Sugestões de desempenho para o Azure Cosmos DB e SDK de .NET v2
APLICA-SE A: ![]() NoSQL
NoSQL
O Azure Cosmos DB é um banco de dados distribuído rápido e flexível que pode ser dimensionado perfeitamente com latência e taxa de transferência garantidas. Você não precisa fazer grandes alterações na arquitetura ou escrever código complexo para dimensionar seu banco de dados com o Azure Cosmos DB. Escalar para cima e para baixo é tão fácil quanto fazer uma única chamada de API. Para saber mais, consulte como provisionar a taxa de transferência do contêiner ou como provisionar a taxa de transferência do banco de dados. Mas como o Azure Cosmos DB é acessado por meio de chamadas de rede, há otimizações do lado do cliente que você pode fazer para atingir o desempenho máximo quando usa o SQL .NET SDK.
Portanto, se você estiver tentando melhorar o desempenho do banco de dados, considere estas opções:
Atualizar para o SDK do .NET V3
O SDK do .NET v3 é lançado. Se você usar o SDK do .NET v3, consulte o guia de desempenho do .NET v3 para obter as seguintes informações:
- Padrão para o modo TCP direto
- Suporte à API de fluxo
- Suporte serializador personalizado para permitir System.Text.JSON uso
- Suporte integrado em lote e em massa
Recomendações de hospedagem
Ativar a coleta de lixo do lado do servidor (GC)
Reduzir a frequência da coleta de lixo pode ajudar em alguns casos. No .NET, defina gcServer como true.
Dimensione a carga de trabalho do cliente
Se você estiver testando em altos níveis de taxa de transferência (mais de 50.000 RU/s), o aplicativo cliente pode se tornar o gargalo devido à máquina limitar a utilização da CPU ou da rede. Se você chegar a esse ponto, poderá continuar a impulsionar ainda mais a conta do Azure Cosmos DB dimensionando seus aplicativos cliente em vários servidores.
Nota
O alto uso da CPU pode causar maior latência e exceções de tempo limite de solicitação.
Operações de metadados
Não verifique se um Banco de Dados e/ou Coleção existe chamando Create...IfNotExistsAsync e/ou Read...Async no caminho ativo e/ou antes de fazer uma operação de item. A validação só deve ser feita na inicialização do aplicativo quando for necessário, se você espera que eles sejam excluídos (caso contrário, não é necessário). Essas operações de metadados gerarão latência extra de ponta a ponta, não terão SLA e suas próprias limitações separadas que não são dimensionadas como operações de dados.
Registo e rastreio
Alguns ambientes têm o .NET DefaultTraceListener habilitado. O DefaultTraceListener apresenta problemas de desempenho em ambientes de produção, causando altos gargalos de CPU e E/S. Verifique e certifique-se de que o DefaultTraceListener está desativado para seu aplicativo removendo-o do TraceListeners em ambientes de produção.
As versões mais recentes do SDK (maiores que 2.16.2) o removem automaticamente quando o detetam, com versões mais antigas, você pode removê-lo por:
if (!Debugger.IsAttached)
{
Type defaultTrace = Type.GetType("Microsoft.Azure.Documents.DefaultTrace,Microsoft.Azure.DocumentDB.Core");
TraceSource traceSource = (TraceSource)defaultTrace.GetProperty("TraceSource").GetValue(null);
traceSource.Listeners.Remove("Default");
// Add your own trace listeners
}
Rede
Política de conexão: usar o modo de conexão direta
O modo de conexão padrão do SDK do .NET V2 é gateway. Configure o modo de conexão durante a DocumentClient construção da instância usando o ConnectionPolicy parâmetro. Se você usar o modo direto, você também precisa definir o Protocol usando o ConnectionPolicy parâmetro. Para saber mais sobre as diferentes opções de conectividade, consulte o artigo Modos de conectividade.
Uri serviceEndpoint = new Uri("https://contoso.documents.net");
string authKey = "your authKey from the Azure portal";
DocumentClient client = new DocumentClient(serviceEndpoint, authKey,
new ConnectionPolicy
{
ConnectionMode = ConnectionMode.Direct, // ConnectionMode.Gateway is the default
ConnectionProtocol = Protocol.Tcp
});
Exaustão de portas efémeras
Se você vir um alto volume de conexão ou alto uso de porta em suas instâncias, primeiro verifique se as instâncias do cliente são singletons. Em outras palavras, as instâncias do cliente devem ser exclusivas durante o tempo de vida do aplicativo.
Ao executar no protocolo TCP, o cliente otimiza a latência usando as conexões de longa duração em oposição ao protocolo HTTPS, que encerra as conexões após 2 minutos de inatividade.
Em cenários em que você tem acesso esparso e se notar uma contagem de conexões maior quando comparado ao acesso no modo gateway, você pode:
- Configure a propriedade ConnectionPolicy.PortReuseMode para
PrivatePortPool(eficaz com framework version>= 4.6.1 e .NET core version >= 2.0): essa propriedade permite que o SDK use um pequeno pool de portas efêmeras para diferentes pontos de extremidade de destino do Azure Cosmos DB. - Configure a propriedade ConnectionPolicy.IdleConnectionTimeout deve ser maior ou igual a 10 minutos. Os valores recomendados são entre 20 minutos e 24 horas.
Chame o OpenAsync para evitar a latência de inicialização na primeira solicitação
Por padrão, a primeira solicitação tem latência maior porque precisa buscar a tabela de roteamento de endereço. Quando você usa o SDK V2, chame OpenAsync() uma vez durante a inicialização para evitar essa latência de inicialização na primeira solicitação. A chamada tem a seguinte aparência: await client.OpenAsync();
Nota
OpenAsync gerará solicitações para obter a tabela de roteamento de endereços para todos os contêineres na conta. Para contas que têm muitos contêineres, mas cujo aplicativo acessa um subconjunto deles, OpenAsync geraria uma quantidade desnecessária de tráfego, o que tornaria a inicialização lenta. Portanto, o uso OpenAsync pode não ser útil nesse cenário, pois retarda a inicialização do aplicativo.
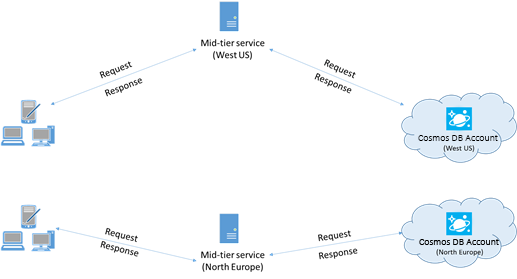
Para desempenho, coloque clientes na mesma região do Azure
Quando possível, coloque todos os aplicativos que chamam o Azure Cosmos DB na mesma região que o banco de dados do Azure Cosmos DB. Aqui está uma comparação aproximada: as chamadas para o Azure Cosmos DB dentro da mesma região são concluídas dentro de 1 ms a 2 ms, mas a latência entre a costa oeste e leste dos EUA é superior a 50 ms. Essa latência pode variar de solicitação para solicitação, dependendo da rota tomada pela solicitação à medida que ela passa do cliente para o limite do datacenter do Azure. Você pode obter a menor latência possível garantindo que o aplicativo de chamada esteja localizado na mesma região do Azure que o ponto de extremidade provisionado do Azure Cosmos DB. Para obter uma lista de regiões disponíveis, consulte Regiões do Azure.
Aumentar o número de threads/tarefas
Como as chamadas para o Azure Cosmos DB são feitas pela rede, talvez seja necessário variar o grau de paralelismo de suas solicitações para que o aplicativo cliente passe o mínimo de tempo esperando entre as solicitações. Por exemplo, se você estiver usando a Biblioteca Paralela de Tarefas do .NET, crie na ordem de centenas de tarefas que leem ou gravam no Azure Cosmos DB.
Habilite a rede acelerada
Para reduzir a latência e os desvios da CPU, recomendamos que você habilite a rede acelerada em máquinas virtuais cliente. Consulte Criar uma máquina virtual do Windows com rede acelerada ou Criar uma máquina virtual Linux com rede acelerada.
Utilização do SDK
Instalar o SDK mais recente
Os SDKs do Azure Cosmos DB estão sendo constantemente aprimorados para fornecer o melhor desempenho. Consulte as páginas do SDK do Azure Cosmos DB para determinar o SDK mais recente e revisar as melhorias.
Usar um cliente singleton do Azure Cosmos DB durante o tempo de vida do seu aplicativo
Cada DocumentClient instância é thread-safe e executa gerenciamento de conexão eficiente e cache de endereços ao operar no modo direto. Para permitir um gerenciamento de conexão eficiente e um melhor desempenho do cliente SDK, recomendamos que você use uma única instância por AppDomain durante o tempo de vida do aplicativo.
Evite bloquear chamadas
O SDK do Azure Cosmos DB deve ser projetado para processar muitas solicitações simultaneamente. As APIs assíncronas permitem que um pequeno pool de threads lide com milhares de solicitações simultâneas, não aguardando o bloqueio de chamadas. Em vez de aguardar a conclusão de uma tarefa síncrona de longa duração, o thread pode trabalhar em outra solicitação.
Um problema de desempenho comum em aplicativos que usam o SDK do Azure Cosmos DB é bloquear chamadas que podem ser assíncronas. Muitas chamadas de bloqueio síncronas levam à inanição do pool de threads e a tempos de resposta degradados.
Não:
- Bloqueie a execução assíncrona chamando Task.Wait ou Task.Result.
- Use Task.Run para tornar uma API síncrona assíncrona.
- Adquira bloqueios em caminhos de código comuns. O Azure Cosmos DB .NET SDK tem mais desempenho quando arquitetado para executar código em paralelo.
- Chame Task.Run e aguarde imediatamente. ASP.NET Core já executa o código do aplicativo em threads normais do Pool de Threads, portanto, chamar Task.Run resulta apenas em agendamento extra desnecessário do Pool de Threads. Mesmo que o código agendado bloqueie um thread, Task.Run não impede isso.
- Use ToList() no
DocumentClient.CreateDocumentQuery(...)qual usa o bloqueio de chamadas para drenar a consulta de forma síncrona. Use AsDocumentQuery() para drenar a consulta de forma assíncrona.
Fazer:
- Chame as APIs .NET do Azure Cosmos DB de forma assíncrona.
- Toda a pilha de chamadas é assíncrona para se beneficiar dos padrões async /await .
Um criador de perfil, como o PerfView, pode ser usado para localizar threads frequentemente adicionados ao pool de threads. O Microsoft-Windows-DotNETRuntime/ThreadPoolWorkerThread/Start evento indica um thread adicionado ao pool de threads.
Aumente System.Net MaxConnections por host ao usar o modo gateway
As solicitações do Azure Cosmos DB são feitas por HTTPS/REST quando você usa o modo de gateway. Eles estão sujeitos ao limite de conexão padrão por nome de host ou endereço IP. Talvez seja necessário definir MaxConnections um valor mais alto (100 a 1.000) para que a biblioteca de cliente possa usar várias conexões simultâneas com o Azure Cosmos DB. No .NET SDK 1.8.0 e posterior, o valor padrão para ServicePointManager.DefaultConnectionLimit é 50. Para alterar o valor, você pode definir Documents.Client.ConnectionPolicy.MaxConnectionLimit para um valor mais alto.
Implementar backoff em intervalos RetryAfter
Durante o teste de desempenho, você deve aumentar a carga até que uma pequena taxa de solicitações seja limitada. Se as solicitações forem limitadas, o aplicativo cliente deverá voltar a ser acelerado para o intervalo de repetição especificado pelo servidor. Respeitar o backoff garante que você passe uma quantidade mínima de tempo esperando entre as tentativas.
O suporte à política de repetição está incluído nestes SDKs:
- Versão 1.8.0 e posterior do SDK do .NET para SQL e do Java SDK para SQL
- Versão 1.9.0 e posterior do SDK do Node.js para SQL e do SDK do Python para SQL
- Todas as versões suportadas dos SDKs do .NET Core
Para obter mais informações, consulte RetryAfter.
Na versão 1.19 e posterior do SDK do .NET, há um mecanismo para registrar informações de diagnóstico adicionais e solucionar problemas de latência, conforme mostrado no exemplo a seguir. Você pode registrar a cadeia de caracteres de diagnóstico para solicitações que têm uma latência de leitura mais alta. A cadeia de caracteres de diagnóstico capturada ajudará você a entender quantas vezes você recebeu 429 erros para uma determinada solicitação.
ResourceResponse<Document> readDocument = await this.readClient.ReadDocumentAsync(oldDocuments[i].SelfLink);
readDocument.RequestDiagnosticsString
Cache de URIs de documentos para menor latência de leitura
Armazene em cache URIs de documentos sempre que possível para obter o melhor desempenho de leitura. Você precisa definir a lógica para armazenar em cache o ID do recurso ao criar um recurso. As pesquisas baseadas em IDs de recursos são mais rápidas do que as pesquisas baseadas em nomes, portanto, armazenar esses valores em cache melhora o desempenho.
Aumentar o número de threads/tarefas
Consulte Aumentar o número de threads/tarefas na seção de rede deste artigo.
Operações de consulta
Para operações de consulta, consulte as dicas de desempenho para consultas.
Política de indexação
Excluir os caminhos não utilizados da indexação para assegurar escritas mais rápidas
A política de indexação do Azure Cosmos DB também permite especificar quais caminhos de documento devem ser incluídos ou excluídos da indexação usando caminhos de indexação (IndexingPolicy.IncludedPaths e IndexingPolicy.ExcludedPaths). Os caminhos de indexação podem melhorar o desempenho de gravação e reduzir o armazenamento de índice para cenários nos quais os padrões de consulta são conhecidos de antemão. Isso ocorre porque os custos de indexação se correlacionam diretamente com o número de caminhos exclusivos indexados. Por exemplo, este código mostra como excluir uma seção inteira dos documentos (uma subárvore) da indexação usando o curinga "*":
var collection = new DocumentCollection { Id = "excludedPathCollection" };
collection.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
collection.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/nonIndexedContent/*");
collection = await client.CreateDocumentCollectionAsync(UriFactory.CreateDatabaseUri("db"), collection);
Para obter mais informações, consulte Políticas de indexação do Azure Cosmos DB.
Débito
Meça e ajuste para menor uso de Unidades de Solicitação/segundo
O Azure Cosmos DB oferece um conjunto avançado de operações de banco de dados. Essas operações incluem consultas relacionais e hierárquicas com UDFs, procedimentos armazenados e gatilhos, todos operando nos documentos dentro de uma coleção de banco de dados. O custo associado a cada uma dessas operações varia dependendo da CPU, E/S e memória necessária para concluir a operação. Em vez de pensar nos recursos de hardware e na sua gestão, pode pensar numa Unidade de Pedido (RU) como medida única para os recursos necessários para executar várias operações de base de dados e realizar um pedido de aplicação.
A taxa de transferência é provisionada com base no número de Unidades de Solicitação definidas para cada contêiner. O consumo unitário de solicitação é avaliado como uma taxa por segundo. Os aplicativos que excedem a taxa de Unidade de Solicitação provisionada para seu contêiner são limitados até que a taxa caia abaixo do nível provisionado para o contêiner. Se seu aplicativo exigir um nível mais alto de taxa de transferência, você poderá aumentar sua taxa de transferência provisionando Unidades de Solicitação adicionais.
A complexidade de uma consulta afeta a quantidade de Unidades de Pedido consumidas numa operação. O número de predicados, a natureza dos predicados, o número de UDFs e o tamanho do conjunto de dados de origem influenciam o custo das operações de consulta.
Para medir a sobrecarga de qualquer operação (criar, atualizar ou excluir), inspecione o cabeçalho x-ms-request-charge (ou a propriedade equivalente RequestCharge no ResourceResponse\<T> SDK do FeedResponse\<T> .NET) para medir o número de Unidades de Solicitação consumidas pelas operações:
// Measure the performance (Request Units) of writes
ResourceResponse<Document> response = await client.CreateDocumentAsync(collectionSelfLink, myDocument);
Console.WriteLine("Insert of document consumed {0} request units", response.RequestCharge);
// Measure the performance (Request Units) of queries
IDocumentQuery<dynamic> queryable = client.CreateDocumentQuery(collectionSelfLink, queryString).AsDocumentQuery();
while (queryable.HasMoreResults)
{
FeedResponse<dynamic> queryResponse = await queryable.ExecuteNextAsync<dynamic>();
Console.WriteLine("Query batch consumed {0} request units", queryResponse.RequestCharge);
}
A cobrança de solicitação retornada neste cabeçalho é uma fração da taxa de transferência provisionada (ou seja, 2.000 RUs/segundo). Por exemplo, se a consulta anterior retornar 1.000 documentos de 1 KB, o custo da operação será 1.000. Assim, dentro de um segundo, o servidor atende apenas duas dessas solicitações antes de limitar as solicitações posteriores. Para obter mais informações, consulte Unidades de solicitação e a calculadora de unidade de solicitação.
Lidar com limitação de taxa / taxa de solicitação muito grande
Quando um cliente tenta exceder a taxa de transferência reservada para uma conta, não há degradação de desempenho no servidor e nenhum uso da capacidade de taxa de transferência além do nível reservado. O servidor terminará preventivamente a solicitação com RequestRateTooLarge (código de status HTTP 429). Ele retornará um cabeçalho x-ms-retry-after-ms que indica a quantidade de tempo, em milissegundos, que o usuário deve aguardar antes de tentar a solicitação novamente.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Todos os SDKs capturam implicitamente essa resposta, respeitam o cabeçalho retry-after especificado pelo servidor e tentam novamente a solicitação. A menos que sua conta esteja sendo acessada simultaneamente por vários clientes, a próxima tentativa será bem-sucedida.
Se você tiver mais de um cliente operando cumulativamente acima da taxa de solicitação, a contagem de tentativas padrão atualmente definida como 9 internamente pelo cliente pode não ser suficiente. Nesse caso, o cliente lança um DocumentClientException com o código de status 429 para o aplicativo.
Você pode alterar a contagem de repetições padrão definindo o RetryOptionsConnectionPolicy na instância. Por padrão, o DocumentClientException com o código de status 429 é retornado após um tempo de espera cumulativo de 30 segundos se a solicitação continuar a operar acima da taxa de solicitação. Esse erro retorna mesmo quando a contagem de tentativas atual é menor que a contagem máxima de tentativas, quer o valor atual seja o padrão de 9 ou um valor definido pelo usuário.
O comportamento de repetição automatizada ajuda a melhorar a resiliência e a usabilidade para a maioria dos aplicativos. Mas pode não ser o melhor comportamento quando você está fazendo benchmarks de desempenho, especialmente quando você está medindo a latência. A latência observada pelo cliente aumentará se o experimento atingir o acelerador do servidor e fizer com que o SDK do cliente tente novamente. Para evitar picos de latência durante experimentos de desempenho, meça a carga retornada por cada operação e verifique se as solicitações estão operando abaixo da taxa de solicitação reservada. Para obter mais informações, consulte Unidades de solicitação.
Para maior taxa de transferência, projete para documentos menores
A taxa de solicitação (ou seja, o custo de processamento da solicitação) de uma determinada operação está diretamente correlacionada ao tamanho do documento. As operações em documentos grandes custam mais do que as operações em documentos pequenos.
Próximos passos
Para obter um aplicativo de exemplo usado para avaliar o Azure Cosmos DB para cenários de alto desempenho em algumas máquinas cliente, consulte Testes de desempenho e dimensionamento com o Azure Cosmos DB.
Para saber mais sobre como projetar seu aplicativo para dimensionamento e alto desempenho, consulte Particionamento e dimensionamento no Azure Cosmos DB.