Fluxo de dados de mapeamento no Azure Data Factory
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
O que são fluxos de dados de mapeamento?
Os fluxos de dados de mapeamento são transformações de dados projetadas visualmente no Azure Data Factory. Os fluxos de dados permitem que os engenheiros de dados desenvolvam lógica de transformação de dados sem escrever código. Os fluxos de dados resultantes são executados como atividades dentro dos pipelines do Azure Data Factory que usam clusters Apache Spark escalonados. As atividades de fluxo de dados podem ser operacionalizadas usando os recursos existentes de agendamento, controle, fluxo e monitoramento do Azure Data Factory.
O mapeamento de fluxos de dados fornece uma experiência totalmente visual, sem necessidade de codificação. Seus fluxos de dados são executados em clusters de execução gerenciados pelo ADF para processamento de dados escalonado. O Azure Data Factory lida com toda a tradução de código, otimização de caminho e execução de seus trabalhos de fluxo de dados.
Introdução
Os fluxos de dados são criados a partir do painel de recursos de fábrica, como pipelines e conjuntos de dados. Para criar um fluxo de dados, selecione o sinal de adição ao lado de Recursos de fábrica e, em seguida, selecione Fluxo de dados.
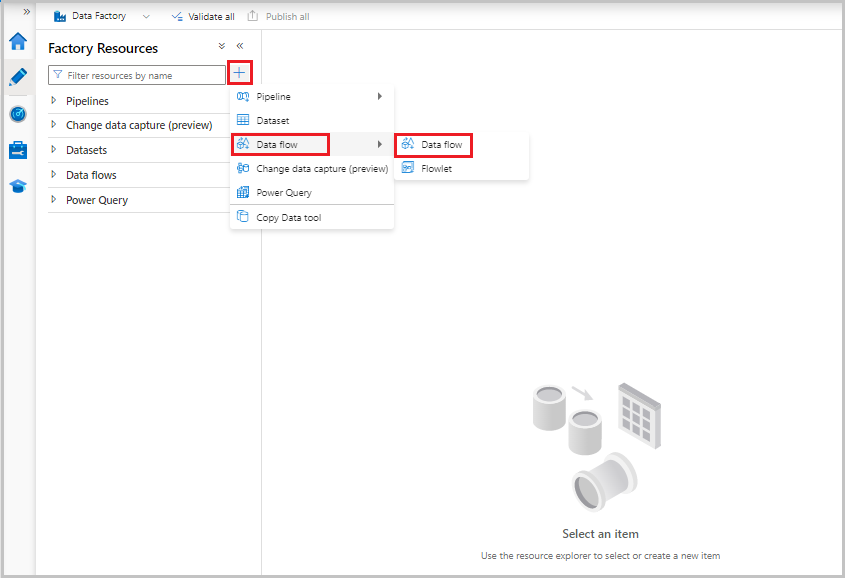 Essa ação leva você para a tela de fluxo de dados, onde você pode criar sua lógica de transformação. Selecione Adicionar fonte para começar a configurar sua transformação de origem. Para obter mais informações, consulte Transformação de origem.
Essa ação leva você para a tela de fluxo de dados, onde você pode criar sua lógica de transformação. Selecione Adicionar fonte para começar a configurar sua transformação de origem. Para obter mais informações, consulte Transformação de origem.
Criação de fluxos de dados
O mapeamento do fluxo de dados tem uma tela de criação exclusiva projetada para facilitar a lógica de transformação da construção. A tela de fluxo de dados é separada em três partes: a barra superior, o gráfico e o painel de configuração.
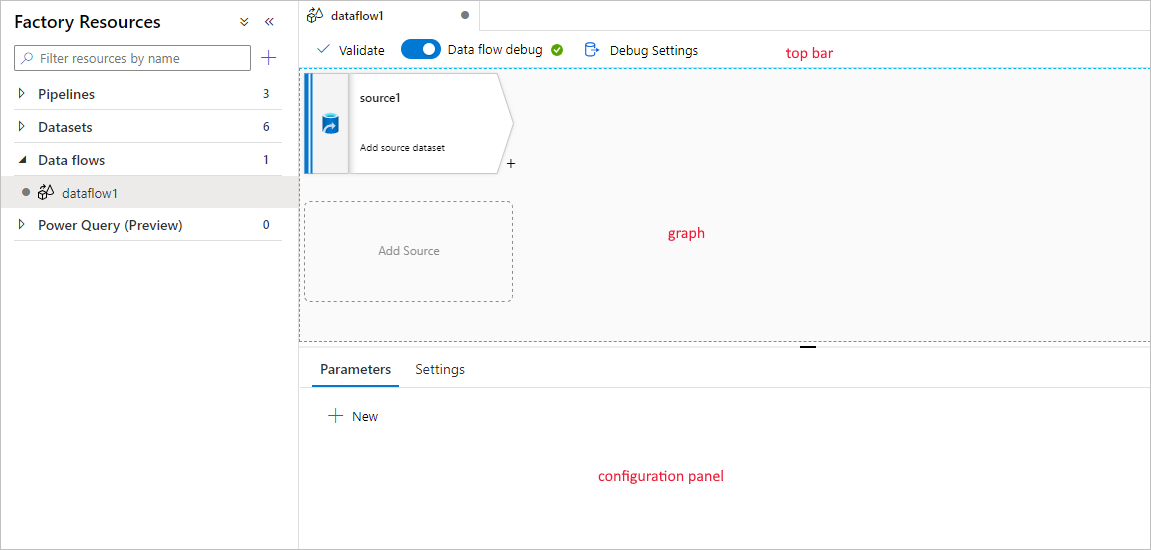
Gráfico
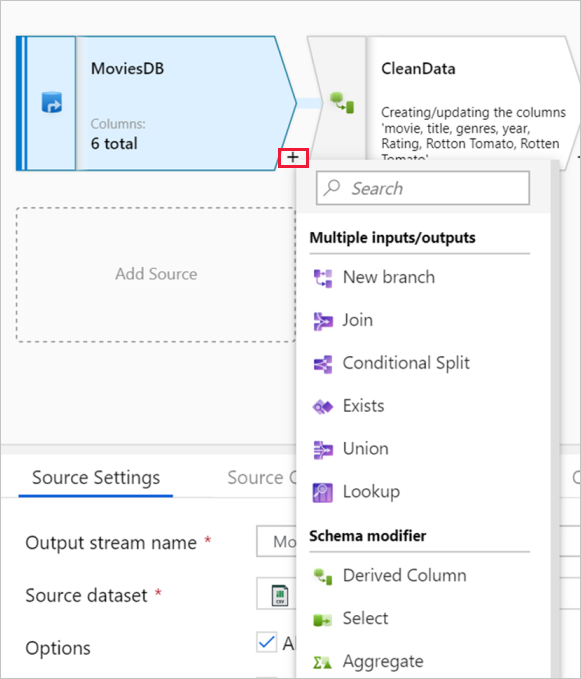
O gráfico exibe o fluxo de transformação. Ele mostra a linhagem de dados de origem à medida que flui para um ou mais coletores. Para adicionar uma nova fonte, selecione Adicionar fonte. Para adicionar uma nova transformação, selecione o sinal de adição no canto inferior direito de uma transformação existente. Saiba mais sobre como gerenciar o gráfico de fluxo de dados.
Painel de configuração
O painel de configuração mostra as configurações específicas para a transformação selecionada no momento. Se nenhuma transformação for selecionada, ela mostrará o fluxo de dados. Na configuração geral do fluxo de dados, você pode adicionar parâmetros por meio da guia Parâmetros . Para obter mais informações, consulte Mapeando parâmetros de fluxo de dados.
Cada transformação contém pelo menos quatro guias de configuração.
Configurações de transformação
A primeira guia no painel de configuração de cada transformação contém as configurações específicas dessa transformação. Para obter mais informações, consulte a página de documentação dessa transformação.
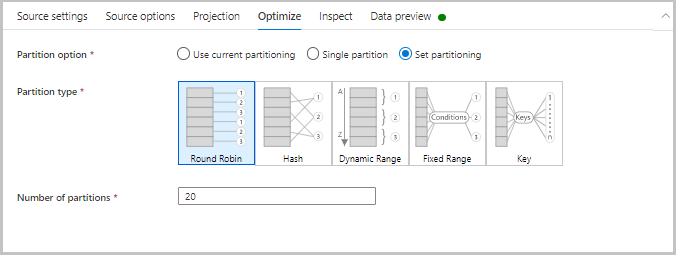
Otimização
A guia Otimizar contém configurações para configurar esquemas de particionamento. Para saber mais sobre como otimizar seus fluxos de dados, consulte o guia de desempenho do fluxo de dados de mapeamento.
Inspecionar
A guia Inspecionar fornece uma exibição dos metadados do fluxo de dados que você está transformando. Você pode ver as contagens de colunas, as colunas alteradas, as colunas adicionadas, os tipos de dados, a ordem das colunas e as referências de coluna. Inspecionar é uma exibição somente leitura de seus metadados. Não é necessário ter o modo de depuração ativado para ver os metadados no painel Inspecionar .
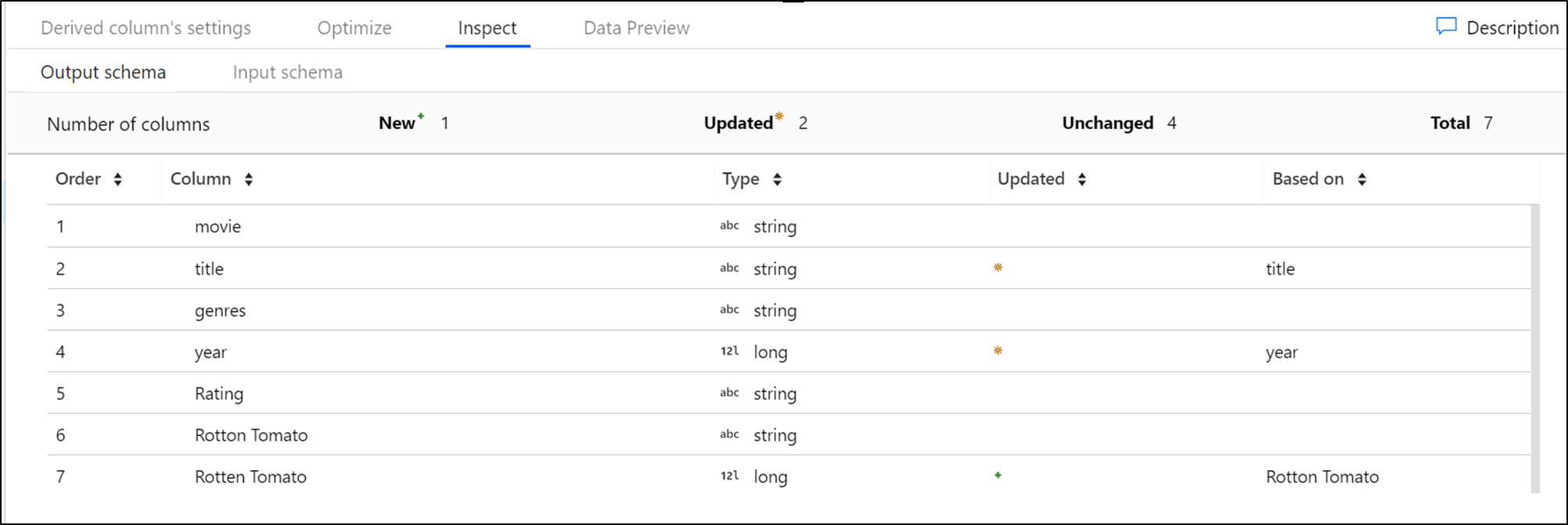
À medida que você altera a forma dos dados por meio de transformações, você verá o fluxo de alterações de metadados no painel Inspecionar . Se não houver um esquema definido na transformação de origem, os metadados não ficarão visíveis no painel Inspecionar . A falta de metadados é comum em cenários de desvio de esquema.
Pré-visualização de dados
Se o modo de depuração estiver ativado, a guia Visualização de dados fornecerá um instantâneo interativo dos dados em cada transformação. Para obter mais informações, consulte Visualização de dados no modo de depuração.
Barra superior
A barra superior contém ações que afetam todo o fluxo de dados, como salvar e validar. Você também pode visualizar o código JSON subjacente e o script de fluxo de dados da sua lógica de transformação. Para obter mais informações, saiba mais sobre o script de fluxo de dados.
Transformações disponíveis
Veja a visão geral da transformação do fluxo de dados de mapeamento para obter uma lista das transformações disponíveis.
Tipos de dados de fluxo de dados
- matriz
- binário
- boolean
- complexo
- decimal (inclui precisão)
- data
- flutuante
- integer
- long
- map
- curtas
- string
- carimbo de data/hora
Atividade de fluxo de dados
Os fluxos de dados de mapeamento são operacionalizados dentro de pipelines do ADF usando a atividade de fluxo de dados. Tudo o que um usuário precisa fazer é especificar qual tempo de execução de integração usar e passar valores de parâmetro. Para obter mais informações, saiba mais sobre o tempo de execução de integração do Azure.
Modo de depuração
O modo de depuração permite que você veja interativamente os resultados de cada etapa de transformação enquanto cria e depura seus fluxos de dados. A sessão de depuração pode ser usada tanto na criação da lógica de fluxo de dados quanto na execução da depuração de pipeline com atividades de fluxo de dados. Para saber mais, consulte a documentação do modo de depuração.
Monitorizar fluxos de dados
O fluxo de dados de mapeamento integra-se com as capacidades de monitorização existentes do Azure Data Factory. Para saber como entender a saída de monitoramento de fluxo de dados, consulte Monitoramento de fluxos de dados de mapeamento.
A equipe do Azure Data Factory criou um guia de ajuste de desempenho para ajudá-lo a otimizar o tempo de execução de seus fluxos de dados depois de criar sua lógica de negócios.
Regiões disponíveis
Os fluxos de dados de mapeamento estão disponíveis nas seguintes regiões no ADF:
| Região do Azure | Fluxos de dados no ADF |
|---|---|
| Austrália Central | |
| Austrália Central 2 | |
| Leste da Austrália | ✓ |
| Austrália Sudeste | ✓ |
| Sul do Brasil | ✓ |
| Canadá Central | ✓ |
| Índia Central | ✓ |
| E.U.A. Central | ✓ |
| Norte da China | |
| China Leste 2 | |
| Chinha - Não Regional | |
| Norte da China | ✓ |
| Norte da China 2 | ✓ |
| Norte da China 3 | ✓ |
| Ásia Leste | ✓ |
| E.U.A. Leste | ✓ |
| E.U.A. Leste 2 | ✓ |
| França Central | ✓ |
| Sul de França | |
| Alemanha Central (Soberana) | |
| Alemanha - Não Regional (Soberana) | |
| Norte da Alemanha (Pública) | |
| Nordeste da Alemanha (Soberana) | |
| Norte da Alemanha (Pública) | ✓ |
| Leste do Japão | ✓ |
| Oeste do Japão | ✓ |
| Coreia do Sul Central | ✓ |
| Sul da Coreia do Sul | |
| E.U.A. Centro-Norte | ✓ |
| Europa do Norte | ✓ |
| Leste da Noruega | ✓ |
| Oeste da Noruega | |
| Norte da África do Sul | ✓ |
| Oeste da África do Sul | |
| E.U.A. Centro-Sul | |
| Sul da Índia | ✓ |
| Sudeste Asiático | ✓ |
| Norte da Suíça | ✓ |
| Oeste da Suíça | |
| E.A.U. Central | |
| Norte dos E.A.U. | ✓ |
| Sul do Reino Unido | ✓ |
| Oeste do Reino Unido | |
| US DoD - Centro | |
| US DoD - Leste | |
| US Gov - Arizona | ✓ |
| US Gov - Não Regional | |
| US Gov - Texas | |
| US Gov - Virginia | ✓ |
| E.U.A. Centro-Oeste | |
| Europa Ocidental | ✓ |
| Oeste da Índia | ✓ |
| E.U.A. Oeste | ✓ |
| E.U.A. Oeste 2 | ✓ |
| EUA Oeste 3 | ✓ |
Conteúdos relacionados
- Saiba como criar uma transformação de origem.
- Saiba como criar seus fluxos de dados no modo de depuração.