Guia de início rápido: classificação de texto personalizada
Use este artigo para começar a criar um projeto de classificação de texto personalizado onde você pode treinar modelos personalizados para classificação de texto. Um modelo é um software de inteligência artificial que é treinado para fazer uma determinada tarefa. Para este sistema, os modelos classificam o texto e são treinados aprendendo com dados marcados.
A classificação de texto personalizada suporta dois tipos de projetos:
- Classificação de rótulo único - você pode atribuir uma única classe para cada documento em seu conjunto de dados. Por exemplo, um roteiro de filme só pode ser classificado como "Romance" ou "Comédia".
- Classificação de vários rótulos - você pode atribuir várias classes para cada documento em seu conjunto de dados. Por exemplo, um roteiro de filme pode ser classificado como "Comédia" ou "Romance" e "Comédia".
Neste guia de início rápido, você pode usar os conjuntos de dados de exemplo fornecidos para criar uma classificação de rótulo múltiplo onde você pode classificar scripts de filmes em uma ou mais categorias ou você pode usar um conjunto de dados de classificação de rótulo único onde você pode classificar resumos de artigos científicos em um dos domínios definidos.
Pré-requisitos
- Subscrição do Azure - Crie uma gratuitamente.
Criar um novo recurso de linguagem de IA do Azure e uma conta de armazenamento do Azure
Antes de poder usar a classificação de texto personalizada, você precisará criar um recurso de linguagem de IA do Azure, que lhe dará as credenciais necessárias para criar um projeto e começar a treinar um modelo. Você também precisará de uma conta de armazenamento do Azure, onde poderá carregar seu conjunto de dados que será usado para criar seu modelo.
Importante
Para começar rapidamente, recomendamos a criação de um novo recurso de linguagem de IA do Azure usando as etapas fornecidas neste artigo. Usar as etapas neste artigo permitirá que você crie o recurso de idioma e a conta de armazenamento ao mesmo tempo, o que é mais fácil do que fazê-lo mais tarde.
Se você tiver um recurso pré-existente que gostaria de usar, precisará conectá-lo à conta de armazenamento.
Criar um novo recurso a partir do portal do Azure
Vá para o portal do Azure para criar um novo recurso de linguagem de IA do Azure.
Na janela exibida, selecione Classificação de texto personalizada & reconhecimento de entidade nomeada personalizada nos recursos personalizados. Selecione Continuar para criar seu recurso na parte inferior da tela.
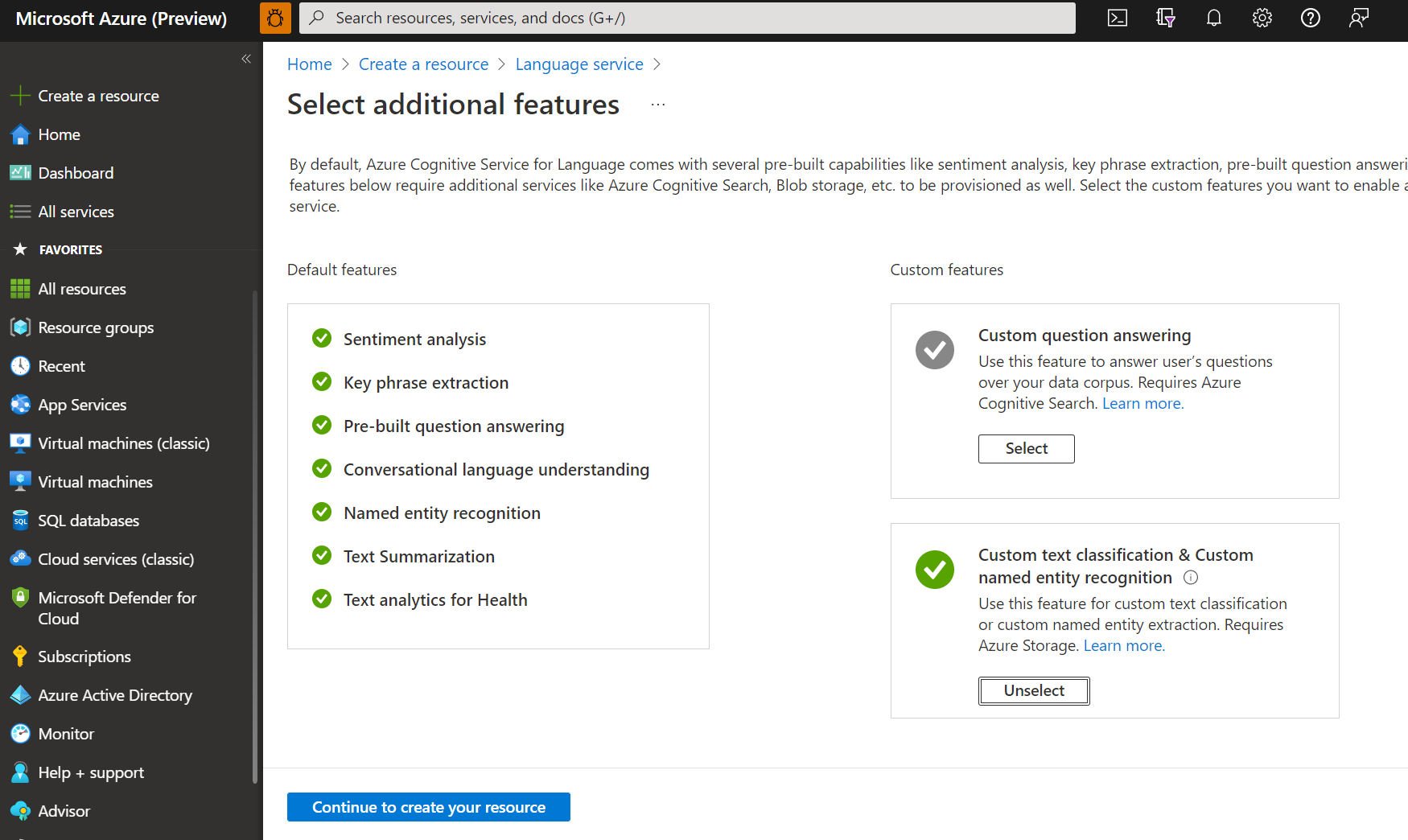
Crie um recurso de idioma com os seguintes detalhes.
Nome Valor obrigatório Subscrição A sua subscrição do Azure. Grupo de recursos Um grupo de recursos que conterá seu recurso. Você pode usar um existente ou criar um novo. País/Região Uma das regiões apoiadas. Por exemplo, "West US 2". Nome Um nome para o seu recurso. Escalão de preço Um dos níveis de preços suportados. Você pode usar a camada Gratuito (F0) para experimentar o serviço. Se você receber uma mensagem dizendo "sua conta de login não é proprietária do grupo de recursos da conta de armazenamento selecionada", sua conta precisará ter uma função de proprietário atribuída no grupo de recursos antes de poder criar um recurso de idioma. Entre em contato com o proprietário da assinatura do Azure para obter assistência.
Você pode determinar o proprietário da assinatura do Azure pesquisando seu grupo de recursos e seguindo o link para sua assinatura associada. Em seguida:
- Selecione a guia Controle de acesso (IAM)
- Selecionar atribuições de função
- Filtrar por Função:Proprietário.
Na seção Classificação de texto personalizada & reconhecimento de entidade nomeada personalizada, selecione uma conta de armazenamento existente ou selecione Nova conta de armazenamento. Observe que esses valores são para ajudá-lo a começar, e não necessariamente os valores da conta de armazenamento que você deseja usar em ambientes de produção. Para evitar latência durante a criação do projeto, conecte-se a contas de armazenamento na mesma região do recurso Idioma.
Valor da conta de armazenamento Valor recomendado Nome da conta de armazenamento Qualquer nome Storage account type LRS padrão Certifique-se de que o Aviso de IA Responsável está verificado. Selecione Rever + criar na parte inferior da página.

Carregar dados de amostra para o contêiner de blob
Depois de criar uma conta de armazenamento do Azure e conectá-la ao seu recurso de idioma, você precisará carregar os documentos do conjunto de dados de exemplo para o diretório raiz do contêiner. Estes documentos serão posteriormente utilizados para treinar o seu modelo.
Faça o download do conjunto de dados de exemplo para projetos de classificação de vários rótulos.
Abra o arquivo .zip e extraia a pasta que contém os documentos.
O conjunto de dados de exemplo fornecido contém cerca de 200 documentos, cada um dos quais é um resumo para um filme. Cada documento pertence a uma ou mais das seguintes classes:
- "Mistério"
- "Drama"
- "Suspense"
- "Comédia"
- "Ação"
No portal do Azure, navegue até a conta de armazenamento que você criou e selecione-a. Você pode fazer isso clicando em Contas de armazenamento e digitando o nome da conta de armazenamento em Filtrar para qualquer campo.
se o seu grupo de recursos não aparecer, certifique-se de que o filtro Subscrição é igual está definido como Todos.
Na sua conta de armazenamento, selecione Contêineres no menu à esquerda, localizado abaixo de Armazenamento de dados. Na tela exibida, selecione + Contêiner. Dê ao contêiner o nome example-data e deixe o nível de acesso público padrão.
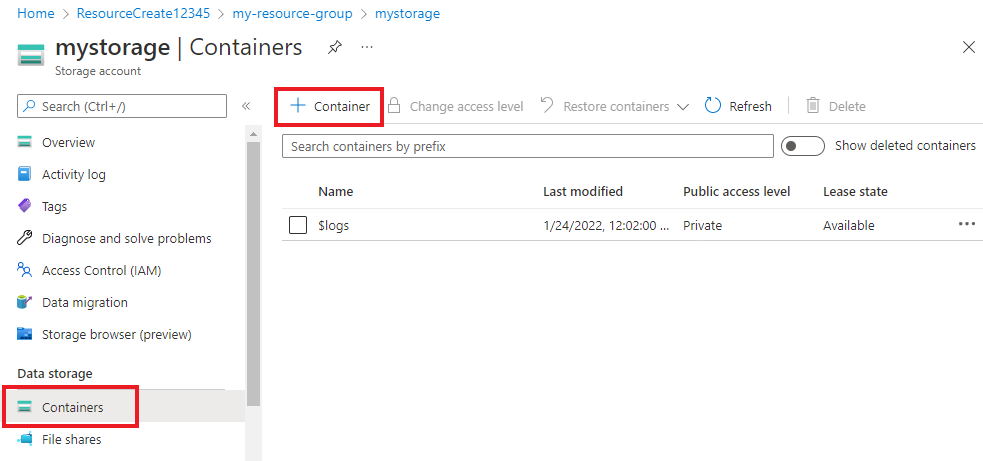
Depois que o contêiner for criado, selecione-o. Em seguida, selecione o botão Carregar para selecionar os
.txtarquivos que.jsonvocê baixou anteriormente.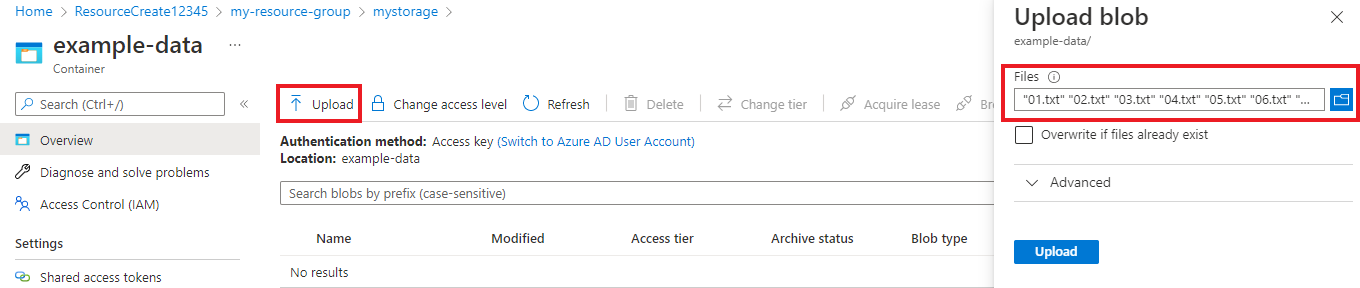


Criar um projeto de classificação de texto personalizado
Depois que o contêiner de recursos e armazenamento estiver configurado, crie um novo projeto de classificação de texto personalizado. Um projeto é uma área de trabalho para criar seus modelos de ML personalizados com base em seus dados. O seu projeto só pode ser acedido por si e por outras pessoas que tenham acesso ao recurso linguístico que está a ser utilizado.
Entre no Language Studio. Será exibida uma janela para permitir que você selecione sua assinatura e recurso de idioma. Selecione o seu recurso Idioma.
Na seção Classificar texto do Language Studio, selecione Classificação de texto personalizada.
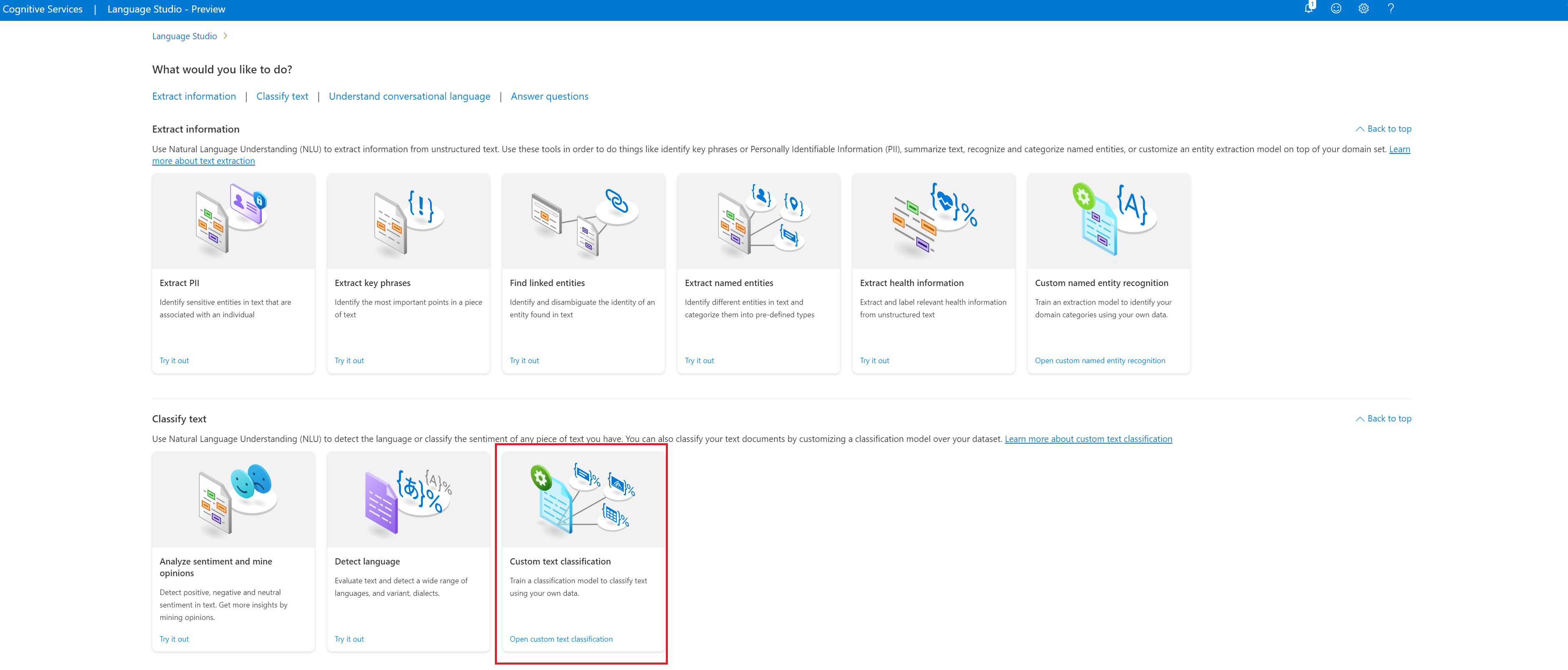
Selecione Criar novo projeto no menu superior da página de projetos. Criar um projeto permitirá que você rotule dados, treine, avalie, melhore e implante seus modelos.
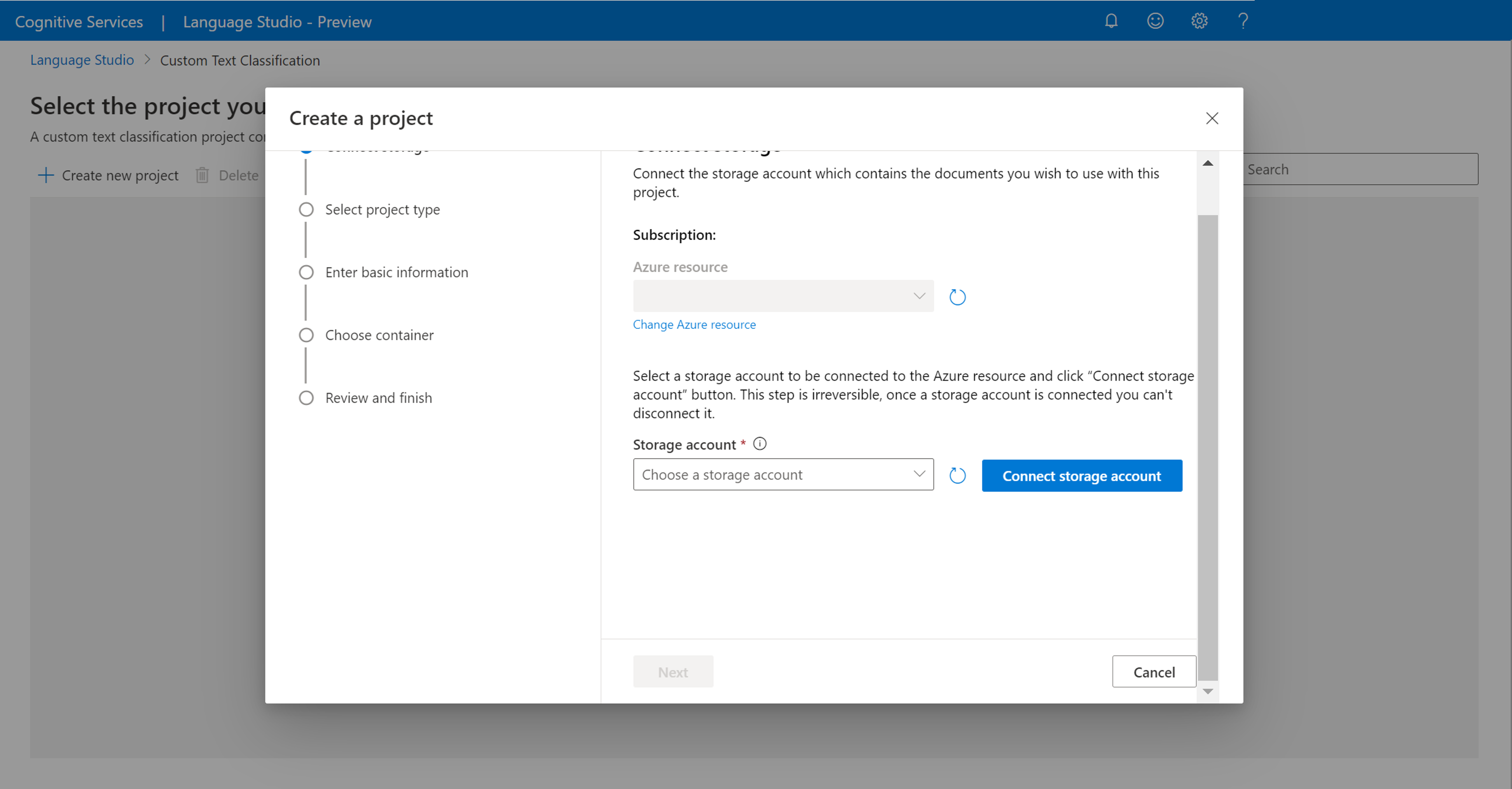
Depois de clicar em Criar novo projeto, aparecerá uma janela para permitir que você conecte sua conta de armazenamento. Se você já tiver conectado uma conta de armazenamento, verá o armazenamento contabilizado conectado. Caso contrário, escolha sua conta de armazenamento na lista suspensa exibida e selecione Conectar conta de armazenamento, isso definirá as funções necessárias para sua conta de armazenamento. Esta etapa possivelmente retornará um erro se você não estiver atribuído como proprietário na conta de armazenamento.
Nota
- Você só precisa fazer essa etapa uma vez para cada novo recurso de idioma usado.
- Esse processo é irreversível, se você conectar uma conta de armazenamento ao seu recurso de idioma, não poderá desconectá-la mais tarde.
- Você só pode conectar seu recurso de idioma a uma conta de armazenamento.
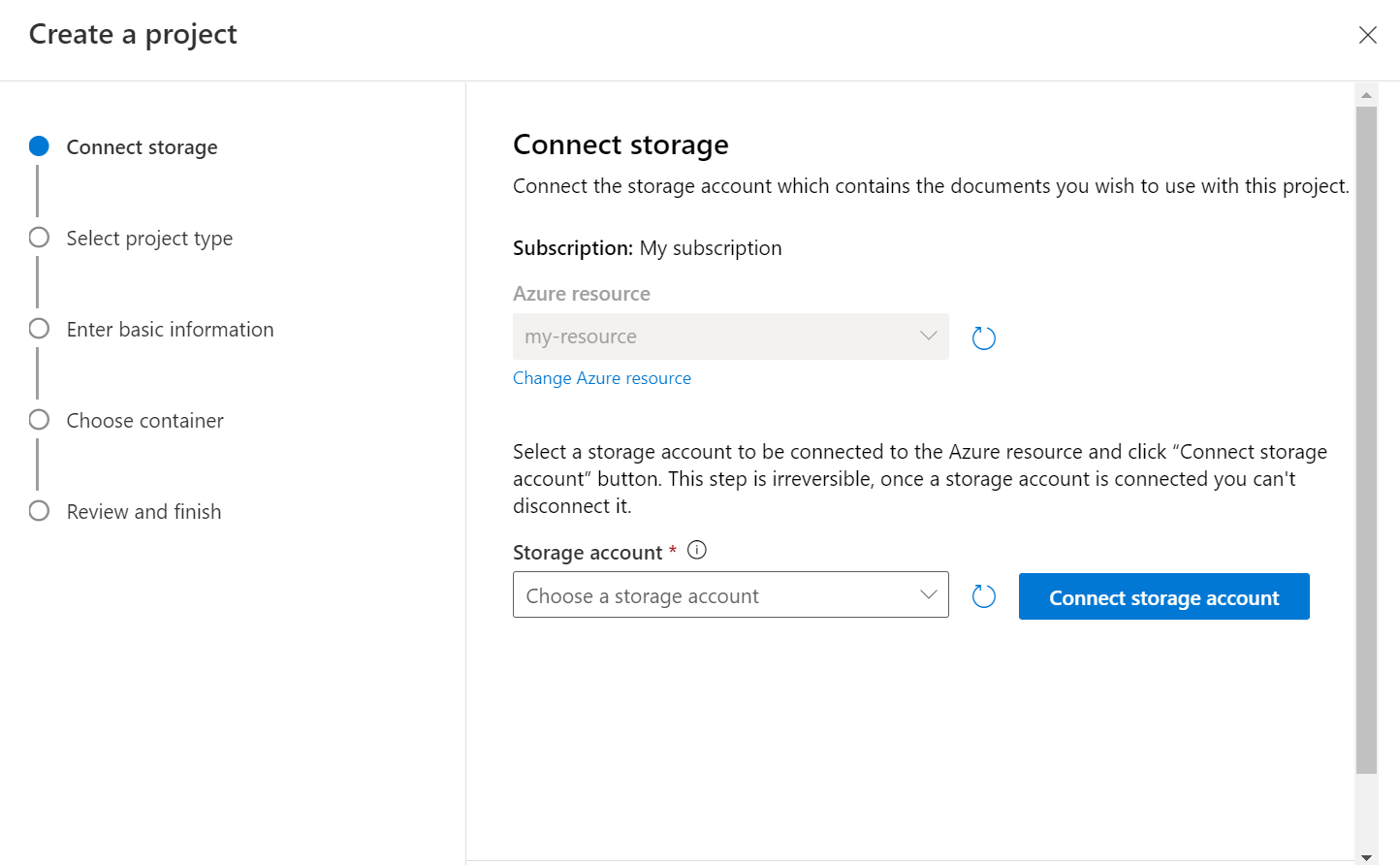
Selecione o tipo de projeto. Você pode criar um projeto de classificação de rótulo múltiplo onde cada documento pode pertencer a uma ou mais classes ou um projeto de classificação de rótulo único onde cada documento pode pertencer a apenas uma classe. O tipo selecionado não pode ser alterado posteriormente. Saiba mais sobre os tipos de projeto
Insira as informações do projeto, incluindo um nome, uma descrição e o idioma dos documentos em seu projeto. Se você estiver usando o conjunto de dados de exemplo, selecione Inglês. Você não poderá alterar o nome do seu projeto mais tarde. Selecione Seguinte.
Gorjeta
Seu conjunto de dados não precisa estar totalmente no mesmo idioma. Você pode ter vários documentos, cada um com diferentes idiomas suportados. Se o conjunto de dados contiver documentos de idiomas diferentes ou se você esperar texto de idiomas diferentes durante o tempo de execução, selecione a opção habilitar conjunto de dados multilíngue ao inserir as informações básicas para seu projeto. Esta opção pode ser ativada posteriormente na página Configurações do projeto.
Selecione o contêiner onde você carregou seu conjunto de dados.
Nota
Se você já rotulou seus dados, certifique-se de que eles seguem o formato suportado e selecione Sim, meus documentos já estão rotulados e eu formatei o arquivo de etiquetas JSON e selecione o arquivo de etiquetas no menu suspenso abaixo.
Se você estiver usando um dos conjuntos de dados de exemplo, use o arquivo included
webOfScience_labelsFileoumovieLabelsjson. Em seguida, selecione Seguinte.Revise os dados inseridos e selecione Criar projeto.




Preparar o modelo
Normalmente, depois de criar um projeto, você vai em frente e começa a rotular os documentos que você tem no contêiner conectado ao seu projeto. Para este início rápido, você importou um conjunto de dados rotulado de exemplo e inicializou seu projeto com o arquivo de rótulos JSON de exemplo.
Para começar a treinar o seu modelo a partir do Language Studio:
Selecione Trabalhos de treinamento no menu do lado esquerdo.
Selecione Iniciar um trabalho de treinamento no menu superior.
Selecione Treinar um novo modelo e digite o nome do modelo na caixa de texto. Você também pode substituir um modelo existente selecionando essa opção e escolhendo o modelo que deseja substituir no menu suspenso. A substituição de um modelo treinado é irreversível, mas não afetará os modelos implantados até que você implante o novo modelo.
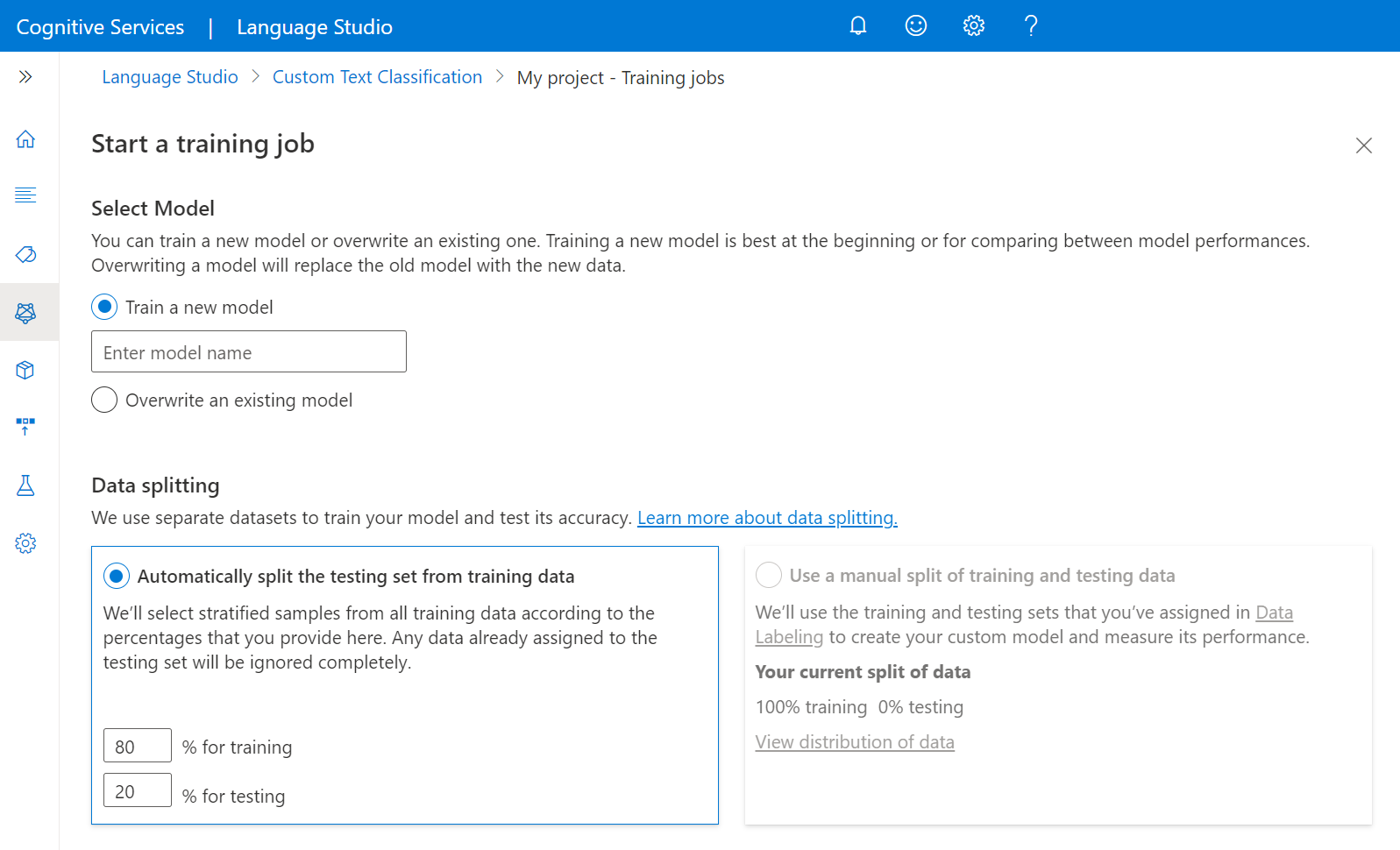
Selecione o método de divisão de dados. Você pode escolher Dividir automaticamente o conjunto de testes dos dados de treinamento, onde o sistema dividirá seus dados rotulados entre os conjuntos de treinamento e teste, de acordo com as porcentagens especificadas. Ou você pode usar uma divisão manual de dados de treinamento e teste, essa opção só é habilitada se você tiver adicionado documentos ao seu conjunto de testes durante a rotulagem de dados. Consulte Como treinar um modelo para obter mais informações sobre a divisão de dados.
Selecione o botão Trem .
Se você selecionar o ID do trabalho de treinamento na lista, um painel lateral aparecerá onde você pode verificar o progresso do treinamento, o status do trabalho e outros detalhes para este trabalho.
Nota
- Apenas trabalhos de formação concluídos com sucesso gerarão modelos.
- O tempo para treinar o modelo pode levar entre alguns minutos a várias horas com base no tamanho dos dados rotulados.
- Só pode ter um trabalho de preparação em execução de cada vez. Não pode iniciar outro trabalho de preparação no mesmo projeto sem que o trabalho em execução esteja concluído.

Implementar o modelo
Geralmente, depois de treinar um modelo, você revisaria seus detalhes de avaliação e faria melhorias , se necessário. Neste início rápido, você apenas implantará seu modelo e o disponibilizará para experimentar no Language Studio, ou poderá chamar a API de previsão.
Para implantar seu modelo a partir do Language Studio:
Selecione Implantando um modelo no menu do lado esquerdo.
Selecione Adicionar implantação para iniciar um novo trabalho de implantação .
Selecione Criar nova implantação para criar uma nova implantação e atribuir um modelo treinado na lista suspensa abaixo. Você também pode substituir uma implantação existente selecionando essa opção e selecionando o modelo treinado que deseja atribuir a ela na lista suspensa abaixo.
Nota
A substituição de uma implantação existente não requer alterações na chamada da API de Previsão, mas os resultados obtidos serão baseados no modelo recém-atribuído.
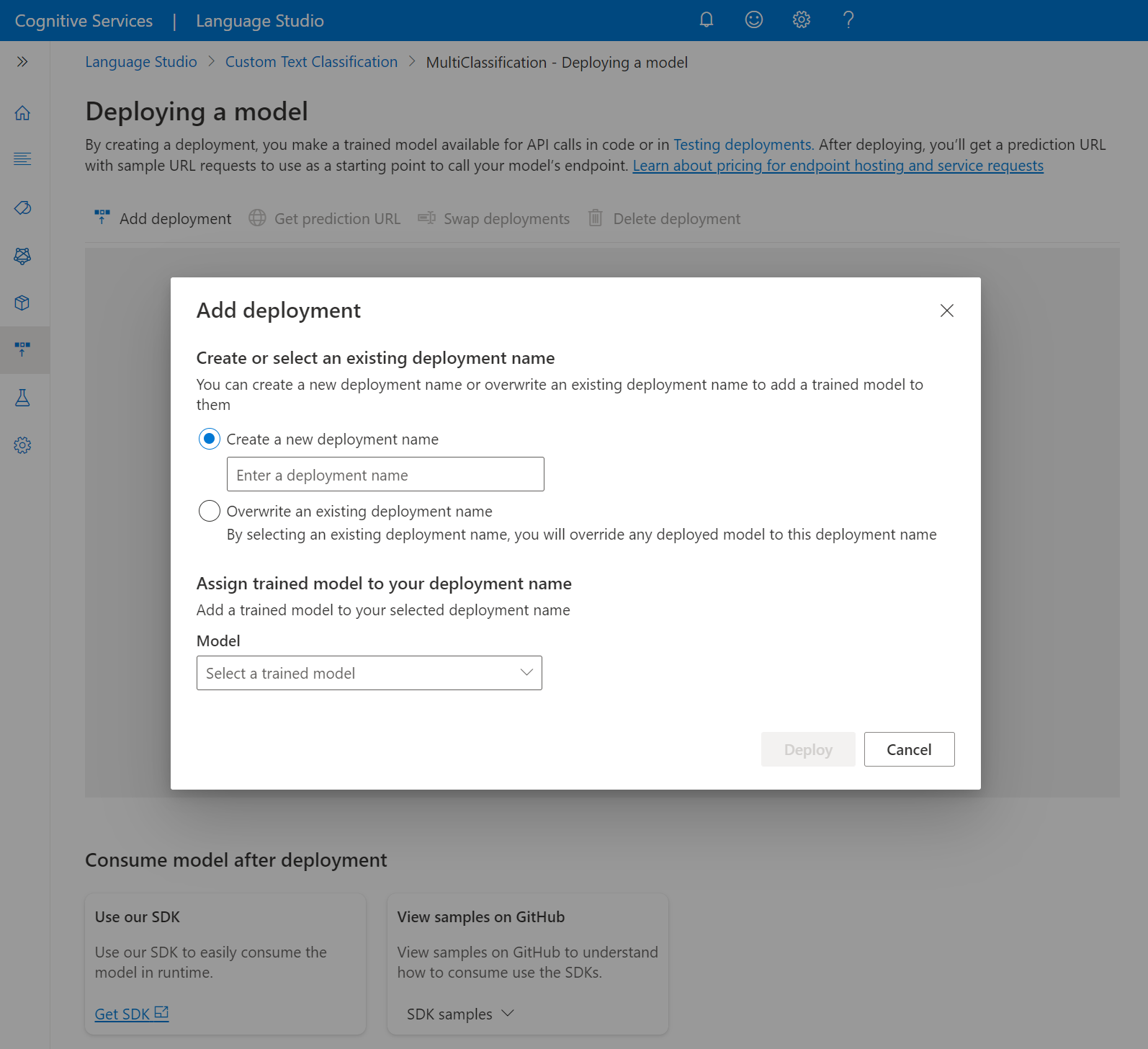
selecione Implantar para iniciar o trabalho de implantação.
Depois que a implantação for bem-sucedida, uma data de expiração aparecerá ao lado dela. A expiração da implantação é quando o modelo implantado não estará disponível para ser usado para previsão, o que normalmente acontece doze meses após a expiração de uma configuração de treinamento.


Testar o seu modelo
Depois que o modelo for implantado, você poderá começar a usá-lo para classificar seu texto por meio da API de previsão. Para este início rápido, você usará o Language Studio para enviar a tarefa de classificação de texto personalizada e visualizar os resultados. No conjunto de dados de exemplo que você baixou anteriormente, você pode encontrar alguns documentos de teste que você pode usar nesta etapa.
Para testar seus modelos implantados no Language Studio:
Selecione Testando implantações no menu do lado esquerdo da tela.
Selecione a implantação que você deseja testar. Você só pode testar modelos atribuídos a implantações.
Para projetos multilíngues, selecione o idioma do texto que você está testando usando a lista suspensa de idiomas.
Selecione a implantação que você deseja consultar/testar na lista suspensa.
Introduza o texto que pretende submeter no pedido ou carregue um
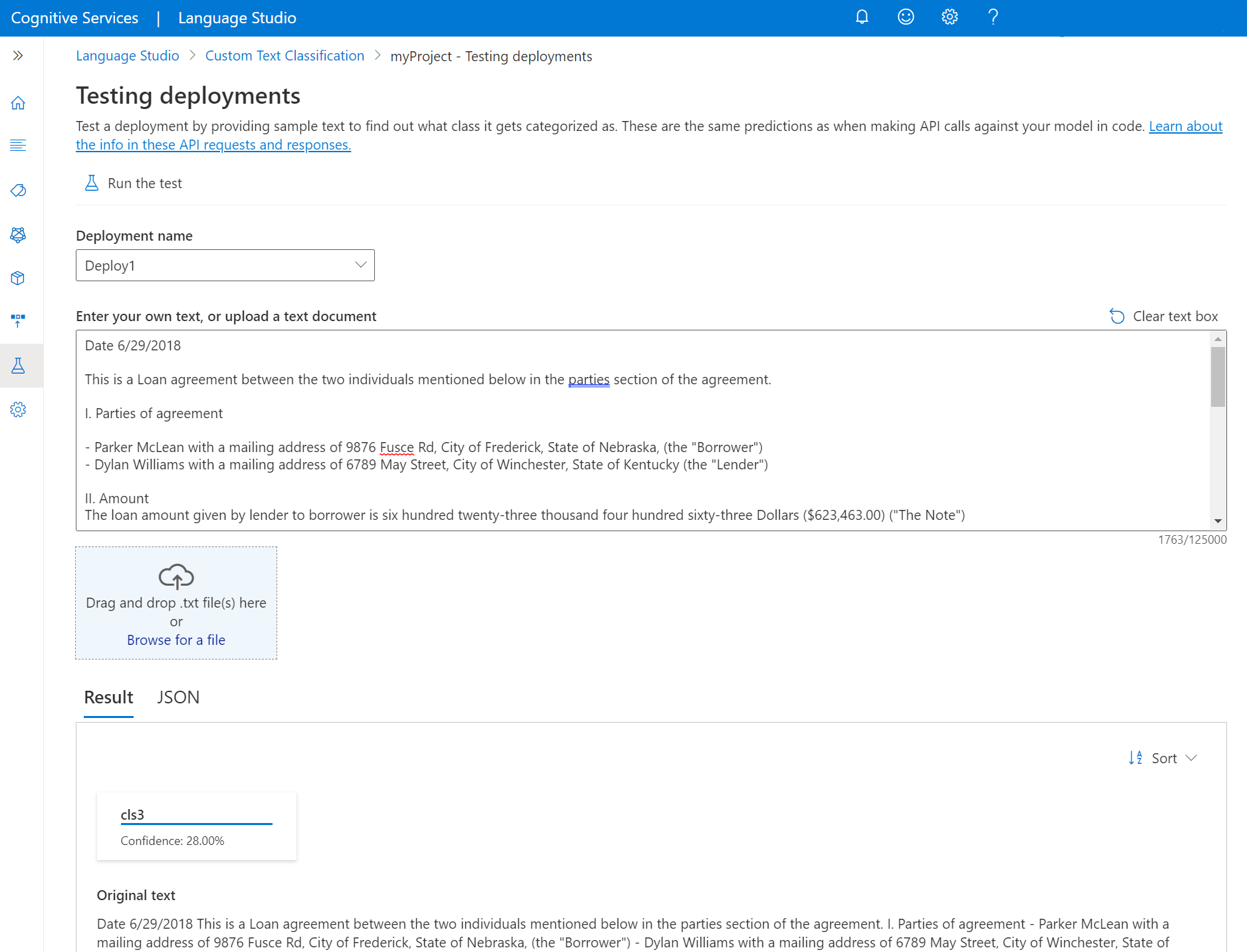
.txtdocumento para utilizar. Se você estiver usando um dos conjuntos de dados de exemplo, poderá usar um dos arquivos de .txt incluídos.Selecione Executar o teste no menu superior.
Na guia Resultado, você pode ver as classes previstas para seu texto. Você também pode exibir a resposta JSON na guia JSON . O exemplo a seguir é para um projeto de classificação de rótulo único. Um projeto de classificação multirótulo pode retornar mais de uma classe no resultado.

Projetos de limpeza
Quando você não precisar mais do seu projeto, poderá excluí-lo usando o Language Studio. Selecione Classificação de texto personalizada na parte superior e, em seguida, selecione o projeto que deseja excluir. Selecione Excluir no menu superior para excluir o projeto.
Pré-requisitos
- Subscrição do Azure - Crie uma gratuitamente.
Criar um novo recurso de linguagem de IA do Azure e uma conta de armazenamento do Azure
Antes de poder usar a classificação de texto personalizada, você precisará criar um recurso de linguagem de IA do Azure, que lhe dará as credenciais necessárias para criar um projeto e começar a treinar um modelo. Você também precisará de uma conta de armazenamento do Azure, onde poderá carregar seu conjunto de dados que será usado na criação de seu modelo.
Importante
Para começar rapidamente, recomendamos criar um novo recurso de Linguagem de IA do Azure usando as etapas fornecidas neste artigo, que permitirão criar o recurso de Idioma e criar e/ou conectar uma conta de armazenamento ao mesmo tempo, o que é mais fácil do que fazê-lo mais tarde.
Se você tiver um recurso pré-existente que gostaria de usar, precisará conectá-lo à conta de armazenamento.
Criar um novo recurso a partir do portal do Azure
Vá para o portal do Azure para criar um novo recurso de linguagem de IA do Azure.
Na janela exibida, selecione Classificação de texto personalizada & reconhecimento de entidade nomeada personalizada nos recursos personalizados. Selecione Continuar para criar seu recurso na parte inferior da tela.
Crie um recurso de idioma com os seguintes detalhes.
Nome Valor obrigatório Subscrição A sua subscrição do Azure. Grupo de recursos Um grupo de recursos que conterá seu recurso. Você pode usar um existente ou criar um novo. País/Região Uma das regiões apoiadas. Por exemplo, "West US 2". Nome Um nome para o seu recurso. Escalão de preço Um dos níveis de preços suportados. Você pode usar a camada Gratuito (F0) para experimentar o serviço. Se você receber uma mensagem dizendo "sua conta de login não é proprietária do grupo de recursos da conta de armazenamento selecionada", sua conta precisará ter uma função de proprietário atribuída no grupo de recursos antes de poder criar um recurso de idioma. Entre em contato com o proprietário da assinatura do Azure para obter assistência.
Você pode determinar o proprietário da assinatura do Azure pesquisando seu grupo de recursos e seguindo o link para sua assinatura associada. Em seguida:
- Selecione a guia Controle de acesso (IAM)
- Selecionar atribuições de função
- Filtrar por Função:Proprietário.
Na seção Classificação de texto personalizada & reconhecimento de entidade nomeada personalizada, selecione uma conta de armazenamento existente ou selecione Nova conta de armazenamento. Observe que esses valores são para ajudá-lo a começar, e não necessariamente os valores da conta de armazenamento que você deseja usar em ambientes de produção. Para evitar latência durante a criação do projeto, conecte-se a contas de armazenamento na mesma região do recurso Idioma.
Valor da conta de armazenamento Valor recomendado Nome da conta de armazenamento Qualquer nome Storage account type LRS padrão Certifique-se de que o Aviso de IA Responsável está verificado. Selecione Rever + criar na parte inferior da página.
Carregar dados de amostra para o contêiner de blob
Depois de criar uma conta de armazenamento do Azure e conectá-la ao seu recurso de idioma, você precisará carregar os documentos do conjunto de dados de exemplo para o diretório raiz do contêiner. Estes documentos serão posteriormente utilizados para treinar o seu modelo.
Faça o download do conjunto de dados de exemplo para projetos de classificação de vários rótulos.
Abra o arquivo .zip e extraia a pasta que contém os documentos.
O conjunto de dados de exemplo fornecido contém cerca de 200 documentos, cada um dos quais é um resumo para um filme. Cada documento pertence a uma ou mais das seguintes classes:
- "Mistério"
- "Drama"
- "Suspense"
- "Comédia"
- "Ação"
No portal do Azure, navegue até a conta de armazenamento que você criou e selecione-a. Você pode fazer isso clicando em Contas de armazenamento e digitando o nome da conta de armazenamento em Filtrar para qualquer campo.
se o seu grupo de recursos não aparecer, certifique-se de que o filtro Subscrição é igual está definido como Todos.
Na sua conta de armazenamento, selecione Contêineres no menu à esquerda, localizado abaixo de Armazenamento de dados. Na tela exibida, selecione + Contêiner. Dê ao contêiner o nome example-data e deixe o nível de acesso público padrão.
Depois que o contêiner for criado, selecione-o. Em seguida, selecione o botão Carregar para selecionar os
.txtarquivos que.jsonvocê baixou anteriormente.
Obtenha suas chaves de recursos e ponto de extremidade
Vá para a página de visão geral dos recursos no portal do Azure
No menu do lado esquerdo, selecione Teclas e Ponto de extremidade. Você usará o ponto de extremidade e a chave para as solicitações de API

Criar um projeto de classificação de texto personalizado
Depois que o contêiner de recursos e armazenamento estiver configurado, crie um novo projeto de classificação de texto personalizado. Um projeto é uma área de trabalho para criar seus modelos de ML personalizados com base em seus dados. O seu projeto só pode ser acedido por si e por outras pessoas que tenham acesso ao recurso linguístico que está a ser utilizado.
Acionar trabalho de projeto de importação
Envie uma solicitação POST usando a seguinte URL, cabeçalhos e corpo JSON para importar seu arquivo de etiquetas. Certifique-se de que o ficheiro de etiquetas segue o formato aceite.
Se já existir um projeto com o mesmo nome, os dados desse projeto serão substituídos.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
Cabeçalhos
Use o cabeçalho a seguir para autenticar sua solicitação.
| Key | valor |
|---|---|
Ocp-Apim-Subscription-Key |
A chave para o seu recurso. Usado para autenticar suas solicitações de API. |
Corpo
Use o JSON a seguir em sua solicitação. Substitua os valores de espaço reservado abaixo pelos seus próprios valores.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Key | Marcador de Posição | valor | Exemplo |
|---|---|---|---|
| api-version | {API-VERSION} |
A versão da API que você está chamando. A versão usada aqui deve ser a mesma versão da API na URL. Saiba mais sobre outras versões de API disponíveis | 2022-05-01 |
| projectName | {PROJECT-NAME} |
O nome do seu projeto. Esse valor diferencia maiúsculas de minúsculas. | myProject |
| projectKind | customMultiLabelClassification |
O seu tipo de projeto. | customMultiLabelClassification |
| idioma | {LANGUAGE-CODE} |
Uma cadeia de caracteres especificando o código de idioma para os documentos usados em seu projeto. Se o seu projeto for multilingue, escolha o código linguístico da maioria dos documentos. Consulte o suporte linguístico para saber mais sobre o suporte multilingue. | en-us |
| multilingue | true |
Um valor booleano que permite que você tenha documentos em vários idiomas em seu conjunto de dados e, quando seu modelo é implantado, você pode consultar o modelo em qualquer idioma suportado (não necessariamente incluído em seus documentos de treinamento. Consulte o suporte linguístico para saber mais sobre o suporte multilingue. | true |
| storageInputContainerName | {CONTAINER-NAME} |
O nome do contêiner de armazenamento do Azure onde você carregou seus documentos. | myContainer |
| objetos | [] | Matriz contendo todas as classes que você tem no projeto. Estas são as classes em que pretende classificar os seus documentos. | [] |
| documents | [] | Matriz que contém todos os documentos em seu projeto e o que as classes rotuladas para este documento. | [] |
| localização | {DOCUMENT-NAME} |
A localização dos documentos no recipiente de armazenamento. Como todos os documentos estão na raiz do contêiner, este deve ser o nome do documento. | doc1.txt |
| conjunto de dados | {DATASET} |
O conjunto de testes para o qual este documento irá quando dividido antes do treinamento. Consulte Como treinar um modelo para obter mais informações sobre a divisão de dados. Os valores possíveis para este campo são Train e Test. |
Train |
Depois de enviar sua solicitação de API, você receberá uma 202 resposta indicando que o trabalho foi enviado corretamente. Nos cabeçalhos de resposta, extraia o operation-location valor. Será formatado da seguinte forma:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} é utilizado para identificar o seu pedido, uma vez que esta operação é assíncrona. Você usará essa URL para obter o status do trabalho de importação.
Possíveis cenários de erro para esta solicitação:
- O recurso selecionado não tem permissões adequadas para a conta de armazenamento.
- O
storageInputContainerNameespecificado não existe. - Código de idioma inválido é usado, ou se o tipo de código de idioma não é string.
multilingualvalue é uma cadeia de caracteres e não um booleano.
Obter status de trabalho de importação
Use a seguinte solicitação GET para obter o status da importação do projeto. Substitua os valores de espaço reservado abaixo pelos seus próprios valores.
URL do Pedido
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
Cabeçalhos
Use o cabeçalho a seguir para autenticar sua solicitação.
| Key | valor |
|---|---|
Ocp-Apim-Subscription-Key |
A chave para o seu recurso. Usado para autenticar suas solicitações de API. |
Preparar o modelo
Normalmente, depois de criar um projeto, você vai em frente e começa a marcar os documentos que você tem no contêiner conectado ao seu projeto. Para este início rápido, você importou um conjunto de dados marcado de exemplo e inicializou seu projeto com o arquivo de tags JSON de exemplo.
Comece a treinar o seu modelo
Depois que seu projeto for importado, você poderá começar a treinar seu modelo.
Envie uma solicitação POST usando a seguinte URL, cabeçalhos e corpo JSON para enviar um trabalho de treinamento. Substitua os valores de espaço reservado abaixo pelos seus próprios valores.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
Cabeçalhos
Use o cabeçalho a seguir para autenticar sua solicitação.
| Key | valor |
|---|---|
Ocp-Apim-Subscription-Key |
A chave para o seu recurso. Usado para autenticar suas solicitações de API. |
Corpo do pedido
Use o JSON a seguir no corpo da solicitação. O modelo será dado assim que o {MODEL-NAME} treinamento for concluído. Só empregos de formação bem sucedidos produzirão modelos.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Key | Marcador de Posição | valor | Exemplo |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
O nome do modelo que será atribuído ao seu modelo depois de treinado com sucesso. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Esta é a versão do modelo que será usada para treinar o modelo. | 2022-05-01 |
| avaliaçãoOpções | Opção para dividir seus dados entre conjuntos de treinamento e teste. | {} |
|
| variante | percentage |
Métodos de divisão. Os valores possíveis são percentage ou manual. Consulte Como treinar um modelo para obter mais informações. |
percentage |
| formaçãoSplitPercentage | 80 |
Porcentagem dos dados marcados a serem incluídos no conjunto de treinamento. O valor recomendado é 80. |
80 |
| testingSplitPercentage | 20 |
Porcentagem dos dados marcados a serem incluídos no conjunto de testes. O valor recomendado é 20. |
20 |
Nota
O trainingSplitPercentage e só são necessários se Kind for definido como percentage e testingSplitPercentage a soma de ambas as percentagens deve ser igual a 100.
Depois de enviar sua solicitação de API, você receberá uma 202 resposta indicando que o trabalho foi enviado corretamente. Nos cabeçalhos de resposta, extraia o location valor. Será formatado da seguinte forma:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} é utilizado para identificar o seu pedido, uma vez que esta operação é assíncrona. Você pode usar essa URL para obter o status de treinamento.
Obter status de trabalho de treinamento
O treino pode demorar entre 10 e 30 minutos. Você pode usar a solicitação a seguir para continuar pesquisando o status do trabalho de treinamento até que ele seja concluído com êxito.
Use a seguinte solicitação GET para obter o status do progresso do treinamento do seu modelo. Substitua os valores de espaço reservado abaixo pelos seus próprios valores.
URL do Pedido
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de Posição | valor | Exemplo |
|---|---|---|
{ENDPOINT} |
O ponto de extremidade para autenticar sua solicitação de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
O nome do seu projeto. Esse valor diferencia maiúsculas de minúsculas. | myProject |
{JOB-ID} |
O ID para localizar o status de treinamento do seu modelo. Esse valor está no valor do location cabeçalho que você recebeu na etapa anterior. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
A versão da API que você está chamando. O valor referenciado aqui é para a última versão lançada. Consulte o ciclo de vida do modelo para saber mais sobre outras versões de API disponíveis. | 2022-05-01 |
Cabeçalhos
Use o cabeçalho a seguir para autenticar sua solicitação.
| Key | valor |
|---|---|
Ocp-Apim-Subscription-Key |
A chave para o seu recurso. Usado para autenticar suas solicitações de API. |
Organismo de resposta
Depois de enviar a solicitação, você receberá a seguinte resposta.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Implementar o modelo
Geralmente, depois de treinar um modelo, você revisaria os detalhes da avaliação e faria melhorias, se necessário. Neste início rápido, você apenas implantará seu modelo e o disponibilizará para experimentar no Language Studio, ou poderá chamar a API de previsão.
Enviar trabalho de implantação
Envie uma solicitação PUT usando a seguinte URL, cabeçalhos e corpo JSON para enviar um trabalho de implantação. Substitua os valores de espaço reservado abaixo pelos seus próprios valores.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
Cabeçalhos
Use o cabeçalho a seguir para autenticar sua solicitação.
| Key | valor |
|---|---|
Ocp-Apim-Subscription-Key |
A chave para o seu recurso. Usado para autenticar suas solicitações de API. |
Corpo do pedido
Use o JSON a seguir no corpo da sua solicitação. Use o nome do modelo que você atribui à implantação.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Key | Marcador de Posição | valor | Exemplo |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
O nome do modelo que será atribuído à sua implantação. Você só pode atribuir modelos treinados com sucesso. Esse valor diferencia maiúsculas de minúsculas. | myModel |
Depois de enviar sua solicitação de API, você receberá uma 202 resposta indicando que o trabalho foi enviado corretamente. Nos cabeçalhos de resposta, extraia o operation-location valor. Será formatado da seguinte forma:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} é utilizado para identificar o seu pedido, uma vez que esta operação é assíncrona. Você pode usar essa URL para obter o status da implantação.
Obter o status do trabalho de implantação
Use a seguinte solicitação GET para consultar o status do trabalho de implantação. Você pode usar a URL recebida da etapa anterior ou substituir os valores de espaço reservado abaixo por seus próprios valores.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Cabeçalhos
Use o cabeçalho a seguir para autenticar sua solicitação.
| Key | valor |
|---|---|
Ocp-Apim-Subscription-Key |
A chave para o seu recurso. Usado para autenticar suas solicitações de API. |
Organismo de resposta
Depois de enviar o pedido, obterá a seguinte resposta. Continue pesquisando este ponto de extremidade até que o parâmetro de status mude para "bem-sucedido". Você deve obter um 200 código para indicar o sucesso da solicitação.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Classificar texto
Depois que o modelo for implantado com êxito, você poderá começar a usá-lo para classificar seu texto por meio da API de previsão. No conjunto de dados de exemplo que você baixou anteriormente, você pode encontrar alguns documentos de teste que você pode usar nesta etapa.
Enviar uma tarefa de classificação de texto personalizada
Use esta solicitação POST para iniciar uma tarefa de classificação de texto.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Marcador de Posição | valor | Exemplo |
|---|---|---|
{ENDPOINT} |
O ponto de extremidade para autenticar sua solicitação de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
A versão da API que você está chamando. O valor referenciado aqui é para a última versão lançada. Consulte Ciclo de vida do modelo para saber mais sobre outras versões de API disponíveis. | 2022-05-01 |
Cabeçalhos
| Key | valor |
|---|---|
| Ocp-Apim-Subscription-Key | A sua chave que fornece acesso a esta API. |
Corpo
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Key | Marcador de Posição | valor | Exemplo |
|---|---|---|---|
displayName |
{JOB-NAME} |
O nome do seu trabalho. | MyJobName |
documents |
[{},{}] | Lista de documentos para executar tarefas. | [{},{}] |
id |
{DOC-ID} |
Nome ou ID do documento. | doc1 |
language |
{LANGUAGE-CODE} |
Uma cadeia de caracteres especificando o código de idioma para o documento. Se essa chave não for especificada, o serviço assumirá o idioma padrão do projeto que foi selecionado durante a criação do projeto. Consulte Suporte a idiomas para obter uma lista de códigos de idiomas suportados. | en-us |
text |
{DOC-TEXT} |
Documentar a tarefa na qual executar as tarefas. | Lorem ipsum dolor sit amet |
tasks |
Lista de tarefas que queremos realizar. | [] |
|
taskName |
CustomMultiLabelClassification | O nome da tarefa | CustomMultiLabelClassification |
parameters |
Lista de parâmetros a serem passados para a tarefa. | ||
project-name |
{PROJECT-NAME} |
O nome do seu projeto. Esse valor diferencia maiúsculas de minúsculas. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
O nome da sua implantação. Esse valor diferencia maiúsculas de minúsculas. | prod |
Response
Você receberá uma resposta 202 indicando sucesso. Nos cabeçalhos de resposta, extraia operation-location.
operation-location está formatado assim:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Você pode usar essa URL para consultar o status de conclusão da tarefa e obter os resultados quando a tarefa for concluída.
Obter resultados de tarefas
Use a seguinte solicitação GET para consultar o status/resultados da tarefa de classificação de texto.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Marcador de Posição | valor | Exemplo |
|---|---|---|
{ENDPOINT} |
O ponto de extremidade para autenticar sua solicitação de API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
A versão da API que você está chamando. O valor referenciado aqui é para a versão mais recente do modelo lançada. | 2022-05-01 |
Cabeçalhos
| Key | valor |
|---|---|
| Ocp-Apim-Subscription-Key | A sua chave que fornece acesso a esta API. |
Corpo da resposta
A resposta será um documento JSON com os seguintes parâmetros.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Clean up resources (Limpar recursos)
Quando você não precisar mais do seu projeto, poderá excluí-lo com a seguinte solicitação DELETE . Substitua os valores de espaço reservado por seus próprios valores.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
Cabeçalhos
Use o cabeçalho a seguir para autenticar sua solicitação.
| Key | valor |
|---|---|
| Ocp-Apim-Subscription-Key | A chave para o seu recurso. Usado para autenticar suas solicitações de API. |
Depois de enviar sua solicitação de API, você receberá uma 202 resposta indicando sucesso, o que significa que seu projeto foi excluído. Uma chamada bem-sucedida resulta com um Operation-Location cabeçalho usado para verificar o status do trabalho.
Próximos passos
Depois de criar um modelo de classificação de texto personalizado, você pode:
Quando você começar a criar seus próprios projetos de classificação de texto personalizados, use os artigos de instruções para saber mais sobre como desenvolver seu modelo com mais detalhes: