Depurar aplicativos Apache Spark em um cluster HDInsight com o Kit de Ferramentas do Azure para IntelliJ por SSH
Este artigo fornece orientação passo a passo sobre como usar as Ferramentas do HDInsight no Kit de Ferramentas do Azure para IntelliJ para depurar aplicativos remotamente em um cluster HDInsight.
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Consulte Criar um cluster do Apache Spark.
Para usuários do Windows: enquanto estiver executando o aplicativo Spark Scala local em um computador Windows, você pode obter uma exceção, conforme explicado no SPARK-2356. A exceção ocorre porque WinUtils.exe está faltando no Windows.
Para resolver esse erro, baixe Winutils.exe para um local como C:\WinUtils\bin. Em seguida, adicione a variável de ambiente HADOOP_HOME e defina o valor da variável como C:\WinUtils.
IntelliJ IDEA (A edição comunitária é gratuita).
Um cliente SSH. Para obter mais informações, veja Ligar ao HDInsight (Apache Hadoop) através de SSH.
Criar um aplicativo Spark Scala
Inicie o IntelliJ IDEA e selecione Criar novo projeto para abrir a janela Novo projeto .
Selecione Apache Spark/HDInsight no painel esquerdo.
Selecione Spark Project with Samples (Scala) na janela principal.
Na lista suspensa Ferramenta de compilação, selecione uma das seguintes opções:
- Suporte ao assistente de criação de projetos Maven for Scala.
- SBT para gerenciar as dependências e construir para o projeto Scala.
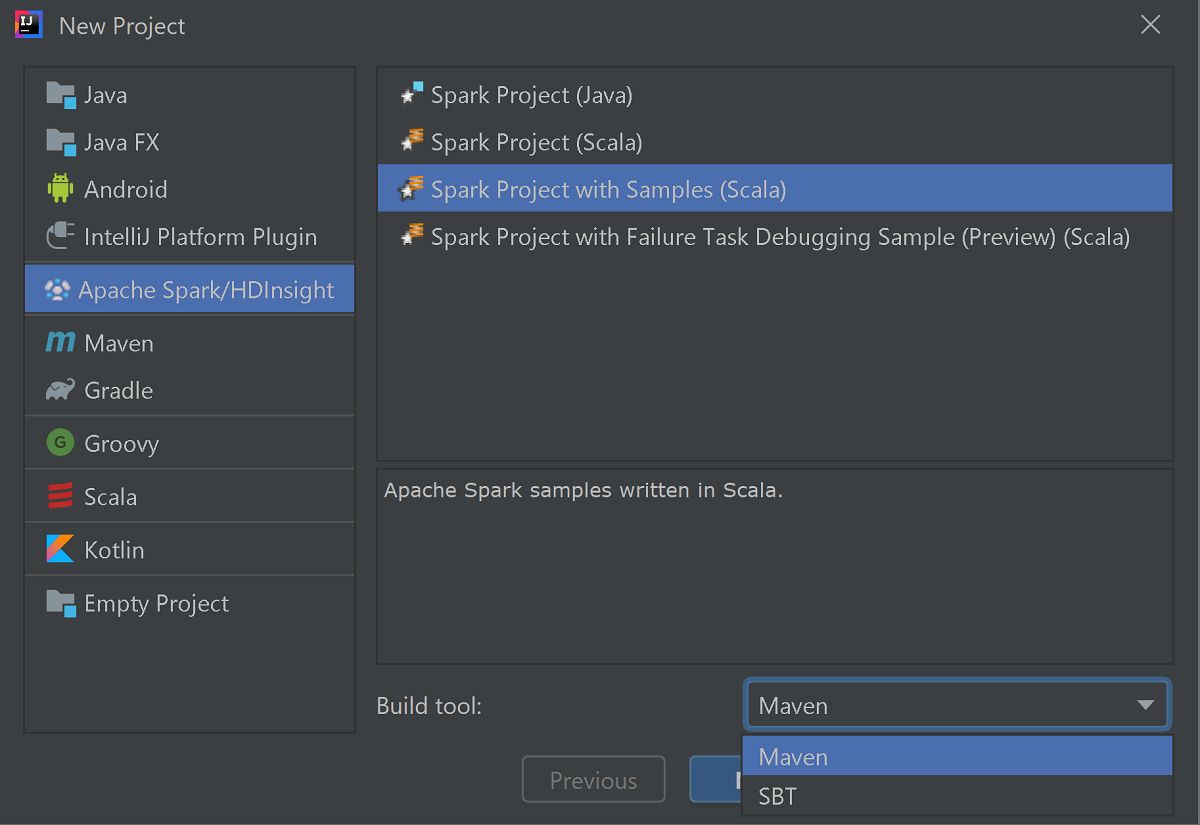
Selecione Seguinte.
Na próxima janela Novo Projeto , forneça as seguintes informações:
Property Description Nome do projeto Introduza um nome. Este passo a passo pelos usos myApp.Localização do projeto Insira o local desejado para salvar seu projeto. SDK do projeto Se estiver em branco, selecione Novo e navegue até o JDK. Versão Spark O assistente de criação integra a versão adequada para o SDK do Spark e o SDK do Scala. Se a versão do cluster do Spark for anterior à 2.0, selecione Spark 1.x. Caso contrário, selecione Spark 2.x.. Este exemplo usa o Spark 2.3.0 (Scala 2.11.8). 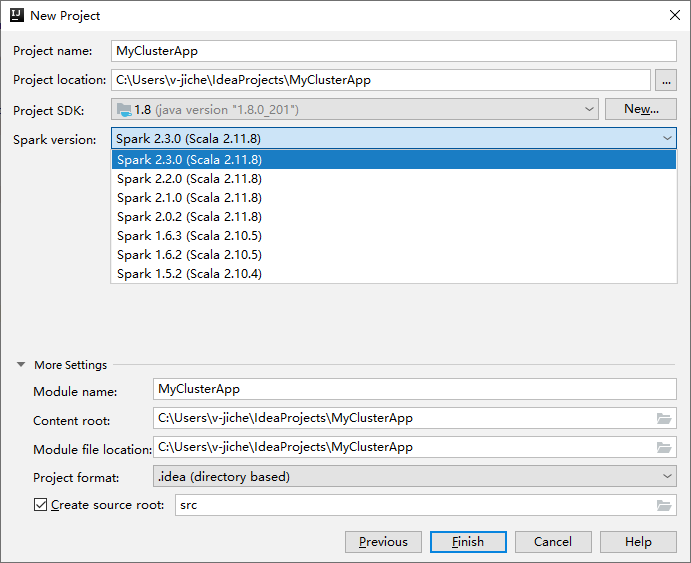
Selecione Concluir. Pode demorar alguns minutos até que o projeto fique disponível. Observe o progresso no canto inferior direito.
Expanda seu projeto e navegue até src>main>scala>sample. Clique duas vezes em SparkCore_WasbIOTest.
Executar execução local
No script SparkCore_WasbIOTest, clique com o botão direito do mouse no editor de scripts e selecione a opção Executar 'SparkCore_WasbIOTest' para executar a execução local.
Depois que a execução local for concluída, você poderá ver o arquivo de saída salvo no padrão de dados> do explorador de projetos atual.
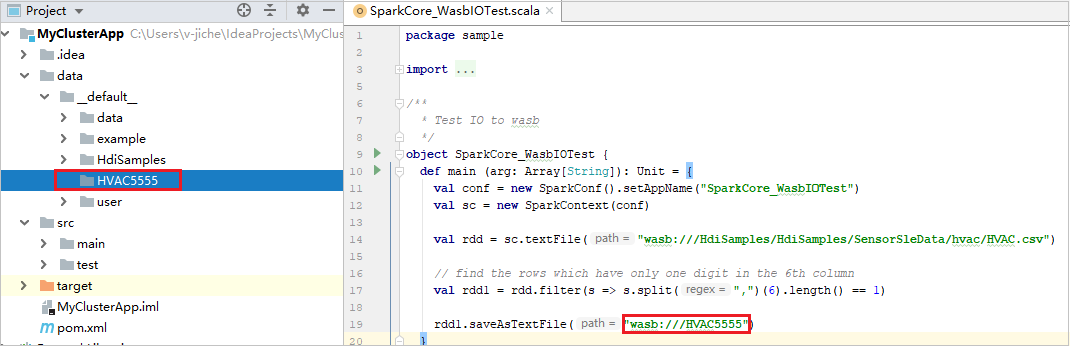
Nossas ferramentas definiram a configuração de execução local padrão automaticamente quando você executa a execução local e a depuração local. Abra a configuração [Spark on HDInsight] XXX no canto superior direito, você pode ver o [Spark on HDInsight]XXX já criado no Apache Spark no HDInsight. Alterne para a guia Executar localmente.

- Variáveis de ambiente: Se você já definiu a variável de ambiente do sistema HADOOP_HOME como C:\WinUtils, ela poderá detetar automaticamente que não há necessidade de adicionar manualmente.
- WinUtils.exe Localização: Se você não definiu a variável de ambiente do sistema, você pode encontrar o local clicando em seu botão.
- Basta escolher qualquer uma das duas opções e, eles não são necessários no MacOS e Linux.
Você também pode definir a configuração manualmente antes de executar a execução local e a depuração local. Na captura de tela anterior, selecione o sinal de adição (+). Em seguida, selecione a opção Apache Spark no HDInsight . Insira as informações para Nome, Nome da classe principal para salvar e clique no botão Executar local.
Executar depuração local
Abra o script SparkCore_wasbloTest , defina pontos de interrupção.
Clique com o botão direito do mouse no editor de scripts e selecione a opção Depurar '[Faísca no HDInsight]XXX' para executar a depuração local.
Executar execução remota
Navegue até Executar>configurações de edição.... Neste menu, você pode criar ou editar as configurações para depuração remota.
Na caixa de diálogo Executar/Depurar Configurações, selecione o sinal de adição (+). Em seguida, selecione a opção Apache Spark no HDInsight .
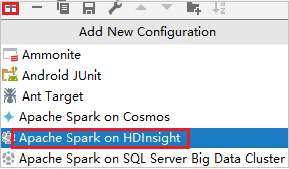
Alterne para a guia Executar remotamente no cluster . Insira informações para Nome, Cluster Spark e Nome da classe Principal. Em seguida, clique em Configuração avançada (Depuração remota). Nossas ferramentas suportam depuração com Executores. O numExectors, o valor padrão é 5. É melhor não definir acima de 3.
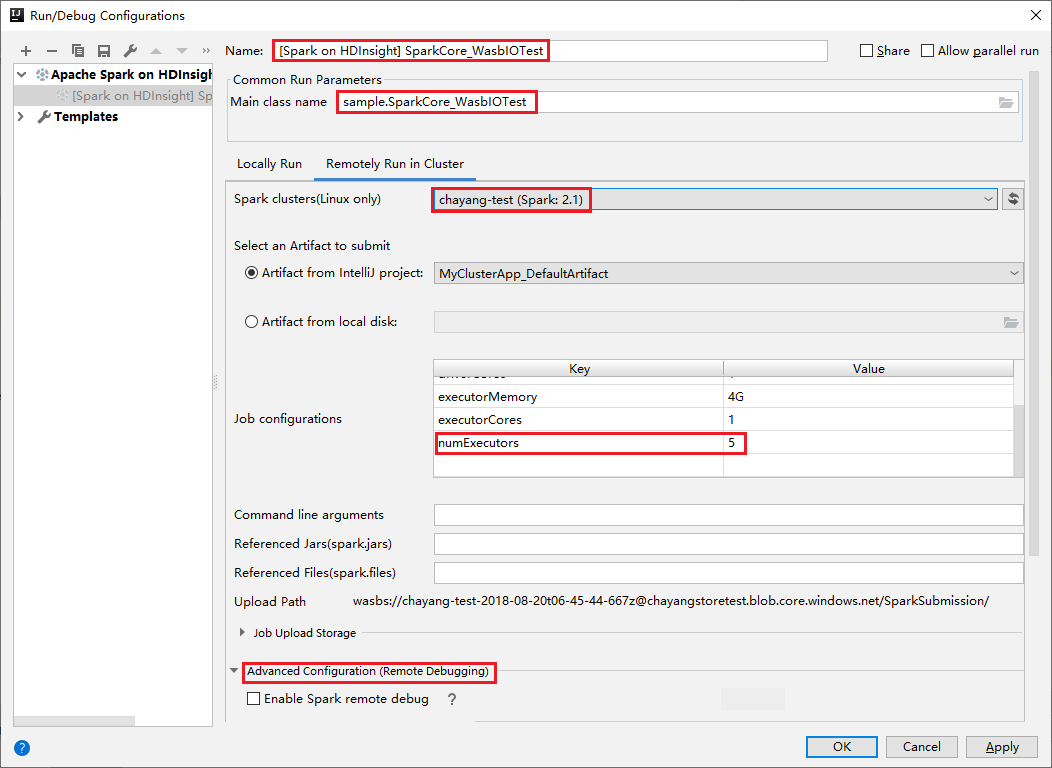
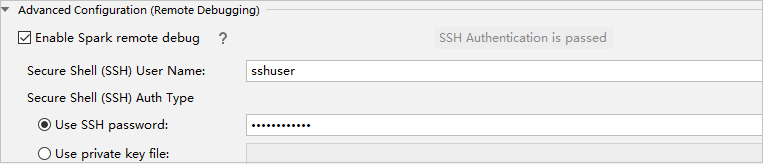
Na parte Configuração Avançada (Depuração Remota), selecione Ativar depuração remota do Spark. Introduza o nome de utilizador SSH e, em seguida, introduza uma palavra-passe ou utilize um ficheiro de chave privada. Se você quiser executar a depuração remota, você precisa configurá-lo. Não há necessidade de configurá-lo se você quiser apenas usar a execução remota.
A configuração agora é salva com o nome que você forneceu. Para visualizar os detalhes da configuração, selecione o nome da configuração. Para fazer alterações, selecione Editar configurações.
Depois de concluir as definições de configurações, você pode executar o projeto no cluster remoto ou executar a depuração remota.

Clique no botão Desconectar para que os logs de envio não apareçam no painel esquerdo. No entanto, ele ainda está sendo executado no back-end.
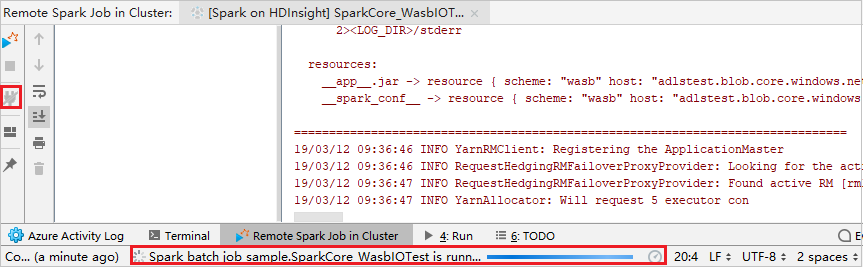
Executar depuração remota
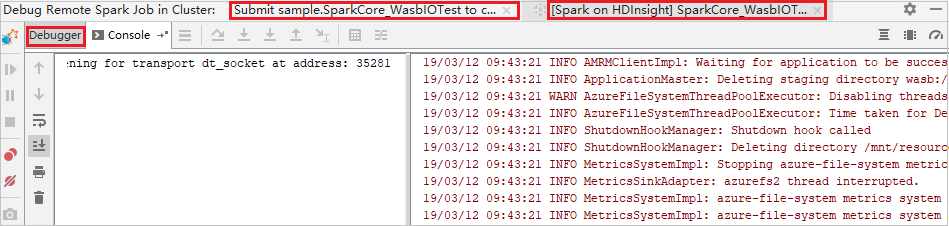
Configure pontos de interrupção e, em seguida, clique no ícone de depuração remota. A diferença com o envio remoto é que o nome de usuário/senha SSH precisa ser configurado.

Quando a execução do programa atinge o ponto de rutura, você vê uma guia Driver e duas guias Executor no painel Depurador . Selecione o ícone Retomar programa para continuar executando o código, que então atinge o próximo ponto de interrupção. Você precisa alternar para a guia Executor correta para encontrar o executor de destino para depurar. Você pode visualizar os logs de execução na guia Console correspondente.
Execute depuração remota e correção de bugs
Configure dois pontos de interrupção e, em seguida, selecione o ícone Depurar para iniciar o processo de depuração remota.
O código para no primeiro ponto de interrupção e as informações de parâmetro e variável são mostradas no painel Variáveis .
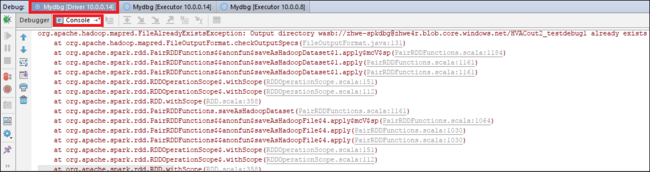
Selecione o ícone Programa de Retomada para continuar. O código para no segundo ponto. A exceção é capturada como esperado.
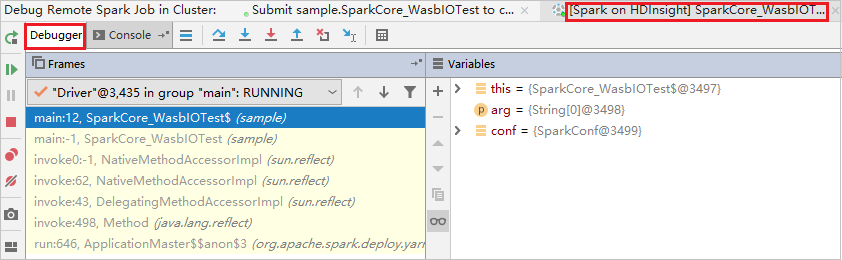
Selecione o ícone Programa de Retomada novamente. A janela Envio do HDInsight Spark exibe um erro "falha na execução do trabalho".
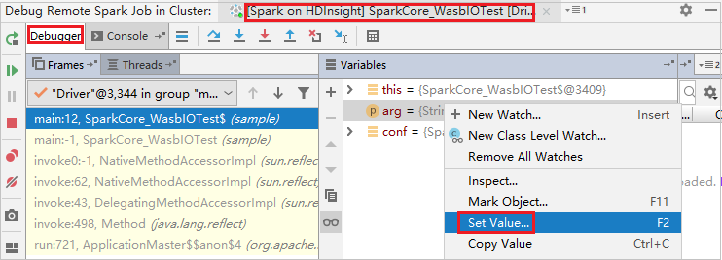
Para atualizar dinamicamente o valor da variável usando o recurso de depuração IntelliJ, selecione Depurar novamente. O painel Variáveis aparece novamente.
Clique com o botão direito do mouse no destino na guia Depurar e selecione Definir Valor. Em seguida, insira um novo valor para a variável. Em seguida, selecione Enter para salvar o valor.
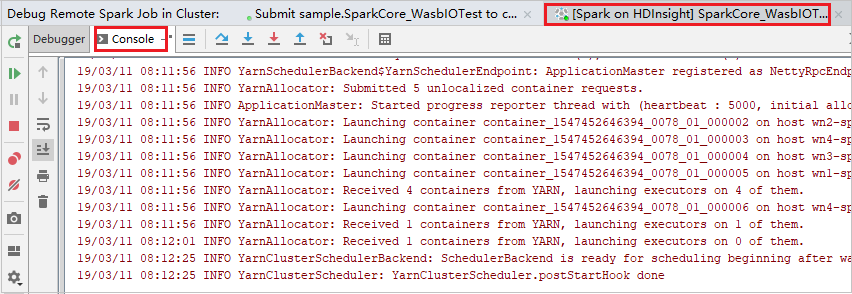
Selecione o ícone Retomar programa para continuar a executar o programa. Desta vez, nenhuma exceção é capturada. Você pode ver que o projeto é executado com êxito sem exceções.
Próximos passos
Cenários
- Apache Spark com BI: execute análises de dados interativas usando o Spark no HDInsight com ferramentas de BI
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever resultados de inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
Criar e executar aplicações
- Criar uma aplicação autónoma com o Scala
- Executar trabalhos remotamente em um cluster Apache Spark usando o Apache Livy
Ferramentas e extensões
- Usar o Kit de Ferramentas do Azure para IntelliJ para criar aplicativos Apache Spark para um cluster HDInsight
- Use o Kit de Ferramentas do Azure para IntelliJ para depurar aplicativos Apache Spark remotamente por meio de VPN
- Usar as Ferramentas do HDInsight no Kit de Ferramentas do Azure para Eclipse para criar aplicativos Apache Spark
- Usar blocos de anotações Apache Zeppelin com um cluster Apache Spark no HDInsight
- Kernels disponíveis para o Jupyter Notebook no cluster Apache Spark para HDInsight
- Use pacotes externos com o Jupyter Notebooks
- Instalar o Jupyter no computador e ligar a um cluster do Spark do HDInsight