Tutorial da extensão VSCode para Databricks: Executar Python em um cluster e como um trabalho
Este tutorial demonstra como começar com a extensão Databricks para Visual Studio Code executando um arquivo de código Python básico em um cluster do Azure Databricks e como um trabalho do Azure Databricks executado em seu espaço de trabalho remoto. Consulte O que é a extensão Databricks para Visual Studio Code?.
O que você vai fazer neste tutorial?
Neste tutorial prático, você faz o seguinte:
- Crie um cluster do Azure Databricks para executar seu código Python local.
- Instale o Visual Studio Code e a extensão Databricks para Visual Studio Code.
- Configure a autenticação do Azure Databricks e configure a extensão Databricks para Visual Studio Code com essas informações.
- Configure a extensão Databricks para Visual Studio Code com informações sobre seu cluster remoto e tenha a extensão para iniciar o cluster.
- Configure a extensão Databricks para Visual Studio Code com o local em seu espaço de trabalho remoto do Azure Databricks para carregar seu código Python local e fazer com que a extensão comece a ouvir eventos de carregamento de código.
- Escreva e salve algum código Python, que dispara um evento de upload de código.
- Use a extensão Databricks para Visual Studio Code para executar o código carregado em seu cluster remoto e, em seguida, para executá-lo com seu cluster como uma execução de trabalho remoto.
Este tutorial demonstra apenas como executar um arquivo de código Python e demonstra apenas como configurar a autenticação de usuário para máquina (U2M) OAuth. Para saber como depurar arquivos de código Python, executar e depurar blocos de anotações e configurar outros tipos de autenticação, consulte Próximas etapas.
Etapa 1: Criar um cluster
Se você já tiver um cluster remoto do Azure Databricks que deseja usar, anote o nome do cluster e pule para a Etapa 2 para instalar o Visual Studio Code. Para exibir os clusters disponíveis, na barra lateral do espaço de trabalho, clique em Computar.
O Databricks recomenda que você crie um cluster de computação pessoal para começar rapidamente. Para criar esse cluster, faça o seguinte:
- No espaço de trabalho do Azure Databricks, na barra lateral, clique em Computação.
- Clique em Criar com computação pessoal.
- Clique em Criar computação.
- Anote o nome do cluster, pois você precisará dele mais tarde na Etapa 5 quando adicionar informações de cluster à extensão.
Etapa 2: Instalar o Visual Studio Code
Para instalar o Visual Studio Code, siga as instruções para macOS, Linux ou Windows.
Se você já tiver o Visual Studio Code instalado, verifique se é a versão 1.69.1 ou superior. Para fazer isso, no Visual Studio Code, no menu principal, clique em Code > About Visual Studio Code for macOS ou Help > About for Linux or Windows.
Para atualizar o Visual Studio Code, no menu principal, clique em Verificação de código > para atualizações para macOS ou Ajuda > para verificar atualizações para Linux ou Windows.
Etapa 3: Instalar a extensão Databricks

- Na barra lateral do Visual Studio Code, clique no ícone Extensões .
- Em Extensões de Pesquisa no Marketplace, introduza
Databricks. - Na entrada rotulada Databricks com a legenda IDE support for Databricks by Databricks, clique em Instalar.
Etapa 4: Configurar a autenticação do Azure Databricks
Nesta etapa, você habilita a autenticação entre a extensão Databricks para Visual Studio Code e seu espaço de trabalho remoto do Azure Databricks, da seguinte maneira:
- No Visual Studio Code, abra uma pasta vazia em sua máquina de desenvolvimento local que você usará para conter o código Python que você criará e executará posteriormente na Etapa 7. Para fazer isso, no menu principal, clique em Arquivo > Abrir pasta e siga as instruções na tela.
- Na barra lateral do Visual Studio Code, clique no ícone do logotipo do Databricks .
- No painel Configuração, clique em Configurar Databricks.
- Na Paleta de comandos, para Databricks Host, insira sua URL por espaço de trabalho, por exemplo
https://adb-1234567890123456.7.azuredatabricks.net. Em seguida, prima Enter. - Selecione OAuth (usuário para máquina).
- Conclua as instruções na tela em seu navegador da Web para concluir a autenticação com o Azure Databricks. Se solicitado, permita o acesso a todas as APIs .
Etapa 5: Adicionar informações de cluster à extensão Databricks e iniciar o cluster
- Com o painel Configuração já aberto na etapa anterior em que você configurou a autenticação, ao lado de Cluster, clique no ícone de engrenagem (Configurar cluster).
- Na Paleta de Comandos, selecione o nome do cluster que você criou na Etapa 1.
- Inicie o cluster, se ainda não tiver sido iniciado: ao lado de Cluster, se o ícone de reprodução (Start Cluster) estiver visível, clique nele.
Etapa 6: Adicione o local de upload de código à extensão Databricks e inicie o ouvinte de upload
- Com o painel Configuração já aberto na etapa anterior em que você adicionou informações de cluster, ao lado de Destino de sincronização, clique no ícone de engrenagem (Configurar destino de sincronização).
- Na Paleta de comandos, selecione Criar novo destino de sincronização.
- Pressione
Enterpara confirmar o nome do diretório de carregamento remoto gerado. - Inicie o ouvinte de upload, se ainda não tiver começado: ao lado de Sync Destination, se o ícone de círculo de seta (Iniciar sincronização) estiver visível, clique nele.

Etapa 7: Criar e executar código Python
Crie um arquivo de código Python local: na barra lateral, clique no ícone da pasta (Explorer).
No menu principal, clique em Arquivo > Novo Arquivo. Nomeie o arquivo demo.py e salve-o na raiz do projeto.
Adicione o seguinte código ao ficheiro e, em seguida, guarde-o. Este código cria e exibe o conteúdo de um DataFrame PySpark básico:
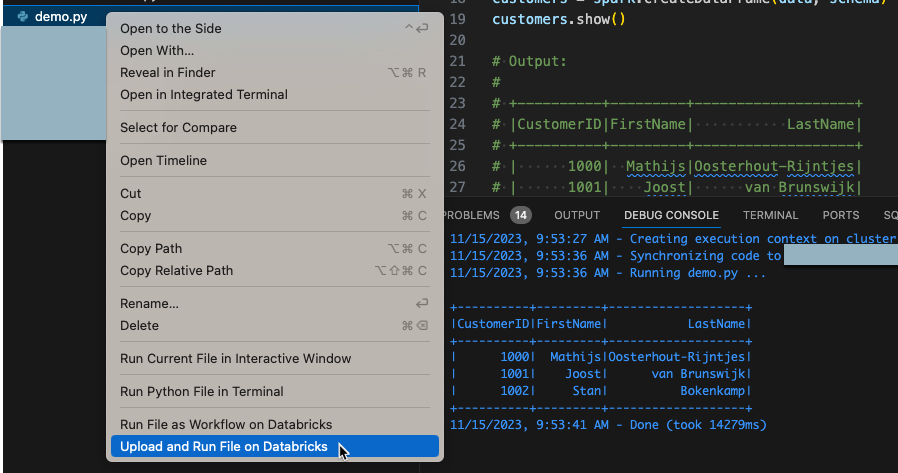
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show() # Output: # # +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Na vista do Explorer, clique com o botão direito do rato no
demo.pyficheiro e, em seguida, clique em Carregar e Executar Ficheiro no Databricks. A saída aparece no painel Debug Console .
Etapa 8: Executar o código como um trabalho
Na etapa anterior, você executou seu código Python diretamente no cluster remoto. Nesta etapa, você inicia um fluxo de trabalho que usa o cluster para executar o código como um trabalho do Azure Databricks. Consulte O que é o Azure Databricks Jobs?.
Para executar esse código como um trabalho, no modo de exibição Explorer, clique com o botão direito do mouse no demo.py arquivo e clique em Executar Arquivo como Fluxo de Trabalho no Databricks. A saída aparece em uma guia separada do editor ao lado do editor de demo.py arquivos.

Você chegou ao final deste tutorial.
Próximos passos
Agora que você usou com êxito a extensão Databricks para Visual Studio Code para carregar um arquivo Python local e executá-lo remotamente, saiba mais sobre como usar a extensão:
- Saiba mais sobre outras maneiras de configurar a autenticação para a extensão. Consulte Configuração de autenticação para a extensão Databricks para VS Code.
- Saiba como habilitar o preenchimento de código do PySpark e do Databricks Utilities, executar ou depurar código Python com o Databricks Connect, executar um arquivo ou um bloco de anotações como um trabalho do Azure Databricks, executar testes com
pytest, usar arquivos de definições de variáveis de ambiente, criar configurações de execução personalizadas e muito mais. Consulte Tarefas de desenvolvimento para a extensão Databricks para Visual Studio Code.