Principais conceitos do Kubernetes para o Serviço Kubernetes do Azure (AKS)
Este artigo descreve os principais conceitos do Serviço Kubernetes do Azure (AKS), um serviço Kubernetes gerenciado que você pode usar para implantar e operar aplicativos em contêineres em escala no Azure. Ele ajuda você a aprender sobre os componentes de infraestrutura do Kubernetes e obter uma compreensão mais profunda de como o Kubernetes funciona no AKS.
O que é o Kubernetes?
O Kubernetes é uma plataforma em rápida evolução que gerencia aplicativos baseados em contêiner e seus componentes de rede e armazenamento associados. O Kubernetes se concentra nas cargas de trabalho do aplicativo e não nos componentes de infraestrutura subjacentes. O Kubernetes fornece uma abordagem declarativa para implantações, apoiada por um conjunto robusto de APIs para operações de gerenciamento.
Você pode criar e executar aplicativos modernos, portáteis e baseados em microsserviços usando o Kubernetes para orquestrar e gerenciar a disponibilidade dos componentes do aplicativo. O Kubernetes suporta aplicativos sem e com monitoração de estado.
Como uma plataforma aberta, o Kubernetes permite que você construa seus aplicativos com sua linguagem de programação preferida, sistema operacional, bibliotecas ou barramento de mensagens. As ferramentas existentes de integração contínua e entrega contínua (CI/CD) podem ser integradas ao Kubernetes para agendar e implantar lançamentos.
O AKS fornece um serviço Kubernetes gerenciado que reduz a complexidade das tarefas de implantação e gerenciamento principal. A plataforma Azure gerencia o plano de controle AKS e você paga apenas pelos nós AKS que executam seus aplicativos.
Arquitetura de clusters do Kubernetes
Um cluster do Kubernetes está dividido em dois componentes:
- O plano de controle, que fornece os principais serviços do Kubernetes e orquestração de cargas de trabalho de aplicativos, e
- nós, que executam as cargas de trabalho do aplicativo.
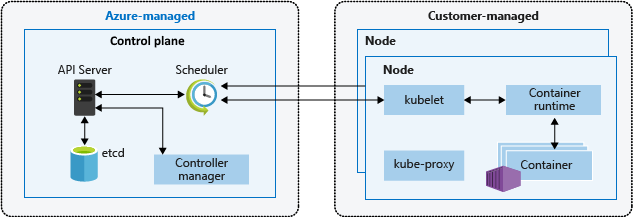
Plano de controlo
Quando você cria um cluster AKS, a plataforma Azure cria e configura automaticamente seu plano de controle associado. Esse plano de controle de locatário único é fornecido sem custo como um recurso gerenciado do Azure abstraído do usuário. Só paga pelos nós anexados ao cluster do AKS. O plano de controle e seus recursos residem somente na região onde você criou o cluster.
O plano de controle inclui os seguintes componentes principais do Kubernetes:
| Componente | Description |
|---|---|
| kube-apiserver | O servidor de API expõe as APIs subjacentes do Kubernetes e fornece a interação para ferramentas de gerenciamento, como kubectl o painel do Kubernetes. |
| etcd | etcd é um armazenamento de chave-valor altamente disponível no Kubernetes que ajuda a manter o estado do cluster e da configuração do Kubernetes. |
| kube-scheduler | Quando você cria ou dimensiona aplicativos, o agendador determina quais nós podem executar a carga de trabalho e inicia os nós identificados. |
| kube-controlador-gerente | O gerente de controlador supervisiona vários controladores menores que executam ações como replicar pods e manipular operações de nó. |
Lembre-se de que você não pode acessar diretamente o plano de controle. As atualizações do plano de controle e do nó do Kubernetes são orquestradas por meio da CLI do Azure ou do portal do Azure. Para solucionar possíveis problemas, você pode revisar os logs do plano de controle usando o Azure Monitor.
Nota
Se quiser configurar ou acessar diretamente um plano de controle, você pode implantar um cluster Kubernetes autogerenciado usando o Provedor de API de Cluster do Azure.
Nós
Para executar seus aplicativos e serviços de suporte, você precisa de um nó Kubernetes. Cada cluster AKS tem pelo menos um nó, uma máquina virtual (VM) do Azure que executa os componentes do nó Kubernetes e o tempo de execução do contêiner.
Os nós incluem os seguintes componentes principais do Kubernetes:
| Componente | Description |
|---|---|
kubelet |
O agente do Kubernetes que processa as solicitações de orquestração do plano de controle junto com o agendamento e a execução dos contêineres solicitados. |
| kube-proxy | O proxy lida com a rede virtual em cada nó, roteando o tráfego de rede e gerenciando o endereçamento IP para serviços e pods. |
| tempo de execução do contêiner | O tempo de execução do contêiner permite que aplicativos em contêineres sejam executados e interajam com outros recursos, como a rede virtual ou o armazenamento. Para obter mais informações, consulte Configuração de tempo de execução de contêiner. |
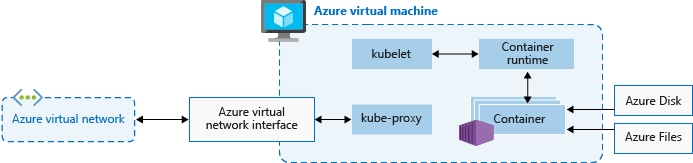
O tamanho da VM do Azure para seus nós define CPUs, memória, tamanho e o tipo de armazenamento disponível, como SSD de alto desempenho ou HDD normal. Planeje o tamanho do nó em torno de se seus aplicativos podem exigir grandes quantidades de CPU e memória ou armazenamento de alto desempenho. Dimensione o número de nós em seu cluster AKS para atender à demanda. Para obter mais informações sobre dimensionamento, consulte Opções de dimensionamento para aplicativos no AKS.
No AKS, a imagem da VM para os nós do cluster é baseada no Ubuntu Linux , Azure Linux ou Windows Server 2022. Quando você cria um cluster AKS ou dimensiona o número de nós, a plataforma Azure cria e configura automaticamente o número solicitado de VMs. Os nós de agente são cobrados como VMs padrão, portanto, quaisquer descontos de tamanho de VM, incluindo reservas do Azure, são aplicados automaticamente.
Para discos gerenciados, o tamanho e o desempenho padrão do disco são atribuídos de acordo com a contagem de SKU e vCPU da VM selecionada. Para obter mais informações, consulte Dimensionamento de disco padrão do sistema operacional.
Nota
Se você precisar de configuração e controle avançados no tempo de execução e no sistema operacional do contêiner do nó Kubernetes, poderá implantar um cluster autogerenciado usando o Provedor de API de Cluster do Azure.
Configuração do SO
O AKS suporta o Ubuntu 22.04 e o Azure Linux 2.0 como o sistema operacional (SO) do nó para clusters com Kubernetes 1.25 e superior. O Ubuntu 18.04 também pode ser especificado na criação do pool de nós para as versões 1.24 e inferiores do Kubernetes.
O AKS suporta o Windows Server 2022 como o sistema operacional padrão para pools de nós do Windows em clusters com Kubernetes 1.25 e superior. O Windows Server 2019 também pode ser especificado na criação do pool de nós para as versões 1.32 e inferiores do Kubernetes. O Windows Server 2019 está sendo desativado depois que o Kubernetes versão 1.32 atinge o fim da vida útil e não é suportado em versões futuras. Para obter mais informações sobre esta aposentadoria, consulte as notas de versão do AKS.
Configuração do tempo de execução do contêiner
Um tempo de execução de contêiner é um software que executa contêineres e gerencia imagens de contêiner em um nó. O tempo de execução ajuda a abstrair sys-calls ou funcionalidades específicas do SO para executar contêineres no Linux ou Windows. Para pools de nós Linux, containerd é usado no Kubernetes versão 1.19 e superior. Para pools de nós do Windows Server 2019 e 2022, containerd está disponível em geral e é a única opção de tempo de execução no Kubernetes versão 1.23 e superior. A partir de maio de 2023, o Docker foi desativado e não terá mais suporte. Para obter mais informações sobre esta aposentadoria, consulte as notas de versão do AKS.
Containerd é um tempo de execução de contêiner principal compatível com OCI (Open Container Initiative) que fornece o conjunto mínimo de funcionalidades necessárias para executar contêineres e gerenciar imagens em um nó. Comcontainerd nós baseados e pools de nós, o kubelet fala diretamente com containerd o uso do plug-in CRI (container runtime interface), removendo saltos extras no fluxo de dados quando comparado à implementação do Docker CRI. Como tal, você vê melhor latência de inicialização do pod e menos uso de recursos (CPU e memória).
Containerd funciona em todas as versões GA do Kubernetes no AKS, em todas as versões do Kubernetes a partir da v1.19, e suporta todos os recursos do Kubernetes e AKS.
Importante
Clusters com pools de nós Linux criados no Kubernetes v1.19 ou superior padrão para o tempo de execução do containerd contêiner. Clusters com pools de nós em versões anteriores suportadas do Kubernetes recebem o Docker para seu tempo de execução de contêiner. Os pools de nós do Linux serão atualizados assim containerd que a versão do Kubernetes do pool de nós for atualizada para uma versão que ofereça suporte containerdao .
containerd está geralmente disponível para clusters com pools de nós do Windows Server 2019 e 2022 e é a única opção de tempo de execução de contêiner para Kubernetes v1.23 e superior. Você pode continuar usando pools de nós e clusters do Docker em versões anteriores à 1.23, mas o Docker não é mais suportado a partir de maio de 2023. Para obter mais informações, consulte Adicionar um pool de nós do Windows Server com containerdo .
É altamente recomendável testar suas cargas de trabalho em pools de nós AKS antes containerd de usar clusters com uma versão do Kubernetes que suporte containerd seus pools de nós.
containerd Limitações/Diferenças
Para
containerdo , recomendamos usarcrictlcomo um substituto para a CLI do Docker para solucionar problemas de pods, contêineres e imagens de contêiner em nós do Kubernetes. Para obter mais informações sobrecrictlo , consulte Uso geral e opções de configuração do cliente.Containerdnão fornece a funcionalidade completa da CLI do Docker. Está disponível apenas para resolução de problemas.crictloferece uma visão mais amigável do Kubernetes dos contêineres, com conceitos como pods, etc. presentes.
ContainerdConfigura o registro em log usando o formato de log padronizadocri. Sua solução de log precisa dar suporte ao formato de log, como ocriAzure Monitor for Containers.Você não pode mais acessar o mecanismo
/var/run/docker.sockdo Docker ou usar o Docker-in-Docker (DinD).- Se você atualmente extrai logs de aplicativos ou dados de monitoramento do mecanismo do Docker, use o Container Insights . O AKS não suporta a execução de comandos fora de banda nos nós do agente que possam causar instabilidade.
- Não recomendamos a criação de imagens ou o uso direto do mecanismo Docker. O Kubernetes não está totalmente ciente desses recursos consumidos, e esses métodos apresentam inúmeros problemas, conforme descrito aqui e aqui.
Ao criar imagens, você pode continuar a usar seu fluxo de trabalho de compilação atual do Docker normalmente, a menos que esteja criando imagens dentro do cluster AKS. Nesse caso, considere mudar para a abordagem recomendada para criar imagens usando tarefas ACR ou uma opção mais segura no cluster, como o Docker Buildx.
Reservas de recursos
O AKS usa recursos de nó para ajudar o nó a funcionar como parte do cluster. Esse uso pode criar uma discrepância entre os recursos totais do seu nó e os recursos alocáveis no AKS. Lembre-se dessas informações ao definir solicitações e limites para pods implantados pelo usuário.
Para localizar o recurso alocável de um nó, você pode usar o kubectl describe node comando:
kubectl describe node [NODE_NAME]
Para manter o desempenho e a funcionalidade do nó, o AKS reserva dois tipos de recursos, CPU e memória, em cada nó. À medida que um nó cresce em recursos, a reserva de recursos cresce devido a uma maior necessidade de gerenciamento de pods implantados pelo usuário. Lembre-se de que as reservas de recursos não podem ser alteradas.
Nota
O uso de complementos AKS, como o Container Insights (OMS), consome recursos extras do nó.
CPU
A CPU reservada depende do tipo de nó e da configuração do cluster, o que pode causar uma CPU menos alocável devido à execução de recursos extras. A tabela a seguir mostra a reserva de CPU em milicores:
| Núcleos de CPU no host | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| Kube-reservado (milicores) | 60 | 100 | 140 | 180 | 260 | 420 | 740 |
Memória
A memória reservada no AKS inclui a soma de dois valores:
Importante
O AKS 1.29 pré-visualiza em janeiro de 2024 e inclui certas alterações nas reservas de memória. Essas alterações são detalhadas na seção a seguir.
AKS 1.29 e posterior
kubeletdaemon tem a regra de remoção memory.available<100Mi por padrão. Esta regra garante que um nó tenha pelo menos 100Mi alocável em todos os momentos. Quando um host está abaixo desse limite de memória disponível, okubeletdispara o encerramento de um dos pods em execução e libera memória na máquina host.Uma taxa de reservas de memória definida de acordo com o menor valor de: 20MB * Max Pods suportados no nó + 50MB ou 25% do total de recursos de memória do sistema.
Exemplos:
- Se a VM fornecer 8GB de memória e o nó suportar até 30 pods, o AKS reservará 20MB * 30 Max Pods + 50MB = 650MB para kube-reserved.
Allocatable space = 8GB - 0.65GB (kube-reserved) - 0.1GB (eviction threshold) = 7.25GB or 90.625% allocatable. - Se a VM fornecer 4GB de memória e o nó suportar até 70 pods, o AKS reservará 25% * 4GB = 1000MB para kube-reserved, pois isso é menos de 20MB * 70 Max Pods + 50MB = 1450MB.
Para obter mais informações, consulte Configurar pods máximos por nó em um cluster AKS.
- Se a VM fornecer 8GB de memória e o nó suportar até 30 pods, o AKS reservará 20MB * 30 Max Pods + 50MB = 650MB para kube-reserved.
Versões do AKS anteriores à 1.29
kubeletdaemon tem a regra de remoção memory.available<750Mi por padrão. Esta regra garante que um nó tenha pelo menos 750Mi alocáveis em todos os momentos. Quando um host está abaixo desse limite de memória disponível, okubeletaciona o encerramento de um dos pods em execução e libera memória na máquina host.- Uma taxa regressiva de reservas de memória para o daemon kubelet funcionar corretamente (kube-reserved).
- 25% dos primeiros 4GB de memória
- 20% dos próximos 4GB de memória (até 8GB)
- 10% dos próximos 8GB de memória (até 16GB)
- 6% dos próximos 112GB de memória (até 128GB)
- 2% de qualquer memória superior a 128GB
Nota
O AKS reserva 2GB extras para processos do sistema em nós do Windows que não fazem parte da memória calculada.
As regras de alocação de memória e CPU são projetadas para:
- Mantenha os nós do agente íntegros, incluindo alguns pods do sistema de hospedagem críticos para a integridade do cluster.
- Faça com que o nó relate menos memória e CPU alocáveis do que relataria se não fizesse parte de um cluster Kubernetes.
Por exemplo, se um nó oferecer 7 GB, ele relatará 34% da memória não alocável, incluindo o limite de remoção de 750 Mi.
0.75 + (0.25*4) + (0.20*3) = 0.75GB + 1GB + 0.6GB = 2.35GB / 7GB = 33.57% reserved
Além das reservas para o próprio Kubernetes, o sistema operacional do nó subjacente também reserva uma quantidade de recursos de CPU e memória para manter as funções do sistema operacional.
Para obter as práticas recomendadas associadas, consulte Práticas recomendadas para recursos básicos do agendador no AKS.
Conjuntos de nós
Nota
O pool de nós do Linux do Azure agora está disponível em geral (GA). Para saber mais sobre os benefícios e as etapas de implantação, consulte a Introdução ao Host de Contêiner Linux do Azure para AKS.
Os nós da mesma configuração são agrupados em pools de nós. Cada cluster do Kubernetes contém pelo menos um pool de nós. Você define o número inicial de nós e tamanhos ao criar um cluster AKS, que cria um pool de nós padrão. Esse pool de nós padrão no AKS contém as VMs subjacentes que executam os nós do agente.
Nota
Para garantir que seu cluster opere de forma confiável, você deve executar pelo menos dois nós no pool de nós padrão.
Você dimensiona ou atualiza um cluster AKS em relação ao pool de nós padrão. Você pode optar por dimensionar ou atualizar um pool de nós específico. Para operações de atualização, os contêineres em execução são agendados em outros nós no pool de nós até que todos os nós sejam atualizados com êxito.
Para obter mais informações, consulte Criar pools de nós e Gerenciar pools de nós.
Dimensionamento de disco padrão do sistema operacional
Quando você cria um novo cluster ou adiciona um novo pool de nós a um cluster existente, o número de vCPUs por padrão determina o tamanho do disco do sistema operacional. O número de vCPUs é baseado na SKU da VM. A tabela a seguir lista o tamanho padrão do disco do sistema operacional para cada SKU de VM:
| Núcleos de SKU de VM (vCPUs) | Camada de disco padrão do sistema operacional | IOPS Aprovisionadas | Taxa de transferência provisionada (Mbps) |
|---|---|---|---|
| 1 - 7 | P10/128G | 500 | 100 |
| 8 - 15 | P15/256G | 1100 | 125 |
| 16 - 63 | P20/512G | 2300 | 150 |
| 64+ | P30/1024G | 5000 | 200 |
Importante
O dimensionamento de disco padrão do sistema operacional só é usado em novos clusters ou pools de nós quando os discos do sistema operacional efêmero não são suportados e um tamanho de disco do sistema operacional padrão não é especificado. O tamanho padrão do disco do sistema operacional pode afetar o desempenho ou o custo do cluster. Não é possível alterar o tamanho do disco do sistema operacional após a criação do cluster ou do pool de nós. Esse dimensionamento de disco padrão afeta clusters ou pools de nós criados em julho de 2022 ou posterior.
Seletores de nós
Em um cluster AKS com vários pools de nós, talvez seja necessário informar ao Agendador do Kubernetes qual pool de nós usar para um determinado recurso. Por exemplo, os controladores de entrada não devem ser executados em nós do Windows Server. Você usa seletores de nó para definir vários parâmetros, como o sistema operacional do nó, para controlar onde um pod deve ser agendado.
O exemplo básico a seguir agenda uma instância NGINX em um nó Linux usando o seletor de nó "kubernetes.io/os": linux:
kind: Pod
apiVersion: v1
metadata:
name: nginx
spec:
containers:
- name: myfrontend
image: mcr.microsoft.com/oss/nginx/nginx:1.15.12-alpine
nodeSelector:
"kubernetes.io/os": linux
Para obter mais informações, consulte Práticas recomendadas para recursos avançados do agendador no AKS.
Grupo de recursos de nó
Ao criar um cluster AKS, você especifica um grupo de recursos do Azure para criar os recursos do cluster. Além desse grupo de recursos, o provedor de recursos AKS cria e gerencia um grupo de recursos separado chamado grupo de recursos do nó. O grupo de recursos do nó contém os seguintes recursos de infraestrutura:
- Os conjuntos de dimensionamento de máquina virtual e VMs para cada nó nos pools de nós
- A rede virtual para o cluster
- O armazenamento para o cluster
O grupo de recursos do nó recebe um nome por padrão com o seguinte formato: MC_resourceGroupName_clusterName_location. Durante a criação do cluster, você pode especificar o nome atribuído ao seu grupo de recursos de nó. Ao usar um modelo do Azure Resource Manager, você pode definir o nome usando a nodeResourceGroup propriedade. Ao usar a CLI do Azure, você usa o --node-resource-group parâmetro com o az aks create comando, conforme mostrado no exemplo a seguir:
az aks create --name myAKSCluster --resource-group myResourceGroup --node-resource-group myNodeResourceGroup
Quando você exclui seu cluster AKS, o provedor de recursos AKS exclui automaticamente o grupo de recursos do nó.
O grupo de recursos do nó tem as seguintes limitações:
- Não é possível especificar um grupo de recursos existente para o grupo de recursos do nó.
- Não é possível especificar uma assinatura diferente para o grupo de recursos do nó.
- Não é possível alterar o nome do grupo de recursos do nó após a criação do cluster.
- Não é possível especificar nomes para os recursos gerenciados dentro do grupo de recursos do nó.
- Não é possível modificar ou excluir marcas criadas pelo Azure de recursos gerenciados dentro do grupo de recursos do nó.
Modificar quaisquer marcas criadas pelo Azure em recursos sob o grupo de recursos de nó no cluster AKS é uma ação sem suporte, que quebra o SLO (objetivo de nível de serviço). Se você modificar ou excluir marcas criadas pelo Azure ou outras propriedades de recursos no grupo de recursos do nó, poderá obter resultados inesperados, como erros de dimensionamento e atualização. O AKS gerencia o ciclo de vida da infraestrutura no grupo de recursos do nó, portanto, fazer qualquer alteração move seu cluster para um estado sem suporte. Para obter mais informações, consulte O AKS oferece um contrato de nível de serviço?
O AKS permite que você crie e modifique tags que são propagadas para recursos no grupo de recursos do nó, e você pode adicionar essas tags ao criar ou atualizar o cluster. Talvez você queira criar ou modificar tags personalizadas para atribuir uma unidade de negócios ou centro de custo, por exemplo. Você também pode criar Políticas do Azure com um escopo no grupo de recursos gerenciados.
Para reduzir a chance de alterações no grupo de recursos do nó afetarem seus clusters, você pode habilitar o bloqueio do grupo de recursos do nó para aplicar uma atribuição de negação aos recursos do AKS. para obter mais informações, consulte Grupo de recursos totalmente gerenciado (visualização).
Aviso
Se você não tiver o bloqueio do grupo de recursos do nó habilitado, poderá modificar diretamente qualquer recurso no grupo de recursos do nó. Modificar diretamente os recursos no grupo de recursos do nó pode fazer com que o cluster fique instável ou sem resposta.
Pods
O Kubernetes usa pods para executar instâncias do seu aplicativo. Um único pod representa uma única instância do seu aplicativo.
Os pods normalmente têm um mapeamento 1:1 com um contêiner. Em cenários avançados, um pod pode conter vários contêineres. Os pods de vários contêineres são agendados juntos no mesmo nó e permitem que os contêineres compartilhem recursos relacionados.
Ao criar um pod, você pode definir solicitações de recursos para uma determinada quantidade de CPU ou memória. O Agendador do Kubernetes tenta atender à solicitação agendando os pods para serem executados em um nó com recursos disponíveis. Você também pode especificar limites máximos de recursos para evitar que um pod consuma muito recurso de computação do nó subjacente. Nossa prática recomendada é incluir limites de recursos para todos os pods para ajudar o Agendador do Kubernetes a identificar os recursos necessários permitidos.
Para obter mais informações, consulte Kubernetes pods e Kubernetes pod lifecycle.
Um pod é um recurso lógico, mas as cargas de trabalho do aplicativo são executadas nos contêineres. As vagens são tipicamente recursos efêmeros e descartáveis. Os pods agendados individualmente perdem alguns dos recursos de alta disponibilidade e redundância do Kubernetes. Em vez disso, os Controladores Kubernetes, como o Controlador de Implantação, implantam e gerenciam pods.
Implantações e manifestos YAML
Uma implantação representa pods idênticos gerenciados pelo Kubernetes Deployment Controller. Uma implantação define o número de réplicas de pod a serem criadas. O Agendador do Kubernetes garante que pods extras sejam agendados em nós íntegros se pods ou nós encontrarem problemas. Você pode atualizar implantações para alterar a configuração de pods, a imagem de contêiner ou o armazenamento anexado.
O Controlador de Implantação gerencia o ciclo de vida da implantação e executa as seguintes ações:
- Drena e encerra um determinado número de réplicas.
- Cria réplicas a partir da nova definição de implantação.
- Continua o processo até que todas as réplicas na implantação sejam atualizadas.
A maioria dos aplicativos sem estado no AKS deve usar o modelo de implantação em vez de agendar pods individuais. O Kubernetes pode monitorar a integridade e o status da implantação para garantir que o número necessário de réplicas seja executado dentro do cluster. Quando agendados individualmente, os pods não são reiniciados se encontrarem um problema e não são reagendados em nós íntegros se o nó atual encontrar um problema.
Você não deseja interromper as decisões de gerenciamento com um processo de atualização se seu aplicativo exigir um número mínimo de instâncias disponíveis. Os orçamentos de interrupção de pod definem quantas réplicas em uma implantação podem ser removidas durante uma atualização ou atualização de nó. Por exemplo, se você tiver cinco réplicas em sua implantação, poderá definir uma interrupção de pod de quatro para permitir que apenas uma réplica seja excluída ou reagendada de cada vez. Assim como acontece com os limites de recursos de pod, nossa prática recomendada é definir orçamentos de interrupção de pod em aplicativos que exigem um número mínimo de réplicas para estar sempre presente.
Normalmente, as implantações são criadas e gerenciadas com kubectl create ou kubectl apply. Você pode criar uma implantação definindo um arquivo de manifesto no formato YAML. O exemplo a seguir mostra um arquivo de manifesto de implantação básico para um servidor Web NGINX:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: mcr.microsoft.com/oss/nginx/nginx:1.15.2-alpine
ports:
- containerPort: 80
resources:
requests:
cpu: 250m
memory: 64Mi
limits:
cpu: 500m
memory: 256Mi
Um detalhamento das especificações de implantação no arquivo de manifesto YAML é o seguinte:
| Especificação | Description |
|---|---|
.apiVersion |
Especifica o grupo de API e o recurso de API que você deseja usar ao criar o recurso. |
.kind |
Especifica o tipo de recurso que você deseja criar. |
.metadata.name |
Especifica o nome da implantação. Este arquivo YAML de exemplo executa a imagem nginx do Docker Hub. |
.spec.replicas |
Especifica quantos pods criar. Este arquivo YAML de exemplo cria três pods duplicados. |
.spec.selector |
Especifica quais pods serão afetados por essa implantação. |
.spec.selector.matchLabels |
Contém um mapa de pares {key, value} que permitem que a implantação localize e gerencie os pods criados. |
.spec.selector.matchLabels.app |
Tem que corresponder .spec.template.metadata.labels. |
.spec.template.labels |
Especifica os pares {key, value} anexados ao objeto. |
.spec.template.app |
Tem que corresponder .spec.selector.matchLabels. |
.spec.spec.containers |
Especifica a lista de contêineres pertencentes ao pod. |
.spec.spec.containers.name |
Especifica o nome do contêiner especificado como um rótulo DNS. |
.spec.spec.containers.image |
Especifica o nome da imagem do contêiner. |
.spec.spec.containers.ports |
Especifica a lista de portas a serem expostas a partir do contêiner. |
.spec.spec.containers.ports.containerPort |
Especifica o número de portas a serem expostas no endereço IP do pod. |
.spec.spec.resources |
Especifica os recursos de computação exigidos pelo contêiner. |
.spec.spec.resources.requests |
Especifica a quantidade mínima de recursos de computação necessários. |
.spec.spec.resources.requests.cpu |
Especifica a quantidade mínima de CPU necessária. |
.spec.spec.resources.requests.memory |
Especifica a quantidade mínima de memória necessária. |
.spec.spec.resources.limits |
Especifica a quantidade máxima de recursos de computação permitidos. O kubelet impõe esse limite. |
.spec.spec.resources.limits.cpu |
Especifica a quantidade máxima de CPU permitida. O kubelet impõe esse limite. |
.spec.spec.resources.limits.memory |
Especifica a quantidade máxima de memória permitida. O kubelet impõe esse limite. |
Aplicativos mais complexos podem ser criados incluindo serviços, como balanceadores de carga, no manifesto YAML.
Para obter mais informações, consulte Implantações do Kubernetes.
Gerenciamento de pacotes com o Helm
O Helm é comumente usado para gerenciar aplicativos no Kubernetes. Você pode implantar recursos criando e usando gráficos Helm públicos existentes que contêm uma versão empacotada do código do aplicativo e manifestos YAML do Kubernetes. Você pode armazenar gráficos Helm localmente ou em um repositório remoto, como um repositório de gráfico Helm do Registro de Contêiner do Azure.
Para usar o Helm, instale o cliente Helm em seu computador ou use o cliente Helm no Azure Cloud Shell. Procure ou crie gráficos Helm e instale-os no cluster do Kubernetes. Para obter mais informações, consulte Instalar aplicativos existentes com o Helm no AKS.
StatefulSets e DaemonSets
O Controlador de Implantação usa o Agendador do Kubernetes e executa réplicas em qualquer nó disponível com recursos disponíveis. Embora essa abordagem possa ser suficiente para aplicativos sem monitoração de estado, o Controlador de Implantação não é ideal para aplicativos que exigem as seguintes especificações:
- Uma convenção de nomenclatura ou armazenamento persistente.
- Uma réplica a existir em cada nó de seleção dentro de um cluster.
Dois recursos do Kubernetes, no entanto, permitem gerenciar esses tipos de aplicativos: StatefulSets e DaemonSets.
StatefulSets mantém o estado dos aplicativos além de um ciclo de vida individual do pod. Os DaemonSets garantem uma instância em execução em cada nó no início do processo de bootstrap do Kubernetes.
StatefulSets
O desenvolvimento de aplicativos modernos geralmente visa aplicativos sem monitoração de estado. Para aplicativos com monitoração de estado, como aqueles que incluem componentes de banco de dados, você pode usar StatefulSets. Como as implantações, um StatefulSet cria e gerencia pelo menos um pod idêntico. As réplicas em um StatefulSet seguem uma abordagem normal e sequencial para operações de implantação, dimensionamento, atualização e encerramento. A convenção de nomenclatura, os nomes de rede e o armazenamento persistem à medida que as réplicas são reagendadas com um StatefulSet.
Você pode definir o aplicativo no formato YAML usando kind: StatefulSet. A partir daí, o StatefulSet Controller lida com a implantação e o gerenciamento das réplicas necessárias. Os dados gravam no armazenamento persistente, fornecido pelos Discos Gerenciados do Azure ou pelos Arquivos do Azure. Com StatefulSets, o armazenamento persistente subjacente permanece, mesmo quando o StatefulSet é excluído.
Para obter mais informações, consulte Kubernetes StatefulSets.
Importante
As réplicas em um StatefulSet são agendadas e executadas em qualquer nó disponível em um cluster AKS. Para garantir que pelo menos um pod em seu conjunto seja executado em um nó, você deve usar um DaemonSet em vez disso.
DaemonSets
Para coleta ou monitoramento de logs específicos, talvez seja necessário executar um pod em todos os nós ou um conjunto selecionado de nós. Você pode usar DaemonSets para implantar em um ou mais pods idênticos. O DaemonSet Controller garante que cada nó especificado execute uma instância do pod.
O DaemonSet Controller pode agendar pods em nós no início do processo de inicialização do cluster antes que o agendador Kubernetes padrão seja iniciado. Essa capacidade garante que os pods em um estado DaemonSet antes dos pods tradicionais em um Deployment ou StatefulSet sejam agendados.
Como StatefulSets, você pode definir um DaemonSet como parte de uma definição YAML usando kind: DaemonSet.
Para obter mais informações, consulte Kubernetes DaemonSets.
Nota
Se você estiver usando o complemento Nós virtuais, os DaemonSets não criarão pods no nó virtual.
Espaços de nomes
Os recursos do Kubernetes, como pods e implantações, são agrupados logicamente em namespaces para dividir um cluster AKS e criar, exibir ou gerenciar o acesso aos recursos. Por exemplo, pode criar espaços de nomes para separar grupos de negócios. Os utilizadores só podem interagir com recursos dentro dos espaços de nomes atribuídos.
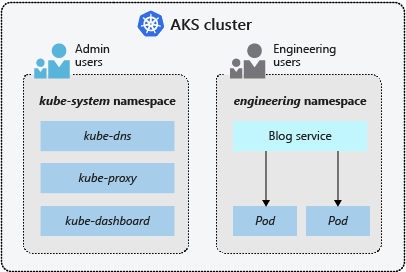
Os namespaces a seguir estão disponíveis quando você cria um cluster AKS:
| Espaço de Nomes | Description |
|---|---|
| default | Onde pods e implantações são criados por padrão quando nenhum é fornecido. Em ambientes menores, você pode implantar aplicativos diretamente no namespace padrão sem criar separações lógicas adicionais. Quando você interage com a API do Kubernetes, como com kubectl get pods, o namespace padrão é usado quando nenhum é especificado. |
| sistema kube | Onde existem recursos principais, como recursos de rede, como DNS e proxy, ou o painel do Kubernetes. Normalmente, não implementa as suas próprias aplicações neste espaço de nomes. |
| kube-público | Normalmente não usado, você pode usá-lo para que os recursos fiquem visíveis em todo o cluster e possam ser exibidos por qualquer usuário. |
Para obter mais informações, consulte Namespaces do Kubernetes.
Próximos passos
Para obter mais informações sobre os principais conceitos de Kubernetes e AKS, consulte os seguintes artigos: