Importe os seus dados de formação em Machine Learning Studio (clássico) a partir de várias fontes de dados
APLICA A: O Machine Learning Studio (clássico)
O Machine Learning Studio (clássico)  Aprendizagem de Máquinas Azure
Aprendizagem de Máquinas Azure
Importante
O suporte para o Estúdio de ML (clássico) terminará a 31 de agosto de 2024. Recomendamos a transição para o Azure Machine Learning até essa data.
A partir de 1 de dezembro de 2021, não poderá criar novos recursos do Estúdio de ML (clássico). Até 31 de agosto de 2024, pode continuar a utilizar os recursos existentes do Estúdio de ML (clássico).
- Consulte informações sobre projetos de machine learning em movimento do ML Studio (clássico) para Azure Machine Learning.
- Saiba mais sobre a Azure Machine Learning
A documentação do Estúdio de ML (clássico) está a ser descontinuada e poderá não ser atualizada no futuro.
Para utilizar os seus próprios dados no Machine Learning Studio (clássico) para desenvolver e formar uma solução de análise preditiva, pode utilizar dados a partir de:
- Arquivo local - Carregue os dados locais com antecedência do seu disco rígido para criar um módulo de conjunto de dados no seu espaço de trabalho
- Fontes de dados on-line - Utilize o módulo de Dados de Importação para aceder a dados de uma de várias fontes online enquanto a sua experiência está em execução
- Experiência machine learning studio (clássico) - Use dados que foram guardados como um conjunto de dados no Machine Learning Studio (clássico)
- SQL Server base de dados - Utilize dados de uma base de dados SQL Server sem ter de copiar dados manualmente
Nota
Existem uma série de conjuntos de dados de amostra disponíveis no Machine Learning Studio (clássico) que pode usar para dados de treino. Para obter informações sobre estes, consulte utilize os conjuntos de dados da amostra no Machine Learning Studio (clássico).
Preparar dados
O Machine Learning Studio (clássico) é projetado para trabalhar com dados retangulares ou tabulares, tais como dados de texto que são delimitados ou dados estruturados a partir de uma base de dados, embora em algumas circunstâncias dados não retangulares possam ser usados.
É melhor se os seus dados estiverem relativamente limpos antes de os importar para o Studio (clássico). Por exemplo, vai querer resolver questões como cordas não citadas.
No entanto, existem módulos disponíveis no Studio (clássico) que permitem alguma manipulação de dados dentro da sua experiência depois de importar os seus dados. Dependendo dos algoritmos de aprendizagem automática que vai utilizar, poderá ter de decidir como lidará com questões estruturais de dados, como valores em falta e dados escassos, e há módulos que podem ajudar nisso. Consulte na secção de Transformação de Dados da paleta de módulos para os módulos que desempenham estas funções.
Em qualquer ponto da sua experiência, pode visualizar ou descarregar os dados que são produzidos por um módulo clicando na porta de saída. Dependendo do módulo, pode haver diferentes opções de descarregamento disponíveis, ou poderá visualizar os dados dentro do seu navegador web em Studio (clássico).
Formatos de dados suportados e tipos de dados
Pode importar vários tipos de dados para a sua experiência, dependendo do mecanismo que utiliza para importar dados e de onde vem:
- Texto simples (.txt)
- Valores separados por vírgula (CSV) com cabeçalho (.csv) ou sem (.nh.csv)
- Valores separados por separados por separados (TSV) com um cabeçalho (.tsv) ou sem (.nh.tsv)
- Arquivo Excel
- Tabela do Azure
- Tabela do Hive
- Tabela de base de dados SQL
- Valores OData
- Dados SVMLight (.svmlight) (ver definição SVMLight para informação de formato)
- Atributo Dados do Formato do Ficheiro de Relação (ARFF) (.arff) (ver definição ARFF para informação de formato)
- Arquivo zip (.zip)
- Ficheiro de objeto R ou espaço de trabalho (. RData)
Se importar dados num formato como o ARFF que inclui metadados, o Studio (clássico) utiliza estes metadados para definir o título e o tipo de dados de cada coluna.
Se importar dados como TSV ou formato CSV que não inclua estes metadados, o Studio (clássico) infere o tipo de dados para cada coluna através da amostragem dos dados. Se os dados também não tiverem títulos de coluna, o Studio (clássico) fornece nomes predefinidos.
Pode especificar ou alterar explicitamente os títulos e tipos de dados para colunas utilizando o módulo de metadados de edição .
Os seguintes tipos de dados são reconhecidos pelo Studio (clássico):
- String
- Número inteiro
- Double (Duplo)
- Booleano
- DateTime
- TimeSpan
O estúdio utiliza um tipo de dados interno chamado tabela de dados para passar dados entre módulos. Pode converter explicitamente os seus dados em formato de tabela de dados utilizando o módulo Converte-se para Conjunto de Dados .
Qualquer módulo que aceite formatos que não a tabela de dados converterá os dados em tabela de dados silenciosamente antes de os passar para o módulo seguinte.
Se necessário, pode converter o formato da tabela de dados de volta em formato CSV, TSV, ARFF ou SVMLight utilizando outros módulos de conversão. Consulte na secção de Conversões de Formato de Dados da paleta de módulos para os módulos que desempenham estas funções.
Capacidades de dados
Os módulos do Machine Learning Studio (clássico) suportam conjuntos de dados de até 10 GB de dados numéricos densos para casos de uso comum. Se um módulo precisar de mais do que uma entrada, 10 GB é o valor do tamanho total de todas as entradas de dados. Pode recolher amostras de conjuntos de dados maiores utilizando consultas da Hive ou SQL do Azure Database, ou pode utilizar o pré-processamento learning by Counts antes de importar os dados.
Os seguintes tipos de dados podem ser expandidos para conjuntos de dados de maiores dimensões durante a normalização da funcionalidade, estando limitados a menos de 10 GB:
- Disperso
- Categórico
- Cadeias
- Dados binários
Os seguintes módulos estão limitados a conjuntos de dados inferiores a 10 GB:
- Módulos de recomendador
- Módulo Synthetic Minority Oversampling Technique (SMOTE)
- Módulos de script: R, Python, SQL
- Módulos onde o tamanho dos dados de saída pode ser superior ao tamanho dos dados de entrada, tais como Associação ou Hashing de Funcionalidade
- Validação Cruzada, Hiperparâmetros do Modelo de Otimização, Regressão Ordinal e Multicasse “One-vs-All”, quando o número de iterações é muito grande
Para conjuntos de dados maiores do que um par de GBs, faça o upload dos dados para Azure Storage ou SQL do Azure Database, ou utilize o Azure HDInsight, em vez de fazer o upload diretamente de um ficheiro local.
Pode encontrar informações sobre dados de imagem na referência do módulo Import Images .
Importação de um arquivo local
Pode fazer o upload de um ficheiro de dados do seu disco rígido para utilizar como dados de treino em Studio (clássico). Quando importa um ficheiro de dados, cria um módulo de conjunto de dados pronto a ser utilizado em experiências no seu espaço de trabalho.
Para importar dados de um disco rígido local, faça o seguinte:
- Clique em +NEW na parte inferior da janela Studio (clássica).
- Selecione DATASET e A PARTIR DE ARQUIVO LOCAL.
- No Upload um novo diálogo do conjunto de dados , navegue para o ficheiro que pretende carregar.
- Introduza um nome, identifique o tipo de dados e introduza opcionalmente uma descrição. Recomenda-se uma descrição - permite registar quaisquer características sobre os dados que pretende lembrar ao utilizar os dados no futuro.
- A caixa de verificação Esta é a nova versão de um conjunto de dados existente que permite atualizar um conjunto de dados existente com novos dados. Para tal, clique nesta caixa de verificação e, em seguida, introduza o nome de um conjunto de dados existente.
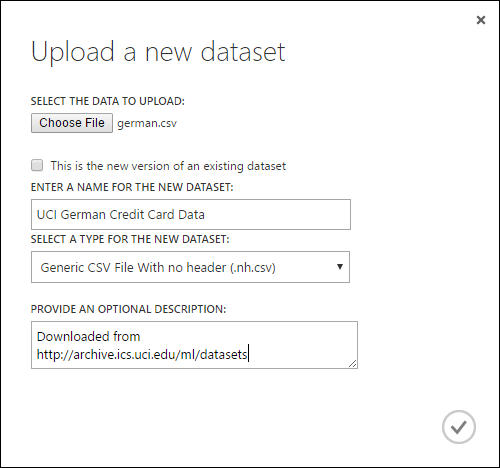
O tempo de upload depende do tamanho dos seus dados e da velocidade da sua ligação ao serviço. Se souber que o ficheiro demorará muito tempo, pode fazer outras coisas dentro do Studio (clássico) enquanto espera. No entanto, fechar o navegador antes do upload de dados é completo faz com que o upload falhe.
Uma vez que os seus dados são carregados, é armazenado num módulo de conjunto de dados e está disponível para qualquer experiência no seu espaço de trabalho.
Quando estiver a editar uma experiência, pode encontrar os conjuntos de dados que carregou na lista my Datasets na lista de Conjuntos de Dados Guardados na paleta de módulos. Pode arrastar e largar o conjunto de dados na tela de experiências quando pretender utilizar o conjunto de dados para análises mais aprofundadas e aprendizagem automática.
Importação de fontes de dados online
Utilizando o módulo De Dados de Importação , a sua experiência pode importar dados de várias fontes de dados online durante a experiência em execução.
Nota
Este artigo fornece informações gerais sobre o módulo de Dados de Importação . Para obter informações mais detalhadas sobre os tipos de dados a que pode aceder, formatos, parâmetros e respostas a questões comuns, consulte o tópico de referência do módulo de referência para o módulo De Dados de Importação .
Ao utilizar o módulo De Dados de Importação , pode aceder aos dados de uma de várias fontes de dados online enquanto a sua experiência está em execução:
- Um URL web usando HTTP
- Hadoop usando HiveQL
- Armazenamento de blobs do Azure
- Tabela do Azure
- Base de Dados SQL do Azure. SQL Managed Instance, ou SQL Server
- Um fornecedor de feed de dados, o OData atualmente
- Azure Cosmos DB
Como estes dados de treino são acedidos enquanto a sua experiência está em execução, só está disponível nessa experiência. Em comparação, os dados que foram armazenados num módulo de conjunto de dados estão disponíveis para qualquer experiência no seu espaço de trabalho.
Para aceder a fontes de dados on-line na sua experiência Studio (clássica), adicione o módulo de Dados de Importação à sua experiência. Em seguida, selecione Launch Import Data Wizard under Properties para obter instruções guiadas passo a passo para selecionar e configurar a fonte de dados. Em alternativa, pode selecionar manualmente a fonte de dados em Propriedades e fornecer os parâmetros necessários para aceder aos dados.
As fontes de dados online que são suportadas estão itemadas na tabela abaixo. Esta tabela também resume os formatos de ficheiros suportados e os parâmetros que são utilizados para aceder aos dados.
Importante
Atualmente, os módulos de Dados de Importação e Dados de Exportação só podem ler e escrever dados a partir do armazenamento Azure criados usando o modelo de implementação Clássico. Por outras palavras, o novo tipo de conta Armazenamento de Blobs do Azure que oferece um nível de acesso de armazenamento quente ou nível de acesso de armazenamento fresco ainda não é suportado.
Geralmente, quaisquer contas de armazenamento Azure que possa ter criado antes desta opção de serviço ficar disponível não devem ser afetadas. Se precisar de criar uma nova conta, selecione Classic para o modelo de Implementação ou utilize o gestor de recursos e selecione o propósito geral em vez do armazenamento blob para o tipo De contas.
Para mais informações, consulte Armazenamento de Blobs do Azure: Níveis de armazenamento quentes e frescos.
Fontes de dados on-line suportadas
O módulo de dados de importação do Machine Learning Studio (clássico) suporta as seguintes fontes de dados:
| Origem de dados | Description | Parâmetros |
|---|---|---|
| Web URL via HTTP | Lê dados em valores separados por vírgulas (CSV), valores separados por separados de separados por separados (TSV), formato de ficheiro de relação de atributos (ARFF) e Máquinas de Vetores de Suporte (luz SVM), a partir de qualquer URL web que utilize HTTP | URL: Especifica o nome completo do ficheiro, incluindo o URL do site e o nome do ficheiro, com qualquer extensão. Formato de dados: Especifica um dos formatos de dados suportados: CSV, TSV, ARFF ou SVM-light. Se os dados ímis ímis agem, é utilizado para atribuir nomes de colunas. |
| Hadoop/HDFS | Lê dados de armazenamento distribuído em Hadoop. Especifica os dados que pretende utilizando o HiveQL, uma linguagem de consulta semelhante ao SQL. O HiveQL também pode ser usado para agregar dados e realizar a filtragem de dados antes de adicionar os dados ao Studio (clássico). | Consulta da base de dados da colmeia: Especifica a consulta de Colmeia utilizada para gerar os dados. HCatalog servidor URI : Especificou o nome do seu cluster utilizando o formato <do seu nome> de cluster.azurehdinsight.net. Nome da conta do utilizador Hadoop: Especifica o nome da conta de utilizador Hadoop utilizada para a provisionação do cluster. Palavra-passe da conta de utilizador Hadoop : Especifica as credenciais utilizadas no fornecimento do cluster. Para obter mais informações, consulte os clusters Create Hadoop em HDInsight. Localização dos dados de saída: Especifica se os dados são armazenados num sistema de ficheiros distribuídos por Hadoop (HDFS) ou em Azure.
Se armazenar os seus dados de saída no Azure, tem de especificar o nome da conta de armazenamento Azure, a chave de acesso ao armazenamento e o nome do contentor de armazenamento. |
| Base de dados SQL | Lê-se dados que são armazenados na base de dados SQL do Azure, SQL Managed Instance ou numa base de dados SQL Server em funcionamento numa máquina virtual Azure. | Nome do servidor da base de dados: Especifica o nome do servidor no qual a base de dados está a funcionar.
No caso de um servidor SQL hospedado numa máquina virtual Azure entrar no TCP:<Virtual Machine DNS Name>, 1433 Nome da base de dados : Especifica o nome da base de dados no servidor. Nome da conta do utilizador do servidor: Especifica um nome de utilizador para uma conta que tem permissões de acesso à base de dados. Senha de conta de utilizador do servidor: Especifica a palavra-passe para a conta de utilizador. Consulta de base de dados:Introduza uma declaração SQL que descreva os dados que pretende ler. |
| Base de dados SQL no local | Lê dados que são armazenados numa base de dados SQL. | Gateway de dados: Especifica o nome do Gateway Gestão de Dados instalado num computador onde pode aceder à sua base de dados SQL Server. Para obter informações sobre a configuração do gateway, consulte Executar análises avançadas com o Machine Learning Studio (clássico) utilizando dados de um servidor SQL. Nome do servidor da base de dados: Especifica o nome do servidor no qual a base de dados está a funcionar. Nome da base de dados : Especifica o nome da base de dados no servidor. Nome da conta do utilizador do servidor: Especifica um nome de utilizador para uma conta que tem permissões de acesso à base de dados. Nome do utilizador e palavra-passe: Clique em Introduzir valores para introduzir as suas credenciais de base de dados. Pode utilizar a autenticação integrada do Windows ou SQL Server autenticação dependendo da configuração do seu SQL Server. Consulta de base de dados:Introduza uma declaração SQL que descreva os dados que pretende ler. |
| Tabela do Azure | Lê dados do serviço table no Azure Storage. Se ler grandes quantidades de dados com pouca frequência, utilize o Serviço de Mesa Azure. Fornece uma solução de armazenamento flexível, não relacional (NoSQL), massivamente escalável, barata e altamente disponível. |
As opções nos Dados de Importação mudam dependendo se você está acedendo a informação pública ou uma conta de armazenamento privado que requer credenciais de login. Isto é determinado pelo Tipo de Autenticação que pode ter valor de "PublicOrSAS" ou "Conta", cada um dos quais tem o seu próprio conjunto de parâmetros. Assinatura de acesso público ou partilhado (SAS) URI: Os parâmetros são:
Especifica as linhas para procurar nomes de propriedade: Os valores são TopN para digitalizar o número especificado de linhas, ou ScanAll para obter todas as linhas na tabela. Se os dados forem homogéneos e previsíveis, recomenda-se que selecione TopN e introduza um número para N. Para mesas grandes, isto pode resultar em tempos de leitura mais rápidos. Se os dados forem estruturados com conjuntos de propriedades que variam em função da profundidade e posição da tabela, escolha a opção ScanAll para digitalizar todas as linhas. Isto garante a integridade da sua propriedade resultante e conversão de metadados.
Chave da conta: Especifica a chave de armazenamento associada à conta. Nome da tabela : Especifica o nome da tabela que contém os dados a ler. Linhas para procurar nomes de propriedade: Os valores são TopN para digitalizar o número especificado de linhas, ou ScanAll para obter todas as linhas na tabela. Se os dados forem homogéneos e previsíveis, recomendamos que selecione TopN e introduza um número para N. Para mesas grandes, isto pode resultar em tempos de leitura mais rápidos. Se os dados forem estruturados com conjuntos de propriedades que variam em função da profundidade e posição da tabela, escolha a opção ScanAll para digitalizar todas as linhas. Isto garante a integridade da sua propriedade resultante e conversão de metadados. |
| Armazenamento de Blobs do Azure | Lê os dados armazenados no serviço Blob no Azure Storage, incluindo imagens, texto não estruturado ou dados binários. Pode utilizar o serviço Blob para expor publicamente dados ou para armazenar dados de aplicações privadas. Pode aceder aos seus dados a partir de qualquer lugar utilizando as ligações HTTP ou HTTPS. |
As opções no módulo De Dados de Importação mudam dependendo se você está acedendo a informação pública ou uma conta de armazenamento privado que requer credenciais de login. Isto é determinado pelo Tipo de Autenticação que pode ter um valor quer de "PublicOrSAS" quer de "Conta". Assinatura de acesso público ou partilhado (SAS) URI: Os parâmetros são:
Formato de ficheiro: Especifica o formato dos dados no serviço Blob. Os formatos suportados são CSV, TSV e ARFF.
Chave da conta: Especifica a chave de armazenamento associada à conta. Caminho para o contentor, diretório ou bolha : Especifica o nome da bolha que contém os dados a ler. Formato de ficheiro Blob: Especifica o formato dos dados no serviço blob. Os formatos de dados suportados são CSV, TSV, ARFF, CSV com uma codificação especificada, e Excel.
Pode utilizar a opção Excel para ler dados dos livros do Excel. Na opção de formato de dados do Excel , indique se os dados estão numa gama de folhas de cálculo do Excel ou numa tabela Excel. Na folha excel ou na opção de mesa incorporada, especifique o nome da folha ou tabela que pretende ler. |
| Fornecedor de feed de dados | Lê dados de um fornecedor de alimentos suportado. Atualmente apenas o formato Do Protocolo de Dados Abertos (OData) é suportado. | Tipo de conteúdo de dados: Especifica o formato OData. URL de origem: Especifica o URL completo para o feed de dados. Por exemplo, o seguinte URL lê-se na base de dados da amostra northwind: https://services.odata.org/northwind/northwind.svc/ |
Importação de outra experiência
Haverá alturas em que vai querer tirar um resultado intermédio de uma experiência e usá-lo como parte de outra experiência. Para tal, guarde o módulo como conjunto de dados:
- Clique na saída do módulo que pretende guardar como conjunto de dados.
- Clique em Guardar como conjunto de dados.
- Quando solicitado, insira um nome e uma descrição que lhe permita identificar facilmente o conjunto de dados.
- Clique na marca de verificação OK .
Quando a poupança terminar, o conjunto de dados estará disponível para utilização em qualquer experiência no seu espaço de trabalho. Pode encontrá-lo na lista de conjuntos de dados guardados na paleta de módulos.