Modelprestaties evalueren in Machine Learning Studio (klassiek)
VAN TOEPASSING OP: Machine Learning Studio (klassiek)
Machine Learning Studio (klassiek)  Azure Machine Learning
Azure Machine Learning
Belangrijk
De ondersteuning voor Azure Machine Learning-studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden om vóór die datum over te stappen naar Azure Machine Learning.
Vanaf 1 december 2021 kunt u geen nieuwe resources voor Azure Machine Learning-studio (klassiek) meer maken. Tot en met 31 augustus 2024 kunt u de bestaande resources van Azure Machine Learning-studio (klassiek) blijven gebruiken.
- Zie informatie over het verplaatsen van machine learning-projecten van ML Studio (klassiek) naar Azure Machine Learning.
- Meer informatie over Azure Machine Learning
De documentatie van ML-studio (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet meer bijgewerkt.
In dit artikel vindt u meer informatie over de metrische gegevens die u kunt gebruiken om modelprestaties te bewaken in Machine Learning Studio (klassiek). Het evalueren van de prestaties van een model is een van de belangrijkste fasen in het data science-proces. Het geeft aan hoe succesvol het scoren (voorspellingen) van een gegevensset is door een getraind model. Machine Learning Studio (klassiek) ondersteunt modelevaluatie via twee van de belangrijkste machine learning-modules:
Met deze modules kunt u zien hoe uw model presteert in termen van een aantal metrische gegevens die vaak worden gebruikt in machine learning en statistieken.
Het evalueren van modellen moet samen met:
Er worden drie algemene leerscenario's met supervisie gepresenteerd:
- Regressie
- binaire classificatie
- classificatie met meerdere klassen
Evaluatie versus kruisvalidatie
Evaluatie en kruisvalidatie zijn standaard manieren om de prestaties van uw model te meten. Ze genereren beide metrische evaluatiegegevens die u kunt inspecteren of vergelijken met die van andere modellen.
Evaluate Model verwacht een gescoorde gegevensset als invoer (of twee voor het geval u de prestaties van twee verschillende modellen wilt vergelijken). Daarom moet u uw model trainen met behulp van de module Train Model en voorspellingen doen voor een bepaalde gegevensset met behulp van de module Score Model voordat u de resultaten kunt evalueren. De evaluatie is gebaseerd op de scorelabels/waarschijnlijkheden, samen met de werkelijke labels, die allemaal worden uitgevoerd door de module Score Model .
U kunt ook kruisvalidatie gebruiken om een aantal train-score-evaluate-bewerkingen (10 vouwen) automatisch uit te voeren op verschillende subsets van de invoergegevens. De invoergegevens worden gesplitst in 10 onderdelen, waarbij de ene is gereserveerd voor testen en de andere 9 voor training. Dit proces wordt 10 keer herhaald en de metrische evaluatiegegevens worden gemiddeld berekend. Dit helpt bij het bepalen hoe goed een model zou generaliseren naar nieuwe gegevenssets. De module Model kruisvalidatie neemt een niet-getraind model en een aantal gelabelde gegevenssets en voert de evaluatieresultaten uit van elk van de 10 vouwen, naast de gemiddelde resultaten.
In de volgende secties bouwen we eenvoudige regressie- en classificatiemodellen en evalueren we hun prestaties, met behulp van zowel de modules Evaluate Model als Cross-Validate Model .
Een regressiemodel evalueren
Stel dat we de prijs van een auto willen voorspellen met behulp van functies zoals afmetingen, pk's, motorspecificaties, enzovoort. Dit is een typisch regressieprobleem, waarbij de doelvariabele (prijs) een doorlopende numerieke waarde is. We kunnen een lineair regressiemodel aanpassen dat, gezien de functiewaarden van een bepaalde auto, de prijs van die auto kan voorspellen. Dit regressiemodel kan worden gebruikt om dezelfde gegevensset te scoren die we hebben getraind. Zodra we de voorspelde autoprijzen hebben, kunnen we de modelprestaties evalueren door te kijken hoeveel de voorspellingen afwijken van de werkelijke prijzen gemiddeld. Ter illustratie gebruiken we de gegevensset Automobile price data (Raw) die beschikbaar is in de sectie Opgeslagen gegevenssets in Machine Learning Studio (klassiek).
Het experiment maken
Voeg de volgende modules toe aan uw werkruimte in Machine Learning Studio (klassiek):
- Autoprijsgegevens (onbewerkt)
- Lineaire regressie
- Trainingsmodel
- Score Model
- Model evalueren
Verbind de poorten zoals hieronder weergegeven in afbeelding 1 en stel de kolom Label van de module Train Model in op prijs.
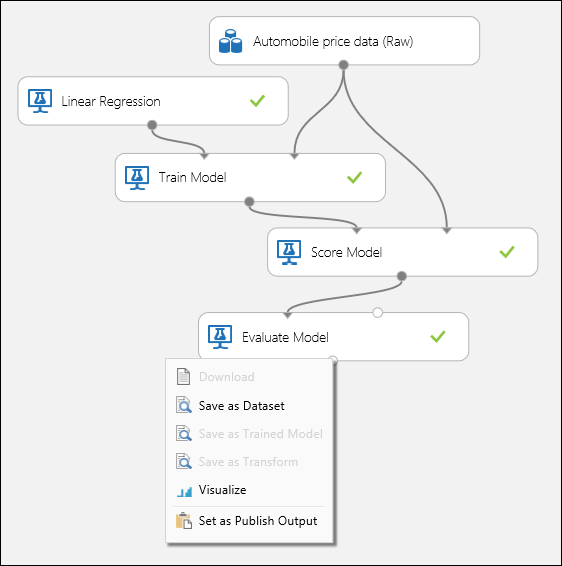
Afbeelding 1. Een regressiemodel evalueren.
De evaluatieresultaten controleren
Nadat u het experiment hebt uitgevoerd, kunt u op de uitvoerpoort van de module Evaluate Model klikken en Visualize selecteren om de evaluatieresultaten te bekijken. De metrische evaluatiegegevens die beschikbaar zijn voor regressiemodellen zijn: Gemiddelde absolute fout, hoofdgemiddelde absolute fout, relatieve absolute fout, relatieve kwadratische fout en de bepalingscoëfficiënt.
De term 'fout' hier vertegenwoordigt het verschil tussen de voorspelde waarde en de werkelijke waarde. De absolute waarde of het kwadraat van dit verschil wordt meestal berekend om de totale grootte van fouten voor alle exemplaren vast te leggen, omdat het verschil tussen de voorspelde en werkelijke waarde in sommige gevallen negatief kan zijn. De metrische foutgegevens meten de voorspellende prestaties van een regressiemodel in termen van de gemiddelde afwijking van de voorspellingen van de werkelijke waarden. Lagere foutwaarden betekenen dat het model nauwkeuriger is bij het maken van voorspellingen. Een algemene foutwaarde van nul betekent dat het model perfect bij de gegevens past.
De bepalingscoëfficiënt, ook wel R kwadraat genoemd, is ook een standaardmethode om te meten hoe goed het model bij de gegevens past. Het kan worden geïnterpreteerd als het aandeel variatie dat door het model wordt uitgelegd. Een hoger aandeel is in dit geval beter, waarbij 1 een perfecte pasvorm aangeeft.
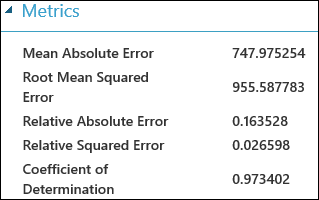
Afbeelding 2. Metrische gegevens voor evaluatie van lineaire regressie.
Kruisvalidatie gebruiken
Zoals eerder vermeld, kunt u automatisch herhaalde training, scoren en evaluaties uitvoeren met behulp van de module Model kruisvalidatie . In dit geval hebt u alleen een gegevensset, een niet-getraind model en een module Model kruisvalidatie nodig (zie onderstaande afbeelding). U moet de labelkolom instellen op prijs in de eigenschappen van de module Model kruisvalideren .
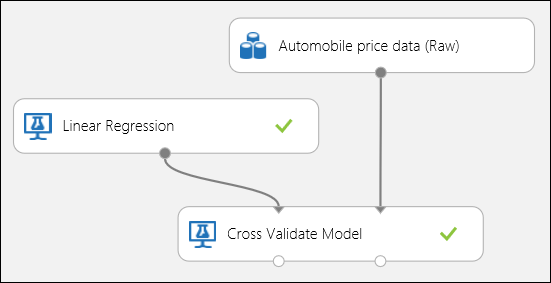
Afbeelding 3. Kruisvalidatie van een regressiemodel.
Nadat u het experiment hebt uitgevoerd, kunt u de evaluatieresultaten inspecteren door op de rechteruitvoerpoort van de module Model kruisvalidatie te klikken. Dit geeft een gedetailleerde weergave van de metrische gegevens voor elke iteratie (vouw) en de gemiddelde resultaten van elk van de metrische gegevens (afbeelding 4).
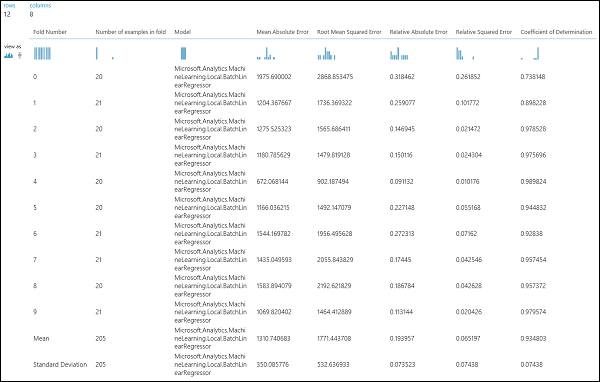
Afbeelding 4: Kruisvalidatieresultaten van een regressiemodel.
Een binair classificatiemodel evalueren
In een binair classificatiescenario heeft de doelvariabele slechts twee mogelijke resultaten, bijvoorbeeld: {0, 1} of {false, true}, {negative, positive}. Stel dat u een gegevensset met volwassen werknemers krijgt met een aantal demografische en werkgelegenheidsvariabelen en dat u wordt gevraagd het inkomensniveau te voorspellen, een binaire variabele met de waarden {"<=50 K", ">50 K"}. Met andere woorden, de negatieve klasse vertegenwoordigt de werknemers die minder dan of gelijk zijn aan 50 K per jaar, en de positieve klasse vertegenwoordigt alle andere werknemers. Net als in het regressiescenario trainen we een model, scoren we enkele gegevens en evalueren we de resultaten. Het belangrijkste verschil hier is de keuze van metrische gegevens die Machine Learning Studio (klassiek) berekenen en uitvoeren. Ter illustratie van het voorspellingsscenario op inkomensniveau gebruiken we de gegevensset Voor volwassenen om een Studio-experiment (klassiek) te maken en de prestaties van een logistiek regressiemodel met twee klassen te evalueren, een veelgebruikte binaire classificatie.
Het experiment maken
Voeg de volgende modules toe aan uw werkruimte in Machine Learning Studio (klassiek):
- Gegevensset Binaire classificatie voor volwassen Census-inkomen
- Logistieke regressie met twee klassen
- Trainingsmodel
- Score Model
- Model evalueren
Verbind de poorten zoals hieronder weergegeven in afbeelding 5 en stel de kolom Label van de module Train Model in op inkomsten.
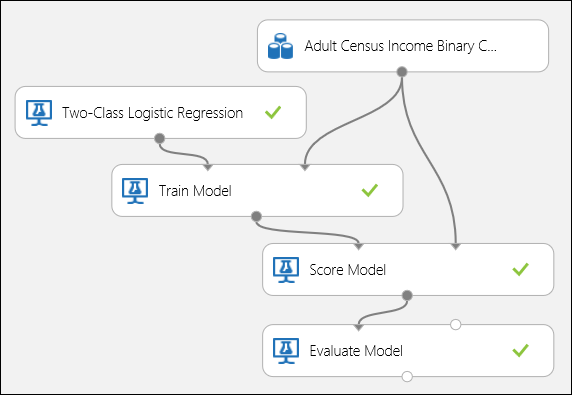
Afbeelding 5. Een binair classificatiemodel evalueren.
De evaluatieresultaten controleren
Nadat u het experiment hebt uitgevoerd, kunt u op de uitvoerpoort van de module Evaluate Model klikken en Visualize selecteren om de evaluatieresultaten te bekijken (afbeelding 7). De metrische evaluatiegegevens die beschikbaar zijn voor binaire classificatiemodellen zijn: Nauwkeurigheid, Precisie, Relevante overeenkomsten, F1 Score en AUC. Daarnaast levert de module een verwarringsmatrix met het aantal terecht-positieven, fout-negatieven, fout-positieven en terecht-negatieven, evenals ROC, Precisie/Relevante overeenkomsten en Lift-curven .
Nauwkeurigheid is gewoon het aandeel correct geclassificeerde exemplaren. Dit is meestal de eerste metrische waarde die u bekijkt bij het evalueren van een classificatie. Wanneer de testgegevens echter niet in balans zijn (waarbij de meeste exemplaren deel uitmaken van een van de klassen), of als u meer geïnteresseerd bent in de prestaties van een van de klassen, wordt de effectiviteit van een classificatie niet echt vastgelegd. In het scenario voor classificatie op inkomensniveau wordt ervan uitgegaan dat u test op sommige gegevens waarbij 99% van de instanties personen vertegenwoordigen die minder dan of gelijk zijn aan 50.000.000 per jaar. Het is mogelijk om een nauwkeurigheid van 0,99 te bereiken door de klasse "<=50K" voor alle exemplaren te voorspellen. De classificatie in dit geval lijkt een goed werk te doen, maar in werkelijkheid kan een van de individuen met een hoog inkomen (de 1%) niet correct worden geclassificeerd.
Daarom is het handig om aanvullende metrische gegevens te berekenen die specifiekere aspecten van de evaluatie vastleggen. Voordat u de details van dergelijke metrische gegevens gaat bekijken, is het belangrijk om de verwarringsmatrix van een binaire classificatie-evaluatie te begrijpen. De klasselabels in de trainingsset kunnen slechts twee mogelijke waarden aannemen, die meestal positief of negatief worden genoemd. De positieve en negatieve exemplaren die een classificatie correct voorspelt, worden respectievelijk terecht-positieven (TP) en terecht-negatieven (TN) genoemd. Op dezelfde manier worden de onjuist geclassificeerde exemplaren fout-positieven (FP) en fout-negatieven (FN) genoemd. De verwarringsmatrix is gewoon een tabel met het aantal exemplaren dat onder elk van deze vier categorieën valt. Machine Learning Studio (klassiek) bepaalt automatisch welke van de twee klassen in de gegevensset de positieve klasse is. Als de klasselabels Booleaanse of gehele getallen zijn, worden de positieve klasse toegewezen aan de 'true' of '1'. Als de labels tekenreeksen zijn, zoals met de inkomstengegevensset, worden de labels alfabetisch gesorteerd en wordt het eerste niveau gekozen als de negatieve klasse terwijl het tweede niveau de positieve klasse is.
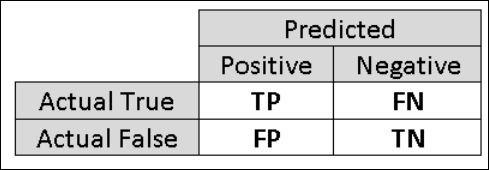
Afbeelding 6. Verwarringsmatrix voor binaire classificatie.
Als we teruggaan naar het probleem met de inkomensclassificatie, willen we verschillende evaluatievragen stellen die ons helpen de prestaties van de gebruikte classificatie te begrijpen. Een natuurlijke vraag is: 'Uit de individuen die het model voorspelde 50 K (TP+FP) te verdienen >, hoeveel zijn er correct geclassificeerd (TP)? Deze vraag kan worden beantwoord door te kijken naar de precisie van het model, wat het aandeel positieven is dat correct is geclassificeerd: TP/(TP+FP). Een andere veelvoorkomende vraag is :"Van alle hoog verdienende werknemers met inkomen >50k (TP+FN), hoeveel heeft de classificatie correct geclassificeerd (TP)". Dit is eigenlijk de relevante waarde of het terecht positieve percentage: TP/(TP+FN) van de classificatie. U merkt misschien dat er sprake is van een duidelijke afweging tussen precisie en relevante overeenkomsten. Als u bijvoorbeeld een relatief evenwichtige gegevensset hebt, zou een classificatie die voornamelijk positieve exemplaren voorspelt, een hoge relevante overeenkomsten hebben, maar een vrij lage precisie omdat veel van de negatieve exemplaren verkeerd zouden worden geclassificeerd, wat resulteert in een groot aantal fout-positieven. Als u een diagram wilt zien van hoe deze twee metrische gegevens variëren, kunt u klikken op de PRECISION/RECALL-curve op de uitvoerpagina van het evaluatieresultaat (linksboven in afbeelding 7).
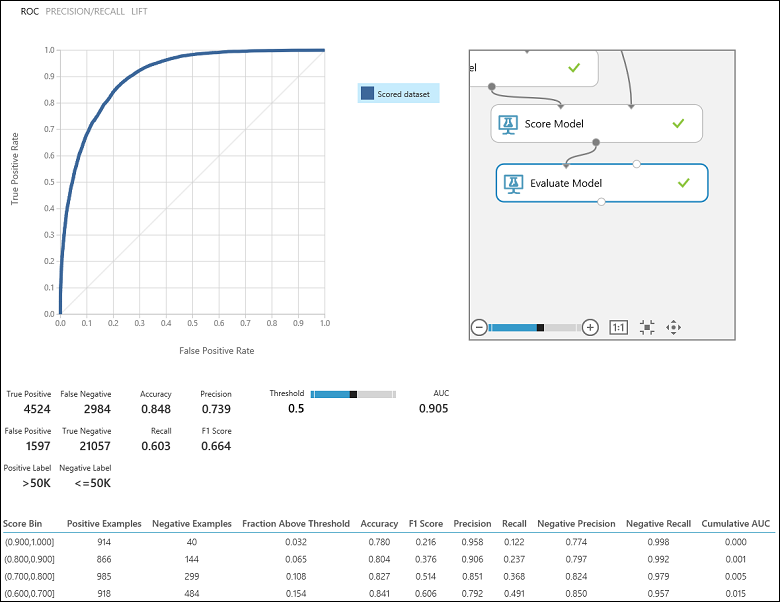
Afbeelding 7. Evaluatieresultaten van binaire classificatie.
Een andere gerelateerde metrische waarde die vaak wordt gebruikt, is de F1-score, die zowel precisie als relevante overeenkomsten in overweging neemt. Het is het harmonische gemiddelde van deze twee metrische gegevens en wordt als zodanig berekend: F1 = 2 (precisie x relevante overeenkomsten) / (precisie + relevante overeenkomsten). De F1-score is een goede manier om de evaluatie in één getal samen te vatten, maar het is altijd een goede gewoonte om te kijken naar zowel precisie als relevante overeenkomsten om beter te begrijpen hoe een classificatie zich gedraagt.
Bovendien kan men de werkelijke positieve snelheid versus de fout-positieve snelheid in de ROC-curve (Receiver Operating Characteristic) en de bijbehorende AUC-waarde (Area Under the Curve) inspecteren. Hoe dichter deze curve zich in de linkerbovenhoek bevindt, hoe beter de prestaties van de classificatie zijn (dat de werkelijke positieve snelheid maximaliseert terwijl de fout-positieve snelheid wordt geminimaliseerd). Curven die zich dicht bij de diagonaal van het diagram bevinden, zijn het resultaat van classificaties die vaak voorspellingen doen die dicht bij willekeurige schattingen liggen.
Kruisvalidatie gebruiken
Net als in het regressievoorbeeld kunnen we kruisvalidatie uitvoeren om verschillende subsets van de gegevens automatisch te trainen, beoordelen en evalueren. Op dezelfde manier kunnen we de module Cross-Validate Model, een niet-getraind logistiek regressiemodel en een gegevensset gebruiken. De labelkolom moet worden ingesteld op inkomsten in de eigenschappen van de module Model kruisvalideren . Nadat u het experiment hebt uitgevoerd en op de rechteruitvoerpoort van de module Model kruisvalidatie hebt geklikt, zien we de metrische waarden voor binaire classificatie voor elke vouw, naast het gemiddelde en de standaarddeviatie van elke module.
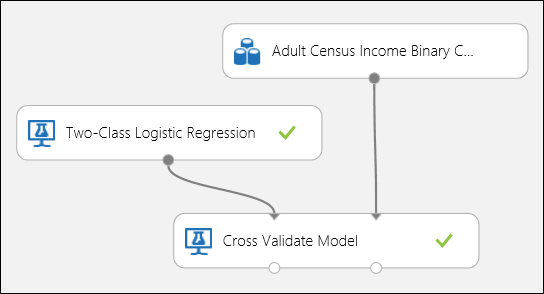
Afbeelding 8. Kruisvalidatie van een binair classificatiemodel.
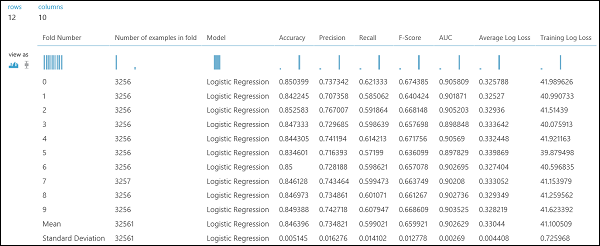
Afbeelding 9. Kruisvalidatieresultaten van een binaire classificatie.
Een classificatiemodel met meerdere klassen evalueren
In dit experiment gebruiken we de populaire Iris-gegevensset , die exemplaren van drie verschillende typen (klassen) van de irisplant bevat. Er zijn vier functiewaarden (sepal length/width en petal length/width) voor elk exemplaar. In de vorige experimenten hebben we de modellen getraind en getest met dezelfde gegevenssets. Hier gebruiken we de module Split Data om twee subsets van de gegevens te maken, te trainen op de eerste en score en te evalueren op de tweede. De Iris-gegevensset is openbaar beschikbaar in de UCI Machine Learning-opslagplaats en kan worden gedownload met behulp van een importgegevensmodule .
Het experiment maken
Voeg de volgende modules toe aan uw werkruimte in Machine Learning Studio (klassiek):
- Gegevens importeren
- Beslissingsforest met meerdere klassen
- Gegevens splitsen
- Trainingsmodel
- Score Model
- Model evalueren
Verbind de poorten zoals hieronder wordt weergegeven in afbeelding 10.
Stel de kolomindex Label van de module Train Model in op 5. De gegevensset heeft geen veldnamenrij, maar we weten dat de klasselabels zich in de vijfde kolom bevinden.
Klik op de module Gegevens importeren en stel de eigenschap Gegevensbronin op web-URL via HTTP en de URL op http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Stel het deel van exemplaren in dat moet worden gebruikt voor training in de module Split Data (bijvoorbeeld 0,7).
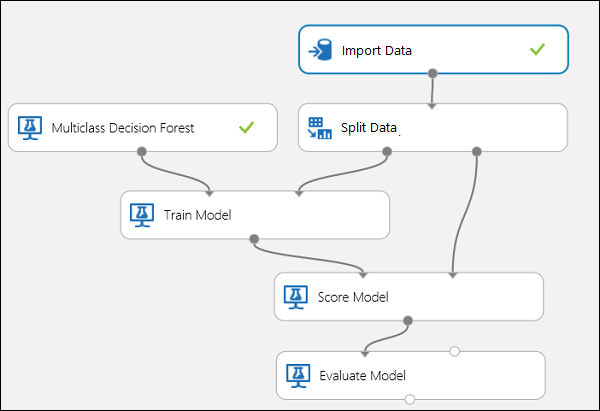
Afbeelding 10. Een classificatie met meerdere klassen evalueren
De evaluatieresultaten controleren
Voer het experiment uit en klik op de uitvoerpoort van Evaluate Model. De evaluatieresultaten worden weergegeven in de vorm van een verwarringsmatrix, in dit geval. De matrix toont de werkelijke versus voorspelde exemplaren voor alle drie klassen.
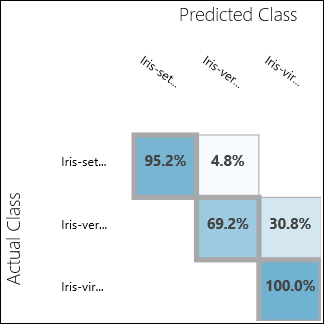
Afbeelding 11. Evaluatieresultaten van classificatie met meerdere klassen.
Kruisvalidatie gebruiken
Zoals eerder vermeld, kunt u automatisch herhaalde training, scoren en evaluaties uitvoeren met behulp van de module Model kruisvalidatie . U hebt een gegevensset, een niet-getraind model en een module Model kruisvalidatie nodig (zie de onderstaande afbeelding). Ook hier moet u de labelkolom van de module Model kruisvalidatie (kolomindex 5 in dit geval) instellen. Nadat u het experiment hebt uitgevoerd en op de rechteruitvoerpoort van het model kruisvalidatie hebt geklikt, kunt u de metrische waarden voor elke vouw en de gemiddelde en standaarddeviatie controleren. De hier weergegeven metrische gegevens zijn vergelijkbaar met de metrische gegevens die in het binaire classificatiescenario worden besproken. In classificatie met meerdere klassen wordt het berekenen van de terecht-positieven/negatieven en fout-positieven/negatieven echter uitgevoerd door per klasse te tellen, omdat er geen algemene positieve of negatieve klasse is. Bij het berekenen van de precisie of relevante overeenkomsten van de klasse Iris-setosa wordt er bijvoorbeeld van uitgegaan dat dit de positieve klasse is en alle andere als negatief.
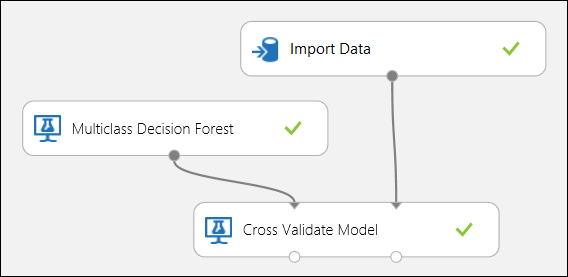
Afbeelding 12. Kruisvalidatie van een classificatiemodel met meerdere klassen.
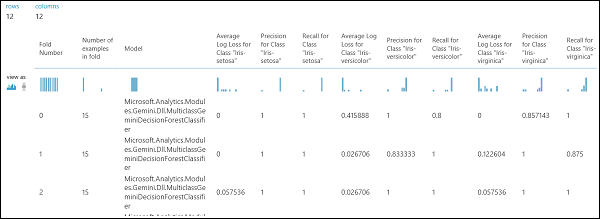
Afbeelding 13. Kruisvalidatieresultaten van een classificatiemodel met meerdere klassen.