Este exemplo de arquitetura é baseado na arquitetura de exemplo de aplicativo Web Básico e a estende para mostrar:
- Práticas comprovadas para melhorar a escalabilidade e o desempenho em um aplicativo Web do Serviço de Aplicativo do Azure
- Como executar um aplicativo do Serviço de Aplicativo do Azure em várias regiões para obter alta disponibilidade
Arquitetura
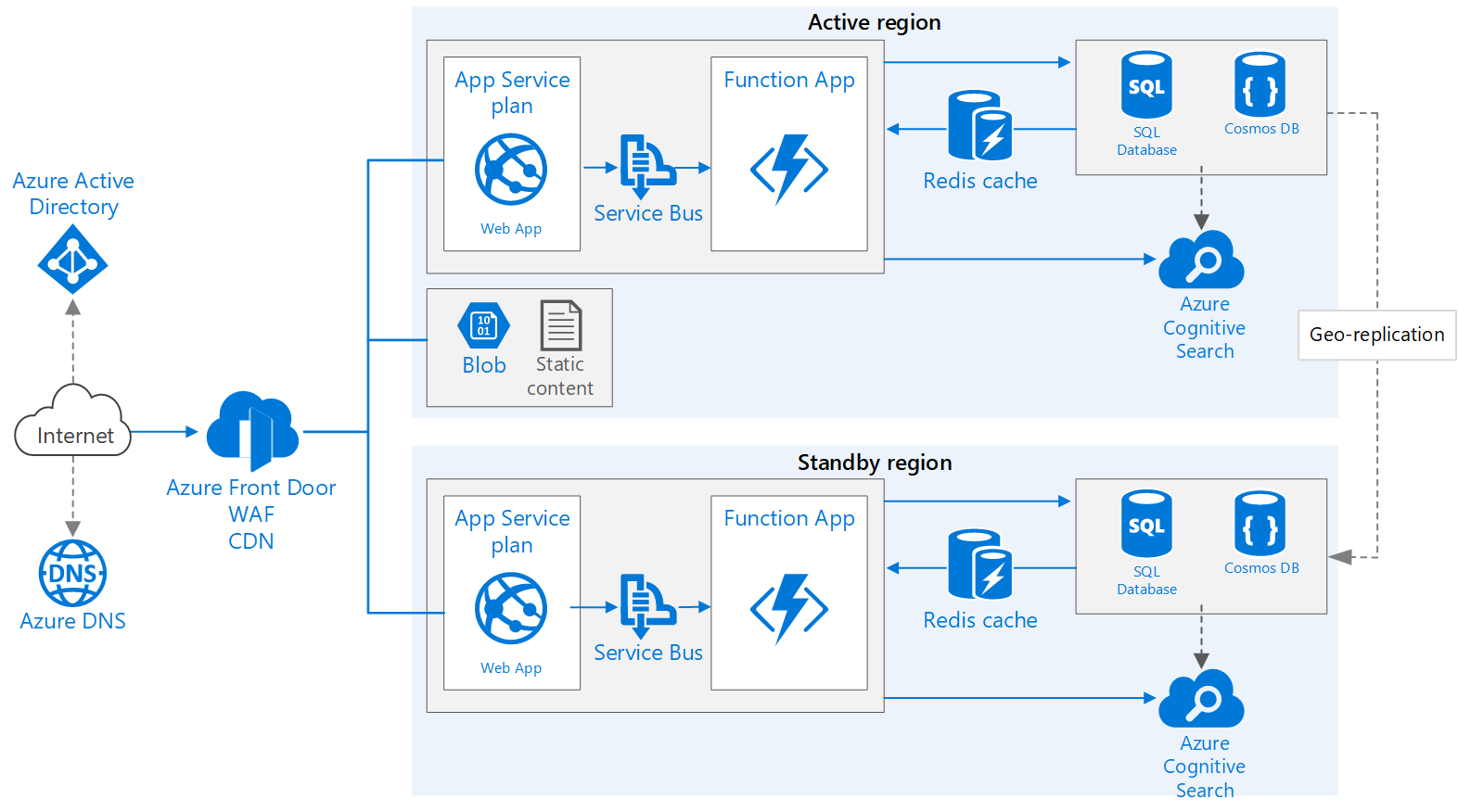
Transfira um ficheiro do Visio desta arquitetura.
Fluxo de Trabalho
Esse fluxo de trabalho aborda os aspetos de várias regiões da arquitetura e se baseia no aplicativo Web Básico.
- Regiões primária e secundária. Esta arquitetura utiliza duas regiões para assegurar disponibilidade mais elevada. A aplicação é implementada para cada região. Durante as operações normais, o tráfego de rede é encaminhado para a região primária. Se a região primária ficar indisponível, o tráfego será encaminhado para a região secundária.
- Porta da frente. O Azure Front Door é o balanceador de carga recomendado para implementações de várias regiões. Ele se integra ao firewall de aplicativos da Web (WAF) para proteger contra explorações comuns e usa a funcionalidade de cache de conteúdo nativo do Front Door. Nessa arquitetura, o Front Door é configurado para roteamento prioritário , que envia todo o tráfego para a região principal, a menos que ele fique indisponível. Se a região primária ficar indisponível, o Front Door encaminhará todo o tráfego para a região secundária.
- Replicação geográfica de Contas de Armazenamento, Banco de Dados SQL e/ou Azure Cosmos DB.
Nota
Para obter uma visão geral detalhada do uso do Azure Front Door para arquiteturas de várias regiões, inclusive em uma configuração protegida por rede, consulte Implementação de entrada segura de rede.
Componentes
Principais tecnologias utilizadas para implementar esta arquitetura:
- O Microsoft Entra ID é um serviço de gerenciamento de identidade e acesso baseado em nuvem que permite que os funcionários acessem aplicativos em nuvem desenvolvidos para sua organização.
- O DNS do Azure é um serviço de alojamento dos domínios DNS que fornece resolução de nomes através da infraestrutura do Microsoft Azure. Ao alojar os seus domínios no Azure, pode gerir os recursos DNS com as mesmas credenciais, APIs, ferramentas e faturação dos seus outros serviços do Azure. Para usar um nome de domínio personalizado (como
contoso.com), crie registros DNS que mapeiam o nome de domínio personalizado para o endereço IP. Para obter mais informações, veja Configurar um nome de domínio personalizado no Serviço de Aplicações do Azure. - A Rede de Entrega de Conteúdo do Azure é uma solução global para fornecer conteúdo de alta largura de banda armazenando-o em cache em nós físicos estrategicamente posicionados em todo o mundo.
- O Azure Front Door é um balanceador de carga de camada 7. Nessa arquitetura, ele roteia solicitações HTTP para o front-end da Web. O Front Door também fornece um firewall de aplicativo da Web (WAF) que protege o aplicativo contra exploits e vulnerabilidades comuns. Front Door também é usado para uma solução de rede de distribuição de conteúdo (CDN) neste projeto.
- O Azure AppService é uma plataforma totalmente gerenciada para criar e implantar aplicativos em nuvem. Ele permite definir um conjunto de recursos de computação para um aplicativo Web ser executado, implantar aplicativos Web e configurar slots de implantação.
- Os Aplicativos de Função do Azure podem ser usados para executar tarefas em segundo plano. As funções são invocadas por um gatilho, como um evento de timer ou uma mensagem sendo colocada na fila. Para tarefas com monitoração de estado de longa duração, use Funções duráveis.
- O Armazenamento do Azure é uma solução de armazenamento em nuvem para cenários modernos de armazenamento de dados, oferecendo armazenamento altamente disponível, massivamente escalável, durável e seguro para uma variedade de objetos de dados na nuvem.
- O Cache Redis do Azure é um serviço de cache de alto desempenho que fornece um armazenamento de dados na memória para recuperação mais rápida de dados, com base no cache Redis de implementação de código aberto.
- O Banco de Dados SQL do Azure é um banco de dados relacional como serviço na nuvem. A Base de Dados SQL partilha a base de código com o motor de bases de dados do Microsoft SQL Server.
- O Azure Cosmos DB é um banco de dados globalmente distribuído, totalmente gerenciado, de baixa latência, multimodelo e com várias APIs de consulta para gerenciar dados em grande escala.
- A Pesquisa Cognitiva do Azure pode ser usada para adicionar funcionalidades de pesquisa, como sugestões de pesquisa, pesquisa difusa e pesquisa específica de idioma. O Azure Search é normalmente utilizado em conjunto com outro arquivo de dados, especialmente se o arquivo de dados primário exigir consistência rigorosa. Nesta abordagem, armazene dados autoritativos no outro arquivo de dados e o índice de pesquisa no Azure Search. O Azure Search também serve para consolidar um único índice de pesquisa a partir de vários arquivos de dados.
Detalhes do cenário
Existem várias abordagens gerais para alcançar a alta disponibilidade entre regiões:
Ativo/Passivo com espera quente: o tráfego vai para uma região, enquanto a outra espera em espera quente. Hot standby significa que o Serviço de Aplicativo na região secundária está alocado e está sempre em execução.
Ativo/Passivo com espera fria: o tráfego vai para uma região, enquanto a outra espera em espera fria. O modo de espera a frio significa que o Serviço de Aplicativo na região secundária não é alocado até que seja necessário para o failover. Esta abordagem tem um custo de execução inferior, mas geralmente demora mais tempo a ficar online durante uma falha.
Ativo/Ativo: ambas as regiões estão ativas e as solicitações têm balanceamento de carga entre elas. Se uma região ficar indisponível, ela será retirada da rotação.
Esta referência concentra-se em ativo/passivo com hot standby.
Potenciais casos de utilização
Esses casos de uso podem se beneficiar de uma implantação em várias regiões:
Projete um plano de continuidade de negócios e recuperação de desastres para aplicativos LoB.
Implante aplicativos de missão crítica executados em Windows ou Linux.
Melhore a experiência do usuário mantendo os aplicativos disponíveis.
Recomendações
Os requisitos podem ser diferentes da arquitetura descrita aqui. Utilize as recomendações nesta secção como um ponto de partida.
Emparelhamento regional
Cada região do Azure é emparelhada com outra região na mesma geografia. Em geral, escolha regiões do mesmo par regional (por exemplo, E.U.A. Leste 2 e E.U.A. Central). Benefícios desta opção:
- Se houver uma interrupção ampla, a recuperação de pelo menos uma região de cada par é priorizada.
- As atualizações planeadas do sistema Azure são implementadas em regiões emparelhadas sequencialmente, para minimizar a possibilidade de períodos de indisponibilidade.
- Na maioria dos casos, os pares regionais residem na mesma área geográfica para satisfazer os requisitos de residência dos dados.
No entanto, verifique se ambas as regiões suportam todos os serviços do Azure necessários para a sua aplicação. Veja Serviços por região. Para obter mais informações sobre pares regionais, veja Continuidade do negócio e recuperação após desastre (BCDR): Regiões Emparelhadas do Azure.
Grupos de recursos
Considere colocar a região primária, a região secundária e a Porta da Frente em grupos de recursos separados. Essa alocação permite gerenciar os recursos implantados em cada região como uma única coleção.
Aplicações do Serviço de Aplicações
Recomendamos que crie a aplicação Web e a API Web como aplicações separadas do Serviço de Aplicações. Esta estrutura permite-lhe executá-las em planos separados do Serviço de Aplicações, pelo que podem ser dimensionadas de forma independente. Se não precisar desse nível de escalabilidade inicialmente, pode implementar as aplicações no mesmo plano e movê-las para planos separados posteriormente, se necessário.
Nota
Para os planos Básico, Padrão, Premium e Isolado, você é cobrado pelas instâncias de VM no plano, não por aplicativo. Veja Preços do Serviço de Aplicações
Configuração da porta dianteira
Encaminhamento. Front Door suporta vários mecanismos de roteamento. Para o cenário descrito neste artigo, use o roteamento de prioridade . Com essa configuração, o Front Door envia todas as solicitações para a região primária, a menos que o ponto de extremidade dessa região se torne inacessível. Nessa altura, este efetua a ativação pós-falha automaticamente para a região secundária. Defina o pool de origem com diferentes valores de prioridade, 1 para a região ativa e 2 ou superior para a região em espera ou passiva.
Sonda de estado de funcionamento. O Front Door usa uma sonda HTTPS para monitorar a disponibilidade de cada back-end. A sonda dá à Front Door um teste de aprovação/reprovação para failover para a região secundária. Este funciona através do envio de um pedido para um caminho URL especificado. Se obtiver uma resposta que não 200 dentro do período de tempo limite, a sonda falhará. Você pode configurar a frequência da sonda de integridade, o número de amostras necessárias para a avaliação e o número de amostras bem-sucedidas necessárias para que a origem seja marcada como íntegra. Se a Front Door marcar a origem como degradada, ela passa para a outra origem. Para obter detalhes, consulte Sondas de integridade.
Como prática recomendada, crie um caminho de teste de integridade na origem do aplicativo que informe a integridade geral do aplicativo. Essa investigação de integridade deve verificar dependências críticas, como os aplicativos do Serviço de Aplicativo, a fila de armazenamento e o Banco de Dados SQL. Caso contrário, a sonda pode relatar uma origem íntegra quando partes críticas do aplicativo estiverem realmente falhando. Por outro lado, não utilize a sonda de estado de funcionamento para verificar os serviços de prioridade inferior. Por exemplo, se um serviço de e-mail ficar inativo, a aplicação poderá mudar para um segundo fornecedor ou enviar os e-mails mais tarde. Para obter mais informações sobre esse padrão de design, consulte Padrão de monitoramento de ponto de extremidade de integridade.
Proteger as origens da Internet é uma parte crítica da implementação de uma aplicação acessível ao público. Consulte a implementação de entrada segura de rede para saber mais sobre os padrões de design e implementação recomendados pela Microsoft para proteger as comunicações de entrada do seu aplicativo com o Front Door.
CDN. Use a funcionalidade CDN nativa do Front Door para armazenar conteúdo estático em cache. O benefício principal de uma CDN é a redução de latência para os utilizadores, uma vez que o conteúdo é colocado em cache num servidor Edge geograficamente próximo do utilizador. A CDN também pode reduzir a carga sobre a aplicação pois esse tráfego não está a ser processado pela aplicação. O Front Door também oferece aceleração dinâmica do site, permitindo que você ofereça uma melhor experiência geral do usuário para seu aplicativo Web do que estaria disponível apenas com cache de conteúdo estático.
Nota
A CDN Front Door não foi projetada para fornecer conteúdo que exija autenticação.
Base de Dados SQL
Use grupos ativos de replicação geográfica e failover automático para tornar seus bancos de dados resilientes. A replicação geográfica ativa permite replicar seus bancos de dados da região primária para uma ou mais (até quatro) outras regiões. Os grupos de failover automático são criados com base na replicação geográfica ativa, permitindo que você faça failover para um banco de dados secundário sem alterações de código em seus aplicativos. Os failovers podem ser executados manualmente ou automaticamente, de acordo com as definições de política que você criar. Para usar grupos de failover automático, você precisará configurar suas cadeias de conexão com a cadeia de conexão de failover criada automaticamente para o grupo de failover, em vez das cadeias de conexão dos bancos de dados individuais.
Azure Cosmos DB
O Azure Cosmos DB dá suporte à replicação geográfica entre regiões no padrão ativo-ativo com várias regiões de gravação. Como alternativa, você pode designar uma região como a região gravável e as outras como réplicas somente leitura. Se houver uma interrupção regional, você poderá fazer failover selecionando outra região para ser a região de gravação. O SDK do cliente envia automaticamente pedidos de escrita para a região de escrita atual, por isso, não precisa de atualizar a configuração do cliente após uma ativação pós-falha. Para obter mais informações, consulte Distribuição global de dados com o Azure Cosmos DB.
Armazenamento
Para o Armazenamento do Microsoft Azure, utilize armazenamento georredundante com acesso de leitura (RA-GRS). Com o armazenamento RA-GRS, os dados são replicados para uma região secundária. Tem acesso só de leitura aos dados na região secundária através de um ponto de final separado. O failover iniciado pelo usuário para a região secundária é suportado para contas de armazenamento replicadas geograficamente. Iniciar um failover de conta de armazenamento atualiza automaticamente os registros DNS para tornar a conta de armazenamento secundário a nova conta de armazenamento principal. Os failovers só devem ser realizados quando você julgar necessário. Esse requisito é definido pelo plano de recuperação de desastres da sua organização e você deve considerar as implicações conforme descrito na seção Considerações abaixo.
Se houver uma interrupção ou desastre regional, a equipe de Armazenamento do Azure pode decidir executar um failover geográfico para a região secundária. Para esses tipos de failovers, não é necessária nenhuma ação do cliente. O failback para a região primária também é gerenciado pela equipe de armazenamento do Azure nesses casos.
Em alguns casos, a replicação de objetos para blobs de bloco será uma solução de replicação suficiente para sua carga de trabalho. Esse recurso de replicação permite copiar blobs de bloco individuais da conta de armazenamento principal para uma conta de armazenamento na região secundária. Os benefícios dessa abordagem são um controle granular sobre quais dados estão sendo replicados. Você pode definir uma política de replicação para um controle mais granular dos tipos de blobs de bloco que são replicados. Exemplos de definições de política incluem, mas não estão limitados a:
- Somente os blobs de bloco adicionados após a criação da política são replicados
- Apenas os blobs de bloco adicionados após uma determinada data e hora são replicados
- Apenas blobs de bloco correspondentes a um determinado prefixo são replicados.
O armazenamento em fila é referenciado como uma opção de mensagens alternativa ao Barramento de Serviço do Azure para este cenário. No entanto, se você usar o armazenamento em fila para sua solução de mensagens, as orientações fornecidas acima em relação à replicação geográfica se aplicam aqui, pois o armazenamento em fila reside em contas de armazenamento. É importante entender, no entanto, que as mensagens não são replicadas para a região secundária e seu estado é indissociável da região.
Azure Service Bus
Para se beneficiar da maior resiliência oferecida para o Barramento de Serviço do Azure, use a camada premium para seus namespaces. A camada premium usa zonas de disponibilidade, o que torna seus namespaces resilientes a interrupções do data center. Se houver um desastre generalizado que afete vários data centers, o recurso de recuperação de desastres geográficos incluído na camada premium pode ajudá-lo a se recuperar. O recurso de recuperação de desastres geográficos garante que toda a configuração de um namespace (filas, tópicos, assinaturas e filtros) seja replicada continuamente de um namespace primário para um namespace secundário quando emparelhado. Ele permite que você inicie uma mudança de failover única do primário para o secundário a qualquer momento. A movimentação de failover reapontará o nome de alias escolhido para o namespace para o namespace secundário e, em seguida, quebrará o emparelhamento. O failover é quase instantâneo uma vez iniciado.
Azure Cognitive Search
Na Pesquisa Cognitiva, a disponibilidade é alcançada por meio de várias réplicas, enquanto a continuidade de negócios e a recuperação de desastres (BCDR) são alcançadas por meio de vários serviços de pesquisa.
Na Pesquisa Cognitiva, as réplicas são cópias do seu índice. Ter várias réplicas permite que a Pesquisa Cognitiva do Azure faça reinicializações de máquina e manutenção em uma réplica, enquanto a execução da consulta continua em outras réplicas. Para obter mais informações sobre como adicionar réplicas, consulte Adicionar ou reduzir réplicas e partições.
Você pode utilizar as Zonas de Disponibilidade com a Pesquisa Cognitiva do Azure adicionando duas ou mais réplicas ao seu serviço de pesquisa. Cada réplica será colocada em uma zona de disponibilidade diferente dentro da região.
Para obter considerações sobre BCDR, consulte a documentação Vários serviços em regiões geográficas separadas.
Cache do Azure para Redis
Embora todas as camadas do Cache Redis do Azure ofereçam replicação Standard para alta disponibilidade, a camada Premium ou Enterprise é recomendada para fornecer um nível mais alto de resiliência e capacidade de recuperação. Analise a Alta disponibilidade e a recuperação de desastres para obter uma lista completa de recursos e opções de resiliência e capacidade de recuperação para esses níveis. Seus requisitos de negócios determinarão qual camada é a mais adequada para sua infraestrutura.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios orientadores que podem ser usados para melhorar a qualidade de uma carga de trabalho. Para obter mais informações, consulte Microsoft Azure Well-Architected Framework.
Fiabilidade
A confiabilidade garante que seu aplicativo possa atender aos compromissos que você assume com seus clientes. Para obter mais informações, consulte Visão geral do pilar de confiabilidade. Considere esses pontos ao projetar para alta disponibilidade entre regiões.
Azure Front Door
O Azure Front Door faz failover automaticamente se a região primária ficar indisponível. Quando o Front Door falha, há um período de tempo (geralmente cerca de 20 a 60 segundos) em que os clientes não conseguem acessar o aplicativo. A duração é afetada pelos seguintes fatores:
- Frequência das sondas de saúde. Quanto mais freqüentes as sondas de saúde são enviadas, mais rápido a Front Door pode detetar o tempo de inatividade ou a origem voltando saudável.
- Configuração do tamanho da amostra. Essa configuração controla quantas amostras são necessárias para que a sonda de integridade detete que a origem primária se tornou inacessível. Se esse valor for muito baixo, você pode obter falsos positivos de problemas intermitentes.
O Front Door é um ponto de falha possível no sistema. Se o serviço falhar, os clientes não poderão acessar seu aplicativo durante o tempo de inatividade. Reveja o Contrato de nível de serviço (SLA) do Front Door e determine se a utilização do Front Door cumpre os seus requisitos empresariais para elevada disponibilidade. Se não for o caso, pondere adicionar outra solução de gestão de tráfego para fins de contingência. Se o serviço Front Door falhar, altere os registos do nome canónico (CNAME) no DNS para que apontem para outro serviço de gestão de tráfego. Este passo tem de ser realizado manualmente e a aplicação ficará indisponível até que as alterações do DNS sejam propagadas.
O Azure Front Door Standard e o nível Premium combinam os recursos do Azure Front Door (clássico), do Azure CDN Standard da Microsoft (clássico) e do Azure WAF em uma única plataforma. Usar o Azure Front Door Standard ou Premium reduz os pontos de falha e permite controle, monitoramento e segurança aprimorados. Para obter mais informações, consulte Visão geral da camada do Azure Front Door.
Base de Dados SQL
O RPO (Recovery Point Objetive, objetivo de ponto de recuperação) e o RTO (Recovery Time Objetive, objetivo de tempo de recuperação) estimado para o Banco de Dados SQL estão documentados em Visão geral da continuidade de negócios com o Banco de Dados SQL do Azure.
Lembre-se de que a replicação geográfica ativa efetivamente dobra o custo de cada banco de dados replicado. Os bancos de dados de sandbox, teste e desenvolvimento normalmente não são recomendados para replicação.
Azure Cosmos DB
O RPO e o RTO (Recovery Time Objetive, objetivo de tempo de recuperação) para o Azure Cosmos DB são configuráveis por meio dos níveis de consistência usados, que fornecem compensações entre disponibilidade, durabilidade de dados e taxa de transferência. O Azure Cosmos DB fornece um RTO mínimo de 0 para um nível de consistência relaxado com multimestre ou um RPO de 0 para forte consistência com mestre único. Para saber mais sobre os níveis de consistência do Azure Cosmos DB, consulte Níveis de consistência e durabilidade de dados no Azure Cosmos DB.
Armazenamento
O armazenamento RA-GRS fornece armazenamento durável, mas é importante considerar os seguintes fatores ao considerar a execução de um failover:
Antecipar a perda de dados: a replicação de dados para a região secundária é realizada de forma assíncrona. Portanto, se um failover geográfico for executado, alguma perda de dados deve ser antecipada se as alterações na conta principal não tiverem sido totalmente sincronizadas com a conta secundária. Você pode verificar a propriedade Last Sync Time da conta de armazenamento secundária para ver a última vez que os dados da região primária foram gravados com êxito na região secundária.
Planeje seu RTO (Recovery Time Objetive, objetivo de tempo de recuperação) de acordo: o failover para a região secundária normalmente leva cerca de uma hora, portanto, seu plano de DR deve levar essas informações em consideração ao calcular seus parâmetros de RTO.
Planeje seu failback com cuidado: é importante entender que, quando uma conta de armazenamento faz failover, os dados na conta principal original são perdidos. Tentar um failback para a região primária sem um planejamento cuidadoso é arriscado. Após a conclusão do failover, o novo primário - na região de failover - será configurado para LRS (armazenamento com redundância local). Você deve reconfigurá-lo manualmente como armazenamento replicado geograficamente para iniciar a replicação para a região primária e, em seguida, dar tempo suficiente para permitir que as contas sejam sincronizadas.
Falhas transitórias, como uma interrupção de rede, não desencadearão um failover de armazenamento. Crie uma aplicação para que seja resiliente a falhas transitórias. As opções de mitigação incluem:
- Leitura a partir da região secundária.
- Alteração temporária para outra conta de armazenamento para novas operações de escrita (por exemplo, para mensagens de fila).
- Cópia de dados da região secundária para outra conta de armazenamento.
- Funcionalidade reduzida até à reativação pós-falha do sistema.
Para obter informações, veja O que fazer em caso de falha do Armazenamento do Azure.
Consulte os pré-requisitos e advertências para a documentação de replicação de objetos para obter considerações ao usar a replicação de objetos para blobs de bloco.
Azure Service Bus
É importante entender que o recurso de recuperação de desastres geográficos incluído na camada premium do Barramento de Serviço do Azure permite a continuidade instantânea das operações com a mesma configuração. No entanto, ele não replica as mensagens mantidas em filas ou assinaturas de tópicos ou filas de letras mortas. Como tal, uma estratégia de mitigação é necessária para garantir um failover suave para a região secundária. Para obter uma descrição detalhada de outras considerações e estratégias de mitigação, consulte os pontos importantes a serem considerados e a documentação de considerações sobre recuperação de desastres.
Segurança
A segurança oferece garantias contra ataques deliberados e o abuso de seus valiosos dados e sistemas. Para obter mais informações, consulte Visão geral do pilar de segurança.
Restringir tráfego de entrada Configure o aplicativo para aceitar tráfego somente da Front Door. Isso garante que todo o tráfego passe pelo WAF antes de chegar ao aplicativo. Para obter mais informações, consulte Como bloquear o acesso ao meu back-end apenas no Azure Front Door?
Compartilhamento de recursos entre origens (CORS) Se você criar um site e uma API da Web como aplicativos separados, o site não poderá fazer chamadas AJAX do lado do cliente para a API, a menos que você habilite o CORS.
Nota
A segurança do browser impede que uma página Web realize pedidos de AJAX para outro domínio. Essa restrição é chamada de política de mesma origem e impede que um site mal-intencionado leia dados confidenciais de outro site. O CORS é uma norma W3C que permite a um servidor reduzir a política da mesma origem e permite alguns pedidos de várias origens, ao mesmo tempo que rejeita outros.
Os Serviços de Aplicações possuem um suporte incorporado para CORS, sem que seja preciso escrever qualquer código de aplicação. Veja Consumir uma aplicação API de JavaScript com CORS. Adicione o site à lista de origens permitidas para a API.
Criptografia do Banco de dados SQL Use a criptografia de dados transparente se precisar criptografar dados inativos no banco de dados. Esta funcionalidade realiza a encriptação e desencriptação em tempo real de uma base de dados completa (incluindo cópias de segurança e ficheiros de registo de transações) e não carece de qualquer alteração à aplicação. A encriptação adiciona alguma latência, pelo que é uma boa prática separar os dados que têm de estar protegidos na sua própria base de dados e ativar a encriptação apenas para essa base de dados.
Identidade Ao definir identidades para os componentes dessa arquitetura, use identidades gerenciadas pelo sistema sempre que possível para reduzir a necessidade de gerenciar credenciais e os riscos inerentes ao gerenciamento de credenciais. Quando não for possível usar identidades gerenciadas pelo sistema, certifique-se de que cada identidade gerenciada pelo usuário exista em apenas uma região e nunca seja compartilhada entre os limites da região.
Firewalls de serviço Ao configurar os firewalls de serviço para os componentes, certifique-se de que apenas os serviços locais da região tenham acesso aos serviços e que os serviços só permitam conexões de saída, o que é explicitamente necessário para a replicação e a funcionalidade do aplicativo. Considere usar o Azure Private Link para obter controle e segmentação aprimorados. Para obter mais informações sobre como proteger aplicativos Web, consulte Aplicativo Web com redundância de zona altamente disponível de linha de base.
Otimização de custos
A otimização de custos consiste em procurar formas de reduzir despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Visão geral do pilar de otimização de custos.
Cache Use o cache para reduzir a carga em servidores que fornecem conteúdo que não é alterado com frequência. Cada ciclo de renderização de uma página pode afetar o custo porque consome computação, memória e largura de banda. Esses custos podem ser reduzidos significativamente usando cache, especialmente para serviços de conteúdo estático, como aplicativos JavaScript de página única e conteúdo de streaming de mídia.
Se seu aplicativo tiver conteúdo estático, use a CDN para diminuir a carga nos servidores front-end. Para dados que não são alterados com frequência, use o Cache do Azure para Redis.
Os aplicativos sem estado configurados para dimensionamento automático são mais econômicos do que os aplicativos com monitoração de estado. Para um aplicativo ASP.NET que usa o estado da sessão, armazene-o na memória com o Cache do Azure para Redis. Para obter mais informações, consulte ASP.NET Provedor de Estado da Sessão para o Cache do Azure para Redis. Outra opção é usar o Azure Cosmos DB como um armazenamento de estado de back-end por meio de um provedor de estado de sessão. Consulte Usar o Azure Cosmos DB como um ASP.NET estado de sessão e provedor de cache.
Funções Considere colocar um aplicativo de função em um plano dedicado do Serviço de Aplicativo para que as tarefas em segundo plano não sejam executadas nas mesmas instâncias que lidam com solicitações HTTP. Se as tarefas em segundo plano forem executadas intermitentemente, considere o uso de um plano de consumo, que é cobrado com base no número de execuções e recursos usados, em vez de por hora.
Para obter mais informações, consulte a seção de custo no Microsoft Azure Well-Architected Framework.
Use a calculadora de preços para estimar custos. Estas recomendações nesta secção podem ajudá-lo a reduzir custos.
Azure Front Door
A cobrança do Azure Front Door tem três níveis de preço: transferências de dados de saída, transferências de dados de entrada e regras de roteamento. Para obter mais informações, consulte Preços da porta frontal do Azure. A tabela de preços não inclui o custo de acesso aos dados dos serviços de origem e transferência para o Front Door. Esses custos são cobrados com base nas taxas de transferência de dados, descritas em Detalhes de preços de largura de banda.
Azure Cosmos DB
Há dois fatores que determinam os preços do Azure Cosmos DB:
A taxa de transferência provisionada ou Unidades de solicitação por segundo (RU/s).
Há dois tipos de taxa de transferência que podem ser provisionados no Azure Cosmos DB, padrão e dimensionamento automático. A taxa de transferência padrão aloca os recursos necessários para garantir o RU/s especificado. Para dimensionamento automático, você provisiona a taxa de transferência máxima e o Azure Cosmos DB aumenta ou diminui instantaneamente, dependendo da carga, com um mínimo de 10% da taxa de transferência máxima de escala automática. A taxa de transferência padrão é cobrada pela taxa de transferência provisionada por hora. A taxa de transferência de dimensionamento automático é cobrada pela taxa de transferência máxima consumida por hora.
Armazenamento consumido. É cobrada uma taxa fixa pela quantidade total de armazenamento (GBs) consumida pelos dados e pelos índices de uma determinada hora.
Para obter mais informações, veja a secção de custos Well-Architected Framework do Microsoft Azure.
Eficiência de desempenho
Uma vantagem principal do Serviço de Aplicações do Azure é a capacidade de dimensionar a aplicação com base na carga. Seguem-se algumas considerações a lembrar quando planear dimensionar a aplicação.
Aplicação do Serviço de Aplicações
Se a sua solução incluir várias aplicações do Serviço de Aplicações, considere implementá-las em planos separados do Serviço de Aplicações. Esta abordagem permite-lhe dimensioná-las de forma independente, uma vez que são executadas em instâncias separadas.
Base de Dados SQL
Aumente a escalabilidade de uma base de dados SQL através fragmentação da base de dados. A fragmentação refere-se à criação de partições da base de dados horizontalmente. A fragmentação permite-lhe aumentar horizontalmente a base de dados com as ferramentas da Base de Dados Elástica. Potenciais benefícios da fragmentação:
- Melhor débito de transação.
- As consultas podem ser executados mais rapidamente num subconjunto dos dados.
Azure Front Door
O Front Door pode realizar o descarregamento SSL e também reduz o número total de conexões TCP com o aplicativo Web de back-end. Isso melhora a escalabilidade porque o aplicativo Web gerencia um volume menor de handshakes SSL e conexões TCP. Esses ganhos de desempenho se aplicam mesmo se você encaminhar as solicitações para o aplicativo Web como HTTPS, devido ao alto nível de reutilização da conexão.
Azure Search
O Azure Search remove a sobrecarga da realização de pesquisas de dados complexas do arquivo de dados primário e pode ser dimensionado para processar carga. Veja Dimensionar níveis de recursos para consulta e indexação de cargas de trabalho no Azure Search.
Excelência operacional
A excelência operacional refere-se aos processos operacionais que implantam um aplicativo e o mantêm em execução em produção e é uma extensão da orientação de confiabilidade do Well-Architected Framework. Este guia fornece uma visão geral detalhada da resiliência de arquitetura em sua estrutura de aplicativo para garantir que suas cargas de trabalho estejam disponíveis e possam se recuperar de falhas em qualquer escala. Um princípio central dessa abordagem é projetar sua infraestrutura de aplicativos para ser altamente disponível, de forma otimizada em várias regiões geográficas, como este design ilustra.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Arvind Boggaram Pandurangaiah Setty - Brasil | Consultor Sénior
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
Aprofundamento no Azure Front Door - métodos de roteamento de tráfego
Criar testes de integridade que relatam a integridade geral do aplicativo com base em padrões de monitoramento de ponto de extremidade
Recursos relacionados
O aplicativo de N camadas de várias regiões é um cenário semelhante. Ele mostra um aplicativo de N camadas em execução em várias regiões do Azure