Depurar um conjunto de habilidades da IA do Azure Search no portal do Azure
Inicie uma sessão de depuração baseada em portal para identificar e resolver erros, validar alterações e enviar alterações por push para um conjunto de habilidades publicado no serviço da IA do Azure Search.
Uma sessão de depuração é uma execução de indexador e conjunto de habilidades armazenados em cache, com escopo em um único documento, em que você pode usar para editar e testar suas alterações interativamente. Quando terminar de depurar, você poderá salvar as alterações no conjunto de habilidades.
Para obter informações sobre como funciona uma sessão de depuração, consulte Sessões de depuração na Pesquisa de IA do Azure. Para praticar um fluxo de trabalho de depuração com um documento de exemplo, confira Tutorial: sessões de depuração.
Pré-requisitos
Um pipeline de enriquecimento existente, incluindo uma fonte de dados, um conjunto de habilidades, um indexador e um índice.
Uma atribuição de função Colaborador no serviço Pesquisa.
Uma conta de armazenamento do Azure usada para salvar o estado de sessão.
Uma atribuição de função de Colaborador de Dados de Blob de Armazenamento no Armazenamento do Microsoft Azure se você estiver usando uma identidade gerenciada pelo sistema. Caso contrário, planeje usar uma cadeia de conexão de acesso completo para a conexão da sessão de depuração com o Armazenamento do Microsoft Azure.
Se a conta de Armazenamento do Microsoft Azure estiver por trás de um firewall, configure-a para permitir acesso de serviço de pesquisa.
Limitações
As sessões de depuração funcionam com todas as fontes de dados de indexador geralmente disponíveis e para a maioria das fontes de dados de pré-visualização. A lista a seguir destaca as exceções:
No momento, não há suporte ao Azure Cosmos DB for MongoDB.
Para o Azure Cosmos DB for NoSQL, se uma linha falhar durante o índice e não houver metadados correspondentes, pode ser que a sessão de depuração não escolha a linha correta.
Para a API do SQL do Azure Cosmos DB, se uma coleção particionada não tiver sido particionada anteriormente, a sessão de depuração não encontrará o documento.
Para habilidades personalizadas, não há suporte para uma identidade gerenciada atribuída pelo usuário para uma conexão de sessão de depuração com o Armazenamento do Microsoft Azure. Conforme indicado nos pré-requisitos, você pode usar uma identidade gerenciada pelo sistema ou especificar uma cadeia de conexão de acesso completo que inclua uma chave. Para obter mais informações, consulte Conectar um serviço de pesquisa a outros recursos do Azure usando uma identidade gerenciada.
O portal não dá suporte à CMK (criptografia de chave gerenciada pelo cliente), o que significa que as experiências do portal, como sessões de depuração, não podem ter cadeias de conexão criptografadas por CMK ou outros metadados criptografados. Se o serviço de pesquisa estiver configurado para imposição de CMK, as sessões de depuração não funcionarão.
Criar uma sessão de depuração
Entre no portal do Azure e localize seu serviço de pesquisa.
Na página de navegação à esquerda, selecione Sessões de depuração.
Na barra de ações na parte superior, selecione Adicionar sessão de depuração.
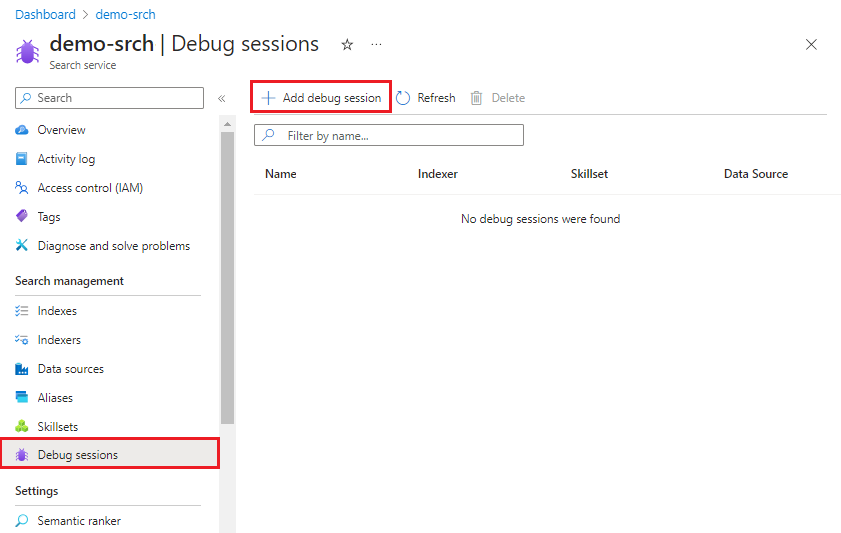
Em Nome da sessão de depuração, forneça um nome que ajudará você a se lembrar de qual conjunto de habilidades, do indexador e da fonte de dados sobre a sessão de depuração.
Em Conexão de armazenamento, encontre uma conta de armazenamento de uso geral para armazenar em cache a sessão de depuração. Será solicitado que você selecione e, opcionalmente, crie um contêiner de blob no Armazenamento de Blobs ou no Azure Data Lake Storage Gen2. É possível reutilizar o mesmo contêiner para todas as sessões de depuração subsequentes criadas por você. Um nome de contêiner útil pode ser "cognitive-search-debug-sessions".
Em Autenticação de identidade gerenciada, escolha Nenhuma se a conexão com o Armazenamento do Microsoft Azure não usar uma identidade gerenciada. Caso contrário, escolha a identidade gerenciada à qual você concedeu permissões de Colaborador de Dados de Blob de Armazenamento.
Em Modelo do indexador, selecione o indexador que orienta o conjunto de habilidades que você deseja depurar. As cópias do indexador e do conjunto de habilidades são usadas para inicializar a sessão.
Em documento a ser depurado, escolha o primeiro documento no índice ou selecione um documento específico. Se você selecionar um documento específico, dependendo da fonte de dados, deverá fornecer um URI ou uma ID de linha.
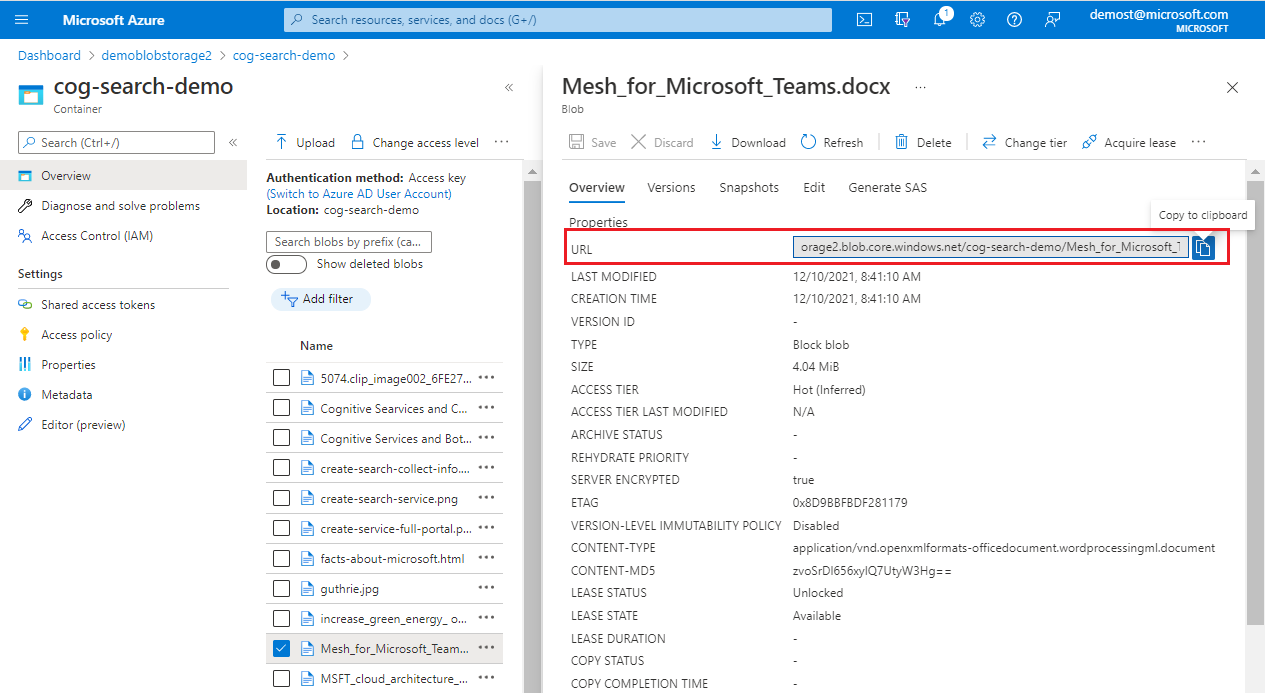
Se o documento específico for um blob, forneça o URI do blob. Você pode encontrar o URI na página de propriedades do blob no portal.
Opcionalmente, em Configurações do indexador, especifique quaisquer configurações de execução do indexador usadas para criar a sessão. As configurações devem imitar as definições usadas pelo indexador real. As opções do indexador que você especificar em uma sessão de depuração não terão efeito no indexador em si.
Sua configuração deve ser semelhante a esta captura de tela. Selecione Salvar sessão para começar.
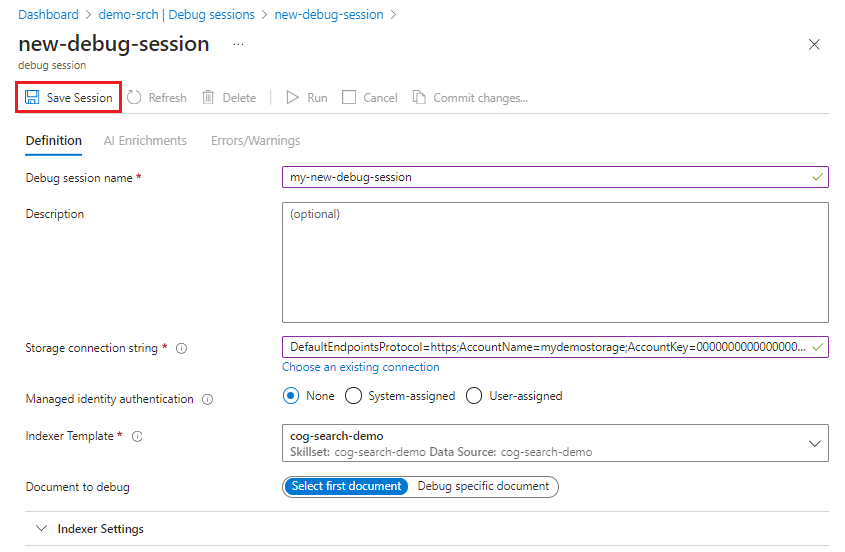
A sessão de depuração começa com a execução do indexador e do conjunto de habilidades no documento selecionado. O conteúdo e os metadados do documento criado estarão visíveis e disponíveis na sessão.
Uma sessão de depuração pode ser cancelada enquanto está em execução por meio do botão Cancelar. Se você apertar o botão Cancelar, poderá analisar os resultados parciais.
Espera-se que uma sessão de depuração leve mais tempo para ser executada do que o indexador, pois ela passa por processamento extra.
Iniciar com erros e avisos
O histórico de execução do indexador no portal fornece a lista completa de erros e avisos para todos os documentos. Em uma sessão de depuração, os erros e avisos estarão limitados a um documento. Você trabalhará nessa lista, fará suas alterações e, em seguida, voltará até a lista para verificar se os problemas foram resolvidos.
Para exibir as mensagens, selecione uma habilidade em Enriquecimento de IA> Gráfico de Habilidades, depois selecione Erros/Avisos no painel de detalhes.
Uma melhor prática a ser seguida é resolver os problemas com as entradas antes de passar para as saídas.
Para verificar se uma modificação resolve um erro, siga estas etapas:
Selecione Salvar no painel de detalhes de habilidade para preservar as alterações.
Selecione Executar na janela de sessão para invocar a execução do conjunto de habilidades usando a definição modificada.
Volte para Erros/Avisos para ver se a contagem foi reduzida. A lista não será atualizada até que você abra a guia.
Exibir o conteúdo dos nós de enriquecimento
Os pipelines de enriquecimento de IA extraem ou inferem informações e estruturas de documentos de origem, criando um documento aprimorado no processo. Um documento enriquecido é criado durante a quebra de documento e preenchido com um nó raiz (/document) e nós para qualquer conteúdo diretamente extraído da fonte de dados, como uma chave de documento e metadados. Mai nós são criados por habilidades durante a execução delas, em que cada saída de habilidade adiciona um novo nó à árvore de enriquecimento.
Os documentos enriquecidos são internos, mas uma sessão de depuração fornece acesso ao conteúdo produzido durante a execução da habilidade. Para exibir o conteúdo ou a saída de cada habilidade, siga estas etapas:
Comece com as exibições padrão: Enriquecimento de IA > Gráfico de Habilidades, com o tipo de gráfico definido como Gráfico de Dependência.
Selecione uma habilidade.
No painel de detalhes à direita, selecione Execuções, clique em uma SAÍDA e, depois, abra o Avaliador de Expressão (
</>) para exibir a expressão e o resultado dela.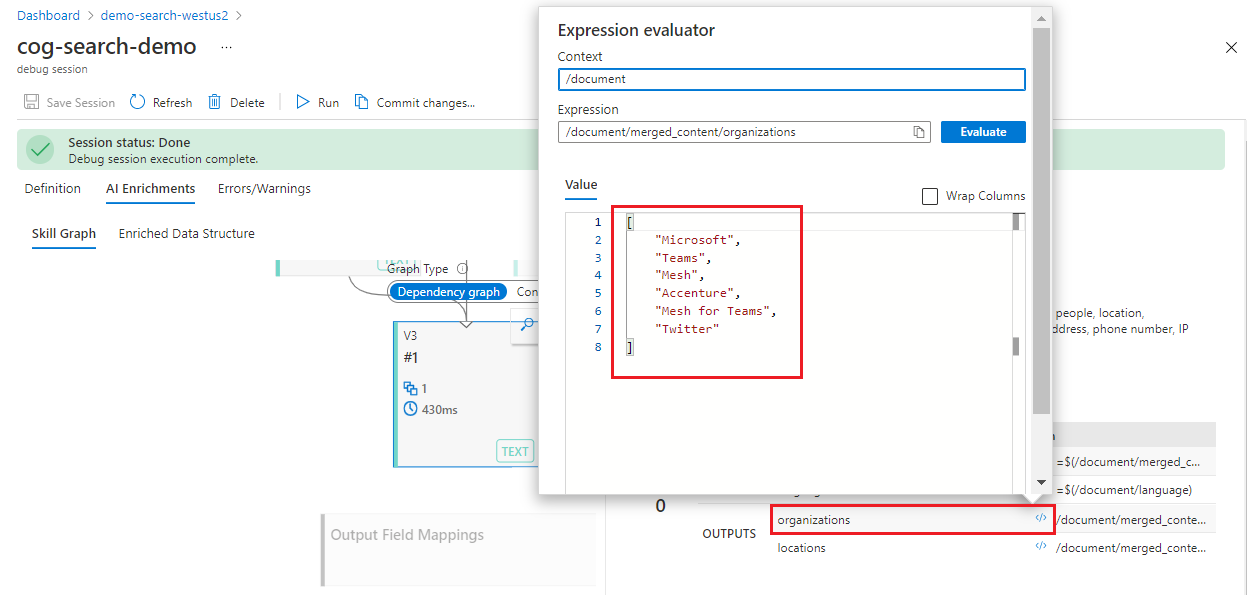
Como alternativa, abra Enriquecimento de IA > Estrutura de Dados Enriquecidos para percorrer a lista de nós. A lista conta com nós potenciais e reais, com uma coluna para saída e outra que indica o objeto upstream usado para produzir a saída.
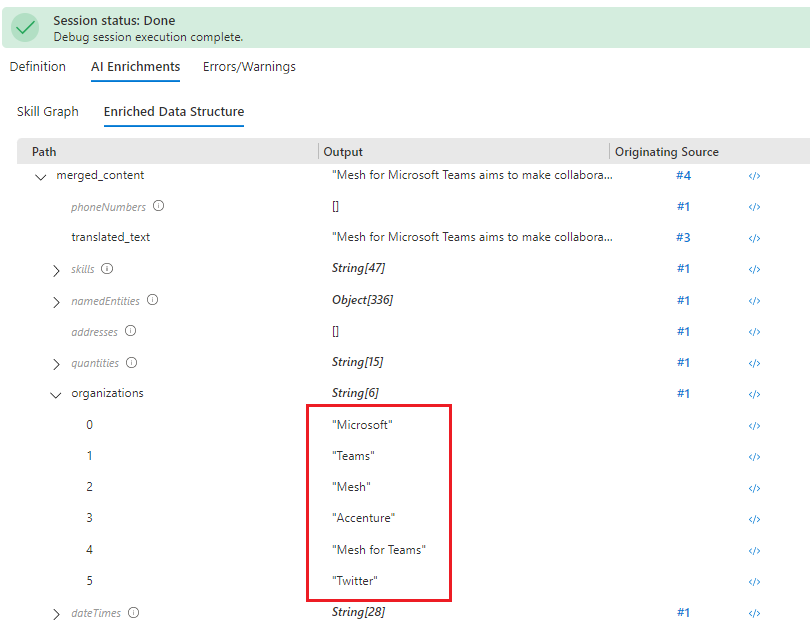
Editar definições de habilidade
Se os mapeamentos de campo estiverem corretos, verifique as habilidades individuais de configuração e conteúdo. Se uma habilidade não produzir a saída, pode ser que esteja faltando uma propriedade ou um parâmetro, o que pode ser determinado por meio de mensagens de erro e validação.
Outros problemas, como um contexto inválido ou uma expressão de entrada, podem ser mais difíceis de resolver, pois o erro informará o que está errado, mas não como corrigir isso. Para obter ajuda com a sintaxe de contexto e de entrada, consulte Enriquecimentos de referência em um conjunto de habilidades da Pesquisa de IA do Azure. Para obter ajuda com mensagens individuais, confira Solucionar problemas de erros e avisos comuns do indexador.
As etapas a seguir mostram como obter informações sobre uma habilidade.
Em Enriquecimento de IA > Gráfico de Habilidades, selecione uma habilidade. O painel de Detalhes de Habilidades é aberto à direita.
Edite uma definição de habilidade usando qualquer abordagem:
- Configurações de Habilidades se preferir um editor visual
- Editor de JSON de Habilidades para editar o documento JSON diretamente
Verifique a sintaxe do caminho para fazer referência a nós em uma árvore de enriquecimento. Confira alguns dos caminhos de entrada mais comuns:
/document/contentpara partes de texto. Esse nó é preenchido a partir da propriedade conteúdo do blob./document/merged_contentpara partes de texto em conjuntos de habilidade que incluem a habilidade de Mesclagem de Texto./document/normalized_images/*para textos reconhecidos ou inferidos a partir de imagens.
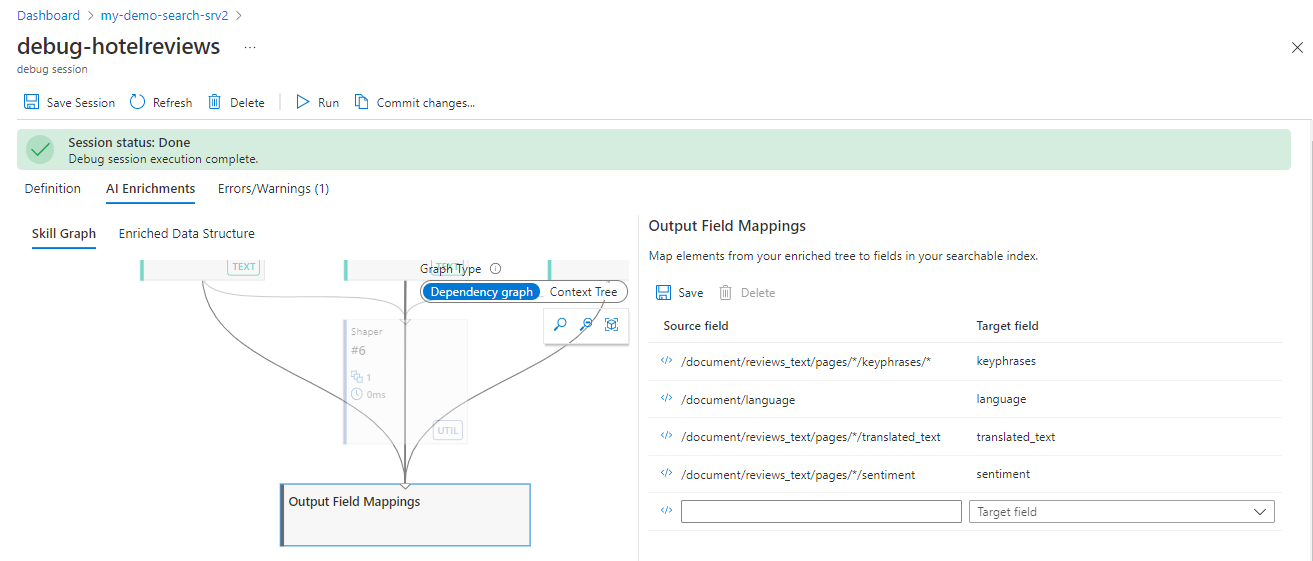
Verificar mapeamentos de campo
Se as habilidades produzirem a saída, mas o índice de pesquisa estiver vazio, verifique os mapeamentos de campo. Os mapeamentos de campo especificam como o conteúdo é movido para fora do pipeline e para um índice de pesquisa.
Comece com as exibições padrão: Enriquecimento de IA > Gráfico de Habilidades, com o tipo de gráfico definido como Gráfico de Dependência.
Selecione Mapeamentos de Campo perto da parte superior. Você deve encontrar pelo menos a chave do documento que identifique exclusivamente e associe cada documento de pesquisa ao índice de pesquisa com o documento de origem na fonte de dados.
Para importações de conteúdo bruto diretamente da fonte de dados que ignoram o enriquecimento, esses campos são exibidos em Mapeamentos de campo.
Selecione Mapeamentos de Campo de Saída na parte inferior do gráfico. Aqui, você encontrará mapeamentos de saídas de habilidades para campos de destino no índice de pesquisa. A menos que você tenha usado o assistente de Importação de Dados, os mapeamentos de campo de saída são definidos manualmente e podem estar incompletos ou digitados incorretamente.
Verifique se os campos em Mapeamentos de Campo de Saída existem no índice de pesquisa conforme especificado, verificando a sintaxe de caminho de nó de enriquecimento e de ortografia.
Depurar uma habilidade personalizada localmente
As habilidades personalizadas podem ser mais difíceis de serem depuradas porque o código é executado externamente, portanto, a sessão de depuração não pode ser usada para depurá-las. Esta seção descreve como depurar localmente a habilidade de API da Web Personalizada, a sessão de depuração, o Visual Studio Code e ngrok ou Tunnelmole. Essa técnica funciona com habilidades personalizadas que são executadas em Azure Functions ou qualquer outro Web Framework executado localmente (por exemplo, FastAPI).
Obter uma URL pública
Usando o Tunnelmole
Tunnelmole é uma ferramenta de túnel de software livre que pode criar uma URL pública que encaminha solicitações para seu computador local por meio de um túnel.
Instalar o Tunnelmole:
- npm:
npm install -g tunnelmole - Linux:
curl -s https://tunnelmole.com/sh/install-linux.sh | sudo bash - Mac:
curl -s https://tunnelmole.com/sh/install-mac.sh --output install-mac.sh && sudo bash install-mac.sh - Windows: Instalar usando o npm. Ou se você não tiver o NodeJS instalado, baixe o arquivo .exe pré-compilado para Windows e coloque-o em algum lugar em seu caminho.
- npm:
Execute este comando para criar um novo túnel:
tmole 7071Você deverá ver um resultado parecido com este:
http://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071 https://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071No exemplo anterior,
https://m5hdpb-ip-49-183-170-144.tunnelmole.netencaminha para a porta7071em seu computador local, que é a porta padrão em que as funções do Azure são expostas.
Usando o ngrok
O ngrok é um aplicativo multiplataforma popular e de código fechado que pode criar uma URL de túnel ou encaminhamento para que as solicitações da Internet cheguem ao computador local. Use o ngrok para encaminhar solicitações de um pipeline de enriquecimento em seu serviço de pesquisa para seu computador para permitir a depuração local.
Instale o ngrok.
Abra um terminal e acesse a pasta com o executável ngrok.
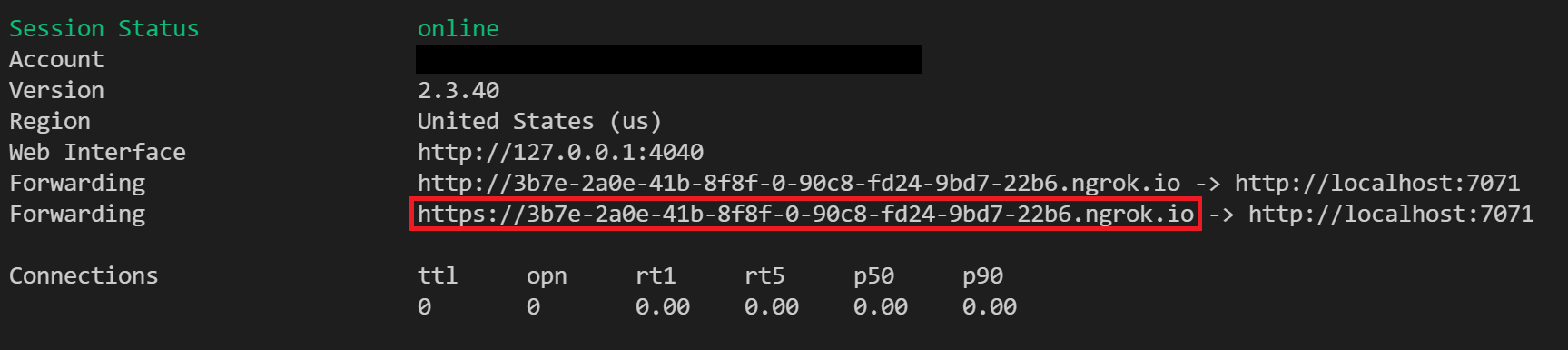
Execute o ngrok com o seguinte comando para criar um novo túnel:
ngrok http 7071Observação
Por padrão, Azure Functions são expostos no 7071. Outras ferramentas e configurações podem exigir que você forneça uma porta diferente.
Quando o ngrok for iniciado, copie e salve a URL de encaminhamento público para a próxima etapa. A URL de encaminhamento é gerada aleatoriamente.
Configurar no portal do Azure
Na sessão de depuração, modifique seu URI de Habilidade de API da Web Personalizada para chamar a URL de encaminhamento do ngrok ou do Tunnelmole. Certifique-se de acrescentar "/api/FunctionName" ao usar o Azure Function para executar o código do conjunto de habilidades.
É possível editar a definição de habilidade no portal.
Testar seu código
Neste ponto, novas solicitações de sua sessão de depuração agora devem ser enviadas para o Azure Function local. É possível usar pontos de interrupção em seu Visual Studio Code para depurar seu código ou executar passo a passo.
Próximas etapas
Agora que você entende como funciona o layout e os recursos do editor visual de Sessões de Depuração, experimente o tutorial para uma experiência prática.