Tutorial: Implementar o Azure Databricks com um ponto final do Azure Cosmos DB
Este tutorial descreve como implementar um ambiente do Databricks injetado na VNet com um Ponto Final de Serviço ativado para o Azure Cosmos DB.
Neste tutorial, vai aprender a:
- Criar uma área de trabalho do Azure Databricks numa rede virtual
- Criar um ponto final de serviço do Azure Cosmos DB
- Criar uma conta do Azure Cosmos DB e importar dados
- Criar um cluster do Azure Databricks
- Consultar o Azure Cosmos DB a partir de um bloco de notas do Azure Databricks
Pré-requisitos
Antes de começar, faça o seguinte:
Criar uma área de trabalho do Azure Databricks numa rede virtual.
Transfira o conector spark.
Transfira dados de exemplo dos Centros Nacionais de Informação Ambiental da NOAA. Selecione um estado ou área e selecione Procurar. Na página seguinte, aceite as predefinições e selecione Procurar. Em seguida, selecione Transferência de CSV no lado esquerdo da página para transferir os resultados.
Transfira o binário pré-compilado da Ferramenta de Migração de Dados do Azure Cosmos DB.
Criar um ponto final de serviço do Azure Cosmos DB
Depois de implementar uma área de trabalho do Azure Databricks numa rede virtual, navegue para a rede virtual no portal do Azure. Repare nas sub-redes públicas e privadas que foram criadas através da implementação do Databricks.
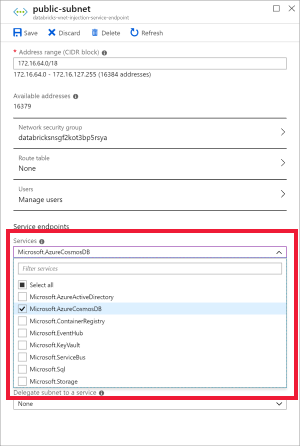
Selecione a sub-rede pública e crie um ponto final de serviço do Azure Cosmos DB. Em seguida, guarde.
Criar uma conta do Azure Cosmos DB
Abra o portal do Azure. No canto superior esquerdo do ecrã, selecione Criar um recurso > Bases de Dados > do Azure Cosmos DB.
Preencha os Detalhes da Instância no separador Noções Básicas com as seguintes definições:
Definição Valor Subscrição a sua subscrição Grupo de Recursos o seu grupo de recursos Nome da Conta db-vnet-service-endpoint API Núcleo (SQL) Localização E.U.A. Oeste Geo-Redundancy Desativar Escritas de várias regiões Ativar 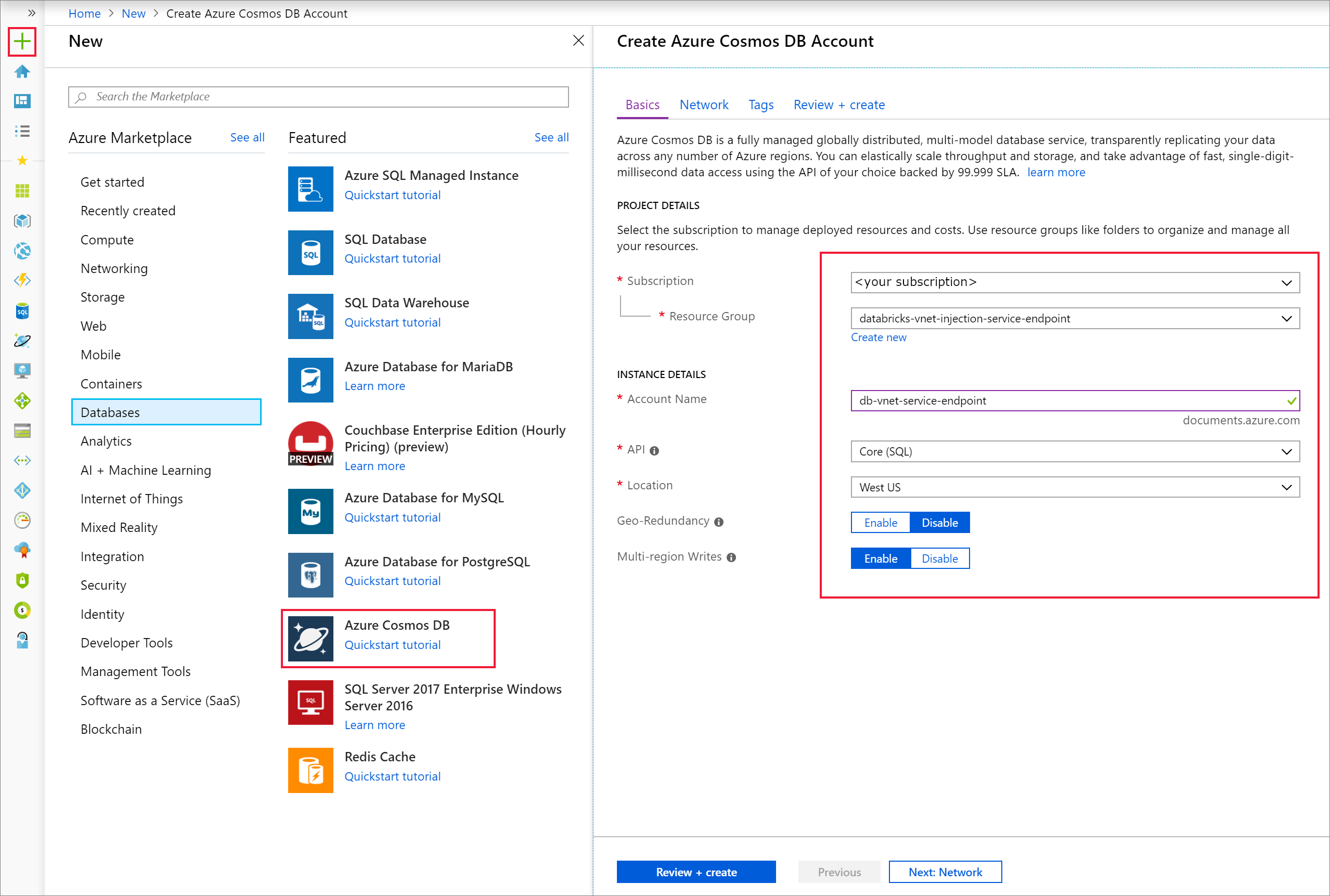
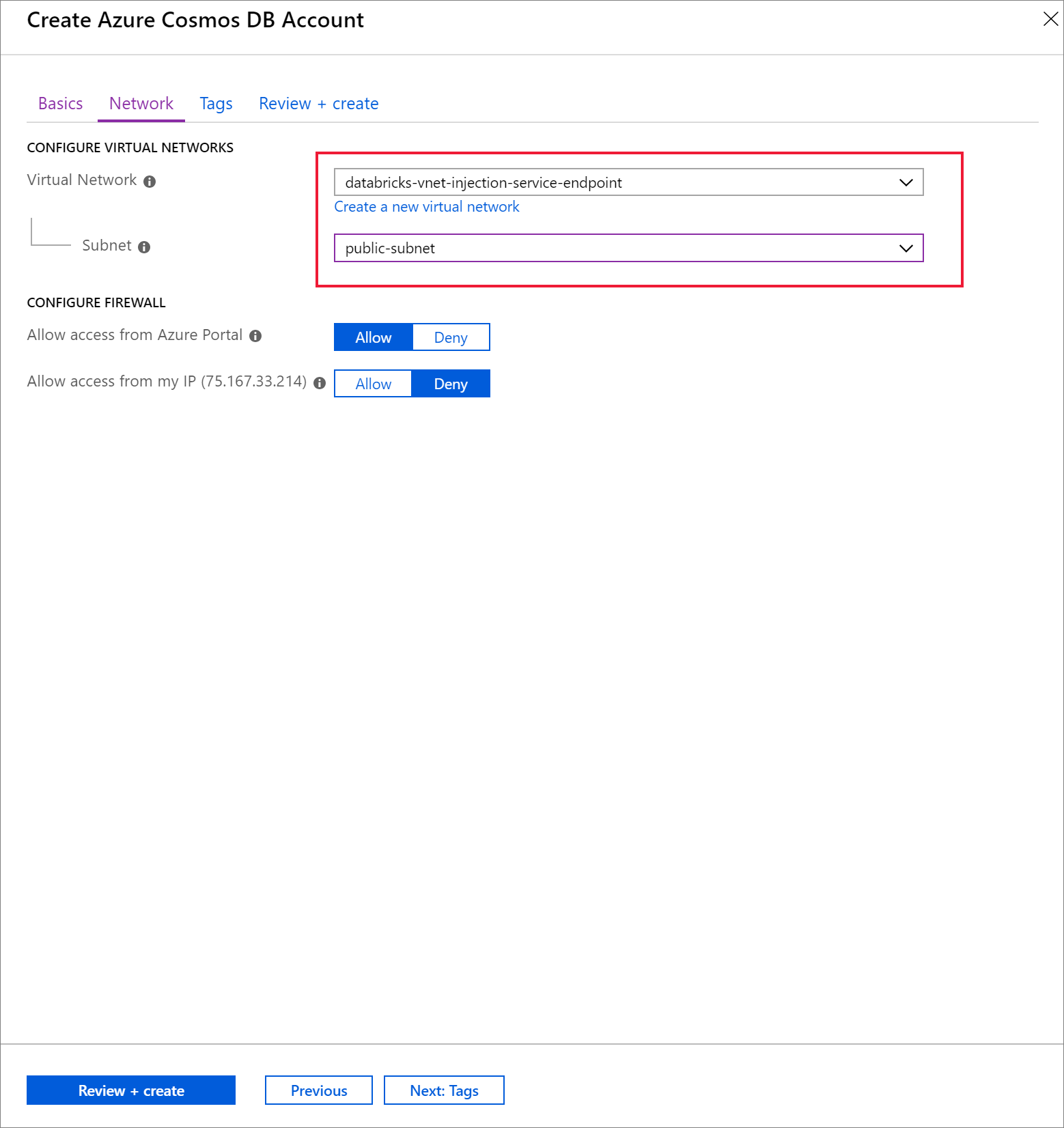
Selecione o separador Rede e configure a sua rede virtual.
a. Escolha a rede virtual que criou como pré-requisito e, em seguida, selecione public-subnet. Repare que a sub-rede privada tem a nota "O ponto final do Microsoft AzureCosmosDB" está em falta". Isto deve-se ao facto de só ter ativado o ponto final de serviço do Azure Cosmos DB na sub-rede pública.
b. Certifique-se de que tem a opção Permitir acesso a partir de portal do Azure ativada. Esta definição permite-lhe aceder à sua conta do Azure Cosmos DB a partir do portal do Azure. Se esta opção estiver definida como Negar, receberá erros ao tentar aceder à sua conta.
Nota
Não é necessário para este tutorial, mas também pode ativar Permitir acesso a partir do meu IP se quiser ter a capacidade de aceder à sua conta do Azure Cosmos DB a partir do seu computador local. Por exemplo, se estiver a ligar à sua conta com o SDK do Azure Cosmos DB, terá de ativar esta definição. Se estiver desativado, receberá erros de "Acesso Negado".
Selecione Rever + Criar e, em seguida, Criar para criar a sua conta do Azure Cosmos DB dentro da rede virtual.
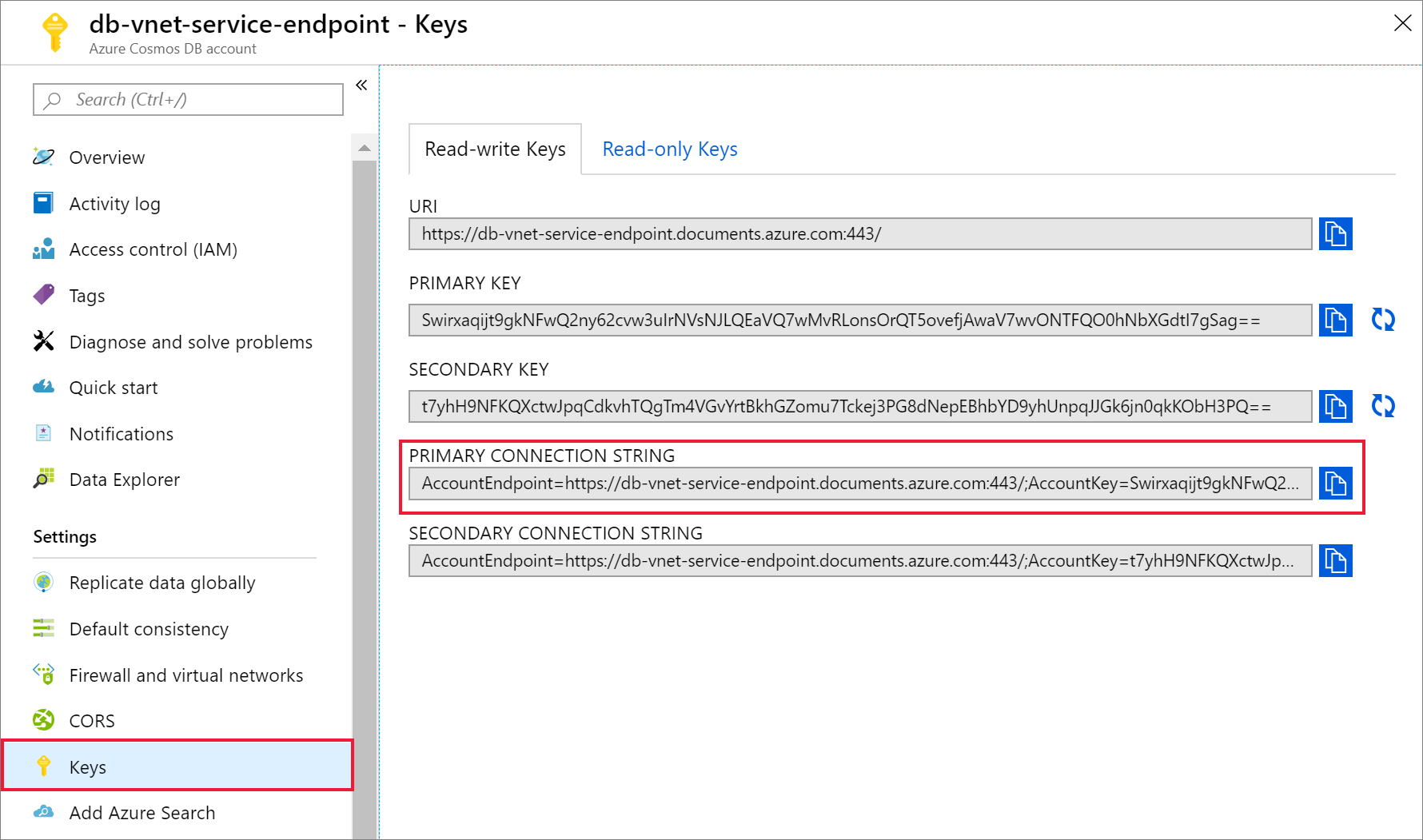
Assim que a sua conta do Azure Cosmos DB tiver sido criada, navegue para Chaves em Definições. Copie a cadeia de ligação primária e guarde-a num editor de texto para utilização posterior.
Selecione Data Explorer e Novo Contentor para adicionar uma nova base de dados e um contentor à sua conta do Azure Cosmos DB.
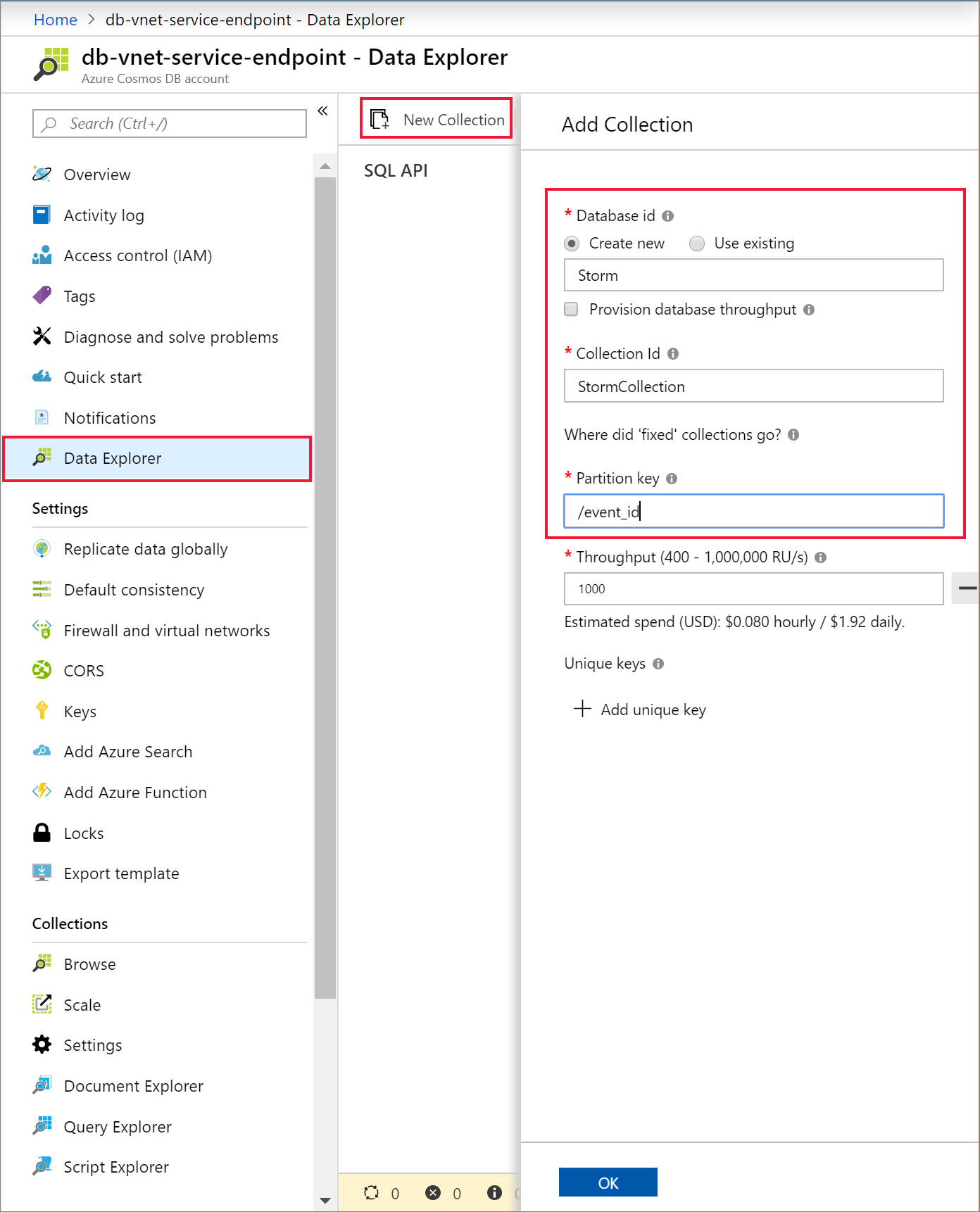
Carregar dados para o Azure Cosmos DB
Abra a versão da interface gráfica da ferramenta de migração de dados do Azure Cosmos DB,Dtui.exe.
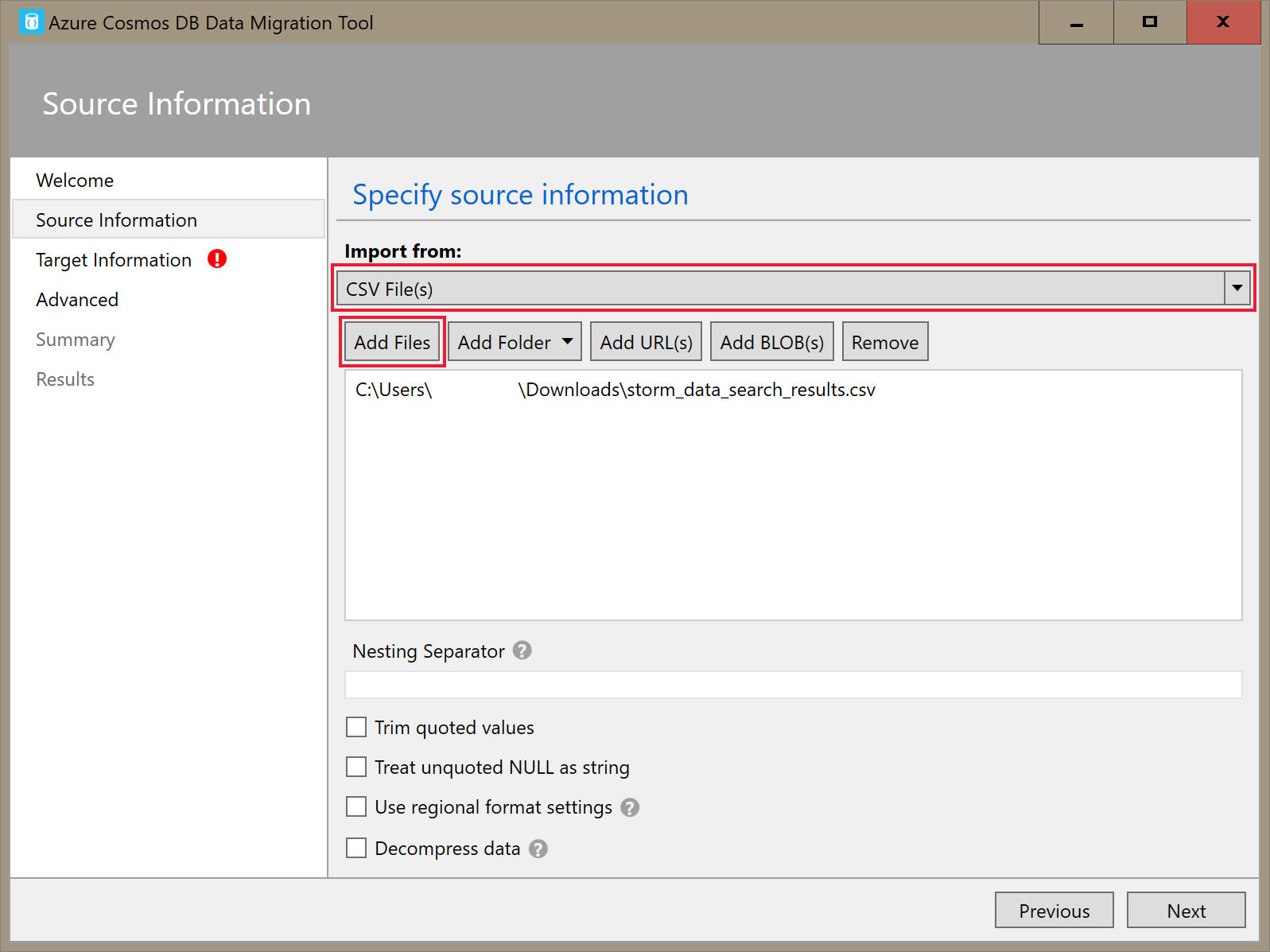
No separador Informações de Origem, selecione Ficheiro(s) CSV na lista pendente Importar a partir de . Em seguida, selecione Adicionar Ficheiros e adicione o CSV de dados do storm que transferiu como pré-requisito.
No separador Informações de Destino , introduza a cadeia de ligação. O formato da cadeia de ligação é
AccountEndpoint=<URL>;AccountKey=<key>;Database=<database>. O AccountEndpoint e AccountKey estão incluídos na cadeia de ligação primária que guardou na secção anterior. AcrescenteDatabase=<your database name>ao fim da cadeia de ligação e selecione Verificar. Em seguida, adicione o Nome do contentor e a chave de partição.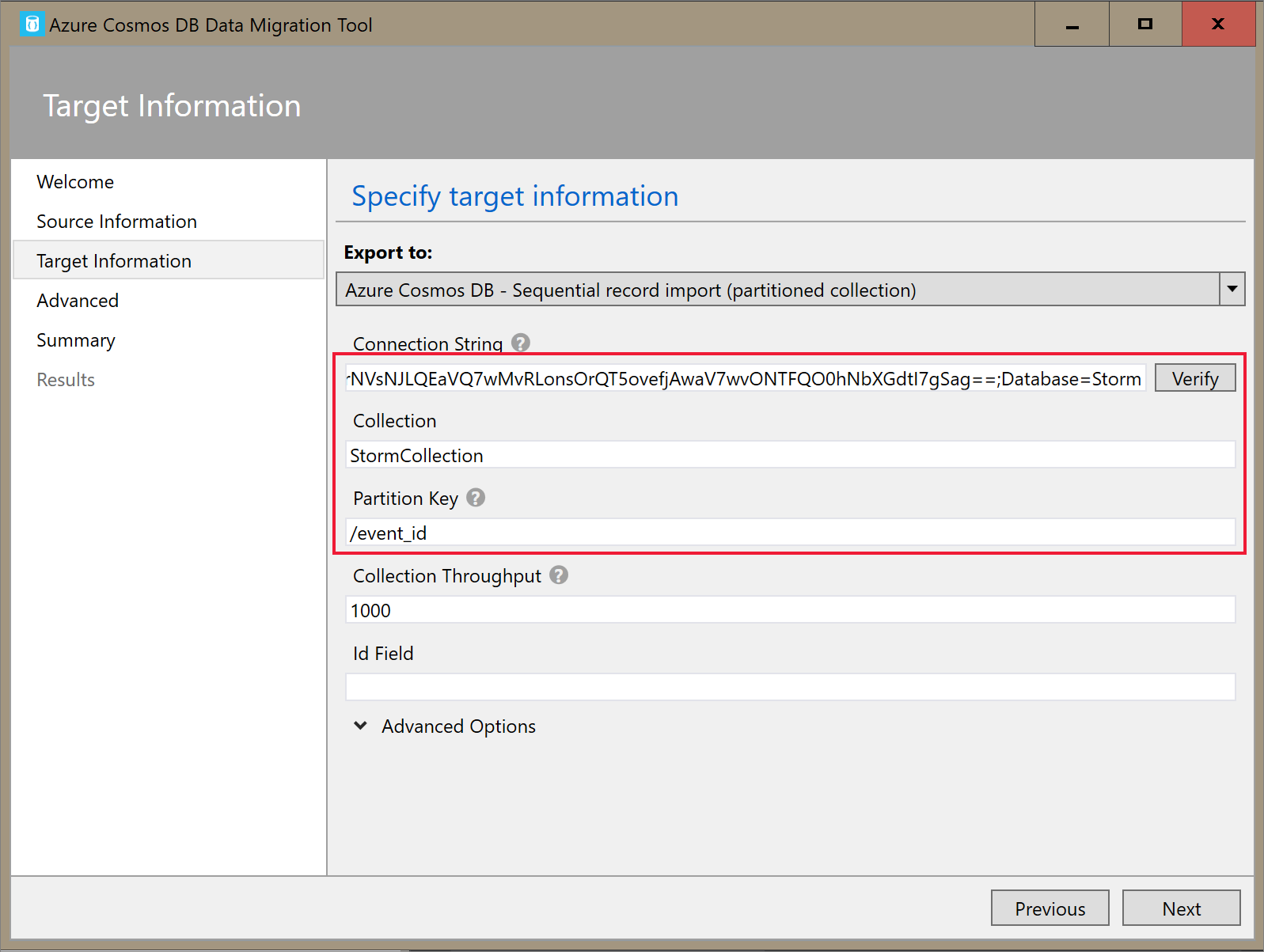
Selecione Seguinte até chegar à página Resumo. Em seguida, selecione Importar.
Criar um cluster e adicionar biblioteca
Navegue para o serviço Azure Databricks no portal do Azure e selecione Iniciar Área de Trabalho.
Criar um novo cluster. Escolha um Nome de Cluster e aceite as restantes predefinições.
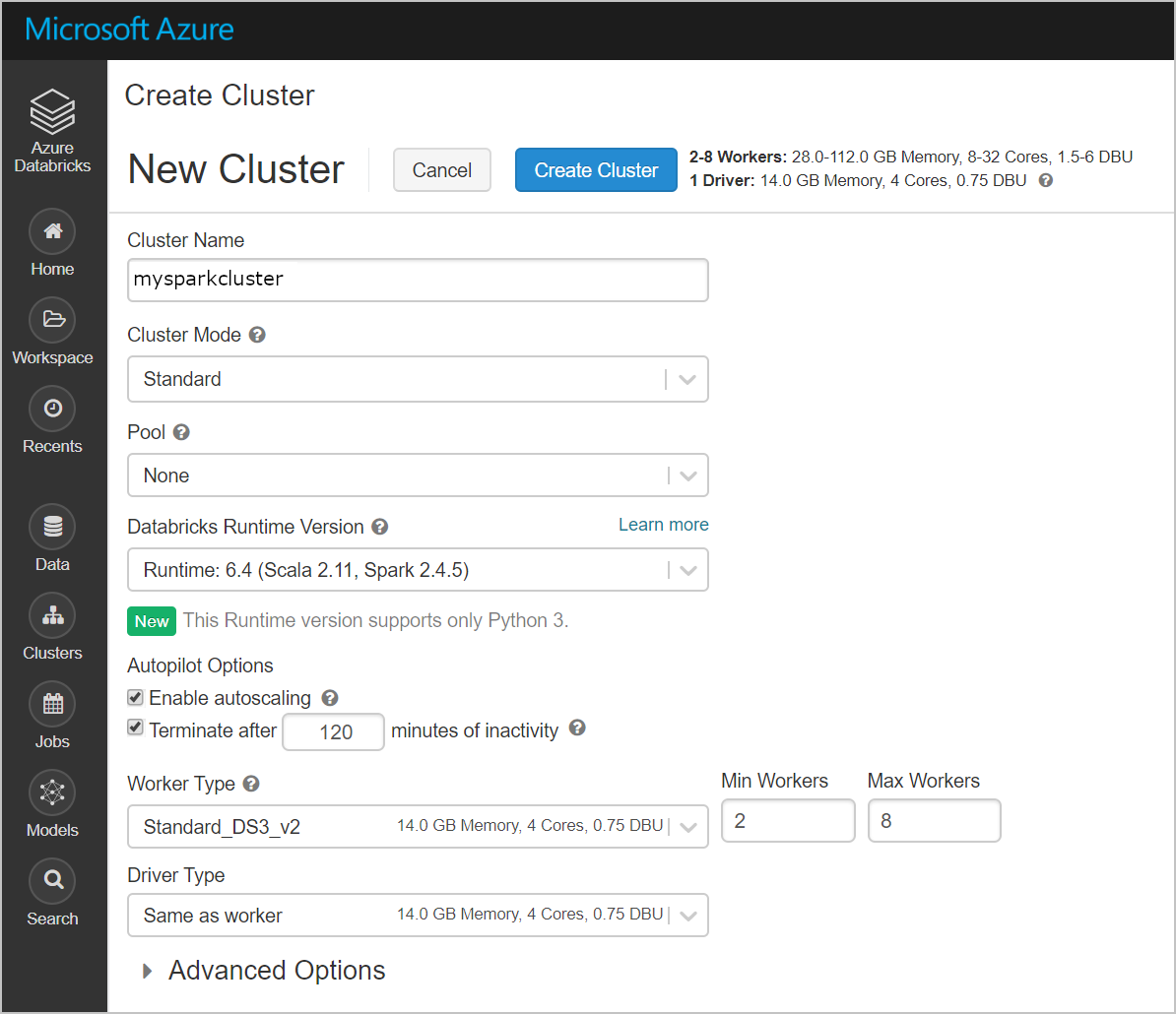
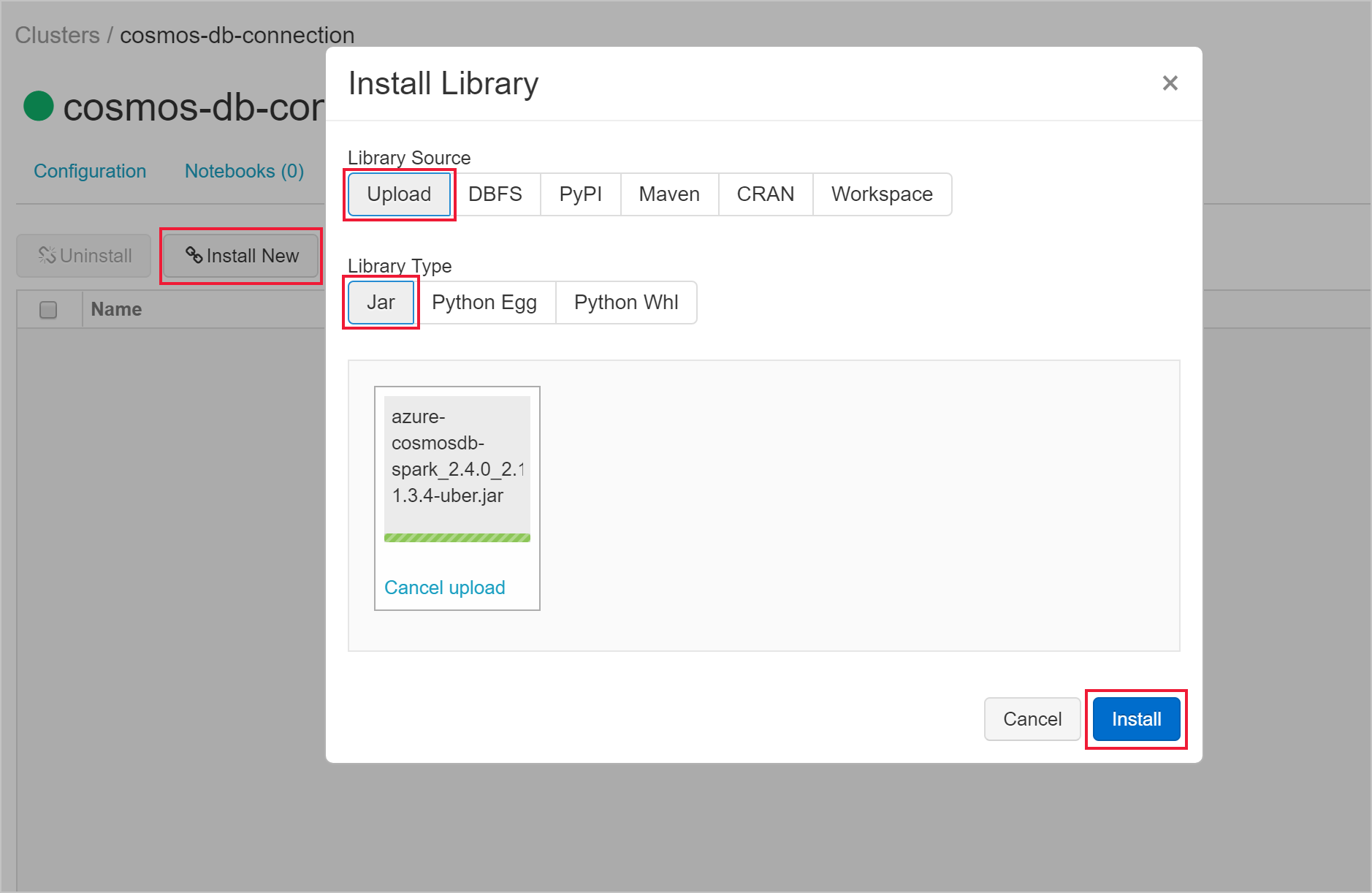
Depois de criar o cluster, navegue para a página do cluster e selecione o separador Bibliotecas . Selecione Instalar Novo e carregue o ficheiro jar do conector do Spark para instalar a biblioteca.
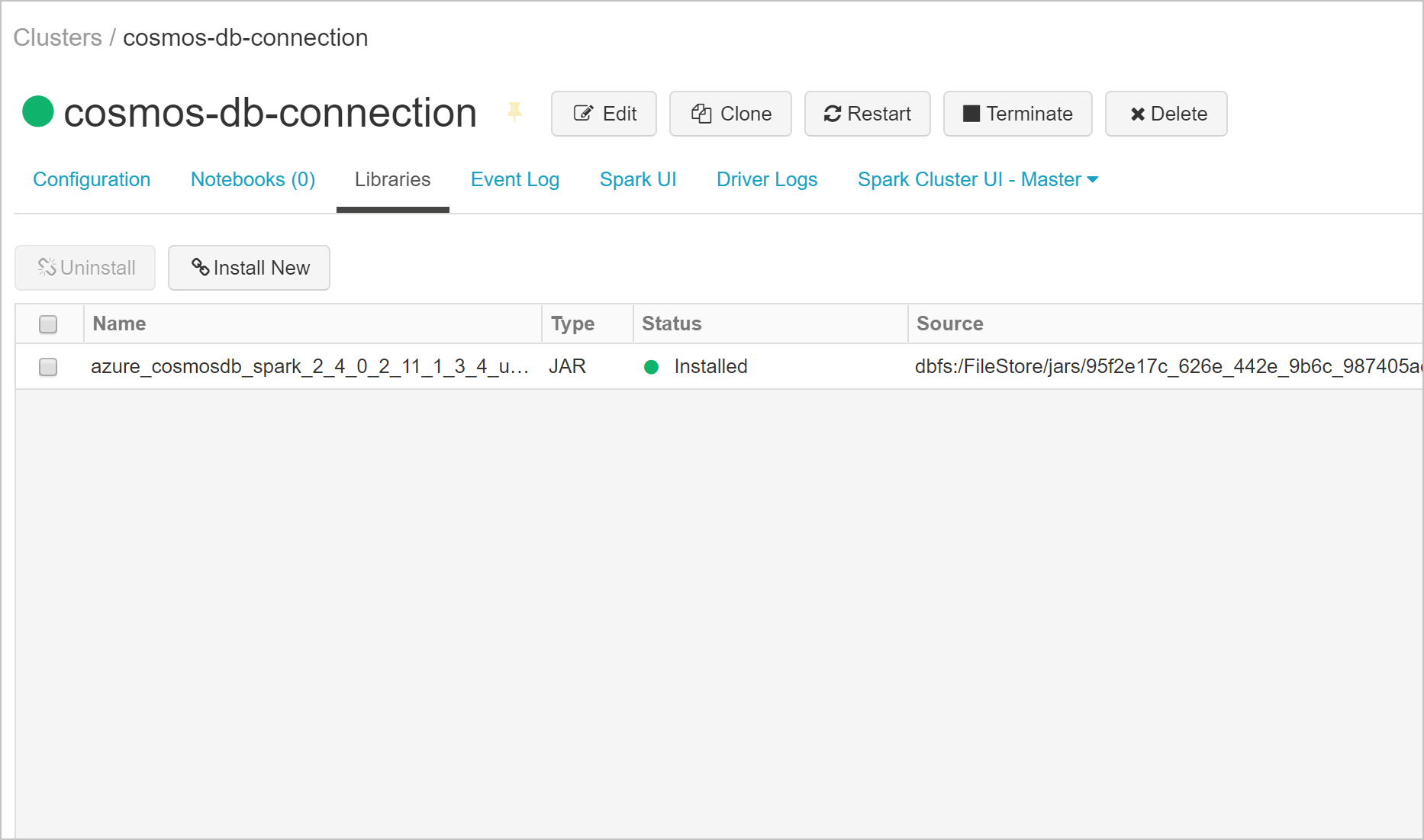
Pode verificar se a biblioteca foi instalada no separador Bibliotecas .
Consultar o Azure Cosmos DB a partir de um bloco de notas do Databricks
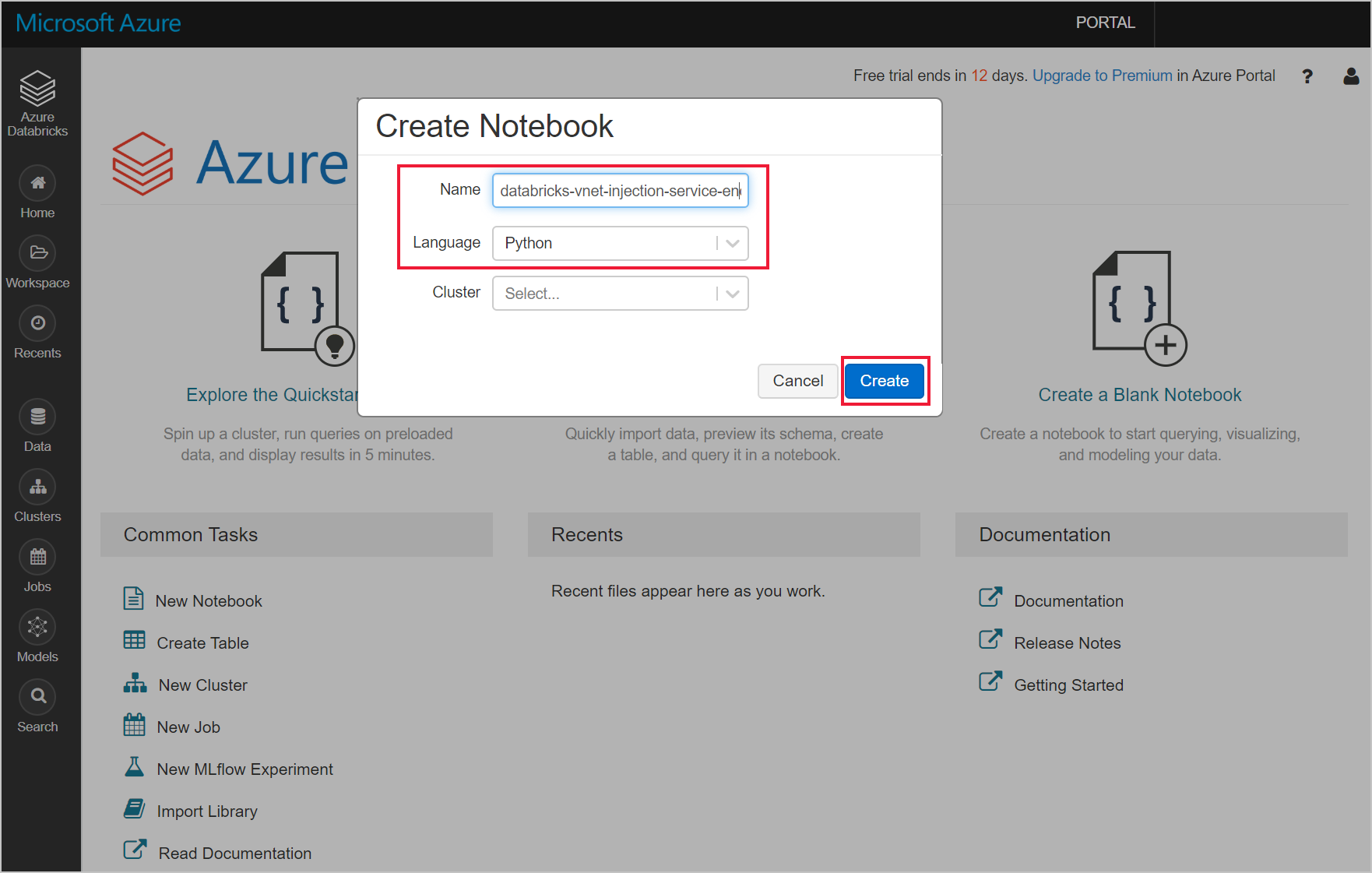
Navegue para a área de trabalho do Azure Databricks e crie um novo bloco de notas python.
Execute o seguinte código python para definir a configuração de ligação do Azure Cosmos DB. Altere o Ponto Final, Chave Mestra, Base de Dados e Contentor em conformidade.
connectionConfig = { "Endpoint" : "https://<your Azure Cosmos DB account name.documents.azure.com:443/", "Masterkey" : "<your Azure Cosmos DB primary key>", "Database" : "<your database name>", "preferredRegions" : "West US 2", "Container": "<your container name>", "schema_samplesize" : "1000", "query_pagesize" : "200000", "query_custom" : "SELECT * FROM c" }Utilize o seguinte código python para carregar os dados e criar uma vista temporária.
users = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**connectionConfig).load() users.createOrReplaceTempView("storm")Utilize o seguinte comando mágico para executar uma instrução SQL que devolve dados.
%sql select * from stormLigou com êxito a sua área de trabalho do Databricks injetada na VNet a um recurso do Azure Cosmos DB compatível com o ponto final de serviço. Para saber mais sobre como ligar ao Azure Cosmos DB, veja Conector do Azure Cosmos DB para Apache Spark.
Limpar recursos
Quando já não for necessário, elimine o grupo de recursos, a área de trabalho do Azure Databricks e todos os recursos relacionados. Eliminar a tarefa evita a faturação desnecessária. Se estiver a planear utilizar a área de trabalho do Azure Databricks no futuro, pode parar o cluster e reiniciá-lo mais tarde. Se não pretender continuar a utilizar esta área de trabalho do Azure Databricks, elimine todos os recursos que criou neste tutorial com os seguintes passos:
No menu esquerdo do portal do Azure, clique em Grupos de recursos e, em seguida, clique no nome do grupo de recursos que criou.
Na página do grupo de recursos, selecione Eliminar, escreva o nome do recurso a eliminar na caixa de texto e, em seguida, selecione Eliminar novamente.
Passos seguintes
Neste tutorial, implementou uma área de trabalho do Azure Databricks numa rede virtual e utilizou o conector spark do Azure Cosmos DB para consultar dados do Azure Cosmos DB a partir do Databricks. Para saber mais sobre como trabalhar com o Azure Databricks numa rede virtual, avance para o tutorial para utilizar SQL Server com o Azure Databricks.