Esta arquitetura de referência mostra como treinar um modelo de recomendação usando o Azure Databricks e, em seguida, implantar o modelo como uma API usando o Azure Cosmos DB, o Azure Machine Learning e o Azure Kubernetes Service (AKS). Para obter uma implementação de referência dessa arquitetura, consulte Criando uma API de recomendação em tempo real no GitHub.
Arquitetura

Transfira um ficheiro do Visio desta arquitetura.
Esta arquitetura de referência destina-se a treinar e implementar uma API de serviço de recomendação em tempo real que pode fornecer as 10 principais recomendações de filmes para um utilizador.
Fluxo de dados
- Rastreie o comportamento do usuário. Por exemplo, um serviço de back-end pode registrar quando um usuário classifica um filme ou clica em um produto ou artigo de notícias.
- Carregue os dados no Azure Databricks a partir de uma fonte de dados disponível.
- Prepare os dados e divida em conjuntos de treinamento e teste para treinar o modelo. (Este guia descreve as opções para dividir dados.)
- Ajuste o modelo de Filtragem Colaborativa do Spark aos dados.
- Avalie a qualidade do modelo usando métricas de classificação e classificação. (Este guia fornece detalhes sobre as métricas que você pode usar para avaliar seu recomendador.)
- Pré-calcule as 10 principais recomendações por usuário e armazene como um cache no Azure Cosmos DB.
- Implante um serviço de API no AKS usando as APIs de Aprendizado de Máquina para criar contêineres e implantar a API.
- Quando o serviço de back-end receber uma solicitação de um usuário, chame a API de recomendações hospedada no AKS para obter as 10 principais recomendações e exibi-las ao usuário.
Componentes
- Azure Databricks. Databricks é um ambiente de desenvolvimento usado para preparar dados de entrada e treinar o modelo de recomendação em um cluster Spark. O Azure Databricks também fornece um espaço de trabalho interativo para executar e colaborar em blocos de anotações para qualquer processamento de dados ou tarefas de aprendizado de máquina.
- Serviço Kubernetes do Azure (AKS). O AKS é usado para implantar e operacionalizar uma API de serviço de modelo de aprendizado de máquina em um cluster Kubernetes. O AKS hospeda o modelo conteinerizado, fornecendo escalabilidade que atende aos seus requisitos de taxa de transferência, gerenciamento de identidade e acesso e registro em log e monitoramento de integridade.
- Azure Cosmos DB. O Azure Cosmos DB é um serviço de banco de dados distribuído globalmente usado para armazenar os 10 principais filmes recomendados para cada usuário. O Azure Cosmos DB é adequado para esse cenário, pois fornece baixa latência (10 ms no percentil 99) para ler os principais itens recomendados para um determinado usuário.
- Machine Learning. Esse serviço é usado para rastrear e gerenciar modelos de aprendizado de máquina e, em seguida, empacotar e implantar esses modelos em um ambiente AKS escalável.
- Recomendações da Microsoft. Este repositório de código aberto contém código utilitário e exemplos para ajudar os usuários a começar a criar, avaliar e operacionalizar um sistema de recomendação.
Detalhes do cenário
Essa arquitetura pode ser generalizada para a maioria dos cenários de mecanismo de recomendação, incluindo recomendações para produtos, filmes e notícias.
Potenciais casos de utilização
Cenário: uma organização de mídia deseja fornecer recomendações de filmes ou vídeos para seus usuários. Ao fornecer recomendações personalizadas, a organização atende a várias metas de negócios, incluindo aumento das taxas de cliques, maior engajamento em seu site e maior satisfação do usuário.
Esta solução é otimizada para o setor de varejo e para as indústrias de mídia e entretenimento.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios orientadores que podem ser usados para melhorar a qualidade de uma carga de trabalho. Para obter mais informações, consulte Microsoft Azure Well-Architected Framework.
A pontuação em lote de modelos do Spark no Azure Databricks descreve uma arquitetura de referência que usa o Spark e o Azure Databricks para executar processos de pontuação em lote agendados. Recomendamos esta abordagem para gerar novas recomendações.
Eficiência de desempenho
Eficiência de desempenho é a capacidade da sua carga de trabalho para dimensionar para satisfazer as exigências que os utilizadores lhe colocam de forma eficiente. Para obter mais informações, consulte Visão geral do pilar de eficiência de desempenho.
O desempenho é uma consideração primária para recomendações em tempo real, porque as recomendações geralmente caem no caminho crítico de uma solicitação do usuário em seu site.
A combinação do AKS e do Azure Cosmos DB permite que essa arquitetura forneça um bom ponto de partida para fornecer recomendações para uma carga de trabalho de tamanho médio com sobrecarga mínima. Sob um teste de carga com 200 usuários simultâneos, essa arquitetura fornece recomendações a uma latência mediana de cerca de 60 ms e executa a uma taxa de transferência de 180 solicitações por segundo. O teste de carga foi executado em relação à configuração de implantação padrão (um cluster AKS 3x D3 v2 com 12 vCPUs, 42 GB de memória e 11.000 Unidades de Solicitação (RUs) por segundo provisionadas para o Azure Cosmos DB).
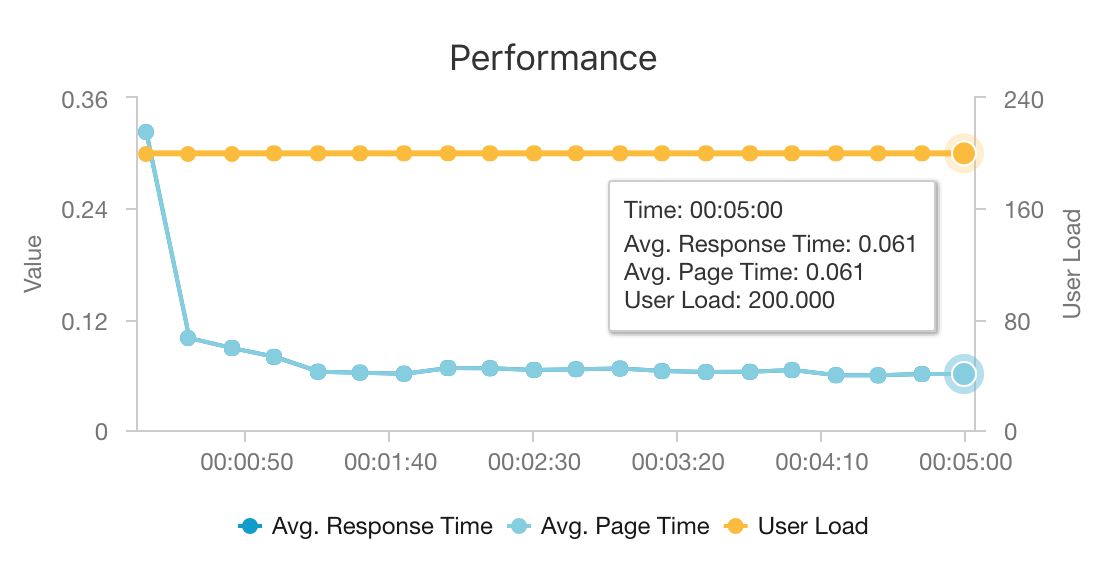
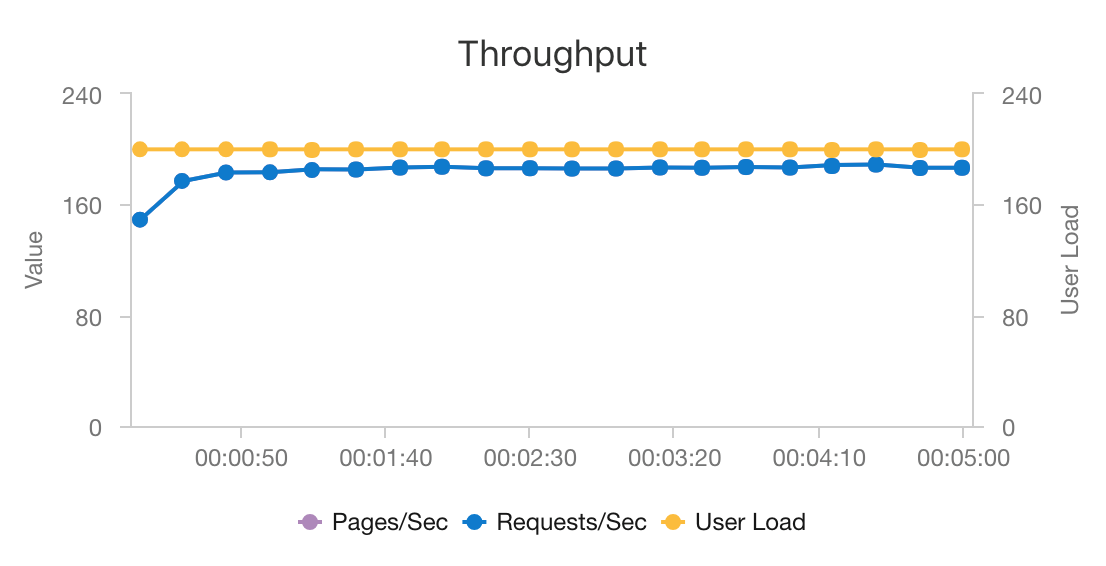
O Azure Cosmos DB é recomendado por sua distribuição global turnkey e utilidade em atender a quaisquer requisitos de banco de dados que seu aplicativo tenha. Para reduzir ligeiramente a latência, considere usar o Cache Redis do Azure em vez do Azure Cosmos DB para servir pesquisas. O Cache Redis do Azure pode melhorar o desempenho de sistemas que dependem fortemente de dados em repositórios back-end.
Escalabilidade
Se você não planeja usar o Spark ou tem uma carga de trabalho menor que não precisa de distribuição, considere usar uma DSVM (Máquina Virtual de Ciência de Dados) em vez do Azure Databricks. Uma DSVM é uma máquina virtual do Azure com estruturas e ferramentas de aprendizagem profunda para aprendizagem automática e ciência de dados. Tal como acontece com o Azure Databricks, qualquer modelo criado numa DSVM pode ser operacionalizado como um serviço no AKS através da Aprendizagem Automática.
Durante o treinamento, provisione um cluster Spark de tamanho fixo maior no Azure Databricks ou configure o dimensionamento automático. Quando o dimensionamento automático está habilitado, o Databricks monitora a carga no cluster e aumenta e diminui a escala conforme necessário. Provisione ou dimensione um cluster maior se você tiver um tamanho de dados grande e quiser reduzir o tempo necessário para tarefas de preparação ou modelagem de dados.
Dimensione o cluster AKS para atender aos seus requisitos de desempenho e taxa de transferência. Tome cuidado para aumentar o número de pods para utilizar totalmente o cluster e dimensionar os nós do cluster para atender à demanda do seu serviço. Você também pode definir o dimensionamento automático em um cluster AKS. Para obter mais informações, consulte Implantar um modelo em um cluster do Serviço Kubernetes do Azure.
Para gerenciar o desempenho do Azure Cosmos DB, estime o número de leituras necessárias por segundo e provisione o número de RUs por segundo (taxa de transferência) necessárias. Use as práticas recomendadas para particionamento e dimensionamento horizontal.
Otimização de custos
A otimização de custos consiste em procurar formas de reduzir despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Visão geral do pilar de otimização de custos.
Os principais impulsionadores de custo neste cenário são:
- O tamanho do cluster do Azure Databricks necessário para treinamento.
- O tamanho do cluster AKS necessário para atender aos seus requisitos de desempenho.
- RUs do Azure Cosmos DB provisionadas para atender aos seus requisitos de desempenho.
Gerencie os custos do Azure Databricks treinando com menos frequência e desativando o cluster do Spark quando não estiver em uso. Os custos do AKS e do Azure Cosmos DB estão vinculados à taxa de transferência e ao desempenho exigidos pelo seu site e serão dimensionados para cima e para baixo, dependendo do volume de tráfego para o seu site.
Implementar este cenário
Para implantar essa arquitetura, siga as instruções do Azure Databricks no documento de instalação. Resumidamente, as instruções exigem que você:
- Crie um espaço de trabalho do Azure Databricks.
- Crie um novo cluster com a seguinte configuração no Azure Databricks:
- Modo de cluster: Padrão
- Versão de tempo de execução do Databricks: 4.3 (inclui Apache Spark 2.3.1, Scala 2.11)
- Versão do Python: 3
- Tipo de driver: Standard_DS3_v2
- Tipo de trabalhador: Standard_DS3_v2 (min e max conforme necessário)
- Rescisão automática: (conforme necessário)
- Configuração da faísca: (conforme necessário)
- Variáveis de ambiente: (conforme necessário)
- Crie um token de acesso pessoal no espaço de trabalho do Azure Databricks. Consulte a documentação de autenticação do Azure Databricks para obter detalhes.
- Clone o repositório Microsoft Recommenders em um ambiente onde você pode executar scripts (por exemplo, seu computador local).
- Siga as instruções de configuração de instalação rápida para instalar as bibliotecas relevantes no Azure Databricks.
- Siga as instruções de configuração de instalação rápida para preparar o Azure Databricks para operacionalização.
- Importe o bloco de anotações ALS Movie Operationalization para o seu espaço de trabalho. Depois de entrar no seu espaço de trabalho do Azure Databricks, faça o seguinte:
- Clique em Página Inicial no lado esquerdo do espaço de trabalho.
- Clique com o botão direito do rato no espaço em branco no seu diretório inicial. Selecione Importar.
- Selecione URL e cole o seguinte no campo de texto:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Clique em Importar.
- Abra o bloco de anotações no Azure Databricks e anexe o cluster configurado.
- Execute o bloco de anotações para criar os recursos do Azure necessários para criar uma API de recomendação que forneça as 10 principais recomendações de filmes para um determinado usuário.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Principais autores:
- Miguel Fierro - Portugal | Gerente Principal de Cientista de Dados
- Nikhil Joglekar - Brasil | Gestor de Produto, algoritmos do Azure e ciência de dados
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
- Criando uma API de recomendação em tempo real
- O que é o Azure Databricks?
- Azure Kubernetes Service
- Bem-vindo ao Azure Cosmos DB
- O que é o Azure Machine Learning?