Time Series Insights (TSI) Gen2 migreren naar Azure Data Explorer
Notitie
De Time Series Insights-service (TSI) wordt na maart 2025 niet meer ondersteund. Overweeg om bestaande TSI-omgevingen zo snel mogelijk naar alternatieve oplossingen te migreren. Raadpleeg onze documentatie voor meer informatie over de afschaffing en migratie.
Overzicht
Aanbevelingen voor migratie op hoog niveau.
| Functie | Gen2-status | Migratie aanbevolen |
|---|---|---|
| JSON opnemen vanuit Hub met platmaken en ontsnappen | TSI-opname | ADX - OneClick Opnemen /Wizard |
| Koude opslag openen | Klantopslagaccount | Continue gegevensexport naar de door de klant opgegeven externe tabel in ADLS. |
| PBI-Verbinding maken or | Privé-voorbeeld | Gebruik ADX PBI Verbinding maken or. Herschrijf TSQ handmatig naar KQL. |
| Spark-connector | Beperkte preview. Query's uitvoeren op telemetriegegevens. Query's uitvoeren op modelgegevens. | Gegevens migreren naar ADX. AdX Spark-connector gebruiken voor telemetriegegevens en exportmodel naar JSON en laden in Spark. Query's herschrijven in KQL. |
| Bulksgewijs uploaden | Privé-voorbeeld | Gebruik ADX OneClick Ingest en LightIngest. U kunt desgewenst partitionering instellen in ADX. |
| Time Series-model | Kan worden geëxporteerd als JSON-bestand. Kan worden geïmporteerd in ADX om joins uit te voeren in KQL. | |
| TSI-verkenner | Warm en koud schakelen | ADX-dashboards |
| Querytaal | Time Series-query's (TSQ) | Query's herschrijven in KQL. Gebruik Kusto-SDK's in plaats van TSI-SDK's. |
Telemetrie migreren
Gebruik PT=Time de map in het opslagaccount om de kopie van alle telemetriegegevens in de omgeving op te halen. Zie Data Storage voor meer informatie.
Migratie stap 1: statistieken over telemetriegegevens ophalen
Gegevens
- Overzicht van Env
- Record Environment ID from first part of Data Access FQDN (bijvoorbeeld d390b0b0-1445-4c0c-8365-68d6382c1c2a From .env.crystal-dev.windows-int.net)
- Overzicht van Env -> Opslagconfiguratie -> Opslagaccount
- Storage Explorer gebruiken om mapstatistieken op te halen
- Recordgrootte en het aantal blobs van
PT=Timede map. Voor klanten in de privé-preview van bulkimport moet u ook de grootte en het aantal blobs opnemenPT=Import.
- Recordgrootte en het aantal blobs van
Migratie stap 2: Telemetrie migreren naar ADX
ADX-cluster maken
Definieer de clustergrootte op basis van de gegevensgrootte met behulp van de ADX Cost Estimator.
- Haal vanuit metrische gegevens van Event Hubs (of IoT Hub) de snelheid op van de hoeveelheid gegevens die per dag worden opgenomen. Haal vanuit het opslagaccount dat is verbonden met de TSI-omgeving op hoeveel gegevens er zijn in de blobcontainer die wordt gebruikt door TSI. Deze informatie wordt gebruikt om de ideale grootte van een ADX-cluster voor uw omgeving te berekenen.
- Open de Azure Data Explorer Cost Estimator en vul de bestaande velden in met de gevonden informatie. Stel 'Workloadtype' in als 'Geoptimaliseerd voor opslag' en 'Dynamische gegevens' met de totale hoeveelheid gegevens die actief wordt opgevraagd.
- Nadat u alle informatie hebt opgegeven, stelt Azure Data Explorer Cost Estimator een VM-grootte en het aantal exemplaren voor uw cluster voor. Analyseer of de grootte van actief opgevraagde gegevens past in de Hot Cache. Vermenigvuldig het aantal exemplaren dat wordt voorgesteld door de cachegrootte van de VM-grootte, per voorbeeld:
- Suggestie voor kostenschatter: 9x DS14 + 4 TB (cache)
- Totaal aantal hot-caches voorgesteld: 36 TB = [9x (instanties) x 4 TB (hot cache per knooppunt)]
- Meer factoren om rekening mee te houden:
- Omgevingsgroei: bij het plannen van de ADX-clustergrootte wordt rekening gehouden met de groei van de gegevens in de loop van de tijd.
- Hydratatie en partitionering: bij het definiëren van het aantal exemplaren in ADX-cluster kunt u extra knooppunten (met 2-3x) overwegen om hydratatie en partitionering te versnellen.
- Zie De juiste reken-SKU voor uw Azure Data Explorer-cluster selecteren voor meer informatie over rekenselectie.
Als u uw cluster en de gegevensopname het beste wilt bewaken, moet u diagnostische Instellingen inschakelen en de gegevens verzenden naar een Log Analytics-werkruimte.
Ga op de blade Azure Data Explorer naar Bewaking | Diagnostische instellingen' en klik op Diagnostische instelling toevoegen
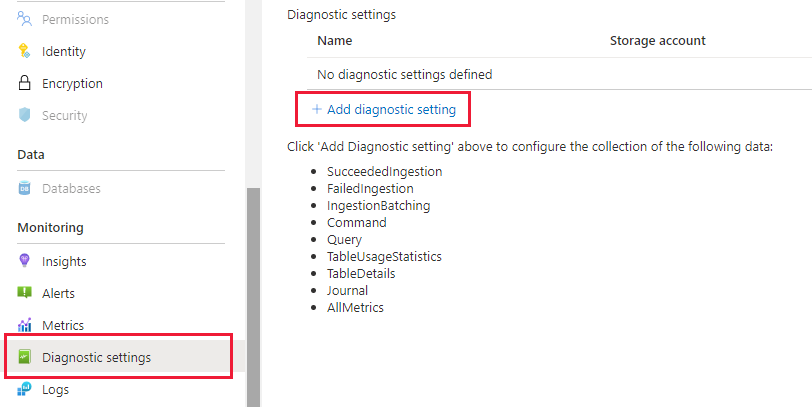
Vul het volgende in
- Naam van diagnostische instelling: Weergavenaam voor deze configuratie
- Logboeken: Selecteer minimaal SucceededIngestion, FailedIngestion, IngestionBatching
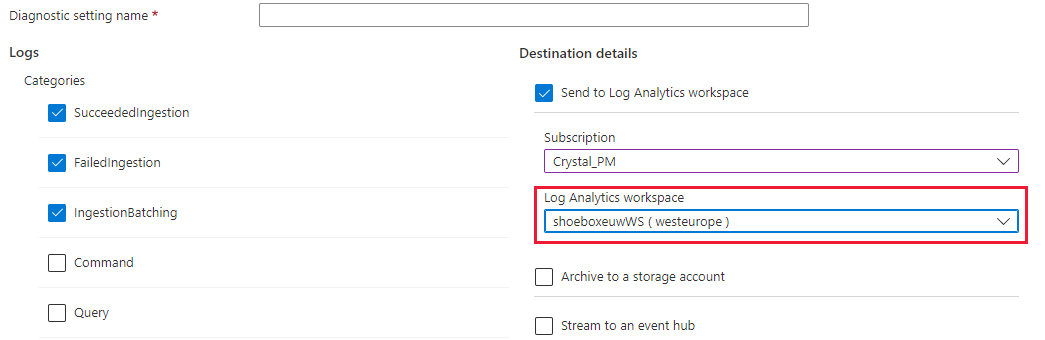
- Selecteer de Log Analytics-werkruimte waarnaar u de gegevens wilt verzenden (als u er nog geen hebt, moet u er vóór deze stap een inrichten)
Gegevenspartitionering.
- Voor de meeste gegevenssets is de standaard ADX-partitionering voldoende.
- Gegevenspartitionering is nuttig in een zeer specifieke set scenario's en moet anders niet worden toegepast:
- De querylatentie in big data-sets verbeteren waarbij de meeste query's filteren op een kolom met tekenreeksen met hoge kardinaliteit, bijvoorbeeld een tijdreeks-id.
- Bij het opnemen van verouderde gegevens, bijvoorbeeld wanneer gebeurtenissen uit het verleden dagen of weken na de generatie in de oorsprong kunnen worden opgenomen.
- Raadpleeg het ADX-beleid voor gegevenspartitionering voor meer informatie.


Voorbereiden op gegevensopname
Ga naar https://dataexplorer.azure.com.
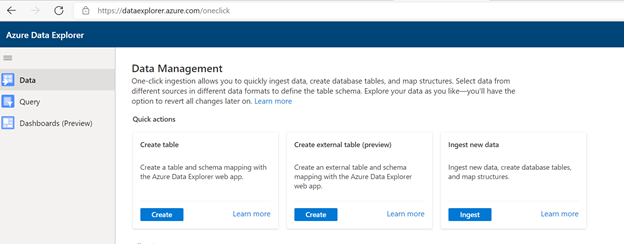
Ga naar het tabblad Gegevens en selecteer 'Opnemen uit blobcontainer'
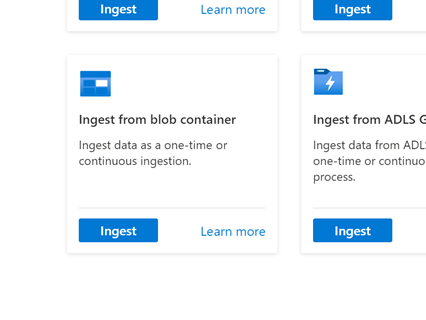
Selecteer Cluster, Database en maak een nieuwe tabel met de naam die u kiest voor de TSI-gegevens
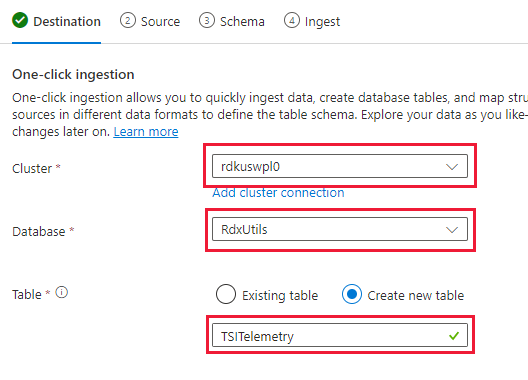
Volgende selecteren: Bron
Selecteer op het tabblad Bron:
- Historische gegevens
- "Container selecteren"
- Kies het abonnements- en opslagaccount voor uw TSI-gegevens
- Kies de container die overeenkomt met uw TSI-omgeving
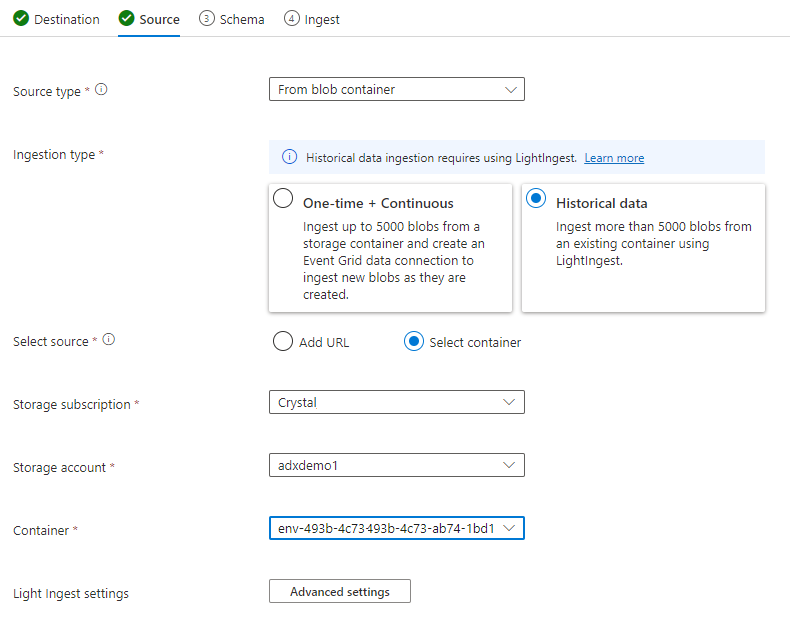
Selecteren op Geavanceerde instellingen
- Patroon voor aanmaaktijd: '/'yyyyMMMdHHmmssfff'_'
- Blob-naampatroon: *.parquet
- Selecteer 'Wacht niet totdat de opname is voltooid'
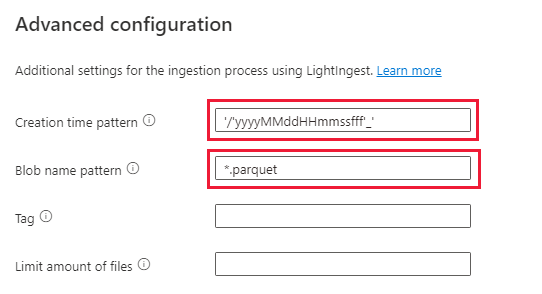
Voeg onder Bestandsfilters het mappad toe
V=1/PT=Time
Volgende selecteren: Schema
Notitie
TSI past wat afvlakken en ontsnappen toe bij het persistent maken van kolommen in Parquet-bestanden. Zie deze koppelingen voor meer informatie: platmaken en ontsnappen aan regels, opnameregels bijwerken.






Als het schema onbekend of varieert
Verwijder alle kolommen die niet vaak worden opgevraagd, waarbij ten minste een tijdstempel en TSID-kolom(en) worden achtergelaten.

Voeg een nieuwe kolom van het dynamische type toe en wijs deze toe aan de hele record met behulp van $-pad.
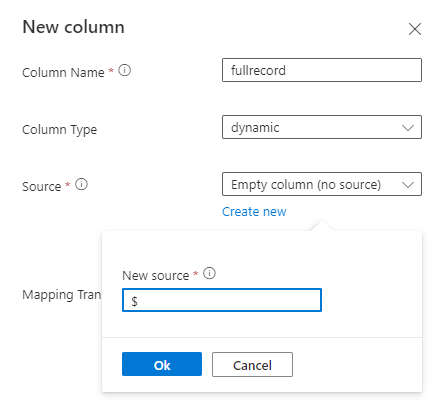
Voorbeeld:
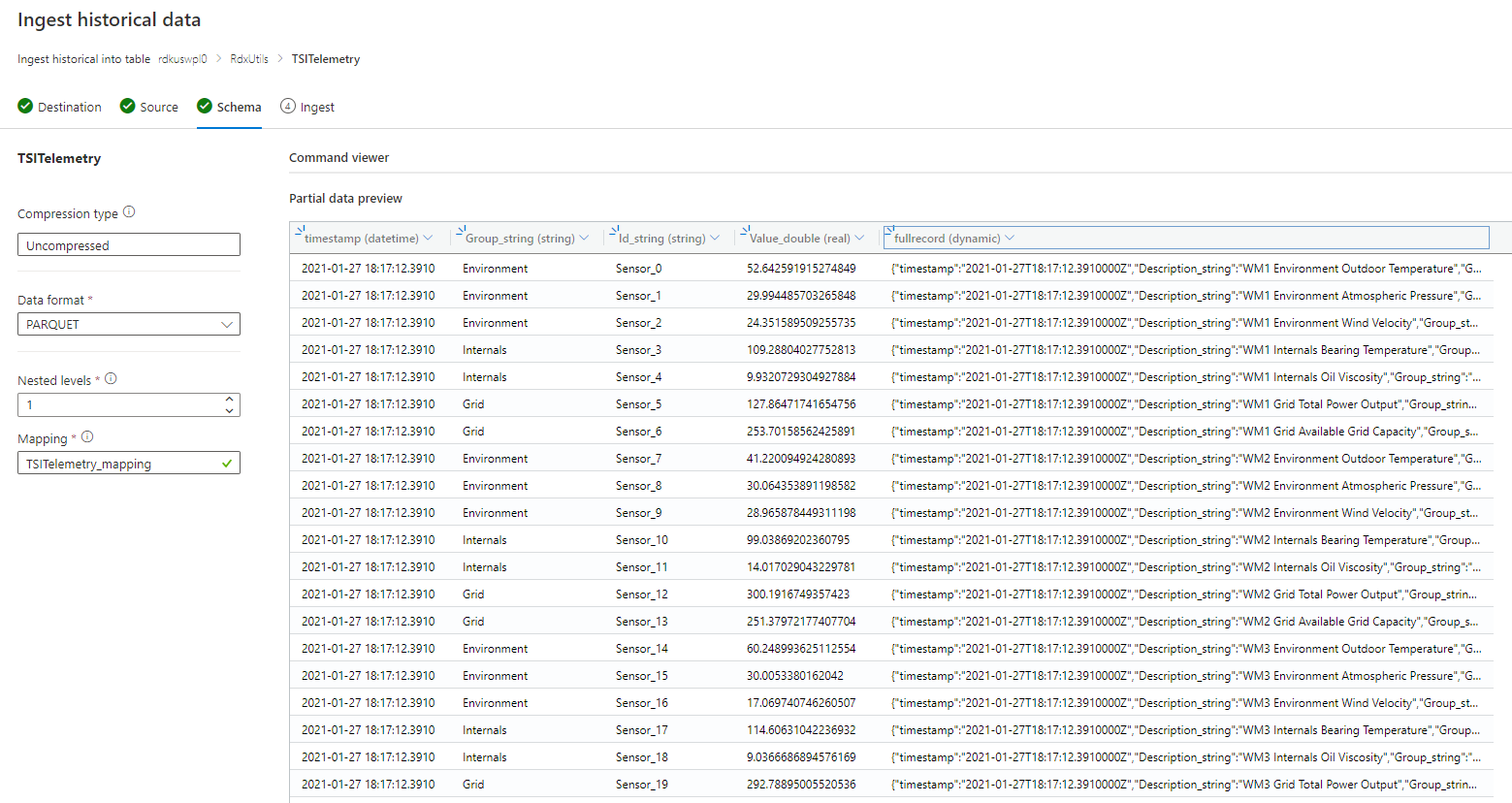
Als het schema bekend of vast is
- Controleer of de gegevens er juist uitzien. Corrigeer indien nodig alle typen.
- Volgende selecteren: Samenvatting



Kopieer de LightIngest-opdracht en sla deze ergens op, zodat u deze in de volgende stap kunt gebruiken.

Gegevensopname
Voordat u gegevens opneemt, moet u het LightIngest-hulpprogramma installeren. De opdracht die is gegenereerd op basis van het hulpprogramma One-Click bevat een SAS-token. U kunt het beste een nieuwe genereren, zodat u controle hebt over de verlooptijd. Navigeer in de portal naar de Blob-container voor de TSI-omgeving en selecteer 'Gedeeld toegangstoken'

Notitie
Het wordt ook aanbevolen om uw cluster omhoog te schalen voordat u een grote opname start. Bijvoorbeeld D14 of D32 met 8+ exemplaren.
Stel het volgende in
- Machtigingen: lezen en weergeven
- Verloopdatum: Ingesteld op een periode waarvan u zeker weet dat de migratie van gegevens is voltooid
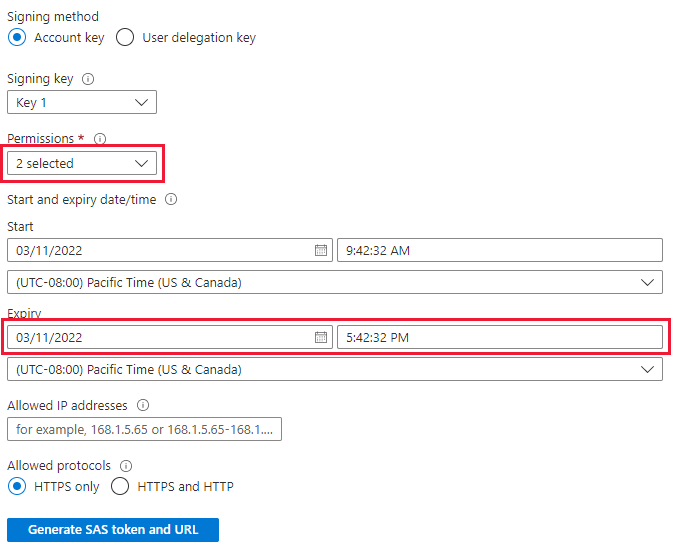
Selecteer 'SAS-token en URL genereren' en kopieer de 'BLob SAS-URL'

Ga naar de LightIngest-opdracht die u eerder hebt gekopieerd. Vervang de parameter -source in de opdracht door deze 'SAS Blob URL'
Optie 1: Alle gegevens opnemen. Voor kleinere omgevingen kunt u alle gegevens opnemen met één opdracht.
- Open een opdrachtprompt en ga naar de map waarin het LightIngest-hulpprogramma is geëxtraheerd. Plak daar de LightIngest-opdracht en voer deze uit.

Optie 2: Gegevens opnemen per jaar of maand. Voor grotere omgevingen of om te testen op een kleinere gegevensset kunt u de opdracht Lightingest verder filteren.
Per jaar: de parameter -voorvoegsel wijzigen
- Voor:
-prefix:"V=1/PT=Time" - Na:
-prefix:"V=1/PT=Time/Y=<Year>" - Voorbeeld:
-prefix:"V=1/PT=Time/Y=2021"
- Voor:
Per maand: de parameter -voorvoegsel wijzigen
- Voor:
-prefix:"V=1/PT=Time" - Na:
-prefix:"V=1/PT=Time/Y=<Year>/M=<month #>" - Voorbeeld:
-prefix:"V=1/PT=Time/Y=2021/M=03"
- Voor:



Nadat u de opdracht hebt gewijzigd, voert u deze uit zoals hierboven. Een van de opnames is voltooid (met behulp van de onderstaande bewakingsoptie) wijzigt u de opdracht voor het volgende jaar en de maand die u wilt opnemen.
Opname bewaken
De LightIngest-opdracht bevatte de vlag -dontWait, zodat de opdracht zelf niet wacht totdat de opname is voltooid. De beste manier om de voortgang te controleren terwijl dit gebeurt, is door het tabblad Inzichten in de portal te gebruiken. Open de sectie van het Azure Data Explorer-cluster in de portal en ga naar Bewaking | Inzichten'

U kunt de sectie 'Opname (preview)' met de onderstaande instellingen gebruiken om de opname te controleren terwijl deze plaatsvindt
- Tijdsbereik: Afgelopen 30 minuten
- Kijken naar geslaagd en op tabel
- Als er fouten zijn, bekijkt u Mislukt en per tabel
U weet dat de opname is voltooid zodra de metrische gegevens naar 0 voor uw tabel gaan. Als u meer informatie wilt zien, kunt u Log Analytics gebruiken. Selecteer in de sectie Azure Data Explorer-cluster de optie op het tabblad Logboek:

Nuttige query's
Schema begrijpen als dynamisch schema wordt gebruikt
| project p=treepath(fullrecord)
| mv-expand p
| summarize by tostring(p)
Toegang tot waarden in matrix
| where id_string == "a"
| summarize avg(todouble(fullrecord.['nestedArray_v_double'])) by bin(timestamp, 1s)
| render timechart
Time Series-model (TSM) migreren naar Azure Data Explorer
Het model kan worden gedownload in JSON-indeling vanuit TSI Environment met behulp van TSI Explorer UX of TSM Batch API. Vervolgens kan het model worden geïmporteerd in een ander systeem, zoals Azure Data Explorer.
Download TSM van TSI UX.
Verwijder de eerste drie regels met BEHULP van VSCode of een andere editor.
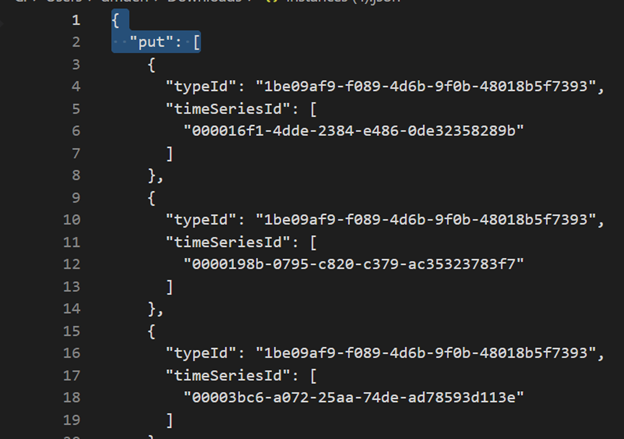
VsCode of een andere editor gebruiken, zoeken en vervangen als regex
\},\n \{door}{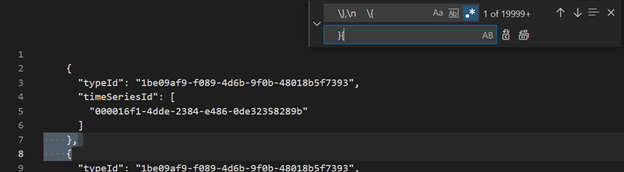
Opnemen als JSON in ADX als een afzonderlijke tabel met uploaden vanuit bestandsfunctionaliteit.



Time Series-query's (TSQ) vertalen naar KQL
GetEvents
{
"getEvents": {
"timeSeriesId": [
"assest1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where assetId_string == "assest1" and siteId_string == "siteId1" and dataid_string == "dataId1"
| take 10000
GetEvents met filter
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'status' AND $event.sensors.unit.String = 'ONLINE"
}
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| where ['sensors.sensor_string'] == "status" and ['sensors.unit_string'] == "ONLINE"
| take 10000
GetEvents met projected variable
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
"projectedVariables": [],
"projectedProperties": [
{
"name": "sensors.value",
"type": "String"
},
{
"name": "sensors.value",
"type": "bool"
},
{
"name": "sensors.value",
"type": "Double"
}
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| take 10000
| project timestamp, sensorStringValue= ['sensors.value_string'], sensorBoolValue= ['sensors.value_bool'], sensorDoublelValue= ['sensors.value_double']
AggregateSeries
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
AggregateSeries met filter
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'heater' AND $event.sensors.location.String = 'floor1room12'"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| where ['sensors.sensor_string'] == "heater" and ['sensors.location_string'] == "floor1room12"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
Migratie van TSI Power BI Verbinding maken or naar ADX Power BI Verbinding maken or
De handmatige stappen voor deze migratie zijn
- Power BI-query converteren naar TSQ
- TSQ converteren naar KQL Power BI-query naar TSQ: De Power BI-query die is gekopieerd uit TSI UX Explorer ziet er als volgt uit zoals hieronder wordt weergegeven
Voor onbewerkte gegevens (GetEvents-API)
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"getEvents":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"take":250000}}]}
- Als u deze wilt converteren naar TSQ, bouwt u een JSON op basis van de bovenstaande nettolading. De GetEvents-API-documentatie bevat ook voorbeelden om deze beter te begrijpen. Query - Uitvoeren - REST API (Azure Time Series Insights) | Microsoft Docs
- De geconverteerde TSQ ziet er als volgt uit. Dit is de JSON-nettolading in 'query's'
{
"getEvents": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"take": 250000
}
}
Voor Aggradate Data (Aggregate Series API)
- Voor één inlinevariabele ziet PowerBI-query uit TSI UX Explorer er als volgt uit:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com", "queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}]}
- Als u deze wilt converteren naar TSQ, bouwt u een JSON op basis van de bovenstaande nettolading. De documentatie van de AggregateSeries-API bevat ook voorbeelden om deze beter te begrijpen. Query - Uitvoeren - REST API (Azure Time Series Insights) | Microsoft Docs
- De geconverteerde TSQ ziet er als volgt uit. Dit is de JSON-nettolading in 'query's'
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
}
},
"projectedVariables": [
"EventCount",
]
}
}
- Voor meer dan één inlinevariabele voegt u de json toe aan 'inlineVariables', zoals wordt weergegeven in het onderstaande voorbeeld. De Power BI-query voor meer dan één inlinevariabele ziet er als volgt uit:
{"storeType":"ColdStore","isSearchSpanRelative":false,"clientDataType":"RDX_20200713_Q","environmentFqdn":"6988946f-2b5c-4f84-9921-530501fbab45.env.timeseries.azure.com","queries":[{"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"EventCount":{"kind":"aggregate","aggregation":{"tsx":"count()"}}},"projectedVariables":["EventCount"]}}, {"aggregateSeries":{"searchSpan":{"from":"2019-10-31T23:59:39.590Z","to":"2019-11-01T05:22:18.926Z"},"timeSeriesId":["Arctic Ocean",null],"interval":"PT1M", "inlineVariables":{"Magnitude":{"kind":"numeric","value":{"tsx":"$event['mag'].Double"},"aggregation":{"tsx":"max($value)"}}},"projectedVariables":["Magnitude"]}}]}
{
"aggregateSeries": {
"timeSeriesId": [
"Arctic Ocean",
"null"
],
"searchSpan": {
"from": "2019-10-31T23:59:39.590Z",
"to": "2019-11-01T05:22:18.926Z"
},
"interval": "PT1M",
"inlineVariables": {
"EventCount": {
"kind": "aggregate",
"aggregation": {
"tsx": "count()"
}
},
"Magnitude": {
"kind": "numeric",
"value": {
"tsx": "$event['mag'].Double"
},
"aggregation": {
"tsx": "max($value)"
}
}
},
"projectedVariables": [
"EventCount",
"Magnitude",
]
}
}
- Als u een query wilt uitvoeren op de meest recente gegevens("isSearchSpanRelative": true), berekent u handmatig de searchSpan zoals hieronder wordt vermeld
- Zoek het verschil tussen 'van' en 'naar' van de Nettolading van Power BI. Laten we dat verschil noemen als 'D' waarbij "D" = "from" - "to"
- Neem de huidige tijdstempel("T") en trek het verschil af dat u in de eerste stap hebt verkregen. Het is nieuw "from"(F) van searchSpan waarbij "F" = "T" - "D"
- De nieuwe 'van' is nu 'F' verkregen in stap 2 en nieuw 'aan' is 'T' (huidige tijdstempel)