O que é o Apache Hadoop no Azure HDInsight?
O Apache Hadoop era a arquitetura de código aberto original para processamento distribuído e análise de conjuntos de macrodados em clusters. O ecossistema Hadoop inclui software e utilitários relacionados, incluindo Apache Hive, Apache HBase, Spark, Kafka e muitos outros.
O Azure HDInsight é um serviço de análise de código aberto totalmente gerenciado e de espectro completo na nuvem para empresas. O tipo de cluster Apache Hadoop no Azure HDInsight permite que você use o Apache Hadoop Distributed File System (HDFS), o gerenciamento de recursos Apache Hadoop YARN e um modelo de programação MapReduce simples para processar e analisar dados em lote em paralelo. Os clusters Hadoop no HDInsight são compatíveis com o armazenamento de Blobs do Azure, o Azure Data Lake Storage Gen1 ou o Azure Data Lake Storage Gen2.
Para ver os componentes da pilha tecnológica do Hadoop disponíveis no HDInsight, veja Componentes e versões disponíveis com o HDInsight. Para ler mais sobre o Hadoop no HDInsight, veja a página de funcionalidades do Azure para o HDInsight.
O que é MapReduce
O Apache Hadoop MapReduce é uma estrutura de software para escrever trabalhos que processam grandes quantidades de dados. Os dados de entrada são divididos em partes independentes. Cada parte é processada em paralelo entre os nós do cluster. Um trabalho MapReduce consiste em duas funções:
Mapeador: consome dados de entrada, analisa-os (geralmente com operações de filtragem e classificação) e emite tuplas (pares chave-valor)
Redutor: consome tuplas emitidas pelo Mapeador e executa uma operação de resumo que cria um resultado menor e combinado a partir dos dados do Mapeador
Um exemplo de trabalho MapReduce de contagem básica de palavras é ilustrado no diagrama a seguir:
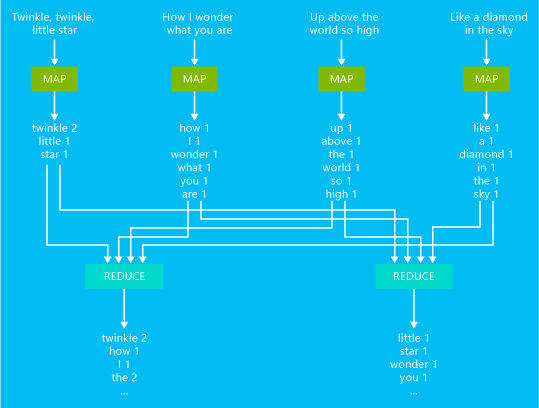
A saída deste trabalho é uma contagem de quantas vezes cada palavra ocorreu no texto.
- O mapeador pega cada linha do texto de entrada como uma entrada e a divide em palavras. Ele emite um par chave/valor cada vez que ocorre uma palavra da palavra é seguida por um 1. A saída é classificada antes de enviá-la para o redutor.
- O redutor soma essas contagens individuais para cada palavra e emite um único par chave/valor que contém a palavra seguida pela soma de suas ocorrências.
MapReduce pode ser implementado em vários idiomas. Java é a implementação mais comum, e é usado para fins de demonstração neste documento.
Linguagens de desenvolvimento
Linguagens ou frameworks baseados em Java e Java Virtual Machine podem ser executados diretamente como um trabalho MapReduce. O exemplo usado neste documento é um aplicativo Java MapReduce. Linguagens não Java, como C#, Python ou executáveis autônomos, devem usar streaming Hadoop.
O streaming do Hadoop se comunica com o mapeador e o redutor por meio de STDIN e STDOUT. O mapeador e o redutor leem dados uma linha de cada vez a partir de STDIN e gravam a saída em STDOUT. Cada linha lida ou emitida pelo mapeador e redutor deve estar no formato de um par chave/valor, delimitado por um caractere de tabulação:
[key]\t[value]
Para obter mais informações, consulte Hadoop Streaming.
Para obter exemplos de como usar o streaming do Hadoop com o HDInsight, consulte o seguinte documento:
Por onde começo
- Guia de início rápido: criar cluster Apache Hadoop no Azure HDInsight usando o portal do Azure
- Tutorial: Enviar trabalhos do Apache Hadoop no HDInsight
- Desenvolver programas Java MapReduce para Apache Hadoop no HDInsight
- Usar o Apache Hive como uma ferramenta ETL (Extrair, Transformar e Carregar)
- Extrair, transformar e carregar (ETL) em escala
- Operacionalizar um pipeline de análise de dados