Introdução ao Databricks Lakehouse Monitoring
Importante
Esta funcionalidade está em Pré-visualização Pública.
Este artigo descreve o Databricks Lakehouse Monitoring. Ele cobre os benefícios de monitorar seus dados e fornece uma visão geral dos componentes e do uso do Databricks Lakehouse Monitoring.
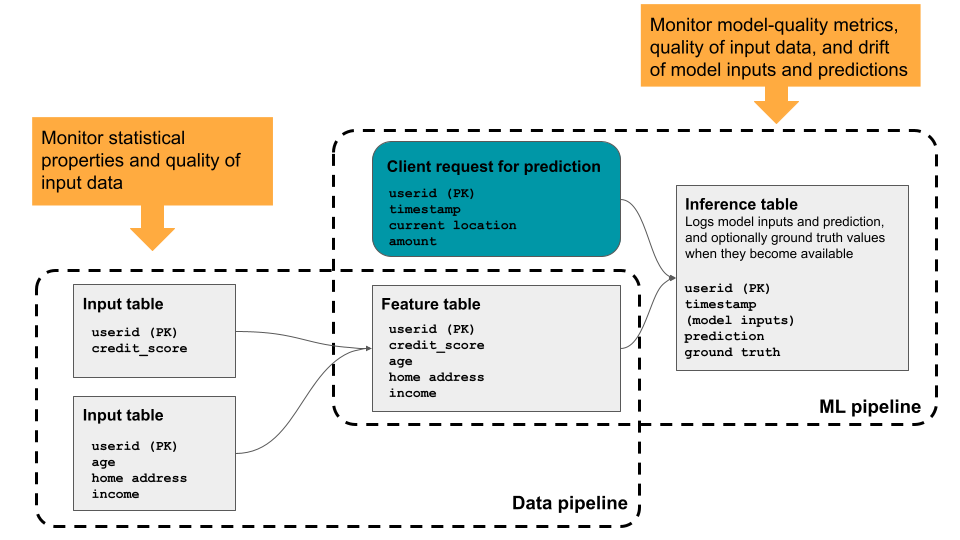
O Databricks Lakehouse Monitoring permite monitorar as propriedades estatísticas e a qualidade dos dados em todas as tabelas da sua conta. Você também pode usá-lo para acompanhar o desempenho de modelos de aprendizado de máquina e pontos de extremidade de serviço de modelo monitorando tabelas de inferência que contêm entradas e previsões de modelo. O diagrama mostra o fluxo de dados através de dados e pipelines de ML no Databricks e como você pode usar o monitoramento para rastrear continuamente a qualidade dos dados e o desempenho do modelo.
Por que usar o Databricks Lakehouse Monitoring?
Para obter informações úteis a partir dos seus dados, deve ter confiança na qualidade dos seus dados. O monitoramento de seus dados fornece medidas quantitativas que ajudam você a rastrear e confirmar a qualidade e a consistência de seus dados ao longo do tempo. Quando você deteta alterações na distribuição de dados da tabela ou no desempenho do modelo correspondente, as tabelas criadas pelo Databricks Lakehouse Monitoring podem capturar e alertá-lo sobre a alteração e podem ajudá-lo a identificar a causa.
O Databricks Lakehouse Monitoring ajuda você a responder a perguntas como as seguintes:
- Como é a integridade dos dados e como ela muda ao longo do tempo? Por exemplo, qual é a fração de valores nulos ou zero nos dados atuais e ela aumentou?
- Como é a distribuição estatística dos dados e como ela muda ao longo do tempo? Por exemplo, o que é o percentil 90 de uma coluna numérica? Ou, o que é a distribuição de valores em uma coluna categórica e como ela difere de ontem?
- Existe desvio entre os dados atuais e uma linha de base conhecida, ou entre janelas de tempo sucessivas dos dados?
- Como é a distribuição estatística ou desvio de um subconjunto ou fatia dos dados?
- Como as entradas e previsões do modelo de ML estão mudando ao longo do tempo?
- Qual é a tendência de desempenho do modelo ao longo do tempo? A versão A do modelo tem um desempenho melhor do que a versão B?
Além disso, o Databricks Lakehouse Monitoring permite controlar a granularidade do tempo das observações e configurar métricas personalizadas.
Requisitos
O seguinte é necessário para usar o Databricks Lakehouse Monitoring:
- Seu espaço de trabalho deve estar habilitado para o Unity Catalog e você deve ter acesso ao Databricks SQL.
- Somente tabelas Delta, incluindo tabelas gerenciadas, tabelas externas, exibições, exibições materializadas e tabelas de streaming são suportadas para monitoramento. Os monitores criados sobre visualizações materializadas e tabelas de streaming não suportam processamento incremental.
- Nem todas as regiões são suportadas. Para obter suporte regional, consulte Regiões do Azure Databricks.
Nota
O Databricks Lakehouse Monitoring usa computação sem servidor para fluxos de trabalho. Para obter informações sobre como controlar as despesas do Lakehouse Monitoring, consulte Exibir despesas do Lakehouse Monitoring.
Como funciona o monitoramento Lakehouse no Databricks
Para monitorar uma tabela no Databricks, crie um monitor anexado à tabela. Para monitorar o desempenho de um modelo de aprendizado de máquina, anexe o monitor a uma tabela de inferência que contém as entradas do modelo e as previsões correspondentes.
O Databricks Lakehouse Monitoring fornece os seguintes tipos de análise: séries temporais, instantâneos e inferência.
| Tipo de perfil | Description |
|---|---|
| Séries cronológicas | Use para tabelas que contêm um conjunto de dados de série temporal com base em uma coluna de carimbo de data/hora. O monitoramento calcula métricas de qualidade de dados em janelas baseadas no tempo da série temporal. |
| Inferência | Use para tabelas que contêm o log de solicitações para um modelo. Cada linha é uma solicitação, com colunas para o carimbo de data/hora, as entradas do modelo, a previsão correspondente e o rótulo (opcional) de verdade básica. O monitoramento compara o desempenho do modelo e as métricas de qualidade de dados em janelas baseadas no tempo do log de solicitações. |
| Instantâneo | Use para todos os outros tipos de tabelas. O monitoramento calcula as métricas de qualidade de dados em todos os dados da tabela. A tabela completa é processada a cada atualização. |
Esta seção descreve brevemente as tabelas de entrada usadas pelo Databricks Lakehouse Monitoring e as tabelas métricas que ele produz. O diagrama mostra a relação entre as tabelas de entrada, as tabelas métricas, o monitor e o painel.
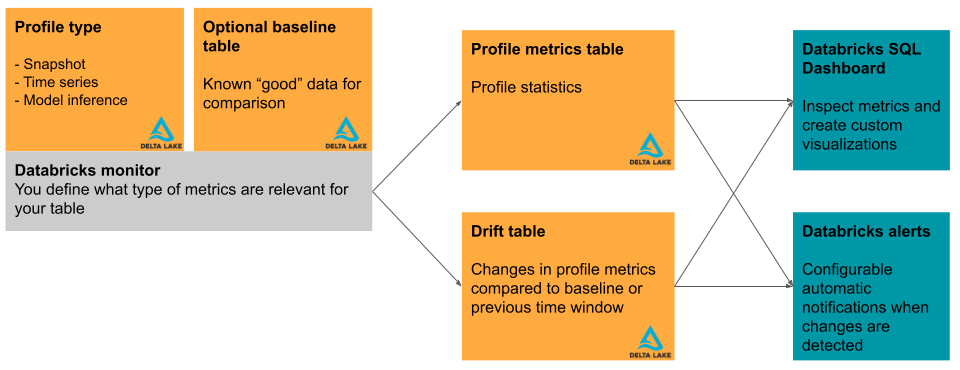
Tabela primária e tabela de linha de base
Além da tabela a ser monitorada, chamada de "tabela primária", você pode, opcionalmente, especificar uma tabela de linha de base para usar como referência para medir o desvio ou a mudança nos valores ao longo do tempo. Uma tabela de linha de base é útil quando você tem uma amostra da aparência esperada dos dados. A ideia é que o desvio seja então calculado em relação aos valores e distribuições de dados esperados.
O quadro de base deve conter um conjunto de dados que reflita a qualidade esperada dos dados de cálculo, em termos de distribuições estatísticas, distribuições de colunas individuais, valores em falta e outras características. Ele deve corresponder ao esquema da tabela monitorada. A exceção é a coluna de carimbo de data/hora para tabelas usadas com séries temporais ou perfis de inferência. Se faltarem colunas na tabela primária ou na tabela de linha de base, o monitoramento usará a heurística de melhor esforço para calcular as métricas de saída.
Para monitores que usam um perfil de instantâneo, a tabela de linha de base deve conter um instantâneo dos dados em que a distribuição representa um padrão de qualidade aceitável. Por exemplo, em dados de distribuição de notas, pode-se definir a linha de base para uma classe anterior onde as notas foram distribuídas uniformemente.
Para monitores que usam um perfil de série temporal, a tabela de linha de base deve conter dados que representam a(s) janela(s) de tempo onde as distribuições de dados representam um padrão de qualidade aceitável. Por exemplo, em dados meteorológicos, você pode definir a linha de base para uma semana, mês ou ano em que a temperatura estava próxima das temperaturas normais esperadas.
Para monitores que usam um perfil de inferência, uma boa opção para uma linha de base são os dados que foram usados para treinar ou validar o modelo que está sendo monitorado. Desta forma, os usuários podem ser alertados quando os dados se desviaram em relação ao que o modelo foi treinado e validado. Esta tabela deve conter as mesmas colunas de recursos que a tabela primária e, adicionalmente, deve ter as mesmas model_id_col que foram especificadas para o InferenceLog da tabela primária para que os dados sejam agregados de forma consistente. Idealmente, o teste ou conjunto de validação usado para avaliar o modelo deve ser usado para garantir métricas de qualidade do modelo comparáveis.
Tabelas métricas e painel
Um monitor de tabela cria duas tabelas métricas e um painel. Os valores de métricas são calculados para toda a tabela e para as janelas de tempo e subconjuntos de dados (ou "fatias") que você especifica ao criar o monitor. Além disso, para análise de inferência, as métricas são calculadas para cada ID de modelo. Para obter mais detalhes sobre as tabelas métricas, consulte Monitorar tabelas métricas.
- A tabela de métricas de perfil contém estatísticas resumidas. Consulte o esquema da tabela de métricas de perfil.
- A tabela de métricas de desvio contém estatísticas relacionadas ao desvio dos dados ao longo do tempo. Se uma tabela de linha de base for fornecida, o desvio também será monitorado em relação aos valores da linha de base. Consulte o esquema da tabela de métricas de deriva.
As tabelas métricas são tabelas Delta e são armazenadas em um esquema de catálogo Unity que você especificar. Você pode exibir essas tabelas usando a interface do usuário do Databricks, consultá-las usando o Databricks SQL e criar painéis e alertas com base nelas.
Para cada monitor, o Databricks cria automaticamente um painel para ajudá-lo a visualizar e apresentar os resultados do monitor. O painel é totalmente personalizável como qualquer outro painel legado.
Comece a usar o Lakehouse Monitoring no Databricks
Consulte os seguintes artigos para começar:
- Crie um monitor usando a interface do usuário do Databricks.
- Crie um monitor usando a API.
- Entenda as tabelas métricas de monitoramento.
- Trabalhe com o painel do monitor.
- Crie alertas SQL com base em um monitor.
- Crie métricas personalizadas.
- Monitore o modelo de servindo endpoints.
- Monitore a equidade e a parcialidade dos modelos de classificação.
- Consulte o material de referência para a API de monitoramento do Databricks Lakehouse.
- Exemplos de blocos de notas.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários