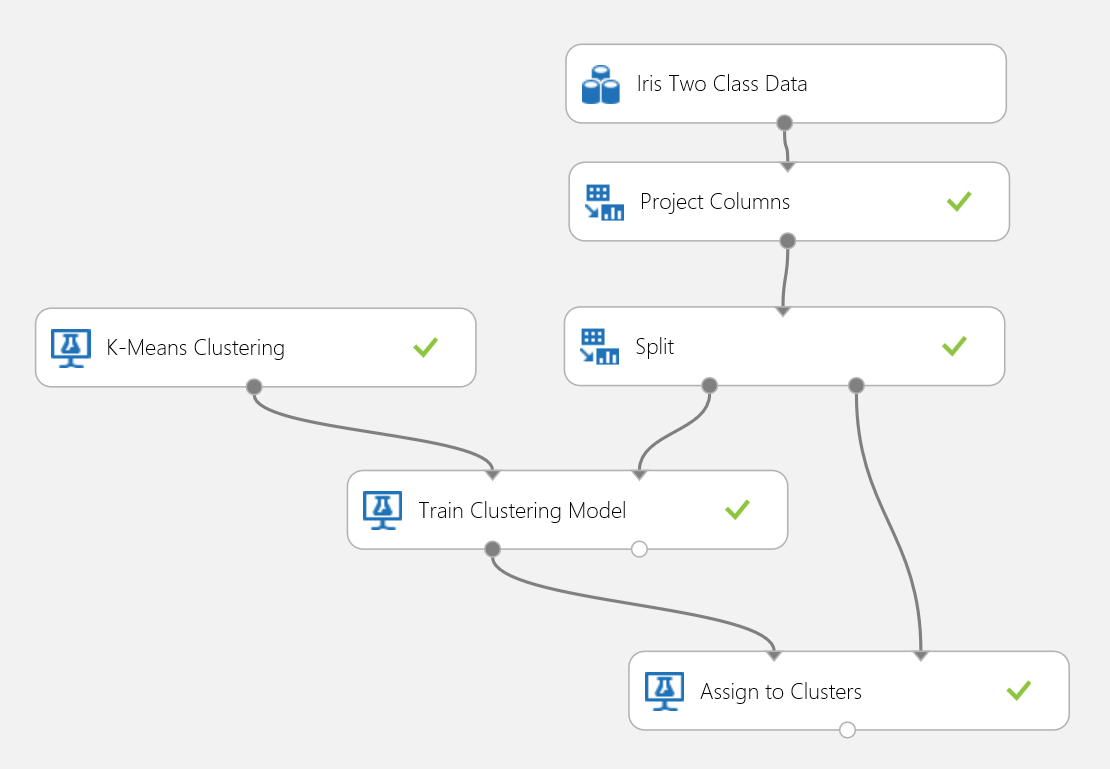
Afbeelding 15. Probleemexperiment irisclustering
Clustering verschilt van classificatie omdat de set met trainingsgegevens zelf geen grondwaarlabels heeft. Clustering groepeert de instanties van de trainingsgegevensset in afzonderlijke clusters. Tijdens het trainingsproces worden de vermeldingen gelabeld door de verschillen tussen hun functies te leren. Daarna kan het getrainde model worden gebruikt om toekomstige vermeldingen verder te classificeren. Er zijn twee delen van het resultaat waarin we geïnteresseerd zijn in een clusterprobleem. Het eerste deel is het labelen van de trainingsgegevensset en de tweede classificeert een nieuwe gegevensset met het getrainde model.
Het eerste deel van het resultaat kan worden gevisualiseerd door te klikken op de linkeruitvoerpoort van Train Clustering Model en vervolgens op Visualize te klikken. De visualisatie wordt weergegeven in afbeelding 16.
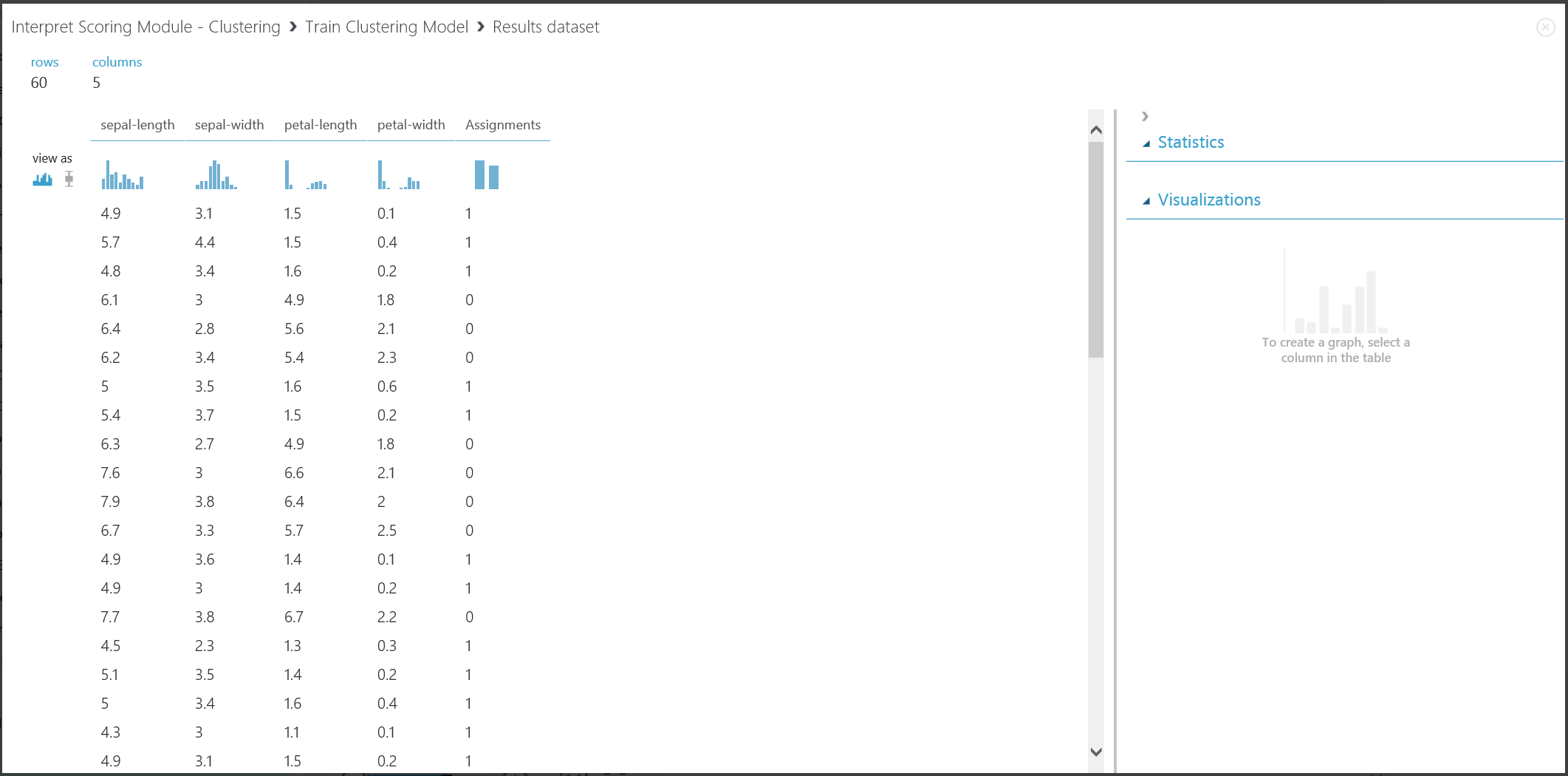
Afbeelding 16. Clusterresultaat visualiseren voor de trainingsgegevensset
Het resultaat van het tweede deel, het clusteren van nieuwe vermeldingen met het getrainde clusteringmodel, wordt weergegeven in afbeelding 17.
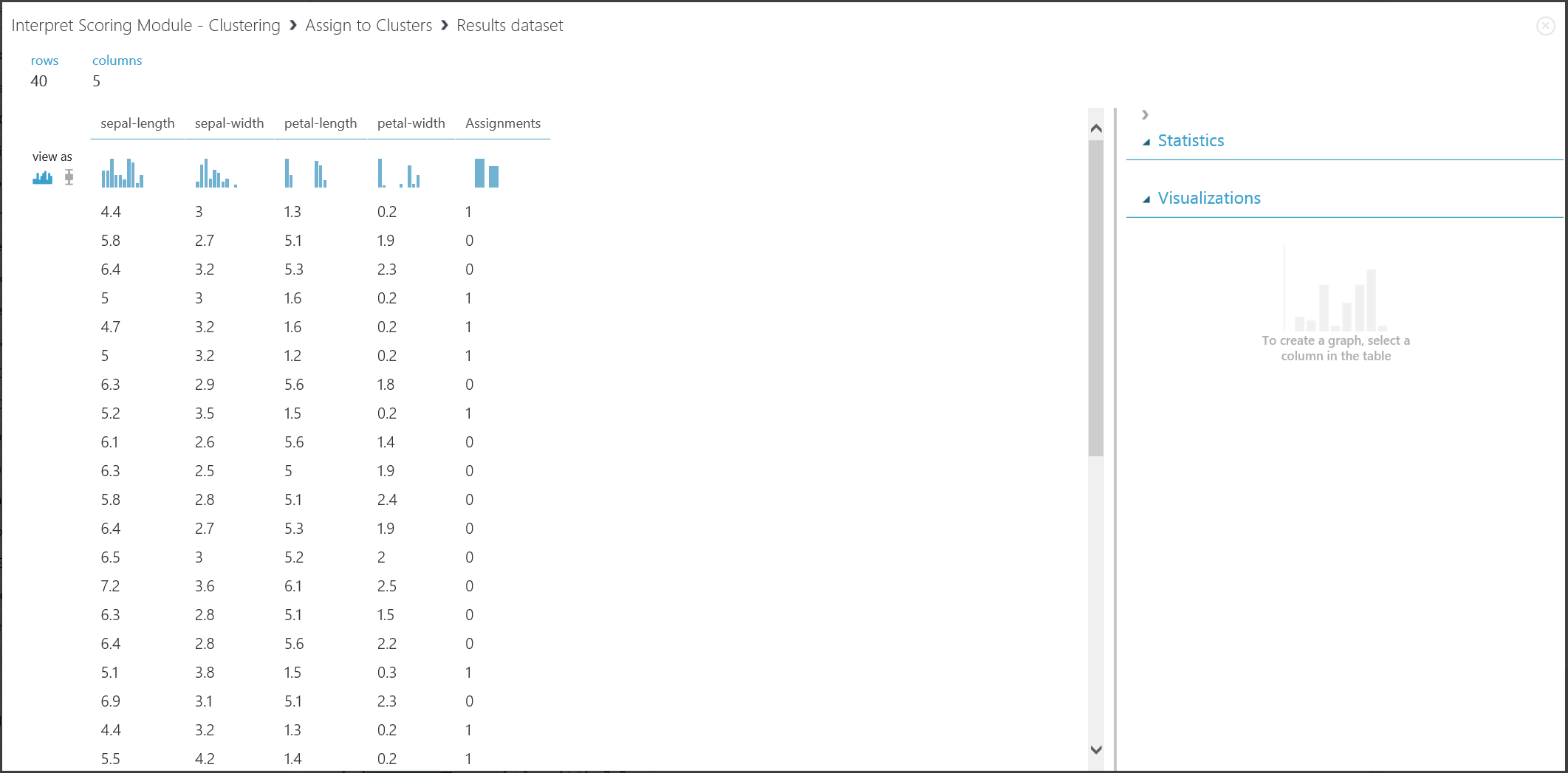
Afbeelding 17. Clusterresultaat visualiseren in een nieuwe gegevensset
Resultaatinterpretatie
Hoewel de resultaten van de twee delen afkomstig zijn van verschillende experimentfasen, zien ze er hetzelfde uit en worden ze op dezelfde manier geïnterpreteerd. De eerste vier kolommen zijn functies. De laatste kolom, Toewijzingen, is het voorspellingsresultaat. De vermeldingen die aan hetzelfde nummer zijn toegewezen, worden voorspeld dat ze zich in hetzelfde cluster bevinden, dat wil zeggen dat ze overeenkomsten op een bepaalde manier delen (dit experiment maakt gebruik van de standaard metrische euclidische afstand). Omdat u het aantal clusters hebt opgegeven dat 2 moet zijn, worden de vermeldingen in Toewijzingen gelabeld als 0 of 1.
Publicatie van webservice
U kunt het clusteringexperiment publiceren in een webservice en deze aanroepen voor clustervoorspellingen op dezelfde manier als in het gebruiksscenario voor classificaties van twee klassen.
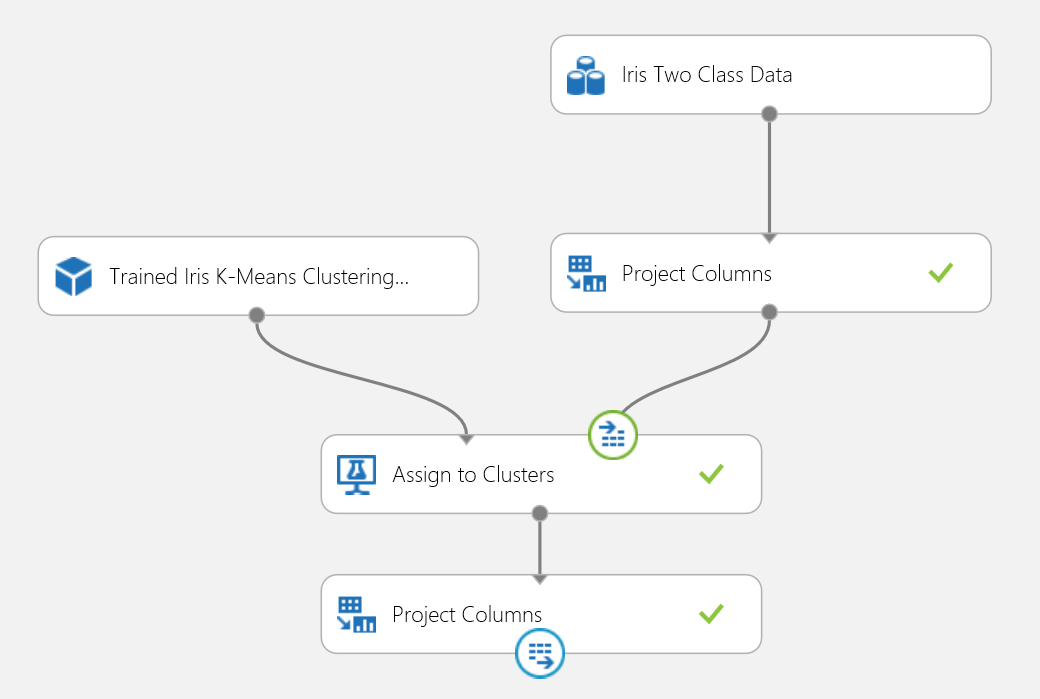
Afbeelding 18. Scoreexperiment van een irisclusterprobleem
Nadat u de webservice hebt uitgevoerd, ziet het geretourneerde resultaat eruit als afbeelding 19. Deze bloem is voorspeld in cluster 0.
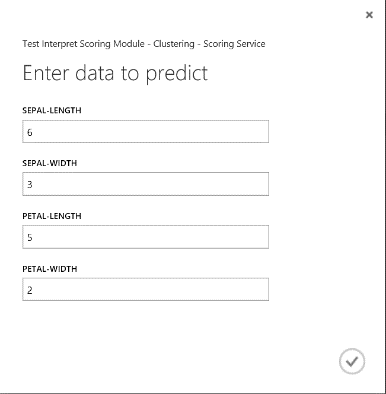

Afbeelding 19. Webserviceresultaat van irisclassificatie in twee klassen
Aanbevelingssysteem
Voorbeeldexperiment
Voor aanbevelingssystemen kunt u het probleem met restaurantaanbeveling gebruiken als voorbeeld: u kunt restaurants aanbevelen voor klanten op basis van hun beoordelingsgeschiedenis. De invoergegevens bestaan uit drie delen:
- Restaurantbeoordelingen van klanten
- Functiegegevens van klant
- Gegevens over restaurantkenmerken
Er zijn verschillende dingen die we kunnen doen met de module Train Matchbox Recommender in Machine Learning Studio (klassiek):
- Classificaties voorspellen voor een bepaalde gebruiker en item
- Items aanbevelen aan een bepaalde gebruiker
- Gebruikers zoeken met betrekking tot een bepaalde gebruiker
- Items zoeken die betrekking hebben op een bepaald item
U kunt kiezen wat u wilt doen door een keuze te maken uit de vier opties in het menu Type voorspelling van aanbeveling . Hier kunt u alle vier de scenario's doorlopen.
Een typisch Machine Learning Studio-experiment (klassiek) voor een aanbevelingssysteem ziet eruit als afbeelding 20. Zie Train matchbox recommender en Score matchbox recommender voor informatie over het gebruik van deze aanbevelingssysteemmodules.

Afbeelding 20. Systeemexperiment aanbevelen
Resultaatinterpretatie
Classificaties voorspellen voor een bepaalde gebruiker en item
Als u Classificatievoorspelling selecteert onder Type aanbevelingsvoorspelling, vraagt u het aanbevelingssysteem om de waardering voor een bepaalde gebruiker en een bepaald item te voorspellen. De visualisatie van de uitvoer Score Matchbox Recommender ziet eruit als afbeelding 21.

Afbeelding 21. Het scoreresultaat van de voorspelling van de aanbevelingssysteem visualiseren
De eerste twee kolommen zijn de paren van gebruikersitems die worden verstrekt door de invoergegevens. De derde kolom is de voorspelde waardering van een gebruiker voor een bepaald item. In de eerste rij wordt klant U1048 bijvoorbeeld voorspeld om restaurant-135026 te beoordelen als 2.
Items aanbevelen aan een bepaalde gebruiker
Als u itemaanbeveling selecteert onder Type aanbevelingsvoorspelling, vraagt u het aanbevelingssysteem om items aan een bepaalde gebruiker aan te bevelen. De laatste parameter die u in dit scenario wilt kiezen, is aanbevolen itemselectie. De optie Van geclassificeerde items (voor modelevaluatie) is voornamelijk bedoeld voor modelevaluatie tijdens het trainingsproces. Voor deze voorspellingsfase kiezen we uit alle items. De visualisatie van de uitvoer Score Matchbox Recommender ziet eruit als afbeelding 22.
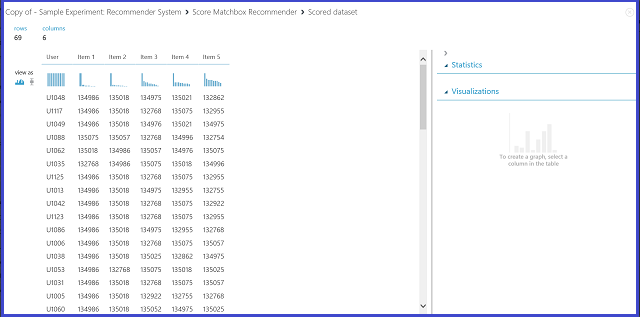
Afbeelding 22. Scoreresultaat van de aanbeveling van het aanbevelingssysteem visualiseren
De eerste van de zes kolommen vertegenwoordigt de opgegeven gebruikers-id's om items voor te bevelen, zoals opgegeven door de invoergegevens. De andere vijf kolommen vertegenwoordigen de items die worden aanbevolen voor de gebruiker in aflopende volgorde van relevantie. In de eerste rij is het meest aanbevolen restaurant voor klant U1048 bijvoorbeeld 134986, gevolgd door 135018, 134975, 135021 en 132862.
Gebruikers zoeken met betrekking tot een bepaalde gebruiker
Als u Gerelateerde gebruikers selecteert onder Type aanbevelingsvoorspelling, vraagt u het aanbevelingssysteem om gerelateerde gebruikers te zoeken naar een bepaalde gebruiker. Gerelateerde gebruikers zijn de gebruikers met vergelijkbare voorkeuren. De laatste parameter die u in dit scenario wilt kiezen, is gerelateerde gebruikersselectie. De optie Van gebruikers die beoordeeld items (voor modelevaluatie) is voornamelijk bedoeld voor modelevaluatie tijdens het trainingsproces. Kies uit alle gebruikers voor deze voorspellingsfase. De visualisatie van de uitvoer Score Matchbox Recommender ziet eruit als afbeelding 23.

Afbeelding 23. Scoreresultaten van de aanbevolen systeemgebruikers visualiseren
In de eerste van de zes kolommen ziet u de opgegeven gebruikers-id's die nodig zijn om gerelateerde gebruikers te vinden, zoals opgegeven door invoergegevens. In de andere vijf kolommen worden de voorspelde gerelateerde gebruikers van de gebruiker opgeslagen in aflopende volgorde van relevantie. In de eerste rij is de meest relevante klant voor klant U1048 U1051, gevolgd door U1066, U1044, U1017 en U1072.
Items zoeken die betrekking hebben op een bepaald item
Als u Gerelateerde items selecteert onder Type aanbevelingsvoorspelling, vraagt u het aanbevelingssysteem om gerelateerde items voor een bepaald item te zoeken. Gerelateerde items zijn de items die waarschijnlijk door dezelfde gebruiker worden leuk gevonden. De laatste parameter die u in dit scenario wilt kiezen, is de selectie van gerelateerde items. De optie Van geclassificeerde items (voor modelevaluatie) is voornamelijk bedoeld voor modelevaluatie tijdens het trainingsproces. We kiezen uit alle items voor deze voorspellingsfase. De visualisatie van de uitvoer Score Matchbox Recommender ziet eruit als afbeelding 24.
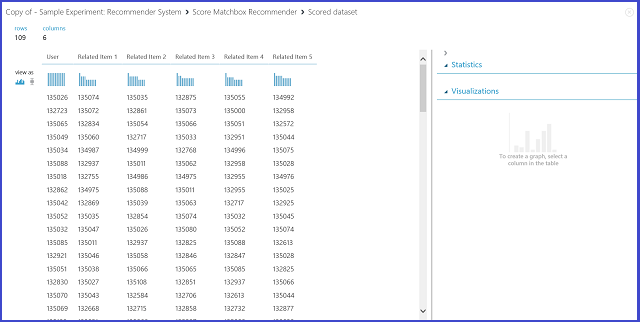
Afbeelding 24. Scoreresultaten van de aanbevolen systeemitems visualiseren
De eerste van de zes kolommen vertegenwoordigt de opgegeven item-id's die nodig zijn om gerelateerde items te vinden, zoals opgegeven door de invoergegevens. In de andere vijf kolommen worden de voorspelde gerelateerde items van het item in aflopende volgorde opgeslagen in termen van relevantie. In de eerste rij is het meest relevante item voor item 135026 bijvoorbeeld 135074, gevolgd door 135035, 132875, 135055 en 134992.
Publicatie van webservice
Het publiceren van deze experimenten als webservices voor het ophalen van voorspellingen is vergelijkbaar voor elk van de vier scenario's. Hier nemen we het tweede scenario (aanbevolen items aan een bepaalde gebruiker) als voorbeeld. U kunt dezelfde procedure volgen met de andere drie.
Als u het getrainde aanbevelingssysteem opslaat als een getraind model en de invoergegevens filtert op één kolom met gebruikers-id's, kunt u het experiment koppelen zoals in afbeelding 25 en publiceren als een webservice.
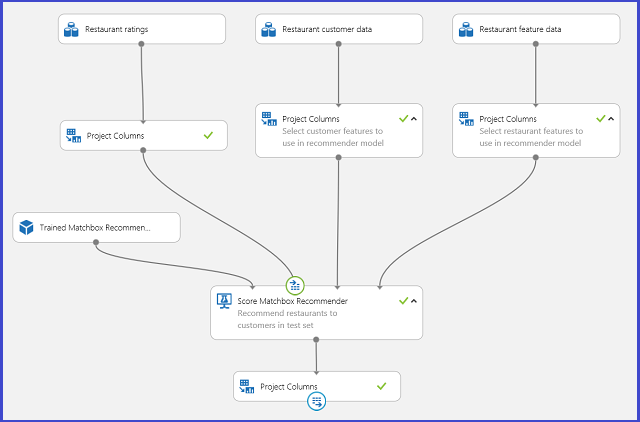
Afbeelding 25. Scoreexperiment van het probleem met de aanbeveling van het restaurant
Als u de webservice uitvoert, ziet het geretourneerde resultaat eruit als afbeelding 26. De vijf aanbevolen restaurants voor gebruiker U1048 zijn 134986, 135018, 134975, 135021 en 132862.
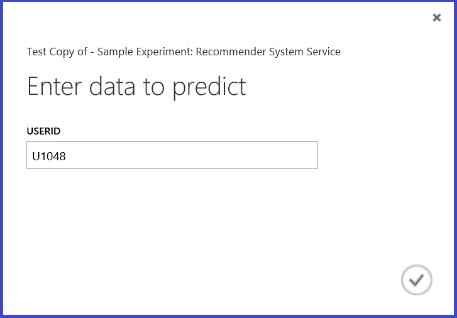

Afbeelding 26. Webserviceresultaat van probleem met aanbeveling van restaurant