Interpretar os resultados do modelo no Machine Learning Studio (clássico)
APLICA A: Machine Learning Studio (clássico)
Machine Learning Studio (clássico)  Aprendizagem de Máquinas Azure
Aprendizagem de Máquinas Azure
Importante
O suporte para o Estúdio de ML (clássico) terminará a 31 de agosto de 2024. Recomendamos a transição para o Azure Machine Learning até essa data.
A partir de 1 de dezembro de 2021, não poderá criar novos recursos do Estúdio de ML (clássico). Até 31 de agosto de 2024, pode continuar a utilizar os recursos existentes do Estúdio de ML (clássico).
- Consulte informações sobre projetos de machine learning em movimento do ML Studio (clássico) para Azure Machine Learning.
- Saiba mais sobre a Azure Machine Learning
A documentação do Estúdio de ML (clássico) está a ser descontinuada e poderá não ser atualizada no futuro.
Este tópico explica como visualizar e interpretar os resultados da previsão no Machine Learning Studio (clássico). Depois de ter treinado um modelo e feito previsões em cima dele ("marcou o modelo"), é preciso compreender e interpretar o resultado da previsão.
Existem quatro grandes tipos de modelos de machine learning no Machine Learning Studio (clássico):
- Classificação
- Clustering
- Regressão
- Sistemas recomendadores
Os módulos utilizados para a previsão em cima destes modelos são:
- Módulo de modelo de pontuação para classificação e regressão
- Atribuir ao módulo Clusters para agrupamento
- Pontuação Matchbox Recomendador para sistemas de recomendação
Saiba como escolher parâmetros para otimizar os seus algoritmos no ML Studio (clássico).
Para aprender a avaliar os seus modelos, consulte Como avaliar o desempenho do modelo.
Se é novo no ML Studio (clássico), aprenda a criar uma experiência simples.
Classificação
Existem duas subcategorias de problemas de classificação:
- Problemas com apenas duas classes (classificação de duas classes ou binárias)
- Problemas com mais de duas classes (classificação multi-classes)
O Machine Learning Studio (clássico) tem diferentes módulos para lidar com cada um destes tipos de classificação, mas os métodos para interpretar os seus resultados de previsão são semelhantes.
Classificação de duas classes
Experimentação de exemplo
Um exemplo de um problema de classificação de duas classes é a classificação das flores da íris. A tarefa é classificar as flores da íris com base nas suas características. O conjunto de dados da Íris fornecido no Machine Learning Studio (clássico) é um subconjunto do popular conjunto de dados da Íris contendo instâncias de apenas duas espécies de flores (classes 0 e 1). Existem quatro características para cada flor (comprimento sepal, largura sepal, comprimento de pétalas e largura de pétala).
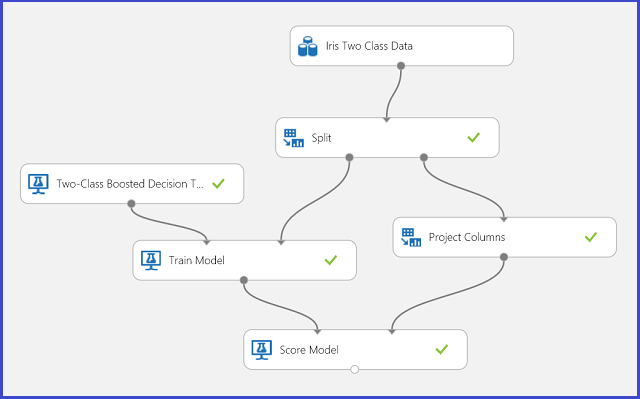
Figura 1: Iris experiência de problema de classificação de duas classes
Foi realizada uma experiência para resolver este problema, como mostra a Figura 1. Um modelo de árvore de decisão reforçada de duas classes foi treinado e pontuado. Agora pode visualizar os resultados da previsão a partir do módulo 'Modelo de Pontuação', clicando na porta de saída do módulo 'Modelo de Pontuação ' e clicando em Visualizar.
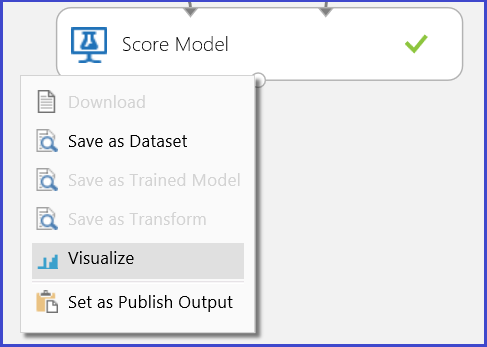
Isto eleva os resultados da pontuação como mostrado na Figura 2.

Figura 2. Visualizar um modelo de pontuação resulta numa classificação de duas classes
Interpretação do resultado
Há seis colunas na tabela de resultados. As quatro colunas esquerdas são as quatro características. As duas colunas direitas, etiquetas pontuadas e probabilidades pontuadas, são os resultados da previsão. A coluna Probabilidades Pontuadas mostra a probabilidade de uma flor pertencer à classe positiva (Classe 1). Por exemplo, o primeiro número da coluna (0.028571) significa que há 0,028571 probabilidade de que a primeira flor pertença à classe 1. A coluna Marcas rótulos mostra a classe prevista para cada flor. Isto baseia-se na coluna De Probabilidades Pontuadas. Se a probabilidade pontuada de uma flor for maior que 0,5, prevê-se como classe 1. Caso contrário, prevê-se como Classe 0.
Publicação de serviço web
Após os resultados da previsão terem sido entendidos e avaliados em som, a experiência pode ser publicada como um serviço web para que você possa implantá-lo em várias aplicações e chamá-lo para obter previsões de classe em qualquer nova flor da íris. Para aprender a transformar uma experiência de formação numa experiência de pontuação e publicá-la como um serviço web, consulte Tutorial 3: Implementar modelo de risco de crédito. Este procedimento proporciona-lhe uma experiência de pontuação como mostrado na Figura 3.
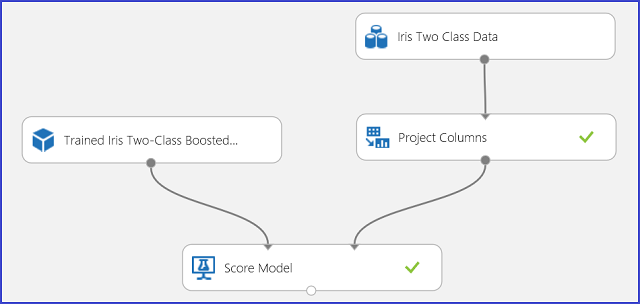
Figura 3. Pontuação da experiência de problema de classificação de duas classes da íris
Agora precisa definir a entrada e saída para o serviço web. A entrada é a porta de entrada certa do Score Model, que é a entrada da flor de Íris. A escolha da saída depende se está interessado na classe prevista (etiqueta pontuada), na probabilidade pontuada, ou em ambos. Neste exemplo, presume-se que está interessado em ambos. Para selecionar as colunas de saída desejadas, utilize um módulo de conjunto de colunas select em dados . Clique em Selecionar Colunas no conjunto de dados, clique no seletor de colunas de lançamento e selecione Etiquetas pontuadas e probabilidades pontuadas. Depois de definir a porta de saída de Colunas Selecionadas no conjunto de dados e executá-la novamente, deve estar pronto para publicar a experiência de pontuação como um serviço web clicando em PUBLISH WEB SERVICE. A experiência final parece a Figura 4.
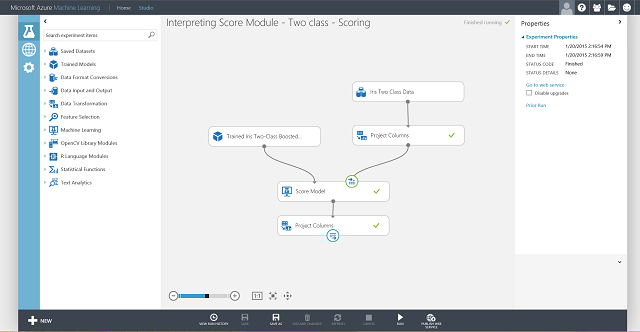
Figura 4. Experiência de pontuação final de um problema de classificação de duas classes da íris
Depois de executar o serviço web e introduzir alguns valores de funcionalidade de uma instância de teste, o resultado devolve dois números. O primeiro número é o rótulo marcado, e o segundo é a probabilidade pontuada. Esta flor é prevista como classe 1 com probabilidade de 0.9655.
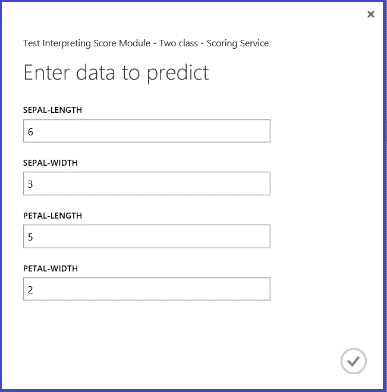

Figura 5. Resultado do serviço web da classificação de duas classes da íris
Classificação multi-classes
Experimentação de exemplo
Nesta experiência, executa uma tarefa de reconhecimento de letras como um exemplo de classificação multiclasse. O classificador tenta prever uma determinada letra %28class%29 com base em alguns valores de atributos escritos à mão extraídos das imagens escritas à mão.
Nos dados de treino, existem 16 funcionalidades extraídas de imagens de cartas escritas à mão. As 26 letras formam as nossas 26 aulas. A figura 6 mostra uma experiência que irá formar um modelo de classificação multiclasse para reconhecimento de letras e prever no mesmo conjunto de recursos num conjunto de dados de teste.
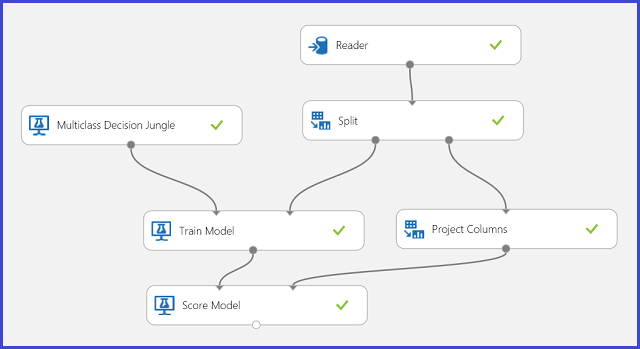
Figura 6. Experiência de problema de classificação multiclasse de reconhecimento de carta
Visualizando os resultados do módulo 'Modelo de Pontuação', clicando na porta de saída do módulo 'Modelo de Pontuação ' e clicando em Visualizar, deverá ver o conteúdo como mostrado na Figura 7.

Figura 7. Visualizar o modelo de pontuação resulta numa classificação multi-classe
Interpretação do resultado
As 16 colunas esquerdas representam os valores de característica do conjunto de testes. As colunas com nomes como Probabilidades Pontuadas para Classe "XX" são como a coluna de Probabilidades Pontuadas no caso de duas classes. Mostram a probabilidade de a entrada correspondente se enquadrar numa determinada classe. Por exemplo, para a primeira entrada, há 0,003571 probabilidade de que seja uma probabilidade "A", 0.000451 de que seja um "B", e assim por diante. A última coluna (Marcas etiquetas) é a mesma que as etiquetas pontuadas no caso de duas classes. Seleciona a classe com maior probabilidade pontuada como a classe prevista da entrada correspondente. Por exemplo, para a primeira entrada, a etiqueta pontuada é "F", uma vez que tem a maior probabilidade de ser um "F" (0,916995).
Publicação de serviço web
Também pode obter a etiqueta pontuada para cada entrada e a probabilidade da etiqueta pontuada. A lógica básica é encontrar a maior probabilidade entre todas as probabilidades pontuadas. Para isso, é necessário utilizar o módulo executar o script R . O código R é mostrado na Figura 8 e o resultado da experiência é mostrado na Figura 9.

Figura 8. Código R para extrair etiquetas pontuais e as probabilidades associadas das etiquetas
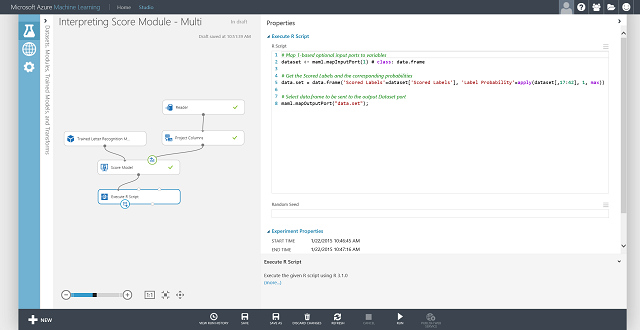
Figura 9. Experiência de pontuação final do problema de classificação multiclasse de reconhecimento de letras
Depois de publicar e executar o serviço web e introduzir alguns valores de funções de entrada, o resultado devolvido parece a Figura 10. Esta carta escrita à mão, com as suas 16 características extraídas, prevê-se que seja um "T" com probabilidade de 0,9715.
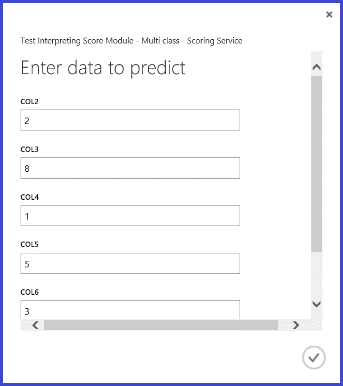

Figura 10. Resultado do serviço web da classificação multiclasse
Regressão
Os problemas de regressão são diferentes dos problemas de classificação. Num problema de classificação, estás a tentar prever classes discretas, como a classe a que pertence uma flor de íris. Mas como pode ver no exemplo seguinte de um problema de regressão, está a tentar prever uma variável contínua, como o preço de um carro.
Experimentação de exemplo
Use a previsão do preço do automóvel como exemplo para regressão. Está a tentar prever o preço de um carro com base nas suas características, incluindo a gata, tipo de combustível, tipo de carroça e roda de tração. A experiência é mostrada na Figura 11.
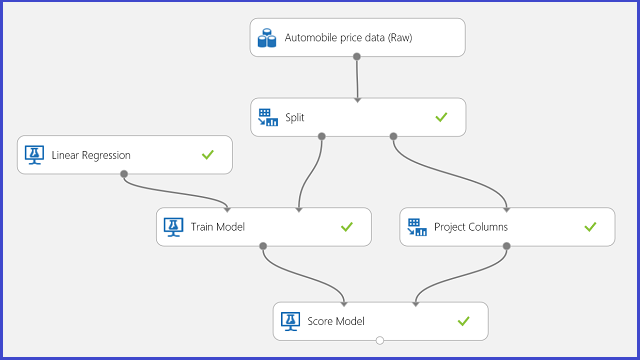
Figura 11. Experiência de problema de regressão do preço do automóvel
Visualizando o módulo do Modelo de Pontuação , o resultado parece a Figura 12.
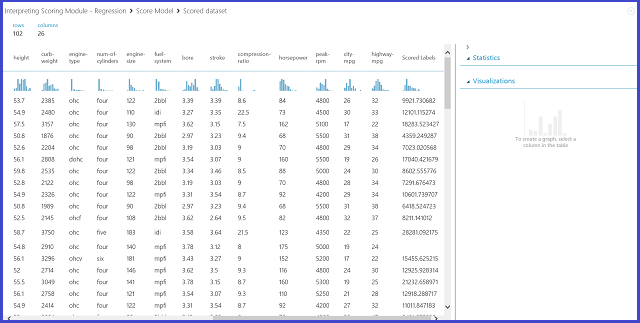
Figura 12. Resultado da pontuação para o problema da previsão dos preços do automóvel
Interpretação do resultado
Etiquetas pontuadas é a coluna de resultados neste resultado de pontuação. Os números são o preço previsto para cada carro.
Publicação de serviço web
Pode publicar a experiência de regressão num serviço web e chamá-la para a previsão do preço do automóvel da mesma forma que no caso de utilização de classificação de duas classes.
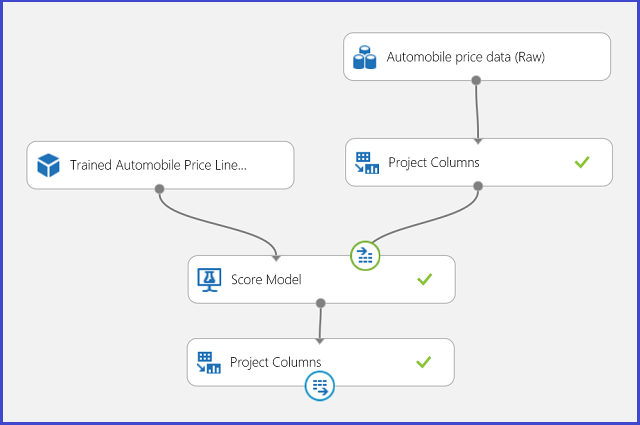
Figura 13. Experiência de pontuação de um problema de regressão dos preços do automóvel
Executando o serviço web, o resultado devolvido parece a Figura 14. O preço previsto para este carro é $15.085,52.
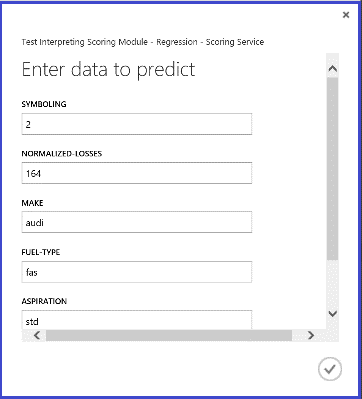

Figura 14. Serviço web resultado de um problema de regressão dos preços do automóvel
Clustering
Experimentação de exemplo
Vamos usar o conjunto de dados da Íris novamente para construir uma experiência de agrupamento. Aqui pode filtrar as etiquetas de classe no conjunto de dados para que tenha apenas características e possa ser usada para o agrupamento. Neste caso de uso da íris, especifique o número de aglomerados a serem dois durante o processo de treino, o que significa que você iria agrupar as flores em duas classes. A experiência é mostrada na Figura 15.
Figura 15. Experiência de problema de agrupamento de íris
O agrupamento difere da classificação, na medida em que o conjunto de dados de treino não tem rótulos de verdade por si só. Agrupamentos de agrupamentos os dados de formação definem casos em agrupamentos distintos. Durante o processo de treino, o modelo rotula as entradas aprendendo as diferenças entre as suas características. Depois disso, o modelo treinado pode ser usado para classificar ainda mais as entradas futuras. Há duas partes do resultado que nos interessam num problema de agrupamento. A primeira parte é a rotulagem do conjunto de dados de formação, e a segunda é classificar um novo conjunto de dados com o modelo treinado.
A primeira parte do resultado pode ser visualizada clicando na porta de saída esquerda do Modelo de Clustering de Comboio e, em seguida, clicando em Visualizar. A visualização é mostrada na Figura 16.
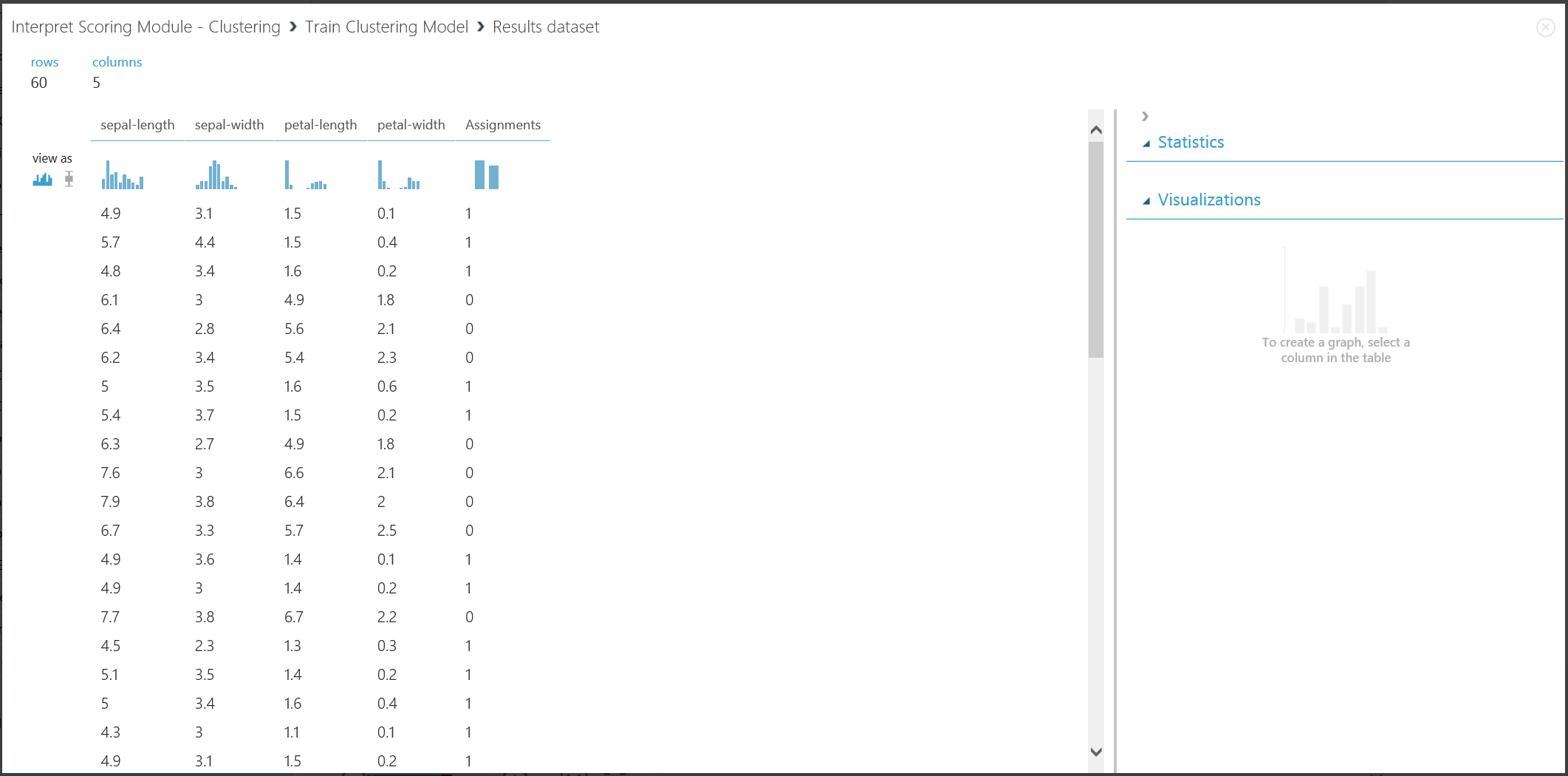
Figura 16. Visualizar o resultado do agrupamento para o conjunto de dados de formação
O resultado da segunda parte, agrupando novas entradas com o modelo de agrupamento treinado, é mostrado na Figura 17.
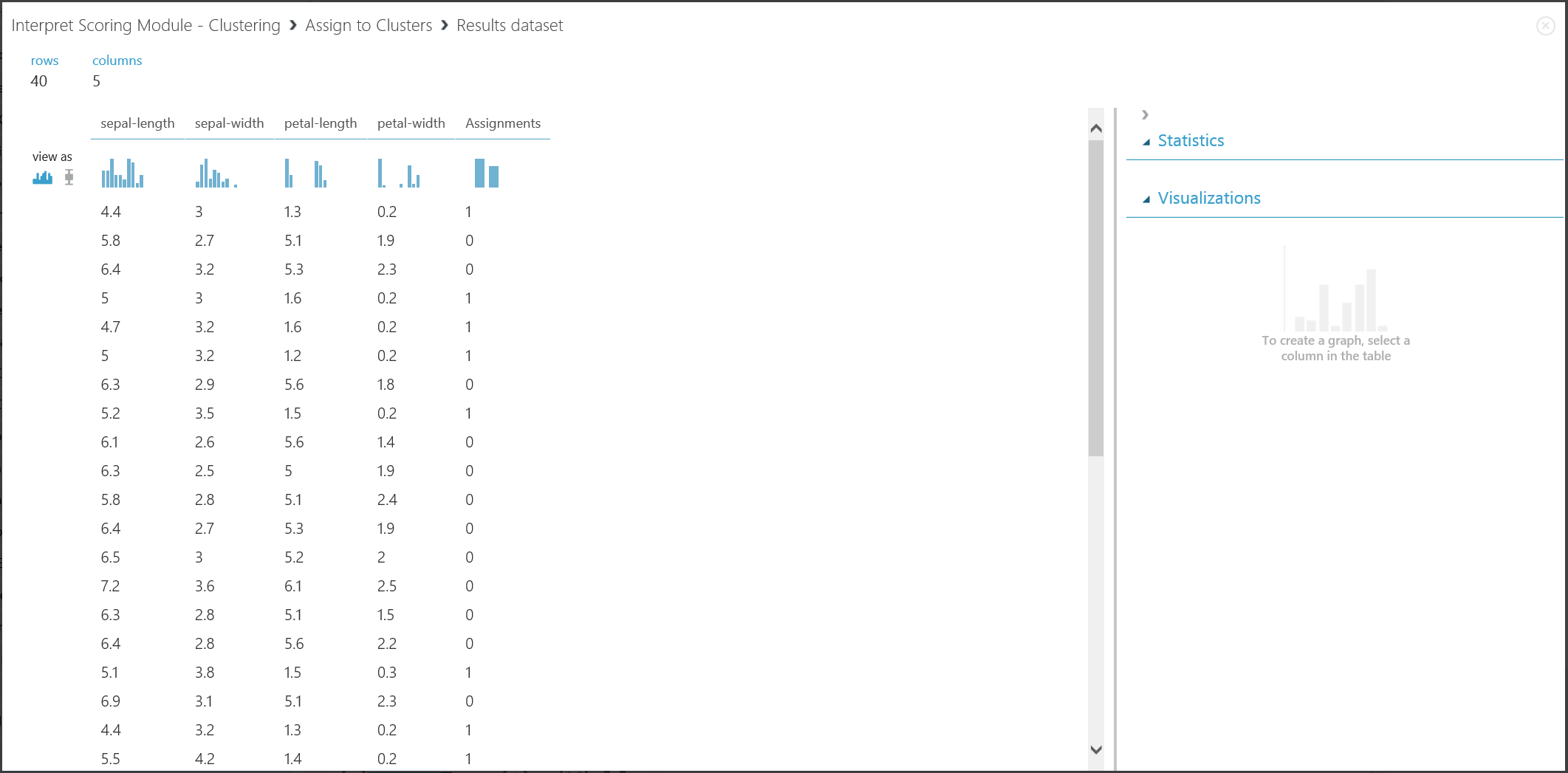
Figura 17. Visualizar o resultado do agrupamento num novo conjunto de dados
Interpretação do resultado
Embora os resultados das duas partes procorrem de diferentes fases de experiência, elas são iguais e são interpretadas da mesma forma. As primeiras quatro colunas são características. A última coluna, Atribuições, é o resultado da previsão. Prevê-se que as entradas atribuídas ao mesmo número estejam no mesmo cluster, ou seja, partilham semelhanças de alguma forma (esta experiência utiliza a métrica de distância euclidana padrão). Como especificou o número de clusters a ser 2, as entradas em Atribuições são rotuladas como 0 ou 1.
Publicação de serviço web
Você pode publicar a experiência de clustering em um serviço web e chamá-lo para previsões de clustering da mesma forma que no caso de utilização de classificação de duas classes.
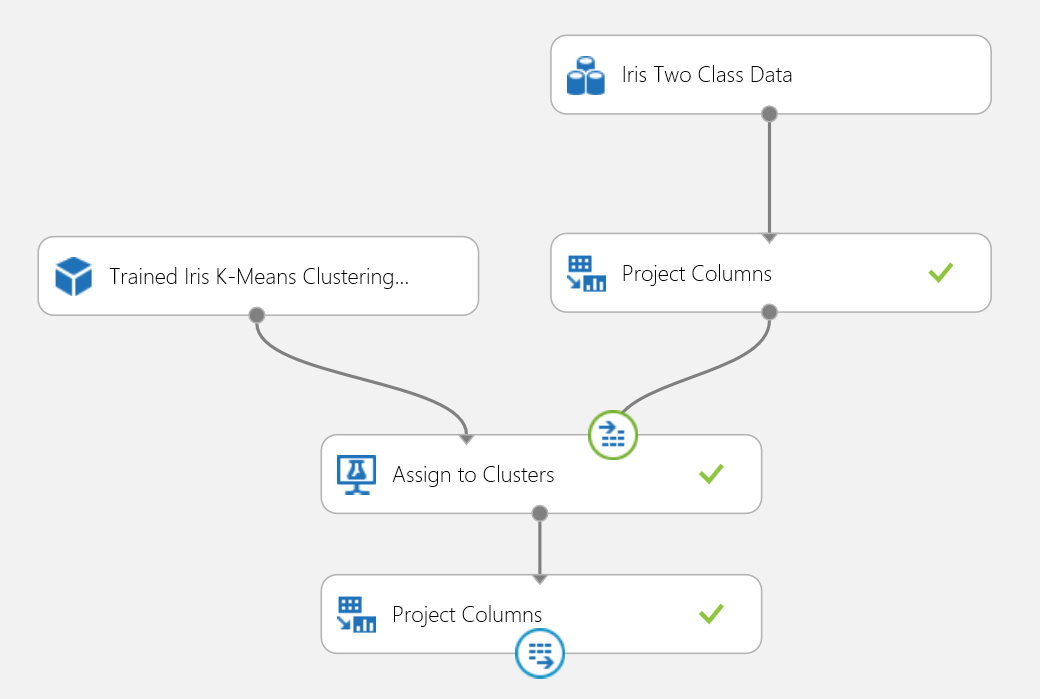
Figura 18. Experiência de pontuação de um problema de agrupamento de íris
Depois de executar o serviço web, o resultado devolvido parece a Figura 19. Prevê-se que esta flor esteja no aglomerado 0.


Figura 19. Resultado do serviço web da classificação de duas classes da íris
Sistema de recomendadores
Experimentação de exemplo
Para sistemas de recomendação, pode usar o problema da recomendação do restaurante como exemplo: pode recomendar restaurantes para clientes com base no seu histórico de classificação. Os dados de entrada consistem em três partes:
- Classificações de restaurantes dos clientes
- Dados de funcionalidades do cliente
- Dados de recursos de restaurante
Há várias coisas que podemos fazer com o módulo de recomendador train Matchbox no Machine Learning Studio (clássico):
- Prever classificações para um determinado utilizador e item
- Recomendar itens a um determinado utilizador
- Localizar utilizadores relacionados com um determinado utilizador
- Encontre itens relacionados com um determinado item
Pode escolher o que pretende fazer selecionando a partir das quatro opções no menu de previsão Recomendador . Aqui podes andar pelos quatro cenários.
Uma experiência típica do Machine Learning Studio (clássico) para um sistema de recomendadores parece a Figura 20. Para obter informações sobre como utilizar os módulos do sistema recomendadores, consulte o recomendador train matchbox e o recomendador score matchbox.
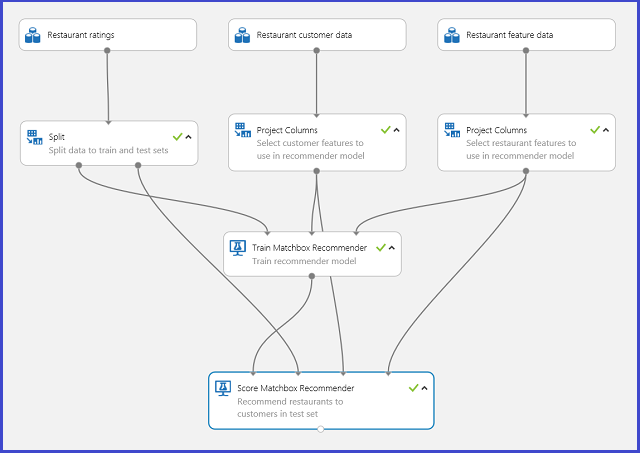
Figura 20. Experiência do sistema recomendador
Interpretação do resultado
Prever classificações para um determinado utilizador e item
Ao selecionar a Previsão de Classificação sob o tipo de previsão De recomendor, está a pedir ao sistema de recomendadores que preveja a classificação para um determinado utilizador e item. A visualização da saída do Recomendador score Matchbox parece a Figura 21.
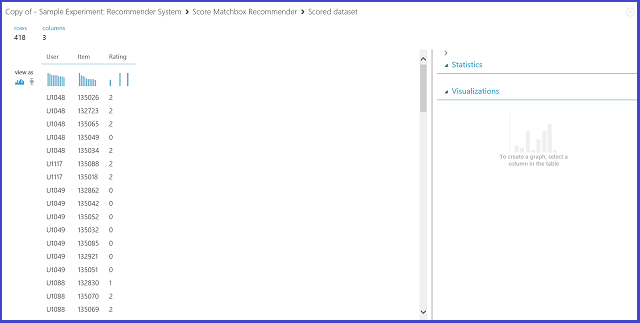
Figura 21. Visualizar o resultado da pontuação do sistema de recomendação-- previsão de classificação
As duas primeiras colunas são os pares de artigos de utilizador fornecidos pelos dados de entrada. A terceira coluna é a classificação prevista de um utilizador para um determinado item. Por exemplo, na primeira fila, prevê-se que o cliente U1048 classifique o restaurante 135026 como 2.
Recomendar itens a um determinado utilizador
Ao selecionar a Recomendação de Artigos sob o tipo de previsão De recomendor, está a pedir ao sistema de recomendação que recomende itens a um determinado utilizador. O último parâmetro a escolher neste cenário é a seleção recomendada de artigos. A opção From Rated Items (para avaliação de modelos) destina-se principalmente à avaliação do modelo durante o processo de treino. Para esta fase de previsão, escolhemos De Todos os Itens. A visualização da saída do Recomendador score Matchbox parece a Figura 22.
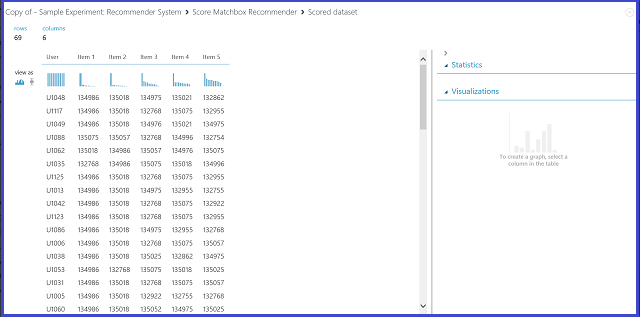
Figura 22. Visualizar o resultado da pontuação do sistema de recomendação-- recomendação de artigo
A primeira das seis colunas representa os IDs do utilizador para recomendar itens, conforme fornecidos pelos dados de entrada. As outras cinco colunas representam os itens recomendados ao utilizador por ordem descendente de relevância. Por exemplo, na primeira fila, o restaurante mais recomendado para o cliente U1048 é 134986, seguido por 135018, 134975, 135021 e 132862.
Localizar utilizadores relacionados com um determinado utilizador
Ao selecionar utilizadores relacionados sob o tipo de previsão Recommender, está a pedir ao sistema de recomendadores que encontre utilizadores relacionados a um determinado utilizador. Os utilizadores relacionados são os utilizadores que têm preferências semelhantes. O último parâmetro a escolher neste cenário é a seleção do utilizador relacionado. A opção dos utilizadores que avaliaram os itens (para avaliação de modelos) destina-se principalmente à avaliação do modelo durante o processo de treino. Escolha entre todos os utilizadores para esta fase de previsão. A visualização da saída do Recomendador score Matchbox parece a Figura 23.
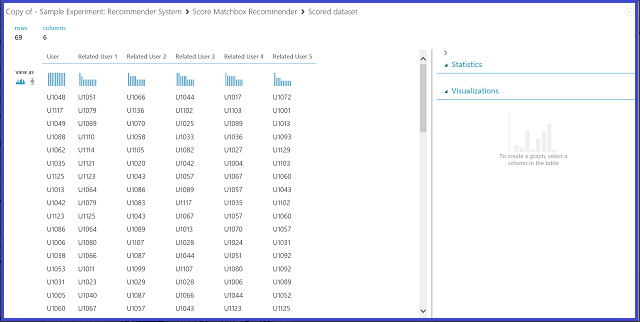
Figura 23. Visualizar os resultados da pontuação dos utilizadores do sistema de recomendação-relacionados com o sistema
A primeira das seis colunas mostra os IDs de utilizador necessários para encontrar utilizadores relacionados, conforme fornecidos pelos dados de entrada. As outras cinco colunas armazenam os utilizadores relacionados previstos do utilizador em ordem descendente de relevância. Por exemplo, na primeira linha, o cliente mais relevante para o cliente U1048 é o U1051, seguido por U1066, U1044, U1017 e U1072.
Encontre itens relacionados com um determinado item
Ao selecionar Itens Relacionados sob o tipo de previsão Recomendador, está a pedir ao sistema de recomendadores que encontre itens relacionados a um determinado item. Os itens relacionados são os itens mais propensos a serem apreciados pelo mesmo utilizador. O último parâmetro a escolher neste cenário é a seleção de artigos relacionados. A opção From Rated Items (para avaliação de modelos) destina-se principalmente à avaliação do modelo durante o processo de treino. Escolhemos De Todos os Itens para esta fase de previsão. A visualização da saída do Recomendador score Matchbox parece a Figura 24.
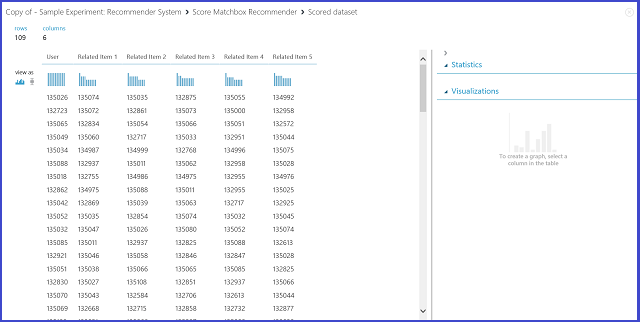
Figura 24. Visualizar os resultados da pontuação dos itens relacionados com o sistema de recomendadores
A primeira das seis colunas representa os IDs de item necessários para encontrar itens relacionados, conforme fornecidos pelos dados de entrada. As outras cinco colunas armazenam os itens relacionados previstos do artigo em ordem descendente em termos de relevância. Por exemplo, na primeira linha, o item mais relevante para o item 135026 é 135074, seguido de 135035, 132875, 135055 e 134992.
Publicação de serviço web
O processo de publicação destas experiências como serviços web para obter previsões é semelhante para cada um dos quatro cenários. Aqui levamos o segundo cenário (recomendar itens a um determinado utilizador) como um exemplo. Pode seguir o mesmo procedimento com os outros três.
Guardar o sistema de recomendadores treinado como um modelo treinado e filtrar os dados de entrada para uma única coluna de ID do utilizador, conforme solicitado, pode ligar a experiência como na Figura 25 e publicá-la como um serviço web.
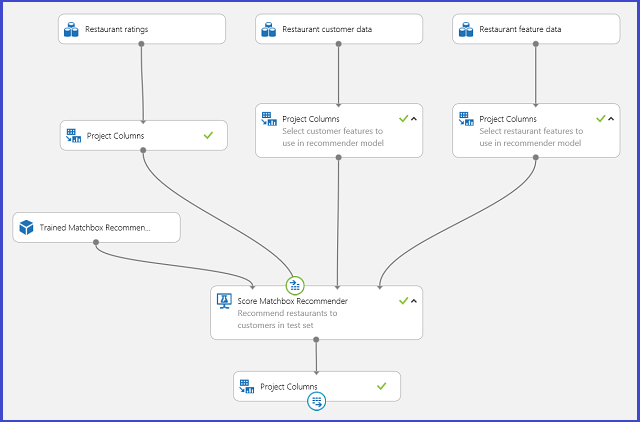
Figura 25. Experiência de pontuação do problema da recomendação do restaurante
Executando o serviço web, o resultado devolvido parece a Figura 26. Os cinco restaurantes recomendados para o utilizador U1048 são 134986, 135018, 134975, 135021 e 132862.
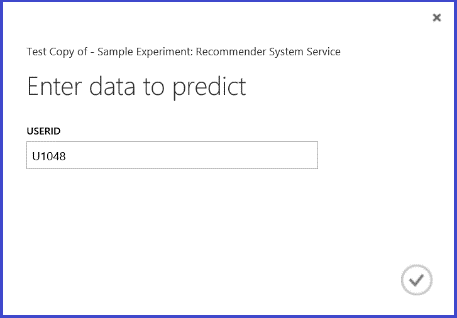

Figura 26. Serviço web resultado do problema da recomendação do restaurante