Tutorial: Criar clusters Apache Hadoop sob demanda no HDInsight usando o Azure Data Factory
Neste tutorial, você aprenderá a criar um cluster Apache Hadoop , sob demanda, no Azure HDInsight usando o Azure Data Factory. Em seguida, use pipelines de dados no Azure Data Factory para executar trabalhos do Hive e excluir o cluster. Ao final deste tutorial, você aprenderá como executar operationalize um trabalho de big data em que a criação de cluster, a execução de trabalho e a exclusão de cluster são feitas de acordo com um cronograma.
Este tutorial abrange as seguintes tarefas:
- Criar uma conta de armazenamento do Azure
- Compreender a atividade do Azure Data Factory
- Criar uma fábrica de dados usando o portal do Azure
- Criar serviços ligados
- Criar um pipeline
- Acionar um pipeline
- Monitorizar um pipeline
- Verificar a saída
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
O módulo Az do PowerShell instalado.
Uma entidade de serviço Microsoft Entra. Depois de criar a entidade de serviço, certifique-se de recuperar a ID do aplicativo e a chave de autenticação usando as instruções no artigo vinculado. Você precisará desses valores mais adiante neste tutorial. Além disso, verifique se a entidade de serviço é membro da função de Colaborador da assinatura ou do grupo de recursos no qual o cluster é criado. Para obter instruções sobre como recuperar os valores necessários e atribuir as funções corretas, consulte Criar uma entidade de serviço do Microsoft Entra.
Criar objetos preliminares do Azure
Nesta seção, você cria vários objetos que serão usados para o cluster HDInsight criado sob demanda. A conta de armazenamento criada conterá o script HiveQL de exemplo, partitionweblogs.hql, que você usa para simular um trabalho de exemplo do Apache Hive que é executado no cluster.
Esta seção usa um script do Azure PowerShell para criar a conta de armazenamento e copiar os arquivos necessários dentro da conta de armazenamento. O script de exemplo do Azure PowerShell nesta seção executa as seguintes tarefas:
- Entra no Azure.
- Cria um grupo de recursos do Azure.
- Cria uma Conta de armazenamento do Azure.
- Cria um contêiner de Blob na conta de armazenamento
- Copia o script HiveQL de exemplo (partitionweblogs.hql) do contêiner Blob. O script de exemplo já está disponível em outro contêiner de Blob público. O script do PowerShell abaixo faz uma cópia desses arquivos na conta de Armazenamento do Azure que ele cria.
Criar conta de armazenamento e copiar arquivos
Importante
Especifique nomes para o grupo de recursos do Azure e a conta de armazenamento do Azure que será criada pelo script. Anote o nome do grupo de recursos, o nome da conta de armazenamento e a chave da conta de armazenamento gerados pelo script. Vai precisar deles na próxima secção.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
Verificar conta de armazenamento
- Inicie sessão no portal do Azure.
- À esquerda, navegue até Todos os grupos de recursos gerais>de serviços.>
- Selecione o nome do grupo de recursos que você criou no script do PowerShell. Use o filtro se tiver muitos grupos de recursos listados.
- No modo de exibição Visão geral , você verá um recurso listado, a menos que compartilhe o grupo de recursos com outros projetos. Esse recurso é a conta de armazenamento com o nome especificado anteriormente. Selecione o nome da conta de armazenamento.
- Selecione o bloco Contêineres .
- Selecione o contêiner adfgetstarted . Você vê uma pasta chamada
hivescripts. - Abra a pasta e certifique-se de que contém o ficheiro de script de exemplo, partitionweblogs.hql.
Compreender a atividade do Azure Data Factory
O Azure Data Factory orquestra e automatiza a movimentação e a transformação de dados. O Azure Data Factory pode criar um cluster Hadoop HDInsight just-in-time para processar uma fatia de dados de entrada e excluir o cluster quando o processamento for concluído.
No Azure Data Factory, uma fábrica de dados pode ter um ou mais pipelines de dados. Um pipeline de dados tem uma ou mais atividades. Existem dois tipos de atividades:
- Atividades de Movimentação de Dados. Você usa atividades de movimentação de dados para mover dados de um armazenamento de dados de origem para um armazenamento de dados de destino.
- Atividades de Transformação de Dados. Você usa atividades de transformação de dados para transformar/processar dados. O HDInsight Hive Activity é uma das atividades de transformação suportadas pelo Data Factory. Você usa a atividade de transformação do Hive neste tutorial.
Neste artigo, você configura a atividade do Hive para criar um cluster Hadoop HDInsight sob demanda. Quando a atividade é executada para processar dados, aqui está o que acontece:
Um cluster Hadoop HDInsight é criado automaticamente para que você processe a fatia.
Os dados de entrada são processados executando um script HiveQL no cluster. Neste tutorial, o script HiveQL associado à atividade do hive executa as seguintes ações:
- Usa a tabela existente (hivesampletable) para criar outra tabela HiveSampleOut.
- Preenche a tabela HiveSampleOut com apenas colunas específicas da hivesampletable original.
O cluster Hadoop do HDInsight é excluído após a conclusão do processamento e o cluster fica ocioso pelo tempo configurado (configuração timeToLive). Se a próxima fatia de dados estiver disponível para processamento com esse tempo ocioso do TimeToLive, o mesmo cluster será usado para processar a fatia.
Criar uma fábrica de dados
Inicie sessão no portal do Azure.
No menu à esquerda, navegue até
+ Create a resource>Analytics>Data Factory.
Insira ou selecione os seguintes valores para o bloco Novo data factory :
Property valor Nome Insira um nome para o data factory. Este nome tem de ser globalmente exclusivo. Versão Deixe na V2. Subscrição Selecione a subscrição do Azure. Grupo de recursos Selecione o grupo de recursos que você criou usando o script do PowerShell. Localização O local é definido automaticamente para o local especificado ao criar o grupo de recursos anteriormente. Para este tutorial, o local é definido como Leste dos EUA. Ativar GIT Desmarque esta caixa. 
Selecione Criar. A criação de uma fábrica de dados pode levar entre 2 a 4 minutos.
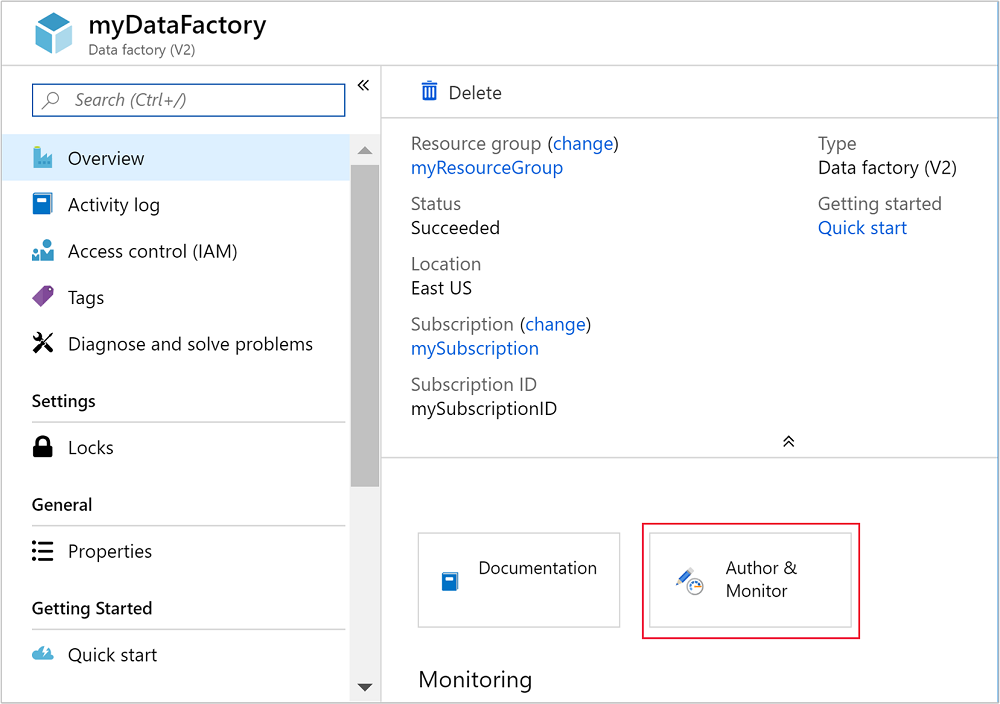
Depois que o data factory for criado, você receberá uma notificação de implantação bem-sucedida com um botão Ir para o recurso . Selecione Ir para recurso para abrir a visualização padrão do Data Factory.
Selecione Author & Monitor para iniciar o portal de criação e monitoramento do Azure Data Factory.
Criar serviços ligados
Nesta seção, você cria dois serviços vinculados dentro do seu data factory.
- Um serviço ligado do Armazenamento do Azure que liga uma conta de armazenamento do Azure à fábrica de dados. Este armazenamento é utilizado pelo cluster do HDInsight a pedido. Ele também contém o script Hive que é executado no cluster.
- Um serviço ligado do HDInsight a pedido. O Azure Data Factory cria automaticamente um cluster HDInsight e executa o script do Hive. Em seguida, elimina o cluster do HDInsight depois de o cluster estar inativo durante um período de tempo pré-configurado.
Criar um serviço ligado do Armazenamento do Azure
No painel esquerdo da página Vamos começar , selecione o ícone Autor .

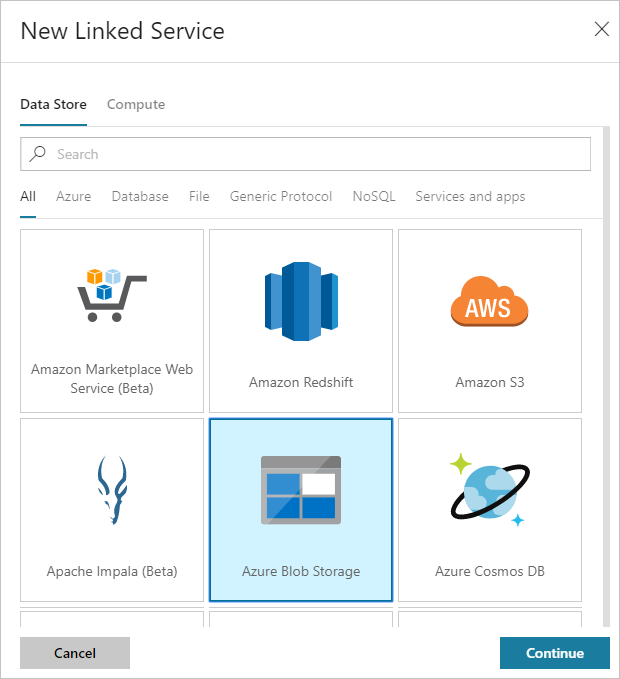
Selecione Conexões no canto inferior esquerdo da janela e, em seguida, selecione +Novo.

Na caixa de diálogo Novo Serviço Vinculado, selecione Armazenamento de Blob do Azure e selecione Continuar.
Forneça os seguintes valores para o serviço vinculado de armazenamento:
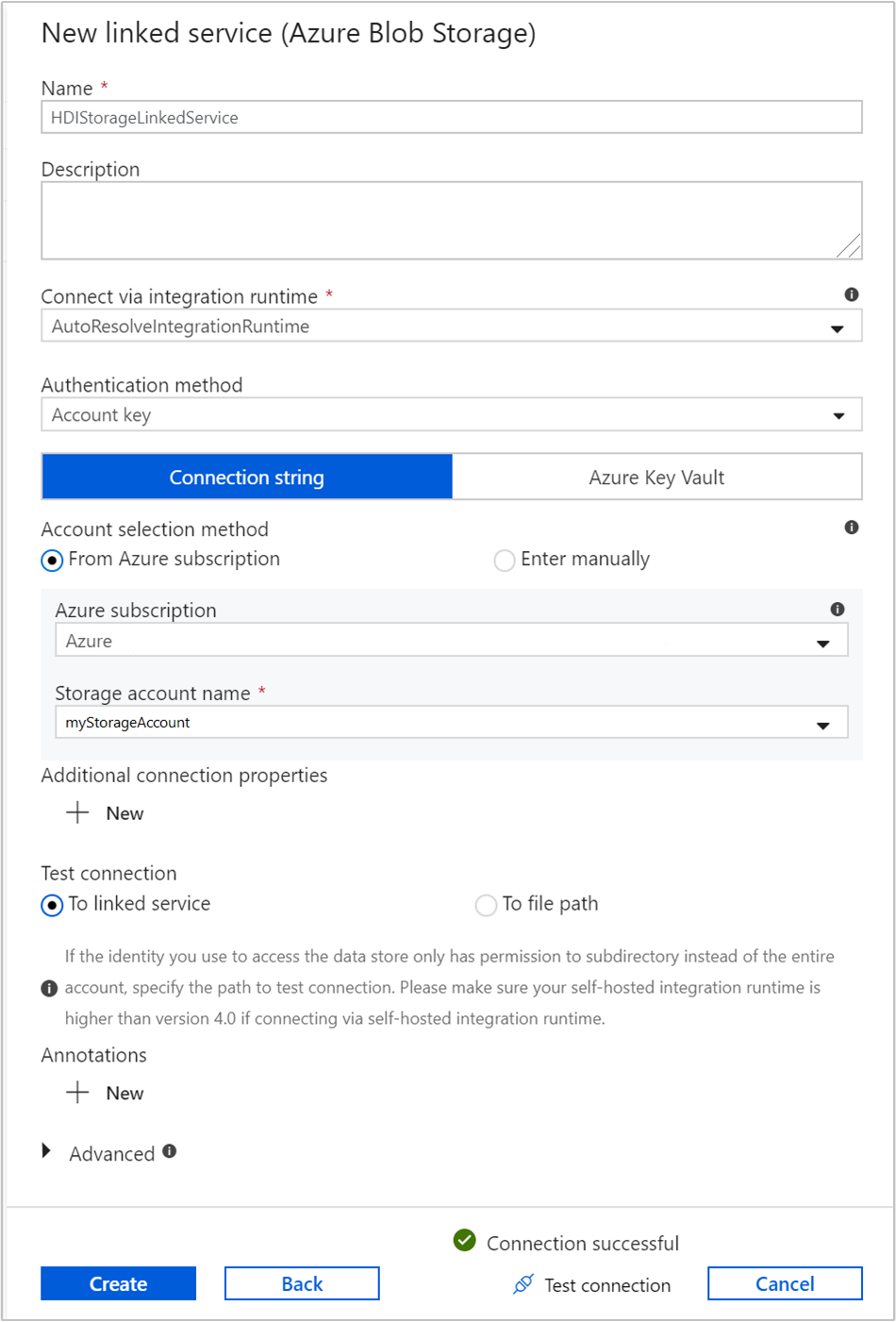
Property valor Nome Introduzir HDIStorageLinkedService.Subscrição do Azure Selecione sua assinatura na lista suspensa. Nome da conta de armazenamento Selecione a conta de Armazenamento do Azure que você criou como parte do script do PowerShell. Selecione Testar conexão e, se for bem-sucedido, selecione Criar.
Crie um serviço ligado do HDInsight a pedido
Selecione o botão + Novo novamente para criar outro serviço ligado.
Na janela Novo Serviço Vinculado, selecione a guia Computação.
Selecione Azure HDInsight e, em seguida, selecione Continuar.

Na janela Novo Serviço Vinculado, insira os seguintes valores e deixe o restante como padrão:
Property valor Nome Introduzir HDInsightLinkedService.Type Selecione HDInsight sob demanda. Serviço Ligado do Armazenamento do Azure Selecione HDIStorageLinkedService.Tipo de cluster Selecionar hadoop Time to live Forneça a duração durante a qual você deseja que o cluster HDInsight esteja disponível antes de ser excluído automaticamente. ID da entidade de serviço Forneça a ID do aplicativo da entidade de serviço do Microsoft Entra que você criou como parte dos pré-requisitos. Chave da entidade de serviço Forneça a chave de autenticação para a entidade de serviço do Microsoft Entra. Prefixo do nome do cluster Forneça um valor que será prefixado a todos os tipos de cluster criados pelo data factory. Subscrição Selecione sua assinatura na lista suspensa. Selecionar grupo de recursos Selecione o grupo de recursos que você criou como parte do script do PowerShell usado anteriormente. Tipo de SO/Nome de utilizador SSH do cluster Insira um nome de usuário SSH, geralmente sshuser.Tipo de SO/Palavra-passe SSH do cluster Forneça uma senha para o usuário SSH Tipo de SO/Nome de utilizador do cluster Insira um nome de usuário de cluster, geralmente admin.Tipo de SO/Palavra-passe do cluster Forneça uma senha para o usuário do cluster. Depois, selecione Criar.

Criar um pipeline
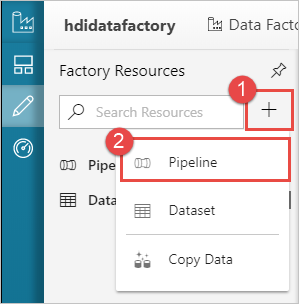
Selecione o botão + (mais) e, em seguida, selecione Pipeline.
Na caixa de ferramentas Atividades, expanda HDInsight e arraste a atividade do Hive para a superfície do designer de pipeline. Na guia Geral, forneça um nome para a atividade.

Verifique se a atividade do Hive está selecionada, selecione a guia Cluster HDI. E na lista suspensa Serviço Vinculado do HDInsight, selecione o serviço vinculado criado anteriormente, HDInsightLinkedService, para o HDInsight.

Selecione a guia Script e conclua as seguintes etapas:
Para Serviço Vinculado por Script, selecione HDIStorageLinkedService na lista suspensa. Esse valor é o serviço vinculado de armazenamento criado anteriormente.
Em Caminho do arquivo, selecione Procurar armazenamento e navegue até o local onde o script Hive de exemplo está disponível. Se você executou o script do PowerShell anteriormente, esse local deve ser
adfgetstarted/hivescripts/partitionweblogs.hql.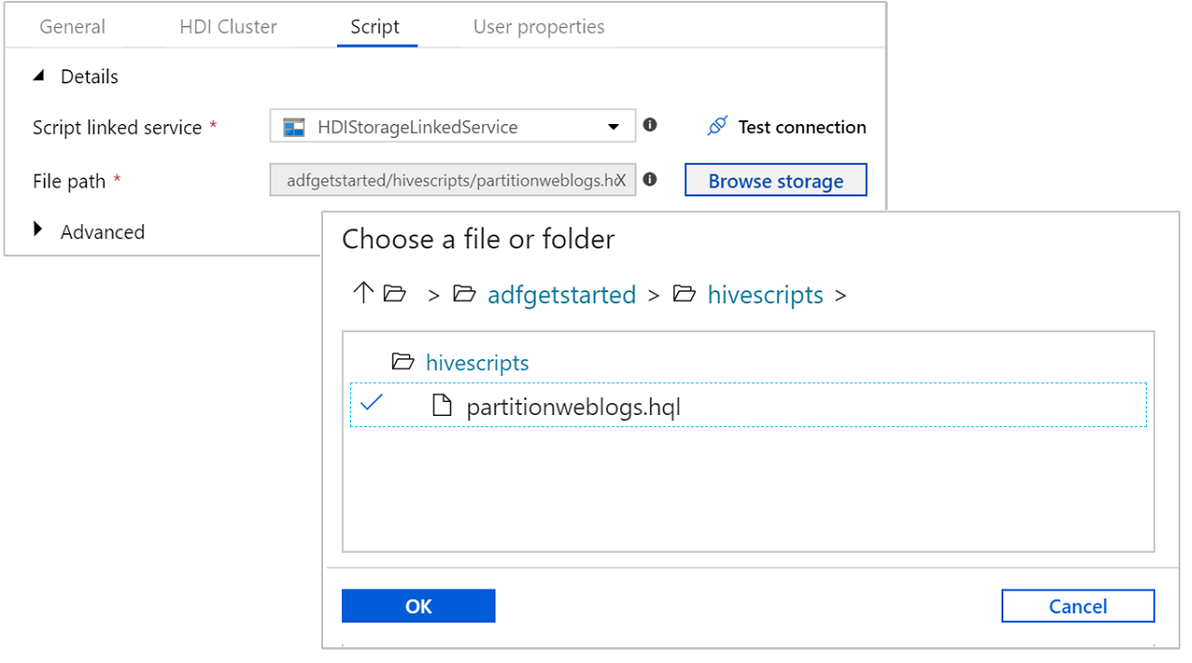
Em Parâmetros Avançados>, selecione .
Auto-fill from scriptEsta opção procura quaisquer parâmetros no script Hive que exijam valores em tempo de execução.Na caixa de texto do valor , adicione a pasta existente no formato
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/. O caminho é sensível a maiúsculas e minúsculas. Esse caminho é onde a saída do script será armazenada. Owasbsesquema é necessário porque as contas de armazenamento agora têm a transferência segura necessária habilitada por padrão.
Selecione Validar para validar o pipeline. Selecione o botão >> (seta para a direita) para fechar a janela de validação.
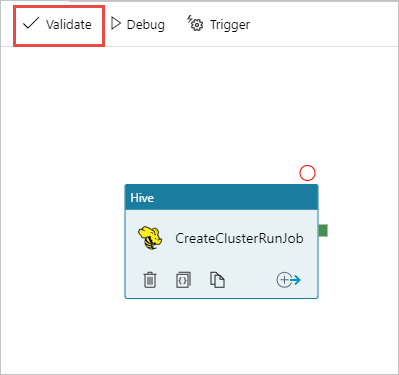
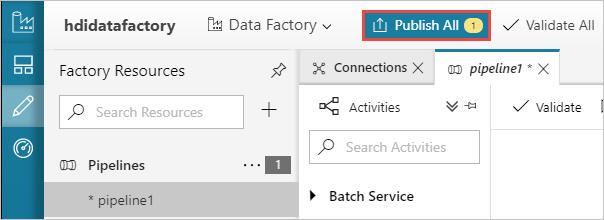
Por fim, selecione Publicar tudo para publicar os artefatos no Azure Data Factory.
Acionar um pipeline
Na barra de ferramentas na superfície do designer, selecione Adicionar gatilho de gatilho>agora.
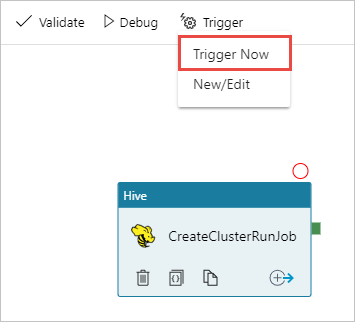
Selecione OK na barra lateral pop-up.
Monitorizar um pipeline
Mude para o separador Monitorizar, no lado esquerdo. Verá uma execução de pipeline na lista Execuções de Pipeline. Observe o status da execução na coluna Status .
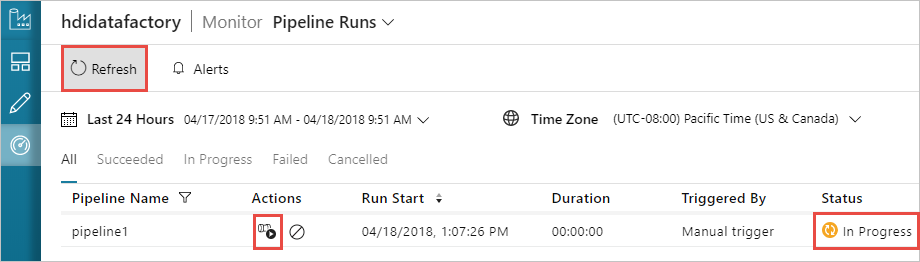
Selecione Atualizar para atualizar o estado.
Você também pode selecionar o ícone Exibir execuções de atividade para ver a atividade executada associada ao pipeline. Na captura de tela abaixo, você verá apenas uma atividade executada, pois há apenas uma atividade no pipeline que você criou. Para voltar à vista anterior, selecione Pipelines na parte superior da página.

Verificar a saída
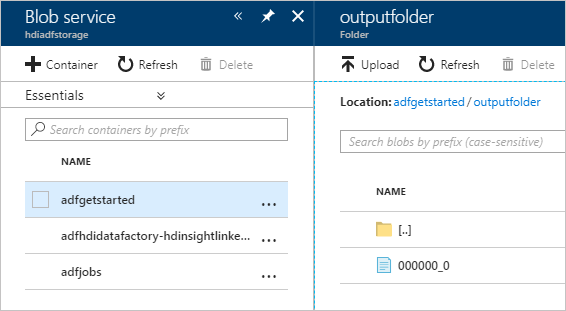
Para verificar a saída, no portal do Azure, navegue até a conta de armazenamento que você usou para este tutorial. Você deve ver as seguintes pastas ou contêineres:
Você vê uma adfgerstarted/outputfolder que contém a saída do script Hive que foi executado como parte do pipeline.
Você vê um contêiner adfhdidatafactory-linked-service-name-timestamp><><. Esse contêiner é o local de armazenamento padrão do cluster HDInsight que foi criado como parte da execução do pipeline.
Você vê um contêiner adfjobs que tem os logs de trabalho do Azure Data Factory.
Clean up resources (Limpar recursos)
Com a criação do cluster HDInsight sob demanda, não é necessário excluir explicitamente o cluster HDInsight. O cluster é excluído com base na configuração fornecida durante a criação do pipeline. Mesmo depois que o cluster é excluído, as contas de armazenamento associadas ao cluster continuam a existir. Esse comportamento é por design para que você possa manter seus dados intactos. No entanto, se não quiser manter os dados, pode eliminar a conta de armazenamento que criou.
Ou, você pode excluir todo o grupo de recursos que você criou para este tutorial. Esse processo exclui a conta de armazenamento e o Azure Data Factory que você criou.
Eliminar o grupo de recursos
Inicie sessão no portal do Azure.
Selecione Grupos de recursos no painel esquerdo.
Selecione o nome do grupo de recursos que você criou no script do PowerShell. Use o filtro se tiver muitos grupos de recursos listados. Abre o grupo de recursos.
No bloco Recursos, você terá a conta de armazenamento padrão e o data factory listados, a menos que compartilhe o grupo de recursos com outros projetos.
Selecione Eliminar grupo de recursos. Isso exclui a conta de armazenamento e os dados armazenados na conta de armazenamento.

Introduza o nome do grupo de recursos para confirmar a eliminação e, em seguida, selecione Eliminar.
Próximos passos
Neste artigo, você aprendeu como usar o Azure Data Factory para criar cluster HDInsight sob demanda e executar trabalhos do Apache Hive. Avance para o próximo artigo para saber como criar clusters HDInsight com configuração personalizada.