Preparar modelos Keras em escala com o Azure Machine Learning
APLICA-SE A:  SDK python azure-ai-ml v2 (atual)
SDK python azure-ai-ml v2 (atual)
Neste artigo, saiba como executar os scripts de preparação do Keras com o SDK Python v2 do Azure Machine Learning.
O código de exemplo neste artigo utiliza o Azure Machine Learning para preparar, registar e implementar um modelo Keras criado com o back-end tensorFlow. O modelo, uma rede neural profunda (DNN) criada com a biblioteca do Keras Python em execução no TensorFlow, classifica os dígitos manuscritos do popular conjunto de dados MNIST.
O Keras é uma API de rede neural de alto nível capaz de executar o topo de outras arquiteturas DNN populares para simplificar o desenvolvimento. Com o Azure Machine Learning, pode aumentar horizontalmente os trabalhos de preparação com recursos de computação na cloud elástica. Também pode controlar as suas execuções de preparação, modelos de versão, implementar modelos e muito mais.
Quer esteja a desenvolver um modelo Keras a partir do zero ou esteja a trazer um modelo existente para a cloud, o Azure Machine Learning pode ajudá-lo a criar modelos prontos para produção.
Nota
Se estiver a utilizar a API keras tf.keras incorporada no TensorFlow e não o pacote Keras autónomo, veja Preparar modelos do TensorFlow.
Pré-requisitos
Para beneficiar deste artigo, terá de:
- Aceda a uma subscrição do Azure. Se ainda não tiver uma, crie uma conta gratuita.
- Execute o código neste artigo com uma instância de computação do Azure Machine Learning ou o seu próprio bloco de notas do Jupyter.
- Instância de computação do Azure Machine Learning – não são necessárias transferências ou instalações
- Conclua Criar recursos para começar a criar um servidor de blocos de notas dedicado pré-carregado com o SDK e o repositório de exemplo.
- Na pasta de aprendizagem profunda de exemplos no servidor de blocos de notas, localize um bloco de notas concluído e expandido ao navegar para este diretório: tarefas python de sdk > v2 > trabalhos de tensorflow >>> de passo > único train-hyperparameter-tune-deploy-with-keras.
- O seu servidor de blocos de notas do Jupyter
- Instância de computação do Azure Machine Learning – não são necessárias transferências ou instalações
- Transfira os scripts de preparação keras_mnist.py e utils.py.
Também pode encontrar uma versão Jupyter Notebook completa deste guia na página de exemplos do GitHub.
Antes de poder executar o código neste artigo para criar um cluster de GPU, terá de pedir um aumento de quota para a área de trabalho.
Configurar a tarefa
Esta secção configura a tarefa de preparação ao carregar os pacotes Python necessários, ligar a uma área de trabalho, criar um recurso de computação para executar uma tarefa de comando e criar um ambiente para executar a tarefa.
Ligar à área de trabalho
Primeiro, terá de se ligar à área de trabalho do Azure Machine Learning. A área de trabalho do Azure Machine Learning é o recurso de nível superior do serviço. Fornece-lhe um local centralizado para trabalhar com todos os artefactos que cria quando utiliza o Azure Machine Learning.
Estamos a utilizar DefaultAzureCredential para obter acesso à área de trabalho. Esta credencial deve ser capaz de processar a maioria dos cenários de autenticação do SDK do Azure.
Se DefaultAzureCredential não funcionar para si, consulte azure-identity reference documentation ou Set up authentication para obter mais credenciais disponíveis.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Se preferir utilizar um browser para iniciar sessão e autenticar, deve anular o comentário do seguinte código e utilizá-lo.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Em seguida, obtenha uma alça para a área de trabalho ao fornecer o ID da Subscrição, o nome do Grupo de Recursos e o nome da área de trabalho. Para localizar estes parâmetros:
- Procure o nome da área de trabalho no canto superior direito da barra de ferramentas estúdio do Azure Machine Learning.
- Selecione o nome da área de trabalho para mostrar o Grupo de Recursos e o ID da Subscrição.
- Copie os valores do Grupo de Recursos e do ID da Subscrição para o código.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)O resultado da execução deste script é uma alça de área de trabalho que irá utilizar para gerir outros recursos e tarefas.
Nota
- A criação
MLClientnão ligará o cliente à área de trabalho. A inicialização do cliente é preguiçosa e aguardará pela primeira vez que precisar de fazer uma chamada. Neste artigo, isto acontecerá durante a criação da computação.
Criar um recurso de computação para executar a tarefa
O Azure Machine Learning precisa de um recurso de computação para executar uma tarefa. Este recurso pode ser uma máquina única ou com vários nós com Linux ou SO Windows, ou um recurso de computação específico, como o Spark.
No script de exemplo seguinte, aprovisionamos um Linux compute cluster. Pode ver a Azure Machine Learning pricing página para obter a lista completa dos tamanhos e preços das VMs. Uma vez que precisamos de um cluster de GPU para este exemplo, vamos escolher um modelo de STANDARD_NC6 e criar uma computação do Azure Machine Learning.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Criar um ambiente de trabalho
Para executar uma tarefa do Azure Machine Learning, precisará de um ambiente. Um ambiente do Azure Machine Learning encapsula as dependências (como o runtime de software e bibliotecas) necessárias para executar o script de preparação de machine learning no recurso de computação. Este ambiente é semelhante a um ambiente Python no seu computador local.
O Azure Machine Learning permite-lhe utilizar um ambiente organizado (ou pronto) ou criar um ambiente personalizado com uma imagem do Docker ou uma configuração do Conda. Neste artigo, irá criar um ambiente conda personalizado para as suas tarefas com um ficheiro YAML conda.
Criar um ambiente personalizado
Para criar o seu ambiente personalizado, irá definir as dependências do Conda num ficheiro YAML. Primeiro, crie um diretório para armazenar o ficheiro. Neste exemplo, nomeámos o diretório dependencies.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)Em seguida, crie o ficheiro no diretório de dependências. Neste exemplo, nomeámos o ficheiro conda.yml.
%%writefile {dependencies_dir}/conda.yaml
name: keras-env
channels:
- conda-forge
dependencies:
- python=3.8
- pip=21.2.4
- pip:
- protobuf~=3.20
- numpy==1.22
- tensorflow-gpu==2.2.0
- keras<=2.3.1
- matplotlib
- azureml-mlflow==1.42.0A especificação contém alguns pacotes habituais (como numpy e pip) que irá utilizar na sua tarefa.
Em seguida, utilize o ficheiro YAML para criar e registar este ambiente personalizado na sua área de trabalho. O ambiente será empacotado num contentor do Docker no runtime.
from azure.ai.ml.entities import Environment
custom_env_name = "keras-env"
job_env = Environment(
name=custom_env_name,
description="Custom environment for keras image classification",
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
job_env = ml_client.environments.create_or_update(job_env)
print(
f"Environment with name {job_env.name} is registered to workspace, the environment version is {job_env.version}"
)Para obter mais informações sobre como criar e utilizar ambientes, veja Criar e utilizar ambientes de software no Azure Machine Learning.
Configurar e submeter a tarefa de preparação
Nesta secção, vamos começar por introduzir os dados para preparação. Em seguida, vamos abordar como executar um trabalho de preparação com um script de preparação que fornecemos. Irá aprender a criar a tarefa de preparação ao configurar o comando para executar o script de preparação. Em seguida, irá submeter a tarefa de preparação para ser executada no Azure Machine Learning.
Obter os dados de preparação
Irá utilizar dados da base de dados modificado do Instituto Nacional de Normas e Tecnologia (MNIST) de dígitos manuscritos. Estes dados são obtidos a partir do site de Yan LeCun e armazenados numa conta de armazenamento do Azure.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Para obter mais informações sobre o conjunto de dados MNIST, visite o site de Yan LeCun.
Preparar o script de preparação
Neste artigo, fornecemos o script de preparação keras_mnist.py. Na prática, deve conseguir utilizar qualquer script de preparação personalizado como está e executá-lo com o Azure Machine Learning sem ter de modificar o código.
O script de preparação fornecido faz o seguinte:
- processa o pré-processamento de dados, dividindo os dados em dados de teste e preparação;
- prepara um modelo com os dados; e
- devolve o modelo de saída.
Durante a execução do pipeline, irá utilizar o MLFlow para registar os parâmetros e as métricas. Para saber como ativar o controlo do MLFlow, veja Controlar experimentações de ML e modelos com o MLflow.
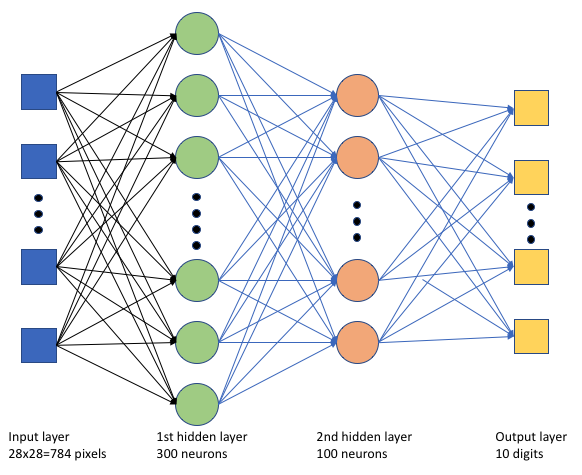
No script keras_mnist.pyde preparação , criamos uma rede neural profunda (DNN) simples. Este DNN tem:
- Uma camada de entrada com 28 * 28 = 784 neurónios. Cada neurónio representa um pixel de imagem.
- Duas camadas ocultas. A primeira camada oculta tem 300 neurónios e a segunda camada oculta tem 100 neurónios.
- Uma camada de saída com 10 neurónios. Cada neurónio representa uma etiqueta de destino de 0 a 9.
Criar a tarefa de preparação
Agora que tem todos os recursos necessários para executar a sua tarefa, está na altura de o criar com o SDK Python v2 do Azure Machine Learning. Neste exemplo, vamos criar um command.
Um Azure Machine Learning command é um recurso que especifica todos os detalhes necessários para executar o código de preparação na cloud. Estes detalhes incluem as entradas e saídas, o tipo de hardware a utilizar, o software a instalar e como executar o código. Contém command informações para executar um único comando.
Configurar o comando
Irá utilizar o objetivo command geral para executar o script de preparação e realizar as tarefas pretendidas. Crie um Command objeto para especificar os detalhes de configuração da sua tarefa de preparação.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=50,
first_layer_neurons=300,
second_layer_neurons=100,
learning_rate=0.001,
),
compute=gpu_compute_target,
environment=f"{job_env.name}:{job_env.version}",
code="./src/",
command="python keras_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="keras-dnn-image-classify",
display_name="keras-classify-mnist-digit-images-with-dnn",
)As entradas para este comando incluem a localização de dados, o tamanho do lote, o número de neurónios na primeira e segunda camada e a taxa de aprendizagem. Tenha em atenção que transmitimos o caminho Web diretamente como uma entrada.
Para os valores dos parâmetros:
- forneça o cluster
gpu_compute_target = "gpu-cluster"de computação que criou para executar este comando; - forneça o ambiente
keras-envpersonalizado que criou para executar a tarefa do Azure Machine Learning; - configure a ação da linha de comandos em si— neste caso, o comando é
python keras_mnist.py. Pode aceder às entradas e saídas no comando através da${{ ... }}notação; e - configurar metadados, como o nome a apresentar e o nome da experimentação; em que uma experimentação é um contentor para todas as iterações que se faz num determinado projeto. Todos os trabalhos submetidos com o mesmo nome de experimentação seriam listados um ao lado do outro no estúdio do Azure Machine Learning.
- forneça o cluster
Neste exemplo, irá utilizar o
UserIdentitypara executar o comando. Utilizar uma identidade de utilizador significa que o comando utilizará a sua identidade para executar a tarefa e aceder aos dados a partir do blob.
Submeter o trabalho
Chegou a altura de submeter a tarefa a ser executada no Azure Machine Learning. Desta vez, irá utilizar create_or_update em ml_client.jobs.
ml_client.jobs.create_or_update(job)Depois de concluída, a tarefa registará um modelo na área de trabalho (como resultado da preparação) e produzirá uma ligação para visualizar a tarefa no estúdio do Azure Machine Learning.
Aviso
O Azure Machine Learning executa scripts de preparação ao copiar todo o diretório de origem. Se tiver dados confidenciais que não pretende carregar, utilize um ficheiro .ignore ou não os inclua no diretório de origem.
O que acontece durante a execução do trabalho
À medida que a tarefa é executada, passa pelas seguintes fases:
Preparação: é criada uma imagem do docker de acordo com o ambiente definido. A imagem é carregada para o registo de contentor da área de trabalho e colocada em cache para execuções posteriores. Os registos também são transmitidos para o histórico de tarefas e podem ser visualizados para monitorizar o progresso. Se for especificado um ambiente organizado, será utilizada a cópia de segurança da imagem em cache que o ambiente organizado.
Dimensionamento: o cluster tenta aumentar verticalmente se precisar de mais nós para executar a execução do que está atualmente disponível.
Em execução: todos os scripts na pasta de script src são carregados para o destino de computação, os arquivos de dados são montados ou copiados e o script é executado. As saídas do stdout e da pasta ./logs são transmitidas em fluxo para o histórico de tarefas e podem ser utilizadas para monitorizar a tarefa.
Otimizar hiperparâmetros de modelo
Preparou o modelo com um conjunto de parâmetros, vamos agora ver se consegue melhorar ainda mais a precisão do modelo. Pode otimizar e otimizar os hiperparâmetros do modelo com as capacidades do sweep Azure Machine Learning.
Para otimizar os hiperparâmetros do modelo, defina o espaço de parâmetros no qual pretende procurar durante a preparação. Irá fazê-lo ao substituir alguns dos parâmetros (batch_size, , first_layer_neuronssecond_layer_neuronse learning_rate) transmitidos para a tarefa de preparação por entradas especiais do azure.ml.sweep pacote.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[25, 50, 100]),
first_layer_neurons=Choice(values=[10, 50, 200, 300, 500]),
second_layer_neurons=Choice(values=[10, 50, 200, 500]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Em seguida, irá configurar o varrimento na tarefa de comando, utilizando alguns parâmetros específicos de varrimento, como a métrica primária para watch e o algoritmo de amostragem a utilizar.
No código seguinte, utilizamos a amostragem aleatória para experimentar diferentes conjuntos de configuração de hiperparâmetros numa tentativa de maximizar a nossa métrica primária, validation_acc.
Também definimos uma política de cessação antecipada: o BanditPolicy. Esta política funciona ao verificar a tarefa a cada duas iterações. Se a métrica primária, validation_acc, ficar fora do intervalo de 10%, o Azure Machine Learning irá terminar a tarefa. Isto impede o modelo de continuar a explorar hiperparâmetros que não mostram nenhuma promessa de ajudar a alcançar a métrica de destino.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="Accuracy",
goal="Maximize",
max_total_trials=20,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Agora, pode submeter esta tarefa como anteriormente. Desta vez, vais fazer um trabalho de limpeza que varre o teu trabalho de comboio.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Pode monitorizar a tarefa utilizando a ligação de interface de utilizador do estúdio que é apresentada durante a execução da tarefa.
Localizar e registar o melhor modelo
Depois de todas as execuções serem concluídas, pode encontrar a execução que produziu o modelo com a maior precisão.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "keras_dnn_mnist_model"
path="azureml://jobs/{}/outputs/artifacts/paths/keras_dnn_mnist_model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="mlflow_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Em seguida, pode registar este modelo.
registered_model = ml_client.models.create_or_update(model=model)Implementar o modelo como um ponto final online
Depois de registar o modelo, pode implementá-lo como um ponto final online, ou seja, como um serviço Web na cloud do Azure.
Para implementar um serviço de machine learning, normalmente precisará de:
- Os recursos de modelo que pretende implementar. Estes recursos incluem o ficheiro e os metadados do modelo que já registou na sua tarefa de preparação.
- Algum código para ser executado como um serviço. O código executa o modelo num determinado pedido de entrada (um script de entrada). Este script de entrada recebe dados submetidos para um serviço Web implementado e transmite-os para o modelo. Depois de o modelo processar os dados, o script devolve a resposta do modelo ao cliente. O script é específico do seu modelo e tem de compreender os dados esperados e devolvidos pelo modelo. Quando utiliza um modelo MLFlow, o Azure Machine Learning cria automaticamente este script automaticamente.
Para obter mais informações sobre a implementação, veja Implementar e classificar um modelo de machine learning com o ponto final online gerido com o SDK Python v2.
Criar um novo ponto final online
Como primeiro passo para implementar o seu modelo, tem de criar o seu ponto final online. O nome do ponto final tem de ser exclusivo em toda a região do Azure. Para este artigo, irá criar um nome exclusivo com um identificador universalmente exclusivo (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "keras-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using Keras",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Depois de criar o ponto final, pode obtê-lo da seguinte forma:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Implementar o modelo no ponto final
Depois de criar o ponto final, pode implementar o modelo com o script de entrada. Um ponto final pode ter várias implementações. Com as regras, o ponto final pode direcionar o tráfego para estas implementações.
No código seguinte, irá criar uma única implementação que processa 100% do tráfego de entrada. Especificámos um nome de cor arbitrário (tff-blue) para a implementação. Também pode utilizar qualquer outro nome, como tff-green ou tff-red para a implementação. O código para implementar o modelo no ponto final faz o seguinte:
- implementa a melhor versão do modelo que registou anteriormente;
- classifica o modelo, utilizando o
score.pyficheiro; e - utiliza o ambiente personalizado (que criou anteriormente) para efetuar a inferência.
from azure.ai.ml.entities import ManagedOnlineDeployment, CodeConfiguration
model = registered_model
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="keras-blue-deployment",
endpoint_name=online_endpoint_name,
model=model,
# code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Nota
Espere que esta implementação dedure um pouco de tempo a concluir.
Testar o modelo implementado
Agora que implementou o modelo no ponto final, pode prever a saída do modelo implementado, utilizando o invoke método no ponto final.
Para testar o ponto final, precisa de alguns dados de teste. Vamos transferir localmente os dados de teste que utilizámos no nosso script de preparação.
import urllib.request
data_folder = os.path.join(os.getcwd(), "data")
os.makedirs(data_folder, exist_ok=True)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-images-idx3-ubyte.gz",
filename=os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"),
)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-labels-idx1-ubyte.gz",
filename=os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"),
)Carregue-os num conjunto de dados de teste.
from src.utils import load_data
X_test = load_data(os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"), False)
y_test = load_data(
os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"), True
).reshape(-1)Escolha 30 exemplos aleatórios do conjunto de testes e escreva-os num ficheiro JSON.
import json
import numpy as np
# find 30 random samples from test set
n = 30
sample_indices = np.random.permutation(X_test.shape[0])[0:n]
test_samples = json.dumps({"input_data": X_test[sample_indices].tolist()})
# test_samples = bytes(test_samples, encoding='utf8')
with open("request.json", "w") as outfile:
outfile.write(test_samples)Em seguida, pode invocar o ponto final, imprimir as predições devolvidas e desenhá-las juntamente com as imagens de entrada. Utilize a cor do tipo de letra vermelho e a imagem invertida (branco a preto) para realçar as amostras mal classificadas.
import matplotlib.pyplot as plt
# predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request.json",
deployment_name="keras-blue-deployment",
)
# compare actual value vs. the predicted values:
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Nota
Uma vez que a precisão do modelo é elevada, poderá ter de executar a célula algumas vezes antes de ver uma amostra mal classificada.
Limpar os recursos
Se não estiver a utilizar o ponto final, elimine-o para parar de utilizar o recurso. Certifique-se de que nenhuma outra implementação está a utilizar o ponto final antes de o eliminar.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Nota
Espere que esta limpeza leve algum tempo a concluir.
Passos seguintes
Neste artigo, preparou e registou um modelo keras. Também implementou o modelo num ponto final online. Veja estes outros artigos para saber mais sobre o Azure Machine Learning.