Relationele versus NoSQL-gegevens
Tip
Deze inhoud is een fragment uit het eBook, Cloud Native .NET Applications for Azure ontwerpen, beschikbaar op .NET Docs of als een gratis downloadbare PDF die offline kan worden gelezen.

Relationele en NoSQL zijn twee typen databasesystemen die vaak worden geïmplementeerd in cloudeigen apps. Ze zijn anders gebouwd, slaan gegevens anders op en worden anders geopend. In deze sectie bekijken we beide. Verderop in dit hoofdstuk bekijken we een opkomende databasetechnologie met de naam NewSQL.
Relationele databases zijn al decennia lang een veelgebruikte technologie. Ze zijn volwassen, bewezen en veel geïmplementeerd. Concurrerende databaseproducten, hulpprogramma's en expertise zijn afhankelijk. Relationele databases bieden een archief met gerelateerde gegevenstabellen. Deze tabellen hebben een vast schema, gebruiken SQL (Structured Query Language) voor het beheren van gegevens en bieden ondersteuning voor ACID-garanties.
No-SQL-databases verwijzen naar hoogwaardige, niet-relationele gegevensarchieven. Ze excelleren in hun gebruiksgemak, schaalbaarheid, tolerantie en beschikbaarheidskenmerken. In plaats van tabellen met genormaliseerde gegevens samen te voegen, slaat NoSQL ongestructureerde of semi-gestructureerde gegevens op, vaak in sleutel-waardeparen of JSON-documenten. No-SQL-databases bieden doorgaans geen ACID-garanties buiten het bereik van één databasepartitie. Voor services met een hoog volume waarvoor een reactietijd van een sub tweede nodig is, is het gunstig voor NoSQL-gegevensarchieven.
De impact van NoSQL-technologieën voor gedistribueerde cloudeigen systemen kan niet worden overdreven. De verspreiding van nieuwe gegevenstechnologieën in deze ruimte heeft oplossingen verstoord die eenmaal uitsluitend afhankelijk waren van relationele databases.
NoSQL-databases bevatten verschillende modellen voor het openen en beheren van gegevens, die elk geschikt zijn voor specifieke use cases. Afbeelding 5-9 bevat vier algemene modellen.
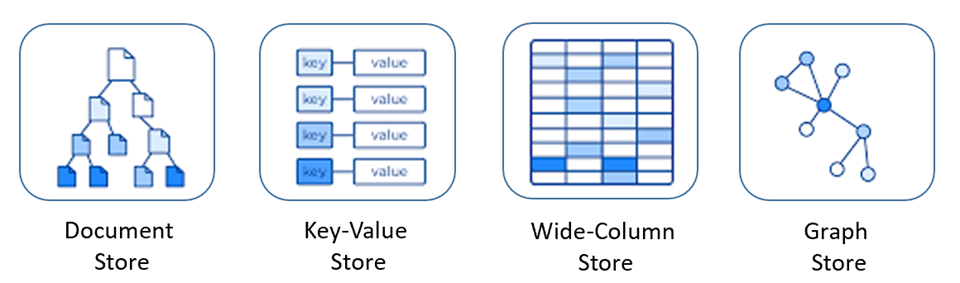
Afbeelding 5-9: Gegevensmodellen voor NoSQL-databases
| Model | Kenmerken |
|---|---|
| Documentarchief | Gegevens en metagegevens worden hiërarchisch opgeslagen in op JSON gebaseerde documenten in de database. |
| Sleutelwaardearchief | De eenvoudigste van de NoSQL-databases, gegevens worden weergegeven als een verzameling sleutel-waardeparen. |
| Archief met brede kolommen | Gerelateerde gegevens worden opgeslagen als een set geneste sleutel-waardeparen binnen één kolom. |
| Grafiekarchief | Gegevens worden opgeslagen in een grafiekstructuur als knooppunt-, edge- en gegevenseigenschappen. |
De CAP Theorem
Als een manier om inzicht te hebben in de verschillen tussen deze typen databases, moet u rekening houden met het CAP-theorema, een set principes die worden toegepast op gedistribueerde systemen die de status opslaan. Afbeelding 5-10 toont de drie eigenschappen van het CAP-theorema.

Afbeelding 5-10. De CAP Theorem
De theorema geeft aan dat gedistribueerde gegevenssystemen een afweging zullen bieden tussen consistentie, beschikbaarheid en partitietolerantie. En dat elke database slechts twee van de drie eigenschappen kan garanderen:
Consistentie. Elk knooppunt in het cluster reageert met de meest recente gegevens, zelfs als het systeem de aanvraag moet blokkeren totdat alle replica's zijn bijgewerkt. Als u een query uitvoert op een 'consistent systeem' voor een item dat momenteel wordt bijgewerkt, wacht u op dat antwoord totdat alle replica's zijn bijgewerkt. U ontvangt echter de meest recente gegevens.
Beschikbaarheid. Elk knooppunt retourneert een direct antwoord, zelfs als dat antwoord niet de meest recente gegevens is. Als u een query uitvoert op een 'beschikbaar systeem' voor een item dat wordt bijgewerkt, krijgt u het best mogelijke antwoord dat de service op dat moment kan bieden.
Partitietolerantie. Garandeert dat het systeem blijft werken, zelfs als een gerepliceerd gegevensknooppunt mislukt of de verbinding met andere gerepliceerde gegevensknooppunten verliest.
CAP-theorema legt de compromissen uit die verband houden met het beheren van consistentie en beschikbaarheid tijdens een netwerkpartitie; met betrekking tot consistentie en prestaties bestaan er echter ook compromissen met betrekking tot de afwezigheid van een netwerkpartitie. CAP-theorema wordt vaak verder uitgebreid naar PACELC om de compromissen uitgebreider uit te leggen.
Relationele databases bieden doorgaans consistentie en beschikbaarheid, maar geen partitietolerantie. Ze worden doorgaans ingericht op één server en verticaal geschaald door meer resources aan de machine toe te voegen.
Veel relationele databasesystemen ondersteunen ingebouwde replicatiefuncties waarbij kopieën van de primaire database kunnen worden gemaakt naar andere secundaire serverexemplaren. Schrijfbewerkingen worden uitgevoerd naar het primaire exemplaar en gerepliceerd naar elk van de secundaire bestanden. Bij een fout kan de primaire instantie een failover naar een secundair exemplaar uitvoeren om hoge beschikbaarheid te bieden. Secundaire bestanden kunnen ook worden gebruikt om leesbewerkingen te distribueren. Schrijfbewerkingen gaan altijd tegen de primaire replica, maar leesbewerkingen kunnen worden doorgestuurd naar een van de secundaire bestanden om de systeembelasting te verminderen.
Gegevens kunnen ook horizontaal worden gepartitioneerd over meerdere knooppunten, zoals met sharding. Maar sharding verhoogt de operationele overhead aanzienlijk door gegevens over veel stukken te spugen die niet eenvoudig kunnen communiceren. Het kan kostbaar en tijdrovend zijn om te beheren. Voor relationele functies met tabeldeelnames, transacties en referentiële integriteit zijn steile prestatiestraffen in shard-implementaties vereist.
Replicatieconsistentie- en herstelpuntdoelstellingen kunnen worden afgestemd door te configureren of replicatie synchroon of asynchroon plaatsvindt. Als gegevensreplica's netwerkconnectiviteit zouden verliezen in een 'zeer consistent' of synchroon relationeel databasecluster, zou u niet naar de database kunnen schrijven. Het systeem weigert de schrijfbewerking omdat deze wijziging niet kan worden gerepliceerd naar de andere gegevensreplica. Elke gegevensreplica moet worden bijgewerkt voordat de transactie kan worden voltooid.
NoSQL-databases ondersteunen doorgaans hoge beschikbaarheid en partitietolerantie. Ze worden horizontaal uitgeschaald, vaak op basisservers. Deze aanpak biedt een enorme beschikbaarheid, zowel binnen als tussen geografische regio's, tegen lagere kosten. U partitionert en repliceert gegevens op deze computers of knooppunten, waardoor redundantie en fouttolerantie worden geboden. Consistentie wordt doorgaans afgestemd via consensusprotocollen of quorummechanismen. Ze bieden meer controle bij het navigeren door compromissen tussen het afstemmen van synchrone versus asynchrone replicatie in relationele systemen.
Als gegevensreplica's de connectiviteit in een NoSQL-databasecluster met hoge beschikbaarheid zouden verliezen, kunt u nog steeds een schrijfbewerking naar de database voltooien. Het databasecluster staat de schrijfbewerking toe en werkt elke gegevensreplica bij naarmate deze beschikbaar is. NoSQL-databases die ondersteuning bieden voor meerdere beschrijfbare replica's, kunnen de hoge beschikbaarheid verder versterken door failover te voorkomen bij het optimaliseren van de beoogde hersteltijd.
Moderne NoSQL-databases implementeren doorgaans partitioneringsmogelijkheden als een functie van hun systeemontwerp. Partitiebeheer is vaak ingebouwd in de database en routering wordt bereikt via plaatsingshints, ook wel partitiesleutels genoemd. Met een flexibele gegevensmodellen kunnen noSQL-databases de belasting van schemabeheer verlagen en de beschikbaarheid verbeteren bij het implementeren van toepassingsupdates waarvoor wijzigingen in het gegevensmodel zijn vereist.
Hoge beschikbaarheid en enorme schaalbaarheid zijn vaak belangrijker voor het bedrijf dan relationele tabeldeelnames en referentiële integriteit. Ontwikkelaars kunnen technieken en patronen zoals Sagas, CQRS en asynchrone berichten implementeren om uiteindelijke consistentie te omarmen.
Tegenwoordig moet u rekening houden met de beperkingen van de CAP-theorema. Er is een nieuw type database met de naam NewSQL ontstaan dat de relationele database-engine uitbreidt ter ondersteuning van zowel horizontale schaalbaarheid als de schaalbare prestaties van NoSQL-systemen.
Overwegingen voor relationele versus NoSQL-systemen
Op basis van specifieke gegevensvereisten kan een cloudeigen microservice een relationeel NoSQL-gegevensarchief of beide implementeren.
| Overweeg een NoSQL-gegevensarchief wanneer: | Overweeg een relationele database wanneer: |
|---|---|
| U hebt workloads met een hoog volume waarvoor voorspelbare latentie op grote schaal is vereist (bijvoorbeeld latentie gemeten in milliseconden tijdens het uitvoeren van miljoenen transacties per seconde) | Uw workloadvolume past doorgaans binnen duizenden transacties per seconde |
| Uw gegevens zijn dynamisch en vaak gewijzigd | Uw gegevens zijn zeer gestructureerd en vereisen referentiële integriteit |
| Relaties kunnen gedenormaliseerde gegevensmodellen zijn | Relaties worden uitgedrukt via tabeldeelnames voor genormaliseerde gegevensmodellen |
| Het ophalen van gegevens is eenvoudig en uitgedrukt zonder table joins | U werkt met complexe query's en rapporten |
| Gegevens worden doorgaans gerepliceerd in verschillende regio's en vereisen een betere controle over consistentie, beschikbaarheid en prestaties | Gegevens worden doorgaans gecentraliseerd of kunnen asynchroon worden gerepliceerd in regio's |
| Uw toepassing wordt geïmplementeerd op basishardware, zoals met openbare clouds | Uw toepassing wordt geïmplementeerd op grote, hoogwaardige hardware |
In de volgende secties verkennen we de opties die beschikbaar zijn in de Azure-cloud voor het opslaan en beheren van uw cloudeigen gegevens.
Database as a Service
Om te beginnen kunt u een virtuele Azure-machine inrichten en uw gewenste database voor elke service installeren. Hoewel u volledige controle over de omgeving hebt, zou u veel ingebouwde functies van het cloudplatform afhouden. U bent ook verantwoordelijk voor het beheren van de virtuele machine en database voor elke service. Deze aanpak kan snel tijdrovend en duur worden.
In plaats daarvan geven cloudeigen toepassingen de voorkeur aan gegevensservices die worden weergegeven als een Database as a Service (DBaaS). Volledig beheerd door een cloudleverancier, bieden deze services ingebouwde beveiliging, schaalbaarheid en bewaking. In plaats van de service te bezitten, gebruikt u deze gewoon als back-upservice. De provider beheert de resource op schaal en draagt de verantwoordelijkheid voor prestaties en onderhoud.
Ze kunnen worden geconfigureerd in cloud-beschikbaarheidszones en -regio's om hoge beschikbaarheid te bereiken. Ze ondersteunen allemaal Just-In-Time-capaciteit en een model voor betalen per gebruik. Azure beschikt over verschillende soorten beheerde gegevensserviceopties, elk met specifieke voordelen.
We kijken eerst naar relationele DBaaS-services die beschikbaar zijn in Azure. U ziet dat de vlaggenschip-SQL Server-database van Microsoft beschikbaar is, samen met verschillende opensource-opties. Vervolgens bespreken we de NoSQL-gegevensservices in Azure.
Relationele Azure-databases
Voor cloudeigen microservices waarvoor relationele gegevens zijn vereist, biedt Azure vier beheerde DBaaS-aanbiedingen (Relational Databases as a Service), weergegeven in afbeelding 5-11.

Afbeelding 5-11. Beheerde relationele databases die beschikbaar zijn in Azure
In de vorige afbeelding ziet u hoe elk zich bevindt op een gemeenschappelijke DBaaS-infrastructuur die zonder extra kosten belangrijke mogelijkheden biedt.
Deze functies zijn met name belangrijk voor organisaties die grote aantallen databases inrichten, maar beperkte resources hebben om ze te beheren. U kunt binnen enkele minuten een Azure-database inrichten door de hoeveelheid verwerkingskernen, het geheugen en de onderliggende opslag te selecteren. U kunt de database on-the-fly schalen en resources dynamisch aanpassen met weinig tot geen downtime.
Azure SQL-database
Ontwikkelteams met expertise in Microsoft SQL Server moeten Azure SQL Database overwegen. Het is een volledig beheerde relationele database-as-a-service (DBaaS) op basis van de Microsoft SQL Server Database Engine. De service deelt veel functies in de on-premises versie van SQL Server en voert de nieuwste stabiele versie van de SQL Server Database Engine uit.
Voor gebruik met een cloudeigen microservice is Azure SQL Database beschikbaar met drie implementatieopties:
Een individuele database vertegenwoordigt een volledig beheerde SQL Database die wordt uitgevoerd op een Azure SQL Database-server in de Azure-cloud. De database wordt als opgenomen beschouwd omdat deze geen configuratieafhankelijkheden heeft op de onderliggende databaseserver.
Een beheerd exemplaar is een volledig beheerd exemplaar van de Microsoft SQL Server Database Engine die bijna 100% compatibiliteit biedt met een on-premises SQL Server. Deze optie ondersteunt grotere databases, maximaal 35 TB en wordt in een virtueel Azure-netwerk geplaatst voor betere isolatie.
Serverloze Azure SQL Database is een rekenlaag voor één database die automatisch wordt geschaald op basis van de vraag naar workloads. Er wordt alleen gefactureerd voor de hoeveelheid rekenkracht die per seconde wordt gebruikt. De service is geschikt voor workloads met onregelmatige, onvoorspelbare gebruikspatronen, af en toe met perioden van inactiviteit. De serverloze rekenlaag onderbreekt ook databases automatisch tijdens inactieve perioden, zodat alleen opslagkosten in rekening worden gebracht. Deze wordt automatisch hervat wanneer de activiteit wordt geretourneerd.
Naast de traditionele Microsoft SQL Server-stack beschikt Azure ook over beheerde versies van drie populaire opensource-databases.
Opensource-databases in Azure
Opensource-relationele databases zijn een populaire keuze geworden voor cloudtoepassingen. Veel ondernemingen geven de voorkeur aan commerciële databaseproducten, met name voor kostenbesparingen. Veel ontwikkelteams genieten van hun flexibiliteit, door de community ondersteunde ontwikkeling en het ecosysteem van hulpprogramma's en extensies. Opensource-databases kunnen worden geïmplementeerd in meerdere cloudproviders, waardoor het probleem van 'vergrendeling van leveranciers' wordt geminimaliseerd.
Ontwikkelaars kunnen eenvoudig elke opensource-database op een Azure-VM zelf hosten. Terwijl u volledige controle hebt, kunt u met deze aanpak aan de haak gaan voor het beheer, de bewaking en het onderhoud van de database en vm.
Microsoft blijft zich echter blijven inzetten om Azure een 'open platform' te houden door verschillende populaire opensource-databases aan te bieden als volledig beheerde DBaaS-services.
Azure Database for MySQL
MySQL is een opensource-relationele database en een pijler voor toepassingen die zijn gebouwd op de LAMP-softwarestack. Veel gekozen voor leesintensieve werkbelastingen, het wordt gebruikt door veel grote organisaties, waaronder Facebook, Twitter en YouTube. De communityversie is gratis beschikbaar, terwijl voor de Enterprise Edition een licentieaankoop is vereist. Oorspronkelijk gemaakt in 1995 werd het product in 2008 gekocht door Sun Microsystems. Oracle kocht Sun en MySQL in 2010.
Azure Database for MySQL is een beheerde relationele databaseservice op basis van de opensource MySQL Server-engine. Deze maakt gebruik van de MySQL Community-editie. De Azure MySQL-server is het beheerpunt voor de service. Dit is dezelfde MySQL-serverengine die wordt gebruikt voor on-premises implementaties. De engine kan één database per server of meerdere databases per server maken die resources delen. U kunt gegevens blijven beheren met behulp van dezelfde opensource-hulpprogramma's zonder nieuwe vaardigheden te hoeven leren of virtuele machines te beheren.
Azure Database for MariaDB
MariaDB Server is een andere populaire opensource-databaseserver. Het is gemaakt als een fork van MySQL toen Oracle Sun Microsystems kocht, die eigenaar is van MySQL. De bedoeling was ervoor te zorgen dat MariaDB open source bleef. Omdat MariaDB een fork van MySQL is, zijn de gegevens- en tabeldefinities compatibel en zijn de clientprotocollen, structuren en API's nauw gebreid.
MariaDB heeft een sterke community en wordt gebruikt door veel grote ondernemingen. Hoewel Oracle MySQL blijft onderhouden, verbeteren en ondersteunen, beheert de MariaDB-stichting MariaDB, waardoor openbare bijdragen aan het product en de documentatie worden toegestaan.
Azure Database for MariaDB is een volledig beheerde relationele database als een service in de Azure-cloud. De service is gebaseerd op de Server-engine van de MariaDB Community Edition. Het kan bedrijfskritieke workloads verwerken met voorspelbare prestaties en dynamische schaalbaarheid.
Azure Database for PostgreSQL
PostgreSQL is een opensource relationele database met meer dan 30 jaar actieve ontwikkeling. PostgreSQL heeft een sterke reputatie voor betrouwbaarheid en gegevensintegriteit. Het is voorzien van uitgebreide, SQL-compatibele en beter presterende functies dan MySQL, met name voor workloads met complexe query's en zware schrijfbewerkingen. Veel grote ondernemingen, waaronder Apple, Red Hat en Fujitsu, hebben producten gebouwd met PostgreSQL.
Azure Database for PostgreSQL is een volledig beheerde relationele databaseservice op basis van de opensource Postgres-database-engine. De service ondersteunt veel ontwikkelplatforms, waaronder C++, Java, Python, Node, C# en PHP. U kunt PostgreSQL-databases naar deze database migreren met behulp van het opdrachtregelinterfaceprogramma of Azure Data Migration Service.
Azure Database for PostgreSQL is beschikbaar met twee implementatieopties:
De implementatieoptie enkele server is een centraal beheerpunt voor meerdere databases waarnaar u veel databases kunt implementeren. De prijzen zijn gestructureerd per server op basis van kernen en opslag.
De optie Hyperscale (Citus) wordt mogelijk gemaakt door Citus Data-technologie. Het maakt hoge prestaties mogelijk door één database horizontaal te schalen op honderden knooppunten om snelle prestaties en schaal te bieden. Met deze optie kan de engine meer gegevens in het geheugen aanpassen, query's parallelliseren op honderden knooppunten en gegevens sneller indexeren.
NoSQL-gegevens in Azure
Cosmos DB is een volledig beheerde, wereldwijd gedistribueerde NoSQL-databaseservice in de Azure-cloud. Het is overgenomen door veel grote bedrijven over de hele wereld, waaronder Coca-Cola, Skype,SourceMobil en Liberty Mutual.
Als uw services snel reageren vanaf elke locatie ter wereld, hoge beschikbaarheid of elastische schaalbaarheid, is Cosmos DB een uitstekende keuze. Afbeelding 5-12 toont Cosmos DB.
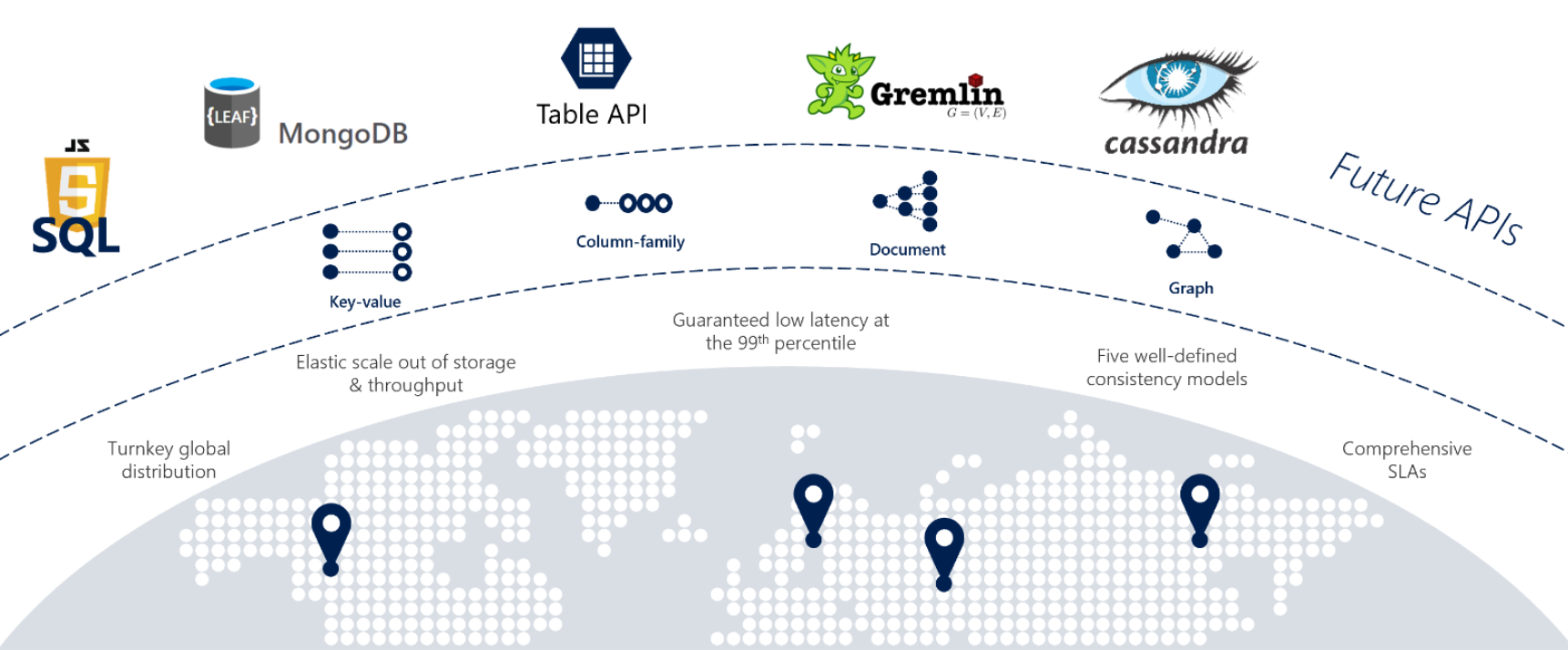
Afbeelding 5-12: Overzicht van Azure Cosmos DB
In de vorige afbeelding ziet u veel van de ingebouwde cloudmogelijkheden die beschikbaar zijn in Cosmos DB. In deze sectie bekijken we deze nader.
Wereldwijde ondersteuning
Cloudtoepassingen hebben vaak een wereldwijde doelgroep en vereisen wereldwijde schaal.
U kunt Cosmos-databases distribueren over regio's of over de hele wereld, gegevens dicht bij uw gebruikers plaatsen, de reactietijd verbeteren en latentie verminderen. U kunt een database toevoegen aan of verwijderen uit een regio zonder uw services te onderbreken of opnieuw te implementeren. Op de achtergrond worden de gegevens in Cosmos DB transparant gerepliceerd naar elk van de geconfigureerde regio's.
Cosmos DB biedt ondersteuning voor actieve/actieve clustering op globaal niveau, zodat u een van uw databaseregio's kunt configureren ter ondersteuning van zowel schrijf- als leesbewerkingen.
Het schrijfprotocol voor meerdere regio's is een belangrijke functie in Cosmos DB die de volgende functionaliteit mogelijk maakt:
Onbeperkte elastische schrijf- en leesschaalbaarheid.
99,999% lees- en schrijf beschikbaarheid over de hele wereld.
Gegarandeerde lees- en schrijfbewerkingen in minder dan 10 milliseconden op het 99e percentiel.
Met de Cosmos DB Multi-Homing-API's is uw microservice automatisch op de hoogte van de dichtstbijzijnde Azure-regio en worden er aanvragen naar verzonden. De dichtstbijzijnde regio wordt geïdentificeerd door Cosmos DB zonder configuratiewijzigingen. Als een regio niet beschikbaar is, stuurt de functie Multi-Homing automatisch aanvragen door naar de dichtstbijzijnde beschikbare regio.
Ondersteuning voor meerdere modellen
Bij het opnieuw platformen van monolithische toepassingen naar een cloudeigen architectuur moeten ontwikkelteams soms opensource-, NoSQL-gegevensarchieven migreren. Cosmos DB kan u helpen uw investering in deze NoSQL-gegevensarchieven te behouden met het gegevensplatform met meerdere modellen . In de volgende tabel ziet u de ondersteunde NoSQL-compatibiliteits-API's.
| Provider | Beschrijving |
|---|---|
| NoSQL-API | API voor NoSQL slaat gegevens op in documentindeling |
| Mongo DB-API | Ondersteunt Mongo DB-API's en JSON-documenten |
| Gremlin-API | Ondersteunt Gremlin-API met knooppunten op basis van grafieken en edge-gegevensweergaven |
| Cassandra-API | Ondersteunt Casandra-API voor gegevensweergaven in brede kolommen |
| Tabel-API | Ondersteunt Azure Table Storage met Premium-verbeteringen |
| PostgreSQL-API | Beheerde service voor het uitvoeren van PostgreSQL op elke schaal |
Ontwikkelteams kunnen bestaande Mongo-, Gremlin- of Cassandra-databases migreren naar Cosmos DB met minimale wijzigingen in gegevens of code. Voor nieuwe apps kunnen ontwikkelteams kiezen uit opensource-opties of het ingebouwde SQL API-model.
Intern slaat Cosmos de gegevens op in een eenvoudige struct-indeling die bestaat uit primitieve gegevenstypen. Voor elke aanvraag vertaalt de database-engine de primitieve gegevens in de modelweergave die u hebt geselecteerd.
In de vorige tabel ziet u de optie Table-API . Deze API is een evolutie van Azure Table Storage. Beide delen hetzelfde onderliggende tabelmodel, maar de Cosmos DB Table-API voegt premium-verbeteringen toe die niet beschikbaar zijn in de Azure Storage-API. De volgende tabel contrasteert de functies.
| Functie | Azure-tabelopslag | Azure Cosmos DB |
|---|---|---|
| Latentie | Snel | Latentie van één milliseconde voor lees- en schrijfbewerkingen overal ter wereld |
| Doorvoer | Limiet van 20.000 bewerkingen per tabel | Onbeperkte bewerkingen per tabel |
| Wereldwijde distributie | Eén regio met optionele secundaire leesregio | Kant-en-klare distributies naar alle regio's met automatische failover |
| Indexeren | Alleen beschikbaar voor eigenschappen van partitie- en rijsleutels | Automatische indexering van alle eigenschappen |
| Prijzen | Geoptimaliseerd voor koude workloads (lage doorvoer: opslagverhouding) | Geoptimaliseerd voor dynamische workloads (hoge doorvoer: opslagverhouding) |
Microservices die Azure Table Storage gebruiken, kunnen eenvoudig worden gemigreerd naar de Cosmos DB Table-API. Er zijn geen codewijzigingen vereist.
Afstelbaar consistentiemodel
Eerder in de sectie Relationeel versus NoSQL hebben we het onderwerp van gegevensconsistentie besproken. Gegevensconsistentie verwijst naar de integriteit van uw gegevens. Cloudeigen services met gedistribueerde gegevens zijn afhankelijk van replicatie en moeten een fundamentele afweging maken tussen leesconsistentie, beschikbaarheid en latentie.
Met de meeste gedistribueerde databases kunnen ontwikkelaars kiezen tussen twee consistentiemodellen: sterke consistentie en uiteindelijke consistentie. Sterke consistentie is de gouden standaard van programmeerbaarheid van gegevens. Het garandeert dat een query altijd de meest recente gegevens retourneert, zelfs als het systeem latentie moet veroorzaken totdat een update wordt gerepliceerd voor alle databasekopieën. Hoewel een database die is geconfigureerd voor uiteindelijke consistentie , onmiddellijk gegevens retourneert, zelfs als die gegevens niet de meest recente kopie zijn. De laatste optie maakt hogere beschikbaarheid, grotere schaal en betere prestaties mogelijk.
Azure Cosmos DB biedt vijf goed gedefinieerde consistentiemodellen die worden weergegeven in afbeelding 5-13.

Afbeelding 5-13: Cosmos DB-consistentieniveaus
Met deze opties kunt u nauwkeurige keuzes en gedetailleerde afwegingen maken voor consistentie, beschikbaarheid en de prestaties voor uw gegevens. De niveaus worden weergegeven in de volgende tabel.
| Consistentieniveau | Beschrijving |
|---|---|
| Eventual | Geen bestelgarantie voor leesbewerkingen. Replica's worden uiteindelijk geconvergeerd. |
| Constant voorvoegsel | Leesbewerkingen zijn nog steeds uiteindelijk, maar gegevens worden geretourneerd in de volgorde waarin ze worden geschreven. |
| Sessie | Garanties dat u alle gegevens kunt lezen die tijdens de huidige sessie zijn geschreven. Dit is het standaardconsistentieniveau. |
| Bounded Staleness | Leest de schrijfbewerkingen per interval dat u opgeeft. |
| Sterk | Leesbewerkingen retourneren gegarandeerd de meest recente vastgelegde versie van een item. Een client ziet nooit een niet-verzonden of gedeeltelijke leesbewerking. |
In het artikel Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained, Microsoft Program Manager Jeremy Likness biedt een uitstekende uitleg van de vijf modellen.
Partitionering
Azure Cosmos DB omvat automatische partitionering om een database te schalen om te voldoen aan de prestatiebehoeften van uw cloudeigen services.
U beheert gegevens in Cosmos DB-gegevens door databases, containers en items te maken.
Containers bevinden zich in een Cosmos DB-database en vertegenwoordigen een schemaagnostische groepering van items. Items zijn de gegevens die u aan de container toevoegt. Ze worden weergegeven als documenten, rijen, knooppunten of randen. Alle items die aan een container worden toegevoegd, worden automatisch geïndexeerd.
Als u de container wilt partitioneren, worden items onderverdeeld in afzonderlijke subsets die logische partities worden genoemd. Logische partities worden gevuld op basis van de waarde van een partitiesleutel die is gekoppeld aan elk item in een container. In afbeelding 5-14 ziet u twee containers met elk een logische partitie op basis van een partitiesleutelwaarde.
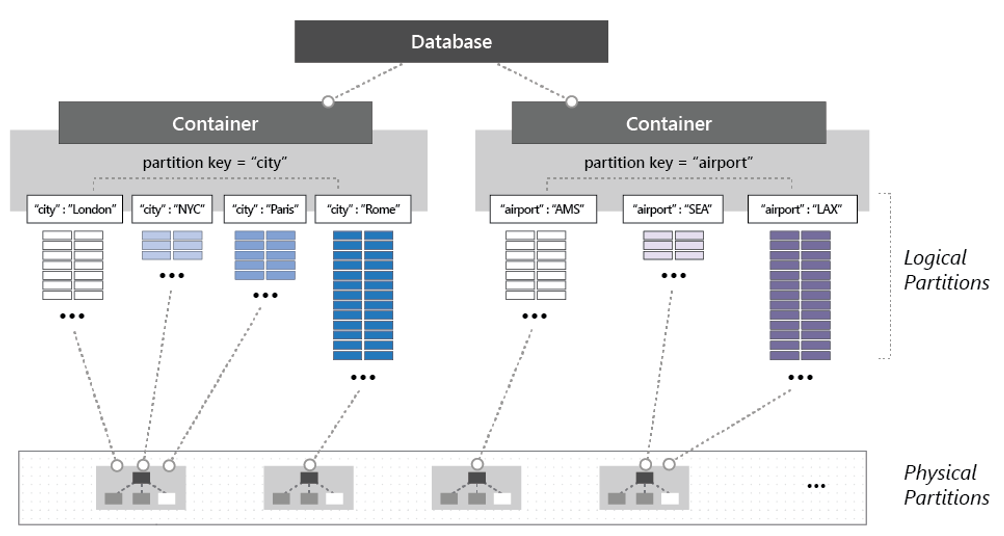
Afbeelding 5-14: Partitioneringsmechanica van Cosmos DB
In de vorige afbeelding ziet u hoe elk item een partitiesleutel bevat van 'stad' of 'luchthaven'. De sleutel bepaalt de logische partitie van het item. Items met een plaatscode worden aan de container aan de linkerkant toegewezen, en items met een luchthavencode, aan de container aan de rechterkant. Als u de partitiesleutelwaarde combineert met de id-waarde, wordt de index van een item gemaakt, waarmee het item uniek wordt geïdentificeerd.
Intern beheert Cosmos DB automatisch de plaatsing van logische partities op fysieke partities om te voldoen aan de schaalbaarheids- en prestatiebehoeften van de container. Naarmate de doorvoer en opslagvereisten van toepassingen toenemen, worden logische partities in Azure Cosmos DB opnieuw verdeeld over een groter aantal servers. Herdistributiebewerkingen worden beheerd door Cosmos DB en zonder onderbreking of downtime aangeroepen.
NewSQL-databases
NewSQL is een opkomende databasetechnologie die de gedistribueerde schaalbaarheid van NoSQL combineert met de ACID-garanties van een relationele database. NewSQL-databases zijn belangrijk voor bedrijfssystemen die grote hoeveelheden gegevens moeten verwerken, in gedistribueerde omgevingen, met volledige transactionele ondersteuning en ACID-naleving. Hoewel een NoSQL-database enorme schaalbaarheid kan bieden, garandeert deze geen gegevensconsistentie. Onregelmatige problemen van inconsistente gegevens kunnen het ontwikkelteam belasten. Ontwikkelaars moeten beveiliging in hun microservicecode bouwen om problemen te beheren die worden veroorzaakt door inconsistente gegevens.
De Cloud Native Computing Foundation (CNCF) bevat verschillende NewSQL-databaseprojecten.
| Project | Kenmerken |
|---|---|
| Kakkerlakken DB | Een ACID-compatibele relationele database die wereldwijd wordt geschaald. Voeg een nieuw knooppunt toe aan een cluster en KakkerlakkenDB zorgt ervoor dat de gegevens worden verdeeld over exemplaren en geografische gebieden. Het maakt, beheert en distribueert replica's om de betrouwbaarheid te garanderen. Het is open source en vrij beschikbaar. |
| TiDB | Een opensource-database die HTAP-workloads (Hybrid Transactional and Analytical Processing) ondersteunt. Het is compatibel met MySQL en biedt horizontale schaalbaarheid, sterke consistentie en hoge beschikbaarheid. TiDB fungeert als een MySQL-server. U kunt bestaande MySQL-clientbibliotheken blijven gebruiken zonder dat er uitgebreide codewijzigingen in uw toepassing nodig zijn. |
| YugabyteDB | Een open source, krachtige, gedistribueerde SQL-database. Het ondersteunt lage querylatentie, tolerantie tegen fouten en wereldwijde gegevensdistributie. YugabyteDB is compatibel met PostgreSQL en verwerkt scale-out RDBMS en OLTP-workloads op internetschaal. Het product ondersteunt ook NoSQL en is compatibel met Cassandra. |
| Vitess | Vitess is een databaseoplossing voor het implementeren, schalen en beheren van grote clusters van MySQL-exemplaren. Het kan worden uitgevoerd in een openbare of privécloudarchitectuur. Vitess combineert en breidt veel belangrijke MySQL-functies en functies zowel verticale als horizontale sharding-ondersteuning uit. Vitess is afkomstig van YouTube en biedt al sinds 2011 al het YouTube-databaseverkeer. |
De opensource-projecten in de vorige afbeelding zijn beschikbaar via de Cloud Native Computing Foundation. Drie van de aanbiedingen zijn volledige databaseproducten, waaronder .NET-ondersteuning. De andere, Vitess, is een databaseclustersysteem waarmee grote clusters van MySQL-exemplaren horizontaal worden geschaald.
Een belangrijk ontwerpdoel voor NewSQL-databases is om systeemeigen te werken in Kubernetes, waarbij gebruik wordt gemaakt van de tolerantie en schaalbaarheid van het platform.
NewSQL-databases zijn ontworpen om te bloeien in tijdelijke cloudomgevingen waar onderliggende virtuele machines opnieuw kunnen worden opgestart of opnieuw kunnen worden gepland op een moment. De databases zijn ontworpen om knooppuntfouten te overleven zonder gegevensverlies of uitvaltijd. KakkerlakkenDB kan bijvoorbeeld een machineverlies overleven door drie consistente replica's van alle gegevens over de knooppunten in een cluster te onderhouden.
Kubernetes maakt gebruik van een Services-constructie waarmee een client een groep identieke NewSQL-databases verwerkt vanuit één DNS-vermelding. Door de database-exemplaren los te koppelen van het adres van de service waaraan deze is gekoppeld, kunnen we schalen zonder dat bestaande toepassingsexemplaren worden onderbroken. Het verzenden van een aanvraag naar een service op een bepaald moment levert altijd hetzelfde resultaat op.
In dit scenario zijn alle database-exemplaren gelijk. Er zijn geen primaire of secundaire relaties. Technieken zoals consensusreplicatie in KakkerlakkenDB maken het mogelijk om elk databaseknooppunt om te gaan met elke aanvraag. Als het knooppunt dat een aanvraag met gelijke taakverdeling ontvangt, de gegevens bevat die lokaal nodig zijn, reageert het onmiddellijk. Als dat niet het geval is, wordt het knooppunt een gateway en wordt de aanvraag doorgestuurd naar de juiste knooppunten om het juiste antwoord te krijgen. Vanuit het perspectief van de client is elk databaseknooppunt hetzelfde: ze worden weergegeven als één logische database met de consistentiegaranties van een systeem met één machine, ondanks dat er tientallen of zelfs honderden knooppunten achter de schermen werken.
Zie het artikel DASH: Four Properties of Kubernetes-Native Databases voor een gedetailleerd overzicht van de mechanica achter NewSQL-databases.
Gegevensmigratie naar de cloud
Een van de meer tijdrovende taken is het migreren van gegevens van het ene gegevensplatform naar het andere. De Azure Data Migration Service kan helpen bij het versnellen van dergelijke inspanningen. Met minimale downtime kunnen gegevens van verschillende externe databasebronnen worden gemigreerd naar Azure-gegevensplatforms. Doelplatformen omvatten de volgende services:
- Azure SQL-database
- Azure Database for MySQL
- Azure Database for MariaDB
- Azure Database for PostgreSQL
- Azure Cosmos DB
De service biedt aanbevelingen om u te begeleiden bij de wijzigingen die nodig zijn om een migratie uit te voeren, zowel klein als groot.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor