Tutorial: Criar um pipeline de dados de ponta a ponta para obter insights de vendas no Azure HDInsight
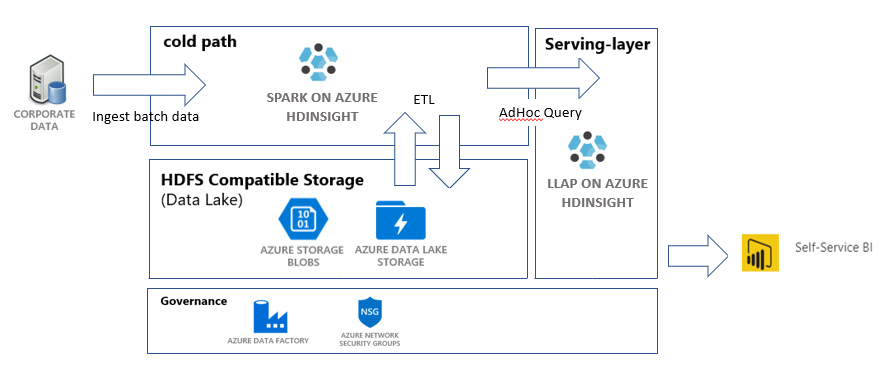
Neste tutorial, você criará um pipeline de dados ponta a ponta, que executa operações de ETL (extração, transformação e carregamento). O pipeline usará clusters Apache Spark e Apache Hive em execução no Azure HDInsight para consulta e manipulação dos dados. Você também usará tecnologias como o Azure Data Lake Storage Gen2 para armazenamento de dados e o Power BI para visualização.
Esse pipeline de dados combina os dados de vários repositórios, remove os dados indesejados, acrescenta novos dados e carrega tudo isso novamente no armazenamento para visualizar insights empresariais. Leia mais sobre pipelines de ETL (extração, transformação e carregamento) em escala.
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
CLI do Azure – versão 2.2.0 ou posterior. Confira Instalar a CLI do Azure.
jq, um processador JSON de linha de comando. Consulte https://stedolan.github.io/jq/.
Um membro da Função interna do Azure – proprietário.
Se você estiver usando o PowerShell para disparar o pipeline do Data Factory, precisará do módulo Az.
Power BI Desktop para visualizar insights empresariais no final deste tutorial.
Criar recursos
Clonar o repositório com scripts e dados
Acesse a sua assinatura do Azure. Se você pretende usar o Azure Cloud Shell, selecione Experimentar no canto superior direito do bloco de código. Caso contrário, insira o comando a seguir:
az login # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"Verifique se você é membro da função proprietário do Azure. Substitua
user@contoso.compela sua conta e, em seguida, insira o comando:az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"Se nenhum registro foi retornado, você não é um membro e não pode concluir este tutorial.
Baixe os dados e os scripts deste tutorial no repositório de ETL de insights de vendas do HDInsight. Insira o seguinte comando:
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etlVerifique se
salesdata scripts templatesfoi criado. Verifique com o seguinte comando:ls
Implantar os recursos do Azure necessários para o pipeline
Adicione permissões de execução para todos os scripts digitando:
chmod +x scripts/*.shDefina a variável para o grupo de recursos. Substitua
RESOURCE_GROUP_NAMEpelo nome de um grupo de recursos novo ou existente e, em seguida, digite o comando:RESOURCE_GROUP="RESOURCE_GROUP_NAME"Execute o script. Substitua
LOCATIONpor um valor desejado e, em seguida, digite o comando:./scripts/resources.sh $RESOURCE_GROUP LOCATIONSe você não tiver certeza de qual região especificar, poderá recuperar uma lista de regiões compatíveis com a assinatura com o comando az account list-locations.
O comando exibirá os seguintes recursos:
- Uma conta de Armazenamento de Blobs do Azure. Essa conta armazenará os dados de vendas da empresa.
- Uma conta do Azure Data Lake Storage Gen2. Essa conta servirá como a conta de armazenamento para ambos os clusters HDInsight. Leia mais sobre o HDInsight e o Data Lake Storage Gen2 na integração do Azure HDInsight ao Data Lake Storage Gen2.
- Uma identidade gerenciada atribuída ao usuário. Essa conta fornece aos clusters HDInsight o acesso à conta do Data Lake Storage Gen2.
- Um cluster do Apache Spark. Esse cluster será usado para limpar e transformar os dados brutos.
- Um cluster Interactive Query do Apache Hive. Esse cluster permitirá consultar os dados de vendas visualizando-os com o Power BI.
- Uma rede virtual do Azure compatível com as regras do NSG (grupo de segurança de rede). Essa rede virtual permite que os clusters se comuniquem e protejam suas comunicações.
A criação do cluster pode levar cerca de 20 minutos.
A senha padrão usada para acesso SSH aos clusters é Thisisapassword1. Caso deseje alterar a senha, vá até o arquivo ./templates/resourcesparameters_remainder.json e altere a senha para os parâmetros sparksshPassword, sparkClusterLoginPassword, llapClusterLoginPassword e llapsshPassword.
Verificar a implantação e coletar informações de recursos
Caso deseje verificar o status da implantação, vá até o grupo de recursos no portal do Azure. Em Configurações, selecione Implantações e depois a sua implantação. Aqui você pode ver os recursos que foram implantados com êxito e aqueles que ainda estão em andamento.
Para exibir os nomes dos clusters, digite o seguinte comando:
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAMEPara exibir a conta de armazenamento e a chave de acesso do Azure, insira o seguinte comando:
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEYPara exibir a conta e a chave de acesso do Azure Data Lake Storage Gen2, insira o seguinte comando:
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
Criar uma data factory
O Azure Data Factory é uma ferramenta que ajuda a automatizar Azure Pipelines. Não é a única maneira de realizar essas tarefas, mas é uma ótima forma de automatizar esses processos. Para obter mais informações sobre o Azure Data Factory, veja a Documentação do Azure Data Factory.
Esse data factory terá um pipeline com duas atividades:
- A primeira atividade copiará os dados do Armazenamento de Blobs do Azure para a conta de armazenamento do Data Lake Storage Gen 2 para simular a ingestão de dados.
- A segunda atividade transformará os dados no cluster Spark. O script transforma os dados removendo colunas indesejadas. Ele também acrescenta uma nova coluna que calcula a receita que uma única transação gera.
Para configurar o pipeline do Azure Data Factory, execute o comando abaixo. Você ainda deve estar no diretório hdinsight-sales-insights-etl.
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
Esse script realiza as seguintes ações:
- Cria uma entidade de serviço com permissões
Storage Blob Data Contributorna conta de armazenamento do Data Lake Storage Gen2. - Obtém um token de autenticação para autorizar solicitações POST para a API REST do sistema de arquivos do Data Lake Storage Gen2.
- Preenche o nome real de sua conta de armazenamento do Data Lake Storage Gen2 nos arquivos
sparktransform.pyequery.hql. - Obtém as chaves de armazenamento para o Data Lake Storage Gen2 e as Contas de Armazenamento de Blobs.
- Cria outra implantação de recurso para criar um pipeline do Azure Data Factory, com suas atividades e seus serviços vinculados associados. Ela passa as chaves de armazenamento como parâmetros para o arquivo de modelo, de modo que os serviços vinculados possam acessar as contas de armazenamento corretamente.
Executar o pipeline de dados
Disparar atividades do Data Factory
A primeira atividade no pipeline do Data Factory que você criou move os dados do Armazenamento de Blobs para o Data Lake Storage Gen2. A segunda atividade aplica as transformações do Spark nos dados e salva os arquivos .csv transformados em uma nova localização. O pipeline inteiro pode levar alguns minutos para ser concluído.
Para recuperar o nome do Data Factory, digite o seguinte comando:
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
Para disparar o pipeline, você pode escolher uma das seguintes alternativas:
Dispare o pipeline do Data Factory no PowerShell. Substitua
RESOURCEGROUPeDataFactoryNamepelos valores apropriados e, em seguida, execute os seguintes comandos:# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipelineExecute novamente
Get-AzDataFactoryV2PipelineRunconforme necessário para monitorar o progresso.Ou
Abra o data factory e selecione Criar e Monitorar. Dispare o pipeline
IngestAndTransformno portal. Para obter informações sobre como disparar pipelines por meio do portal, veja Criar clusters Apache Hadoop sob demanda no HDInsight usando o Azure Data Factory.
Para verificar se o pipeline foi executado, execute uma das seguintes etapas:
- Vá até a seção Monitorar no data factory por meio do portal.
- Em Gerenciador de Armazenamento do Azure, vá para sua conta de armazenamento do Data Lake Storage Gen 2. Vá para o sistema de arquivos
filese, em seguida, vá para a pastatransformede verifique seu conteúdo para ver se o pipeline foi bem-sucedido.
Para obter outras maneiras de transformar dados usando o HDInsight, veja artigo sobre como usar o Jupyter Notebook.
Criar uma tabela no cluster da Consulta Interativa para exibir dados no Power BI
Copie o arquivo
query.hqlpara o cluster LLAP usando o SCP. Insira o comando:LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net:/home/sshuser/Lembrete: A senha padrão é
Thisisapassword1.Use SSH para acessar o cluster LLAP. Insira o comando:
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.netUse o comando a seguir para executar o script:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hqlEsse script criará uma tabela gerenciada no cluster da Consulta Interativa que pode ser acessado no Power BI.
Criar um dashboard do Power BI dos dados de vendas
Abra o Power BI Desktop.
No menu, navegue até Obter dados>Mais...>Azure>Interactive Query do HDInsight.
Selecione Conectar.
Na caixa de diálogo Interactive Query do HDInsight:
- Na caixa de texto Servidor, digite o nome do cluster LLAP no formato
https://LLAPCLUSTERNAME.azurehdinsight.net. - Na caixa de texto banco de dados, digite
default. - Selecione OK.
- Na caixa de texto Servidor, digite o nome do cluster LLAP no formato
Na caixa de diálogo AzureHive:
- Na caixa de texto Nome de usuário, digite
admin. - Na caixa de texto Senha, insira
Thisisapassword1. - Selecione Conectar.
- Na caixa de texto Nome de usuário, digite
No Navegador, selecione
salese/ousales_rawpara visualizar os dados. Depois que os dados forem carregados, você poderá experimentar o painel que deseja criar. Confira os seguintes links para obter uma introdução aos dashboards do Power BI:
Limpar os recursos
Se não desejar continuar usando este aplicativo, exclua todos os recursos usando as etapas a seguir para não ser cobrado por eles.
Para remover o grupo de recursos, insira o comando:
az group delete -n $RESOURCE_GROUPPara remover a entidade de serviço, insira os comandos:
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL