Recuperação de desastre regional para clusters do Azure Databricks
Este artigo descreve uma arquitetura de recuperação de desastre útil para clusters do Azure Databricks e as etapas para obter esse design.
Arquitetura do Azure Databricks
Quando você cria um espaço de trabalho do Azure Databricks a partir do portal do Azure, um aplicativo gerenciado é implantado como um recurso do Azure na sua assinatura, na região do Azure escolhida (por exemplo, Oeste dos EUA). Esse dispositivo é implantado em uma Rede Virtual do Azure com um Grupo de Segurança de Rede e uma conta de Armazenamento do Azure, disponível em sua assinatura. A rede virtual fornece segurança em nível de perímetro para o workspace do Databricks e é protegida por meio de um grupo de segurança de rede. No espaço de trabalho, você cria os clusters do Databricks fornecendo o tipo de VM do trabalho e do driver e a versão de runtime do Databricks. Os dados persistentes estão disponíveis na sua conta de armazenamento. Após a criação do cluster, você poderá executar trabalhos por meio de notebooks, APIs REST ou pontos de extremidade ODBC/JDBC, anexando-os a um cluster específico.
O painel de controle do Databricks gerencia e monitora o ambiente de workspace do Databricks. Qualquer operação de gerenciamento, como criar clusters, será iniciada a partir do painel de controle. Todos os metadados, como trabalhos agendados, são armazenados em um Banco de Dados do Azure e os backups do banco de dados são automaticamente replicados geograficamente nas regiões emparelhadas onde são implementados.
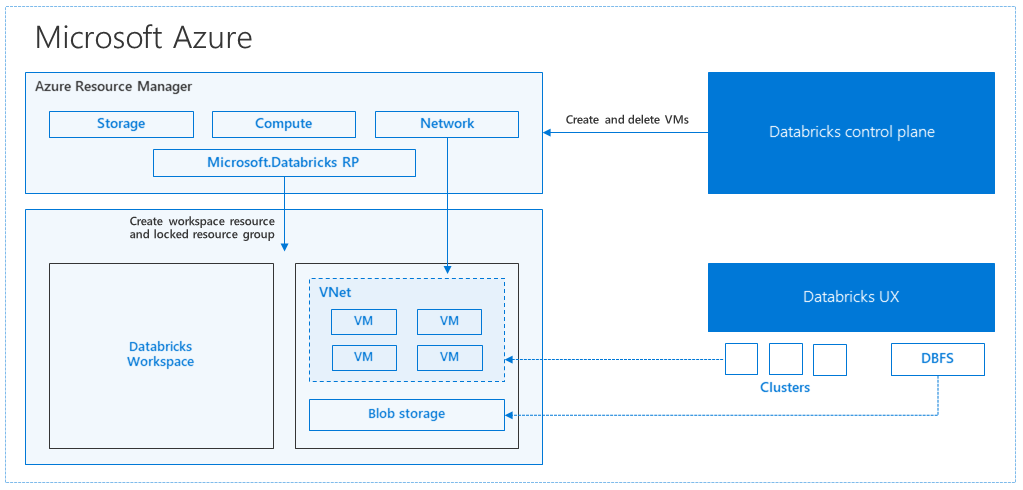
Uma das vantagens dessa arquitetura é que os usuários podem conectar o Azure Databricks a qualquer recurso de armazenamento em sua conta. Um benefício importante é que a computação (Azure Databricks) e o armazenamento podem ser dimensionados independentemente uns dos outros.
Como criar uma topologia de recuperação de desastre regional
Na descrição da arquitetura anterior, há vários componentes utilizados para um pipeline de Big Data com o Azure Databricks: Armazenamento do Microsoft Azure, Banco de Dados do Azure e outras fontes de dados. O Azure Databricks é a computação para pipeline de Big Data. É de natureza efêmera, o que significa que, embora seus dados ainda estejam disponíveis no Armazenamento do Microsoft Azure, a computação (cluster Azure Databricks) pode ser encerrada para evitar o pagamento pela computação quando você não precisar dela. A computação (Azure Databricks) e fontes de armazenamento devem estar na mesma região para que os trabalhos não apresentem alta latência.
Para criar sua própria topologia de recuperação de desastre regional, siga estes requisitos:
Provisione vários workspaces do Azure Databricks em regiões do Azure separadas. Por exemplo, crie o workspace primário do Azure Databricks no Leste dos EUA. Crie o workspace secundário do Azure Databricks para recuperação de desastre em uma região separada, como Oeste dos EUA. Para obter uma lista de regiões de Azure emparelhadas, veja Replicação entre regiões. Para obter detalhes sobre as regiões do Azure Databricks, veja Regiões com suporte.
Use o armazenamento com redundância geográfica. Por padrão, os dados associados ao Azure Databricks são armazenados no Armazenamento do Azure, e os resultados dos trabalhos do Databricks são armazenados no Armazenamento de Blobs do Azure, de modo que os dados processados sejam duráveis e permaneçam altamente disponíveis após o cluster ser encerrado. O armazenamento de cluster e o armazenamento de trabalhos estão localizados na mesma zona de disponibilidade. Para proteção contra indisponibilidade regional, os workspaces do Azure Databricks usam o armazenamento com redundância geográfica por padrão. Com o armazenamento com redundância geográfica, os dados são replicados para uma região emparelhada do Azure. O Databricks recomenda que você mantenha o padrão de armazenamento com redundância geográfica, mas se precisar usar o armazenamento com redundância local, poderá definir
storageAccountSkuNamecomoStandard_LRSno modelo do ARM do workspace.Depois de criar a região secundária, será necessário migrar os usuários, pastas do usuário, blocos de notas, configuração do cluster, configuração de trabalhos, bibliotecas, armazenamento, scripts init e reconfigurar o controle de acesso. Mais detalhes são descritos na seguinte seção.
Desastre regional
Para se preparar para desastres regionais, você precisa manter explicitamente outro conjunto de Workspaces do Azure Databricks em uma região secundária. Consulte Recuperação de desastres.
Nossas ferramentas recomendadas para a recuperação de desastres são principalmente Terraform (para replicação de Infraestrutura) e Delta Deep Clone (para replicação de dados).
Etapas de migração detalhadas
Configurar a interface de linha de comando do Databricks em seu computador
Este artigo mostra um número de exemplos de código que usam a interface de linha de comando para a maioria das etapas automatizadas, porque ela é um wrapper fácil de usar por meio da API REST do Azure Databricks.
Antes de executar quaisquer etapas de migração, instale o databricks-cli em seu computador desktop ou em uma máquina virtual em que você planeja realizar o trabalho. Para obter mais informações, consulte Install Databricks CLI (Instalar CLI do Databricks)
pip install databricks-cliObservação
Todos os scripts do Python fornecidos neste artigo devem funcionar com o Python 2.7 e superior < 3.x.
Configurar dois perfis.
Configure um para o workspace primário e outro para o workspace secundário:
databricks configure --profile primary --token databricks configure --profile secondary --tokenOs blocos de código neste artigo alternam entre perfis em cada etapa subsequente usando o comando do workspace correspondente. Certifique-se de que os nomes dos perfis criados sejam substituídos em cada bloco de código.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"É possível alternar manualmente na linha de comando, se necessário:
databricks workspace ls --profile primary databricks workspace ls --profile secondaryMigrar usuários do Microsoft Entra ID (antigo Azure Active Directory)
Adicione manualmente os mesmos usuários do Microsoft Entra ID (antigo Azure Active Directory) ao workspace secundário que existe no workspace primário.
Migrar as pastas de usuário e os blocos de anotações
Use o seguinte código do python para migrar os ambientes de usuário em sandbox, que incluem os blocos de anotações e a estrutura de pasta aninhada por usuário.
Observação
As bibliotecas não são copiadas nesta etapa, porque a API subjacente não dá suporte a elas.
Copiar e salvar o seguinte script python em um arquivo e executá-lo em sua linha de comando do Databricks. Por exemplo,
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "ls", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")Migrar as configurações de cluster
Após a migração dos blocos de notas, será possível, opcionalmente, migrar as configurações de cluster para o novo workspace. Usar o databricks-cli é quase uma etapa totalmente automatizada, a menos que você deseje realizar a migração de configuração de cluster seletiva em vez de para todos.
Observação
Infelizmente, não há nenhum ponto de extremidade de configuração de cluster de criação, e esse script tenta criar cada cluster imediatamente. Se não houver núcleos suficientes disponíveis em sua assinatura, a criação do cluster poderá falhar. A falha pode ser ignorada, contanto que a configuração seja transferida com êxito.
O script fornecido a seguir imprime um mapeamento de IDs de cluster antigas para novas, o que poderia ser usado para migração de trabalhos posteriormente (para trabalhos configurados para usar clusters existentes).
Copiar e salvar o seguinte script python em um arquivo e executá-lo em sua linha de comando do Databricks. Por exemplo,
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")). splitlines() print("Printting Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append (cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")Migrar a configuração de trabalhos
Se você migrou configurações de cluster na etapa anterior, é possível optar por migrar configurações de trabalho para o novo workspace. Usar o databricks-cli é uma etapa totalmente automatizada, a menos que você deseje realizar uma migração de configuração de trabalho seletiva, em vez de fazer isso para todos os trabalhos.
Observação
A configuração de um trabalho agendado contém as informações do "agendamento" também; portanto, por padrão, ela começará a funcionar de acordo com o tempo configurado assim que for migrada. Portanto, o bloco de código a seguir remove quaisquer informações de agendamento durante a migração (para evitar execuções duplicadas entre workspaces antigos e novos). Configure os agendamentos para esses trabalhos depois que estiver pronto para a substituição.
A configuração do trabalho requer configurações para um cluster novo ou um existente. Se estiver usando um cluster, o script/código abaixo tentará substituir a ID do cluster antigo pela nova.
Copiar e salvar o seguinte script python para um arquivo. Substitua o valor de
old_cluster_idenew_cluster_idpela saída da migração do cluster feita na etapa anterior. Execute-o em sua linha de comando databricks-cli, por exemplo,python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate ") + job job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id ") + job_req_settings_json['existing_cluster_id'] continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Migrar bibliotecas
No momento, não há uma maneira simples de migrar bibliotecas de um workspace para outro. Em vez disso, reinstale essas bibliotecas no novo workspace manualmente. É possível automatizar usando a combinação da CLI DBFS para carregar bibliotecas personalizadas para o workspace e para a CLI das bibliotecas.
Migrar as montagens do Armazenamento de Blobs do Azure e do Azure Data Lake Storage
Remonte manualmente todos os pontos de montagem do Armazenamento Blob do Azure e do Azure Data Lake Storage (Gen 2) usando uma solução baseada em notebook. Os recursos de armazenamento teriam sido montados no workspace primário, e isso precisaria ser repetido no workspace secundário. Não há nenhuma API externa para montagens.
Migrar scripts de inicialização de cluster
Quaisquer scripts de inicialização de cluster podem ser migrados do workspace antigo para o novo usando a CLI DBFS. Primeiro, copie os scripts necessários do
dbfs:/dat abricks/init/..para a sua área de trabalho local ou máquina virtual. Em seguida, copie esses scripts para o novo workspace no mesmo caminho.// Primary to local dbfs cp -r dbfs:/databricks/init ./old-ws-init-scripts --profile primary // Local to Secondary workspace dbfs cp -r old-ws-init-scripts dbfs:/databricks/init --profile secondaryReconfigurar manualmente e reaplicar o controle de acesso.
Se seu workspace primário existente for configurado para usar a camada Premium ou Enterprise (SKU), você provavelmente também estará usando o recurso de Controle de Acesso.
Se você usar o recurso de Controle de acesso manualmente, reaplique o controle de acesso aos recursos (Blocos de anotações, clusters, trabalhos, tabelas).
Recuperação de desastre para seu ecossistema do Azure
Se estiver usando outros serviços do Azure, implemente as melhores práticas de recuperação de desastre para esses serviços também. Por exemplo, se você optar por usar uma instância externa do metastore do Hive, considere o uso da recuperação de desastre para o Banco de Dados SQL do Azure, o Azure HDInsight e/ou o Banco de Dados do Azure para MySQL. Para obter informações gerais sobre a recuperação de desastre, confira Recuperação de desastre para aplicativos do Azure.
Próximas etapas
Para obter mais informações, consulte a documentação do Azure Databricks.