Extrair, transformar e carregar (ETL) em escala
Extrair, transformar e carregar (ETL) é o processo pelo qual os dados são adquiridos de várias fontes. Os dados são coletados em um local padrão, limpos e processados. Em última análise, os dados são carregados em um armazenamento de dados a partir do qual podem ser consultados. O ETL herdado processa dados de importação, limpa-os no local e armazena-os em um mecanismo de dados relacional. Com o Azure HDInsight, uma ampla variedade de componentes de ambiente Apache Hadoop oferece suporte a ETL em escala.
O uso do HDInsight no processo de ETL é resumido por este pipeline:
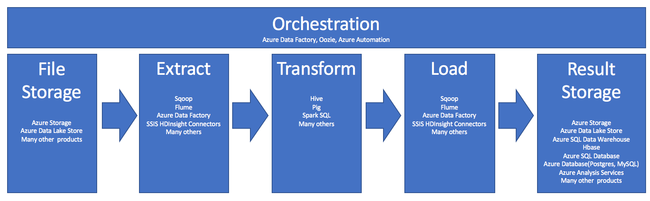
As seções a seguir exploram cada uma das fases de ETL e seus componentes associados.
Orquestração
A orquestração abrange todas as fases do pipeline de ETL. Os trabalhos de ETL no HDInsight geralmente envolvem vários produtos diferentes trabalhando em conjunto uns com os outros. Por exemplo:
- Você pode usar o Apache Hive para limpar uma parte dos dados e o Apache Pig para limpar outra parte.
- Você pode usar o Azure Data Factory para carregar dados no Banco de Dados SQL do Azure a partir do Repositório Azure Data Lake.
A orquestração é necessária para executar o trabalho apropriado no momento apropriado.
Apache Oozie
O Apache Oozie é um sistema de coordenação de fluxos de trabalho que gere as tarefas do Hadoop. O Oozie é executado em um cluster HDInsight e é integrado à pilha do Hadoop. O Oozie suporta trabalhos Hadoop para Apache Hadoop MapReduce, Pig, Hive e Sqoop. Você pode usar o Oozie para agendar trabalhos específicos de um sistema, como programas Java ou shell scripts.
Para obter mais informações, consulte Usar o Apache Oozie com o Apache Hadoop para definir e executar um fluxo de trabalho no HDInsight. Consulte também, Operacionalizar o pipeline de dados.
Azure Data Factory
O Azure Data Factory fornece recursos de orquestração na forma de plataforma como serviço (PaaS). O Azure Data Factory é um serviço de integração de dados baseado na cloud. Ele permite que você crie fluxos de trabalho orientados por dados para orquestrar e automatizar a movimentação e a transformação de dados.
Use o Azure Data Factory para:
- Crie e agende fluxos de trabalho orientados por dados. Esses pipelines ingerem dados de armazenamentos de dados diferentes.
- Processe e transforme os dados usando serviços de computação como HDInsight ou Hadoop. Você também pode usar o Spark, o Azure Data Lake Analytics, o Azure Batch ou o Azure Machine Learning para esta etapa.
- Publique dados de saída em armazenamentos de dados, como o Azure Synapse Analytics, para que os aplicativos de BI sejam consumidos.
Para obter mais informações sobre o Azure Data Factory, consulte a documentação.
Ingerir armazenamento de arquivos e armazenamento de resultados
Os arquivos de dados de origem normalmente são carregados em um local no Armazenamento do Azure ou no Armazenamento do Azure Data Lake. Os arquivos geralmente estão em um formato simples, como CSV. Mas, podem ser em qualquer formato.
Armazenamento do Azure
O Armazenamento do Azure tem destinos específicos de adaptabilidade. Consulte Metas de escalabilidade e desempenho para armazenamento de Blob para obter mais informações. Para a maioria dos nós analíticos, o Armazenamento do Azure é melhor dimensionado ao lidar com muitos arquivos menores. Desde que esteja dentro dos limites da sua conta, o Armazenamento do Azure garante o mesmo desempenho, independentemente do tamanho dos ficheiros. Você pode armazenar terabytes de dados e ainda obter um desempenho consistente. Esta afirmação é verdadeira quer esteja a utilizar um subconjunto ou todos os dados.
O Armazenamento do Azure tem vários tipos de blobs. Um blob de apêndice é uma ótima opção para armazenar logs da web ou dados do sensor.
Vários blobs podem ser distribuídos em vários servidores para expandir o acesso a eles. Mas um único blob é servido apenas por um único servidor. Embora os blobs possam ser agrupados logicamente em contêineres de blob, não há implicações de particionamento desse agrupamento.
O Armazenamento do Azure tem uma camada de API WebHDFS para o armazenamento de blobs. Todos os serviços do HDInsight podem acessar arquivos no armazenamento de Blob do Azure para limpeza e processamento de dados. Isso é semelhante a como esses serviços usariam o Hadoop Distributed File System (HDFS).
Os dados normalmente são ingeridos no Armazenamento do Azure por meio do PowerShell, do SDK do Armazenamento do Azure ou do AzCopy.
Azure Data Lake Storage
O Armazenamento Azure Data Lake é um repositório gerenciado de hiperescala para dados analíticos. É compatível e utiliza um paradigma de design semelhante ao HDFS. O Data Lake Storage oferece adaptabilidade ilimitada para a capacidade total e o tamanho de arquivos individuais. É uma boa opção ao trabalhar com arquivos grandes, porque eles podem ser armazenados em vários nós. O particionamento de dados no Data Lake Storage é feito nos bastidores. Desta forma, fornece um débito maciço para executar tarefas de análise com milhares de executores simultâneos que leem e escrevem centenas de terabytes de dados de forma eficaz.
Os dados geralmente são ingeridos no Armazenamento Data Lake por meio do Azure Data Factory. Você também pode usar SDKs de armazenamento Data Lake, o serviço AdlCopy, Apache DistCp ou Apache Sqoop. O serviço escolhido depende de onde estão os dados. Se estiver em um cluster Hadoop existente, você pode usar o Apache DistCp, o serviço AdlCopy ou o Azure Data Factory. Para dados no armazenamento de Blob do Azure, você pode usar o SDK do Azure Data Lake Storage .NET, o Azure PowerShell ou o Azure Data Factory.
O Armazenamento Data Lake é otimizado para ingestão de eventos por meio dos Hubs de Eventos do Azure.
Considerações para ambas as opções de armazenamento
Para carregar conjuntos de dados no intervalo de terabytes, a latência da rede pode ser um grande problema. Isso é particularmente verdadeiro se os dados forem provenientes de um local local. Nesses casos, você pode usar estas opções:
Azure ExpressRoute: crie conexões privadas entre os datacenters do Azure e sua infraestrutura local. Essas conexões fornecem uma opção confiável para transferir grandes quantidades de dados. Para obter mais informações, consulte a documentação do Azure ExpressRoute.
Carregamento de dados de unidades de disco rígido: pode utilizar o serviço de Importação/Exportação do Azure para enviar unidades de disco rígido com os seus dados para um centro de dados do Azure. Seus dados são carregados primeiro no armazenamento de Blob do Azure. Em seguida, você pode usar o Azure Data Factory ou a ferramenta AdlCopy para copiar dados do armazenamento de Blob do Azure para o Armazenamento Data Lake.
Azure Synapse Analytics
O Azure Synapse Analytics é uma escolha apropriada para armazenar resultados preparados. Você pode usar o Azure HDInsight para executar esses serviços para o Azure Synapse Analytics.
O Azure Synapse Analytics é um armazenamento de banco de dados relacional otimizado para cargas de trabalho analíticas. Ele é dimensionado com base em tabelas particionadas. As tabelas podem ser particionadas em vários nós. Os nós são selecionados no momento da criação. Eles podem ser dimensionados após o fato, mas esse é um processo ativo que pode exigir a movimentação de dados. Para obter mais informações, consulte Gerenciar computação no Azure Synapse Analytics.
Apache HBase
O Apache HBase é um armazenamento de chave/valor disponível no Azure HDInsight. É um banco de dados NoSQL de código aberto que é construído no Hadoop e modelado de acordo com o Google BigTable. O HBase fornece acesso aleatório de alto desempenho e forte consistência para grandes quantidades de dados não estruturados e semiestruturados.
Como o HBase é um banco de dados sem esquema, não é necessário definir colunas e tipos de dados antes de usá-los. Os dados são armazenados nas linhas de uma tabela e agrupados por família de colunas.
O código open source é dimensionado linearmente para processar petabytes de dados em milhares de nós. O HBase depende de redundância de dados, processamento em lote e outros recursos fornecidos por aplicativos distribuídos no ambiente Hadoop.
O HBase é um bom destino para dados de sensores e logs para análises futuras.
A adaptabilidade do HBase depende do número de nós no cluster HDInsight.
Bancos de dados SQL do Azure
O Azure oferece três bancos de dados relacionais PaaS:
- O Banco de Dados SQL do Azure é uma implementação do Microsoft SQL Server. Para obter mais informações sobre desempenho, consulte Ajustando o desempenho no Banco de Dados SQL do Azure.
- O Banco de Dados do Azure para MySQL é uma implementação do Oracle MySQL.
- O Banco de Dados do Azure para PostgreSQL é uma implementação do PostgreSQL.
Adicione mais CPU e memória para aumentar a escala desses produtos. Você também pode optar por usar discos premium com os produtos para um melhor desempenho de E/S.
Azure Analysis Services
O Azure Analysis Services é um mecanismo de dados analítico usado no suporte à decisão e na análise de negócios. Ele fornece os dados analíticos para relatórios de negócios e aplicativos cliente, como o Power BI. Os dados analíticos também funcionam com Excel, relatórios do SQL Server Reporting Services e outras ferramentas de visualização de dados.
Dimensione cubos de análise alterando as camadas para cada cubo individual. Para obter mais informações, consulte Preços do Azure Analysis Services.
Extrair e carregar
Depois que os dados existirem no Azure, você poderá usar muitos serviços para extraí-los e carregá-los em outros produtos. O HDInsight suporta Sqoop e Flume.
Apache Sqoop
O Apache Sqoop é uma ferramenta projetada para transferir dados de forma eficiente entre fontes de dados estruturadas, semiestruturadas e não estruturadas.
O Sqoop usa o MapReduce para importar e exportar os dados, para fornecer operação paralela e tolerância a falhas.
Apache Flume
O Apache Flume é um serviço distribuído, confiável e disponível para coletar, agregar e mover com eficiência grandes quantidades de dados de log. Sua arquitetura flexível é baseada em fluxos de dados de streaming. O Flume é robusto e tolerante a falhas com mecanismos de confiabilidade ajustáveis. Ele tem muitos mecanismos de failover e recuperação. O Flume usa um modelo de dados extensível simples que permite a aplicação analítica on-line.
O Apache Flume não pode ser usado com o Azure HDInsight. Mas, uma instalação Hadoop local pode usar o Flume para enviar dados para o armazenamento de Blob do Azure ou para o Armazenamento do Azure Data Lake. Para obter mais informações, consulte Usando o Apache Flume com o HDInsight.
Transformação
Depois que os dados existirem no local escolhido, você precisará limpá-los, combiná-los ou prepará-los para um padrão de uso específico. Hive, Pig e Spark SQL são boas opções para esse tipo de trabalho. Todos eles são suportados no HDInsight.