Integratiepaden voor Microsoft Fabric voor ISV's
Microsoft Fabric biedt drie verschillende trajecten voor ISV's om naadloos te integreren met Fabric. Voor een ISV die op deze reis begint, willen we verschillende resources doorlopen die we beschikbaar hebben op elk van deze trajecten.

Interoperabiliteit met Infrastructuur
De primaire focus met het Interop-model is het inschakelen van ISV's om hun oplossingen te integreren met de OneLake Foundation. Voor interop met Microsoft Fabric bieden we integratie met BEHULP van REST API's voor OneLake, een groot aantal connectors in Data Factory, snelkoppelingen in OneLake en databasespiegeling.

Hier volgen een aantal manieren om aan de slag te gaan met dit model:
OneLake-API's
- OneLake ondersteunt bestaande API's van Azure Data Lake Storage (ADLS) Gen2 voor directe interactie, zodat ontwikkelaars hun gegevens in OneLake kunnen lezen, schrijven en beheren. Meer informatie over ADLS Gen2 REST API's en hoe u verbinding maakt met OneLake.
- Omdat niet alle functionaliteit in ADLS Gen2 rechtstreeks aan OneLake wordt toegewezen, dwingt OneLake ook een set mapstructuur af om Infrastructuurwerkruimten en -items te ondersteunen. Voor een volledige lijst met verschillende gedragingen tussen OneLake en ADLS Gen2 bij het aanroepen van deze API's, raadpleegt u de pariteit van OneLake-API.
- Als u Databricks gebruikt en verbinding wilt maken met Microsoft Fabric, werkt Databricks met ADLS Gen2-API's. Integreer OneLake met Azure Databricks.
- Om optimaal te profiteren van wat de Delta Lake-opslagindeling voor u kan doen, bekijkt en begrijpt u de indeling, tabeloptimalisatie en V-Order. Optimalisatie van Delta Lake-tabellen en V-Order.
- Zodra de gegevens zich in OneLake hebben opgeslagen, verkent u lokaal met OneLake Bestandenverkenner. OneLake-bestandsverkenner integreert OneLake naadloos met Windows Bestandenverkenner. Met deze toepassing worden automatisch alle OneLake-items gesynchroniseerd waartoe u toegang hebt in Windows Bestandenverkenner. U kunt ook elk ander hulpprogramma gebruiken dat compatibel is met ADLS Gen2, zoals Azure Storage Explorer.

Realtime Intelligence-API's
Realtime intelligence stroomlijnt gegevensanalyse en -visualisatie en biedt een gecentraliseerde oplossing voor onmiddellijke inzichten en acties op gegevens die in beweging zijn binnen een organisatie. Het beheert efficiënt grote hoeveelheden gegevens via robuuste query-, transformatie- en opslagmogelijkheden.
- Event houses zijn speciaal ontworpen voor het streamen van gegevens, compatibel met Realtime Hub en ideaal voor gebeurtenissen op basis van tijd. Gegevens worden automatisch geïndexeerd en gepartitioneerd op basis van opnametijd, waardoor u ongelooflijk snel en complexe analysemogelijkheden voor query's kunt uitvoeren op gegevens met hoge granulariteit die kunnen worden geopend in OneLake voor gebruik in de suite met ervaringen van Fabric. Event houses ondersteunen bestaande Event House-API's en SDK's voor directe interactie, zodat ontwikkelaars hun gegevens in Event Houses kunnen lezen, schrijven en beheren. Meer informatie over REST API.
- Met gebeurtenisstromen kunt u realtime gebeurtenissen uit verschillende bronnen overbrengen en deze routeren naar verschillende bestemmingen, zoals OneLake, KQL-databases in gebeurtenishuizen en Data Activator. Meer informatie over gebeurtenisstromen en gebeurtenisstromen-API.
- Als u Databricks of Jupyter Notebooks gebruikt, kunt u de Kusto Python-clientbibliotheek gebruiken om te werken met KQL-databases in Fabric. Meer informatie over Kusto Python SDK.
- U kunt de bestaande Microsoft Logic Apps-, Azure Data Factory- of Microsoft Power Automate-connectors gebruiken om te communiceren met uw Event Houses of KQL-databases.
- Databasesnelkoppelingen in Realtime Analytics zijn ingesloten verwijzingen binnen een gebeurtenishuis naar een brondatabase. De brondatabase kan een KQL-database zijn in realtime analytics of een Azure Data Explorer-database. Snelkoppelingen kunnen worden gebruikt voor het inplacen van het delen van gegevens binnen dezelfde tenant of voor meerdere tenants. Meer informatie over het beheren van databasesnelkoppelingen met behulp van de API.

Data Factory in Fabric
- Data Pipelines bieden een uitgebreide set connectors, waardoor ISV's moeiteloos verbinding kunnen maken met een groot aantal gegevensarchieven. Of u nu traditionele databases of moderne cloudoplossingen gebruikt, onze connectors zorgen voor een soepel integratieproces. Verbinding maken of overzicht.
- Met onze ondersteunde Dataflow Gen2-connectors kunnen ISV's de kracht van Fabric Data Factory benutten om complexe gegevenswerkstromen te beheren. Deze functie is vooral nuttig voor ISV's die gegevensverwerkings- en transformatietaken willen stroomlijnen. Gegevensstroom Gen2-connectors in Microsoft Fabric.
- Bekijk deze Data Factory in Fabric-blog voor een volledige lijst met mogelijkheden die worden ondersteund door Data Factory in Fabric.
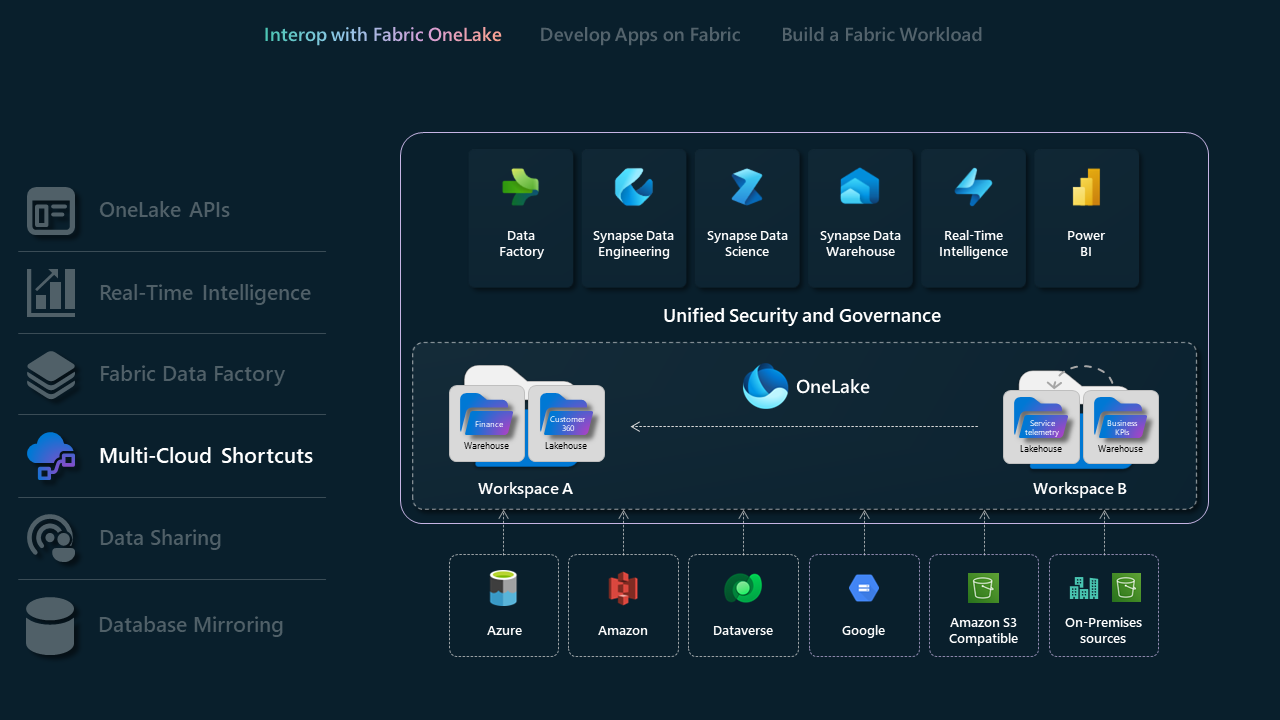
Snelkoppelingen voor meerdere clouds
Met snelkoppelingen in Microsoft OneLake kunt u uw gegevens samenvoegen tussen domeinen, clouds en accounts door één virtuele data lake voor uw hele onderneming te maken. Alle Fabric-ervaringen en analytische engines kunnen rechtstreeks verwijzen naar uw bestaande gegevensbronnen, zoals OneLake in een andere tenant, Azure Data Lake Storage (ADLS) Gen2, Amazon S3-opslagaccounts en Dataverse via een geïntegreerde naamruimte. OneLake presenteert ISV's met een transformatieve oplossing voor gegevenstoegang, waarbij integratie naadloos wordt overbrugd tussen verschillende domeinen en cloudplatforms.
- Meer informatie over OneLake-snelkoppelingen
- Meer informatie over OneLake, één kopie
- Meer informatie over KQL-databasesnelkoppelingen
Databasespiegeling
U hebt de snelkoppelingen gezien, nu vraagt u zich af wat de integratiemogelijkheden zijn met externe databases en magazijnen. Spiegeling biedt een moderne manier om continu en naadloos toegang te krijgen tot en gegevens op te nemen vanuit elke database of datawarehouse in de datawarehousingervaring in Microsoft Fabric. Mirror is allemaal in bijna realtime, waardoor gebruikers direct toegang hebben tot wijzigingen in de bron. Meer informatie over spiegeling en de ondersteunde databases vindt u in Introducing Mirroring in Microsoft Fabric.

Ontwikkelen op infrastructuur

Met de ISV's ontwikkelen op fabric-modellen kunnen hun producten en services op fabric bouwen of de functionaliteiten van Fabric naadloos insluiten binnen hun bestaande toepassingen. Het is een overgang van basisintegratie tot het actief toepassen van de mogelijkheden die Fabric biedt. Het belangrijkste integratieoppervlak is via REST API's voor verschillende Fabric-workloads. Hier volgt een lijst met REST API's die momenteel beschikbaar zijn.
Werkplek
| API | Beschrijving |
|---|---|
| CRUD-API's voor werkruimte- en werkruimterolbeheer | Werkruimte maken, Werkruimtegegevens ophalen, Werkruimte verwijderen, Werkruimte toewijzen aan een capaciteit, een werkruimteroltoewijzing toevoegen. |
OneLake
| API | Beschrijving |
|---|---|
| Snelkoppeling maken | Hiermee maakt u een nieuwe snelkoppeling. |
| Snelkoppeling verwijderen | Hiermee verwijdert u de snelkoppeling, maar verwijdert u de doelopslagmap niet. |
| Snelkoppeling ophalen | Retourneert snelkoppelingseigenschappen. |
| ADLS Gen2-API's | ADLS Gen2-API's voor het maken en beheren van bestandssystemen, mappen en pad. |
Realtime intelligence
| Artikel | API | Beschrijving |
|---|---|---|
| Event House | Gebeurtenishuis maken | Hiermee maakt u een gebeurtenishuis. |
| Gebeurtenishuis verwijderen | Hiermee verwijdert u een bestaand gebeurtenishuis. | |
| Gebeurtenishuis ophalen | Metagegevens ophalen over een gebeurtenishuis. | |
| Gebeurtenishuis vermelden | Lijst met gebeurtenisruimten in uw werkruimte. | |
| Gebeurtenishuis bijwerken | Een bestaand gebeurtenishuis bijwerken. | |
| KQL-database | KQL-database maken | Hiermee maakt u een KQL-database of KQL Database-snelkoppelingen. |
| KQL-database verwijderen | Hiermee verwijdert u een bestaande KQL-database of KQL Database-snelkoppelingen. | |
| KQL-database ophalen | Metagegevens ophalen over een KQL-database of KQL Database-snelkoppelingen. | |
| KQL-database weergeven | Maak een lijst met KQL-databases in uw werkruimte of KQL Database-snelkoppelingen. | |
| KQL-database bijwerken | Werk een bestaande KQL-database of KQL Database-snelkoppelingen bij. | |
| KQL-queryset | KQL-queryset maken | Hiermee maakt u een KQL-queryset of KQL Database-snelkoppelingen. |
| KQL-queryset verwijderen | Hiermee verwijdert u een bestaande KQL-queryset. | |
| KQL-queryset ophalen | Metagegevens ophalen over een KQL-queryset. | |
| KQL-queryset weergeven | KQL-querysets weergeven in uw werkruimte. | |
| KQL-queryset bijwerken | Een bestaande KQL-queryset bijwerken. | |
| Gebeurtenisstroom | Gebeurtenisstroom maken | Hiermee maakt u een gebeurtenisstroom. |
| Gebeurtenisstroom verwijderen | Hiermee verwijdert u een bestaande gebeurtenisstroom. | |
| Gebeurtenisstroom ophalen | Metagegevens ophalen over een gebeurtenisstroom. | |
| Gebeurtenisstroom vermelden | Gebeurtenisstromen weergeven in uw werkruimte. | |
| Gebeurtenisstroom bijwerken | Een bestaande gebeurtenisstroom bijwerken. |
Fabric Data Factory
| API | Beschrijving |
|---|---|
| Binnenkort beschikbaar |
Datawarehouse
| API | Beschrijving |
|---|---|
| Magazijn maken | Hiermee maakt u een datawarehouse. |
| Magazijn ophalen | Metagegevens ophalen over magazijn. |
| Warehouse bijwerken | Een bestaand magazijn bijwerken. |
| Magazijn verwijderen | Een bestaand magazijn verwijderen. |
| Lijstwarehouse | Maak een lijst met magazijnen in uw werkruimte. |
Data engineer
| API | Beschrijving |
|---|---|
| Lakehouse maken | Hiermee maakt u Lakehouse samen met het SQL-analyse-eindpunt. |
| Lakehouse bijwerken | Hiermee werkt u de naam van een lakehouse en het SQL Analytics-eindpunt bij. |
| Lakehouse verwijderen | Hiermee verwijdert u Lakehouse en het bijbehorende SQL-analyse-eindpunt. |
| Eigenschappen ophalen | Hiermee haalt u de eigenschappen van een lakehouse en het SQL-analyse-eindpunt op. |
| Tabellen weergeven | Lijst met tabellen in het lakehouse. |
| Tabel laden | Hiermee maakt u deltatabellen op basis van CSV- en Parquet-bestanden en -mappen. |
Deze sectie wordt bijgewerkt naarmate er meer Fabric-API's beschikbaar komen.
Een infrastructuurworkload bouwen

Het bouwen van een Fabric Workload-model is ontworpen om ISV's uit te rusten met de hulpprogramma's en platformmogelijkheden die nodig zijn om aangepaste workloads en ervaringen op Fabric te maken. Hiermee kunnen ISV's hun aanbod aanpassen om hun waardepropositie te leveren terwijl ze gebruikmaken van het Fabric-ecosysteem door het beste van beide werelden te combineren. We werken nauw samen met geselecteerde ontwerppartners voor dit integratiepad en het is momenteel alleen beschikbaar via uitnodiging.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor